

-
Python.org – основной сайт. Тут можно скачать актуальный python на windows/linux/mac os, посмотреть документацию
- Гвидо ван Россум – творец языка. По сути аналог Линус Торвальдса для Linux. 1989 год Голландский разработчик Гвидо ван Россум в качестве хобби-проекта во время рождественских каникул создает язык программирования Python. Шутка зашла слишком далеко: сегодня это самый популярный язык программирования. По данным GitHub, в 2024 Python впервые стал лидером по количеству активных пользователей, что связано с его широкой применимостью в областях анализа данных, машинного обучения, ИИ и автоматизации. Все основные большие языковые модели используют Python.
- Python – the second best language for everything. И это действительно так, включая новые-модные devops, AI, BigData, autotests. При этом нельзя забывать, что 1) любой язык в конечном счете является лишь инструментом для решения задачи и какой-то инструмент может быть лучше, чем текущий 2) зная один язык, проще изучить новый. Подробнее в статье про программирование.
- В статье про алгоритмы и структуры данных решено много python-задач Алгориртмы и структуры данных, оценка сложности алгоритмов (асимптотическая оценка, оценка Big O)
- онлайн интерпретаторы
- repl.it
- https://pythonide.online/
- Web сравнение кода/текста между собой https://text-compare.com
- Культовая книга: Изучаем Python.| Лутц Марк
- PEP8 – правила по написанию кода, важно соблюдать. Подробнее в Coding: архитектура, программирование и разработка, подходы, best practices, devops, containers (k8s, docker, nomad, mesos), releases, waterfall/agile, scrum, sprints, CI/CD, Serverless computing, Microservice Architecture Помогут:
- (python, coding best practices) formatter’ы типо black и autopep8, автоматически форматирующие код в соответствие PEP8 при сохранении/изменении (Visual Studio Code -> Format on save)
- (python, coding best practices) рекомендуется использовать линтеры/linters, которые проверят ваш код напр. pylance, pylint, flake8 (особенно хорош) для Python – все вместе (и не только они) легко включаются в VisualStudio Code. Из спорного однозначно
- размер строки менее 80 символов – это для экранов в прошлом, на мой экран помещается в три раза больше. Поэтому 120 от PyCharm более логичны.
- flake8 – command palette -> open user settings (JSON
“python.linting.flake8Args”: [
“–max-line-length=120”
],
- flake8 – command palette -> open user settings (JSON
- выдавать warning о том, что import не наверху файла, если все что перед ним это append/insert специфичного пути
- если линтеры не работают – проверь что для файла выставлено trust (внизу в индикаторах ошибок надпись Restricted Mode).
- размер строки менее 80 символов – это для экранов в прошлом, на мой экран помещается в три раза больше. Поэтому 120 от PyCharm более логичны.
- одноименный чекер. Пример стилистики описан в статье про лучшие практики программирования.
- У Python одна из лучших документаций в мире.
- Название Python не от змеи, а от комедийного шоу.
- Python2 оффициально deprecated
/home/user/.local/lib/python2.7/site-packages/paramiko/transport.py:33: CryptographyDeprecationWarning: Python 2 is no longer supported by the Python core team. Support for it is now deprecated in cryptography, and will be removed in the next release.
- Python3 по факту python 3000. В этой версии значительно улучшена архитектура. На сегодняшний день все основные библиотеки поддерживают 3’ю версию.
- (Python, best practices) Zen of python (рекомендуемые best practice) можно прочитать по import this
- The core principle in Python is DRY (Don’t Repeat Yourself)
Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!

- Python GUI automation – pywinauto/pyautogui – автоматизация GUI.
pywinauto is a set of python modules to automate the Microsoft Windows GUI. At its simplest it allows you to send mouse and keyboard actions to windows dialogs and controls. PyAutoGUI works on Windows, macOS, and Linux, and runs on Python 2 and 3.
- Python wx – графика, вполне себе работает в связке с X Windows System, работал с инструментом на базе wx написанном поверх Python2
- Python 3.8-3.9 требуют установленного Service Pack 1 на Windows 7
- В отличии от многих других языков отступ (indentation) в python очень важен (обозначает блок кода, как скобки в php/c) и неправильный отступ может приводить к ошибкам. В этом есть большой плюс – код по умолчанию должен быть «красивым».
- Python – язык с динамической типизацией – переменным не обязательно задавать тип. При этом это возможно и даже нужно – см. ниже поиском по типизации.
- Переменные в python являются ссылками на область памяти (подробнее в описании функции id)
- Интерпретатор Python делает поиск значения переменной в последовательности областей видимостей (scope, namespace) по приоритету до первого совпадения, это называется правило LEGB. Из-за такой приоритезации можно переназначить переменные, уже определенные во встроенных/внешних функциях.
- L (local) – в локальной функции – locals()
- E (enclosing) – в функции, включающей нашу локальную функцию
- G (global) – в общем пространстве скрипта – globals()
- B (built-in) – во встроенных функциях
>>> str <class 'str'> >>> str=[] >>> str [] >>> del str # удаляем переменную str >>> str <class 'str'>
Поэтому проверка объявления переменной (иногда нужно в коде) осуществляется поиском строки с названием переменной в необходимом scope. Если строка s1 содержится в строке s2, то говорят, что строка s1 является подстрокой для строки s2. Другими словами, оператор in определяет является ли одна строка подстрокой другой.
var1_global = "exist"
if 'var1_global' in globals():
print("yes")
- В python работает механизм garbage collection. Garbage collection – процесс, который удаляет ненужные элементы. К примеру, чистит память (старые участки) при переназначении переменных – на участки памяти не ссылаются переменные, их можно высвобождать.
- None – это нулевой/Null элемент.
Noneв Python позволяет представитьnullпеременную, то есть переменную, которая не содержит какого-либо значения. Другими словами,None– это специальная константа, означающая пустоту.- Обратите внимание, что функции, не возвращающие значений, на самом деле, в Python возвращают значение None.
- Все переменные, которым присвоено значение
None, ссылаются на один и тот же объект типаNoneType. - Объекты, существующие в единственном экземпляре ((такие, как None)), называются синглтонами.
- Создание собственных экземпляров типа
NoneTypeнедопустимо. - Для того, чтобы проверить значение переменной на None, мы используем либо оператор is, либо оператор проверки на равенство ==. Предпочтительным является is. Сравнение
Noneс любым объектом, отличным отNone, дает значениеFalse. В том числе ЗначениеNoneне отождествляется с значениями0,False,''. None– это объект специального типа данныхNoneType.>>> a = None >>> type(a) <class 'NoneType'>
- Чаще всего результат сравнений
isи==одинаков, но есть исключения
list1 = [1, 2, 3] list2 = list1.copy() print(list2 is list1) print(list2 == list1) False True
- Заполненный чем то элемент при этом является True и этим можно пользоваться (главное не думать, что если массив заполнен False, то он будет считаться False):
sm_str = "haha"
if sm_str:
print("{}".format(sm_str))
# вместо
if sm_str != "":
print("{}".format(sm_str))
- Проверить что в массиве нет False элементов можно через стандартную функцию in.
if False not in l: res = True else: res = False
Обучение
- Базовое обучение на py4e.com от Dr. Charles Russell Severance – создателя популярной книги python for everybody и одноименного курса на своем сайте и coursera
- python for network engineers
Версии
- Cython – компилятор python кода like python, но с трансляцией в производительный C/C++ код. Используется для написания C расширений для Python. “Использование Cython — один из самых мощных способов оптимизации”
- Код Cython преобразуется в C/C++ код для последующей компиляции и впоследствии может использоваться как расширение стандартного Python или как независимое приложение со встроенной библиотекой выполнения Cython.
- Cython is a Python compiler that makes writing C extensions for Python as easy as Python itself. Cython is based on Pyrex, but supports more cutting edge functionality and optimizations. Cython translates Python code to C/C++ code, but additionally supports calling C functions and declaring C types on variables and class attributes. This allows the compiler to generate very efficient C code from Cython code.
- CPython – эталонная (классическая) реализация языка. Интерпретатор написан на C.
- Jython – специальная версия Python (значительно менее популярная канонической) для виртуальной машины Java позволяет интерпретатору выполняться на любой системе, поддерживающей Java, при этом классы Java могут непосредственно использоваться из Python и даже быть написанными на Python.
- IronPython – специальная версия Python (значительно менее популярная канонической) на основе C#
- MicroPython – lightweight реализация для микроконтроллеров с малым потреблением памяти, процессора и питания. Пример девайса есть на канале Dan Bader (известный популяризатор Python).
it is compact enough to fit and run within just 256k of code space and 16k of RAM
aritigicial intelligence AI
-
- (AI, python) самые популярные ML-библиотек для искуственного интелллекта/aritigicial intelligence AI: PyTorch, TensorFlow, Scikit-learn
-
- (AI, python) Пример базовой работы с openai (chatgpt) через python:
- устанавливаем библиотеку,
- в переменные среды добавляем api ключ – пример для linux, но можно и в windows; в целом можно указать и в скрипте при инициализации клиента
- скриптом делаем запрос и получаем ответ
pip install openai
export OPENAI_API_KEY="your_api_key_here"
from openai import OpenAI #(with key) client = OpenAI(api_key="ТВОЙ_КЛЮЧ_ЗДЕСЬ") client = OpenAI() response = client.chat.completions.create( model="gpt-4o-mini", # или "gpt-3.5-turbo" messages=[{"role": "user", "content": "1+1= ?"}] ) print(response.choices[0].message.content) - (AI, python) Пример базовой работы с openai (chatgpt) через python:
Frameworks
Web фреймворки:
- Flask для простых проектов
- Django для всего остального
- FastAPI
пример работы фреймворка на примере fastAPI: ты создаешь экземпляр класса fastAPI, создаешь асинхронную функцию, делаешь роут/вызываешь application логику, отдаешь response пользователю от application.
- При этом ты не запускаешь никак созданный код – их запускает фрейморк/получает результат/отдает клиенту, от нас это скрыто. Поэтому чтобы все это заработало на созданную асинхронную функцию надо навесить декоратор фреймворка типа app-get – называется это паттерн registry – твои функции не будут вызваны фреймворком/он о них не узнает, пока ты не добавишь нужный декоратор перед ними тем самым добавив свой код в реестр/registry фреймворка.
- Из этого же вывод что фреймворк реализует принцип инверсии управления – в отличии от библиотеки при работе с фреймворком твой код запускает фреймворк/обрабатывает его результат и возвращает клиенту, а не наоборот – ты вызываешь код библиотеки, ты обрабатываешь результат и возвращаешь клиенту, но в случае с библиотеками и в случае с фреймворками ты должен следовать каким то правилам при работе с ними (от банального что передавать на вход). В том числе это упрощает обработку – ты пишешь асинхронную функцию, но вызывает ее фреймворк и фреймворк уже под компотом реализует асинхронность (подробнее о асинхронности в целом отдельно) без твоего непосредственного участия.
Install
CentOS 7
Установка python3.6 (поддерживает String Interpolation в виде format и f-strings) на Ubuntu 14.04.
sudo yum install https://centos7.iuscommunity.org/ius-release.rpm sudo yum install python36 python3.6 -V sudo apt install python3-pip sudo yum install python36u-pip # ставим pip и setuptools sudo pip3.6 install --upgrade pip # обновляем его sudo pip3.6 install virtualenv sudo pip3.6 install requests # ставим пакет requests sudo pip3.6 install beautifulsoup4 sudo python3 -m pip install virtualenv # альтернатива # PIP2 sudo apt install python-pip sudo pip2 install PyYAML
CentOS 6
Установка python3.6 на CentOS 6.
sudo yum install https://centos6.iuscommunity.org/ius-release.rpm sudo yum install python36u python3.6 -V == other same as CentOS 7 ==
Ubuntu 14.04
Установка python3.6 на Ubuntu 14.04.
sudo add-apt-repository ppa:deadsnakes/ppa sudo apt-get update sudo apt-get install python3.6 sudo apt-get install python3-pip # ставим pip и setuptools == other same as CentOS 7 ==
После установки в коде (#!/usr/bin/env python3.6) или при запуске (python3.6 <script>) указываем конкретную версию. Так же можно сделать эту версию версией по умолчанию для python3 (не рекомендую т.к. на него полагается shell – стоит ввести фигню в консоли чтобы это увидеть) или даже для “просто” python (еще меньше рекомендую) используя утилиту update-alternatives.
~$ python3 -V Python 3.4.3 ~$ sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.6 1 update-alternatives: using /usr/bin/python3.6 to provide /usr/bin/python3 (python3) in auto mode ~$ sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.4 2 update-alternatives: using /usr/bin/python3.4 to provide /usr/bin/python3 (python3) in auto mode ~$ sudo update-alternatives --config python3 There are 2 choices for the alternative python3 (providing /usr/bin/python3). Selection Path Priority Status ------------------------------------------------------------ * 0 /usr/bin/python3.4 2 auto mode 1 /usr/bin/python3.4 2 manual mode 2 /usr/bin/python3.6 1 manual mode Press enter to keep the current choice[*], or type selection number: 2 update-alternatives: using /usr/bin/python3.6 to provide /usr/bin/python3 (python3) in manual mode ~$ python3 -V Python 3.6.8
Shebang возможен с конкретной версией python. Важно использовать env – такая запись универсальнее статического задания интерпретатора т.к. env будет находить python автоматически.
#!/usr/bin/env python3.7
Если при установке shebang выдает ошибку, то нужно очистить скрипт от служебного символа \r или ^M. Причем не обязательно он в конце строки на которую ругается. Оболочка интерпретирует эти символы CR как аргументы.
/usr/bin/env: «python3.7\r»: Нет такого файла или каталога
No such file or directory
# cat -v test.py | head -n 2
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# cat -v test_old.py | head -n 2
#!/usr/bin/env python3^M
# -*- coding: utf-8 -*-^M
Чаще всего помогает запуск не через shebang, а напрямую указав интерпретатор (он эти символы игнорирует). Но правильнее удалить их.
Пример скрипта для очистки.
with open('test.py', 'rb+') as f:
content = f.read()
f.seek(0) # переход в самое начало файла
f.write(content.replace(b'\r', b''))
f.truncate()
PIP (установка и использование)
Огромное количество модулей входит в стандартную библиотеку python. Те, которые не входят, обычно можно найти в pip, за редким исключением.
Просмотр установленных библиотек.
pip3 list Package Version ---------- ---------- certifi 2018.11.29 chardet 3.0.4 idna 2.8 pip 18.1 requests 2.21.0 setuptools 39.0.1 urllib3 1.24.1
Просмотр установленных библиотек/модулей и сохранение их в файл с возможностью последующего использования как конфигурации/snapshot.
pip3 freeze # save to file pip3 freeze > requirements.txt
Установка модулей делается через установку из источника, easy_install или pip. Лучшим вариантом насколько понимаю является pip – это аналог gem в Ruby. Он требует отдельную установку себя like “sudo pip3.6 install requests”.
Установка библиотеки.
sudo pip3 install requests # ставим пакет requests sudo pip3 install beautifulsoup4
Установка библиотеки из файла whl (требует разрешение конфликтов).
pip3 install pywin32-228-cp37-cp37m-win_amd64.whl
pip3 install cffi-1.14.3-cp37-cp37m-win_amd64.whl
pip3 install pycparser-2.20-py2.py3-none-any.whl
Установка нескольких библиотек на основе списка в файле (напр. из вывода pip3 freeze).
#pip3 install -r requirements.txt #cat requirements.txt Pillow
Обновление библиотеки.
sudo pip3 install -U requests
Удаление библиотеки.
sudo pip3 uninstall requests
Ошибки
Если не получается поставить pip с ошибкой “No package python-pip available. Error: Nothing to do”, то нужно поставить репу ius.
sudo yum install https://centos7.iuscommunity.org/ius-release.rpm
Если в качестве результата при установке пакета выдает “Consider using the `–user` option or check the permissions.”, значит нужно запускать из под sudo.
sudo pip3.6 install requests
Если выдает “sudo: pip3.6: command not found”, то надо каждый раз при использовании pip указывать полный путь или сделать symbolic link.
sudo /usr/local/bin/pip3.6 install requests
Если выдает timeout, то нужно проверить сеть (iptables, proxy, etc).
Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.VerifiedHTTPSConnection object at 0x7f443823edd8>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/pytest/
Если не удается установить библиотеку т.к. она не собрана под нашу систему – можно собрать эту библиотеку. При сборке могут поднадобиться системные библиотеки (напр. MS Visual C++).
pip3 install bcrypt-3.2.0-cp36-abi3-win_amd64.whl bcrypt-3.2.0-cp36-abi3-win_amd64.whl is not a supported wheel on this platform.
python setup.py build
python setup.py install
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": https://visualstudio.microsoft.com/downloads/
http://go.microsoft.com/fwlink/?LinkId=691126&fixForIE=.exe.
Интерпретатор
Просмотр версии, запуск в интерактивном режиме. Другие опции можно посмотреть в man python.
$ python -V # версия второго Python 2.7.10 $ python3 -V # версия третьего Python 3.7.2 $ python3 # запуск в интерактивном режиме Python 3.7.2 (v3.7.2:9a3ffc0492, Dec 24 2018, 02:44:43) [Clang 6.0 (clang-600.0.57)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> #Простейшая математика в интерактивном режиме >>> x=6 >>> print(x) 6 >>> x=x*6 >>> print(x) 36 quit() # выход
-u – важная опция, которая может пригодиться, особенно для длительно работающих скриптов, вывод которых нужно сохранять. При ее использовании вывод в файл при редиректе в файл (в том числе при использовании tee) будет происходить без буфферизации, как при выводе в shell. В итоге можно применять tail -f на файл и следить за процессом исполнения. В противном случае вывод будет записан в файл только после завершения скрипта. Тут подробнее и альтернативы.
-u Force stdin, stdout and stderr to be totally unbuffered. python -u
Reserved words
33 штуки
and del from None True
as elif global nonlocal try
assert else if not while
break except import or with
class False in pass yield
continue finally is raise
def for lambda return
Виртуальная среда
Позволяет изолировать разные проекты между собой как в рамках версий python, так и в рамках версий библиотек. Аналог vrf в сетях.
Существует несколько способов создания виртуальной среды python, не говоря даже про docker или виртуализацию уровня VM.
virtualenv
sudo pip3.7 install virtualenv
Прямое управление virtualenv возможно через команды утилиты virtualenv, но возможно и с использованием отдельных библиотек, например virtualenvwrapper.
virtualenv <PROJECT> # CREATE source <PROJECT>/bin/activate # ACTIVATE deactivate # DEACTIVATE
virtualenvwrapper – упрощает взаимодействие с виртуальными окружениями.
sudo pip3.7 install virtualenvwrapper
После установки добавляем в .bashrc и перезапускаем bash
export VIRTUALENVWRAPPER_PYTHON=/usr/local/bin/python3.7 export WORKON_HOME=~/venv . /usr/local/bin/virtualenvwrapper.sh
exec bash
Создание виртуального окружения с python3.7 по умолчанию.
mkvirtualenv --python=/usr/local/bin/python3.7 test_env
Удаление виртуального окружения
rmvirtualenv Test
Переход в виртуальное окружение
workon test_env
Выход из виртуального окружения
deactivate
Просмотр пакетов в виртуальном окружении
lssitepackages
Подключение/импорт библиотек/модулей/классов/функций
- Нежелательно использование import + * (лучше импортировать только то, что нужно).
- С помощью import подключаем всю системную библиотеку json
- С помощью import подключаем системные библиотеки json, sys, requests
- С помощью from + import из файла net_query.py (в директории исполнения текущего скрипта) подключаем только функцию model из пользовательской библиотеки net_query.
- С помощью from + import из файла LoadManager.py импортируем класс LoadManager.
import json import json, sys, requets from net_query import model from LoadManager import LoadManager
При этом мы так же могли бы импортировать весь модуль net_query и наоборот – часть (одну) функций модуля json. В любом случае импорта исполняется весь код модуля, просто:
- в случае from + import в пространство имен кода импортируется только объекты (переменные) кода конкретной импортируемой функции, а не весь модуль
- при import всего модуля обращение к объектам идет через модуль (import читает файл с модулем и создает объект этого модуля), а при from + import напрямую к объекту. По этой причине нельзя использовать from + import + * т.к. не будет понятно, откуда появился тот или иной объект в коде.
import statement - A statement that reads a module file and creates a module object. module object - A value created by an import statement that provides access to the data and code defined in a module.
import sys sys.argv sys.version from sys import argv, version argv version #DO NOT USE from sys import *
В случае длинного названия модуля можно использовать import совместно с as.
import concurrent.futures as cf
Например, код ниже импортирует функцию getcwd из модуля os под псевдонимом work_folder.
from os import getcwd as work_folder
При необходимости импорта из несистемной и нелокальной папки можно расширить пространство поиска библиотек используя sys.path.append:
sys.path.append('/home/user/new/some_dri')
from external_lib import external_lib_function
ЛИНТЕРы/linters/SAST
Теория о SAST описана тут.
Пример alert’ов linter pylance/pylint в VS Code. Включается простой установкой модуля (Extension -> pylint -> Install). Была только проблема с “The PyLint server crashed 5 times in the last 3 minutes. The server will not be restarted. See the output for more information.”, решилось установкой альтернативной версии модуля (pre-release вместо release).
Пример на простой код:
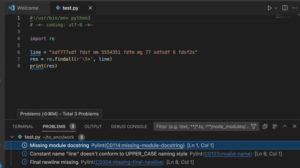
Исправленная версия:
Methods
Best practices
Отдельная статья про лучшие практики. В контексте python:
- Использовать Logging вместо print
- Использовать Debuggers (напр. встроенный в VS Code extension ms-python) для отладки
- Использовать Linters (напр. встроенный в VS Code extension ms-python pylance/pylint VS) Code) для написания industry standard кода (при возможности)
- Использовать f-string и Str.format вместо конкатенации (лучше f-string, подробнее ниже)
ConfigParser
Конфиг:
[settings] mode = default direction = server check_success = on check_directions = on
Парсинг конфига:
config = configparser.ConfigParser()
config.read('config.conf')
mode = config.get('settings', 'mode', fallback='default')
direction = config.get('settings', 'direction', fallback='client')
check_success = config.get('settings', 'check_success', fallback='on')
check_directions = config.get('settings', 'check_directions', fallback='on')
Logging
import logging
debug = True
if debug:
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
log.debug("Doing something!")
Пример 2: вывод одного и того же лога с severity INFO (setlevel) в консоль (STDOUT) и файл.
import logging
logger = logging.getLogger()
formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(filename)s:%(message)s')
fh = logging.FileHandler("log_fname.log")
fh.setFormatter(formatter)
logger.addHandler(fh)
lh = logging.StreamHandler(sys.stdout)
lh.setFormatter(formatter)
logger.addHandler(lh)
logger.setLevel( logging.INFO )
logger.debug('Debug message.')
logger.info('Info message.')
logger.warning('Warning message.')
logger.error('Error message.')
Пример 3: вывод DEBUG лога в файл, вывод INFO лога упрощенного формата в консоль. Причем глобальная команда setLevel на logger обязательна – это первичная глобальная выборка, без нее сообщения не попадут в handler. В глобальной выборке нужно указывать максимальный уровень, который будет применятся на уровне handlers – в данном случае DEBUG.
import logging
logger = logging.getLogger()
logger.setLevel( logging.DEBUG )
# add file handler
fh_formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(filename)s:%(message)s')
fh = logging.FileHandler(log_fname_appmix)
fh.setLevel( logging.DEBUG )
fh.setFormatter(fh_formatter)
logger.addHandler(fh)
# add stdout handler
lh_formatter = logging.Formatter('%(asctime)s\t%(message)s', "%Y-%m-%d %H:%M:%S")
lh = logging.StreamHandler(sys.stdout)
lh.setLevel( logging.INFO )
lh.setFormatter(lh_formatter)
logger.addHandler(lh)
Этим способом логгирования пользуются библиотеки (напр. urllib3, paramiko), поэтому самое логичное в создаваемом коде использовать его же.
DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): 192.168.1.1:443 DEBUG:paramiko.transport:=== Key exchange agreements === DEBUG:paramiko.transport:Kex: curve25519-sha256@libssh.org DEBUG:paramiko.transport:HostKey: ssh-ed25519 DEBUG:paramiko.transport:Cipher: aes128-ctr DEBUG:paramiko.transport:MAC: hmac-sha2-256 DEBUG:paramiko.transport:Compression: none
pip install colorlog
Ошибка “TypeError: ‘RootLogger’ object is not callable” может иметь причиной простая ошибка синтаксиса – нужно обращаться к объекту log через метод, соответствующий logging severity (info, debug, etc), а не напрямую.
TypeError: 'RootLogger' object is not callable
log("Hello")
This is wrong. Correct is
log.info("Hello")
Пример настройки уровня логгирования и логгирование в файл (в том числе можно /dev/null).
# 1
import logging
import paramiko
logging.basicConfig()
logging.getLogger("paramiko").setLevel(logging.WARNING) # for example
# 2
paramiko.util.log_to_file("<log_file_path>", level = "WARN")
Logging функция
def log_start() -> logging.RootLogger:
'''Start logging and returning logging object'''
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# add file handler
fh_formatter = logging.Formatter('%(asctime)s:%(levelname)s:%(filename)s:%(message)s')
fh = logging.FileHandler(config["log_fname"])
fh.setLevel(logging.DEBUG)
fh.setFormatter(fh_formatter)
logger.addHandler(fh)
# add stdout handler
lh_formatter = logging.Formatter('%(asctime)s\t%(message)s', "%Y-%m-%d %H:%M:%S")
lh = logging.StreamHandler(sys.stdout)
if config["debug_to_console_output"]:
lh.setLevel(logging.DEBUG)
else:
lh.setLevel(logging.CRITICAL)
lh.setFormatter(lh_formatter)
logger.addHandler(lh)
logger.debug(globals())
return logger
logger = log_start()
if i == 0: logger.critical(f'Script was started, logfile: {log_fname}') # Лучше CRICICAL чем INFO. Иначе by default будут SSH PARAMIKO и прочий мусор: Connected (version 2.0, client OpenSSH_7.4p1)
logger.debug("config_gen was started")
logger.handlers.clear() # для объявления новых файлов
SUPPRESS LOGS
Пример подавления логов на основе отключения warnings сообщений модуля paramiko.
warnings.filterwarnings(action='ignore',module='.*paramiko.*')
Есть так же множество других вариантов подавления логов – напр. всех.
python -W ignore foo.py
paramiko.util.log_to_file("/dev/null", level = "WARN")
Functions
# The first line of the function definition is called the header; the rest is called the body. The header has to end with a colon and the body has to be indented. The body can contain any number of statements. As you might expect, you have to create a function before you can execute it.
def fctn():
print("lol")
def some_funct(a,b): '''some description of function''' return(a+b) print(some_funct.__doc__)
some description of function
Аргументы (переменные) в функцию могут передаваться:
- позиционно – позиция аргумента при вызове функции соответствует описанию функции на входе. Используя * на входе есть возможность приема на входе функции всех переменных или только части и парсинга их уже в функции (по примеру ARGV из системных). Удобство такого подхода – можно написать сразу универсальную функцию, которая работает как с отдельной строкой, так и с массивом данных т.к. строка по умолчанию преобразуется в массив с одним элементом на входе в функцию.
some_funct(a,b)
>> def some_funct(*all_arg): >> print(all_arg) >> a=1 >> b=3 >> c=5 >> some_funct(a,b,c) (1, 3, 5)
>> def some_funct(a,*all_arg): >> print(a, all_arg) >> a=1 >> b=3 >> c=5 >> some_funct(a,b,c) 1 (3, 5)
- по ключу – позиция не важна, важен ключ, можно передавать переменные в произвольном порядке, главное, чтобы на входе функции ключи соответствовали передаваемым. При передаче чисел или значений Boolean крайне удобный функционал. При этом можно только часть переменных передавать по ключу, но обязательно, чтобы та часть, которая передается по ключу, была в конце, а позиционные аргументы в начале. Кроме того есть вариант передачи в функцию словаря вида ключ: значение используя ** при передаче переменных. В таком случае функция сама распарсит значения из ключей, как и при стандартном вызове функции. Используя же ** на входе в функцию можно принимать часть или все переменные в виде словаря.
some_funct(a=a,b=b)
some_funct(a,b=b)
ndr_benchmark_test(server='127.0.0.1', iteration_duration=780.0,
title='ndr-experiments-xf5000', verbose=True, max_iterations=10,
allowed_error=1.0, q_full_resolution=2.0,
latency_pps=0, max_latency=0, lat_tolerance=0,
output=None, yaml_file=None, plugin_file=None,
tunables={}, profile='/opt/trex/v2.82/astf/rus_ent_appmix.py', profile_tunables={},
high_mult=100, low_mult=0,
>> def some_funct(**d):
>>
>> d = {"pos_ip": "1.1.1.1000", "exception_debug": True}
>> some_funct(**d)
>> some_funct(pos_ip = "1.1.1.1000", exception_debug = True)
>> some_funct("1.1.1.1000", True)
'1.1.1.1000' does not appear to be an IPv4 or IPv6 address
False
>> def some_funct(a,**all_arg):
>> print(a, all_arg)
>> a=1
>> b=3
>> c=5
>> some_funct(a,b=5,c=7)
1 {'b': 5, 'c': 7}
Словарь вида ключ-значение (напр. kwargs) легко распарсить в переменная-значение с использованием setattr.
def get_profile(self, tunables, **kwargs):
# Assign kwargs
for key, value in kwargs.items():
setattr(self, key, value)
print(self.var1)
print(self.var2)
При использовании значений по умолчанию для переменных на входе функции, крайне нежелательно использовать массивы и другие изменяемые элементы (если не нужно именно то, что описано ниже в виде инкремента на каждый вызов list). В линтерах эта потенциальная ошибка подсвечивается как dangerous-default-value.
def some_funct(a,b,c=[]): '''some description of function''' c.append(a) c.append(b) return(c) a = 2 b = 3 print(some_funct(a,b)) print(some_funct(a,b)) print(some_funct(a,b))
[2, 3] [2, 3, 2, 3] [2, 3, 2, 3, 2, 3]
VAR basic (type, ID)
- type(var) # узнаем тип переменной
~$ python3
>>> type("Hello weril!")
