


- о code review / код ревью
- (Мониторинг, devops) Как tivoli менеджер проникся puppet и практиками devops для эксплуатации


Развитие технология, изменение стеков, изменение подходов
- Era: mainframe – client/server – cloud
- Language: cobol – c – java
- Cycle time: Years – months – weeks
- Costs: Billion – million – 100k
- Risks: company – product – feature

Разные цели эксплуатации и разработки (operations & development)


Программирование Best Practices

-
Почему все не стоит писать на С: Потому что в абсолютном большинстве веб приложений бутылочным горлышком является база данных, а не код приложения. Нет смысла тратить в разы больше ресурсов для улучшения производительности на 5%.
-
Почему исполняемый файл имеет зачастую большой объем: Например, если скомпилировать hello world на go, то он будет весить 2-3 мегабайта, потому что в бинарнике будет весь рантайм (сборщик мусора и всякие библиотеки для работы с IO операционной системы). Можно компилировать без системных зависимостей, но тогда придется мучиться со всякими системными библиотеками. Такой подход используют для embedded devices.
- Соответствие кода best practice (code style, security и проч) могут проверять как IDE, так и отдельные мощные продукты типа SonarQube.
- Программист – это прикладная профессия, программист поэтому должен уметь писать код в первую очередь, нужен ли кому то программист, не умеющий писать код – риторический вопрос).
- Так же для командной разработки жизненно необходимо разбираться в чужом коде, codestyle, архитектуре, уметь интегрироваться с разными продуктами, ревьюить, использовать корректные подходы/паттерны, знать теорию так же обязательно нужно. Работа в команде это стандартная работа программиста – в среднем продукт это сто и больше тысяч строк кода, несколько лет люди над ним работали, несколько программистов.
- Code review/document review – крайне важный аспект в программировании в каких-либо командах, помимо покрытия этого вопроса инструментами вроде git/tfs есть отдельные инструменты типо smartbear Collaborator
- Для отладки кода использовать debuggers, а не print/logging функции, пример в Python (при этом даже middle dev зачастую ищут проблему через print)
- Тестирование крайне важный аспект программирования, каждый программист должен уметь тестировать свой код и исключать основные потенциальные проблемы в коде еще на моменте его написания; в том числе в алгоритмических собеседованиях проверяются навыки программиста по составлению тест-кейсов путем генерации тестовых данный на вход разрабатываемому алгоритму до написания кода
- Если разработчик хотя бы базово тестирует код перед тем, как отдать его в QA, это ускорит выкладку кода в продакшен.
- Разработчик знает особенности реализации и может подумать о таких тестах, которые могут не прийти в голову тестировщику.
- Стараться не повторять код, Code reuse, переиспользование кода – критичный аспект в программировании всегда был и остается сейчас.
- использовать функции
- использовать чужой код (библиотеки/library и проч)
- иногда программы поставляются сразу с необходимыми для своей работы зависимостями и не разделяют библиотеки с другими программами – snap пакеты (отображаются обычно как отдельные разделы в df -h), docker контейнеры и проч сущности
- но есть и разделяемые библиотеки на уровне системы (расширение .so, следит/собирает их в каталог library daemon – ld с конфигом в /etc/ld.so.conf.d) – в Linux так много системных библиотек, одних директорий только в которых могут быть библиотеки не мало (от одной директории lib как самой главной до как минимум 4 в актуальных системах; библиотеки находятся в /usr/, но линки на них сделаны в / и могут быть и в других местах), обычно внутри содержится короткое имя библиотеки и одна или несколько версий этой библиотеки, на одну из которых ссылается короткое имя. Есть так же очень полезная команда ldd (library daemon dependencies), которая показывает какие библиотеки использует приложение. Для установки библиотек не рекомендуется просто копировать их в системные директории через cp, рекомендуется копировать их в локальную для пользователя директорию lib, точно так же как и бинарники в локальнаю bin и указывать новую директорию для поиска ldconfig (командой ldconfig -n /home/user/lib или созданием конфига с путем к новой директории в /etc/ld.so.conf.d).
# ls /
bin lib mnt sys
boot lib32 opt tmp
dev lib64 proc usr
etc libx32 root var
home log.conf run vmlinuz
initrd.img lost+found sbin vmlinuz.old
initrd.img.old media srv
# ls /usr/lib/libdiscover.so.2*
/usr/lib/libdiscover.so.2
/usr/lib/libdiscover.so.2.0.1
# ldconfig - v
/usr/local/lib:
/lib/x86_64-linux-gnu:
librte_latencystats.so.18.11 -> librte_latencystats.so.18.11
librte_pdump.so.18.11 -> librte_pdump.so.18.11
libapparmor.so.1 -> libapparmor.so.1.6.0
libfastjson.so.4 -> libfastjson.so.4.2.0
libncursesw.so.6 -> libncursesw.so.6.1
libgcc_s.so.1 -> libgcc_s.so.1
…
# cat /etc/ld.so.conf.d/x86_64-linux-gnu.conf
# Multiarch support
/usr/local/lib/x86_64-linux-gnu
/lib/x86_64-linux-gnu
/usr/lib/x86_64-linux-gnu
# type ping
ping является /usr/bin/ping
# ldd /usr/bin/ping
linux-vdso.so.1 (0x00007fffdd497000)
libidn.so.11 => /lib/x86_64-linux-gnu/libidn.so.11 (0x00007f0935322000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f0935162000)
/lib64/ld-linux-x86-64.so.2 (0x00007f093557b000)
Хорошее описание, зачем используется LD_LIBRARY_PATH – переопределение библиотек.
LD_LIBRARY_PATH is the predefined environmental variable in Linux/Unix which sets the path which the linker should look in to while linking dynamic libraries/shared libraries.
LD_LIBRARY_PATH contains a colon separated list of paths and the linker gives priority to these paths over the standard library paths /lib and /usr/lib. The standard paths will still be searched, but only after the list of paths in LD_LIBRARY_PATH has been exhausted.
The best way to use LD_LIBRARY_PATH is to set it on the command line or script immediately before executing the program. This way the new LD_LIBRARY_PATH isolated from the rest of your system.
- Стараться делить большой/сложный код на отдельные простые функции
- Если можно написать без усложнений универсальный код для покрытия краевых случаев/edge case – это стоит сделать
- Даже если язык case-sensitive (переменная Var != var), не стоит это использовать
- Даже если в языке не задано ограничение по неймингу переменных/функций/классов, стоит использовать стандарты
- Даже если язык позволяет назвать одинаково переменную и функцию/метод, не стоит это использовать
- Страуструп “язык программирования c++” считается очень сильной книгой для программистов, которую мало кто может полностью прочитать и понять
- https://habr.com/ru/articles/929024/ «Как один глупый Bash-скрипт сэкономил нам 100 часов ручной работы» – О том что главное решать задачу и для решения можно использовать в том числе программирование на bash
- Идеология PHP от создателя Rasmus Lerdord:
- лучше иметь плохо работающий в каких то условиях функционал/библиотеку, но который позволяет решить задачи, чем не иметь функционала вообще. Если вы спорите без предложения альтернативной реализации (просто ноете) – вы скорей всего проиграете спор. https://ihts.pr4e.com/columns/2012-11-Rasmus-Lerdorf-Copyright-IEEE.pdf
If someone wants to disagree with that way of doing things, or if they can offer an alternative implementation, that's a really good argument. If all they do is whine about it, that's a really bad argument, and chances are, the implementation will win even though it might not be the best way of doing things. If there's code and it sort of works, that's what we go with, and that has always been the default. It doesn't always lead to consistency, but it does lead to getting new features and actually being able to do something.
Being able to connect to this type of database even though it might not be the best way of doing it, at least it gets you there. That's what PHP has always been about-solving a problem. We would rather have an ugly feature than not have a feature at all.

-
- я изначально не интересовался программированием – для меня это было средство решения моих задач и программирование было дотошным/скучным. Я старался минимизировать время, которое посвещаю программированию, отсюда появился PHP – его первая версия позволяла мне очень быстро реализовывать проекты клиентам)))) уже потом люди начали интересоваться и привносить свою лепту и я поделился своим проектом – я продавал услуги решения проблем, не инструмент (мой “hammer”). И люди сдавали мне баги, а я их фиксил у клиентов, которые удивлялись моей продуктивности)) Это был 1994, до того как термин open source еще появился. В 1997 я передал права на CVS репозиторий, чтобы любой мог вносить свою лепту в язык и считать его своим (это легко и сейчас, таких аккаунтов более 1000, где-то половина из которых что-то коммитила за последний год). Я старался сделать максимально простым как сам язык, так и возможность его совершенствовать – я лучше помогу новому контрибьютору и укажу на его ошибки, чтобы он стал более продуктивен, чем буду орать на него и отпугну его от проекта.

