
- Про фильтрацию/NAT на базе TC (TC NAT, TC BLOCK) в отдельной статье
Фильтрация на базе DPDK
О ОБРАБОТКЕ ПАКЕТА В ЯДРЕ LINUX
-
Разное из интересного про сетевые карты из презентации google о BIG TCP (сама преза по ссылке):
- Часть функционала, который поддерживается loopback драйвером не поддерживается реальными аппаратными NIC. Поэтому тестирования сетевого приложения по loopback – спорная тема.
-
Внутри Google использовали все ключевые вендоры NIC – Intel, Mellanox (mlnx4, mlnx5), Broadcom (bnx2x, от них отказались в итоге, что-то напоминает :)).
-
Помимо оптимизации BIG TCP Google в своем ядре google linux kernel использует и другие вещи для увеличения размера payload относительно служебных данных – MTU 4k, использование максимального значения frag-list (MAX_SKB_FRAGS/MAX_FETCH_BD) на сетевой карте.
Handling packets in linux (briefly, partly from linkmeup telecom 98), mega detail article
-
- NIC
- receive on port
- demodulation/analog-digital from physical media
- send to RAM (old: nic memory) ring buffer (nic queue) via DMA (bypassing cpu) through PCI (old: other interfaces)
- Кольцевой буфер, или циклический буфер (англ. ring-buffer) — это структура данных, использующая единственный буфер фиксированного размера таким образом, как будто бы после последнего элемента сразу же снова идет первый. Такая структура легко предоставляет возможность буферизации потоков данных.
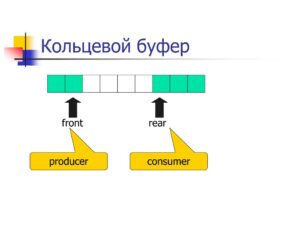
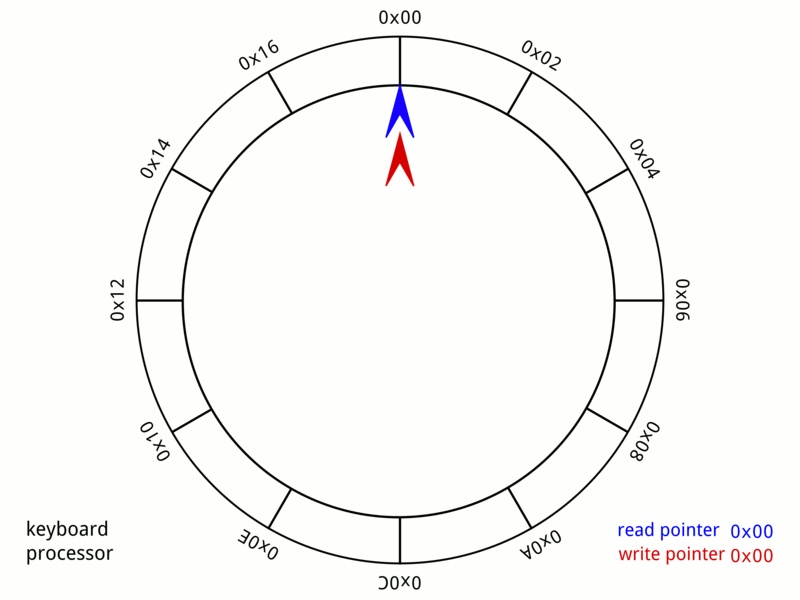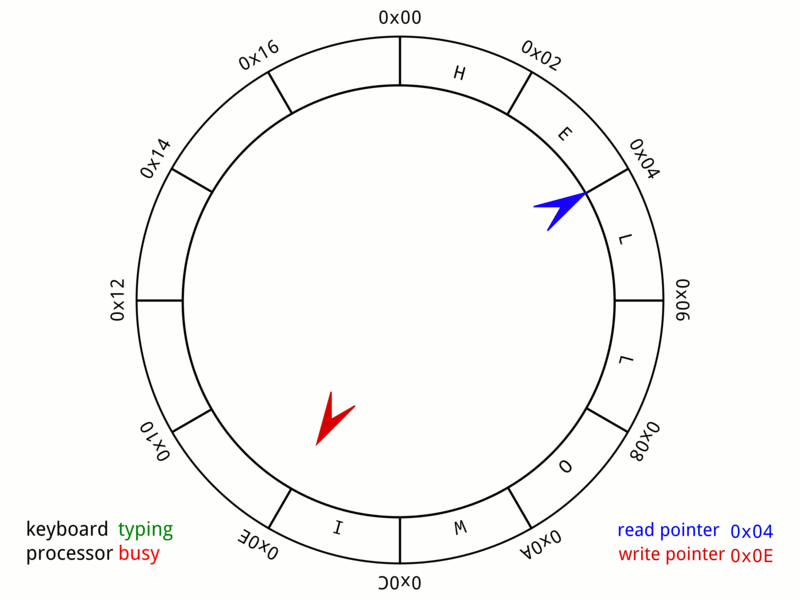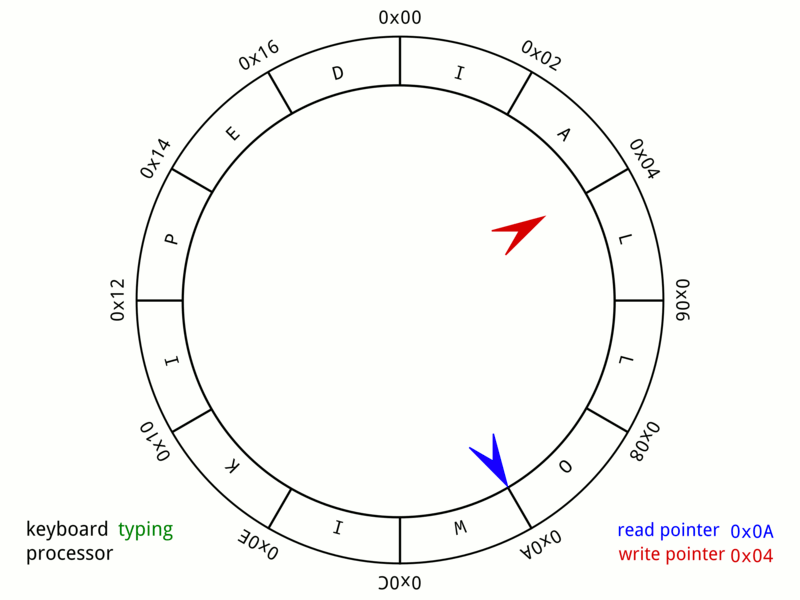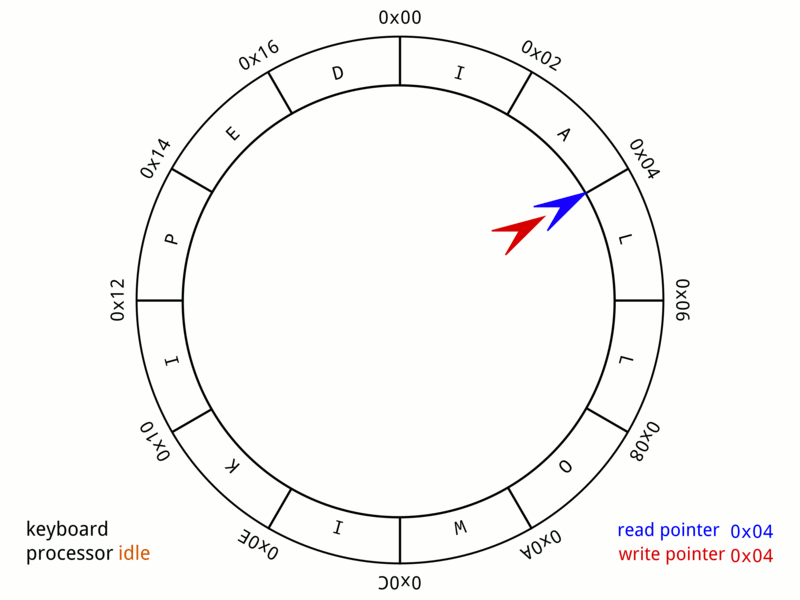
- A 24-byte keyboard circular buffer. When the write pointer is about to reach the read pointer—because the microprocessor is not responding—the buffer stops recording keystrokes. On some computers a beep would be played.