<class 'str'>
>>> type(666)
<class 'int'>
>>> type(666.6)
<class 'float'>
>>> type("666.6")
<class 'str'>
>>> type(True)
<class 'bool'>
>>> type(Funct)
<class 'function'>
>>> type(None)
<class 'NoneType'>
- isinstance(25,int) # проверяем принадлежность переменной определенному типу, правильно делать именно так, а не через if type(25) == int так как isinstance принимает во внимание иерархию типов (ООП).
if not isinstance(ip, dict):
raise argparse.ArgumentTypeError('Dictionary is expected.')
- метод — функция, применяемая к объекту, напр. объекту класса string. Метод вызывается в виде
имя_объекта.имя_метода(параметры). Например,s.find('e')— это применение к строкеsметодаfindс одним параметром'e'. - str(var) # преобразование в string.
- Про строки – строка является неизменяемым (immutable) типом данных.
- Про изменяемость:
- Неизменяемые типы – str, int, float, nan, bool.
- Изменяемые типы – list, dict, set.
- Под неизменяемостью подразумевается то, что при создании нового объекта из двух строк в любом случае новая переменная будет хранится в новом месте (т.е. поменяв данные ты в любом случае меняешь ссылку на эти данные), а не как в случае изменяемых типов – переменная хранится там же, а данные меняются (т.е. поменяв данные ты сохраняешь старую ссылку на эти данные). При этом старые ячейки памяти, которые не используются, должны будут отчищены garabage collector.
- Метод
isalpha()определяет, состоит ли исходная строка из буквенных символов. Метод возвращает значениеTrueесли исходная строка является непустой и состоит только из буквенных символов иFalseв противном случае. - Метод
islower()определяет, являются ли все буквенные символы исходной строки строчными (имеют нижний регистр). Метод возвращает значениеTrueесли все буквенные символы исходной строки являются строчными иFalseв противном случае. Все неалфавитные символы игнорируются! - Метод
isupper()определяет, являются ли все буквенные символы исходной строки заглавными (имеют верхний регистр). Метод возвращает значениеTrueесли все буквенные символы исходной строки являются заглавными иFalseв противном случае. Все неалфавитные символы игнорируются! - Метод
isspace()определяет, состоит ли исходная строка только из пробельных символов. Метод возвращает значениеTrueесли строка состоит только из пробельных символов иFalseв противном случае.
>>> "sdf".isalpha() True >>> "sdf1".isalpha() False >>> "".isalpha() False >>> "sdf1".islower() True >>> "sdf&".islower() True >>> "sdF".islower() False
- int(var) # преобразование в integer. Немного оффтоп, но про integer:
- В python, в отличии от множества других языков (С*, java) integer не имеет ограничений по памяти/диапазону значений, ограничен только памятью.
- Перед преобразованием с помощью метода isdigit можно проверить, что данные являются числом (не содержат, например, символов). Метод
isdigit()определяет, состоит ли исходная строка только из цифровых символов. Метод возвращает значениеTrueесли исходная строка является непустой и состоит только из цифровых символов иFalseв противном случае. - Явно указанное численное значение в коде программы называется целочисленным литералом. Когда Python встречает целочисленный литерал, он создает объект типа int, хранящий указанное значение. В контексте литерала – строка и boolean тоже летерал (literal), противовесом литерала является контейнерных объект (containers).
- Для удобного чтения чисел можно использовать символ подчеркивания.
>>> var1=10 # целочисленный литерал >>> var1="10" >>> var1.isdigit() True >>> var1="10a" >>> var1.isdigit() False >>> var1=555_555_555 >>> var1 555555555
- float(var) # преобразование в float (число с плавающей ТОЧКОЙ, не запятой) – дробные (вещественные) числа в информатике называют числами с плавающей точкой. В отличие от математики, где разделителем является запятая, в информатике используется точка. С python3 по факту преобразования во float редко требуются т.к. при операциях с float результатом происходит автоматическая трансляция int во float – при делении двух int результатом является float – в Python3 (не Python2!, там он отбрасывает все после точки – сохраняет int тип для результата). Для сохранения остатка в python2 нужно преобразовать цифры во float.
# python3 >>> a=3/2 >>> a 1.5 >>> type(a) <class 'float'> # python2 >>> a=3/2 >>> a 1 >>> type(a) <type 'int'> # python2 >>> a=float(3)/float(2) >>> a 1.5 >>> type(a) <type 'float'>
- Метод
isalnum()определяет, состоит ли исходная строка из буквенно-цифровых символов. Метод возвращает значениеTrueесли исходная строка является непустой и состоит только из буквенно-цифровых символов иFalseв противном случае.
>>> "123abc".isalnum() True >>> "1".isalnum() True >>> "123abc!".isalnum() False >>> "".isalnum() False
- print(globals()) или print(locals()) – вывести все текущие глобальные (определенные в основном коде)/локальные переменные (определенные в функции) и их значения – очень удобно для дебага или сохранения test environment в логах (так и использовал).
- id(var) смотрим адрес переменной в памяти. Чаще всего используется только в учебных целях чтобы показать, что разные переменные ссылаются на одно место памяти при равенстве. Лучше всего демонстрируется на списках т.к. они в python изменяемые, в отличии от, например, чисел. При присвоении другого числа/строки переменной всегда переменная создается заново, ей назначается новый участок памяти, а для списка в памяти по старому адресу меняется значение. Причем какой-то родительской связи между копируемым и скопированным элементом не существует – обе переменных просто ссылаются на один участок памяти, который может изменяться при изменении любой из переменных. По этой причине копирование массивов в общем случае бессмысленно и имеет смысл только при использовании метода copy – при его использовании для новой переменной создается отдельный учаток памяти, но и он имеет подводные камни – не копирует вложенные массивы (оставляет только основной). Для этого обычно используют метод deepcopy. Все способы обхода этой проблемы ниже.
new_list = my_list doesn't actually create a second list. The assignment just copies the reference to the list, not the actual list, so both new_list and my_list refer to the same list after the assignment. # integer/string >>> var1=1000 # нужно использовать числа отличные от -5 до 256 т.к. уже хранятся в памяти (одно число всегда имеет один и тот же адрес в памяти - не создается заново), в отличии от чисел вне диапазона (каждый раз создаются в памяти заново) >>> var2=var1 >>> id(var1) 4359970544 >>> id(var2) 4359970544 >>> var1=1001 >>> id(var1) 4359970480 >>> id(var2) 4359970544 # array >>> var1=[1,2] >>> var2=var1 >>> id(var1) 4360043528 >>> id(var2) 4360043528 >>> var1[0]=3 >>> id(var1) 4360043528 >>> id(var2) 4360043528 >>> var2 [3, 2] >>> var2.append(555) >>> var2 [3, 2, 555] >>> var1 [3, 2, 555] >>> var3=var2.copy() >>> id(var2) 4317072392 >>> id(var3) 4317830152 >>> var2.append(666) >>> var2 [3, 2, 555, 666] >>> var3 [3, 2, 555]
VARIABLE SWAP (Обмен значений переменных)
Оба кода ниже делают одно – в переменной X сохраняют значение Y и наоборот (в Y значение X).
# general way (including python) temp = x x = y y = temp # python way x, y = y, x # Аналогичным образом можно менять местами значения трех и более переменных.
FLAGS (сигнальные метки)
Метка в программе после определенного условия, которая в последующем используется для принятия решения.
bag_potatoes = [2, 2, 2, 1, 2, 1, 2, 2, 2, 2] # это наш мешок, в нем 2 гнилушки
rot_flag = False # это наш флаг на гниль, сейчас у него значение фолз (ложь)
for potato in bag_potatoes: # запустим цикл перебора картошки
if potato == 1:
rot_flag = True # замечена гнилая картошка, флаг мы переводим в Тру (истина)
# ниже мы смотрим на значение флага, т.е. наших наблюдений, и делаем выводы
if rot_flag:
print('есть гнилая картошка')
print('Нужно сходить выкинуть, то что нашли')
else:
print('нет гнилой картошки')
print('Ничего выкидывать не нужно')
User Input
var = input("what are you? ") # raw_input Python2
print ("Welcome", var)
Запрос пароля, прячет символы при вводе:
>>> import getpass >>> getpass.getpass() Password: '32423424'
DIR
dir(var) – с помощью метода dir можем узнать какие методы возможно применить к объекту. Определяется типом объекта
- к строке строковые методы
- к целому числу – целочисленные
var = "test" print(dir(var)) ...['capitalize', 'casefold', 'center', 'count', 'encode']... var = 1 print(dir(var)) ...['from_bytes', 'imag', 'numerator', 'real', 'to_bytes']...
Boolean/булевые переменные (True/False) и логика
- В программировании функция, которая возвращает значение
TrueилиFalse, называется предикатом. - Примеры разных операций
>>> a = True >>> b = False >>> print(a and b) False >>> print(a or b) True >>> print(not a) False >>> print(True == 1) True >>> print(False == 0) True
- В python приоритет оператора
notвыше, чем у оператораand, приоритет которого, в свою очередь, выше, чем у оператораor. Stackoverflow, official doc.
https://stackoverflow.com/questions/16679272/priority-of-the-logical-operators-order-of-operations-for-not-and-or-in-pyth https://docs.python.org/3/reference/expressions.html#operator-precedence
- Правильное сравнение с False считается через If not
comparison to False should be 'if cond is False:' or 'if not cond:'flake8(E712) # Wrong if client_port == False: # Right if not client_port:
File (работа с файлами, Files)
Создаем файл, если он отсутствует.
if not os.path.exists(fl): os.mknod(fl)
Создаем директорию, если она отсутствует.
if not os.path.isdir(fname): Path(fname).mkdir(parents=True, exist_ok=True)
read (open default)
Классический подход чтения через with open и функцию открытия/итерирования по строкам не в одну строку, из минусов – чуть больше строк в сравнение с one-liner’ами, из плюсов – 1) невозможно забыть закрытие файла 2) в случае если объем данных большой, мы еще до добавления строки в массив можем строку отбросить/предобработать и не расходовать оперативную память ((в которую загружаются данные из файла)). one-liner’ы есть (примеры ниже), но нужно понимать, закрывают они файл по окончанию своей работы или нет (аналогичное справедливо не только для файлов – напр. открытых socket/ssh) – если нет (примеры ниже), то это в целом неправильно, хоть и будет чаще всего работать без каких либо проблем (файл закроется по завершению execution программы или после работы garbage collection).
# good classic read to array/list
l = []
with open("test.txt") as f:
for line in f:
l.append(line.rstrip())
# bad one-liner (closing issue)
def parse_file_to_list(fname):
l = open(fname).read().split("\n")
return(l)
# bad one-liner2 (closing issue) - берем login из файла, удаляем из него мусор (\n), кодируем в байт-строку
lgn = open('/home/redkin_p/.duser').read().encode('utf-8')
# bad one-liner3 (closing issue) - берем большой файл, кладем его в массив (каждая строка как элемент]), ищем в каждом элементе определенный паттерн (аналог ruby .select), выдергиваем из подпавших строк последний столбец (последний элемент каждого массива) и помещаем его в новый массив
data_list = open('/home/redkin_p/ORANGE').read().split("\n")
data_list = list(x for x in data_list if "DGS-3620" in x)
ip_list = []
for s in data_list:
ip_list.append(s.split("\t")[-1].replace(" ", ""))
print(ip_list)
write (open with w – write, a – append)
w – перезатирает файл и пишет контент в него
a – добавляет содержимое в существующий файл
# string
def write_to_file(text, fname):
with open(fname, 'a') as the_file:
the_file.write(text + "\n")
write_to_file(text, fname)
# array
with open('/home/redkin_p/result.csv', 'a') as the_file:
for n,e in enumerate(interfaces):
res = '{};{};{};{}\n'.format(e, broadcast[n], multicast[n], unknowncast[n])
the_file.write(res)
# bytes
def write_bytes_to_new_file(bytes, fname):
with open(fname, 'wb') as the_file:
the_file.write(bytes)
# string with new line and datetime (for basic logs, best logs with logging)
def write_to_file_with_new_line_and_dt(text, fname):
dt = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") # for log
with open(fname, 'a') as the_file:
the_file.write(str(dt) + " " + text + "\n")
write + print
Полезная функция, когда нужно вывод из print добавить формированием файла с этим print – просто подменяем print на print_write. Имя файла должно быть в GLOBALS или определенно в классе при ООП (self).
def print_write(line): print(line) write_to_file(line, global_file)
delete (удаление)
import os
os.remove("/home/redkin_p/result.csv")
copy (копирование)
from shutil import copyfile copyfile(src, dst)
seek
Перемещает позицию в файле (при итерации по файлу) в самое начало. Нужно редко, но может пригодится (напр. двойное чтение одного файла).
f.seek(0)
change/edit (изменение)
Изменение содержимого файла, как ни странно, не решаемая несколькими простыми строками кода python задача и самый “простой и надежный” способ по факту самый “тупой и прямолинейный”.
# Read in the file
with open('file.txt', 'r') as file :
filedata = file.read()
# Replace the target string
filedata = filedata.replace('ram', 'abcd')
# Write the file out again
with open('file.txt', 'w') as file:
file.write(filedata)
import os
from pathlib import Path
dirpath = "/root/"
paths = sorted(Path(dirpath).iterdir(), key=os.path.getmtime)
for fname in paths:
fname = f"{fname}" # protection from TypeError: argument of type 'PosixPath' is not iterable
Полезные методы/функции
Методы по удалению:
import os
def delete_file(fname):
try:
os.remove("{}".format(fname))
except FileNotFoundError:
pass
def delete_files_in_dir(somedir):
res = os.listdir("{}".format(somedir))
for fname in res:
fname_full_path = "{}/{}".format(somedir,fname)
delete_file(fname_full_path)
Можно использовать усовершенствованную версию – опциональный exception при ошибке удаления, удаление по маске.
def delete_file(fname, except_if_fail=False):
if except_if_fail:
os.remove("{}".format(fname))
else:
try:
os.remove("{}".format(fname))
except FileNotFoundError:
pass
def delete_files_in_dir(somedir, pattern=""):
res = os.listdir("{}".format(somedir))
for fname in res:
fname_full_path = "{}/{}".format(somedir,fname)
if pattern in fname:
delete_file(fname_full_path)
Методы по проверке наличия (isfile или exists)/ненулевому размеру (st_size != 0):
import os
def check_file_existance_boolean(file):
if os.path.isfile(file) and os.stat(file).st_size != 0:
return True
else:
return False
def check_file_existance(file):
if os.path.isfile(file) and os.stat(file).st_size != 0:
pass
else:
print("Error: нет файла {} или он имеет нулевой размер".format(file))
quit()
Расчет MD5 файла
import hashlib
def md5(fname):
hash_md5 = hashlib.md5()
with open(fname, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
Управление сервисами. Запуск функции.
check_and_change_service_status("inactive", "trex_server")
Управление сервисами. Получение статуса.
def get_service_status(service_name):
serv1_status_raw = subprocess.run("systemctl status {}".format(service_name).split(" "), stdout=subprocess.PIPE, stderr=null)
serv1_status = serv1_status_raw.stdout.decode().split("\n")[2].split()[1].replace("failed", "inactive")
return serv1_status
Управление сервисами. Установка статуса.
def set_service_status(expected_service_status, service_name):
if expected_service_status == "inactive":
expected_service_status = "stop"
elif expected_service_status == "active":
expected_service_status = "start"
else:
write_to_file_with_new_line_and_dt("real service_name {} status is {} expected is {}".format(service_name, real_status, expected_service_status), log_fname)
subprocess.run("systemctl {} {}".format(expected_service_status, service_name).split(" "), stderr=null)
Управление сервисами. Управляющая функция.
def check_and_change_service_status(expected_service_status, service_name):
real_status = get_service_status(service_name)
write_to_file_with_new_line_and_dt("real service_name {} is {} expected is {}".format(service_name, real_status, expected_service_status), log_fname)
if real_status != expected_service_status:
set_service_status(expected_service_status, service_name)
real_status = get_service_status(service_name)
if real_status != expected_service_status:
raise Exception("Can't change {} to expected value {}".format(service_name, expected_service_status), log_fname, global_log_fname)
write_to_file_with_new_line_and_dt("successfully changed {} to expected value {}".format(service_name, expected_service_status), log_fname)
CSV
Парсинг csv (отброс header, delimiter) с функцией reader.
import csv
with open('file.csv') as f:
reader = csv.reader(f, delimiter=';')
headers = next(reader)
for row in reader:
print(row)
Можно так же перевернуть массив (чтение с конца).
l = reversed(list(csv.reader(f, delimiter=';'))) for row in l:
Использование библиотеки для некоторых кейсов лучше простого split.
- можно использовать csv.DictReader вместо обычного reader для сопоставления значений в header (главное чтобы он был или в файле или заданным опцией fieldnames=[]) конкретным элементам без своего кода.
- данные ниже будут корректно разбиты по элементам при использовании библиотеки т.к. используемый разделитель “;” находится внутри кавычек.
ip;10.10.10.10;"Узловая 1-ая д.1; чердак"
Запись без библиотеки (line = строка)
write_to_file(f"{';'.join(line)}", file_with_res)
Запись через библиотеку csv
Записываем в файл список в виде строки с разделителями с функцией writerow для объекта writer. Можно использовать опцию quoting (QUOTE_NONNUMERIC, ALL) для обозначения тех данных, которые должны быть в скобках.
writer = csv.writer(f, delimiter=';', quoting=csv.QUOTE_NONNUMERIC) for line in data: writer.writerow(line)
Так же можно записать большое количество данных скопом, используя функцию writerows. В виде данных должен быть список списков (каждая строка = отдельный список).
writer = csv.writer(f, delimiter=';', quoting=csv.QUOTE_NONNUMERIC) writer.writerows(data)
Есть и аналогичная reader функция DictWriter, которая позволяет записать словарь (формат аналогичный получаемому из DictReader) с использованием writerow/writerows. При использовании есть особенность – header нужно записывать отдельно (writeheader()), даже если он задан в fieldnames к объекту.
pandas
При чтении файла в csv желательно загружать в память только нужные столбцы (usecols) этого csv. Для float, которые разделены через “,” можно так же указать опцию decimal в read.
df = pd.read_csv("/tmp/test.csv", usecols=[ "DateTime", "Packet Loss (%)" ], delimiter=";", header=24, decimal=",")
Сохранение только одного столбца по его имени в header.
Pandas is spectacular for dealing with csv files, and the following code would be all you need to read a csv and save an entire column into a variable: import pandas as pd df = pd.read_csv(csv_file) saved_column = df.column_name saved_column = saved_column.values.tolist() # transform to list # example print(df["Packet Loss (%)"])
Фильтрация – значения в столбце Stream ID должны быть равны total.
df_only_total = df[df["Stream ID"] == "total"]
Можно применять функции mean или даже quantile/расширенного describe к столбцу – очень удобно.
print(df["Packet Loss (%)"].mean()) print(df["Packet Loss (%)"].quantile(0.75)
(статистика, python, сетевое тестирование)
В целом всегда порекомендовать делать pandas describe на выборку для получения разнообразной статистики:
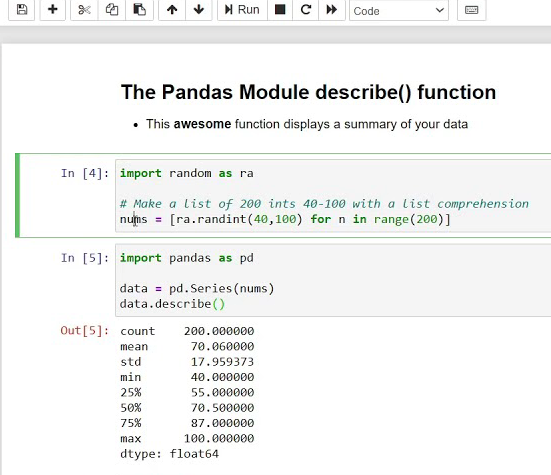
-
-
-
- count 94248.000000 – количество элементов (размер выборки)
- mean 1.691554 – среднее
- std 0.979690 – стандартное отклонение (величина высокая)
- min -0.108278 – меньше этого гарантировано (на основе выборки) не будет
- 25% 0.396944 – 25% выборки выше этого значения
- 50% 2.301407 – медиана (median)
- 75% 2.348383 – 75% выборки ниже этого значения
- max 6.486859 – больше этого гарантировано (на основе выборки) не будет
-
-
Так же может дополнительно быть необходимо:
-
-
-
- 1%
- https://www.rfc-editor.org/rfc/rfc9693.html
- 80% использовал для индикации высокого результата без spike/ramp up вверх и вниз. 80ый перцентиль пример для понимания:
- 20% выборки имею результат выше
- 80% имеют результат ниже
- 95% load testing app best practice
- 99% 99th percentile, for robustness against outliers
- https://www.rfc-editor.org/rfc/rfc9693.html
- https://datatracker.ietf.org/doc/html/rfc8238
- range статистический размах
- 1%
-
-
Directory (директории, папки)
Смотрим файлы в директории
import os
for fname in os.listdir( sys.argv[1] ):
print("{}".format(fname))
Копирование директории.
from distutils.dir_util import copy_tree copy_tree(from_dir, to_dir)
Удаление директории.
import shutil
shutil.rmtree('/folder_name')
Определение текущей директории. Очень полезно для скриптов, которые оперируют относительными путями.
# current directory import os os.path.dirname(os.path.realpath(__file__))
Time: date, month, hours, seconds
Datetime
import datetime print(datetime.datetime.now())
Date-time to string
import datetime
datetime.datetime.now().strftime("%Y-%m-%d_%H%M%S") # for file_names
dt = datetime.datetime.now().strftime("%M%S.%f")[:-3] # for file_names with milkiseconds
datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") # for general usage
# function
def get_dt() -> datetime.datetime:
dt = datetime.datetime.now()
dt_files = dt.strftime("%Y-%m-%d_%H%M%S") # для файлов
dt_logs = dt.strftime("%Y-%m-%d %H:%M:%S") # для логов
return dt_files, dt_logs
String date to date object
dt = datetime.datetime.strptime('2020-11-04', "%Y-%m-%d").date()
dt = datetime.datetime.strptime('2022-04-28 15:09:04', "%Y-%m-%d %H:%M:%S")
dt_seconds_before = (datetime.datetime.now() - dt).total_seconds()
Today
print(datetime.date.today())
Day of week (день недели), можно и на русском (см. пример в locale)
>>> from datetime import datetime as date
>>> date.today().weekday()
6
>>> date.today().strftime("%A")
'Sunday'
Datetime + seconds.
scheduled_time = datetime.datetime.now() + datetime.timedelta(seconds=5) print(datetime.datetime.now()) print(scheduled_time)
Month, можно и на русском (см. пример в locale).
>>> date.today().strftime("%B")
'August'
Определение по году (высокосный/не высокосный) и номеру месяца количества дней.
>>> from calendar import monthrange >>> monthrange(2011, 2) (1, 28) >>> monthrange(2012, 2) (2, 29)
Разность времени в секундах. Может быть полезно для расчета сколько времени прошло с запуска программы/участка кода. Напр.
- исполняем/спим до тех пор, пока время со старта не приросло на N секунд. Как только время превышено – делаем что-то другое (напр. прекращаем работу).
- спим вариативное время, т.к. execution в рамках итерации может происходить за разное время, а наша цель, чтобы каждая итерация занимала примерно одинаковое время
# BASIC EXMPL
>>> import time
>>> start_time=time.time()
>>> end_time=time.time() - start_time
>>> end_time
15.806370258331299
>>> end_time=time.time() - start_time
>>> end_time
24.918872117996216
# USAGE 1 тестируем пока не закончилось время
while (time.time() - test_start_time < test_time):
print("test code")
# USAGE 2 замедляем итерирование в скрипте на основе времени для каждой итерации.
elapsed_time = time.time() - start_time
need_to_sleep = speed - elapsed_time
time.sleep(need_to_sleep)
В коде выше используется time.time конструкция, которая может быть замененаа time.perfcounter. time.perfcounter стоит использовать при наличии требований по высокой точности (микросекунды), например, задач измерения производительности кода/максимально точных интервалов между запусками и с учетом, что:
1) выдаваемое время не привязано к “человеческому”
2) валидно сравнивать только time.perfcounter с time.perfcounter
https://stackoverflow.com/questions/66036844/time-time-or-time-perf-counter-which-is-faster time.time() - deals with absolute time, i.e., "real-world time" (the type of time we're used to). It's measured from a fixed point in the past. According to the docs, time.time() returns time. perf_counter() - on the other hand, deals with relative time, which has no defined relationship to real-world time (i.e., the relationship is unknown to us and depends on several factors). It's measured using a CPU counter and, as specified in the docs, should only be used to measure time intervals: The reference point of the returned value is undefined, so that only the difference between the results of consecutive calls is valid. Because of that, time.perf_counter() is mostly used to compare performance.