- Не нужно учить синтаксис, будь то программирование или работа с устройствами. Намного важнее понимать технологии и принципы. Синтаксис на практике натаскается или за’tab’ится (в IDE/CLI).
- Нет самых лучших языков во всем, так же как и самых худших. Нужно рассматривать язык как инструмент для достижения цели, какие то языки могут решать задачу быстрее/качественнее/надежнее. Знание одного языка существенно облегчает изучение другого (SRE Google).
You should think about any given programming language as being just one of the potential tools in the IT support specialist toolbox. From traditionally platform specific scripting languages like PowerShell for Windows and Bash for Linux, to more general purpose scripting languages, similar to Ruby, like Python and Pearl. There are many options available to the IT support specialist who is interested in automation. If you want, there's also a whole world of more traditionally compiled languages like C, C++, Java, and Go to Explorer. One nice feature of learning the basics of programming in one language is that the concepts you learn can generally be applied to other languages. This transferability means that becoming familiar with a language like Ruby will help you pick up new languages in the future, because you'll be able to spot similarities between them and understand their differences.
- Документация, исправление багов и работа с community зачастую важнее самого кода – создатель JQuery пишет, что это была единственная среди конкурентов библиотека с документацией (причем актуальной и на весь функционал) и во многом из-за этого она выстрелила.
- Нужно минимизировать использование if в пакетной обработке т.к. каждый if стоит дорог при том что без них совсем невозможно 🙂 (50к пакетов разработчики Cisco VPP linkmeup 98)
- Есть два паттерна у программистов python – просить прощения (try/except) и просить разрешения (if/then), в среднем при возможности лучше не смешивать для удобства чтения, на практике частт не соблюдается 😙
- Высшая математика и алгоритмы (в среднем по больнице) редко нужны в программировании – ее не много в бизнес задачах. Важнее (в среднем, опять же) знать существующие инструменты/библиотеки/умение писать.
- Митапы по IT (coding, devops, nets, bigdata, AI, etc) круты тем, что инфа с них хорошо усваивается и зачастую уникальна.
- На stackoverflow для популярных языков есть почти все. Поэтому есть термин stackoverflow coding.
- Текущий фронтент сложен. После базого курса по js bootstrap (хорошая тема для backend в том числе) все намного сложнее (dom model, flow, rendering и прочее).
- Nested conditions (напр. вложенные if) лучше максимально избегать т.к. их сложно читать и менять. Лучше их заменять, например, логическими операциями. В целом лишние conditions/условия стараются убирать, есть даже на этот счет троллинг с созданием 4 млрд. If в исполняемом файле 40GB написанном на асемблере 🤣
Although the indentation of the statements makes the structure apparent, nested conditionals become difficult to read very quickly. In general, it is a good idea to avoid them when you can. Logical operators often provide a way to simplify nested conditional statements.
- Есть такая общая концепция что explicit лучше чем implicit, но в контексте завершения каждого кода exit или в результате метода выдавать return (в случае с Ruby не обязательно) – это, считаю, не тот кейс.
You will notice that there was no need to have quit() at the end of the Python program in the file. When Python is reading your source code from a file, it knows to stop when it reaches the end of the file.
- При отладке очень опасны ошибки со спец-символами \r, \n, etc (white-spaces)
Whitespace errors can be tricky because spaces and tabs are invisible and we are used to ignoring them.
- Раньше была концепция наличия единой точки выхода (exit point) в коде – сейчас это скорее не актуально
https://stackoverflow.com/questions/4838828/why-should-a-function-have-only-one-exit-point
There are different schools of thought, and it largely comes down to personal preference.
- One is that it is less confusing if there is only a single exit point - you have a single path through the method and you know where to look for the exit. On the minus side if you use indentation to represent nesting, your code ends up massively indented to the right, and it becomes very difficult to follow all the nested scopes.
- Another is that you can check preconditions and exit early at the start of a method, so that you know in the body of the method that certain conditions are true, without the entire body of the method being indented 5 miles off to the right. This usually minimises the number of scopes you have to worry about, which makes code much easier to follow.
- A third is that you can exit anywhere you please. This used to be more confusing in the old days, but now that we have syntax-colouring editors and compilers that detect unreachable code, it's a lot easier to deal with.
I'm squarely in the middle camp. Enforcing a single exit point is a pointless or even counterproductive restriction IMHO, while exiting at random all over a method can sometimes lead to messy difficult to follow logic, where it becomes difficult to see if a given bit of code will or won't be executed. But "gating" your method makes it possible to significantly simplify the body of the method.
ООП
- Классы – не всегда хорошо.
- Классы и функции не обязательны в целом для программирования, но они крайне полезны для простого переиспользования/использования кода, а чем больше кода, тем больше этого переиспользования.
- Есть мнение, что классы следует использовать уже при 100-300 строках кода.
- Но есть и оппоненты этому мнению с справедливыми аргументами, которые говорят на основе практики, что создавать классы без большой reusability и продуманной архитектуры/структуры является, зачастую, вредным мероприятием. Это не редко усложнение структуры кода, кроме того, многие отказываются от классов ООП (напр. сделанных в C++ в пользу “плоского” C) из-за проблем с производительностью (максимальное исключение слоев абстракции для повышения производительности см. Linkmeup 98).
- Принципы ООП:
- энкапсуляция – заключение кода/методов в классы и при необходимости их сокрытие
- наследование
- полиморфизм
- абстракция
Стилистика
- (Python, best practices) Zen of python (рекомендуемые best practice) можно прочитать по import this
- The core principle in Python is DRY (Don’t Repeat Yourself)
Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!

