
https://regexr.com/ – хороший сайт для создания regexp
http://www.pcre.org/original/doc/html – прекрасная документация к самому популярному синтаксису regexp
man 7 regex – базовое описание регулярных выражений
regex - POSIX.2 regular expressions
Regular expressions ("RE"s), as defined in POSIX.2, come in two forms: modern REs (roughly those of egrep; POSIX.2 calls these "extended" REs) and obsolete REs (roughly those of ed(1); POSIX.2 "basic" REs). Obsolete REs mostly exist for backward compatibility in some old programs
- Ускорить regexp могут детерминированные конечные автоматы, типо таких, которые реализует Intel Hyperscan
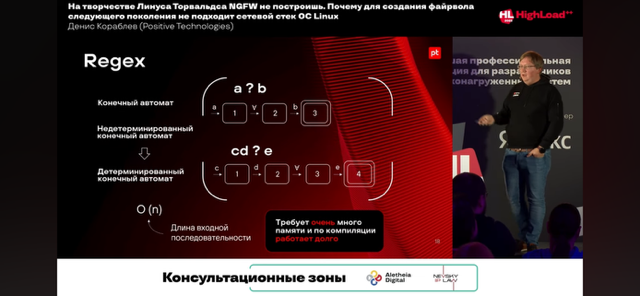
Regexp используются очень широко, в том числе в сетевом оборудовании:
- В целом регулярные выражения (а точнее pattern matching) используются везде в ngfw – антивирус, IPS, DPI, URLF
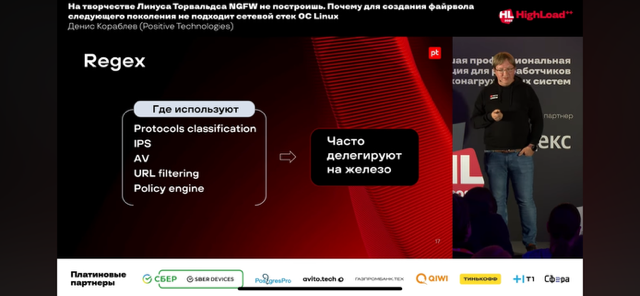
- У Titan IC есть RXP (regular expression processor), который интегрируется с чипами Mellanox; Mellanox купила Titan IC и судя по всему выходит на рынок DPI/SEC (IDS/IPS/etc).
“We have worked with Mellanox for many years to integrate our RXP regular expression processor into their advanced line of BlueField I/O Processing Units (IPUs). Now as part of Mellanox, we will be able to achieve new capabilities for cyber intelligence, intrusion detection and protection, and advanced data analytics applications,” said Noel McKenna, CEO, Titan IC. Our customers will benefit from the deep analytics and enhanced security that will be delivered by the integration of our best-in-class Ethernet and InfiniBand products and world-leading deep packet inspection and analytics technologies from Titan IC.
cisco3850# show interfaces Te1/4 | i packets .*put 1385 packets input, 193568 bytes, 0 no buffer 0 packets output, 0 bytes, 0 underruns
Router# sh run | include ^interface|^ ip address interface Tunnel0 ip address 10.255.0.1 255.255.255.0 interface Tunnel3 interface Tunnel4 interface Ethernet0/0 ip address 15.0.0.1 255.255.255.0 interface Ethernet0/1 ip address 10.1.1.1 255.255.255.0 interface Ethernet0/2 ip address 10.101.1.1 255.255.255.0 interface Ethernet0/3 interface Ethernet1/0 interface Ethernet1/1
Router# show ip bgp regexp 108$ BGP table version is 1738, local router ID is 172.16.72.24 Status codes: s suppressed, * valid, > best, i - internal Origin codes: i - IGP, e - EGP, ? - incomplete Network Next Hop Metric LocPrf Weight Path * 172.16.0.0 172.16.72.30 0 109 108 ? * 172.16.1.0 172.16.72.30 0 109 108 ? * 172.16.11.0 172.16.72.30 0 109 108 ? * 172.16.14.0 172.16.72.30 0 109 108 ?