Math (математика, статистика)
База
Приоритеты: a = 82 // 3 ** 2 % 7= 82 // 9 % 7 = 9 % 7 = 2
| Оператор | Описание |
|---|---|
| + | сложение |
| – | вычитание |
| * | умножение |
| / | деление |
| ** | возведение в степень, имеет наивысший приоритет, правоассоциативно 2 ** 2 ** 3 = 256 |
| % | остаток от деления, приоритет аналогичен делению/умножению
10 % 3 = 1
|
| // | целочисленное деление, приоритет аналогичен делению/умножению
10 // 3 = 3 10 // 12 = 0 -10 // 3 = -4 |
Отходящую от базовой калькуляции можно делать со стандартной библиотекой math. Далее, по аналогии с re (regexp), можно вызывая модуль объект math применять функции (или извлекать данные, например значение числа pi), определенные в этом модуль-объекте через точку (dot-notation).
import math math.pi # число PI math.sin(radians) math.log10(ratio) math.sqrt(2) # квадратный корень числа, заменяется возведением в степень 1/2: n ** 0.5 The module object contains the functions and variables defined in the module. To access one of the functions, you have to specify the name of the module and the name of the function, separated by a dot (also known as a period). This format is called dot notation. dot notation - The syntax for calling a function in another module by specifying the module name followed by a dot (period) and the function name.| log(x) | Натуральный логарифм числа x. Основание натурального логарифма равно числу e |
| log10(x) | Десятичный логарифм числа x. Основание десятичного логарифма равно числу 10 |
| log(x, b) | Логарифм числа x по основанию b, напр: math.log(100, 2) |
| factorial(n) | Факториал натурального числа n |
Округление к большему (round up) делается с помощью функции ceil.
import math print(math.ceil(4.2))
Округление к меньшему с помощью функции floor. Но можно 1) использовать деление на цело // вместо обычного 2) преобразовать float в int
import math print(math.floor(4.2))
Среднее значение (average/mean value) для списка (массива).
import statistics first_values_avr = statistics.mean(first_values) last_values_avr = statistics.mean(last_values)
Медиана. Почему часто лучше использовать медиану описано тут (с примером).
Пример расчет в python: >>> import statistics >>> l = [25, 17, 23, 18, 24, 23, 16, 85, 50] >>> statistics.mean(l) 31.22222222222222 >>> statistics.median(l) 23 Наглядно между какими значениями находится среднее (23) и медиана (31): 16 17 18 23 23 24 25 50 85
Процентиль (numpy).
# PYTHON
>> import numpy as np
>> a = np.array([1,2,3,4,5])
>>> p = np.percentile(a, 50)
>>> print(p) 3.0
Коэффициент корреляции (correlation coefficient).
import numpy #a = list(map(int, a)) # example for data from file #b = list(map(int, b)) # example for data from file a = [1,4,6] b = [1,2,3] print(numpy.corrcoef(a,b)[0][1])
| Количественная мера тесноты связи |
Качественная характеристика силы связи |
| 0,1-0,3 | Слабая |
| 0,3-0,5 | Умеренная |
| 0,5-0,7 | Заметная |
| 0,7-0,9 | Высокая |
| 0,9-0,99 | Весьма высокая |
Линия тренда в математическом виде (судя по всему рассчитанная на основе метода наименьших квадратов).
Несколько интересных задач с использованием целочисленного деления и остатка деления (stepik Поколение Python)
- При помощи операции нахождения остатка и целочисленного деления можно достаточно несложно вычислить любую цифру числа. Чтобы получить последнюю цифру любого числа, нужно найти остаток от деления числа на 10.
Рассмотрим программу получения цифр трёхзначного числа:
num = 754 a = num % 10 b = (num % 100) // 10 c = num // 100 print(a) print(b) print(c) >>> 4 5 7
Алгоритм получения цифр n-значного числа
Первая цифра: (num % 10^n) // 10^n-1 Последняя цифра: (num % 10) // 100 3 # num % 10
- Напишите программу для пересчёта величины временного интервала, заданного в минутах, в величину, выраженную в часах и минутах.
mn = int(input()) print(mn, "мин - это", mn//60, "час", mn%60, "минут.")
- Безумный титан Танос собрал все 6 камней бесконечности и намеревается уничтожить половину населения Вселенной по щелчку пальцев. При этом если население Вселенной является нечетным числом, то титан проявит милосердие и округлит количество выживших в большую сторону. Помогите Мстителям подсчитать количество выживших.На вход дается число целое n – население Вселенной. Программа должна вывести одно число – количество выживших.
Номер теста Входные данные Выходные данные 1 99 50 2 1132 566 3 1 1 Решил так: a//2+a%2 Так же решение: (a+1)//2
- В купейном вагоне имеется 9 купе с четырьмя местами для пассажиров в каждом. Напишите программу, которая определяет номер купе, в котором находится место с заданным номером (нумерация мест сквозная, начинается с 1). На вход программе подаётся целое число – место с заданным номером в вагоне. Программа должна вывести одно число – номер купе, в котором находится указаное место.
Номер теста Входные данные Выходные данные 1 1 1 2 2 1 3 3 1 4 4 1 5 5 2 6 6 2 7 7 2 8 8 2 9 9 3 10 10 3 Решил так (не совчем честно тк не проходили float): int(a//4.1+1) Более кошерное решение: (a - 1) // 4 + 1
Комментарии
В целом о комментариях и их использовании тут.
Simple comment:
# comment
Multiline Code, Variable, Comment (многострочный код/переменная комменты)
Полезно когда много всего в одной строке расщеплять ее на несколько:
Import
from some_module import 1, 2, 3, 4, 5, 6, \ 6, 7, 8, 9, 10, \ 11, 12, 13,14
Variable
msg = f"Error: retry ({i}/{i_max}) receive data is not ready" + \
"to read (not buffered), waiting 2 seconds..."
Comment
# - обычный однострочный ''' или """ - multiline
Как правильно разбивать длинные строки кода.
The preferred way of wrapping long lines is by using Python’s implied line continuation inside parentheses, brackets and braces.
Long lines can be broken over multiple lines by wrapping expressions in parentheses. These should be used in preference to using a backslash for line continuation.
# 1 my_sum = (0 + 1 + 2 Break up line + 3 + 4 + 5 + 6 + 7 + 8) # 1-2 from trex_stl_lib.api import (STLClient, Ether, STLScVmRaw, STLVmFlowVar, STLVmWrFlowVar, STLVmFixIpv4, STLPktBuilder, STLStream, STLTXCont, STLError) # 2 assert True == True, \ 'This is a very long error message that should be put on a separate line'
Variable
var = '''line1 line2 line3'''
Очень удобно multiline использовать для более-менее симпатичного пользовательского вывода в CLI. Пример вывода информаци о VM Azure:
print(f'''Key VMs info:
name: {vm_info["name"]}
size: {vm_info["hardwareProfile"]["vmSize"]}
location: {vm_info["location"]}
proximityPlacementGroup: {ppg}
nics: {json.dumps(nics, indent=10)}
''')
Random
Библиотека random позволяет генерировать псевдо-случайные числа.
The random module provides functions that generate pseudorandom numbers (which I will simply call "random" from here on).
В random есть глобальная (для функций random) возможность использовать random seed для генерации псевдослучайного распределения. Чтобы повторять результат random можно заранее задекларировать seed (при вызове любой функции рандомизации будет использован этот seed), чтобы иметь каждый раз (каждый вызов функции) разный результат – сбросить seed. При этом, в документации python гарантируется, что несмотря на реальные будущие изменения алгоритмов в стандартной библиотеке random, при использовании одного seed value будет получаться одинаковое псевдорандомное распределение. Примеры использования повторяемого рандома (random seed/repeatable random) – токены MFA, генераторы трафика: tcpreplay-edit, isic, TRex, Ixia IxNetwork.
random.seed(1) # declare seed random.seed() # reset seed (use random seed) https://docs.python.org/3/library/random.html Most of the random module’s algorithms and seeding functions are subject to change across Python versions, but two aspects are guaranteed not to change: - If a new seeding method is added, then a backward compatible seeder will be offered. - The generator’s random() method will continue to produce the same sequence when the compatible seeder is given the same seed.
Функция .random к объекту random генерирует случайное число от 0.1 до 1.
The functionrandomreturns a random float between 0.0 and 1.0 (including 0.0 but not 1.0). import randomrandom.random()
Функция .randint к объекту random генерирует случайное int число от заданного x до y.
The functionrandinttakes the parameterslowandhigh, and returns an integer betweenlowandhigh(including both).random.randint(3, 10)
Функция .choice к объекту random выбирает случайный элемент из массива.
To choose an element from a sequence at random, you can use choice
random.choice([1, 4, 2, 5])
random.choice([5,7,9,11,10,31,32,34])
>>> import random
>>> random.choice([5,7,9,11,10,31,32,34])
7
>>> random.choice([5,7,9,11,10,31,32,34])
31
>>> random.choice([5,7,9,11,10,31,32,34])
7
>>> random.choice([5,7,9,11,10,31,32,34])
10
>>> random.choice([5,7,9,11,10,31,32,34])
7
Функция shuffle перемешивает массив.
# BASIC from random import shuffle x = [[i] for i in range(10)] shuffle(x) print(x) >> [[5], [1], [8], [4], [6], [3], [9], [2], [7], [0]]
Кодировка (Coding), utf-8, ascii, encode, decode, ENCODING
- В Python строки хранятся в виде последовательности Unicode символов.
- Подробнее о таблицах символов ascii/unicode и кодировках utf-8/16/32 в словаре.
- Пример вывода всех ASCI символов
>>> import string >>> print(string.ascii_letters) abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ >>> print(string.ascii_letters[0]) a >>> print(string.ascii_letters[5]) f
- Всегда лучше указывать кодировку в header файла. Может помочь от ошибок типа “Non-ASCII character ‘\xc2’ in file” и открывать файлы со скриптами в utf-8 на Windows без преобразований в другие кодировки.
# -*- coding: utf-8 -*-
Для кодирования символов в byte строку используем encode. Можно применять на саму строку или на класс str. Если символы не поддерживаются в таблице символов – будет ошибка. Можно указать разные опции (костыли), что делать с символами, которые не распознаются (ignore, replace, namereplace).
>>> print("привет".encode("utf-8")) b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' >>> print(str.encode("привет","utf-8")) b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82'
>>> print("привет".encode("ascii")) Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-5: ordinal not in range(128) >>> print("привет".encode("ascii","ignore")) b'' >>> print("привет".encode("ascii","replace")) b'??????' >>> print("привет".encode("ascii","namereplace")) b'\\N{CYRILLIC SMALL LETTER PE}\\N{CYRILLIC SMALL LETTER ER}\\N{CYRILLIC SMALL LETTER I}\\N{CYRILLIC SMALL LETTER VE}\\N{CYRILLIC SMALL LETTER IE}\\N{CYRILLIC SMALL LETTER TE}'
Для кодирования чисел (integer) в byte используем to_bytes. Пример str to bytes и integer to bytes в формировании DNS запросов для scapy payload.
full_payload = '\x00\x00\x01\x00\x00\x01\x00\x00\x00\x00\x00\x00\x05\x77\x65\x72\x69\x6c\x02\x6d\x65\x00\x00\x01\x00\x01' # эталон
payload_prepend = b'\x00\x00\x01\x00\x00\x01\x00\x00\x00\x00\x00\x00'
payload_append = b'\x00\x00\x01\x00\x01'
domain = b''
domain_str = 's1.d1.weril.me'
domain_dot_number = 0
chr_num = 0
for chr in domain_str:
if chr == "." or chr_num == 0:
domain1_len = len(domain_str.split(".")[domain_dot_number])
byte_int = domain1_len.to_bytes(1, 'big')
domain = domain + byte_int
domain_dot_number = domain_dot_number + 1
if chr_num == 0:
domain = domain + chr.encode()
else:
domain = domain + chr.encode()
chr_num = chr_num + 1
full_payload = payload_prepend + domain + payload_append
pkt = Ether()/IP(src="16.0.0.1",dst="48.0.0.1")/UDP(sport=1025)/(full_payload)
Для декодирования символов из byte строки используем decode. При декодировании нужно знать исходную кодировку, иначе (если кодировка кодирования и декодирования не совпадают, например utf-8 – utf-16) могут декодироваться кракозябры или может быть ошибка декодирования (можно так же как в случае с кодированием игнорировать недекодируемые символы). Поэтому желательно указывать кодировку в header файла (см. выше).
>>> print(b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82'.decode("utf-8")) привет >>> print(bytes.decode(b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82',"utf-8")) привет
>>> print(b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82'.decode("utf-16")) 뿐胑룐닐뗐苑
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 0: ordinal not in range(128) hi_unicode = 'привет' hi_bytes = hi_unicode.encode('utf-8') hi_bytes.decode('ascii',"ignore")
num2words library – Convert numbers to words in multiple languages – позволяет конвертировать числа в пропись, полезно для бугалтерии/документов с деньгами.
$ num2words 10001
ten thousand and oneПо умолчанию кодировка для Linux/MAC – UTF-8, для Windows – зависит от языка системы, в случае русского это cp1251.
Lin >>> import locale >>> locale.getpreferredencoding() 'UTF-8' Win >>> import locale >>> locale.getpreferredencoding() 'cp1251'
Строку из UTF-8 преобразовать в CP1251 легко. Напр. может пригодиться тогда, когда программа исполняется с utf-8 кодировкой (под исполняется – имеет комментарии/оперирует с базой/сохраняет вывод/etc с utf-8 символами) но какой-то или весь вывод нужно сохранить в cp1251 – формируем какой-нибудь CSV файл, который будет открываться в Windows.
"привет".decode("utf-8").encode("cp1251",'ignore') # convert from UTF-8 to cp1251
Пример изменения locale для отображения дней недели/месяцов на русском стандартными функциями.
>>> import locale
>>> locale.setlocale(locale.LC_ALL, ('ru_RU', 'UTF-8'))
'ru_RU.UTF-8'
>>> date.today().strftime("%B")
'августа'
>>> date.today().strftime("%A")
'воскресенье'
Большинство библиотек, которые работают с внешними данными (файлы, подключения по сети и к базам данными) позволяют указать кодировку данных непосредственно при вызове. Например, subprocess, file. Каким то библиотекам данные обязательно нужны в виде byte (telnetlib).
test = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, encoding='utf-8') # декодируем полученные байты в строку
>>> open('/home/redkin_p/sw') <_io.TextIOWrapper name='/home/redkin_p/sw' mode='r' encoding='UTF-8'>
Особенность python – байт строку с ascii символами python автоматически декодирует (показывает симолы вместо byte) при отображении, при этом не меняя тип. При этом к byte строке можно применить методы строк типо uppper и это создает еще большую иллюзию, что идет работа с с символами, а не байтами. Если символы не ascii – python показывает сырые байты, как они есть (as is). В случае перемешки ascii и не-ascii происходит отображение в виде символов того, что удалось конвертировать.
>>> print("hi".encode("utf-8")) b'hi' >>> print("привет".encode("utf-8")) b'\xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82' >>> print(type("привет".encode("utf-8"))) <class 'bytes'> >>> print(type("hi".encode("utf-8"))) <class 'bytes'>
>>> print("hello and привет".encode("utf-8")) b'hello and \xd0\xbf\xd1\x80\xd0\xb8\xd0\xb2\xd0\xb5\xd1\x82'
Функция ord() принимает на входе символ (одиночный символ) и возращает его код в таблице символов Unicode.
num1 = ord('A')
num2 = ord('B')
num3 = ord('a')
print(num1, num2, num3)
>>>
65 66 97Функция chr() по коду символа возвращает строку (str) с символом Юникода.
>>> chr(97)
'a'
>>> chr(98)
'b'
>>> chr(122)
'z'
a = "weril.me"
for s in a:
code = ord(s)
print(f"s:{s}, codecode:{code}")
s:w, code:119
s:e, code:101
s:r, code:114
s:i, code:105
s:l, code:108
s:., code:46
s:m, code:109
s:e, code:101
a = "weril.me"
for s in a:
code = ord(s)
reverse = chr(code)
print(f"s:{s}, code:{code}, reverse:{reverse}")
s:w, code:119, reverse:w
s:e, code:101, reverse:e
s:r, code:114, reverse:r
s:i, code:105, reverse:i
s:l, code:108, reverse:l
s:., code:46, reverse:.
s:m, code:109, reverse:m
s:e, code:101, reverse:e
# Мы можем использовать следующий код для вывода всех заглавных букв английского алфавита:
for i in range(26):
print(chr(ord('A') + i))
# На вход программе подаются два числа a и b. Напишите программу, которая для каждого кодового значения в диапазоне от a до b(включительно), выводит соответствующий ему символ из таблицы символов Unicode
num1=int(input())
num2=int(input())
for n in range(num1, num2+1):
print(chr(n), end=" ")
# На вход программе подается строка текста. Напишите программу, которая переводит каждый ее символ в соответствующий ему код из таблицы символов Unicode.
num=input()
for n in num:
print(ord(n), end=" ")
Telnet
При использовании telnetlib с python 3+ обязательно кодируем в байт строку данные иначе будет выдавать ошибку TypeError: ‘str’ does not support the buffer interface (python 3.4) или TypeError: a bytes-like object is required, not ‘str’ (python 3.6). Это можно сделать поставив символ “b” перед строкой или применив к нему метод encode (с кодировкой utf-8/ascii или без указания кодировки). Полученные данные в str декодируем в байт строку через decode.
#!/usr/bin/env python3.6
#coding: utf-8
import telnetlib
# bad one-liner read (closing issue) (see above)
lgn = open('/home/redkin_p/.duser').read().rstrip().encode('utf-8') #берем login из файла, удаляем из него мусор (\n), кодируем в байт-строку
pswd = open('/home/redkin_p/.dpass').read().rstrip().encode('ascii') #берем password из файла, удаляем из него мусор (\n), кодируем в байт-строку
tn = telnetlib.Telnet("10.10.10.10") #подключаемся к узлу
tn.read_until("UserName:".encode()) #ждем строку "UserName:"
tn.write(lgn + b"\r") #передаем кодированный в байт-строку login
tn.read_until(b"PassWord:") #ждем строку "PassWord:"
tn.write(pswd + b"\r") #передаем кодированный в байт-строку password
tn.read_until(b"#") #ждем строку "#"
tn.write(b"show switch\r") #передаем необходимый запрос
res = tn.read_until(b"#") #забираем данные, можно так же использовать функцию read_very_eager() на объект telnetlib.
tn.close
print(res.decode('ascii')) #
SSH
Для ssh используем paramiko.
Функции подключения по ssh и отправке команд в созданный connect.
import paramiko import time def ssh_login(ssh_ip, ssh_user, ssh_password): client = paramiko.SSHClient() client.set_missing_host_key_policy(paramiko.AutoAddPolicy()) client.connect(ssh_ip, username=ssh_user, password=ssh_password) return client.invoke_shell(), client def push_ssh_command(ssh_conn, command, timeout, out_buf, encoding): ssh_conn.send(command) time.sleep(timeout) command_result = ssh_conn.recv(out_buf).decode(encoding, "ignore") print(command_result) return command_result
После этого можно делать операции.
Отдельными командами:
push_ssh_command(ssh_conn, 'conf t\n', ssh_timeout, 5000, 'utf-8')
Или набором, объединенным в функции:
def shutdown_if(ssh_conn, ssh_timeout, if):
push_ssh_command(ssh_conn, 'conf t\n', ssh_timeout, 5000, 'utf-8')
push_ssh_command(ssh_conn, 'int {}\n'.format(if), ssh_timeout, 5000, 'utf-8')
push_ssh_command(ssh_conn, 'shutdown', ssh_timeout, 5000, 'utf-8')
Закрытие подключения. В примере ssh_login возвращается объект shell и отдельный объект client, на который нужно применять метод close после завершения работы по ssh (client.close()). Делать это на объект shell неправильно – соединение закрывается не полностью и при накомплении произойдет reject!
You can have multiple channels in a single SSH connection. Hence closing a single channel, won't close whole SSH connection. You need to call SSHClient.close to close the physical SSH connection (it takes all channels down with it, if any are still open). ssh.close() invoke_shell(term='vt100', width=80, height=24, width_pixels=0, height_pixels=0, environment=None)¶ Start an interactive shell session on the SSH server. A new Channel is opened and connected to a pseudo-terminal using the requested terminal type and size.
SCP
Для начала создаем ssh-подключение, например, используя paramiko.
ssh_conn, ssh_client = ssh_login(ssh_ip, ssh_user, ssh_password, ssh_shell_password)
Для загрузки файла используем scp.put, в качестве транспорта используем созданное ssh-подключение.
def scp_put(ssh_conn, fromdir, todir): scp = SCPClient(ssh_conn.get_transport()) scp.put(fromdir, todir)
Для получения файла по scp проще/лучше всего использовать стандартную функцию get. В интернете есть пример с использованием вида получения файла receive, далее чтения content и записи в файл, но по факту в Windows при таком подходе могут быть проблемы с поврежденным tar архивом (crc правильный, но контент поврежден).
def scp_get(ssh_conn, fromdir, todir): scp = SCPClient(ssh_conn.get_transport()) scp.get(fromdir, todir)
Нежелательно
scp = scpclient.Read(ssh.get_transport(), localDir) content = scp.receive( remoteFile ) if content: fd = open( '%s/%s' % (localDir, os.path.split(remoteFile)[1]), 'w' ) fd.write( content ) fd.close()
Conditional structures
- Walrus operator удобно использовать в conditions (см. выше в python 3.8)
- Пустой словарь рассматривается как False, непустой как True
>>> some_dict = {}
>>> if some_dict: print("LOL")
...
>>> if not some_dict: print("LOL")
...
LOL
>>> some_dict = { "1": "2" }
>>> if not some_dict: print("LOL")
...
If/else/elif. В случае использования elif не обязателен else (в отличии от Ruby), а подпадание под несколько elif не означает исполнения кода под каждым – только под первым (как ACL в сетевом мире).
# one-line
if res == "test": print(x)
if "string" in somevar: print("Hit")
# simple
if res == "test":
print("true")
# if with else
if res == "test":
print("true")
else:
print("false")
# if with else with elif
if res == "test":
print("true")
elif res == "test2":
pass # do nothing
elif res == "test3":
print("false3")
else:
print("false")
# можно делать конструкции и без else (если не подпадет ни под одно из условий, то не отработает никак)
if res == "test":
print("true")
elif res == "test2":
print("false")
Цепочки сравнения (chained comparison operator) очень удобно, но, для неравенства нужно использовать аккуратно т.к. A!=B и B!=C не говорит, что C!=A
if first == second == third:
print("All values are equal")
if 3 <= age <= 6:
print("Вы ребёнок от 3 до 6 лет")
if 7 <= age <= 9: # вместо более громоздкого if age >= 7 and age <= 9:
print("Вам от 7 до 9 лет")
Числа (Integer/FLOAT, Hex, dec, bin)
Python even or odd (остаток деления)
number % 2 == 0
Округление python. Вторая переменная определяет количество знаков после запятой. В случае ее отсутствия округляет до чистого integer (чаще всего это и нужно).
>>> round(2.65) 3 >>> round(2.65, 1) 2.6
Long
Тип long в python 2x использовался для длинных целы чисел. В общем случае при сравнении типов нужно учитывать что число может быть и int и long и не делать exception (если только exception именно то, что вы хотели – не получить длинное целое число).
В python 3x отказались от Long вообще.
Системы исчисления
Для перевода между системами исчисления может помимо описанных способов использоваться метод format, подробнее в описании функции.
bin – dec
Из десятичного в двоичный (binary – 0b): Функция bin() возвращает строку с двоичным представлением указанного целого числа. Важно: обратите внимание на приставку 0b, которая сигнализирует о том, что число представлено в двоичной системе счисления. Если нам требуется избавиться от приставок, то мы можем воспользоваться строковым срезом: res[2:].
>>> bin(128)
'0b10000000'
print(bin(10))
print(bin(128))
print(bin(150)) print(bin(18765))
0b1010
0b10000000
0b10010110
0b100100101001101
Из двоичного в десятичный (decimal):
>>> int('10000000', 2)
128
binascii.hexlify('weril')
binascii.hexlify(b'weril', '-')
>>>
domain = 'weril.me'
hex_domain = ''
for chr in domain:
hex_domain = hex_domain + hex(ord(chr)).replace('0', '\\', 1)
print(domain)
print(hex_domain)
>>>
weril.me
\x77\x65\x72\x69\x6c\x2e\x6d\x65
var1 = b'\x00\x05\x77\x65\x72\x69\x6c\x02\x6d\x65\x00\x01' # EQUAL var1 = b'\x00\x05' + b'\x77\x65\x72\x69\x6c\x02\x6d\x65' + b'x00\x01'
Из десятичного в шестнадцатеричный (hex – 0x): Функция hex() возвращает строку с шестнадцатеричным представлением указанного целого числа. Важно: обратите внимание на приставку 0x, которая сигнализирует о том, что число представлено в шестнадцатеричной системе счисления. Если нам требуется избавиться от приставок, то мы можем воспользоваться строковым срезом: res[2:].
>>> hex(255)
'0xff'
print(hex(10))
print(hex(128))
print(hex(150)) print(hex(18765))
0xa
0x80
0x96
0x494d
Из шестнадцатеричного в десятичный (decimal):
>>> int('ff', 16)
255
String
Стандартная работа функции print
print(x) # вывод переменной х print(‘hello world’) # вывод текста hello world (можно как в двойных, так и в одинарных скобках)
Опциональные параметры функции print (аргументы надо передавать как ключевые, не позиционные):
-
- символ в конце строки end – например, позволяет делать print без new_line
- разделитель sep – по аналогии с AWK
- файл file – по умолчанию std.out, можно сделать std.err, в теории так же можно делать вывод сразу в файл, но лучше не делать
- параметр flush – полезно в циклах (печатать сразу после итерации, к примеру, реализация таймера sleep при print на одном line)
>> print("no_new_line", end='&')
no_new_line&
>> print("new_sep", "test", sep=';')
new_sep;test
for i in range(10):
print(i, end=" ", flush=True)
time.sleep(1)
0 1 2 3 4 5 6 7 8 9
replace позволяет сделать замену всех символов (по умолчанию), которые подпадают под первое условие, в том числе можно удалить символы заменой на “”, с регулярными выражениями не работает:
.replace("\x08", "")
В третьем аргументе replace можно указать количество подпадений, которое нужно поменять (чаще всего нужно первое):
.replace("\x08", "", 1)
in позволяет сделать поиск строки в подстроке:
if "string" in somevar: print("Hit")
if "vlan" in "switchport access vlan 666":
print("Yep")
В print перед строкой можно использовать разные опции, особенно популярно это было раньше, но можно встретить и сейчас. Что-то решается очень легко именно так, например – печатаем фиксированное количество символов в строке, количество пробелов зависит от количества символов строки. По факту эта задача сейчас решается через format и более гибко, в сравнении со старым способом (напр. указание выравнивания). Подробнее в format ниже.
# OLD
>>> print('%5s' % 'x')
x
>>> print('%5s' % 'xxx')
xxx
>>> print('%5s' % 'xxxxx')
xxxxx
# NEW
>>> "{0:>5}".format('xxx')
' xxx'
Простая конкатенация с print через + и ,:
print ("Hello"+name+"master") # конкатенация статичного текста и переменных без пробела
print ("Hello", name, "master") # конкатенация статичного текста и переменных через пробел
Конкатенация через .format, довольно удобно, хотя и в начале кажется что хуже ruby string interpolation
res = '{};{};{};{}\n'.format(e, broadcast[n], multicast[n], unknowncast[n])
Конкатенация через +=
error_text += f"Код ошибки: {result.returncode} - {error_msg}\n
Но .format очень функциональный – к примеру, можно:
- указывать размер столбца по количеству символов в каждом (как в bash printf) или указывать размер строки, дополняя ее пробелами если в исходной строке недостаточно символов,
- делать выравнивание текста (влево <, вправо >, вверх ^):
- указывать название переменных (удобно когда их много и/или они похожего формата данные) или (как по мне хуже) использовать нумерацию переменных
- исключать дублированные данные с использованием именование или индексов
- переводить из одной системы исчисления в другую
- используя * передавать данные не в виде отдельных элементов, а всем массивом
1-2
var = "{:<2} {:20} {:4} {:4}".format(1, "FastEthernet0/1", "down", "down")
print(var)
var = "{:<2} {:20} {:4} {:4}".format(2, "FastEthernet0/10", "down", "down")
print(var)
1 FastEthernet0/1 down down
2 FastEthernet0/10 down down
python3
>>> "{0:>5}".format('xxx')
' xxx'
>>> "{0:^5}".format('xxx')
' xxx '
3
var = "{num:<2} {int:20} {pstat:4} {dstat:4}".format(num=1, pstat="down", dstat="down", int="FastEthernet0/1")
print(var)
1 FastEthernet0/1 down down
txt = 'My name is {0}, I am {1}, I work as a {2}'.format(name, age, profession)
txt = 'My name is {0}-{0}-{0}'.format(name)
4
var = "{num:<2} {int:20} {dstat:4} {dstat:4}".format(num=1, dstat="down", int="FastEthernet0/1")
print(var)
1 FastEthernet0/1 down down
var = "1 FastEthernet0/1 down down"
var = "{0:<2} {2:20} {1:4} {1:4}".format(1, "down", "FastEthernet0/1")
1 FastEthernet0/1 down down
5
var = "{:b}.{:b}.{:b}.{:b}".format(192, 168, 1, 1)
var = "{:08b}.{:08b}.{:08b}.{:08b}".format(192, 168, 1, 1)
11000000.10101000.1.1
11000000.10101000.00000001.00000001
6
temp = "{} {} {}"
values = ["1", "2", "3"]
res = temp.format(*values)
1 2 3
Для конкатенации так же можно использовать f-strings (с python 3.6), он поддерживает максимально простой способ string interpolation – прямо в тексте (как в ruby). Мне этот способ нравится больше всего – он выглядит при большом количестве переменных самым чистаемым:
>>> name = "Petr"
>>> print(f"Hello, {name}!")