- generate interrupt for OS kernel/nic driver
- KERNEL/NIC DRIVER
- handle interrupt (softirq)
- sending interrupt to CPU (may be for N packets only, virtio)
- through napi pull nic registers other frames (by time_limit in msecs/packet_budget from the first frame – can be tunned) from NIC to RAM without interrupts
- separate each frame: create OS header (descriptor/socket buffer – skb?) and payload (buffer)
- optional RSS/RPS
- send frame to queue
- optional
-
- FCS/Checksums
- GRO
- qdisc
- netfilter/FW rules
- routing
- socket (UDP or TCP)
- routing
-
- handle interrupt (softirq)
- NIC
packet flow (pipeline)
Тут только packet flow, подробнее в отдельном разделе. Есть так же куча других представлений packet flow внутри ядра Linux.
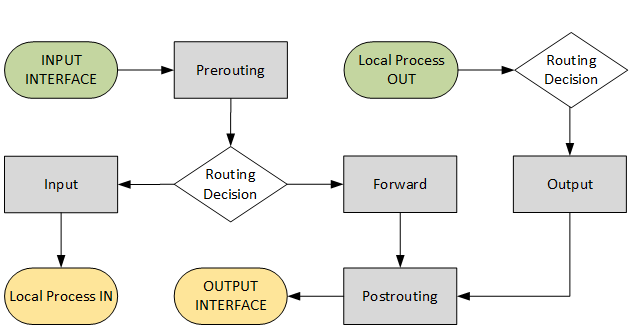
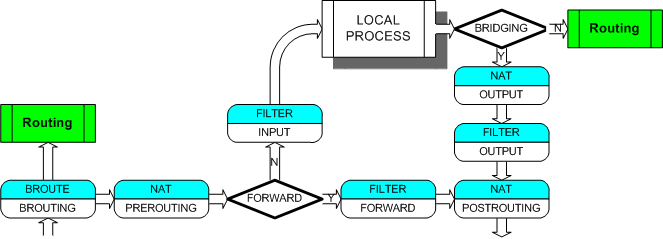
- Определение цепочек (основа) прохождения пакетов в зависимости от источника и назначения
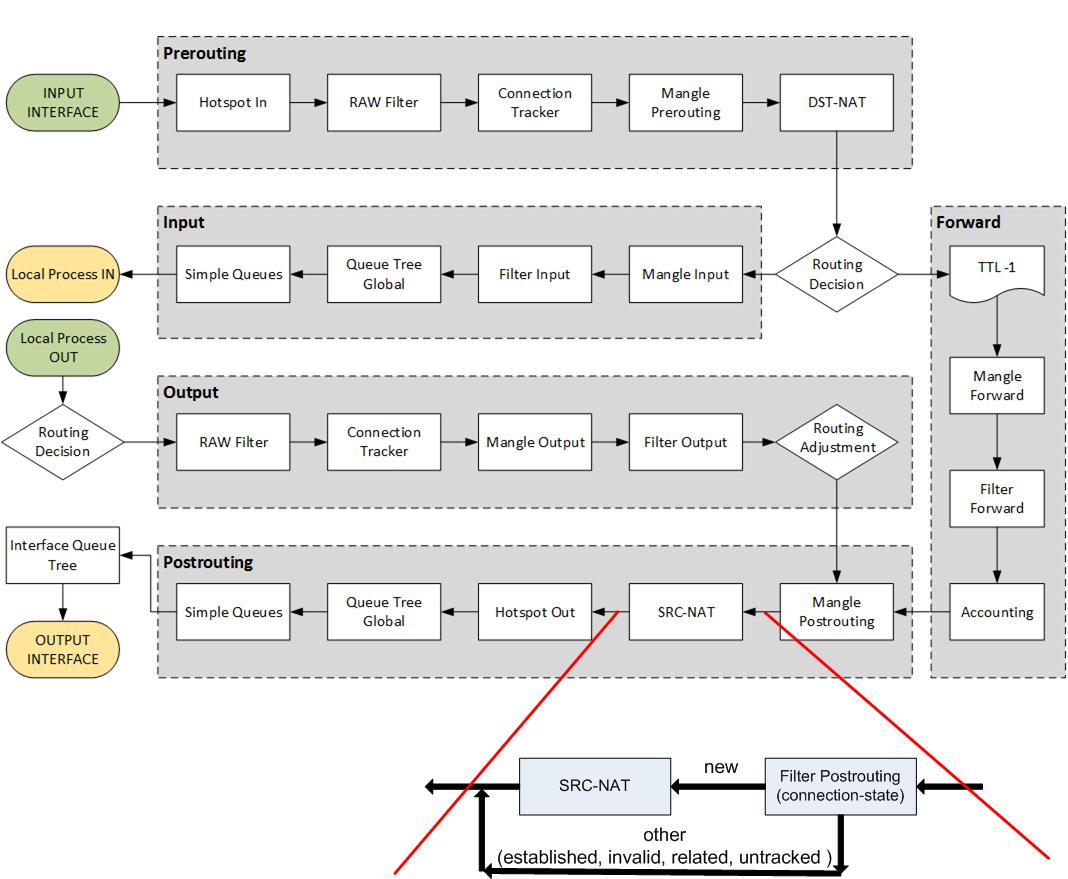
- Более полная и довольно понятная схема (так же из статьи выше в habr с небольшим дополнением автора)
{kind=link}
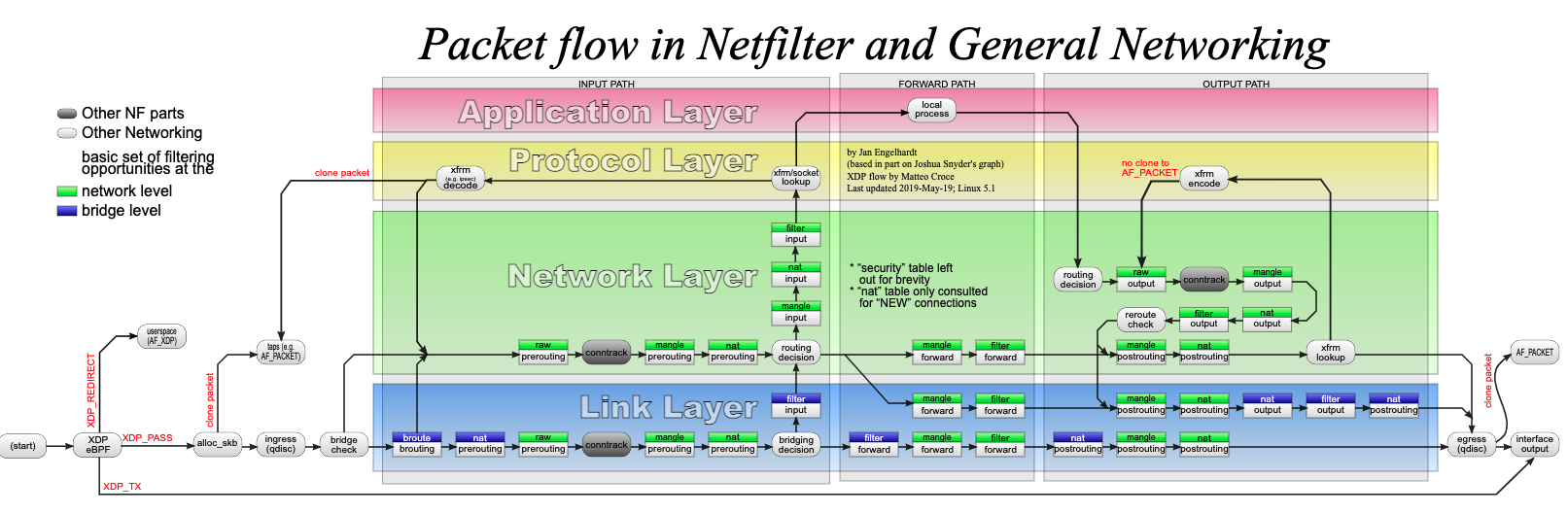
еще одна вариация