В разных ЯП может различаться, в среднем (pep8 python):
-
- (python, coding best practices) formatter’ы типо black и autopep8, автоматически форматирующие код в соответствие PEP8 при сохранении/изменении (Visual Studio Code -> Format on save)
- (python, coding best practices) рекомендуется использовать линтеры/linters, которые проверят ваш код напр. pylance, pylint, flake8 (особенно хорош) для Python – все вместе (и не только они) легко включаются в VisualStudio Code. Из спорного однозначно
- размер строки менее 80 символов – это для экранов в прошлом, на мой экран помещается в три раза больше. Поэтому 120 от PyCharm более логичны.
- flake8 – command palette -> open user settings (JSON
“python.linting.flake8Args”: [
“–max-line-length=120”
],
- flake8 – command palette -> open user settings (JSON
- выдавать warning о том, что import не наверху файла, если все что перед ним это append/insert специфичного пути
- если линтеры не работают – проверь что для файла выставлено trust (внизу в индикаторах ошибок надпись Restricted Mode).
- размер строки менее 80 символов – это для экранов в прошлом, на мой экран помещается в три раза больше. Поэтому 120 от PyCharm более логичны.
- Переменные с малой буквы, не с большой, в качестве разделителя между словами подчеркивание
- Identation важно, особенно в python (4 пробела, не табы) – там без них код просто не заработает
- После блока кода хорошо оставлять пустую строку, для улучшения читаемости кода
- Очень важно правильно именовать переменные/функции/классы. К примеру, функции – это сказуемые, они что-то делают. Константы – это существительные, с ними происходят манипуляции.
- Для именования констант в Python используется стиль UPPERCASEWITH_UNDERSCORES. Все буквы заглавные, слова разделены подчёркиваниями.
A blank line at the end of a block of statements is not necessary when writing and executing a script, but it may improve readability of your code.
https://pypi.org/project/pep8-naming/
code sample message
N801 class names should use CapWords convention
N802 function name should be lowercase
N803 argument name should be lowercase
N804 first argument of a classmethod should be named ‘cls’
N805 first argument of a method should be named ‘self’
N806 variable in function should be lowercase
Комменты
- Комментировать в целом хорошо, но избыточное комментирование, как и полное его отсутствие, тоже порок, потому что отвлекает
- Нужно комментировать в первую очередь ЗАЧЕМ код это делает, а не КАК. Потому что КАК описано в коде.
- Большую часть комментариев можно избежать если правильно, по смыслу ( “mnemonic variable names”), называть переменные (не слишком длинно). Подробно о важности naming переменных/функций тут.
Good variable names can reduce the need for comments, but long names can make complex expressions hard to read, so there is a trade-off.
We often give variables mnemonic names to help us remember what is stored in the variable.
- Однозначно комментируются неочевидные (со стороны) вещи
Comments are most useful when they document non-obvious features of the code.
- docstrings очень круты тем, что всплывают в коде при просмотре в IDE (зачастую можно не переходить в функцию для просмотра коммента)
short-circuiting evaluation
short-circuiting evaluation – это когда при анализе логического выражения интерпретатор (Python, Ruby, snort content + pcre) заранее знает результат и перестает исполнять его дальше – например:
-
- один из элементов TRUE в выражении состоящем из OR
- один из элементов FALSE в конструкции состоящем из AND
When Python detects that there is nothing to be gained by evaluating the rest of a logical expression, it stops its evaluation and does not do the computations in the rest of the logical expression. When the evaluation of a logical expression stops because the overall value is already known, it is called short-circuiting the evaluation.
x >= 2 and (x/y) > 2 % # without guard crashes when devision on zero
The short-circuit behavior leads to a clever technique called the guardian pattern. We can construct the logical expression to strategically place a guard evaluation just before the evaluation that might cause an error as follows:
x >= 2 and y != 0 and (x/y) > 2 % # with guard
Этапы разработки ПО
Этапы разработки (кратко):
-
- анализ потребностей (требований), возможностей реализации
- алгоритмизация
- программирование
- тестирование
Правильное тестирование: dev -> test -> pre prod/stage/preproduction -> prod/production
SAP: D/q/p - development/quality/production servers
- написание документации
- написание инструкций по работе
Devops и архитектура
- Архитектура ПО (разработка архитектуры ПО), это искусство и наука строить и проектировать программное обеспечение таким образом, чтобы оно удовлетворяло всем заявленным к нему требованиям, а также обеспечивало максимальную простоту доработки, развертывания и масштабирования приложения.
- Myth about devops
- Myth-DevOps is incompatible with information security and compliance
- Myth-DevOps replaces Agile
- Myth-DevOps is Only for Startups
- Myth-DevOps is incompatible with ITIL
- Myth-DevOps Means Eliminating IT Operations or NoOps
- Myth-DevOps is just Infrastructure as a code or automation
-
Myth-DevOps is only for open source software
- Под балансировкой/отказоустойчивостью системы в целом обычно подразумевается возможность балансировать между разными обработчиками горизонтально (на разные pod/VM/физические ноды), а не возможности балансировать вертикально/внутри одной «коробки» (очереди/worker). Чаще всего при горизонтальной балансировке используется отдельный/независимый от системы балансировщик. При этом экземпляры приложения на разных «коробках» при использовании балансировки должны быть stateless – т.е. не сохранять у себя состояние запроса (а напр. сохранять в общей для экземпляров базе) иначе при перебалансировке/обращении на другой экземпляр приложения у клиента ничего нормально работать не будет. В таком случае база данных легко может стать узким местом – поэтому ее тоже масштабируют, как горизонтально, так и вертикально (подробнее в отдельной статье про основы БД).
- HEAD-FIRST подход – сначала думай, потом делай. Например сначала заложи архитектуру, потом закупай оборудование 🙂 сначала придумай архитектуру кода, а потом программируй 🙂
- KISS (акроним для «Keep it simple, stupid» — «Делай проще, тупица») — принцип проектирования, принятый в ВМС США в 1960. Принцип KISS утверждает, что большинство систем работают лучше всего, если они остаются простыми, а не усложняются. Поэтому в области проектирования простота должна быть одной из ключевых целей, и следует избегать ненужной сложности.
- на практике сталкивался с таким, что в архитектуру закладывали заранее плохо-работающие, но современные технологии (gnmi/gRPC) вместо хорошо-работающих и не современных (telnet), при этом серьезных требований для использования современных не было
- Яндекс отказался от MPLS в пользу максимального упрощения сети ((не яндекс облако)).
- пример из практики (perf conf)
- самый понятный результат для всех (не только для бизнеса) выглядит как зеленая галочка и красный крест

- когда это могло спасти проваленный проект:

-
“В моём опыте проблема не в джунах, а в некомпетентной инженерии на высшем уровне. Системы проектируются хаотичным образом с высоким уровнем оверинжиниринга и технического долга. К таким системам даже опытным программистам сложно прикасаться, что уж говорить о начинающих. Во всех компаниях премии выдаются раз в год, поэтому и горизонт планирования один год. Через несколько лет проект превращается в банку с червями.” (с) Бывший коллега
- Про Единую точку отказа Single Point Of Failure (SPOF/SPF) отдельная мини-статья
- In information science and information technology, single source of truth (SOT) (SSOT) architecture, or single point of truth (SPOT) architecture, for information systems is the practice of structuring information models and associated data schemas such that every data element is mastered (or edited) in only one place. The advantages of SSOT architectures include easier prevention of mistaken inconsistencies (such as a duplicate value/copy somewhere being forgotten), and greatly simplified version control. Without a SSOT, dealing with inconsistencies implies either complex and error-prone consensus algorithms.
- Practice: Нужно стремиться к принципу единственного источника правды (single source of truth), иначе мы сталкиваемся с рядом недостатков, связанных с дублированием логики. Из этого вытекает лишняя работа в виде оповещений при изменении и закладывания повторения логики, риски неповторения результатов в тестированиях с одним набором входных параметров.
-
Из культовой книги про devops –
- о том, что завязка одних проектов на другие и составление множества регламентов может приводить к огромным проблемам, вытекающим в конечном счете в бизнес результаты т.к. конечная ценность приносится все позже и позже
Everything becomes just a little more difficult, bit by bit—everybody gets a little busier, work takes a little more time, communications become a little slower, and work queues get a little longer. Our work becomes more tightly coupled, smaller actions cause bigger failures, and we become more fearful and less tolerant of making changes. Work requires more communication, coordination, and approvals; teams must wait just a little longer for their dependent work to get done; and our quality keeps getting worse. The wheels begin grinding slower and require more effort to keep turning. (See Appendix 3.) As a result, our product delivery cycles continue to move slower and slower, fewer projects are undertaken, and those that are, are less ambitious. Furthermore, the feedback on everyone’s work becomes slower and weaker, especially the feedback signals from our customers. And, regardless of what we try, things seem to get worse—we are no longer able to respond quickly to our changing competitive landscape, nor are we able to provide stable, reliable service to our customers. As a result, we ultimately lose in the marketplace.
-
-
о важности плановой деятельности в бизнес интересах компании, минимизации влияний аварий/любых изменений на бизнес процессы, быструю и качественную передачу из разработки в эксплуатацию с быстрой обратной связью, создание культуры экспериментов/не-боязни ошибок. Изменением (которое должно логироваться в системе) считается все, что может повлиять на IT сервисы.
-
-
“If you think IT Operations has nothing to learn from Plant Operations, you’re wrong. Dead wrong,” he says. “Your job as Vp of IT Operations is to ensure the fast, predictable, and uninterrupted flow of planned work that delivers value to the business while minimizing the impact and disruption of unplanned work, so you can provide stable, predictable, and secure IT service.”
-
“The First Way helps us understand how to create fast flow of work as it moves from Development into IT Operations, because that’s what’s between the business and the customer. The Second Way shows us how to shorten and amplify feedback loops, so we can fix quality at the source and avoid rework. And the Third Way shows us how to create a culture that simultaneously fosters experimentation, learning from failure, and understanding that repetition and practice are the prerequisites to mastery.”
-
A half hour later, we finally write on the whiteboard: “a change is any activity that is physical, logical, or virtual to applications, databases, operating systems, networks, or hardware that could impact services being delivered.”
-
-
-
- В Devops часто используется практика при которой запрещено изменение в конфигурации внутри продкутивной среды и любое изменение конфигурации должно приводить к полному пересозданию сервиса и подмене продуктивного сервиса на пересозданный ((см. в devops notes IMMUTABLE INFRASTRUCTURE))
- Используются практики наиболее плавного/менее рискованного внедрения изменений (у провайдеров на критичных объектах так же) – рядом с prod сервером/VM/контейнером разворачивается реплика, вносятся необходимые изменения в реплику (все что угодно – кодовая база, версии пакетов, интерпретаторов) и переключается prod нагрузка на созданную реплику
- Используется практика хранения всего в облаке и использования этого в сценариях отказоустойчивости/единого источника правды – к примеру в S3 хранилище хранится конфигурация/файлы сервера/все что угодно (VPN/HTTP/артефакты сборок/etc) или все что угодно, в случае отказа основной ноды разворачивается/включается резервная, которая маунтит к себе object storage S3 (S3FS) и читает конфиг.
Devops включает в себя лучшие практики архитектуры, разработки и эксплуатации, объединяет множество технический и управленческих (project management) актуальных практик.
На основе данных курса Azure Fundamentals.
Software developers and operations professionals strive to create working software systems that satisfy the needs of the organization. However, sometimes their short-term objectives are at cross-purposes, which can result in technical issues, delays, and downtime.
DevOps is a new approach that helps to align technical teams as they work toward common goals. To accomplish this alignment, organizations employ practices and processes that seek to automate the ongoing development, maintenance, and deployment of software systems. Their aim is to expedite the release of software changes, ensure the ongoing deployability of the system, and ensure that all changes meet a high quality bar.
When done correctly, DevOps practices and processes touch nearly every aspect of the company, not to mention the software development lifecycle, including planning, project management, and the collaboration of software developers with each other and with operations and quality assurance teams. Tooling automates and enforces most of the practices and processes, making it both difficult and unnecessary to work around.
DevOps requires a fundamental mindset change from the top down. Organizations can't merely install software tools or adopt services and hope to get all of the benefits promised by DevOps.
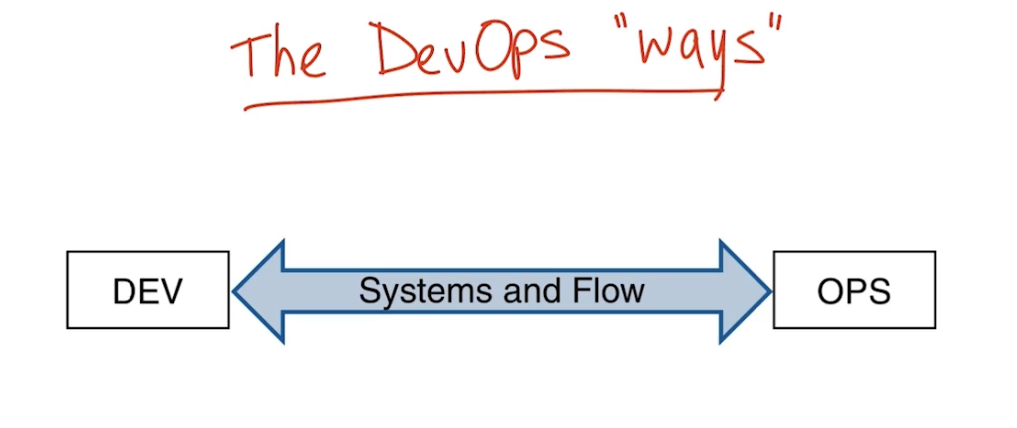
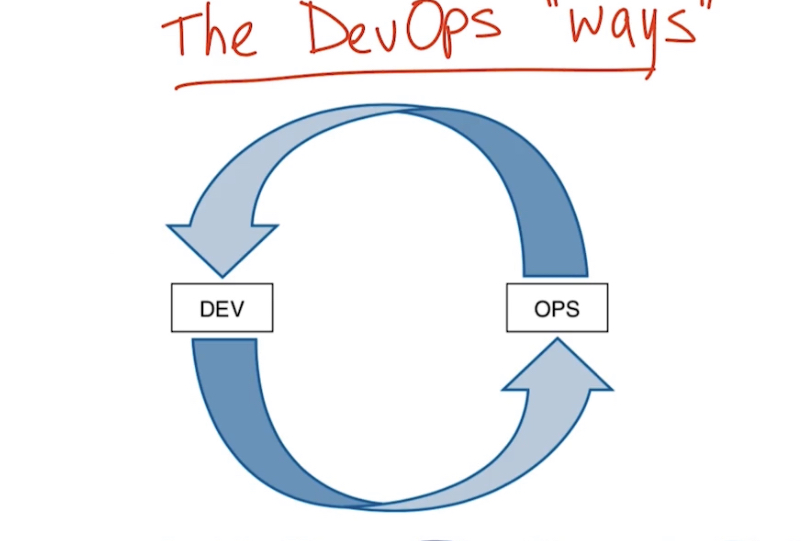
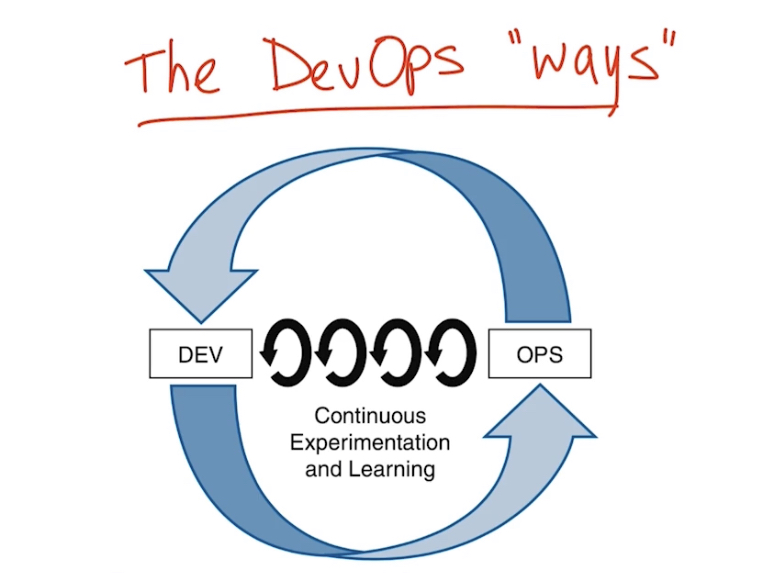
Три основных концепции/философии (ways) DevOps:
-
- Systems and flow – организация потока работы, работа становится более видимой за счет уменьшения размера работ – большая работа разделяется на ряд мелких с небольшими интервалами между ними (sprints); защита от дефектов реализуется с помощью реализации QA процесса повсеместно (throughout a process)
- Feedback loop – замыкаем обратную связь из эксплуатации в разработку, защита от того, что проблема произойдет еще раз. Позволяет быстрее обнаруживать проблемы и быстрее их устранять за счет этого. Обучаться на ошибках.
- Continuous Experimentation and Learning – постоянные эксперименты и обучение, разрешено экспериментировать с рисками, при этом выделяется время на то, чтобы исправлять ошибки и сделать систему лучше; использование shared/central repositories (github, gitlab)
CSIT (Continuous System Integration Testing) – пример CI процесса функционального и нагрузочного тестирования Cisco VPP, страница команды (публичная с указанием участников) и можно даже почитать их обсуждения (не перебор ли)
DEVSECOPS

Devsecops – концепт, используемый в последнее время, который описывает, как перенести активности по безопасности к началу цикла разработки. Подразумевает при разработке ПО:
-
- внедрение практик по безопасности в CI/CD pipeline; CSIT (Continuous System Integration Testing)
- внедрение Secure Development Lifecycle (SDLC/SDL)
DevSecOps enables integration of security testing earlier in the software development lifecycle (SDLC). DevSecOps enables seamless application security earlier in the software development lifecycle, rather than at the end when vulnerability findings requiring mitigation are more difficult and costly to implement.
Практики devsecops & SDLC используются многими современными организациями, особенно теми, кто разобрался с devops и реализовал CI/CD.