Hello, Petr!
Так же для конкатенации можно использовать %. Считаю, устаревший в сравнении с format, f-string метод, но лучше +.
var1 = "Hello"
var2 = "World"
print("% s % s" % (var1, var2))
Можно еще так же множить текст, умножив str на int
>>> first = 'Test '
>>> second = 3
>>> print(first * second)
Test Test TestDowncase/lowercase, upcase/uppercase. Тут и в аналогичных случаях можно вызывать метод напрямую на переменную, а можно на объект str, передав переменную в метод. Так же есть метод capitalize.
>>> "A".lower()
'a'
>>> "a".upper()
'A'
>>> "Word".capitalize()
'Word'
>>> str.lower("A")
'a'
>>> str.upper("a")
'A'
>>> str.capitalize("Word")
'Word'
swapcase, title
-
- Метод
swapcase()возвращает копию строкиs, в которой все символы, имеющие верхний регистр, преобразуются в символы нижнего регистра и наоборот. - Метод
title()возвращает копию строкиs, в которой первый символ каждого слова переводится в верхний регистр.
- Метод
>>> "Word".swapcase() 'wORD' >>> "Word is a word".title() 'Word Is A Word'
strip – удаляет все whitespace символы в начале и конце строки. rstrip удаляет только справа (в конце строки), lstrip только слева. В качестве аргумента можно указать символ(ы), которые будут удаляться, например, по умолчанию данные методы не удалят пробел U+0008: BACKSPACE ( rstrip(‘\x08’) ).
out = "[- vlan1 --]"
print(out.strip(" [-]"))
vlan1
(R)FIND, INDEX
- FIND
- Метод
find(<sub>, <start>, <end>)находит индекс первого вхождения подстроки<sub>в исходной строкеs. Если строкаsне содержит подстроки<sub>, то метод возвращает значение-1. Мы можем использовать данный метод наравне с операторомinдля проверки: содержит ли заданная строка некоторую подстроку или нет. - rfind – полный аналог, но возвращает последний индекс с конца строки (right).
- Метод
- INDEX
- Методы
index(<sub>, <start>, <end>)иrindex(<sub>, <start>, <end>)идентичны методамfind/rfind, за тем исключением, что они вызывают ошибкуValueError: substring not foundво время выполнения программы, если подстрока<sub>не найдена.
- Методы
С их использованием можно найти позицию определенной строки/буквы в заданной строке, а потом извлечь данные используя slice и номер позиции.
>>> s = "hello.my@weril.me"
>>> pos = s.find(".")
>>> pos
5
>>> pos = s.rfind(".")
>>> pos
14
s = "hello.my@weril.me"
pos = s.find("@")
print(pos)
pos2 = s.find(".", pos) # второй аргумент в find определяет стартовую позицию, иначе в выборку попал бы индекс 5 вместо 14
print(pos2)
res = s[pos+1:pos2]
print(res)
# test.py
8
14
weril
Startswith/endwith
Метод startswith(<suffix>, <start>, <end>)определяет начинается ли исходная строка s подстрокой <suffix>. Если исходная строка начинается с подстроки <suffix>,метод возвращает значение True, а если нет, то False.
В итоге можно сделать поиск по началу строки не только с помощью regexp:
line = "From weril@me.com"
if line.startswith("From "):
print("choto")
И не обязательно старт должен быть фактическим стартом строки – его можно сместить.
>>> "From weril@me.com".startswith("weril")
False
>>> "From weril@me.com".startswith("weril",5)
True
Метод endswith(<suffix>, <start>, <end>)определяет оканчивается ли исходная строка s подстрокой <suffix>. Метод возвращает значение True если исходная строка оканчивается на подстроку <suffix> и False в противном случае
SPLIT
split – по умолчанию split разделяет строку по whitespace (пробел/etc, причем любое количество whitespace рассматривается как одно целое) на массив (список), но можно конкретно указывать конкретный символ или набор символов. Если указать только пробел ” “, то дефолтное поведение изменится и набор пробелов/whitespace не будут рассматриваться как разделители.
line.split()
line.split("\n")
>>> line="some more line exist"
>>> line.split()
['some', 'more', 'line', 'exist']
В сравнении с regexp split будет работать быстрее/занимать меньше строк кода/будет более понятным по коду:
- для ^ или $ использовать split()[0] с доступом к первому или последнему элементу
x.split()[0]
- для того же, после определенного pattern можно использовать двойной split (например, для получения числа, окруженного двумя уникальными для строки pattern – blabsdfsdfbla;user_id:666;user_class:admin;blablalblsdfsdf)
The double split pattern - Sometimes we split a line one way, and then grab one of the pieces of the line and split that piece again.
x.split(";user_id:")[1].split(";user_class:")[0]
REGEXP
- Вместо регулярных выражений для извлечения данных зачастую можно и нужно использовать (достаточно использовать): Find, Startswith (ниже).
- База про regexp с примерами. Там в том числе описаны флаги (напр. DOTALL).
- Перед строками, в которых написано регулярное выражение в python желательно использовать r string literal (raw string notation), чтобы не приходилось заведомо экранировать спец. символы, которые могут быть в выражении
# with r
re.sub(r'def\s+([a-zA-Z_][a-zA-Z_0-9]*)\s*\(\s*\):',
... r'static PyObject*\npy_\1(void)\n{',
... 'def myfunc():')
# without r
re.sub('def\\s+([a-zA-Z_][a-zA-Z_0-9]*)\\s*\\(\\s*\\):',
... 'static PyObject*\\npy_\\1(void)\\n{',
... 'def myfunc():')
- regexp compile (re.compile)
- для ускорения сейчас не слишком нужен т.к. по факту в современном python сделано ряд операций, по сути делающих compile и не-compile выражения эквивалентными по скорости
- зачастую используется по привычке и для красивого кода (заранее описываем regexp выражение и к нему применяем методы regexp)
- используемые методы эквивалентны, только применяются к компилированному объекту, а не объекту re
regex = re.compile(r'som[Ee] reg[Ee]xp') m = regex.search(line)
Case insensitive
# example 1 cve = re.sub(r"(cve)", "CVE", cve, flags=re.IGNORECASE) # example 2 res = re.sub(r".*(cve[,_-]\d\d\d\d[,_-]\d\d\d\d?\d)", '', x, flags=re.IGNORECASE)
При этом для объекта regexp есть split, который позволит решить те задачи, которые сложнее/невозможно решить обычным split.
Методы
re.search – смотрим, подпадает есть ли regexp в строке, в результате в базовом сценарии получаем true/false (none). Есть так же почти аналогичная функция re.match, которая делает поиск только в начале строки. По факту при подпадении возвращается объект Match, из которого
-
- можно получить конкретный match (первое подпадение) или match подпавшей группы используя функцию group (нулевой элемент конкретный match, все последующие относятся к группам); причем в новых версиях python3 (c python 3.6 точно, но не работает в python 3.4) groups использовать не обязательно и можно обратится к match объекту по index для извлечения группы (аналог group: нулевой элемент занят под match, все последующие по номеру подпавшей группы)
- можно получить подпавшие группы () как отдельные элементы списка, используя groups
- можно так же получить index start/stop (span) начала/окончания match строки.
import re
line = "sdfsdf fdsf mm 555 fdfm ffsdf weril.me mg 77 sdfsdf 66"
res = re.search("weril.me", line)
print(res)
print(res.group())
$ python3 ./test.py
<re.Match object; span=(31, 39), match='weril.me'>
weril.me
# добавляем в regexp группы и делаем print groups
res = re.search("(weril.me).*(66)", line)
print(res.groups())
print(res.group(2))
print(res[2])
~$ python3.6 bin/test.py
<_sre.SRE_Match object; span=(30, 54), match='weril.me mg 77 sdfsdf 66'>
('weril.me', '66')
66
66
re.sub – замена символов с поддержкой regexp. Поддерживает счетчик количества замен (по умолчанию бесконечность) – при указании заменит только столько раз. Так же поддерживает группы – можно из какого то вывода извлечь с помощью regexp matching group и сделать подмену.
import re re.sub(r".*interface gei-0/1/1/", '', text) re.sub(r".*interface gei-0/1/1/", '', text, count=10) re.sub(r"(\d+) (\d+)", r'\1:\2', text)
re.findall – получение данных из match. Причем в результате не только первый/последний match, а все в виде list. Есть так же почти аналогичная функция re.finditer, которая возвращает итератор с объектами Match (в разных случаях разный- list/set list, но в любом случае итератор). Используя группировку () (подробнее в статье про regexp) можно получать только часть данных из match:
import re # получаем все числа line = "sdfsdf fdsf mm 555 fdfm ffsdf mg 77 sdfsdf 66" res = re.findall(r"\d+", line) print(res) $ python3 ./test.py ['555', '77', '66'] line = "kakayato chush = 0.432423" res = re.findall(r"^kakayato chush = [0-9.]+", line) print(res) $ python3 ./test.py ['kakayato chush = 0.432423'] line = "kakayato chush = 0.432423" res = re.findall(r"^kakayato chush = ([0-9.]+)", line) print(res) $ python3 ./test.py ['0.432423'] line = "From toster@weril.me at Sat Jan 13 01:01:01 2019" res = re.findall(r"^From .*@([^ ]*)", line) print(res) $ python3 ./test.py ['weril.me']
re.split – для объекта regexp есть split, который позволит решить те задачи, которые сложнее/невозможно решить обычным split.
re.split(r' +', text) re.split(r'[ ,|]', text)
Кодировки
- Строка в python3 имеет по умолчанию кодировку unicode, в отличии от python2.
- В python2 для преобразования в unicode нужно перед строкой ставить u.
- В python3 нужно преобразовывать данные, полученные из сети.
Python 3.7.2 >>> line='line' >>> type(line) <class 'str'> >>> line=u'line' >>> type(line) <class 'str'> Python 2.7.10 >>> line='line' >>> type(line) <type 'str'> >>> line=u'line' >>> type(line) <type 'unicode'>
Array/LIST/TUPLE/DICTIONARY/set (массивы, списки, словари, кортежи, множества)
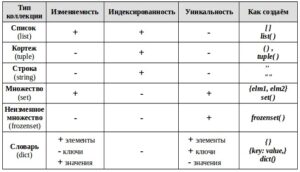
- До python 3.7 словари были неупорядоченны – т.е. последовательность элементов после создания могла меняться. Начиная с python 3.7 они упорядочены. Полагаться на это стоит только если код не будет запускаться со старыми версиями. Если нужно создать последовательный словарь для поддержки старых веррсий, то можно
- использовать функцию ordereddict класса Collections при создании массива. Конвертации многомерного массива в ordered нет, но можно это сделать с помощью json (см. ниже по object_pairs_hook=collections.OrderedDict).
- Ordered dictionaries are just like regular dictionaries but have some extra capabilities relating to ordering operations. They have become less important now that the built-in dict class gained the ability to remember insertion order (this new behavior became guaranteed in Python 3.7).
- В отличии от стандартного словаря ordereddict выдаст False на словари в разном порядке
- The equality operation for OrderedDict checks for matching order
- использовать функцию ordereddict класса Collections при создании массива. Конвертации многомерного массива в ordered нет, но можно это сделать с помощью json (см. ниже по object_pairs_hook=collections.OrderedDict).
import collections # создание нового массива d1 = collections.OrderedDict() d1['a'] = 'A' d1['b'] = 'B' d1['c'] = 'C' d1['d'] = 'D' d1['e'] = 'E' print(d1) # конвертация многомерного массива с сохранением позиций json_pattern = json.loads(json_pattern, object_pairs_hook=collections.OrderedDict)
-
- конвертировать элементы словаря, которые должны быть упорядочены, в список – списки сохраняют последовательность
WAS (not order preservation)
{
"x: {"packets": 881160, "size": 110145},
"y": {"packets": 896550, "size": 35862},
}
NOW (order preserved)
[
{"name":"x", "packets": 881160, "size": 110145},
{"name":"y", "packets": 896550, "size": 35862},
]
- В Python (и большинстве других ЯП) существует две основных разновидности циклов:
- циклы, повторяющиеся определенное количество раз (for, счетные циклы, counting loops);
- циклы, повторяющиеся до наступления определенного события (while, условные циклы, conditional loops).
- Так же интересное по циклам:
- оба типа циклов имеют возможность использования else после цикла, который исполняется только в случае, если цикл прерван корректно (не по break), на практике использование этой фичи не встречал, да и она “не огонь” даже по мнению Гвидо
- оператор break выполняет прерывание ближайшего цикла в котором он расположен (вложенные циклы). Аналогично, оператор continue осуществляет переход на следующую итерацию ближайшего цикла.
Про особенности копирования массивов делай поиск по deepcopy. С точки зрения практике важно, что копирование простым равно не работает и даже вредно, нужно использовать методы copy, slice, list, deepcopy (самый медленный, но скопирует и вложенные объекты).
https://stackoverflow.com/questions/2612802/how-do-i-clone-a-list-so-that-it-doesnt-change-unexpectedly-after-assignment To actually copy the list, you have several options: 1) You can use the built-in list.copy()method (available since Python 3.3): new_list = old_list.copy() 2) You can slice it: new_list = old_list[:] 3) You can use the built-in list()constructor: new_list = list(old_list) 4) You can use generic copy.copy(): import copy new_list = copy.copy(old_list) This is a little slower than list()because it has to find out the datatype of old_list first. 5) If you need to copy the elements of the list as well, use generic copy.deepcopy(): import copy new_list = copy.deepcopy(old_list) Obviously the slowest and most memory-needing method, but sometimes unavoidable. This operates recursively; it will handle any number of levels of nested lists (or other containers).
Длина массива или строки (length), если использовать в итерациях как защиту от выхода за пределы массива (IndexError), нужно держать в уме что длина массива на единицу больше, чем индекс последнего элемента в массиве
len(arr) # right while len(pd) > k_pd+1 and v_pd == pd[k_pd+1]: # wrong while len(pd) >= k_pd+1 and v_pd == pd[k_pd+1]:
count – Количество определенных элементов в массиве или строке (итерируемом объекте)
- читает количество непересекающихся вхождений подстроки
<sub>в исходную строку - можно указать диапазон поиска
arr = [ 1, 2, 3, 1, 5, 1] print( arr.count(1) ) >> 3
s = 'foo goo moo'
print(s.count('oo'))
print(s.count('oo', 0, 8)) # подсчет в диапазоне с 0 по 7 символ
>>
3
2Максимальный/минимальный элемент – работает для элементов в виде str по их номеру в Unicode, так и для int/float, так же работает и для array
-При сравнении строк в Python, каждый символ в строке имеет свой порядковый номер в таблице Unicode, и сравнение строк происходит путем сравнения порядковых номеров их символов слева направо. - Если этим функциям передается несколько списков, то целиком возвращается один из переданных списков. При этом сравнение происходит поэлементно: сначала сравниваются первые элементы списков. Если они не равны, то функция min() вернет тот список, первый элемент которого меньше, max() – наоборот. Если первые элементы равны, то будут сравниваться вторые и т. д. >>> min([1,2,3]) 1 >>> max([1,2,3]) 3 >>> min(["a","b","c"]) 'a' >>> max(["a","b","c"]) 'c' >>> min([1,2,3],[2,3,4],[0,1,55,66]) [0, 1, 55, 66] >>> max([1,2,3],[2,3,4],[0,1,55,66]) [2, 3, 4]
Сумма элементов массива (должны быть int/float). Если нет – может помочь метод ниже.
sum(arr)
Разделение массивов на две части используя slice (split in two parts/half).
count = len(values) first_values = values[:count//2] last_values = values[count//2:] print(count, len(first_values), len(last_values))
Конкатенация нескольких массивов (списков, кортежей, множеств). Аналогична возможна разность.
>>> a=[1,2] >>> b=[3,4] >>> a+b [1, 2, 3, 4]
Переворачивание (reverse) массива.
reversed(l)
Поиск элементов по шаблону в списке/массиве и возврат нового списка/массива (аналог ruby .select) работает через генератор (generator expression).
data_list = list(x for x in data_list if "DGS-3620" in x)
Преобразование всех элементов массива в int. Для этого можно использовать генераторы, а можно map. Вообще map, filter, reduce (и напр. есть в pandas) это циклы на базе C-кода в python и они считаются что работают быстрее нативных циклов python и по этой причине могут быть полезны при большом количестве данных для итерирования/перебора.
results = map(int, results)
results = [int(x) for x in results]Список кортежей или словарь (hash) можно создать из объединения двух списков с помощью функции zip. Для списка кортежей можно zip’ить и большее количество list, не только два.
arr1 = [1,2,3]
arr2 = ["kaka", "maka", "myka"]
print(list(zip(arr1,arr2)))
[(1, 'kaka'), (2, 'maka'), (3, 'myka')]
print(dict(zip(arr1,arr2)))
{1: 'kaka', 2: 'maka', 3: 'myka'}
arr3 = ["l", "k", "m"]
print(list(zip(arr1,arr2,arr3)))
[(1, 'kaka', 'l'), (2, 'maka', 'k'), (3, 'myka', 'm')]
Tuple (кортеж) – по сути тот же самый list, только его нельзя изменять (not mutable) и сортировать. Поэтому он быстрее/занимает меньше памяти. Tuple не изменяется, но поменять вложенный в tuple объект возможно – в tuple хранится ссылка на list, поэтому значение мы присваиваем list’у, а не tuple’у
>>> a1 [1, 3, 5] >>> t1 (1, 3, 5) >>> import sys >>> sys.getsizeof(a1) 88 >>> sys.getsizeof(t1) 72 >>> tp = (1, [2,3], 4) >>> tp[0]=10 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> tp[1][0]=10 >>> tp (1, [10, 3], 4)
Используются всегда, когда могут с учетом “недостатков”. Часто используются для временных переменных, для данных, которые хочется иметь в исходном виде (например, данные выгруженные из БД).
Tuples is that they're not mutable and that allows them to be stored more densely than lists. Whatever order you put the tuple in when you create it, it stays in that. You can't append, extend, flip, sort it.
We tend to use tuples when we can.
tup = ("raz", "dvas")
print(tup[0])
>> raz
print(max(tup))
>> raz
print(len(tup))
>> 2
tup[0] = 2
>> Traceback (most recent call last):
File ".\test.py", line 5, in <module>
tup[0] = 2
TypeError: 'tuple' object does not support item assignment
Из list можно получить кортеж, используя метод tuple (справедливо и обратное с помощью метода list).
>>> a = [1, 2] >>> tuple(a) (1, 2)
Кортеж из одного элемента можно создать поставив запятую после него, иначе интерпретатор будет думать, что это число в скобках. Аналогично и с операциями с tuple – например, добавление элемента.
>>> t1=(1) >>> t1 1 >>> type(t1) <class 'int'> >>> t1=(1,) >>> t1 (1,) >>> type(t1) <class 'tuple'> >>> t1 = (1,3,5) >>> t1 + (7,) (1, 3, 5, 7)
Из dictionary так же можно получить список кортежей, используя метод items (справедливо и обратное с помощью метода list). Подробнее о методе в dictionary.
>>> a.items()
dict_items([('id', 1), ('name', 'Sesame Street'), ('location', None), ('location2', 'some_loc')])
Кортежи (так же как и списки/множества) поддерживают multiple assignment, что используется при итерациях/выводе с функций.
raz, dvas = ("raz", "dvas")
print(raz)
>> raz
print(dvas)
>> dvas
d = {"id": 1, "name":"Sesame Street"}
for key, value in d.items():
print(key, value)
print(d.items())
dict_items([('id', 1), ('name', 'Sesame Street')])
Кортежи можно объединять.
>>> t1=(1,3,5) >>> t2=(2,4,6) >>> t1+t2 (1, 3, 5, 2, 4, 6)
Создание
Для создания списков/словарей и других итерируемых объектов могут применяться генераторы (generator expressions) и list comprehension – например, цикл for внутри списка. Они являются синтетическим сахаром – т.е. не обязательны для создания программы, но зачастую делают код красивее/быстрее. list comprehension возвращает list, а generator expression объект итератор. Я в основном использую первые. Иногда используются совместно с lambda функциями.
# Generator expression -- returns iterator >>> stripped_iter = (line.strip() for line in line_list) >>> # List comprehension -- returns list >>> stripped_list = [line.strip() for line in line_list]
Читать их достаточно просто – начинай с середины: middle -> tail (condition) -> head:
>>> var1 = [ 2**i for i in range(10)] >>> var1 [1, 2, 4, 8, 16, 32, 64, 128, 256, 512] >>> var1 = [ i**2 for i in range(10)] >>> var1 [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> var1 = [ i**2 for i in range(10) if i>5] >>> var1 [36, 49, 64, 81] >>> var1 = [ i for i in range(10) if i % 2 == 0] >>> var1 [0, 2, 4, 6, 8] >>> var1 = [ i for i in range(10) if i % 2 == 1] >>> var1 [1, 3, 5, 7, 9] >>> var1 = ["line " + str(i) for i in range(10)] >>> var1 ['line 0', 'line 1', 'line 2', 'line 3', 'line 4', 'line 5', 'line 6', 'line 7', 'line 8', 'line 9'] >>> arr = [random.randint(-100000, 100000) for x in range(100000)] >>> arr [ тут 100 тыс. рандомизированных элементов ] >>> ip_correct_list = [ip for ip in ip_list if check_ip(ip)]
array of unique values
Один массив – создаем ряд на основе списка (множество set по умолчанию содержит только уникальные значения), преобразуем обратно в список
>>> a1
[1, 2, 3, 1, 2, 3, 3, 3, 5, 1]
>>> set(a1)
{1, 2, 3, 5}
>>> list(set(a1))
[1, 2, 3, 5]
Объединение массивов (union)
Несколько массивов, через объединение массовой получаем список уникальных значений в обоих массивах (дубли между массивами удаляются). Так же используем множества (set) для этой операции.
a = [2, 3, 555]
b = [3, 9, 777]
a_b = a + b # базовое объединение (без исключения дублей)
a_b_set = set(a) | set(b) # объединение set с исключением дублей
a_b_union = set(a).union(set(b)) # полностью аналогично
print(f"a_b:{a_b}")
print(f"a_b_set:{a_b_set}")
print(f"a_b_union:{a_b_union}")
>>>
a_b:[2, 3, 555, 3, 9, 777]
a_b_set:{2, 3, 777, 9, 555}
a_b_union:{2, 3, 777, 9, 555}
Добавление значений list в этот же list
-
-
- +=
- extend
- распоковать дважды
-
>>> lst [1, 2, 2, 3, 22, 2] # 1 >>> lst+=lst >>> lst [1, 2, 2, 3, 22, 2, 1, 2, 2, 3, 22, 2] >>> lst = lst + lst >>> lst [1, 2, 2, 3, 22, 2, 1, 2, 2, 3, 22, 2] # 2 >>> lst.extend(lst) >>> lst [1, 2, 2, 3, 22, 2, 1, 2, 2, 3, 22, 2] # 3 >>> lst = [1,2,2,3,22,2] >>> [*lst,*lst] [1, 2, 2, 3, 22, 2, 1, 2, 2, 3, 22, 2] >>> [*lst,lst] [1, 2, 2, 3, 22, 2, [1, 2, 2, 3, 22, 2]]
Разность (Удаление)
Разность массивов (находим значения, которые уникальны в первом массиве относительно второго):
a = [2, 3, 555] b = [3, 9, 777] a_b_set = set(a) - set(b) # в выводе то, что отличается в A от B a_b_set2 = set(b) - set(a) a_b_diff = set(a).difference(set(b)) # полность аналогично a_b_diff_symmetric = set(a).symmetric_difference(set(b)) # альтернативный способ (требует a и b в виде множеств), разница с вышестоящим, что выдает все различающиеся значения между массивами, а не только то, что отличается A от B без чета того, что B отличает от A print(f"a_b_set:{a_b_set}") print(f"a_b_diff:{a_b_diff}") print(f"a_b_diff_symmetric:{a_b_diff_symmetric}") >>> a_b_set:{2, 555} a_b_set2:{9, 777} a_b_diff:{2, 555} a_b_diff_symmetric:{2, 9, 777, 555}
Пересечение
Пересечение массивов (находим значения, которые есть в обоих массивах):
a = [2, 3, 555]
b = [3, 9, 777]
a_b_set = set(a) & set(b)
a_b_intersection = set(a).intersection(set(b)) # полностью аналогично
>>>
a_b_set:{3}
a_b_intersection:{3}
Проверка на то что одно (меньшее) множество является частью другого (равного или большего) множества с помощью issubset.
Issubset() — метод в Python, который проверяет, является ли одно множество подмножеством другого.
Если все элементы первого множества присутствуют во втором, метод возвращает True, в противном случае — False.
>>> print({1,2,3}.issubset({1,2,3,4,5}))
True
>>>
>>>
>>> print({1,2,3}.issubset({1,2,2,4,5}))
False
умножение
Для генерации списков, состоящих строго из повторяющихся элементов, умножение на число — самый короткий и правильный метод.
>>> [7, 8] * 3 [7, 8, 7, 8, 7, 8] >>> [0] * 10 [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] >>> a = [1,2,3] >>> a*=5 >>> a [1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3] >>> [[1,2,3]]*3 [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
LOOP (WHILE TRUE)
while True: ...
Пример использования: инициализируем подключение по SSH,
- если подключились – выходим из цикла “подключений”,
- если exception (напр. timeout), то ждем какое-то время и пытаемся еще раз. Полезно для того, чтобы не ждать фиксированное время перезагрузки устройства, а подключаться как только устройство готово принять подключение.
while True:
try:
ssh = SshControl(params)
break
except:
time.sleep(ssh_timeout) # ожидание между попытками подключения по SSH
Split
Описывал выше.
Join
Преобразует массив в строку. Что интересно, join – строковой метод, применяется на строку, но в качестве аргумента использует массив. Работает метод только со списком строк.
delim = "%" arg_str = delim.join(sys.argv[1:]) >>> lst = ["1","2","3"] >>> "*".join(lst) '1*2*3' >>> lst = [1,2,3] >>> "*".join(lst) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: sequence item 0: expected str instance, int found
join не обязательно через переменную указывать, можно непосредственно строку.
>>> L ['a', 'b', 'c'] >>> ''.join(L) 'abc' data_list = "\n".join(L)
Slice/срезы
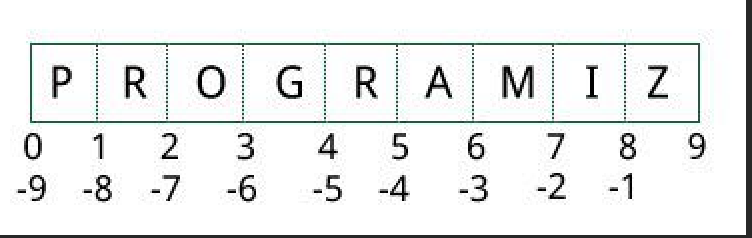
- При построении среза s[x:y] первое число – это то место, где начинается срез (включительно), а второе – это место, где заканчивается срез (не включительно).