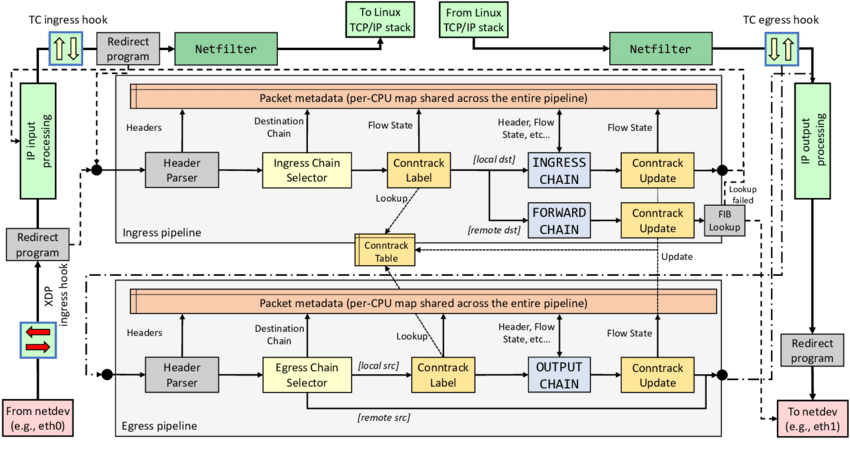
iface input -> xdp -> qdisc (ingress) -> brouting -> prerouting -> conntrack -> prerouting -> forward -> postrouting -> qdisc (egress) -> iface output

{kind=link}
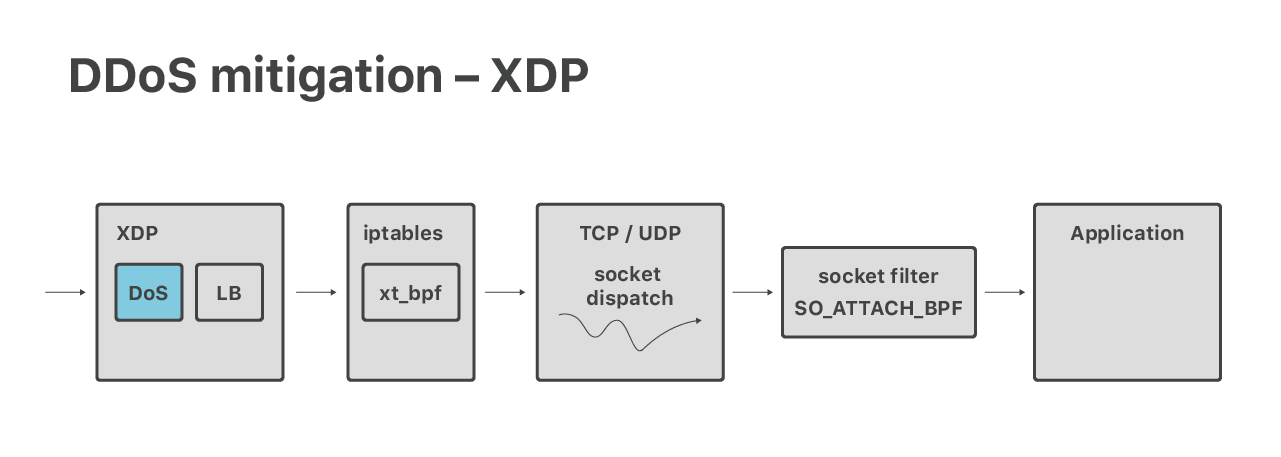
- CloudFlare:
XDP -> qdisc -> IPTABLES -> SOCKET -> APPLICATION
XDP
подробнее в dpdk
firewalld (firewall-cmd)
Является надстройкой над Iptables. Примеры применения firewall-cmd описаны в статьях по деплою ftp/tftp на базе CentOS7.
UFW
По умолчанию UFW настроен для VM Debian 13 при деплое на firstvds. Удобно создавать/удалять правила (например, ipsmanager если он не используется или широкие правила разрешения SSH), правила автосохраняются после действий.
Uncomplicated Firewall (UFW) — это простой инструмент командной строки для управления брандмауэром (firewall) в Linux, используемый по умолчанию в Ubuntu и Debian. Он упрощает настройку сложных правил iptables или nftables, позволяя легко разрешать/блокировать порты, IP-адреса и протоколы IPv4/IPv6 для защиты сервера от несанкционированного доступа.
root@weril:~# ufw version
ufw 0.36.2
Copyright 2008-2023 Canonical Ltd.