Работа с регулярными выражениями в конкретных языка/инструментах есть тут:
check_ip() {
IP_REGEX='^(([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([0-9]|[1-9][0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])$'
printf '%s' "$1" | tr -d '\n' | grep -Eq "$IP_REGEX"
}
regexp нужны для парсинга/поиска вхождения данных в строку. Описываются формальным языком, который интерпретируется движком регулярных выражений. По сути это язык программирования символами, старый и довольно “стремный” – одни скобки означают набор символов, другие – начало и конец извлечения данных. В программировании рекомендуют их использовать умеренно, т.к. читаемость “кода” регулярного выражения может быть довольно сложной задачей. Так же как и другой код, его обязательно нужно тестировать.
A regular expression is written in a formal language that can be interpreted by a regular expression processor. They're kind of fun, like a whole programming language in characters. This is a very, very cryptic and arcane language: brackets means the beginning of a set of characters, parenthesis means start extracting, other parenthesis means stop extracting. I would suggest you don't overuse them. It's really important that you test your code, so that you see kind of weird anomalies. Charles R. Severance
При использовании regexp всегда надо помнить, что если операция простая и осуществима методами строк – то скорей всего использование regexp излишне и приведет только к более долгому исполнению (на больших объемах). Зачастую методы поиска строк используются как предфильтр (своего рода guardian pattern) перед регулярным выражением (например, можно встретить запрет использования только regexp без предфильтра content в правилах написания сигнатур для snort) – отлавливаем только строки, которые потенциально могут подпадать под regexp, а далее уже анализируем движком regexp.
- Always put pcre checks after one or more content checks - Never start your rule with a pcre keyword or use pcre as the only keyword in the rule
Спец. символы
^ – начало строки или отрицание при использовании в [] (см. ниже и примеры в языках программирования)
$ – конец строки
* – астериск/звездочка (asterisk) означает любое количество символов в строке, предшествующих “звездочке”, в том числе и нулевое число символов.
Выражение "1133*" -- означает 11 + один или более символов "3" + любые другие символы: 113, 1133, 113312, и так далее.
+ – матчит любое количество символов в строке, предшествующих плюсу, но не нулевое число символов (в отличии от *), часто используется для обозначения одного продолженного элемента – напр. извлечь не каждый символ integer из строки, а все полные (продолженные) числа
# python example 1 line = "sdf777sdf fdsf mm 5554351 fdfm mg 77 sdfsdf 6 fdsf2s" res = re.findall(r'\d', line) ['7', '7', '7', '5', '5', '5', '4', '3', '5', '1', '7', '7', '6', '2'] # python example 2 line = "sdf777sdf fdsf mm 5554351 fdfm mg 77 sdfsdf 6 fdsf2s" res = re.findall(r'\d+', line) ['777', '5554351', '77', '6', '2']
. – точка совпадает с любым одиночным символом, за исключением символа перевода строки (\n). Сделать так, чтобы срабатывала и на \n обычно можно с помощью флага, например в Python это DOTALL.
Выражение "13." будет означать 13 + по меньшей мере один любой символ (включая пробел): 1133, 11333, но не 13 (отсутствуют дополнительные символы).
.* – точка совместно со звездочкой означают подпадание любого (в том числе ненулевого) количества символов
? – вопросительный знак означает что знак перед вопросительным является опциональным (может отсутствовать), так же с помощью вопросительного знака можно матчить более тонко/коротко/менее жадно (non-gready matching). По умолчанию символы повторения (напр. * и +) жадные (gready) и будут всегда отображать наиболее длинный match.
Greedy Matching says you're going to get back the larger thing. Надо заматчить From: в строке: "From: Using the : character"
# Пример regexp для решения задачи ^F.+?: # полный regexp, где: ^ - начало строки . - любой символ + - минимум одно подпадание ? - non-gready (короткое подпадание) : - конкретный символ
| – параллель используется как оператор “или”
cisco1#show ip interface brief | i Inter|t1/0/[2][0-4] Interface IP-Address OK? Method Status Protocol FastEthernet1/0/20 192.168.1.49 YES NVRAM administratively down down FastEthernet1/0/21 192.168.119.113 YES NVRAM up up FastEthernet1/0/22 unassigned YES unset up up FastEthernet1/0/23 192.168.12.25 YES NVRAM up up FastEthernet1/0/24 unassigned YES unset up up
\ – обратный слэш служит для экранирования специальных символов (рассмотренных тут), это означает, что экранированные символы должны интерпретироваться буквально, т.е. как простые символы.