- При использовании срезов со списками мы также можем опускать второй параметр в срезе
numbers[x:](но поставить двоеточие), тогда срез берется до конца списка. Аналогично если опустить первый параметрnumbers[:y], то можно взять срез от начала списка. - С использованием slice (и в целом позиционных индексов) можно не только получать элементы, но и удалять/подменять
>>> a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] >>> a.pop(-1) 10 >>> a [1, 2, 3, 4, 5, 6, 7, 8, 9] >>> a=[1,2,3,4,5,6,7,8,9,10] >>> del a[1:4] >>> a [1, 5, 6, 7, 8, 9, 10] >>> a=[1,2,3,4,5,6,7,8,9,10] >>> a[0:2]=[99,100] >>> a [99, 100, 3, 4, 5, 6, 7, 8, 9, 10]
- Использование индексов в Slice не приведет к exception типа Index out of range:
- если end индекс превышает предел – end будет по сути подменен на последний индекс
- если start индекс превышает предел – вернется нулевой массив
Python slicing means to access a subsequence of a sequence type using the notation [start:end]. A little-known feature of slicing is that it has robust end indices. Slicing is robust even if the end index is greater than the maximal sequence index. The slice just takes all elements up to the maximal element. If the start index is out of bounds as well, it returns the empty slice.
Получаем от элемента (строки/массива) до элемента, но не включая. Например: получаем первые пять элементов массива (или букв строки). Применений множество.
arr[0:5] # первые пять элементов массива (с нулевого по четвертый) arr[:5] # первые пять элементов массива (сокращение) s[5:] # с пятого элемента до конца s[-3:] # последние 3 элемента s[:] # копия списка, часто очень полезно s[::-1] # перевернутый список s[1:] # все элементы кроме первого (полезно при получении аргументов и ARGV для исключения названия скрипта) s[2:-2] # откидываем первые и последние 2 s[::2] # парные элементы s[1:4:2] # элементы с первого по четвертый с шагом 2
С помощью срезов так же можно изменять изменяемые элементы (напр. списки, но не строки и кортежи). В том числе диапазоны значений.
fruits = ['apple', 'apricot', 'banana', 'cherry', 'kiwi', 'lemon', 'mango'] fruits[2:5] = ['банан', 'вишня', 'киви'] >>> ['apple', 'apricot', 'банан', 'вишня', 'киви', 'lemon', 'mango']
Iteration/Итерация/итерирование
- В программировании для переменных цикла обычно используют буквы
i, j, k. Почему для переменной циклов зарезервированы буквыi, j, k? Дело в том, что раньше программы использовались для математических расчетов, а в математике буквыa, b, cиx, y, zуже зарезервированы для других целей. Поэтому программисты выбрали для этой цели переменныеi, j, k, и это стало общепринятой практикой. - Бывают ситуации, когда переменная цикла не используется в теле цикла. В таком случае, вместо того, чтобы давать ей имя, указывайте вместо нее символ нижнего подчеркивания
_.
for _ in range(5):
print('Python - awesome!')Итерирование работает с итерируемыми (iterable) объектами. Внутри в базовом сценарии (for до окончания элементов) это процесс последовательных next, next, next на один итерируемый объект до exception (StopIteration).
l = [3,4,7,9] i = iter(l) print(next(i)) print(next(i)) print(next(i)) print(next(i)) print(next(i)) 3 4 7 9 Traceback (most recent call last): File "/home/redkin_p/bin/test.py", line 11, in <module> print(next(i)) StopIteration
Без индекса
for sw in sw_list:
print(sw)
Итерация с индексом или значением ключа dictionary (по умолчанию при итерации словаря берутся только ключи) на основе:
- enumerate – создает список кортежей кортеж/tuple – номер (key), значение (value); можно поменять стартовое значение с 0 на кастомное; enumerate полезно использовать для route-map, EEM скриптов, там, где нужно создавать некую последовательность. Под капотом это отдельный класс enumerate (выясняется type на объект).
- items – по сути enumerate для dict(). items создает список кортежей кортеж/tuple вида key, value. Под капотом это отдельный класс dict_items (выясняется type на объект).
for n,e in enumerate(interfaces): print(n) 0 str1 1 str2 2 str3 for n,e in enumerate(interfaces, 1): print(n) 1 str1 2 str2 3 str3
# two iteration variables (key and value) for dictionary (default only key) for key, value in d.items():
С помощью range можно легко итерироваться, создавать последовательности (см. генераторы). При указании range одного аргумента оно используется в качестве stop, а в качестве start используется 0, так же можно указать start value и шаг. Причем функция хранит только эти значения, а промежуточные вычисляются -> независимо от размера диапазона он будет занимать фиксированный объем памяти. Совместно с range удобно использовать функцию in – можно проверить, есть ли значение в диапазоне. Так же из range можно получать значения элементов, как будто это список, рассчитывать длину диапазона с помощью len, делать slice. Чтобы реализовать обратную последовательность нужно на range применить функцию reversed или использовать опцию задания шага (шаг -1).
| Вызов функции | Последовательность чисел |
|---|---|
range(10) |
0, 1, 2, 3, 4, 5, 6, 7, 8, 9 |
range(1, 10) |
1, 2, 3, 4, 5, 6, 7, 8, 9 |
range(3, 7) |
3, 4, 5, 6 |
range(7, 3) |
пустая последовательность |
range(2, 15, 3) |
2, 5, 8, 11, 14 |
range(9, 2, -1) |
9, 8, 7, 6, 5, 4, 3 |
range(3, 10, -2) |
пустая последовательность |
>>> for i in range(5): ... print(i) ... 0 1 2 3 4 >>> list(range(6,16)) [6, 7, 8, 9, 10, 11, 12, 13, 14, 15] >>> list(range(3)) [0, 1, 2] >> r1 = range(10) >> r2 = range(5,10) >> r3 = range(4,10,2) >> print(list(r1)) >> print(list(r2)) >> print(list(r3)) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [5, 6, 7, 8, 9] [4, 6, 8] >> print(10 in range(11)) True >> print(range(10)[9]) 9 >> print(range(10)[0]) 0 >> print(len(range(10))) 10 >> print(range(10)[0:5]) range(0, 5)
С помощью range можно создать цифровой словарь (предположим, для bruteforce). Например код ниже создает 8-digit dictionary. В коде сделан костыль для добавления в словарь чисел с leading zero 00000000 – 09999999.
for i in range(100000000):
if (len(str(i))) == 8:
if str(i)[0] == "1":
zero_list = list(str(i))
zero_list[0] = "0"
zero_int = str("".join(zero_list))
print(zero_int)
print(i)
for i in range(5, 0, -1):
print(i, end=' ')
print('Взлетаем!!!')all – выдает True если все элементы True или элемент пустой – последнее довольно нелогично т.к. пустой объект по умолчанию False (можно проверить функцией bool).
print(all([True, True, False])) print(all([True, True, True])) print(all([])) print(bool([])) False True True False
any – выдает True если любой элемент True. При этом нулевой элемент считается False, что доставляет (с учетом вышестоящего).
print(any([True, True, False])) print(any([True, True, True])) print(any([])) True True False
append – добавление элемента в конец списка
# Одного
sw_list_with_hostname = []
for sw in sw_list:
sw_list_with_hostname.append(sw)
# Нескольких (через вложенный массив)
sw_list_with_hostname = []
for sw in sw_list:
sw_list_with_hostname.append([sw, hostname])
extend – добавление нескольких элементов в конец списка (не вложенного массива в виде одного элемента, как сделает append), особенность поэлементной работы extend особенно видна при его использовании со строкой – каждый символ строки будет добавлен в целевой список отдельно.
>>> var2
[3, 2, 444, 555, 666]
>>> var2.append(777,888,999)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: append() takes exactly one argument (3 given)
>>> var2
[3, 2, 555, 666, [777, 888, 999]]
>>> var2.extend([777,888,999])
>>> var2
[3, 2, 555, 666, [777, 888, 999], 777, 888, 999]
>>> a = [1,2,3]
>>> a.extend("abc")
>>> a
[1, 2, 3, 'a', 'b', 'c']
>>> a.append("abc")
>>> a
[1, 2, 3, 'a', 'b', 'c', 'abc']
insert – добавление элемента (444) на определенную позицию (2) (не в конец)
>>> var2 [3, 2, 555, 666] >>> var2.insert(2,444) >>> var2 [3, 2, 444, 555, 666]
pop – удаление последнего элемента или произвольного элемента по id
>>> var2 [3, 2, 555, 666, [777, 888, 999], 777, 888, 999] >>> var2.pop() 999 >>> var2 [3, 2, 555, 666, [777, 888, 999], 777, 888] >>> var2.pop(3) 666 >>> var2 [3, 2, 555, [777, 888, 999], 777, 888]
remove – удаление элемента по значению (удаляется первый подпавший элемент)
>>> var2 [3, 2, 555, [777, 888, 999], 777, 888] >>> var2.remove(777) >>> var2 [3, 2, 555, [777, 888, 999], 888]
filter – фильтрация массива в новый урезанный массив по заданному условию. К примеру, ищем строки, которые можно интерпретировать как число. Работает это через генераторы (см. поиском по select).
>>> a = ["a", "b", "1", "6"] >>> list(filter(str.isdigit, a)) ['1', '6']
** – распаковка – удобный способ вывода элементов списка ((по факту итерирруемого объекта – в том числе строки)) без использования цикла for.
>>> print([1,2,3])
[1, 2, 3]
>>> print(*[1,2,3])
1 2 3
>>> print(*[1,2,3], sep="\n")
1
2
3
>>> print("abc")
abc
>>> print(*"abc")
a b c
>>> print(*"abc", sep="\n")
a
b
c
Поиск элементов
Самый простой способ:
7 in a # 7 in array?
Можно так же в dictionary (hash/assoc array) по ключу, что зачастую удобно (хотя конкретно для задачи подсчета при возможности лучше использовать collections counter):
if name in names: names[name] = names[name] + 1 else: names[name] = 1
Пример
# берем большой файл, кладем его в массив (каждая строка как элемент]), ищем в каждом элементе определенный паттерн, выдергиваем из подпавших строк последний столбец (последний элемент каждого массива) и помещаем его в новый массив
# bad one-liner read (see above)
data_list = open('/home/redkin_p/ORANGE').read().split("\n")
data_list = list(x for x in data_list if "DGS-3620" in x)
ip_list = []
for s in data_list:
ip_list.append(s.split("\t")[-1].replace(" ", ""))
print(ip_list)
collections
Аналог sort | uniq –c (количество уникальных объектов)
from collections import Counter
a = [ 'a', 'a', 'b', 'b', 'b' ]
c = Counter(a)
print(c)
>> Counter({'b': 3, 'a': 2})
sorted, sort
sorted – сортировка list (array), более универсальная в сравнении с sort альтернатива, работает не только с list, а с любым итерируемым (iterable) объектом. Не изменяет исходный list, в отличии, опять же, от sort. Кроме того, sorted можно использовать на многомерный массив. Сортировка по умолчанию будет по первому элементу в каждом массиве, но этим можно управлять, например, с помощью использования ключевого аргумента key + itemgetter или с помощью key + lambda.
sort – сортировка list (array), работает только с list, изменяет исходный list, из плюса метод менее накладной по памяти (time complexity).
flist.sort() sorted(flist) >>> a = [14,1,4,55,91,5] >>> sorted(a) [1, 4, 5, 14, 55, 91] >>> >>> a [14, 1, 4, 55, 91, 5] >>> >>> a.sort() >>> a [1, 4, 5, 14, 55, 91]
arr = [ [1, 22, 55], [7, 11, 34], [2, 111, 23], [31, 11, 24] ] print(sorted(arr)) [[1, 22, 55], [2, 111, 23], [7, 11, 34], [31, 11, 24]]
import operator <same_array> print(sorted(arr, key=operator.itemgetter(1))) [[7, 11, 34], [31, 11, 24], [1, 22, 55], [2, 111, 23]]
>>> print(sorted(arr, key=lambda x: x[1])) [[7, 11, 34], [31, 11, 24], [1, 22, 55], [2, 111, 23]]
через равно sort делать не надо, будет ошибка; sorted можно
flist = flist.sort() TypeError: 'NoneType' object is not iterable flist = sorted(flist)
reverse с помощью sort (безусловно можно и с sorted)
flist.reverse() flist.sort(reverse=True) sorted(flist, reverse=True)
Сортировка dictionary (hash, assoc array)
по значению (аналогичное можно и с помощью itemgetter)
names = {}
sorted_x = sorted(names.items(), key=lambda kv: kv[1])
по ключу (аналогичное можно и с помощью itemgetter)
names = {}
sorted_x = sorted(names.items(), key=lambda kv: kv[0])
lambda functions
lambda – это по сути однострочный эквивалент функции (типа генераторов), поэтому их называют анонимные функции (small anonymous function). Зачастую достаточно удобно, чаще всего используются когда по какой то причине недостаточно функционала чистого list comprehension и его нужно дообогатить функционалом.
# general def sum(a,b): return a+b # lambda lambda a, b: a+b # equal
decorators (декораторы)
Это возможность расширения или изменения существующих классов/методов. Примеры использования есть тут же в статье: execution timeout, dataclass.
Сортировки
- Пузырьковая сортировка в python (bubble sort)
- Быстрая сортировка на основе рекурсии (quick sort)
- Сортировка рекурсивным слиянием (merge sort; recursive sorting algorithm) с двоичным делением
sortedcontainers (SortedList, SortedSet,Sorteddict)
Модуль, позволяющий создавать итерируемые объекты, сохраняющие сортировку (возможны как int, так и str элементы в массиве), сортировка сохраняется после добавления и удаления элементов. Поддерживаются так же разные другие методы работы с массивами, включая напр. bisect.
pip3 install sortedcontainers from sortedcontainers import SortedList a = SortedList([7,4,12,3,1,1.9,2,2,2.1,3,5,6]) print(a) a.add(300) a.discard(1.9) print(a) print(a.bisect_right(2)) print(a.bisect_left(2)) >>> SortedList([1, 1.9, 2, 2, 2.1, 3, 3, 4, 5, 6, 7, 12]) SortedList([1, 2, 2, 2.1, 3, 3, 4, 5, 6, 7, 12, 300]) 3 1
Еще пример от яндекса – кратко рейтинги участников, возврат лучших работ по лайкам. Задача расписана в двух статьях т.к. представляет интерес как с точки зрения статьи Coding: Python заметки, так и с точки зрения статьи Алгориртмы и структуры данных, оценка сложности алгоритмов (асимптотическая оценка, оценка Big O)
Решение на базе сортировки:
-
- get_best_works – сама задача по возврату лучших работ решается той же сортировкой, только реализуемой на базе специальной структуры, которая поддерживает сортировку элементов SortedList/SortedSet и вывод через slice нужного количества последних элементов, имеющих наибольшее количество Like. Сложность O(K) по сложности slice в SortedSet.
- (dis)like – O(logN) по сложности операций add, remove
from sortedcontainers import SortedSet
class Competition:
def __init__(self, participant_count):
self._scores = [0] * participant_count
initial_frequencies = [(0, id) for id in range(participant_count)]
self._ordered_works = SortedSet(initial_frequencies)
def _change_score(self, participant_id, change):
old_participant_stat = (self._scores[participant_id], participant_id)
self._ordered_works.remove(old_participant_stat)
self._scores[participant_id] += change
new_participant_stat = (self._scores[participant_id], participant_id)
self._ordered_works.add(new_participant_stat)
def like(self, participant_id):
self._change_score(participant_id, 1)
def dislike(self, participant_id):
self._change_score(participant_id, -1)
def get_best_works(self, count):
return [id for (_, id) in self._ordered_works[-count:][::-1]]
Binary search, дихотомия, bisect
Стандартные функции bisect_left, bisect_right осуществляют поиск индекса элемента в заведомо отсортирорванный массив с учетом сохранения сортировки. Left от Right отличается положением индекса, которое получит элемент при наличии совпадений по value в существующем массиве.
import bisect a = [1,1.9,2,2,2.1,3,5,6] print(bisect.bisect_right(a, 2)) print(bisect.bisect_left(a, 2)) >>> 4 2
Python dictionary (key-value store: hash, associative array, property bag)
Python dictionary – наиболее “powerful” memory collection в стандартной библиотеке Python. По сути это key-value store, который реализован в большинстве ЯП (примеры в header). Такое хранилище позволяет создавать простую in-memory “database” в одной переменной.
Ключем dictionary чаще всего является строка, но если говорить в целом ключем dictionary может быть любой хешируемый объект, это можно увидеть, попытавшись сделать ключ в виде list. Принято использовать неизменяемые (immutable) хешируемые (hashable) объекты, содержимое которых не изменит свой hash т.к. все операции “внутри” по ключу происходят именно по hash, но если месье любит боль, то можно использовать и изменяемую, но хешируемую сущность (напр. объекты у которых есть метод hash) и при ее изменении (с последующим изменением hash) получить exception.
Создание
# базовое применение, ключ str
a = {"id": 1, "name":"Sesame Street"}
a = dict(id=1, name="Sesame Street")
#
>>> a = {[1,2]: 1, "name":"Sesame Street"}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
# на основе массива, не использовать если значение будет arr - иначе arr будет единый для всех ключей (не уникален т.к. ссылка на один участок памяти) - подробнее в примере. В таком случае лучше использовать генератор (по аналоги с list).
>>> arr = [1,2,3]
>>> dict.fromkeys(arr)
{1: None, 2: None, 3: None}
>>> dict.fromkeys(arr, "some_data")
{1: 'some_data', 2: 'some_data', 3: 'some_data'}
# пример почему не стоит использовать массив в качестве value при создании с помощью fromkeys
>>> dct = dict.fromkeys(arr, "some_data")
>>> dct
{1: 'some_data', 2: 'some_data', 3: 'some_data'}
>>> dct[1] = "some_new_data"
>>> dct
{1: 'some_new_data', 2: 'some_data', 3: 'some_data'}
>>>
>>> dct = dict.fromkeys(arr, [1])
>>> dct
{1: [1], 2: [1], 3: [1]}
>>> dct[1].append(555)
>>> dct
{1: [1, 555], 2: [1, 555], 3: [1, 555]}
Добавление элемента
a["id"] = 1
Update – Обновление элемента/элементов (или добавление нового, если такого элемента нет; append for dict), можно обновить сразу группу элементов
a.update({'some_key': 555})
a.update({"some_key": "x-value",
"some_key2": False,
"some_key3": True })
Del – Удаление элемента. При работе со списком так же можно удалить срезом/slice.
>>> a = {"id": 1, "name":"Sesame Street"}
>>> a
{'id': 1, 'name': 'Sesame Street'}
>>> del a["id"]
>>> a
{'name': 'Sesame Street'}
>>> a = [1,2,3,4,5]
>>> del a[0:3]
>>> a
[4, 5]
Получение значения элемента по ключу.
>>> a["name"] 'Sesame Street'
При отсутствии ключа и потенциальной возможности запроса по несуществующему ключу нужно или использовать try except или использовать метод get (возвращает None при отсутствии элемента или заданное во второй переменной к методу значение), в противном случае будет exception. Еще одной безусловной альтернативой (но хуже get – он по сути делает тоже самое без if) является использование in совместно с if – с помощью in мы сможем посмотреть есть ли ключ в словаре (пример выше).
The pattern of checking to see if a key is already in a dictionary and assuming a default value if the key is not there so common that there is a method called get() that does this for us.
>>> a["location"]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'location'
>>> a.get("location")
>>> a.get("location", "some_val")
'some_val'
# dynamic error messages by codes example
error_codes = {
1: "Общая ошибка",
2: "Ошибка синтаксиса команд",
100: "Элемент не найден",
}
error_msg = error_codes.get(result.returncode, f"Неизвестная ошибка ({result.returncode})")
Очень удобно функцию get использовать при инициализации dictionary, со счетчиком срабатываний элемента. Не нужно расссматривать специальный случай обращения по ключу к отсутствующему элементу (как описано выше). Если же говорить о лучшем способе решения конкретной задачи histogram, то я бы использовал collections counter (см. поиском).
# simple histogram without if-else
counts = dict()
items = [1,2,2,3,1,1]
for item in items:
counts[item] = counts.get(item, 0) + 1
print(counts)
~$ test.py
{1: 3, 2: 2, 3: 1}
Удобное использование get в conditions (если нет нужных элементов):
i _r.get('type', True) and _r.get('version', True):
Так же в таком случае возможно использование:
- структуры defaultdict. В случае наличия ключа она возвращает его значение, при отсутствии ключа создает его с значением типа по умолчанию.
defaultdict means that if a key is not found in the dictionary, then instead of a KeyError being thrown, a new entry is created. The type of this new entry is given by the argument of defaultdict.
from collections import defaultdict
somedict = {}
print(somedict[3]) # KeyError
someddict = defaultdict(int)
print(someddict[3]) # print int(), thus 0
- функции setdefault. В случае наличия ключа она возвращает его значение, при отсутствии ключа создает его с значением по умолчанию None. В аргументах None можно изменить на что-то конкретное.
>>> a.setdefault("location")
>>> a
{'id': 1, 'name': 'Sesame Street', 'location': None}
>>> a.setdefault("name")
'Sesame Street'
>>> a
{'id': 1, 'name': 'Sesame Street', 'location': None}
>>> a.setdefault("location2", "some_loc")
'some_loc'
>>> a
{'id': 1, 'name': 'Sesame Street', 'location': None, 'location2': 'some_loc'}
Методами keys, values, items можно получить/преобразовать данные исходного словаря в списки. При использовании этих методов нужно учитывать, что при изменении исходного словаря изменятся и значения в соответствии с ним. Для защиты от этого результат метода можно преобразовывать в list или работать с копией массива (использовать deepcopy).
>>> a
{'id': 1, 'name': 'Sesame Street', 'location': None, 'location2': 'some_loc'}
>>> a.keys()
dict_keys(['id', 'name', 'location', 'location2'])
>>> a["new_id"] = 2
>>> a.keys()
dict_keys(['id', 'name', 'location', 'location2', 'new_id'])
>>> b = list(a.keys())
>>> a["new_new_id"] = 2
>>> list(a.keys())
['id', 'name', 'location', 'location2', 'new_id', 'new_new_id']
>>> b
['id', 'name', 'location', 'location2', 'new_id']
keys – получить все ключи.
>>> a
{'id': 1, 'name': 'Sesame Street', 'location': None, 'location2': 'some_loc'}
>>> a.keys()
dict_keys(['id', 'name', 'location', 'location2'])
values – получить все значения. Очень удобно использовать values для поиска по значениям “value” in <dictionary>.values()
>>> a.values() dict_values([1, 'Sesame Street', None, 'some_loc'])
items – преобразовать словарь в список кортежей.
>>> a.items()
dict_items([('id', 1), ('name', 'Sesame Street'), ('location', None), ('location2', 'some_loc')])
update – 1) обновляем значения ключей при наличии ключей в существующем массиве 2) создаем пары ключ-значение при отсутствии ключа в существующем массиве
>>> a = {'id': 1, 'name': 'Sesame Street', 'location': None}
>>> a
{'id': 1, 'name': 'Sesame Street', 'location': None}
>>> b = {'id':2, 'password':123456}
>>> a.update(b)
>>> a
{'id': 2, 'name': 'Sesame Street', 'location': None, 'password': 123456}
Python set (множества)
Содержит уникальные значения. Часто используется для задач слияния/разности массивов.
>>> set('tetst')
{'e', 's', 't'}
>>> set([1,2,"ha",2,3,1])
{1, 2, 3, 'ha'}
Для множеств есть аналогичные list методы только с другими названиями (помимо discard есть remove, discard не формирует exception при out of range).
>>> s1 = {1,3,5,7}
>>> type(s1)
<class 'set'>
>>> s1.add(9)
>>> s1
{1, 3, 5, 7, 9}
>>> s1.discard(3)
>>> s1
{1, 5, 7, 9}
>>> s1.discard(3) # нет exception в случае отсутствия значения в множестве
Как и в случае с кортежами/словарями из списка/кортежа/словаря можно получить множество и наоборот. Это свойство может использоваться для чистки дублей в списке – преобразовываем его во множество, а потом обратно в список.
>>> s1
{1, 5, 7, 9}
>>> list(s1)
[1, 5, 7, 9]
>>> a1
[1, 2, 3]
>>> set(a1)
{1, 2, 3}
>>> a1
[1, 2, 3, 1, 2, 3, 3, 3, 5, 1]
>>> set(a1)
{1, 2, 3, 5}
>>> list(set(a1))
[1, 2, 3, 5]
Нельзя обращаться по индексу к set т.к. в set не сохраняется позиция элемента. Обходим через list(set).
res_set = set(res_arr) print(res_set[0]) TypeError: 'set' object is not subscriptable uniq_res_arr = list(set(res_arr)) print(uniq_res_arr[0])
Thread
Про многопроцессность/асинхронность и gil/race conditions можно почитать ниже поиском. Многопоточность можно запустить очень просто
from multiprocessing.dummy import Pool as ThreadPool
def query_data(ip):
print(ip)
pool = ThreadPool(10) # количество потоков
pool.map(query_data, sw_list) # запускаем функцию query_data и передаем ей на входе массив sw_list
Если аргументов в функцию нужно передать несколько, можно создать двумерный массив и далее:
1) передать его starmap вместо одномерного и наслаждаться стандартной функцией (starmap требует python версии как минимум 3.3 иначе будет ошибка AttributeError: ‘ThreadPool’ object has no attribute ‘starmap’)
from multiprocessing.dummy import Pool as ThreadPool
def query_data(ip, hostname):
print(ip, hostname)
pool = ThreadPool(10) # количество потоков
sw_list_with_hostname = [] # создаем новый массив вида [[ip, hostname], [ip2, hostname]]
pool.starmap(query_data, sw_list_with_hostname) # запускаем функцию query_data и передаем ей на входе массив sw_list_with_hostname
Пример простейшего создания нового массива для многопоточной обработки:
ip_list = [] for ip in ip_list: ip_list.append([ip, <var2>, <var3>])
2) передать его pool.map вместо одномерного и разбирать на входе функции (менее удобно)
from multiprocessing.dummy import Pool as ThreadPool
def query_data(data):
ip = data[0]
hostname = data[1]
print(ip)
pool = ThreadPool(10) # количество потоков
sw_list_with_hostname = [] # создаем новый массив вида [[ip, hostname], [ip2, hostname]]
pool.map(query_data, sw_list_with_hostname) # запускаем функцию query_data и передаем ей на входе массив sw_list_with_hostname
Генератор и итератор чем отличаются (частый вопрос на собесах)
Генератор и итератор чем отличаются – You may want to use a custom iterator, rather than a generator, when you need a class with somewhat complex state-maintaining behavior, or want to expose other methods besides __next__ (and __iter__ and __init__) or you need to extend a Python object as an object that can be iterated over. Most often, a generator (sometimes, for sufficiently simple needs, a generator expression) is sufficient, and it’s simpler to code because state maintenance (within reasonable limits) is basically “done for you” by the frame getting suspended and resumed – in the vast majority of cases, you are best suited to use yield to define a function that returns a Generator Iterator or consider Generator Expressions.
-
- итератор – более широкий термин, по сути итератор это класс для объекта который реализует dunder методы iter и next и по нему мы моем итерироваться в for loop или вызовом метода next пока он не поднимет stop iteration
- The __iter__ method is called when you attempt to use an object with a for-loop. Then the __next__ method is called on the iterator object to get each item out for the loop. The iterator raises StopIteration when you have exhausted it, and it cannot be reused at that point.