root@weril:~# ufw status verbose
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
New profiles: skip
To Action From
-- ------ ----
80/tcp ALLOW IN Anywhere
443 ALLOW IN Anywhere
22/tcp ALLOW IN Anywhere
1500/tcp (ispmanager) ALLOW IN Anywhere
80/tcp (v6) ALLOW IN Anywhere (v6)
443 (v6) ALLOW IN Anywhere (v6)
22/tcp (v6) ALLOW IN Anywhere (v6)
1500/tcp (ispmanager (v6)) ALLOW IN Anywhere (v6)
root@weril:~# ufw allow 35101/tcp
Rule added
Rule added (v6)
root@weril:~# ufw allow from 1.1.1.1 to any port 35101 proto tcp
Rule added
root@weril:~# ufw allow from 2.2.2.2 to any port 35101 proto tcp
Rule added
root@weril:~# ufw status numbered
Status: active
To Action From
-- ------ ----
[ 1] 80/tcp ALLOW IN Anywhere
[ 2] 443 ALLOW IN Anywhere
[ 3] 22/tcp ALLOW IN Anywhere
[ 4] ispmanager ALLOW IN Anywhere
[ 5] 35101/tcp ALLOW IN Anywhere
[ 6] 80/tcp (v6) ALLOW IN Anywhere (v6)
[ 7] 443 (v6) ALLOW IN Anywhere (v6)
[ 8] 22/tcp (v6) ALLOW IN Anywhere (v6)
[ 9] ispmanager (v6) ALLOW IN Anywhere (v6)
[10] 35101/tcp (v6) ALLOW IN Anywhere (v6)
root@weril:~# ufw delete 3
Deleting:
allow 22/tcp
Proceed with operation (y|n)? y
Rule deleted
Отключение IPv6 через конфигурацию (после отключения не создаются дублирующиеся ipv6 правила):
nano /etc/default/ufw
IPV6=no
Изменение глобальной политики для input/output/forward возможно как через cli, так и через конфигурацию /etc/default/ufw :
ufw default deny incoming
ufw default allow outgoing
ufw default deny routed
nano /etc/default/ufw
DEFAULT_INPUT_POLICY="DROP"
DEFAULT_OUTPUT_POLICY="ACCEPT"
DEFAULT_FORWARD_POLICY="DROP"
(ИИ, UFW, WordPress, docker)
На реальной практике ИИ (grok) помог разобраться
- в проблеме с блокировкой графика UFW с внешнего интерфейса в докер контейнера; по факту решил, но не до конца (потери исходящего из контейнера трафика, глюки с доступностью сайта с восстановлением после отключения ufw), полноценное решение – разрешение всего маршрутизируегося трафика на podman1 интерфейс и входящего DNS трафика на podman1 интерфейс. Проблема связана с конфликтами UFW правил и docker/podman, который напрямую настраивает ip/nftables!
You shouldn’t use UFW with Docker/Podman since they have their own networking. This is stated in the official Docker/Podman documentations.
Docker and ufw
Uncomplicated Firewall (ufw) is a frontend that ships with Debian and Ubuntu, and it lets you manage firewall rules. Docker and ufw use firewall rules in ways that make them incompatible with each other.
When you publish a container's ports using Docker, traffic to and from that container gets diverted before it goes through the ufw firewall settings. Docker routes container traffic in the nat table, which means that packets are diverted before it reaches the INPUT and OUTPUT chains that ufw uses. Packets are routed before the firewall rules can be applied, effectively ignoring your firewall configuration.
ufw disable # check reachibility ufw enable
# PARTIAL SOLUTION ufw route allow proto tcp from any to any port 80 ufw route allow proto tcp from any to any port 443
# COMPLETE SOLUTION
ufw route allow in on podman1
ufw route allow out on podman1
ufw allow in on podman1 to any port 53 proto udp
-
В проблеме с некорректными скобками в конфигурации WordPress (wp-config.php) и ошибкой 500
podman logs wordpress
nftables
Разработчики Netfilter официально объявили инструментарий iptables устаревшим.
nftables является проектом по замене фреймворков iptables, ip6tables, arptables[en], ebtables в межсетевом экране Netfilter.
И nftables и bpfilter умеют транслировать команды (часть nftables и как понимаю все bpfiler) традиционного синтаксиса iptables в “свои”.
Как я понял nftables в сравнении с iptables:
1) + быстрее за счет уменьшения строк кода + сам код меньше памяти занимает. Это достигается за счет использования ассоциированных масивов (хешей/картежей) в nftables можно создавать правила (например SNAT, DNAT с разных IP на разные IP), аналогичные Iptables, только имеющие значительно меньше строк.
2) + может обновляться без пересборки ядра
3) + использование netlink вместо системных вызовов (огромный ряд плюсов напр. netlink позволяет поддерживать синхронность, ядро может отдавать данные в приложение без опроса)
4) – ipt_netflow нет
Пример настройки nftables (разница с iptables по сути только в синтаксисе):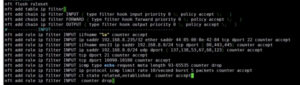
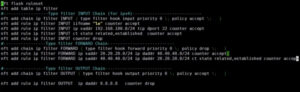
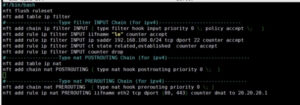
EBTABLES
В них можно использовать bridge правила – broute/brouting. Схемы выше.
(e)BPF
-
(dpdk, bpf) dpdk + bpf
-
rte_bpf позволяет применять к пакетикам eBPF код. Предполагается, видимо, что такие фильтры будут предварительно составляться на С и отдельно транслироваться в ebpf программу, которую потом можно будет применить в DPDK. А вот если хочется применять привычные фильтры, написанные в синтаксисе tcpdump (pcap-filter), то возникает проблема: с одной стороны, их умеет транслировать в cBPF библиотека libpcap. А с другой стороны, dpdk rte_bpf не умеет загружать cBPF. Кажется, что глобально вариантов ровно 2: 1) как-то транслировать прямо pcap-filter -> eBPF 2) транслировать cBPF -> eBPF . Было бы интересно узнать, если кто-то решал такую задачу.
-
Есть более простой вариант. В main есть функция rte_bpf_convert(). Она принимает cBPF опкеды, которые из тестового фильтра можно получить через libpcap. Будет работать и jit: Имеем опкоды cBPF. Получаем опкоды EBPF через rte_bpf_convert(). Отдаем их в rte_bpf_load(), получаем struct rte_bpf* с JIT.
BPF filters are widely used by the Linux kernel, TCP dump and others. Basically any tcpdump filtering tutorial can be used to define a filter for TRex.
Some simple examples using BPF:
All ARP or ICMP packets:
'arp or icmp'
All UDP packets with destination port 53:
'udp and dst 53'
All packets VLAN tagged 200 and TCP SYN:
'vlan 200 and tcp[tcpflags] == tcp-syn'Hardware BPF
BPF в целом очень перспективное направление – оно позволяет сделать фильтрацию по байт коду еще до Kernel без всяких kernel bypass (как в случае DPDK) еще на уровне NIC. Но пока не полноценное – сложные фильтры пока не реализуемы, для загрузки BPF кода на NIC нужна поддержка NIC такого действия.
bpfilter
Является проектом, который должен заменить всех тех же что и nftables, только и сам nftables))))))))
И nftables и bpfilter умеют транслировать команды (часть nftables и как понимаю все bpfiler) традиционного синтаксиса iptables в “свои”.
EBPF
- (xdp, ebpf) Хорошее описание работы eBPF и XDP
eBPF (Extended Berkeley Packet Filter)
eBPF очень активно используют CloudFlare для работы с трафиком. На базе eBPF реализован XDP.
The talk ended up being mostly about BPF. It seems, no matter the question - BPF is the answer.
eBPF предоставляет встроенный в ядро интерпретатор байткода, дающий возможность через загружаемые из пространства пользователя обработчики на лету менять поведение системы без необходимости изменения кода ядра, что позволяет добавлять эффективные обработчики без усложнения самой системы. В том числе на базе eBPF можно создавать обработчики сетевых операций, управлять пропускной способностью, контролировать доступ, отслеживать работу систем и выполнять трассировку. Благодаря применению JIT-компиляции, байткод на лету транслируется в машинные инструкции и выполняется с производительностью нативного кода.