Комбинация "\$" указывает на то, что символ "$" трактуется как обычный символ, а не как признак конца строки в регулярных выражениях. Аналогично, комбинация "\\" соответствует простому символу "\".
X670-48x.1 # show lldp ports 1-48 neighbors detailed | i ": 10\." Management Address : 10.6.9.129 Management Address : 10.6.10.129 Management Address : 10.6.12.1 Management Address : 10.6.11.129
\s – матчим пробел и спец. символы (whitespace characters)
AB\sC = "AB C"
\S – матчим все кроме whitespace characters, с помощью только \S+ можно извлекать столбцы (по примеру awk).
$ python3 ./test.py
['toster@weril.me']
import re
line = "From toster@weril.me at Sat Jan 13 01:01:01 2019"
res = re.findall("^From (\S+@\S+)", line)
print(res)
\d – является сокращением для [0-9], очень круто, особенно когда цифр много, например /\d{3}/ – подпадание любых трех цифр, \d+ – подпадание всех цифр (без нулевого). Может использоваться как простейший regexp для отлова IP-адреса.
\D – любой символ, кроме цифр
\w – любая буква или цифра
\w+ # матчим слово (буквы или цифры до whitespace)
\W – все, кроме букв или цифр
ФЛАГИ
i/ignorecase – с помощью этого символа в конце регулярного выражения делаем его caseinsensitive, очень полезно. Причем работает даже для русских символов.
@feedback = /^(feedback|отзыв)/i
dotall – сделать так, чтобы точка срабатывала и на \n.
Конструкции
[] – группа, обозначающая один символ. Используя спец. символы * и + группа может обозначать ряд символов.
- [ ] – подпадение всего пробела
- [^ ] – подпадение всего, кроме пробела
- [fFkal] – подпадание любой буквы из списка
- [^fFam] – подпадание буквы, отсутствующей в списке
- [a-z] – подпадание любой буквы из алфавита в нижнем регистре
- [a-zA-Z] – подпадание буквы в любом регистре
- [а-яА-Я] – аналогично кириллица
- [0-9] – подробнее в \d
# Пример поиска домена почты
$ python3 ./test.py
['weril.me']
line = "From toster@weril.me at Sat Jan 13 01:01:01 2019"
res = re.findall("^From .*@([^ ]*)", line)
print(res)
# Пример поиска всех цифр из строки и вычисления их суммы
$ python3 ./test.py
27486
line = '''Why should you learn to write programs? 7746
12 1929 8827
Writing programs (or programming) is a very creative
7 and rewarding activity. You can write programs for
many reasons, ranging from making your living to solving
8837 a difficult data analysis problem to having fun to helping 128
someone else solve a problem. This book assumes that
everyone needs to know how to program ...'''
res = re.findall("[0-9]+", line)
res = map(int, res)
print(sum(res))
() – выражение в скобках рассматривается как один элемент и автоматически является группой для подпадания (matching group), позволяет получить из подпавшей под полное выражение строки конкретную группу (пример выше так же подходит).
$ python3 ./test.py
['0.432423']
import re
line = "kakayato chush = 0.432423"
res = re.findall("^kakayato chush = ([0-9.]+)", line)
print(res)
{3} – повторяем три раза предыдущий элемент или выражение в скобках (напр. () или []).
\d{8} matches exactly 8 digits. An opening curly bracket that appears in a position where a quantifier is not allowed, or one that does not match the syntax of a quantifier, is taken as a literal character. For example, {,6} is not a quantifier, but a literal string of four characters.
{3, } – матчит от трех и более повторений.
[aeiou]{3,} matches at least 3 successive vowels, but may match many more, while
z{2,4} – повторения. От 2 до 4 z: матчит zz, zzz, zzzz. Если убрать четверку, но оставить запятую (применяется довольно часто) – то нет лимита сколько zz будет, главное не меньше двух. Если убрать и второе число и запятую – то матчится будет только ровно два z.
z{2,4} matches "zz", "zzz", or "zzzz". A closing brace on its own is not a special character. If the second number is omitted, but the comma is present, there is no upper limit; if the second number and the comma are both omitted, the quantifier specifies an exact number of required matches.
Q
What does the + symbol mean in the following grep regular expression: grep ‘^d[aei]\+d$’ /usr/share/dict/words
A. Match the preceding character set ([aei]) one or more times.
B. Match the preceding character set ([aei]) zero or more times.
C. Match the preceding character set ([aei]) zero or one times.
D. Match a literal + symbol.
A
Given the following input stream: txt1.txt atxt.txt txtB.txt Which of the following regular expressions turns this input stream into the following output stream? txt1.bak.txt atxt.bak.txt txtB.bak.txt
A. s/^.txt/.bak/
B. s/txt/bak.txt/
C. s/txt$/bak.txt/
D. s/^txt$/.bak^/
E. s/[.txt]/.bak$1/
Answer:C
Explanation
The correct answer is C, s/txt$/bak.txt/. This regular expression will turn the input stream into the desired output stream by using the s command, which is used to substitute or replace a pattern with another pattern.
The syntax of the s command is:
s/pattern/replacement/
The pattern is the regular expression that matches the text to be replaced, and the replacement is the text that replaces the matched text. The / symbol is used as a delimiter to separate the pattern and the replacement, but other characters can be used as well.
The pattern in this regular expression is txt$, which means that it will match the string txt at the end of the line.
The $ symbol is an anchor that matches the end of the line. The replacement in this regular expression is bak.txt, which means that it will replace the matched string with the string bak.txt.
Therefore, the command s/txt$/bak.txt/ will replace the string txt at the end of each line with the string bak.txt, resulting in the following output stream:
txt1.bak.txt atxt.bak.txt txtB.bak.txt
The other regular expressions are incorrect for the following reasons:
* A, s/^.txt/.bak/: This regular expression will not work as expected, because it has several errors. First, the pattern in this regular expression is ^.txt, which means that it will match the string .txt at the beginning of the line. The ^ symbol is an anchor that matches the beginning of the line. However, none of the lines in the input stream start with .txt, so the pattern will not match anything. Second,the replacement in this regular expression is .bak, which means that it will replace the matched string with the string .bak. However, this will not produce the desired output, because it will not append the string
.txt to the end of the line, but rather replace the existing string with .bak.
* B, s/txt/bak.txt/: This regular expression will not work as expected, because it has several errors. First, the pattern in this regular expression is txt, which means that it will match the string txt anywhere in the line, not just at the end. This will cause unwanted replacements in the middle of the words, such as atxt and txtB. Second, the replacement in this regular expression is bak.txt, which means that it will replace the matched string with the string bak.txt. However, this will not produce the desired output, because it will not preserve the original string, but rather replace it with bak.txt.
* D, s/txt$/.bak/: This regular expression will not work as expected, because it has several errors. First, the pattern in this regular expression is ^txt$, which means that it will match the string txt only if it is the entire line. The ^ and $ symbols are anchors that match the beginning and the end of the line, respectively. However, none of the lines in the input stream are exactly txt, so the pattern will not match anything. Second, the replacement in this regular expression is .bak^, which means that it will replace the matched string with the string .bak^. However, this will not produce the desired output, because it
* will not append the string .txt to the end of the line, but rather replace the existing string with .bak^, which is not a valid file name.
* E, s/[.txt]/.bak$1/: This regular expression will not work as expected, because it has several errors. First, the pattern in this regular expression is [.txt], which means that it will match any one of the characters inside the brackets, which are ., t, and x. This will cause unwanted replacements of single characters, such as the dot in the file extension or the letter t in the word atxt. Second, the replacement in this regular expression is .bak$1, which means that it will replace the matched character with the string .bak followed by the first backreference. A backreference is a way to refer to a part of the pattern that was captured by parentheses. However, there are no parentheses in the pattern, so the backreference $1 is invalid and will not work. Third, the replacement in this regular expression will not produce the desired output, because it will not append the string .txt to the end of the line, but rather replace the existing character with .bak$1, which is not a valid file name.
Which wildcards will match the following filenames? (Choose two.) ttyS0 ttyS1 ttyS2
A. ttyS[1-5]
B. tty?[0-5]
C. tty*2
D. tty[A-Z][012]
E. tty[Ss][02]
Answer: BD B and D are correct. A doesn't include 0, C is definitely wrong and E doesn't include 1. root@serv:~# ls tty?[0-5] ttyS0 ttyS1 ttyS2 root@serv:~# ls tty[A-Z][012] ttyS0 ttyS1 ttyS2