- An Iterator is a subtype of Iterable
- Iterator
- requires an __iter__ method that returns an Iterator
- require a next or __next__ method
- итератор – более широкий термин, по сути итератор это класс для объекта который реализует dunder методы iter и next и по нему мы моем итерироваться в for loop или вызовом метода next пока он не поднимет stop iteration
>>> issubclass(collections.Iterator, collections.Iterable)
True
### iterator example
class Squares(object):
def __init__(self, start, stop):
self.start = start
self.stop = stop
def __iter__(self):
return self
def __next__(self): # next in Python 2
if self.start >= self.stop:
raise StopIteration
current = self.start * self.start
self.start += 1
return current
iterator = Squares(a, b)
-
- генератор – подтип итератора, по сути синтаксический сахар над реализацией итератора, значительно уменьшающий количество строк кода/упрощающий чтение кода. Генератор создается с помощью функции с использованием ключевого слова yield. Yield это аналог return – когда код доходит до yield он прекращает свою работу и возвращает результат, отличие yield в том, что следующий вызов функции произойдет с того момента, когда он был завершен (с последнего yield т.е. с сохранением последнего места исполнения состояния) до того момента, когда не произойдет exception stopiteration (см. пример ниже generator easy example) или даже вообще никогда (см. пример ниже generator loop). Очень полезно использовать при большом переборе (напр. загружаем много данных из базы) т.к. ни в какой момент времени не приходится использовать много памяти – после yield предыдущее значение из памяти стирается и подменяет новым, это под капотом делает цикл for.
- generator is a subtype of iterator
- Python’s generators provide a convenient way to implement the iterator protocol.
- If a container object’s __iter__() method is implemented as a generator, it will automatically return an iterator object (technically, a generator object) supplying the __iter__() and next() [__next__() in Python 3] methods.
- We can create a generator several ways. A very common and simple way to do so is with a function. Specifically, a function with yield in it is a function, that, when called, returns a generator.
- С помощью Send можно изменять исполнение функции с yield в зависимости от этих передаваемых событий/переменных (см. в примере ниже generator + send). По похожему принципу реализована асинхронность.
- генератор – подтип итератора, по сути синтаксический сахар над реализацией итератора, значительно уменьшающий количество строк кода/упрощающий чтение кода. Генератор создается с помощью функции с использованием ключевого слова yield. Yield это аналог return – когда код доходит до yield он прекращает свою работу и возвращает результат, отличие yield в том, что следующий вызов функции произойдет с того момента, когда он был завершен (с последнего yield т.е. с сохранением последнего места исполнения состояния) до того момента, когда не произойдет exception stopiteration (см. пример ниже generator easy example) или даже вообще никогда (см. пример ниже generator loop). Очень полезно использовать при большом переборе (напр. загружаем много данных из базы) т.к. ни в какой момент времени не приходится использовать много памяти – после yield предыдущее значение из памяти стирается и подменяет новым, это под капотом делает цикл for.
# class
>>> import collections, types
>>> issubclass(types.GeneratorType, collections.Iterator)
True
>>> def a_function():
"just a function definition with yield in it"
yield
>>> type(a_function)
<class 'function'>
>>> a_generator = a_function() # when called
>>> type(a_generator) # returns a generator
<class 'generator'>
>>> isinstance(a_generator, collections.Iterator)
True
# generator easy example
>>> def simple_gen():
... for n in range(3):
... yield n
...
>>> a = simple_gen() # создаем объект функции
>>> next(a) # переходим на следующий шаг
0
>>> next(a)
1
>>> next(a)
2
>>> next(a)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
>>> type(a)
<class 'generator'>
# аналог с созданием итератора
>>> a = iter([0,1,2])
>>> next(a)
0
>>> type(a)
<class 'list_iterator'>
# использование генератора в for
>>> for a in simple_gen():
... print(a)
...
0
1
2
# generator loop
>>> def simple_gen():
... print("Started")
... while True:
... print("I'm in loop")
... yield 1
... yield 2
...
>>> a = simple_gen()
>>> next(a)
Started
I'm in loop
1
>>> next(a)
2
>>> next(a)
I'm in loop
1
>>> next(a)
2
>>> def yieldvar():
... while True:
... x = yield
... print(x)
...
>>> a = yieldvar()
>>> next(a)
>>> next(a)
None
>>> next(a)
None
>>> a.send("test")
test
>>> a.send("test2")
test2
>>> next(a)
None
# generator example ((аналог на базе итератора выше))
def squares(start, stop):
for i in range(start, stop):
yield i * i
generator = squares(a, b)
# generator example 2 ((аналог на базе итератора выше))
generator = (i*i for i in range(a, b))
Sleep
import time time.sleep(1)
Sleep функция с print счетчиком countdown в одной строке на основе. Работает и для Python 3 и для Python 2 (2.7).
# python3 ./test.py
[*] sleep to get some data... 10 9 8 7 6 5 4 3 2 1
/test.py
import sys
import time
def sleep(sleep_interval, reason=""):
sys.stdout.write("[*] sleep{}... ".format(reason))
for i in range(sleep_interval,0,-1):
sys.stdout.write(str(i)+' ')
sys.stdout.flush()
time.sleep(1)
print("")
sleep(10, " to get some data")
ARGV
Получаем данные из системных переменных в виде array – путь к исполняемому файлу (всегда в argv[0]) и далее опционально (что передали) – имена файлов, адреса (IP, mail, url), все что угодно.
import sys print(sys.argv) print(sys.argv[1]) quit()
Определяем название исполняемого файла без использования argv и полного пути к файлу.
print(os.path.basename(__file__))
Для этой задачи можно так же использовать argparse (есть и другие альтернативы) – позволит сделать аналогию linux утилитам.
python ping_function.py -a 8.8.8.8 -c 5
import argparse
args = argparse.ArgumentParser()
args.add_argument( '-v', '--version', action='store_true' )
args.add_argument( '-d', '--debug', action='store_true' )
if not isinstance(ip, dict):
raise argparse.ArgumentTypeError('Dictionary is expected.')
$ python ping_function.py usage: ping_function.py [-h] -a IP [-c COUNT] ping_function.py: error: the following arguments are required: -a
$ python ping_function.py -h usage: ping_function.py [-h] -a IP [-c COUNT] Ping script optional arguments: -h, --help show this help message and exit -a IP -c COUNT
PSUTIL, OS
Работа с системными процессами из python.
Получить все процессы.
pip3 install psutil import psutil psutil.pids()
Проверка на то, что другой instance исполняемого скрипта не исполняется в системе.
# проверяем, что не запущены какие то другие процессы исполняемого скрипта
current_script_name = os.path.basename(__file__)
current_scipt_pid = os.getpid()
for p in psutil.process_iter():
cmdline = p.cmdline()
if len(cmdline) > 1 and "python3" == cmdline[0] and current_script_name in cmdline[1] and current_scipt_pid != p.pid:
print(f"Error: Another {current_script_name} script with PID {p.pid} detected!")
Проверка на то, что процесс существует в системе по PID.
import os
def check_pid(pid):
""" Check For the existence of a unix pid. """
try:
os.kill(pid, 0)
return True
except OSError:
return False
Получить cmdline Linux процесса без psutil.
def get_pid_cmdline(pid):
""" Get unix pid cmdline. """
try:
cmdline = open(f"/proc/{pid}/cmdline").read()
return cmdline
except OSError:
return ""
Смотрим сессии в текущем VRF. Пример скрипта для вывода информации в формате “netstat/ss”.
psutil.net_connections # default format [sconn(fd=3, family=<AddressFamily.AF_INET: 2>, type=<SocketKind.SOCK_STREAM: 1>, laddr=addr(ip='0.0.0.0', port=80), r addr=(), status='LISTEN', pid=1484)] # netstat script import socket from socket import AF_INET, SOCK_STREAM, SOCK_DGRAM import psutil AD = "-" AF_INET6 = getattr(socket, 'AF_INET6', object()) proto_map = { (AF_INET, SOCK_STREAM): 'tcp', (AF_INET6, SOCK_STREAM): 'tcp6', (AF_INET, SOCK_DGRAM): 'udp', (AF_INET6, SOCK_DGRAM): 'udp6', } def main(): templ = "%-5s %-30s %-30s %-13s %-6s %s" print(templ % ( "Proto", "Local address", "Remote address", "Status", "PID", "Program name")) proc_names = {} for p in psutil.process_iter(['pid', 'name']): proc_names[p.info['pid']] = p.info['name'] for c in psutil.net_connections(kind='inet'): laddr = "%s:%s" % (c.laddr) raddr = "" if c.raddr: raddr = "%s:%s" % (c.raddr) name = proc_names.get(c.pid, '?') or '' print(templ % ( proto_map[(c.family, c.type)], laddr, raddr or AD, c.status, c.pid or AD, name[:15], )) if __name__ == '__main__': main()
HARDWARE INFO (OS, PSUTIL, cpuinfo)
Количество threads/logical CPU разные способы:
import multiprocessing multiprocessing.cpu_count() import os print(os.cpu_count()) import psutil psutil.cpu_count(logical=True)
Производитель процессора.
import cpuinfo cpuinfo.get_cpu_info()['brand_raw']
Утилизация процессора, в том числе по ядрам. Нужно учитывать что первичный счетчик всегда будет нулевой, нужно запускать с интервалом съем.
The first call will always be 0.0 as calculating percentage is something which requires comparing two values over time, and as such, some time has to pass. import psutil # average psutil.cpu_percent() # per core psutil.cpu_percent(percpu=True) >>> psutil.cpu_percent() 45.0 >>> psutil.cpu_percent(percpu=True) [6.5, 0.0, 0.0, 0.0, 0.0, 0.0, 0.1, 0.1, 0.0, 0.0, 0.1, 38.5] >>> psutil.cpu_percent(percpu=True, interval=10) [38.9, 0.0, 0.0, 0.0, 0.0, 0.0, 0.3, 0.3, 0.3, 0.3, 0.4, 100.0]
Exception
offtop: зачастую вместо exception handling лучше использовать guardian pattern – перед опасным участком кода делать необходимые для корректного исполнения кода проверки. Их можно делать в отдельных if блоках или составляя логическое выражение, где первыми элементами проверяются guardian, а в последующем необходимая логика (последовательность важна, иначе guardian не сработает и будет exception). Подробнее о guardian pattern и short-circuit evaluation можно прочитать тут.
# Guardian
if len(a) < 0:
quit()
if a[0] == "Added":
print(a)
# Guardian in compound statement
if len(a) > 0 and a[0] == "Added":
print(a)
Exception raise (вызов)
Raise можно использовать для генерации exception.
# example 1
if os.path.exists(workDir):
raise Exception("Error: Directory already exist.")
# example 2
raise RuntimeError("error_text")
Для создания своего Exception и логики его обработки нужно создавать класс. В базовом случае реализация простая – пример отключением многопоточной обработки:
class StopThreadExection(Exception): pass
<some_func execution>
raise StopThreadExection()
try:
pool.starmap(some_func, exec_data)
print("All tasks completed.")
except StopThreadExection:
pool.close() # Prevent new tasks
pool.join() # Wait for existing tasks to finish
print("Some tasks not completed because 'StopThreadExection' was raised.")
exception Handling (обработка)
Отработка на KeyBoardInterrupt exception, далее на ZeroDivisionError. Ниже так же можно было бы добавить блоки else (исполнение в случае если exception не сработал), finally (исполнение в любом случае – сработал exception или нет).
try:
print("here is untrusted code")
except (KeyboardInterrupt, SystemExit):
print("KeyBoard exception")
except ZeroDivisionError:
print("Do not divide by zero")
Отработка на все ошибки (так не рекомендуется делать), без сбора информации о ошибке
# bad
try:
print("here is untrusted code")
except: # catch *all* exceptions
print("exception")
# no so bad
try:
print("here is untrusted code")
except Exception: # catch *all* exceptions
print("exception")
# good
try:
print("here is untrusted code")
except ZeroDivisionError:
print("exception")
# why catch *all* exceptions BAD
Because it's terribly nonspecific and it doesn't enable you to do anything interesting with the exception. Moreover, if you're catching every exception there could be loads of exceptions that are happening that you don't even know are happening (which could cause your application to fail without you really knowing why). You should be able to predict (either through reading documentation or experimentation) specifically which exceptions you need to handle and how to handle them, but if you're blindly suppressing all of them from the beginning you'll never know.
Отработка на все ошибки, со сбором информации о ошибке (что за ошибка) и traceback (что еще более важно – содержит, напр. указание конкретной строки с ошибкой).
import traceback
try:
print("here is untrusted code")
except Exception as e:
tb = traceback.format_exc()
print(f"exception {e}")
print(f"traceback {tb}")
Функция по генерации exception с сохранением ин-ии о нем в лог.
def raise_exception_and_log(msg):
logger.critical(msg)
raise Exception(msg)
raise_exception_and_log("Test1 execution failed")
Повтор операции N раз в случае exception легко делается через связку for + break.
How to retry after exception? https://stackoverflow.com/questions/2083987/how-to-retry-after-exception Do awhile Trueinside your for loop, put yourtrycode inside, and break from thatwhileloop only when your code succeeds.
for i in range(1,exception_retries_count+1):
try:
<some_not_stable_process>
break
except Exception as e:
time.sleep(10)
write_to_file(f"exception {} was raised (retry ({}/{})".format(e, i, exception_retries_count), log_fname)
if i == exception_retries_count:
quit_with_log("Error: maximum retries count reached.", log_fname)
Retiries до success делается с помощью while True + rescue + break:
while True:
try:
<CODE>
except Exception as e:
sleep_fun(10, " caught exception ({}), trying again".format(e))
continue
break
В функции с exception можно заложить режим debug (писать exception) по передаваемой опции.
def check_ip(pos_ip, exception_debug=False):
'''check ip function'''
try:
ipaddress.ip_address(pos_ip)
exceptValueErroras e:
if exception_debug: print(e)
return(False)
return(True)
check_ip(ip, exception_debug=True)
decarator
Элемент перед функцией, который реализует какую-то особенность обработки данной функции.
-
- @staticmethod – по сути независимость метода от класса
@staticmethod — используется для создания метода, который ничего не знает о классе или экземпляре, через который он был вызван. Он просто получает переданные аргументы, без неявного первого аргумента, и его определение неизменяемо через наследование. Проще говоря, @staticmethod — это вроде обычной функции, определенной внутри класса, которая не имеет доступа к экземпляру, поэтому ее можно вызывать без создания экземпляра класса.
execution timeout
В python есть ряд разных реализаций execution timeout разной степени “поршивости” – что-то например не будет работать в Windows, что-то переодически подвисать из-за использования thread, вызова дочерних процессов и каких то еще проблем. Чаще всего работают через декоратор перед функцией. Наиболее стабильной функцией в этом контексте была timeout опция для subprocess и timeout утилита для linux – т.е. не питоновские “исходные” функции вовсе.
Способы, которые пробовал (первые более менее – последние совсем “зашквар”):
1. Способ wrapt-timeout-decorator работает в виде декоратора (перед функцией) и не имеет недостатков выше – возвращает как значения при успешном исполнении, не применяется на другие функции. Но есть недостаток в том, что процесс дочерний (напр. функция с timeout запускает subprocess) остается жив, что потенциально может приводить к формированию zombie.
pip3 install wrapt-timeout-decorator
import time
from wrapt_timeout_decorator import *
@timeout(5)
def mytest(message):
print(message)
for i in range(1,10):
time.sleep(1)
print('{} seconds have passed'.format(i))
return "puk"
def mytest2(message):
print(message)
for i in range(1,10):
time.sleep(1)
print('{} seconds have passed'.format(i))
return "puk"
res = mytest2('starting')
print(res)
2. timeout-decorator, не работает на Windows в режиме по умолчанию.
import time
import timeout_decorator
@timeout_decorator.timeout(5) # для Linux передаем timeout(5, use_signals=False)
def mytest():
print("Start")
for i in range(1,10):
time.sleep(1) print("{} seconds have passed".format(i))
if __name__ == '__main__': mytest()
- 3. Метод со stackoverflow работает и не требует установки модулей и зависимый библиотек (были с этим проблемы). Может зависать сам (ждет пользовательского ввода).
#!/usr/bin/env python # -*- coding: utf-8 -*- from threading import Thread import functools def timeout(timeout): ... ... ..
4. Не очень способ т.к. он глобальный и если в коде есть функции, которые должны долго исполнятся, а другие нет – не подойдет.
import signal
import time
def handler(signum, frame):
print("Forever is over!")
raise Exception("end of time")
def loop_forever():
while 1:
print("sec")
time.sleep(1)
def loop_forever2():
while 1:
print("sec2")
time.sleep(1)
signal.signal(signal.SIGALRM, handler)
signal.alarm(10)
try:
loop_forever2()
except:
print("some shit")
5. Есть так же вариант с использованием thread, но он так же довольно кривой т.к. в таком случае нужно собирать output из процесса, например, используя shared variables, что усложняет код.
import multiprocessing
import time
# bar
def bar():
for i in range(100):
print("Tick")
time.sleep(1)
# Start bar as a process
p = multiprocessing.Process(target=bar)
p.start()
# Wait for 10 seconds or until process finishes
p.join(10)
# If thred is still active
if p.is_alive():
print("running... let's kill it...")
# Terminate
p.terminate()
p.join()
p = multiprocessing.Process(target=bar)
p.start()
logrotate на базе python кода
import os
import time
# Папка для очистки
LOG-DIR = "/var/log/myapp"
DAYS_TO_KEEP = 7 # Храним файлы не старше 7 дней
# Текущее время
now = time.time()
# Очистка старых файлов
for file_name in os.listdir(LOG_DIR):
file_path = os.path.join(LOG_DIR, file_name)
if os.path.isfile(file_path):
# Проверяем возраст файла
if now - os.path.getmtime(file_path) > DAYS_TO_KEEP * 86400:
os.remove(file_path)
print(f"Удалён файл: {file_path}")
print ("* Очистка завершена!")
ООП
Инкапсуляция, наследование, полиморфизм
- Инкапсуляция – строе разделение контрактных обязательств сущностей за их интерфейсом (набором public методов) и как итог сокрытие внутренней реализации сущностей. Сущности предоставляют друг другу интерфейс, за которым и скрываются контрактные обязательства. Взаимодействие между сущностями реализуется через интерфейс. Контрактные обязательства в виде правильного input в метод (корректность данных на вход) и вида outpu из метода справедливы и для функций без классов, с ООП в инкапсуляцию добавляется то, что за функцией скрыта не только реализация функционала, но и состояние объекта класса, которым можно управлять через интерфейс.
- Наследование – возможность в коде с использованием классов реализации связей множество-подмножество как в реальном мире: множество животные (техника), подмножество хищники (передвижная), подмонежство кошачие (автомобили с массой до 3 тонн) и т.д. Используя такие связи ты можешь не дублировать код (следствие/профит) – в классе child переиспользуя код parent класса, но в каких то случаях и изменяя под свое подмножество (исключения). Соответственно и в коде правильно сохранять логичность структуры родитель-ребенок и не допускать таких вещей как наследование от колес классом автомобиля т.к. в колесах есть нужный метод (регулярно встречаемая ошибка).
- Полиморфизм подразумевает обычно взаимозаменяемость объектов с одинаковым интерфейсом (in/out), это определение полиморфизма является следствием наследования – реализация принципа Барбары Лисков (Liskov Substitution Principle, LSP), когда ты можешь с дочерним классом работать так же, как м с родительским. Важно что интерфейс должен быть одинаковым (между родительским и дочерним классами) – иначе это нарушение принципа LSP и полиморфизма соответственно.

модификаторы/уровни доступа public, private, protected
Модификаторы условные, их можно обойти:
- public – по умолчанию без подчеркиваний, можно и нужно вызывать вне класса обращаясь к методу
- protected – с одним подчеркиванием, можно использовать вне класса, но нежелательно
- private – с двумя подчеркиваниями, можно использовать вне класса, но крайне нежелательно – вызов происходит через _ClassName__PrivateMethodName
Классы (CLasses)
Простые примеры: dataclass
Удобное расширение, появившееся в python3.7, которое позволяет создавать класс с описанием объекта в пару строк.
Было так:
class RegularBook:
def __init__(self, title, author):
self.title = title
self.author = author
Теперь можно переписать вот так – включение dataclass реализуется с использованием декоратора dataclass:
from dataclasses import dataclass @dataclass class Book: title: str author: str
И работать как обычно
>>> book = Book(title="Fahrenheit 451", author="Bradbury") >>> book Book(title='Fahrenheit 451', author='Bradbury') >>> book.author 'Bradbury'
Чтобы объекты нельзя было изменить можно заморозить (сделать immutable/неизменяемыми) это при инициализации класса.
@dataclass(frozen=True)
class Book:
title: str
author: str
>>> book = Book("Fahrenheit 451", "Bradbury")
>>> book.title = "1984"
dataclasses.FrozenInstanceError: cannot assign to field 'title'
ПРОСТые примеры: практика
Инициализируем SSH класс.
-
- (# Assign params) Переменные назначаем из dictionary динамически по key:value, что позволяет не создавать одноименные параметры внутри класса – очень удобно.
- (# Ssh login) Возвращаем объект SSH в котором уже пройдена аутентификация (результат внутри класса в self.ssh_conn, self.ssh_client доступен всем функциям класса).
class SshControl:
def __init__(self, kwargs):
# Assign params
for key, value in params.items():
setattr(self, key, value)
log.debug(f"{params}", self.log_fname)
# Ssh login
log.debug(f"[*] ssh_login to {self.ssh_ip} with {self.ssh_user}:{self.ssh_password}...", self.log_fname)
self.ssh_client = paramiko.SSHClient()
self.ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
self.ssh_client.connect(self.ssh_ip, username=self.ssh_user, password=self.ssh_password)
time.sleep(self.ssh_timeout_shell_waiting)
self.ssh_conn = self.ssh_client.invoke_shell()
ssh_params = { "ip": "172.16.13.2", "ssh_user": "admin", "ssh_password": "admin", "port": 22, "log_fname": "test.log"}
ssh = SshControl(ssh_params)
Еще пример от яндекса – кратко рейтинги участников, возврат лучших работ по лайкам. Задача расписана в двух статьях т.к. представляет интерес как с точки зрения статьи Coding: Python заметки, так и с точки зрения статьи Алгориртмы и структуры данных, оценка сложности алгоритмов (асимптотическая оценка, оценка Big O)
-
- почеркивания
- _change_score – методы, необходимые для работы только класса принято называть через знак подчеркивания
- get_best_works – при итерировании, если значение не обрабатывается, общая практика называть его знаком подчеркивания
- __init__ – в этой функции создается массив по количеству участников, индекс элемента в массиве = ID участника, число по этому индексу = рейтинг
- сама задача по возврату лучших работ решается простой сортировкой и reverse (чтобы старшие элементы, имеющие больший рейтинг были первыми)
- почеркивания
class Competition:
def _change_score(self, participant_id, change):
self._scores[participant_id] += change
def __init__(self, participant_count):
self._scores = [0] * participant_count
def like(self, participant_id):
self._change_score(participant_id, 1)
def dislike(self, participant_id):
self._change_score(participant_id, -1)
def get_best_works(self, count):
scores_ids = [(value, id) for id, value in enumerate(self._scores)]
scores_ids.sort(reverse=True)
return [id for _, id in scores_ids[:count]]
test = Competition(300)
test.like(30)
test.like(30)
test.like(55)
test.like(77)
test.like(99)
print(test.get_best_works(10))
>>>
[30, 99, 77, 55, 299, 298, 297, 296, 295, 294]
super
- super – функция, которая может использоваться в базовом сценарии для переопределения функции, в наследовании.
Вызов метода внутри класса возможен с помощью self.
def json_gen(self, var1, var2, var3): ... self.json_gen(var1, var2, var3)
Аналогично через self. можно переиспользовать переменные между методами класса – не обязательно их передавать в сам метод в виде переменной.
self.somevar = "test"
OS.SYSTEM (EXTERNAL COMMAND)
С системным модулем subprocess запуск внешних команд похож на обычный shell или запуск в ruby/php через ‘command’. НО есть огромная разница – вывод не сохранить сразу в переменную в python, он только отображается в bash.
В целом общее мнение, что os.system сейчас лучше не использовать, а использовать subprocess.
import sys
os.system("ip netns exec VRF1 ip a")
Subprocess (external command)
- Бывают случаи, когда команды пересылаемые с рядом pipe linux должны запускаться не пользователем напрямую в терминале (напр. cron или запуск скрипта через WEB), в таких случаях чаще всего наиболее рабочим (и на имение крипово выглядящим в коде) будет вариант запуска отдельного скрипта, включающего команды с pipe, а не попытка запуска всех pipe непосредственно в subprocess/os.system. Пример с настройкой прерываний через web скрипт.
subprocess.call( "sudo /var/www/cgi-bin/scr.sh %s" % iface, shell=True ) # shell=True нежелателен для использования (security problems)
subprocess.check_output( "sudo /bin/grep -E %s /proc/interrupts | /usr/bin/awk '{print $1}' | /usr/bin/tr ':' ' ' | while read irq; do sudo echo 000002 > /proc/irq/$irq/smp_affinity; done" % iface, shell=True )
- С системным модулем subprocess запуск внешних команд похож gem Ruby Open3. Subprocess.run появился в новых версиях subprocess, раньше его не было. По практике – всегда, когда возможно, лучше использовать run вместо check_output. В отличии от Popen функция run ожидает исполнения процесса до перехода к следующей строке кода.
import subprocess subprocess.run(["ls", "-l"]) subprocess.check_output(["snmpget", "-v", "2c", "-c", "test", "-Ov", "-Oq", ip, oid])
- Для длинных команд удобно сначала использовать split и переменную.
cmd = "ip netns exec VRF1 ip a".split() subprocess.run(cmd)
- Вывод STDOUT/STDERR скрыть можно через опции. Для check_output можно скрыть только stderr (stdout аргумент не разрешен для check_output).
import os import subprocess null = open(os.devnull, 'w') subprocess.run(cmd, stderr=null, stdout=null) subprocess.check_output(cmd, stderr=null)
- Так же может быть перенаправление stderr в stdout. Например, утилиты зачастую информацию о своей версии выводят в stderr.
tcpreplay_version_info = subprocess.check_output("tcpreplay -V".split(" "), stderr=subprocess.STDOUT)
write_to_file(tcpreplay_version_info, "file_with_tcpreplay_info.txt")
- Ниже я всячески хвалю функцию run в пользу других, но The subprocess.run() function only exists in Python 3.5 and newer.
- Получение stdout/stderr в subprocess возможно и с использованием run и с использованием Popen при перенаправлении stdout в PIPE. При использовании check_output stdout изменить нельзя и он не отображается, запускается процесс и отсутствует ожидание его исполнения (т.е. поведение аналогично & в bash, в отличии от run, ожидающего execution). По практике Popen лучше не использовать в пользу замены на run, несмотря на наличие в Popen функционала, которого нет в других режимах subpocess (напр. получение дочернего pid процесса при использовании preexec_fn=os.setsid). Проблема в том, что Popen может работать нестабильно (независимо от использования опций) и фризить периодически дочерний процесс.
test = subprocess.Popen(cmd, stdout=subprocess.PIPE) data = test.communicate() print(data) test = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE) print(data) print(test.stdout) # вывод в виде byte cтроки print(test.stdout.decode()) # преобразуем в string print(test.returncode) Обратите внимание на то, что когда вы запускаете этот код, цель которого – поддержка связи, он будет дожидаться финиша процесса, После чего выдаст кортеж, состоящий из двух элементов, которые являются содержимым stdout и stderr.