Сессии
Сессии на порту
netstat -na | grep ":33231"
ss | grep ":33231"Количество сессий
netstat -pant | wc -l
NAT статистика
netstat-nat -n -N # показываем, во что резолвим (напр. src - changed src - dst)
Сессии по приложениям (windows only)
netstat -nabo
iptraf
Утилита старая (судя по about разработка закончиалсь в далеком 2004), но рабочая. Установка ее простейшая.
apt install iptraf
iptraf
Утилита собирает сетевую статистику с интерфейсов. Неплохо кастомизируется и легко управляется (pseudo-gui): можно выбрать интерфейс, тип статистики.
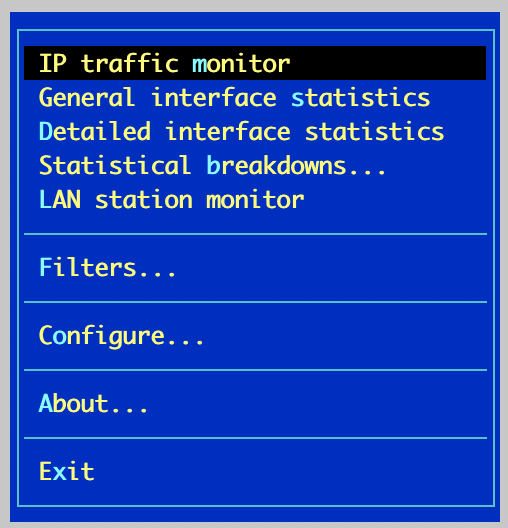
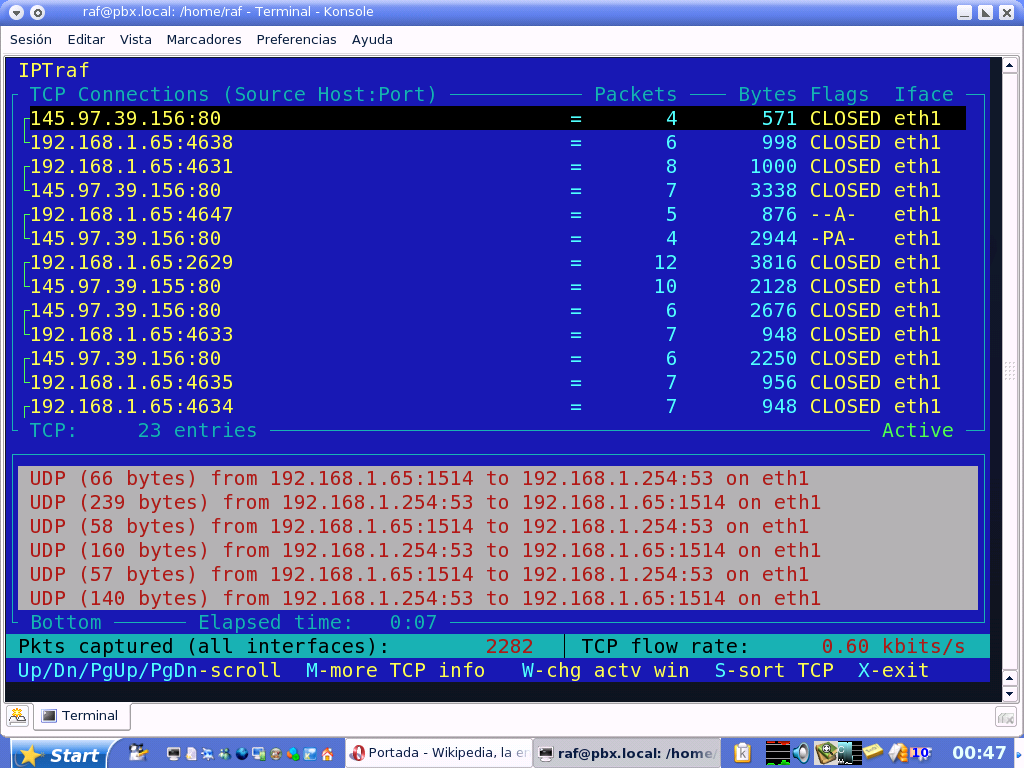
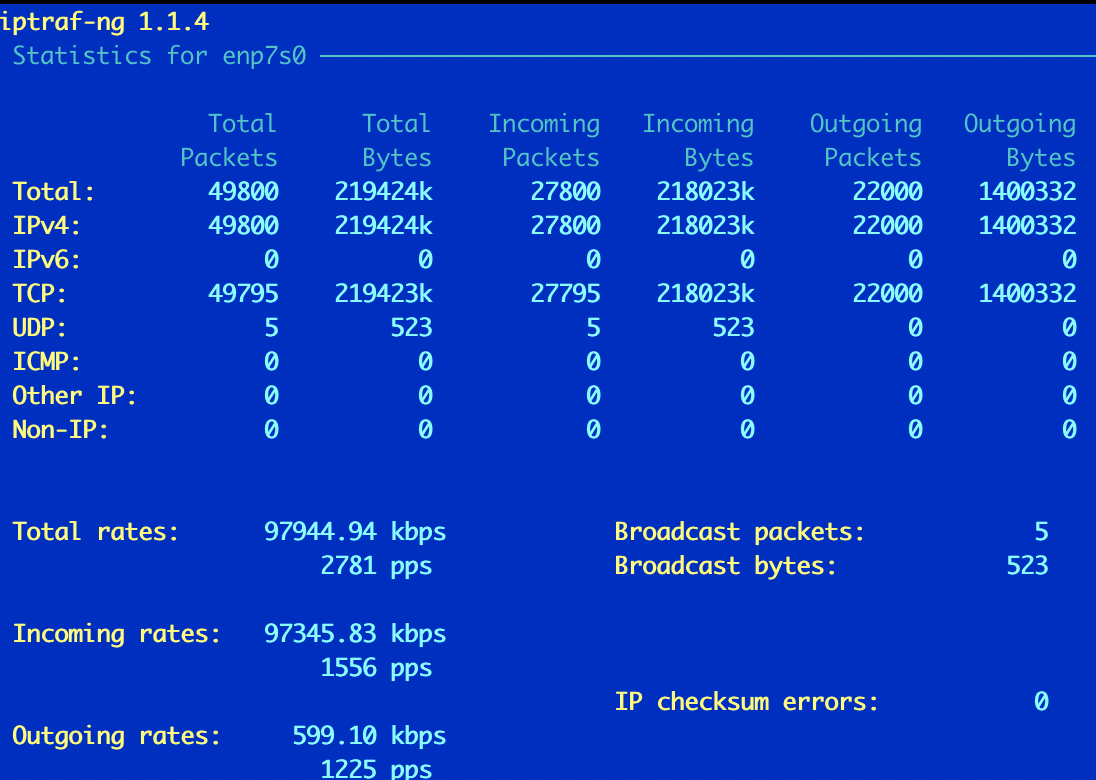


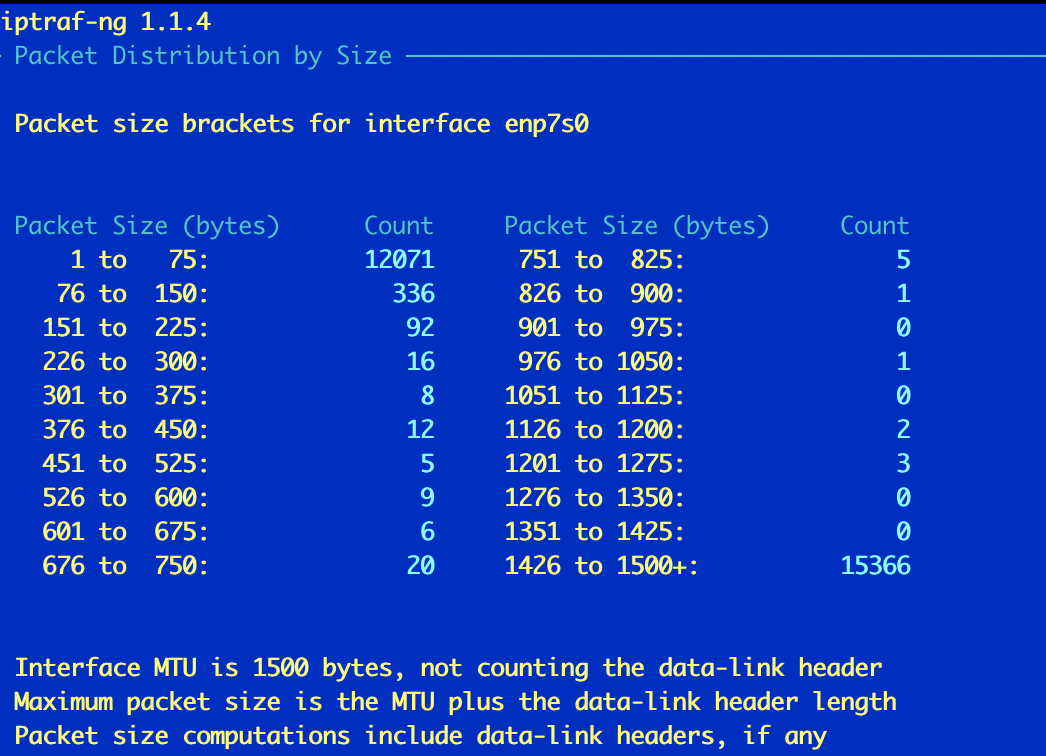
Conntrack
Conntrack netfilter — модуль для отслеживания/управления соединениями. Используется при NAT и “улучшенной” пакетной фильтрации.
Conntrackd — демон инструментов netfilter, отслеживающий user-space соединения. Может быть использован в паре с keepalived для создания отказоусточивого кластера шлюзов. Является инструментом из пакета cronntrack-tools.
conntrackd -s # просмотр синхронизации сессий в кластере
Пример настроек conntrack для высокопроизводительных серверов с NAT и для минимизации влияния DOS в статье DOS.
Connection tracking keeps a record of what packets have passed through your machine, in order to figure out how they are related into connections. This is required to do Masquerading or other kinds of Network Address Translation. It can also be used to enhance packet filtering (see `Connection state match support' below).
Usage
# conntrack –E # смотрим онлайн
# conntrack -L # аналог cat /proc/net/ip_conntrack
conntrack v1.2.1 (conntrack-tools): 999889 flow entries have been shown.
999889 14998333 158996207
# conntrack -F
conntrack v1.2.1 (conntrack-tools): connection tracking table has been emptied.
# /proc/sys/net/ipv4/netfilter/ip_conntrack_max # макс. количество соединенийПро тюнинг размера таблицы iptables conntrack – memory dependent. Тюнить нужно аккуратно – где-то будет прирост, а где-то наоборот деградация. С ростом значения hash-таблицы деградирует скорость удаления записей, причем это справедливо даже для пустой таблицы!- По умолчанию 1/8 от количества соединений
- По опыту одного из подписчиков IETF BMWG (G?bor LENCSE)
- влияние на CPS: hashsize лучше настраивать аналогичным значению количества соединений nf_conntrack_max
- влияние на tear down: hashsize лучше настраивать по умолчанию т.к. с ростом размера увеличивается время на чистку
https://datatracker.ietf.org/doc/html/draft-lencse-v6ops-transition-scalability-02
The ratio of number of connections in the connection tracking table
and the value of the hashsize parameter of iptables significantly
influences its performance. Although the default setting is
hashsize=nf_conntrack_max/8, we have usually set.
hashsize=nf_conntrack_max to increase the performance of iptables.
We note that according to the recommended settings of iptables, 8