Примером того, на что будет опираться devsecops/программист SDLC может быть Top 10 owasp proactive control – это набор безопасных практик разработки и руководств которые любой разработчик должен следовать для создания безопасных приложений. Все эти практики помогают перенести безопасность в самые ранние стадии разработки, такие как требования и дизайн, программирование и тестирования.
Top 10 owasp proactive control:
-
- Define security requirements
- Leverage security frameworks and libraries – не переизобретайте колесо (reinvent the wheel), иначе можете наступить на грабли, которые учли в фреймворках
- Secure database access
- Encode and escape data
- Validate all inputs – до сих пор актуальная и серьезная проблема многих приложений
- Implement digital identity
- Enforce access controls
- Protect data everywhere – без разницы в облаке или on premise
- Implement security logging and monitoring
- Handle all errors and exceptions

Инструментами devsecops могут быть software assurance инструменты. Есть проект на сайте devsecops.github.io, который включает большое количество инструментов и мануалов о Devsecops и практиках devsecops.
-
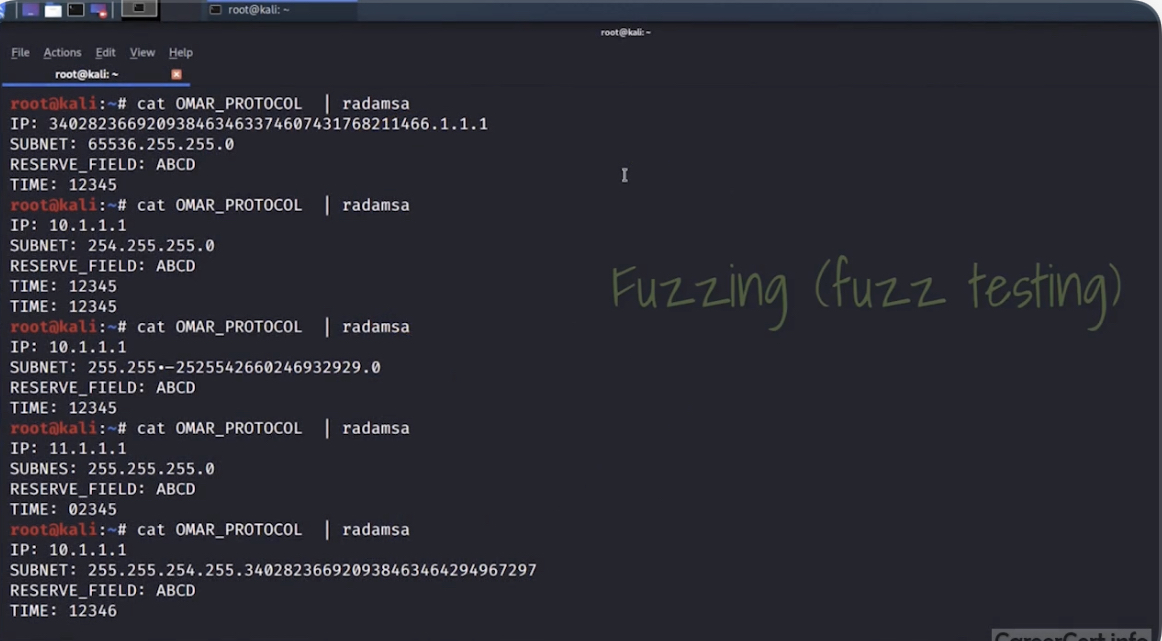
- фаззеры (fuzzers) – Fuzzing позволяет выявить програмные ошибки/баги (связанные в основном с input validation и buffer overflow) в разном ПО за счет отправки рандомных данных на обьект тестирования. Fuzzers – инструменты для fuzzing. Примеры:
- radamsa
- mutiny fuzzing framework (Cisco) – проигрывает packet capture файлы через мутационный фаззер.
- средства статического тестирования приложений (SAST, static application security testing) – ПО, которое проводит анализ программы (исходных кодов) без ее выполнения. К этому классу относится, например, pylint – линтер Python.
- средства динамического тестирования приложений (DAST, dynamic application security testing) – ПО, которое проводит анализ программы с ее выполнением.
- фаззеры (fuzzers) – Fuzzing позволяет выявить програмные ошибки/баги (связанные в основном с input validation и buffer overflow) в разном ПО за счет отправки рандомных данных на обьект тестирования. Fuzzers – инструменты для fuzzing. Примеры:
Примеры SAST утилит:
Svace - российский! используют многие крупные разработчики ПО (Ivannikov Institute for System Programming of the RAS)
Micro Focus Fortify
Snyk.io
AppScan (HCL)
Checkmarx
Cppcheck
PVS-Studio
SonarQube
Prefast
Сlang static analyzer
Blackduck
Примеры DAST:
- Acunetix
- Netsparker (Invicti)
- Burp Pro
Правила использования SAST/DAST могут быть разными, например
- запуск/оценка SAST/DAST для каждой сборки, для каждой релизной, для каждой сертификационной
- использование нескольких анализаторов
- запуск вручную/по триггеру/по коммиту/по pull requests


Releases/релизные циклы
Релизые циклы очень разные на практике – в среднем по больнице крупные релизы ПО обычно выходят раз в месяц/два. Реже раз в неделю-две или один-два релиза в год (Trex).
Software releases were once scheduled in terms of months or even years. Today, teams release features in smaller batches that are often scheduled in days or weeks. Some teams even deliver software updates continuously--sometimes with multiple releases within the same day.
Разработка ПО
Пример описания разработки ПО на примере презентации от Инфотекс



- системный аналитик ближе к программистам
- бизнес аналитик ближе к бизнесу
- ревью может быть таким – архитектор ревьюит программиста, программист тестера
- кодер не разработчик 🙂

itil/management
Хорошо когда знаешь потребности (demand), приоритеты (priorities), статусы работ (status of work) и доступные ресурсы (resource available).

waterfall
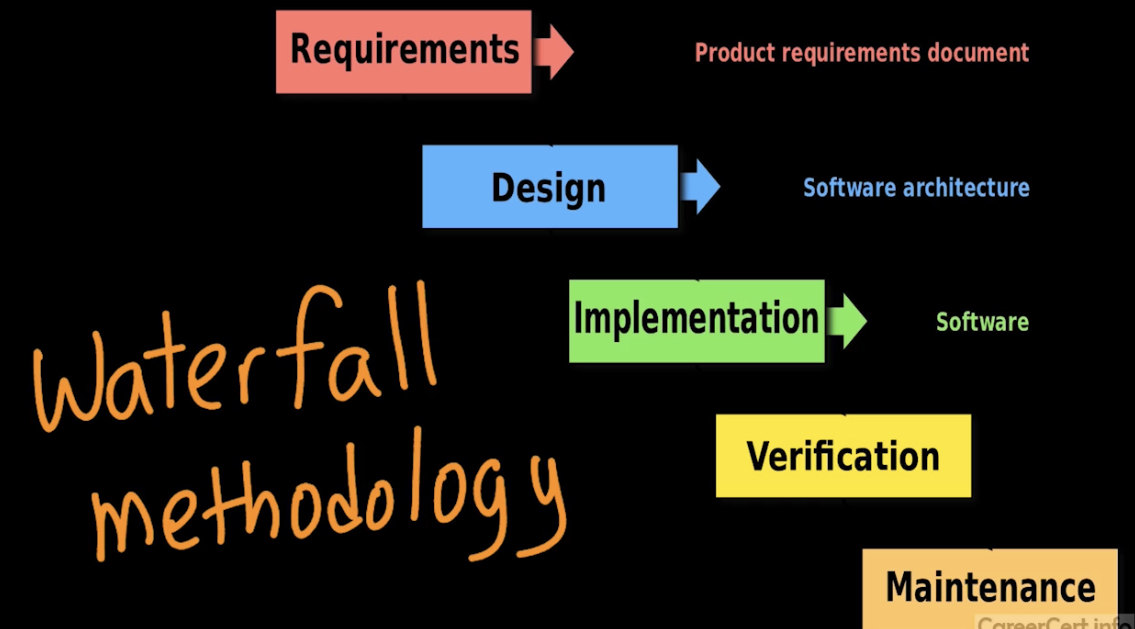
В прошлом широко использовалась (а где то и продолжает :)) методология waterfall, которая представляла из себя подход к разработке ПО из 5 основных фаз (в некоторых интерпретациях 7). Фазы строго следовали друг за другом, фаза не могла начаться, если предыдущая не выполнена.
- Требования (requirements) к продукту согласовываются на самой ранней стадии. Требования могут быть описаны конечным клиентом в виде user stories, которые описывают, какие проблемы продукт должен решать и как будет продукт использоваться в их среде. Такой подход:
- позволяет легче разрабатывать архитектуру продукта и проще оценить результат реализованного продукта. Процесс разработки всем понятен и последователен и это основное достоинство.
- с другой стороны часто все заинтересованные лица не могут определить все необходимые требования к продукту на данной фазе и это приводит к тому, что продукт доходит до фаз verification/maintenance и только на этих фазах выявляются принципиальные недостатки, которые может быть очень дорого исправить. Отсутствует гибкость и это основной недостаток.
- Дизайн, архитектура (design, architecture)
- Реализация, программирование (implementation)
- Проверка, тестирование (verification/testing)
- Поддержка (maintenance)
Agile
- В целом интересная статья о agile, но не только – постановка правильных целей, презентация результата владельцу продукта, взаимодействие между командами, оценка результатов, лидерство (обучение/развитие сотрудничества/направление работы); напр.
- на Daily Scrum нужно каждый день задавать вопрос: «То, что мы делаем, с целью вообще коррелирует?» Постепенно вы приучите людей думать больше о цели, чем о скоупе.
- Понимаете, что есть еще куча народу: порядка 150 других специалистов (10-12 команд). И с которыми, похоже, придется общаться, потому что вы от них зависите, а они — от вас. Как общаться? Во всех подходах Agile даёт простой рецепт: «Just talk: есть у тебя с кем-то зависимость, пойди да поговори с ним».
- умеете ли вы оценивать план-факт не просто как «Нам кажется, эта фича, наверное, повлияла», а собрали ли продакты с бизнесом реальные метрики с А/В-тестов, с каких-то вариантов дотягивания до клиентов.
- если вы не саморазвиваетесь, люди под вами тоже это не делают
- Фокусироваться нужно в первую очередь на поставке бизнес ценности – фокусироваться на решении задач востребованных бизнесом (делать то, что востребовано бизнесом)
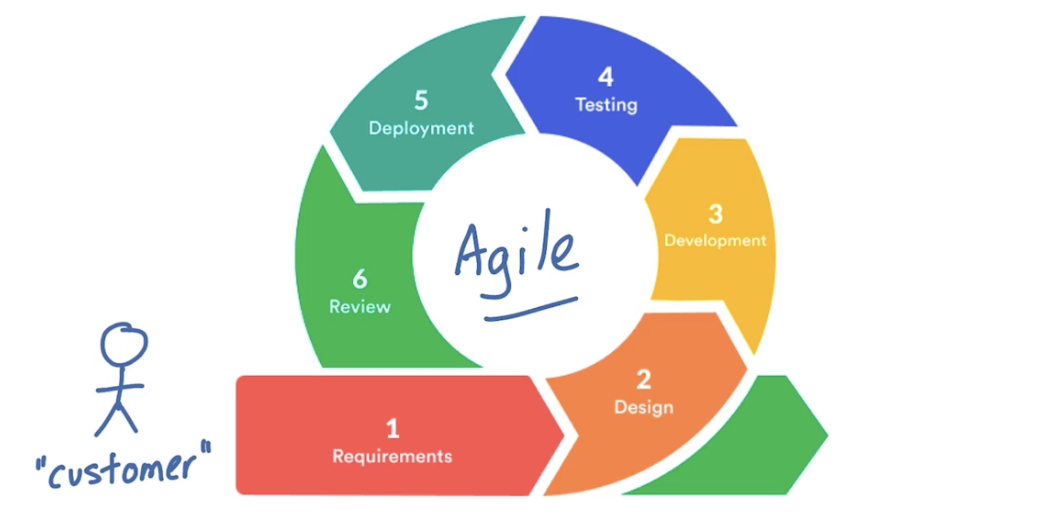
Agile методология разработки имеет все (по сути) те же самые ключевые фазы, только все заинтересованные лица всегда вовлечены в проект и возможны постоянные улучшения и взаимодействия на каждом stage с доработками требований/продукта на любом из stage. До сих пор популярная методология.
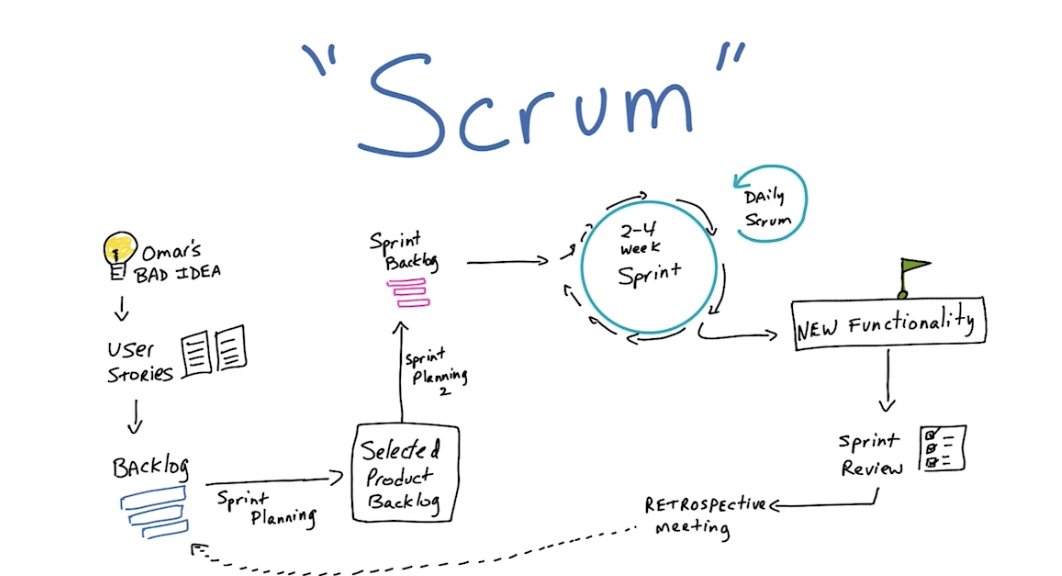
SCRUM, SPRINTS
- Scrum.org имеет большое количество материалов, включая даже обучение и сертификацию.
- Экспертами в scrum, agile, sprints, etc обычно являются project managers.
Scrum концепция используется многими организациями, работающими по Agile. Scrum по сути своей это framework, который позволяет командам организации работать вместе и способствует обучению команд через усвоение опыта за счет анализа (Continuous Experimentation and Learning) побед и поражений. Scrum описывает набор встреч, инструментов, ролей которые будут работать вместе для того чтобы команда структуировала и управляла своей работой.
Scrum методология использует концепцию spint’ов – это двухнедельные периоды, в которые команда работает для решения определенных ранее задач. Sprint’ы это одна из ключевых концепций scrum и agile методологий.

CI/CD PipeLines
- hh: описание пайплайнов выкатки, понимание принципов работы раннеров, понимание принципов CI/CD
- собрать/подтюнить простой Pipeline (кодеру)
- gitlab CI/CD – люди любят больше в среднем чем jenkins за счет своей простоты; но по функционалу он хуже Jenkins. Gitlab часто используется для централизованного хранения. В gitlab репозитории часто хранятся конфиги/скрипты; а Gitlab CI позволяет доставлять куда надо эти конфиги/скрипты.
- jenkins – расширяемый и крайне богатый функционал, в том числе в сравнении в gitlab ci. При этом кто-то отказывается от него в пользу gitlab ci.
- github actions – достаточен зачастую для реализации pipeline и в некоторых сценариях им вполне себе заменяют jenkins, в итоге pipeline работает без прослойки в виде jenkins
- drone kubernetes
- bitbucket
- treamcity – кто-то отказывается от него в пользу gitlab ci.
- в любом ci есть понятие runner’ов (раннеров). Пример: GitLab Runner — это агент, который собственно и занимается выполнением инструкций из специального файла .gitlab-ci.yml. В отличие от Jenkins раннеры гитлаба написаны на Go, поэтому они очень маленькие и быстрые. И умеют запускать задачи совершенно различными способам: локально, в докер-контейнерах, в различных облаках ((и на хостах windows)) или через ssh-коннект к какому либо серверу. Подробности, как всегда, в документации
CI/CD pipelines – процессы/алгоритмы CI и CD, последовательность которых (по сути последовательность job) автоматизируют релиз софта. Поддерживается многими организациями сейчас и это огромное преимущество компаний, которые поддерживают этот процесс. Причем через слеш CI/CD не значит что это либо одно, либо другое – это один последовательный процесс, сначала CI, потом CD. Затрагивает весь процесс выпуска ПО: программирование, тестирование, доставку, развертывание.
Каждое изменение кода по сути запускает ряд (настраиваемых) действий/алгоритм, включающих процесс сборки и тестирования ПО с реализацией feedback (feedback loop) для программистов, которые сделали изменения и всей команды (логи).
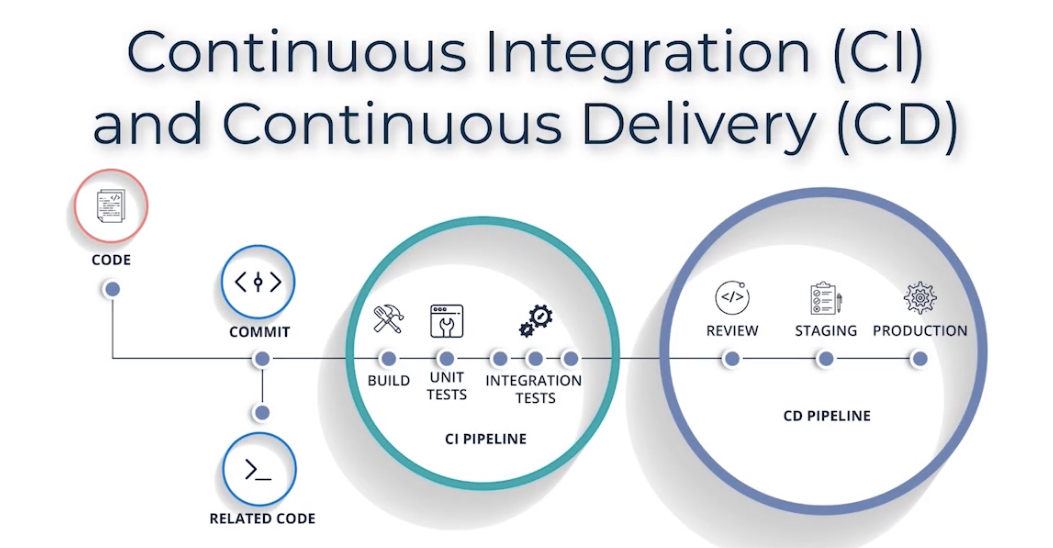
- Continuous Integration (CI) (по сути проверка кода) – практика разработки софта при которой программисты постоянно (on ongoing basis), несколько раз в день, commit’ят код в централизованном репозитории типа github/gitlab
ci - после коммита кодера в определенный бранч без действий программиста в ci/cd триггерится pipeline worker/runner (которых может жить некоторое кол-во и мониторить репозиторий на наличие нового кода), происходит:
-статический анализ кода - линтеры/typechecker/sast,
-запуск unit test самого кодера или автотестера на код,
-запуск сборки/компиляции кода с оценкой наличия ошибок при сборке в итоговый артефакт (в зависимости от проекта может быть все что угодно - образ диска, VM, докер образ, deb пакет, бинарный/jar файл),
- динамические автотестирования сборки на функционал (напр. Selenium)/производительность (jmeter/any tool)/безопасность dast,
-пуш результата сборки/билда кода и логов сборки в какое то хранилище артефактов (напр. Artifactory или любое другое хранилище - s3 bucket, сетевая шара, etc),; последним шагом т.к. предыдущие проверки могут провалится и потенциально нет никакого смысла сохранять этот артефакт, на этом завершается CI pipeline
- Continuous Delivery (CD) (доставка/деплой кода) – полагается на процесс CI, может подразумевать настройку/провиженинг облака под новую сборку софта, что раньше делалось вручную
cd - далее инструмент деплоя (напр. Ansible для bare metal/vm, helm для k8s, terraform для облаков)
берет сборку из хранилища и деплоит ее в разные staging (реже в prod), с возможными доп. шагами/тестами в зависимости от окружения, включая автоматический анализ метрик после деплоя (мониторинг/видимость) и автоматизация отката в случае обнаружения каких либо серьезных проблем. После деплоя в staging тестировщики/заинтересованные лица/кодеры могут делать review результата на соответствие ожидаемому.
Serverless computing
Serverless computing = PaaS cloud computing
With serverless applications, the cloud service provider automatically provisions, scales, and manages the infrastructure required to run the code. Serverless architectures are highly scalable and event-driven, only using resources when a specific function or trigger occurs.
- Serverless – не означает, что вам не понадобится сервер вообще, это означает то, что вы используете облачную платформу (PaaS) для хостинга вашего кода и облачный провайдер, а не вы, отвечает за обслуживание и деплой серверов.
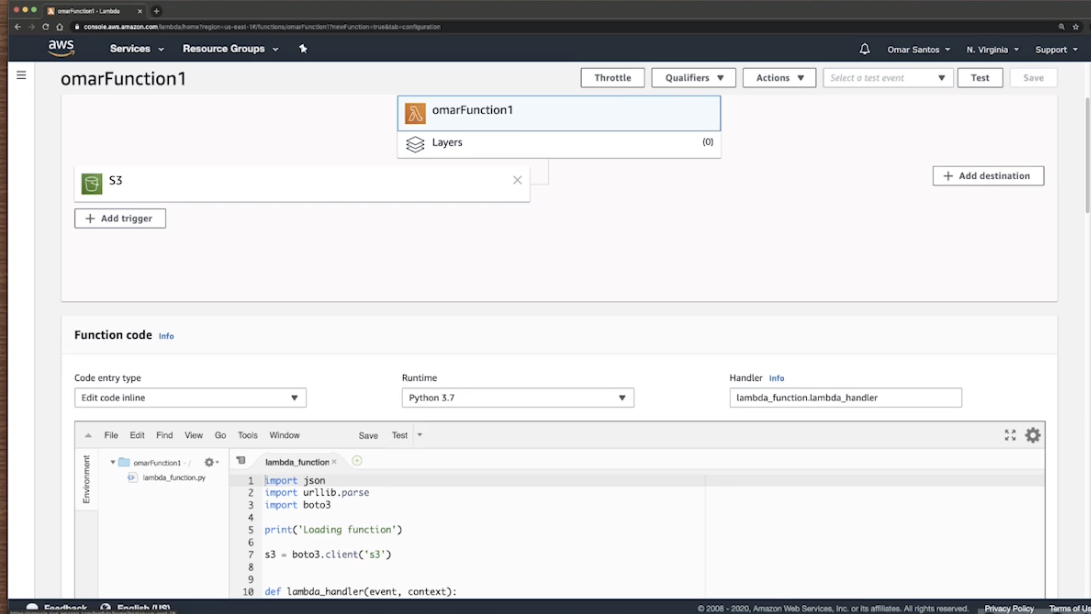
- Serverless приложения обычно работают в stateless контейнерах, которые являются ephemeral и event trigger – по сути это означает, что они полностью управляются облачным провайдером. Пример такого serverless популярного сервиса – AWS Lambda, Azure Functions.
AWS Lambda – это бессерверный вычислительный сервис, который позволяет исполнять код без необходимости выделять серверы и управлять ими, создавать логику масштабирования кластера с учетом рабочих нагрузок, поддерживать интеграцию событий или управлять временем выполнения. Lambda позволяет выполнять код практически любого приложения или серверного сервиса без администрирования. Просто загрузите свой код в виде ZIP-файла или образа контейнера, и Lambda автоматически и точно выделит вычислительную мощность и запустит код на основе входящего запроса или события для любого масштаба трафика. Можно настроить автоматический запуск программного кода из более чем 200 сервисов AWS и приложений Saas или вызывать его непосредственно из любого мобильного или интернет‑приложения. Функции Lambda можно писать на своем любимом языке (Node.js, Python, Go, Java и др.) и использовать бессерверные и контейнерные инструменты, такие как AWS SAM или Docker CLI, для создания, тестирования и развертывания ваших функций.

Монолит / Microservice architecture
у меня тут монолит всю жизнь был а в Сбере микросервисы были
и там и там свои плюсы/минусы

- монолит – это архитектура в которой объединяются разные слои и каждый слой приложения отвечает за свою часть функционала, например: работа с базой, логирование, интерфейс. В плюсах простота масштабирования, E2E тестирования, простота развертки.
Если ваше приложении не разрастется (и Вы в этом уверены), у вас маленькая команда и сильно ограниченные ресурсы – (в общем случае) выбирайте монолит.
Наиболее популярный шаблон монолита это MVC и его производные MPV (model view presenter), MVVM (model view view model). Model-View-Controller(MVC, «Модель-Вид-Контроллер») — схема разделения данных приложения и управляющей логики на три отдельных компонента: модель, представление/вид и контроллер — таким образом, что модификация каждого компонента может осуществляться независимо:
-
Модель (Model) предоставляет данные и реагирует на команды контроллера, изменяя своё состояние.
-
Вид/Представление (View) отвечает за отображение данных модели пользователю, реагируя на изменения модели.
-
Контроллер (Controller) интерпретирует действия пользователя, оповещая модель о необходимости изменений.
-
Microservice – небольшая часть (кода) имеющего строгую функциональную задачу (single business capability) и мало связанная с какими то другими Web сервисами. Обычно такие сервисы объединяются в microservice architecture. Микросервисы часто используют docker/containerd т.к. сами микросервисы могут писаться на чем угодно и иметь абсолютно разные зависимости. В общем случае правильно, когда каждый такой сервис имеет свою базу.
К плюсам можно отнести независимость между микросервисами, междумасштабируемость, простоту модульного тестирования.
A miscroservice is a way to simplify an application architecture by focusing on creating smaller, more manageable, autonomous and independently deployed web services.
Тренд оттока от монолита к микросервисам есть, но всегда нужно понимать, что при этом нет серебрянной пули – напр. создание chaining из разных микросервисов по обработке транзакции вместо одного монолита в теории может быть хуже т.к. больше элементов/прослоек между ними задействовано и общая схема в итоге менее надежна в сравнении с одним монолитом обрабатывающим/коммитящим транзакцию в базу.
Команды по поддержке могут быть в рамках каждого сервиса и каждая команда в итоге может выбрать свой язык/среду для реализации сервиса. Упрощается релиз улучшений систем. Divide and conquer:
-
- Чем меньше объем кода каждого сервиса, тем проще выпускать релизы и подключать новых людей для разработки (проще разобраться в работе).
- Команда может обновить существующий сервис без пересборки/редеплоя всего приложения. Плюс упрощается откат (roll back), если что-то пойдет не так.
- Тестирование упрощается, баги проще найти и устранить. В итоге релизы более управляемые и несут меньше рисков.
- Scaling микросервисов зачастую проще – можно расширить конкретный проблемный компонент посредством горизонтального масштабирования, а не вертикального. Особенно это относится к stateless микросервисам, которые не привязаны к состоянию – их масштабировать проще всего добавляя ноды-обработчики, не заботясь о том, новые это запросы или старые для которых уже есть какое то состояние (stateful).
Взаимодействия между микросервисами часто реализуются посредством API, но часто используется и подход к созданию отдельного orchestration/management layer в приложении, которое координирует запросы к разным микросервисам и объединяет результат.
Требования к микросервисам: каждый микросервис должен быть автономен – должен сохранять свои данные и состояние, не полагаясь на общий репозиторий ((по факту далеко не всегда соблюдается)). Some microservice experts insist that each microservice should even have its own separate database (как по мне перегиб). This kind of freedom provides a layer of fault isolation. If a service goes down, it won’t necessarily take out the entire application.
Containers are often used to create solutions by using a microservice architecture. This architecture is where you break solutions into smaller, independent pieces. For example, you might split a website into a container hosting your front end, another hosting your back end, and a third for storage.
This split allows you to separate portions of your app into logical sections that can be maintained, scaled, or updated independently.
Инструменты DEVOPS
Сборка ПО
TeamCity
Серверное программное обеспечение от компании JetBrains, написанное на языке Java, билд-сервер для обеспечения непрерывной интеграции. Первый релиз состоялся 2 октября 2006 года.
Оркестрация контейнеров
Оркестрация подразумевает деплой, управление, удаление контейнеров. Инструментов разных много, например:
-
- Kubernates (k8s) – самый популярный инструмент/фреймворк управления контейнерами (чаще всего docker). Изначально разработан Google. В github находится как код k8s, так и в h4cker.org/github есть ресурсы для изучения и старта работы с k8s. Подробнее.
- openshift – k8s + сервисы поверх kubernates (напр. интеграция jenkins и другие плюшки для удобного управления/devops), платный от redhat, использует сбер
- terraform – IaC
- Nomad (hashicorp) – другой оркестратор контейнеров.
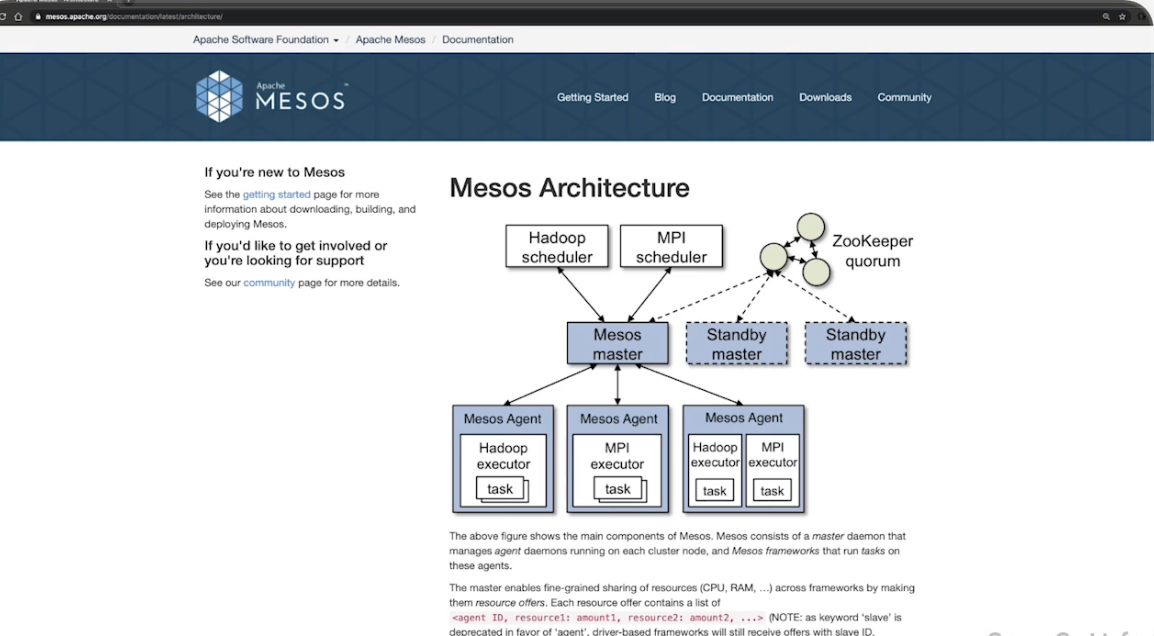
- Mesos (apache) – включен в ядро Linux (another distributed linux kernel), позволяет работать с контейнерами docker, apc images.
- Docker swarm – для управления докерами от создателей докера. Подробнее в статье про Docker.

Документирование
Markdown
VERSION TRACKING/CHANGES
- Подходы бывают разные
- Лично мне нравится подход версий с датом и временем – версия ПО от 03.12.2025 14:25
Преимущества и особенности
Простота и наглядность: Позволяет быстро определить, когда была выпущена версия.
Удобство сортировки: Версии, основанные на дате, можно легко отсортировать по возрастанию времени выпуска.
Отсутствие необходимости в строгих правилах: Не нужно придумывать, как определить, когда увеличивать основную, дополнительную или минорную часть, что часто используется в семантическом версионировании (например, 1.9.0 -> 1.10.0).
- Достаточно популярно семантическое версионирование semantic versioning
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backward compatible manner
PATCH version when you make backward compatible bug fixes


shift left
- чем раньше выявляется дефект, тем дешевле стоит его исправление
- хорошие разработчики/тестировщики всегда хотят максимально быстрые тесты, включая сложные, вплоть до
- тестов после каждого коммита
- стенда у себя на ПК
- каждодневных тестов (напр. ночных)
- когда это могло спасти проваленный проект (perf conf)


- С другой стороны есть разумное мнение, что тестировать НТ до создания требований не стоит т.к. на это могут уйти ресурсы/превращается в оверинджиниринг

Questions
Which command shows all shared libraries required by a binary executable or another shared library? (Specify ONLY the command without any path or parameters.)
ldd
Which of the following environment variables overrides or extends the list of directories holding shared libraries?
A. LD_LOAD_PATH
B. LD_LIB_PATH
C. LD_LIBRARY_PATH
D. LD_SHARE_PATH
E. LD_RUN_PATH
Answer: C
To what environment variable will you assign or append a value if you need to tell the dynamic linker to look in a build directory for some of a program’s shared libraries?
A. LD_LOAD_PATH
B. LD_LIB_PATH
C. LD_LIBRARY_PATH
D. LD_SHARE_PATH
E. LD_RUN_PATH
Answer: C