- Вместо преобразования byte строки через decode (как выше) можно указать кодирование вывода в unicode используя utf-8 сразу в subprocess.
test = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, encoding='utf-8')
- Пример subprocess с переходом в другую директорию.
cmd = f"cd /test/; /test/test.script" subprocess.call(cmd, shell=True, stdout=null)
Execution Timeout (subprocess)
В subprocess есть встроенная функция с execution timeout, которая работает с subprocess.run.
res = subprocess.run("some_scripts", stdout=subprocess.PIPE, stderr=subprocess.PIPE, encoding='utf-8', timeout=900)
Timeout + stdout/err in file (немного костылей)
Очень удобно использовать timeout, но есть недостаток – если мы присваиваем вывод в переменную, она не соберет данные при exception execution timeout. В итоге мы не будем знать что же сформировалось за время работы скрипта/не увидим ошибки. Решение – использовать запись в файл stdout/stderr через промежуточный скрипт bash скрипт. Обязательно /bin/bash, а не /bin/sh, иначе редирект не будет работать.
scripts.sh
#!/bin/bash
$1 $2 $3 &>$4
res = subprocess.run("some_scripts opt1 opt2 log_file.log", timeout=900)
Background
Базовый запуск background subprocess.
test = subprocess.Popen(cmd)
- Using shell=True enables all of the shell's features. Don't do this unless command including thingy comes from sources that you trust. - After this statement is executed, the command will run in background. If you want to be sure that it has completed, run p.wait().
Аналогичный выше запуск через run. Для запуска в background (shell символ & для background) без сбора вывода (т.к. capture_output=True отменяет background и subprocess ждет завершение child) или при использовании в коде спец. символов (например, *|) может потребоваться использование shell=True.
subprocess.run("echo 10 &", shell=True)
Background + сбор вывода (немного костылей)
- По умолчанию subprocess.call не дает доступ к stdout/stderr
The subprocess.call() function in Python executes a command and waits for it to complete, returning only the exit code of the executed program. It does not directly provide access to the standard output (stdout) or standard error (stderr) of the child process.
Запуск в background + запись в файл ((есть так же вариант с промежуточный bash-скриптом, см выше)). Реализация через shell:
- tee для записи в файл,
- & для background,
- stdout=null для отброса вывода в консоль (запись только в файл)
import os
null = open(os.devnull, 'w')
subprocess.call('some_script.hz | tee log_file &', shell=True, stdout=null)
OUTLOOK (MAIL)
Отправка письма через outlook приложение на Windows, работает. Для нескольких адресатов указываем их через “;” в string.
import win32com.client as win32
outlook = win32.Dispatch('outlook.application')
mail = outlook.CreateItem(0)
mail.To = 'To address'
mail.Subject = 'Message subject'
mail.Body = 'Message body'
mail.HTMLBody = '<h2>HTML Message body</h2>' #this field is optional
# To attach a file to the email (optional):
attachment = "Path to the attachment"
mail.Attachments.Add(attachment)
mail.Send()
SYSTEM INFO
Библиотека sys.
sys.platform == "win32"
Тестирование кода; pytest
- (JMeter, Locust) Кто-то мигрирует с JMeter на Locust (на базе python)
- Согласно исследованию JetBrains, Pytest использует каждый второй питонист.
- В крупных проектах используются тест-кейс системы типо Allure TestOps
- Используется в том числе в сетевой разработке (напр. завернуть функциональный тест коммутатора в pytest).
Судя по статье
- конструкции pytest лаконичнее unittest.
import pytest def
setup_module(module):
#init_something()
pass
def teardown_module(module):
#teardown_something()
pass
def test_numbers_3_4():
print "test 3*4"
assert 3*4 == 12
def test_strings_a_3():
print "test a*3"
assert 'a'*3 == 'aaa'
def test_upper():
assert 'foo'.upper() == 'FOO'
def test_isupper():
assert 'FOO'.isupper()
def test_failed_upper():
assert 'foo'.upper() == 'FOo'
- есть разные возможности отчетности, в том числе xml/html
$ py.test sample_tests.py --junitxml=C:\path\to\out_report.xml pip install pytest-html pytest --html=report.html
- пример обработки исключений
import pytest
def f():
print 1/0
def test_exception():
with pytest.raises(ZeroDivisionError):
f()
SOCKETS
- Sockets можно использовать в нагрузочном тестировании (как набор соединений concurrent connections, так и скорость установки соединений CPS с возможностью работы с TLS посредством OpenSSL), главное чтобы было достаточное количество RAM при установке значительного количества соединений
- Расчет по памяти: примерно 64 GB для поднятия 10 МЛН сессий (CC). т.е. порядка 6.7 KB на сессию
Python как и Ruby имеет встроенную библиотеку socket, которая позволяет как принимать данные из сети, так и отправлять их. С ней можно поднять базовый TCP-сервер, отправить какой-то трафик (часто используется в exploit’ах) и проч.
Базовая работа с socket: import, create, connect, send, receive, close.
import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) connect=s.connect((HOST,PORT)) s.send(evil) data = s.recv(4096) s.close()
Пример включения и настройки отправки TCP keepalive для создаваемого socket. Так же timeout можно сделать безусловным на socket (без idle).
s.setsockopt(socket.SOL_SOCKET, socket.SO_KEEPALIVE, 1) s.setsockopt(socket.IPPROTO_TCP, socket.TCP_KEEPIDLE, 60) s.setsockopt(socket.IPPROTO_TCP, socket.TCP_KEEPINTVL, 60) s.setsockopt(socket.IPPROTO_TCP, socket.TCP_KEEPCNT, 30) s.settimeout(30) Пример системных (при установке socket из python не работают): root@debian8:~# cat /proc/sys/net/ipv4/tcp_keepalive_intvl 75 root@debian8:~# cat /proc/sys/net/ipv4/tcp_keepalive_time 7200
Настройка MSS (уменьшаем с default 1460 до 96). Сделать еще меньше (48 байт) можно настроив mtu на интерфейсе. При попытке задать MSS через TCP_MAXSEG может выдавать ошибку OSError: [Errno 22] Invalid argument.
s.setsockopt(socket.IPPROTO_TCP, socket.TCP_MAXSEG, 96) # sysctl -a | grep -i tcp | grep mss net.ipv4.tcp_base_mss = 1024 net.ipv4.tcp_min_snd_mss = 48
Настройка размера TCP окна через задание размера буферов на прием и отправку. Про настройку Linux и особенности работы в TCP.
# python socket rewrite tcp_rmem/tcp_wmem (Linux) (не rmem_max/wmem_max) s.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF, 2048) s.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 2048) # default from tcp_rmem/tcp_wmem (Linux) (не rmem_max/wmem_max) >>> print(s.getsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF)) 131072 >>> print(s.getsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF)) 16384
Включаем возможность socket reuse, например полезно в сценарии когда демон постоянно по какой-то причине должен перезагружаться и “подниматься” максимально быстро (без ожидания полного высвобождения socket, аллокации памяти под сокет). Опцию можно использовать и для UDP сокета, в таком случае копию трафика будут получать все приложения, подключенные к socket, like a multicast/broadcast (справедливо и для multicast и для broadcast). Теория о socket reuse (в основном перевод статьи IBM) в статье TCP.
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) I'm aware that using SO_REUSEADDR with UDP in a *NIX environment, behaves like a multicast, where multiple clients bound to the same port can listen and receive broadcast datagrams simultaneously. Multiple UDP sockets on Windows bound to the same port will all receive broadcast packets together.
Отправка данных в TCP сокет.
s.send(data_new)
Прием данных в TCP. 4096 – количество байт, по факту столько одним пакетом редко когда будет получено из-за стандартного MTU 1500.
c.recv(4096)
-
- Oracle считает, что лучше данное значение увеличивать вплоть до 100 (listenBacklog), а для некоторых своих app настраивает в 511!
https://www.ibm.com/docs/en/was-zos/8.5.5?topic=SS7K4U_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/tprf_tunetcpip.html https://stackoverflow.com/questions/36594400/what-is-backlog-in-tcp-connections The default listen backlog is used to buffer spikes in new connections which come with a protocol like HTTP. The default listen backlog is 10 requests. You should use the TCP transport channel listenBacklog custom property to increase this value to something larger. For example: listenBacklog=100 For channel types that are not HTTP, HTTP SSL, IIOP and IIOP SSL, the default for listenBacklog is 511.
-
- По некоторым мнениям значения больше пяти не имеют смысла. Логика такая – это ограничение принятых подключений, соединения должны приниматься быстро, не достигая этого ограничения
https://stackoverflow.com/questions/2444459/python-sock-listen You don't need to adjust the parameter to listen() to a larger number than 5. It specifies the number of unaccepted connections that the system will allow before refusing new connections. If not specified, a default reasonable value is chosen. s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) s.listen()
- NAGL (TCP_NODELAY) – на практике в коротких экспериментах вкл/выкл nagl не влияло на производительность, подробнее о nagle в статье про TCP
s.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
- setblocking – по умолчанию socket’ы блокирующие, управлять блокировками можно с использованием socketblocking (так же управление возможно через таймауты), non-blocking требует асинхронную обработку (ниже в gil/race conditions и многопоточности/процессорности подробнее про asyncio/epool)
socket.setblocking(flag) Set blocking or non-blocking mode of the socket: if flag is false, the socket is set to non-blocking, else to blocking mode. This method is a shorthand for certain settimeout() calls: sock.setblocking(True) is equivalent to sock.settimeout(None) sock.setblocking(False) is equivalent to sock.settimeout(0.0) Примечания о тайм-аутах сокетов. Объект сокета может находиться в одном из трех режимов: блокирующий, неблокирующий или тайм-аут. По умолчанию сокеты всегда создаются в режиме блокировки, но это можно изменить, вызвав функцию socket.setdefaulttimeout(). - В режиме блокировки (default), операции блокируются до тех пор, пока не будут завершены или система не возвратит ошибку (например, истекло время ожидания соединения). By default, TCP sockets are placed in a blocking mode. This means that the control is not returned to your program until some specific operation is complete. For example, if you call the connect() method, the connection blocks your program until the operation is complete. - В неблокирующем режиме операции завершаются неудачно (с ошибкой, которая, к сожалению, зависит от системы), если они не могут быть выполнены немедленно: можно использовать функции из модуля select для определения того, когда и доступен ли сокет для чтения или записи. - В режиме тайм-аута операции завершаются ошибкой, если они не могут быть завершены в течение тайм-аута, указанного для сокета (они вызывают исключение socket.timeout) или если система возвращает ошибку.
UDP socket (SOCK_DGRAM)
Особенности UDP socket. Несколько примеров.
TCP sockets should use socket.recv and UDP sockets should use socket.recvfrom. This is because TCP is a connection-oriented protocol. Once you create a connection, it does not change. UDP, on the other hand, is a connectionless ("send-and-forget") protocol. You use recvfrom so you know to whom you should send data back. Recvfrom does not work on TCP sockets the same way. As for the 1024/2048, these represent the number of bytes you want to accept. Generally speaking, UDP has less overhead than TCP allowing you to receive more data, but this is not a strict rule and is almost negligible in this context. You can receive as much or as little as you would like. 4096 is common as well (for both).
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
if proto == "TCP":
s.listen()
c, addr = s.accept()
print("TCP connection established with client ip/port: {}".format(addr))
data = c.recv(4096)
else:
data, addr = s.recvfrom(4096)
print("UDP data received from client ip/port: {}".format(addr))
data_new = "hello"
s.sendto(data_new, addr)
NSLOOKUP
Простой nslooup на базе sockets.
simple nslookup in python
def simple_nslookup(fqdn):
ip_list = []
ais = socket.getaddrinfo(fqdn,0,0,0,0)
for result in ais:
if ":" not in result[-1][0]: # exclude IPv6
ip_list.append(result[-1][0])
return list(set(ip_list))
print(simple_nslookup("pool.ntp.org"))
IPADDRESS
Безусловно есть как поддержка IPv4Address/Network объектов, так и IPv6. Ниже описана работа только с IPv4. IPv6 по аналогии.
Address
С помощью функций модуля можно делать разные вещи, например с помощью функции ip_address легко проверять строки на соответствие формату IP-адреса.
import ipaddress
def check_ip(pos_ip):
'''check ip function'''
try:
ipaddress.ip_address(pos_ip)
except ValueError:
return(False)
return(True)
ip1 = "1.1.1.1"
ip2 = "2.2.2.2"
ip66 = "6.66.666.66"
print(ip1, check_ip(ip1))
print(ip2, check_ip(ip2))
print(ip66, check_ip(ip66))
1.1.1.1 True
2.2.2.2 True
6.66.666.66 False
С помощью функции is_private можем понять, относится ли IP к private диапазонам. Есть так же аналогичные функции is_multicast, is_loopback.
ip1 = "10.1.1.1" ip1_validated = ipaddress.ip_address(ip1) print(ip1_validated.is_private) print(ip1_validated.is_multicast) print(ip1_validated.is_loopback) True False False
Можно так же сравнивать между собой адреса (ip1 > ip2), добавлять к адресам integer для получения нового адреса.
ip1 = "10.1.1.1" ip1_validated = ipaddress.ip_address(ip1) print(ip1_validated + 300) 10.1.2.45
Можно сделать проверку принадлежности Address объекта к сети Network.
ip = ipaddress.IPv4Address(u"1.1.1.1") net = ipaddress.IPv4Network(u"1.1.1.1/255.255.255.0", strict=False) print(ip in net) True
Network
С помощью функций network_address и broadcast_address можно получить соответствующие адреса на основе адреса сети или даже IP адреса (strict false) для объекта Network. Так же можно получить общее количество адресов в сети, используя num_addresses. Так же Network является итерируемым объектом – из него можно извлечь объекты IPAddress для каждого адреса как по одному, так и по index.
net = ipaddress.IPv4Network(u"1.1.1.1/255.255.255.0", strict=False)
print('Network address:', net.network_address)
print('Broadcast:', net.broadcast_address)
print('Addr count:', net.num_addresses)
Network address: 1.1.1.0
Broadcast: 1.1.1.255
Addr count: 256
for ip in net:
print(ip)
1.1.1.0
1.1.1.1
1.1.1.2
...
1.1.1.254
1.1.1.255
print(net[4])
1.1.1.4
# без strict будет ошибка, если указать не адрес сети
File "/usr/lib/python2.7/dist-packages/ipaddress.py", line 1662, in __init__
raise ValueError('%s has host bits set' % self)
ValueError: 1.1.1.1/24 has host bits set
Представлять маску в любом формате (with_netmask – mask, with_hostmask-wildcard, prefixlen – prefix) для объекта Network.
net = "10.1.1.0/24" ipnet = ipaddress.ip_network(net) print(ipnet.with_netmask) print(ipnet.with_hostmask) print(ipnet.prefixlen) 10.1.1.0/255.255.255.0 10.1.1.0/0.0.0.255 24
Можно так же для объекта Network использовать разделение сети на подсети – указав конкретную подсеть (new_prefix) или сделав вычитание из текущей (prefixlen_diff, по умолчанию 1, поэтому не обязательно указывать).
net = ipaddress.IPv4Network(u"1.1.1.1/255.255.255.0", strict=False)
print(list(net.subnets(new_prefix=27)))
[IPv4Network('1.1.1.0/27'), IPv4Network('1.1.1.32/27'), IPv4Network('1.1.1.64/27'), IPv4Network('1.1.1.96/27'), IPv4Network('1.1.1.128/27'), IPv4Network('1.1.1.160/27'), IPv4Network('1.1.1.192/27'), IPv4Network('1.1.1.224/27')]
print(list(net.subnets(prefixlen_diff=1)))
[IPv4Network('1.1.1.0/25'), IPv4Network('1.1.1.128/25')]
print(list(net.subnets()))
[IPv4Network('1.1.1.0/25'), IPv4Network('1.1.1.128/25')]
pyroute2 (netns)
Устанавливаем netns, возвращаемся в дефолтный. Работает с socket и psutil (напр. для просмотра сессий в VRF с использованием psutil.net_connections) без каких-либо проблем.
pip3 install pyroute2
import socket
from pyroute2 import netns
netns.setns('VRF1')
# do some stuff in netns, than return back to default
netns.setns('/proc/1/ns/net')
Connections
psutil.net_connections()
SCAPy

Самый удобный способ когда нужно сделать более чем одно действие по изменению сетевых дампов. Легко можно сделать даже непростые операции, например, заменить все сетевые (MAC, IP, PORT) адреса в дампе на другие, IPv6 header на IPv4. Замена IPv6 header на IPv4 подразумевает извлечение payload, создание IPv4 header, добавление в него payload, пересчет checksum и length (см. в HEX EDITORS).
Установка
sudo pip3 install scapy
Базовый запуск
from scapy.all import *
packets = rdpcap('test.pcap')
print(len(packets))
for packet in packets:
print(packet) # print packet info from layer 2
print(dir(packet))# print functions
print(packet.payload) # print packet info from layer 3
print(packet['TCP']) # print only TCP info
print(packet['TCP'].flags) # print only TCP flag info
Scapy packet examples (часть из документации к TRex)
# PARSING
print(packet.summary())
print(packet.show())
packet['IP'].src
packet['IP'].src
packet['IP'].proto # определяем транспортный протокол 6 TCP, 17 UDP
packet['TCP'].sport
packet['TCP'].dport
packet['TCP'].flags == "S"
# Payload manipulation
payload = packet[TCP/UDP].payload # packet.payload is just a pointer to the next layer.
payload = raw(payload) # преобразуем payload в byte строку
if type(payload) == scapy.packet.Padding # проверяем не является ли payload == padding, иначе это пакет без фактического payload
# CREATION
# UDP header
Ether()/IP(src="16.0.0.1",dst="48.0.0.1")/UDP(dport=12,sport=1025)
# UDP over one vlan
Ether()/Dot1Q(vlan=12)/IP(src="16.0.0.1",dst="48.0.0.1")/UDP(dport=12,sport=1025)
# UDP QinQ
Ether()/Dot1Q(vlan=12)/Dot1Q(vlan=12)/IP(src="16.0.0.1",dst="48.0.0.1")/UDP(dport=12,sport=1025)
#TCP over IP over VLAN
Ether()/Dot1Q(vlan=12)/IP(src="16.0.0.1",dst="48.0.0.1")/TCP(dport=12,sport=1025)
# IPv6 over vlan
Ether()/Dot1Q(vlan=12)/IPv6(src="::5")/TCP(dport=12,sport=1025)
#Ipv6 over UDP over IP
Ether()/IP()/UDP()/IPv6(src="::5")/TCP(dport=12,sport=1025)
#DNS packet
Ether()/IP()/UDP()/DNS()
Ether()/IP(src="16.0.0.1",dst="48.0.0.1")/UDP(sport=1025)/DNS(rd=1, qd=DNSQR(qname="weril.me"))
Ether()/IP(src="16.0.0.1",dst="48.0.0.1")/UDP(sport=1025)/('\x00\x00\x01\x00\x00\x01\x00\x00\x00\x00\x00\x00\x05\x77\x65\x72\x69\x6c\x02\x6d\x65\x00\x00\x01\x00\x01') # полная аналогия запроса выше
#HTTP packet
Ether()/IP()/TCP()/"GET / HTTP/1.1\r\nHost: www.google.com\r\n\r\n"
В целом scapy очень функциональный. Например, есть даже fuzzing (подробнее в документации по ссылке сверху).
>>> send(IP(dst="target")/fuzz(UDP()/NTP(version=4)),loop=1)
Поля можно посмотреть через ls. Очень удобно.
ls(Ether) dst : DestMACField = (None) src : SourceMACField = (None) type : XShortEnumField = (36864) ls(IP) version : BitField (4 bits) = (4) ihl : BitField (4 bits) = (None) tos : XByteField = (0) len : ShortField = (None) id : ShortField = (1) flags : FlagsField (3 bits) = (<Flag 0 ()>) frag : BitField (13 bits) = (0) ttl : ByteField = (64) proto : ByteEnumField = (0) chksum : XShortField = (None) src : SourceIPField = (None) dst : DestIPField = (None) options : PacketListField = ([]) ls(TCP) sport : ShortEnumField = (20) dport : ShortEnumField = (80) seq : IntField = (0) ack : IntField = (0) dataofs : BitField (4 bits) = (None) reserved : BitField (3 bits) = (0) flags : FlagsField (9 bits) = (<Flag 2 (S)>) window : ShortField = (8192) chksum : XShortField = (None) urgptr : ShortField = (0) options : TCPOptionsField = (b'')
СКРИПТЫ
Best practice – все скрипты должны включать конструкцию if __name__ == ‘__main__’:
main(), это может решить ряд задач и проблем
1) читатели кода поймут, что это скрипт – иначе в среднем читатель кода будет думать, что скрипт не executable, а некая библиотека
2) код в функции вместо plain text работает быстрее т.к. использует local scope (used Opcodes are `STORE_FAST` and not `STORE_GLOBAL`)
3) код в функциях проще тестировать
4) при вызове из других мест можно разбить операции импорта и запуска скрипта
Скрипт по изменению MAC/IP адресов без создания нового пакета c пересчетом checksum IP/TCP.
from scapy.all import *
packets = rdpcap('/home/user/test.pcap')
new_packets = []
for packet in packets:
sport = packet['TCP'].sport
payload = packet['TCP']
if sport == 80 or sport == 8080:
packet[Ether].dst = "00:10:11:a4:08:87"
packet[Ether].src = "00:10:11:b0:8e:e7"
packet[IP].dst = "172.0.0.2"
packet[IP].src = "172.1.0.2"
else:
packet[Ether].dst = "00:10:11:a4:56:40"
packet[Ether].src = "00:10:11:b0:8e:e5"
packet[IP].dst = "172.1.0.2"
packet[IP].src = "172.0.0.2"
del(packet[IP].chksum)
del(packet[TCP].chksum)
print(packet.show2()) # смотрим содержимое пакета
new_packets.append(packet)
wrpcap("test_new.pcap",new_packets)
Скрипт по извлечению TCP сегмента из существующего дампа, создание нового фрейма и IP пакета, добавление в него TCP payload. В итоге можно из исходного дампа удалить IPv6 header, изменить MAC/IP адреса и прочее, при этом сохранив полностью L4.
from scapy.all import *
packets = rdpcap('old.pcap')
new_packets = []
for packet in packets:
sport = packet['TCP'].sport
payload = packet['TCP']
if sport == 49474:
new_packet = Ether(src='00:11:22:33:44:55', dst='aa:bb:cc:dd:ee:ff')/IP(dst="1.1.1.1",src="192.168.0.1",proto=6)/Raw(load=payload)
else:
new_packet = Ether(src='00:11:22:33:44:55', dst='aa:bb:cc:dd:ee:ff')/IP(dst="192.168.0.1",src="1.1.1.1",proto=6)/Raw(load=payload)
new_packets.append(new_packet)
wrpcap("new.pcap",new_packets)
Можно извлечь и данные других протоколов, например, ICMP. И добавить в новый IP пакет/фрейм.
payload = packet['ICMP'] new_packet = Ether(src='00:11:22:33:44:55', dst='aa:bb:cc:dd:ee:ff')/ IP(dst="1.1.1.1",src="172.17.0.2",proto=1)/ Raw(load=payload)
IP пакет с рандомным ID, установленным флагом DF, и TOS 16.
new_packet = Ether(src='00:11:22:33:44:55', dst='aa:bb:cc:dd:ee:ff')/ IP(dst="1.1.1.1",src="172.17.0.2",flags=2,id=random.randint(1,65534),tos=16,proto=6) / Raw(load=payload)
Модификация payload в дампе с пересчетом checksum.
TODO 48 54 54 50 2f 31 2e 31 20 32 30 30 20 4f 4b 0d HTTP/1.1 200 OK. 48 54 54 50 2f 31 2e 30 20 32 30 30 20 4f 4b 0d HTTP/1.0 200 OK.
from scapy.all import *
#!/usr/bin/env python3
# ver 1.0 by Petr V. Redkin
from scapy.all import *
def change_payload(packet, load):
packet["Raw"].load = load
del packet["IP"].len
del packet["IP"].chksum
del packet["TCP"].chksum
return packet
packets = rdpcap('unmodified.pcap')
new_packets = []
n = 0
for packet in packets:
payload = packet['TCP'].payload
if "HTTP/1.1 200 OK" in str(payload):
print("MATCH!")
print("transaction changed!")
new_payload = packet["Raw"].load.replace(b"HTTP/1.1 200 OK",b"HTTP/1.0 200 OK")
packet = change_payload(packet,new_payload)
new_packets.append(packet)
wrpcap("modified.pcap",new_packets)
Скрипт конвертирует исходный pcap с IP содержимым (payload) и добавляет UDP прослойку, так же урезает payload (на 8 байт) чтобы длины пакетов были аналогичны исходным.
from scapy.all import *
# save packets from pcap to array
packets = rdpcap('test.pcap')
new_packets = []
for packet in packets:
new_packets.append(packet)
print(packet["IP"].src, packet["IP"].dst, packet["IP"].len)
# change & write packets to new pcap
changed_packets = []
for packet in new_packets:
changed_packet = Ether(src=packet.src,dst=packet.dst)/IP(src=packet["IP"].src,dst=packet["IP"].dst)/UDP(dport=55433,sport=55430)/(raw(packet["IP"].payload)[:-8])
changed_packets.append(changed_packet)
wrpcap("test_new.pcap",changed_packets)
Аналогично вышестоящему, но payload не извлекается из пакетов, а фиксирован + сохранены timestamp пакетов.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from scapy.all import *
# save packets from pcap to array
packets = rdpcap('test.pcap')
new_packets = []
for packet in packets:
new_packets.append(packet)
print(packet.time, packet["IP"].src, packet["IP"].dst, packet["IP"].len)
# change & write packets to new pcap
changed_packets = []
for packet in new_packets:
data_str = '1234567890ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' * 100
original_data_len = packet["IP"].len - 20 - 8 # 20 IP, 8 UDP
data = data_str[:original_data_len].encode('utf-8')
changed_packet = Ether(src=packet.src,dst=packet.dst)/IP(src=packet["IP"].src,dst=packet["IP"].dst)/UDP(dport=55433,sport=55430)/(raw(data))
changed_packet.time = packet.time
changed_packets.append(changed_packet)
wrpcap("test_new.pcap",changed_packets)
Scapy отправка трафика
# Ethernet new_packet = Ether(src='00:11:22:33:44:55', dst='aa:bb:cc:dd:ee:ff')/ IP(dst="172.17.0.2",src="1.2.3.4",proto=6) / Raw(load=payload) sendp(new_packet, iface="enp5s0f0")
# IP pi=IP(dst="10.13.37.218")/ICMP() send(pi, loop=True)
Можно отправить и в vrf (так же можно напрямую в коде python используя pyroute2):
ip netns exec VRF1 python3 pcap_replay.py
Scapy может не распознавать дампы из-за некорректного magic в файле. Решается пересохранением дампа в Wireshark/tcpdump/tshark, которые этот дамп зачастую (рил кейс) распознают без проблем.
https://stackoverflow.com/questions/32465850/not-a-pcap-capture-file-bad-magic-scapy-python "Not a pcap capture file (bad magic: %r)" % magic scapy.error.Scapy_Exception: Not a pcap capture file (bad magic: b'4\xcd\xb2\xa1') "Not a pcapng capture file (bad magic: %r)" % magic scapy.error.Scapy_Exception: Not a pcapng capture file (bad magic: b'4\xcd\xb2\xa1') scapy.error.Scapy_Exception: Not a supported capture file
Не надо называть скрипт, использующий scapy, по имени модуля (т.е. scapy.py).
https://stackoverflow.com/questions/59618380/modulenotfounderror-no-module-named-scapy # python3 ./scapy.py Traceback (most recent call last): File "./scapy.py", line 1, in <module> from scapy.all import * File "/opt/trex/trex-core/scripts/scapy.py", line 1, in <module> from scapy.all import * ModuleNotFoundError: No module named 'scapy.all'; 'scapy' is not a package
Из интересного – Fragment offset затрагивает как поле Fragment Offset (IP.frag), так и Flags. И так не только в scapy, но и в wireshark.