connections are hashed to each place of the hash table on average,
but we wilfully used much smaller number (0.745 whenever it was
possible) to increase the maximum connection estabilishment rate and
thus to speed up experimenting. However, finally this choice
significantly slowed down our experiments due to the very low
connection tear down rate.As for iptables, I can tune the size of the connection tracking table nearly arbitrarily, it seems that the memory capacity is the only limit.
I can tune two values:
- nf_conntrack_max-- It specifies the maximum of the number of entries in the state table
- hashsize-- It specifies the number of entries of the hash table. (I far as I remember, all of them are linked list heads. The elements of the lists store the parameters of the connections.)
This source https://ixnfo.com/en/tuning-nf_conntrack.html recommends
hashsize=nf_conntrack_max/8, (what would result in linked lists of 8
elements on average) and my experience shows that larger hashsize
ensures higher performance. (When I could, I used
hashsize=nf_conntrack_max.) The value of hashsize is limited by the size
of the memory. E.g. having 384GB of RAM, I could set it to 2^28, but I
could not set it to 2^29. (I got an error message.) With hashsize=2^28,
I used nf_conntrack_max=2^30, and the memory usage was somewhat below
300GB. (Using another computer, I once accidentally exhausted its 256GB
of RAM.)-bash-4.4# cat /proc/net/stat/ip_conntrack
entries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete search_restart
00000027 00082000 0a4c957c 00156632 000018c4 0a56dc4f 0015660b 00155d1f 00155d46 00000007 00000000 00000000 00000001 00000000 00000000 00000000 00000000IPSET
Настройка IPSET может влиять на performance, но в кейсе применения в нагрузочном тесте было 400 ТЫС записей blacklist и это понижало производительность до 15% и только для мелких пакетов. Для крупных/в firewall тестированиях просадок не было. Потребление памяти минимальное (до +30МБ без ipset). В целом крутая фича, просадка чистого iptables правила значительно выше (при 20к правил просадка до 95%).
IP sets are a framework inside the Linux kernel, which can be administered by the ipset utility. Depending on the type, an IP set may store IP addresses, networks, (TCP/UDP) port numbers, MAC addresses, interface names or combinations of them in a way, which ensures lightning speed when matching an entry against a set.
If you want to
- store multiple IP addresses or port numbers and match against the collection by iptables at one swoop;
- dynamically update iptables rules against IP addresses or ports without performance penalty;
- express complex IP address and ports based rulesets with one single iptables rule and benefit from the speed of IP sets
IP blacklist
Используется для блокировки спама/DoS/DDoS в связке с iptables. Еще примеры. Пример блокировки пула (китайские IP). Пулы можно взять с сайта https://www.countryipblocks.net/ или сайта2 https://www.ipdeny.com/ (могут быть недоступны из России).
# apt install ipset
# ipset create countryblock nethash
# ipset add countryblock 1.0.1.0/24
# ipset add countryblock 1.0.2.0/23
# ipset add countryblock 1.0.8.0/21
# ipset add countryblock 1.1.0.0/24
# ipset add countryblock 1.1.2.0/23
# ipset -L blacklist
# iptables -A INPUT -m set --match-set countryblock src -j DROPIP whitelist
Кроме blacklist можно создавать и whitelist, особенно это полезно, когда сервис локализован какой-то страной. Там так же есть скрипт выгрузки с сайта https://www.ipdeny.com/ и формирования списков стран СНГ как whitelist для ipset.
Список подходящих мне стран гораздо меньше, чем список нежелательных. Так что я пошел по другому пути и запретил доступ всем, кроме некоторых стран.
Не забывайте важный момент - чтобы у вас белый список работал, у вас должен весь трафик, который не разрешен явно, блокироваться.# ipset -N whitelist nethash # альтернативное создание/добавление флагами
# ipset -A whitelist 6.43.240.0/21 # ipset -A whitelist 7.100.64.0/18 # ipset -A whitelist 8.159.112.0/21
# iptables -A INPUT -i $WAN -m set --match-set whitenet src -p tcp --dport 80 -j ACCEPT # iptables -A INPUT -i $WAN -m set --match-set whitenet src -p tcp --dport 443 -j ACCEPTМаксимумы можно тюнить тут.
ipset create blacklist nethash hashsize 16348 maxelem 131072
NOT IP OBJECTS
Кроме IP утилита может работать (создавать списки) так же с портами, MAC адресами и номерами интерфейсов. Real example.
ipset -N BAD-PORTS bitmap:port range 135-1512
ipset -A BAD-PORTS 135
ipset -A BAD-PORTS 137-139
ipset -A BAD-PORTS 144
ipset -A BAD-PORTS 445
ipset -A BAD-PORTS 1512IPtables
-
- Разработчики Netfilter официально объявили инструментарий iptables устаревшим. См. Nftables/bpfilter. Схемы обработки выше.
- Iptables не проверяет существование добавляемого правила
- По умолчанию на цепочках POLICY ACCEPT, это означает permit any any в конце списка правил
- ACCEPT means that the default policy for that chain, if there are no matching rules, is to allow the traffic. DROP does the opposite.
- Отличия DROP от REJECT.
- При сбросе пакетов используют обычно две цели — DROP и REJECT, при этом нужно понимать, почему вы используете именно этот вариант. Основное различие состоит в том, что при использовании DROP не будет отправлен ICMP-ответ, по которому можно будет определить, что в соединении отказано. Оно просто не пройдет. Когда вы используете REJECT, то вы явно получите ответ, что в соединении отказано.
-
В сети давно идет холивар на тему что лучше. Выбор зависит от того, какие задачи нужно решить и от чего защититься. В нашем примере будем использовать Drop, это позволит снизить нагрузку на процессор и уменьшить исходящий трафик, так как маршрутизатор не будет отправлять ответ (как при reject), а просто сбрасывать соединение.
- (tcp, iptables) Изменение TCP окна на промежуточном оборудовании – огромная редкость и должно быть использовано только для тестов в общем случае. Изменить можно добавив модуль ipt_tcpwin в iptables. Одна из причин, почему это делать не стоит – изменение требует пересчет TCP Checksum, хотя это и может быть реализовано на уровне offload, но не в данном случае судя по коду модуля.
https://serverfault.com/questions/528065/how-to-edit-tcp-window-size-from-iptables
To change TCP window from iptables you need to:
1) checkout https://github.com/p5n/ipt_tcpwin ((to use in POSTROUTING chain we should modify TCP checksum))
2) build both modules using "make"
3) add iptables rule, for example:
iptables -t mangle -I OUTPUT -p tcp --sport 80 --tcp-flags SYN,ACK SYN,ACK -j TCPWIN --tcpwin-set 1000
This iptables module changes TCP window header field. The purpose is only testing and debugging because of changing TCP window
usualy is very bad idea.IPtables часто работает в связке с fail2ban. Fail2ban автоматически добавляет правила в iptables: после нескольких некорректных авторизаций (bruteforce), после обнаруженной атаки по порогу (syn flood) или других атак (можно самому паттерны создавать). Причем при массовой атаке в iptables может оказаться до нескольких тысяч-десятков тысяч адресов одновременно. На событие добавления блокировки может служить триггером – отправить email/sms/etc.
Команды и опции
-
-
- APPEND (-A) / PREPEND (-I) – добавление в конец (APPEND) и начало/конкретную позицию (PREPEND)
- SOURCE IP (-s) / DESTINATION IP (-d)
-
добавляем на первую позицию разрешение для SOURCE IP
-
iptables -t raw -i ens3 -I PREROUTING 1 -s 185.17.123.239 -j ACCEPT
-
-
добавляем на вторую позицию разрешение для DST IP
-
iptables -t raw -i ens3 -I PREROUTING 2 -d 185.17.123.239 -j ACCEPT
-
-
iptables –list или –L – смотрим правила iptables. Для просмотра нужны права админа.
~$ sudo iptables --list Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination $ iptables --list iptables v1.4.20: can't initialize iptables table `filter': Permission denied (you must be root)
iptables -nvL – смотрим правила по категориям, используя -nat так же смотрим правила prerouting/postrouting. Тут же отображается статистика по пакетам для каждого правила, что очень удобно.
# iptables -nvL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
# iptables -t nat -nvL
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
iptables … –line-numbers – нумеруем правила
iptables -L -vn --line-numbers | grep <ip or comment>
iptables … -tee – c помощью IPTABLES можно зеркалировать трафик который идет к хосту, перенаправляя копию пакета к другому хосту используя опцию tee.
There is an experimental target (ROUTE) which offers an option (--tee) that behaves like the good old linux “tee” command. It copies a packet to a target ip address and then goes on with the normal behaviour (routing it to it’s normal target.) This will send a copy of all packets to the monitor pc with the ip 192.168.1.254. iptables -A PREROUTING -t mangle -j ROUTE --gw 192.168.1.254 --tee iptables -A POSTROUTING -t mangle -j ROUTE --gw 192.168.1.254 --tee
Пример блокировки любого ICMP, SSH и трафика на порт 25007 (management outline)
(vpn-linux, iptables) При поднятии любого сервера нужно ограничивать доступ к портам его управления (ICMP, SSH, управление VPN сервером) не через VPN и console/VNC облака, проще всего это сделать через настройку на стороне облачного firewall, но иногда это проблематично, тут пригодится iptables. Блокируем ICMP, открытый SSH (не через туннель) и доступ к MGMT outline (не через туннель):
# смотрим правила, наши должны быть первыми, при необходимости удаляем через iptables -t raw -D PREROUTING 4
iptables -nvL -t raw --line-numbers
# создаем правила, проверяем, что они работают без поднятного VPN
iptables -t raw -i ens3 -A PREROUTING -p icmp -j DROP
iptables -t raw -i ens3 -A PREROUTING -p tcp --dport 25007 -j DROP
iptables -t raw -i ens3 -A PREROUTING -p tcp --dport 22 -j DROP
# при необходимости удаляем и траблшутим
iptables -t raw -D PREROUTING 1
tcpdump -n -i ens3 src host <1.1.1.1> and not port 22
# сохраняем даже на случай перезагрузок
sudo apt install iptables-persistent
sudo service netfilter-persistent save
nat в IPTABLES
PORT FORWARDING (проброс портов)
Доступ к IP 172.20.1.51 по SSH через подключение к 172.20.1.50:10051: Пробрасываем трафик пришедший на 10051 порт IP 172.20.1.50 на IP 172.20.1.51:22 (SSH default). Для обратного трафика от 172.20.1.51:22 подменяем IP на 172.20.1.50.
sudo iptables -t nat -A PREROUTING -i enp7s0 -p tcp --dport 10051 -j DNAT --to-destination 172.20.1.51:22
sudo iptables -t nat -A POSTROUTING -o enp7s0 -p tcp --dport 22 -d 172.20.1.51 -j SNAT --to-source 172.20.1.50
Доступ к IP 172.20.1.51 по WEB через подключение к 172.20.1.50:18051: Пробрасываем трафик пришедший на 18051 порт IP 172.20.1.50 на IP 172.20.1.518080 (WEB). Для обратного трафика от 172.20.1.51:8080 подменяем IP на 172.20.1.50.
sudo iptables -t nat -A PREROUTING -i enp7s0 -p tcp --dport 18051 -j DNAT --to-destination 172.20.1.51:8080
sudo iptables -t nat -A POSTROUTING -o enp7s0 -p tcp --dport 8080 -d 172.20.1.51 -j SNAT --to-source 172.20.1.50
MASQUERADE
Настройка NAT в iptables простейшая – нужно указать вместо enp0s17 название вашего интерфейса через который выходите в интернет.
Работает и для router on a stick в топологии, когда на NAT роутере всего один интерфейс (и внешний и внутренний).
iptables -t nat -A POSTROUTING -o enp0s17 -j MASQUERADE
Смотрим настройки NAT.
iptables --list -t nat
Чистим настройки NAT.
iptables -F -t nat
Удаляем правило №3 nat postrouting/prerouting.
iptables -t nat -D POSTROUTING 3
iptables -t nat -D PREROUTING 3
Смотрим сессии NAT.
netstat-nat -n -N # показываем, во что резолвим (напр. src - changed src - dst)
MISC USAGE
Показать все правила.
iptables -S
Удалить все правила.
iptables -F
Сохранить все правила в файл. Для сохранения при перезагрузках лучше всего использовать iptables-persistent (см. ниже и выше).
iptables-save > /etc/network/iptables.rules
Разрешить весь входящий трафик
sudo iptables -I INPUT -j ACCEPT
sudo iptables -D INPUT 1
Разрешить весь исходящий трафик
sudo iptables -I OUTPUT -j ACCEPT
sudo iptables -D OUTPUT 1
Добавляем входящие правило N 93 c разрешением для определенного TCP порта, определенного хоста.
sudo iptables -I INPUT 93 -s 66.133.109.36 -p tcp -m tcp --dport 80 -m comment --comment "HTTP for let's encrypt certbot" -j ACCEPT
Запретить трафик еще на раннем в цепочке уровне prerouting (смотри выше в схемах).
iptables -t raw -I PREROUTING -m iprange --src-range 1.2.3.0-1.2.3.250 -j DROP
iptables -t raw -A PREROUTING -p udp -m limit --limit 1/sec --limit-burst 1000 -j ACCEPT
iptables -t raw -A PREROUTING -p udp -j DROP
Запретить трафик на порт 80.
iptables -A INPUT -p tcp --dport 80 -j DROP
Запретить трафик на порт 80 с reject и tcp reset или icmp host uncreachable.
iptables -A INPUT -p tcp --dport 80 -j REJECT iptables -A INPUT -p tcp --dport 80 -j REJECT --reject-with tcp-reset iptables -A INPUT -p tcp --dport 80 -j REJECT --reject-with icmp-host-unreachable
Удаляем входящие правило N 93
sudo iptables -D INPUT 93
Смотрим трафик (gentoo)
sudo tail -f /var/log/kern.log | grep TCP
Сохранение в постоянные настройки правил iptables.
sudo apt install iptables-persistent
sudo service netfilter-persistent save # deprecated sudo service iptables-persistent save
IPTABLES + SSHD
На примере CentOS 7 ограничиваем доступ к SSH серверу. Не забываем на всякий случай сделать аналогичные настройки в самом демоне ssh – реализуем концепцию defense in depth (даже если по какой-то причине “рухнет” iptables, будет продолжать работать защита на базе application).
/etc/ssh/sshd_config
AllowUsers <username>@<ip>
Прописываем конкретный хост для доступа по SSH порту
sudo iptables -I IN_public_allow 5 -s <IP> -p tcp -m tcp --dport <ssh port> -m comment --comment "SSH from <LOCATION>" -j ACCEPT
Удаляем стандартный доступ со всех хостов
sudo iptables -D IN_public_allow 1
BSD PF (packet filter)
- pf filter BSD был создан примерно одновременно с iptables (2001 год PF, 1998 iptables)
- pfctl используется для управления BSD (FreeBSD, OpenBSD) packet filter
BSD IPFW
IPFW – считается очень хорошим файрволом на FreeBSD – быстрым, удобным, с большим количеством функционала. У мелких провайдеров зачастую используются FreeBSD тачки с BRAS-функционалом (политика разрешения + шейпер) на базе IPFW – например, по IP пользователя узнаем его тариф из базы, на его основе назначаем bandwidth в ACL для трафика с этого IP.
Для установки лучше пересобирать ядро, а не загружать модулем или еще как (через порты). Пример настройки тут.
Один пример (разрешаем конкретные типы ICMP):
${FwCMD} add allow icmp from any to any icmptypes 0,8,11
Еще пример с bash-логикой (режем bandiwdth по ночам чтобы не качали непонятно кто, непонятно что):
Также, необходимо заметить, что сам файл файрволла, по сути является shell-скриптом, - со всеми вытекающими плюсами - типа регулировка траффика день/ночь, в последнем примере..chour=`date '+%H'`
if [ ${chour} -lt 8 ]; then
${FwCMD} add pipe 1 ip from not ${NetIn} to ${NetIn}
${FwCMD} pipe 1 config bw 33600 bit/s
fi
if [ ${chour} -ge 22 ]; then
${FwCMD} add pipe 1 ip from not ${NetIn} to ${NetIn}
${FwCMD} pipe 1 config bw 33600 bit/s
fi
Jool (NAT64)
I had experience only with iptables (stateful NAT44). Since then, I have some experience with Jool (stateful NAT64).
Scalability of iptables VS Scalability of Jool
https://datatracker.ietf.org/doc/html/draft-lencse-v6ops-transition-scalability-02#page-8
We are aware that the performance of removing the entire content of the connection tracking table at one time may be different from removing all the entries one by one.
https://datatracker.ietf.org/doc/html/draft-lencse-v6ops-transition-scalability-01#section-3
As an application of you draft "Benchmarking Methodology for Stateful NATxy Gateways using RFC 4814 Pseudorandom Port Numbers", I have measured the peformance of the Jool stateful NAT64 implementation. I have examined, how its performance metrics (maximum connection establisment rate and throughput) scale up with the number of CPU cores, and how the number of connections degrade its performance. (Jool scaled up much less well than iptables.)