# одинаковые по смыслу строки конфигурации TRex STLVmWrFlowVar(fv_name="frag",pkt_offset= "IP.frag"), STLVmWrFlowVar(fv_name="frag",pkt_offset= 20),
pyshark
не умеет модифицировать пакеты. Scapy умеет.
sudo pip3 install pyshark
import pyshark
shark_cap = pyshark.FileCapture('test.pcap')
for packet in shark_cap:
print(packet.tcp)
print(dir(packet.tcp))
NTP client
import ntplib
from time import ctime
c = ntplib.NTPClient()
response = c.request('pool.ntp.org')
print(ctime(response.tx_time))
JSON
Python содержит встроенный модуль под названием json для кодирования и декодирования данных JSON.
import json
arr = { "test": 2, "test2": "xxx", "arr": [1,2,7] }
print(arr)
encoded = json.dumps(arr)
print(encoded)
decoded = json.loads(encoded)
print(decoded)
>
{'test': 2, 'test2': 'xxx', 'arr': [1, 2, 7]}
{"test": 2, "test2": "xxx", "arr": [1, 2, 7]}
{'test': 2, 'test2': 'xxx', 'arr': [1, 2, 7]}
Пример функции чтения json из файла (вместо loads используем load, который в качестве аргумента принимает файл).
d = get_json('strings.json')
print(d)
def get_json(j):
with open(j) as f:
j_parsed = json.load(f)
return j_parsed
Пример выгрузки json с помощью urlib, парсинга его и сложения всех итемов “count”.
import json
from urllib.request import urlopen
url = "http://py4e-data.dr-chuck.net/comments_247944.json"
data = urlopen(url).read()
info = json.loads(data)
summ = 0
for item in info['comments']:
print('Test', item['count'])
summ = summ + int(item['count'])
print(summ)
Pretty print json, полезно для итерируемых/контейнерных объектов (dict, list, set, etc).
print(json.dumps(<some_iterable>, indent=4))
XML
You can use an XPath selector string to look through the entire tree of XML for any tag named 'count' with the following line of code:
counts = tree.findall('.//count')
from urllib.request import urlopen
import xml.etree.ElementTree as ET
url = input('Enter location: ')
data = urlopen(url).read()
print('Retrieved', len(data), 'characters')
print(data.decode())
tree = ET.fromstring(data)
results = tree.findall('.//count')
smm = 0
for item in results:
print("Count: ", item.text)
smm = smm + int(item.text)
print(smm)
JAML
Установка
sudo pip3 install PyYAML
import yaml
with open(some_file) as f: content = f.read() test = yaml.safe_load(content) print(test)
test.update({"test":True})
del test["test"]["test2"]["test3"]
val = test["test"]["test2"]["test3"]
pPrint
Стандартный модуль. Позволяет читаемо отобразить list/dict и прочие данные. Единственное нужно помнить, что длинная строка (меньше width) может быть разделена на string literal – одна строка будет состоять из нескольких строк (каждая из которых укладывается в width), объединенных пробелом. При использовании на словари можно указывать уровень “погружения” depth. Подробнее тут.
from pprint import pprint
data = [('Interface', 'IP', 'Status', 'Protocol'),
('FastEthernet0/0', '15.0.15.1', 'up', 'up'),
('FastEthernet0/1', '10.0.12.1', 'up', 'up'),
('FastEthernet0/2', '10.0.13.1', 'up', 'up'),
('Loopback0', '10.1.1.1', 'up', 'up'),
('Loopback100', '100.0.0.1', 'up', 'up')]
print(data)
pprint(data)
[('Interface', 'IP', 'Status', 'Protocol'), ('FastEthernet0/0', '15.0.15.1', 'up', 'up'), ('FastEthernet0/1', '10.0.12.1', 'up', 'up'), ('FastEthernet0/2', '10.0.13.1', 'up', 'up'), ('Loopback0', '10.1.1.1', 'up', 'up'), ('Loopback100', '100.0.0.1', 'up', 'up')]
[('Interface', 'IP', 'Status', 'Protocol'),
('FastEthernet0/0', '15.0.15.1', 'up', 'up'),
('FastEthernet0/1', '10.0.12.1', 'up', 'up'),
('FastEthernet0/2', '10.0.13.1', 'up', 'up'),
('Loopback0', '10.1.1.1', 'up', 'up'),
('Loopback100', '100.0.0.1', 'up', 'up')]
Tabulate
Позволяет list/dict (в том числе многомерные) отобразить в красивом виде – с разделением по табам, html тегами, в виде таблиц и проч. Требует установки т.к. не стандартный модуль. Подробно тут.
sudo pip3 install tabulate
from tabulate import tabulate
data = [('Interface', 'IP', 'Status', 'Protocol'),
('FastEthernet0/0', '15.0.15.1', 'up', 'up'),
('FastEthernet0/1', '10.0.12.1', 'up', 'up'),
('FastEthernet0/2', '10.0.13.1', 'up', 'up'),
('Loopback0', '10.1.1.1', 'up', 'up'),
('Loopback100', '100.0.0.1', 'up', 'up')]
print(tabulate(data, headers='firstrow'))
Interface IP Status Protocol
--------------- --------- -------- ----------
FastEthernet0/0 15.0.15.1 up up
FastEthernet0/1 10.0.12.1 up up
FastEthernet0/2 10.0.13.1 up up
Loopback0 10.1.1.1 up up
Loopback100 100.0.0.1 up up
print(tabulate(data, headers='firstrow', tablefmt='grid'))
+-----------------+-----------+----------+------------+
| Interface | IP | Status | Protocol |
+=================+===========+==========+============+
| FastEthernet0/0 | 15.0.15.1 | up | up |
+-----------------+-----------+----------+------------+
| FastEthernet0/1 | 10.0.12.1 | up | up |
+-----------------+-----------+----------+------------+
| FastEthernet0/2 | 10.0.13.1 | up | up |
+-----------------+-----------+----------+------------+
| Loopback0 | 10.1.1.1 | up | up |
+-----------------+-----------+----------+------------+
| Loopback100 | 100.0.0.1 | up | up |
+-----------------+-----------+----------+------------+
Parsing WEB/парсинг
Простейший get-аналог curl с входом из терминала в виде трех переменных и выводом в терминал.
import requests
import sys
one = sys.argv[1]
two = sys.argv[2]
three = sys.argv[3]
# Set the URL you want to webscrape from
url = 'http://127.0.0.1:2222/?text={}%{}%{}'.format(one, two, three)
# Connect to the URL
print(requests.get(url).text)
Можно оптимизировать используя join c разделителем % и отбросом через slice первого элемента, чтобы на входе были любое количество переменных.
delim = "%"
arg_str = delim.join(sys.argv[1:])
# Set the URL you want to webscrape from
url = 'http://127.0.0.1:2222/?text={}'.format(arg_str)
С utf-8 есть траблы. Вот как решаются:
# Узнать кодировку ответа requests.get(url).encoding # Использовать заданную кодировку на полученный ответ requests.encoding = 'utf-8' # Пример res = requests.get(url) print(res.encoding) res.encoding = 'utf-8' print(res.text)
BeautifulSoup with ssl disable
Примеры парсинга c bs4 HTTP
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = input('Enter - ')
html = urlopen(url).read()
soup = BeautifulSoup(html, "html.parser") # Retrieve all of the anchor tags
tags = soup('a')
2) Выгружаем все с тагом span, далее смотрим в содержимое этого тага и складываем содержимое во всех тагах
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = input('Enter - ')
html = urlopen(url).read()
soup = BeautifulSoup(html, "html.parser")
# Retrieve all of the span tags
tags = soup('span')
summ = 0
for tag in tags:
# Look at the parts of a tag
#print('Contents:', tag.contents[0])
summ = summ + int(tag.contents[0])
print(summ)
HTTPS требует добавления всего нескольких строк и изменения одной:
import ssl
# Ignore SSL certificate errors
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
html = urlopen(url, context=ctx).read()
SSL
Standard library, under the hood использует OpenSSL. Используя Linux + Python + OpenSSL можно создать достаточно высокую нагрузку в CPS (сопоставимую или даже выше специализированной IXIA PerfectStorm). А насчет гибкости тут вообще речи нет – в OpenSSL можно добавить поддержку даже ГОСТ.
Создание графиков (plotly)
import plotly
from plotly.graph_objs import Scatter, Layout
plotly.offline.plot({
"data": [
Scatter(
x=[1, 2, 3, 4],
y=[4, 1, 3, 7]
)
],
"layout": Layout(
title="hello world"
)
})
fig = {
"data": [
Scatter(
x=[1, 2, 3, 4],
y=[4, 1, 3, 7]
)
],
"layout": Layout(
title = "Результат тестирования",
xaxis=dict(
title='X, количество',
titlefont=dict(
family='Courier New, monospace',
size=18,
color='#7f7f7f'
)
),
yaxis=dict(
title='Y, производительность',
titlefont=dict(
family='Courier New, monospace',
size=18,
color='#7f7f7f'
)
)
)
}
plotly.offline.plot(fig, filename = pic_file, auto_open=False)
import plotly.graph_objs as go
fig = {
"data": [
Scatter(
x=[1, 2, 3, 4],
y=[4, 1, 3, 7]
)
],
"layout": Layout(
title = "Результат тестирования",
xaxis=dict(
title='X, количество',
titlefont=dict(
family='Courier New, monospace',
size=18,
color='#7f7f7f'
)
),
yaxis=dict(
title='Y, производительность',
titlefont=dict(
family='Courier New, monospace',
size=18,
color='#7f7f7f'
)
)
)
}
fig = go.Figure(fig)
tb = go.Figure(data=[go.Table(
header=dict(values=['Столбец 1', 'Столбец 2']),
cells=dict(values=[[1,2,3,4,5], [10,20,30,40,50]]))
])
with open('test.html', 'a') as f:
f.write(fig.to_html(full_html=False, include_plotlyjs='cdn'))
f.write(tb.to_html(full_html=False, include_plotlyjs='cdn'))
f.write(fig.to_html(full_html=False, include_plotlyjs=True)) https://plotly.github.io/plotly.py-docs/generated/plotly.html <script src="https://cdn.plot.ly/plotly-2.16.1.min.js">
СОЗДАНИЕ ГРАФИКОВ PyPlot
Помимо plotly так же есть pyplot.
from matplotlib import pyplot as plt
Пример кода TRexDataAnalysis.py в целом по описанию что-то напоминает 🙂
plt.plot_date(x=float_test_time_stamps, y=test_data, label=test.name, fmt='.-', xdate=True)
plt.legend(fontsize='small', loc='best')
plt.xlabel('Index of Tests')
plt.ylabel('MPPS/Core (Norm)')
plt.title('Setup: ' + self.name)
plt.tick_params(axis='x',which='both',bottom='off',top='off',labelbottom='off')
plt.xticks(rotation='horizontal')
plt.xlabel('Time Period: ' + start_date[:-6] + ' - ' + self.end_date)
plt.savefig(os.path.join(save_path, self.name + file_name))
plt.close('all')
Построение графов
- В python хорошая библиотека networkx с встроенным функицоналом работы с графами, включая алгоритмы (см. ниже примеры)
- На практике я использовал graphviz для построение графов при работе с PHP/bash (подробности в Отрисовка сетевых топологий), в python есть соответствующая библиотека (поддерживается).
- Видео по базовой теории графов, кратко:
- вершины как объекты
- ребра как связи между вершинами
- веса ребер (опционально)
- рейтинг вершин
- смежность
- связность
- деревья
- алгоритмы поиска кратчайшего пути (вверх и вниз)
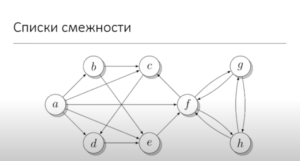


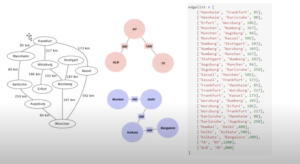
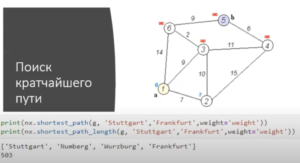
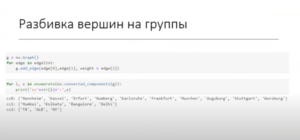
DEBUG/debugger/дебаггера/отладчики
Отладчики зачастую встроены в IDE (PyCharm, VS Code). Позволяют интерактивно (построчно) отслеживать исполнение программы с визуализацией переменных в каждый момент времени. Позволяют не делать 100 тысяч print после каждой строчки кода. Ключем работы с дебаггером является установка breakpoint, при достижении которого по умолчанию программа останавливается, отталкиваясь от него можно построчно исполнять код (step into для всегда построчного исполнения, step over для обхода функций, step out для выхода из функции) и фиксировать 1) значения переменных 2) output программы. В целом в VS Code все крайне удобно на мой взгляд.
Пример базового отладчика – pythontutor.com Позволяет проследить ход исполнения программы, например, понять, как итерируются объекты.
RACE CONDITIONS
На своей практике с данным явлением в python сталкивался при работе с библиотекой wx python. Несколько потоков взаимодействовали с GUI интерфейсом приложения и просиходил конфликт между потоками, который приводил к полному фризу графического интерфейса. Особенность проблемы была в том, что фиксировалась только на низко-производительном CPU на базе Intel Atom и на других платформах никогда не воспроизводилась. Решил конкретно эту проблему отказом от одногоиз thread в пользу запуска его функций в конфликтном без какого либо пользовательского drawback. Потенциально так же можно было бы отказаться от используемых функций в пользу thread save функций (ниже) или с использованием блокировок (lock acquire/release).
GLib-CRITICAL **: Source ID 36 was not found when attempting to remove it
https://www.blog.pythonlibrary.org/2010/05/22/wxpython-and-threads/ https://wiki.wxpython.org/LongRunningTasks In the wxPython world, there are three related “threadsafe” methods. If you do not use one of these three when you go to update your user interface, then you may experience weird issues. Sometimes your GUI will work just fine. Other times, it will crash Python for no apparent reason. Thus the need for the threadsafe methods. The following methods are thread-safe: wx.CallAfter wx.CallLater wx.PostEvent
https://digitrain.ru/articles/304806/ Проблема с условиями гонки может привести к катастрофическим последствиям для кода, поэтому параллельное выполнение потоков следует использовать с осторожностью. Библиотеки Python, такие как threading, lock, могут помочь нам решить эту проблему. from threading import Thread,Lock x = 1 #Shared resource #Initialize an instance of object Lock lock_race = Lock() # аналог lock_race=thread.allocate_lock() try: lock_race.acquire() finally: lock_race.release()
Ассинронные функцит, Что такое корутина/coroutine
-
- Краткое описание работы с асинхронными функциями: создание асинхронной функции, создание объекта корутины из асинхронной функции, помещение его в event loop, запуск event loop напр. Run until complete и обработка результатов, которая функция вернула
- Как работают корутины:
- Изначально корутина придумана не для асинхронной обработки, но именно там она чаще всего используется. Корутина похожа на генератор, отличается тем, что у нее yeild находится “с другой стороны”, а в ранних версиях python с помощью генераторов (yeild from) делались корутины.
- asyncdev (async/await) асинхронно запускает корутины, с помощью ключевого слова await задаются breakpoint в которых компилятор python может остановится и отдать исполнение другому потоку до события в потоке который мы ожидаем
Определения
-
-
- Корутины (coroutines) – это сопрограммы. Сопрограмма – особый вид функции, которая реализует взаимосовместимость через кооперативную многозадачность.
- Корутины – Это основа асинхронного программирования на Python и фундаментальный стройматериал инфраструктуры асинхронного ввода-вывода (async i/o).
- Coroutine (корутины), или сопрограммы — это блоки кода, которые работают асинхронно, то есть по очереди. В нужный момент исполнение такого блока приостанавливается с сохранением всех его свойств, чтобы запустился другой код. Когда управление возвращается к первому блоку, он продолжает работу. В результате программа выполняет несколько функций одновременно.
- Сопрограммы — это потоки исполнения кода, которые организуются поверх системных потоков. Поток исполнения кода — это последовательность операций, выполняющихся друг за другом. Она исполняется, пока не наступит момент, который задан в коде или определен разработчиком. Затем может начать выполняться часть другой последовательности операций. В системных потоках содержатся инструкции процессора, на одном его ядре могут по очереди работать разные системные потоки. Корутины работают на более высоком уровне: несколько сопрограмм могут поочередно выполнять свой код на одном системном потоке. Для конечного пользователя работа корутин выглядит как несколько действий, которые выполняются параллельно.
-
Для чего нужны корутины
-
-
- Для создания асинхронных приложений, которые могут выполнять несколько действий одновременно.
- Для гибкой и удобной реализации многозадачности.
- Для большего контроля при переключении между разными задачами.
- Корутинами управляют разработчик и программа, а не операционная система. Потоками управляет операционная система. Переключением корутин — разработчик с помощью кода.
- Для снижения нагрузки на аппаратные ресурсы устройства. Потоки ускоряют выполнение сложной задачи, но отнимают много ресурсов. Корутины не повышают скорость, но помогают оптимизировать нагрузку.
-
Ускорения; GIL, многопоточность, многопроцессность, асинхронность; ASYNCIO, EPOlL
- Для ускорения python можно почитать эту статью
- Про Cython выше “Использование Cython — один из самых мощных способов оптимизации”
Асинхронность в данном разделе нужна т.к. решает ту же задачу ускорения обработки, но по факту к GIL/RC и multiproc/multithreads отношение она имеет опосредованное. Реализация асинхронности позволяет снять блокировку ожидания потоком неких IO данных (на IN/OUT, напр. API/HTTP/SNMP/BD) задачи и вместо ожидания ответа обрабатывать другую задачу (в этом же потоке) и так до тех пор пока не придет callback от ранее запущенных задач. Асинхронная неблокируемая обработка нескольких потоков (в примере ниже обработка соединений в сокетах) в python реализуется за счет:
-
- select + poll/epoll и их прямого использования select.epoll()
- asyncio в виде удобного “синтаксического сахара”/корутин над асинхронными функциями select/poll/epoll (или другими), который управляется с использованием async/await:
How does asyncio work? https://stackoverflow.com/questions/49005651/how-does-asyncio-actually-work https://www.linux.org.ru/forum/development/14645644Python 3.4, asyncioДопустим у меня стоит задача опроса состояния GPIO-пина и выполнения некоторых действий в связи с этим. Я могу поступить по-простому: - завернуть пару-тройку for-while циклов, сделать в них poll состояния и логику того, что делать если состояние изменилось. - А могу использовать asyncio. И я пока не понимаю, чем он отличается от такой же for-loops по большому счету, кроме того что представляет некоторую абстракцию над ними. Ну то есть читаемость - да, улучшается. - asyncio в питоне это асинхронщина построенная на спрятанных тредах и мультиплексорах. asyncio синтаксический сахар над ними. - asyncio просто аккуратно эти fd в epoll засунет. Идея в том, что мы делаем read/write над обычными fd, но с флагом NONBLOCK - который гарантирует, что процесс не войдёт в Sleep state, а вернёт errno = WOULDBLOCK. Дальше если всё что мы хотим читать/писать вернуло WOULDBLOCK - вручную вызываем sleep state на сразу множество fd. После просыпания ядро гарантирует (почти), что один из fd можно читать-писать без блокировки (есть данные в буфере). asyncio это всё автоматизирует синтаксическим сахаром до уровня как будто бы мы используем несколько тредов.
https://stackoverflow.com/questions/39145357/python-error-socket-error-errno-11-resource-temporarily-unavailable-when-s In the server you are setting the remote socket (that returned by accept()) to non-blocking mode setblocking(0), which means that I/O on that socket will terminate immediately by an exception if there is no data to read. There will usually be a period of time between establishing the connection with the server and the image data being sent by the client. The server attempts to immediately read data from the client once the connection is accepted, however, there might not be any data to read yet, so c.recv() raises a socket.error: [Errno 11] Resource temporarily unavailable exception. Errno 11 corresponds to EWOULDBLOCK, so recv() aborted because there was no data ready to read. Your code does not seem to require non-blocking sockets because there is an accept() at the top of the while loop, and so only one connection can be handled at a time. You can just remove the call to c.setblocking(0) and this problem should go away. But what do I do, if the server is supposed to get multiple connection? That's another problem. You can use select() to determine which of multiple sockets are ready to read, and then call recv() on those that are. You would also add the main server socket to the list of sockets passed to select() and call accept on that socket whenever select() indicates that it is readable. There are alternatives in the select module such as poll() et. al. You might also consider using the selectors module or asyncio if you are using Python 3.4 or later. asyncore is an option on Python 2.
Потоки сами по себе – сущности одного процесса с общими ресурсами на исполнение (RAM). Проблема GIL (и RACE CONDITIONS во вторую очередь) о потокобезопасном управлении памяти, она справедлива для многих языков в их популярных версиях – Python, Ruby, JavaScript. Проблема в том, что многопоточный код python из-за GIL при cpu bound задачах, затрагивающих непосредственно обработку интерпретатором CPython, не исполняется одновременно на разных ядрах (на одном в любом случае не исполняется одновременно т.к. происходит context switching) из-за блокировки интерпретатором. Соответственно и смысл – если задача cpu bound, то из-за gil она не будет ускорена.
При этом проблема с GIL возникает она далеко не всегда и имеет решения:
Если что, в Python GIL - это и есть, по сути своей, mutex, который контролирует доступ к состоянию процесса интерпретатора. Многопоточный код писать на Python еще как можно, если он касается задач ввода/вывода.
-
- проблема GIL затрагивает только работу нескольких потоков в рамках одного процесса (разделение общих ресурсов данных процесса несколькими потоками) и GIL не затрагивает несколько независимых однопоточных процессов, в том числе, порожденных родительским (см. «чистый» multiprocessing ; но не multiprocessing ThreadPool, он использует threads, подверженные gil)
- GIL не затрагивает ситуации, когда потоки высвобождают GIL в ожидании IO (read/write) операций (IO bound) – поэтому в моих кейсах работы с многопоточностью и сетевыми задачами она работала неплохо в ruby/python (сетевые запросы по snmp/icmp и запросы в локальную БД), аналогично мне известны и другие достаточно высокопроизводительные сетевые обработчики, использующие python (CPS + TLS generator, SNMP trap receiver)
- GIL не затрагивает ситуации, когда CPU bound задачи создаются отличным от CPython (и не подверженным GIL) интерпретатором, например
- за счет вызова функций/модулей, написанных на C
- за счет использования алтернативных интерпретаторов Jython, IronPython
Кратко можно послушать тут:
GIL расшифровывается как Global Interpreter Lock (Глобальная блокировка интерпретатора), и его задача состоит в том, чтобы сделать интерпретатор CPython потокобезопасным.
Первый эффект GIL хорошо известен: несколько потоков Python не могут работать параллельно. Таким образом, многопоточная программа не ((ВСЕГДА)) будет быстрее, чем ее однопоточный эквивалент, даже на многоядерной машине.
-
- Переход от одного потока к двум почти в 2 раза ускоряет выполнение, потому что потоки выполняются параллельно. Добавление дополнительных потоков не сильно помогает, потому что на моей машине всего два физических ядра. Вывод здесь заключается в том, что можно ускорить процессорно-интенсивный код Python с помощью многопоточности, если код вызывает функции C, которые освобождают GIL. Обратите внимание, что такие функции можно найти не только в стандартной библиотеке, но и в мощных сторонних модулях, таких как NumPy. Вы даже можете самостоятельно написать расширение C, которое выпустит GIL.
- На самом деле многопоточные программы могут работать ((ДАЖЕ)) медленнее из-за накладных расходов, связанных с переключением контекста. Интервал переключения по умолчанию составляет 5 мс, поэтому переключение контекста происходит не так часто. Но если мы уменьшим интервал переключения, мы увидим замедление.
ТИПИЗАЦИЯ
Python – язык с динамической типизацией – переменным не обязательно задавать тип. При этом с python 3.6 никто не запрещает создавать переменные в стиле C с заведомым указанием (аннотацией) типов и в целом это даже приветствуется – так всем понятнее с чем на входе и на выходе работает код.
variable: type = value >>> var1: int = 10 >>> print(var1) 10 >>> type(var1) <class 'int'>
Пример функции:
def concat(a: int, b: int) -> str:
return f"{a} {b}"
А так она будет выглядеть, если добавить default values.
def concat(a: int=5, b: int=6) -> str:
return f"{a} {b}"
Ранее (deprecated):
from typing import List x: List[int] = []
Сейчас:
x: list[int] = []
Чтобы узнать тип логично использовать функцию type(). Пример:
>>> import logging
>>> logger = logging.getLogger()
>>> type(logger)
<class 'logging.RootLogger'>
>>> import binascii
>>> word = binascii.unhexlify('44444f5348696768506572660000000000010' + '2030405060708090a0b0c0d0e0f1011121314151617')
>>> word
b'DDOSHighPerf\x00\x00\x00\x00\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17'
>>> type(word)
<class 'bytes'>
SQL
- Обычно при разработке архитектуры последовательность такая – создается схема БД, далее на основе схемы в БД создаются модели в фреймворке и на основе этой модели создаются бизнес-сущности, вокруг которых и крутится логтка приложения.
В Python в качестве стандартной библиотеки включен sqlite3 и его достаточно для основных/базовых задач. Базовый пример:
import sqlite3
con = sqlite3.connect('example.db')
cur = con.cursor()
# Create table
cur.execute('''CREATE TABLE stocks
(date text, trans text, symbol text, qty real, price real)''')
# Insert a row of data
cur.execute("INSERT INTO stocks VALUES ('2006-01-05','BUY','RHAT',100,35.14)")
# Save (commit) the changes
con.commit()
# Get data
for row in cur.execute('SELECT * FROM stocks ORDER BY price'):
print(row)
# We can also close the connection if we are done with it.
# Just be sure any changes have been committed or they will be lost.
con.close()
sqlalchemy
Используется чаще всего с ООП, чаще всего используется функционал ORM (object relational mapping). Реализует по сути абстракцию/доп.прослойку между базой и кодом – сущности в базе маппятся на объекты (экземпляры классов)/бизнес сущности, которые создаются в твоем коде – т.е. за тебя ORM создает в коде бизнес сущности из базы. Sql alchemny по сути реализует соответствие принципу инверсии зависимостей – высокоуровневый код не должен зависеть напрямую от низкоуровневого, а должен зависеть от абстракций (которые в свою очередь не должны зависеть от деталей реализации, а наоборот – детали должны зависеть от абстракций).
В sql alchemy так же есть конструктор запросов ORA – позволяет создавать базовые запросы, не погружаясь в специфику SQL.
clickhouse
- Подключенте к clickhouse с помощью панда хаус, работа так же через него.
Pandas interface for Clickhouse HTTP API.
рекурсия
Решение разных задач, в том числе на алгоритмы
What’s new in new python versions
WALRUS python 3.8 # whithout WALRUS data = get_data() while data is not None: process(data) data = get_data() # with WALRUS while (data := get_data()) is not None: process(data)
some_funct(a,b,/):
раньше
f'var={var}'
сейчас можно
f'{var=}'
результат один
'var=var_value'
ошибки
Ошибка
TabError: inconsistent use of tabs and spaces in indentation
Появляется если разные разделители (tab and spaces), нужно к одному привести (лучше в соответствии с pep8 4 spaces вместо каждого tab). Проще всего это сделать используя sublime text, у него есть полезная функция по конвертации в один формат – View -> Indentation -> Convert Indentation to tabs/spaces.
Меняем byte object на string
strng.decode() #a bytes-like object is required, not 'str'
Меняем string на byte object
btobj.encode() #cannot use a string pattern on a bytes-like object
Ошибка
UnboundLocalError: local variable 'exection_timeout' referenced before assignment
Появляется когда объявили глобальную переменную и захотели переназначить ее в методе. Можно исправить сделав ее глобальной, можно передать explicit в метод при его вызове и уже после этого переназначить внутри метода.
Не поддерживается except по ‘FileNotFoundError’, вместо него можно использовать IOError.
FileNotFoundError apparently doesn't exist in python 2.7 . a1ee437 should fix this. except FileNotFoundError: NameError: global name 'FileNotFoundError' is not defined except IOError: