
TCP & UDP notes





-
Сегментация в общем случае желательней фрагментации
-
TCP MSS по умолчанию = 536 байт в том числе в актуальном RFC 9293
The default IP Maximum Datagram Size is 576.
The default TCP Maximum Segment Size is 536.
- В новом linux kernel 6.7. В протокол TCP добавлена опциональная возможность использования временных меток (TCP TS) с микросекундной точностью (RFC 7323), что позволяет более точно оценивать задержки и создавать более продвинутые модули управления перегрузкой. Для включения можно использовать команду “ip route add 10/8 … features tcp_usec_ts”.
- Используют netperf для тестов tcp/udp 😉 В новом linux kernel 6.7. Проведена оптимизация производительности планировщика пакетов fq (Fair Queuing), позволившая поднять пропускную способность на 5% при больших нагрузках в тесте tcp_rr (TCP Request/Response) и на 13% при неограниченном потоке UDP-пакетов.
- Сотрудники google в 2021 говорят, что любят TCP 🙂 Информация о TCP/UDP пакетах внутри ядра Linux как на отправку, так и на прием оперируются с использованием структуры skb (sk_buff, socket buffer). Google старается сохранить его в текущем виде и просит его не трогать (причины думаю в доп. памяти). Ниже так же ссылаюсь на данное же видео по основной его тематике – функционалу BIG TCP.

https://dri.freedesktop.org/docs/drm/networking/skbuff.html
http://vger.kernel.org/~davem/skb.html
The socket buffer, or "SKB", is the most fundamental data structure in the Linux networking code. Every packet sent or received is handled using this data structure.
When a packet is sent or received for a socket, the memory assosciated with the packet must be charged to the socket for proper memory accounting. Read more about socket packet buffer memory accounting here.
- Основа TCP была описана в RFC 761 от 1980 и RFC 793 от 1981 года. RFC 9293 от 2022 года агрегирует знания. Изначальным заказчиком является Defense Advanced Research Projects Agency (DARPA) – Управление перспективных исследовательских проектов Министерства обороны США DARPA.
TRANSMISSION CONTROL PROTOCOL September 1981 (Defense Advanced Research Projects Agency)
https://systemsapproach.substack.com/p/tcp-the-p-is-for-platform
There have been so many extensions and implementation notes that it’s hard to keep track of all of them, so in case you missed it, RFC 9293 was just published to address that problem. In a major milestone, RFC 793 is now officially Obsolete.
- (L4, IxChariot) На основе документации IxChariot Endpoint (работает на разных ОС, включая Linux) – использование одного транспортного порта несколькими приложениями нежелательна, (даже в случае если socket разный насколько я понимаю, явно не написано) т.к. это может влиять на производительность работы. Насколько это соответствует действительности конечно, как по мне, вопрос т.к. каждый socket connection должен быть уникальным от других, но написание в документации тоже сделано явно не просто так.
Use AUTO if possible when testing with multiple pairs. If the same port is specified for multiple pairs, the performance degrades, since the pairs must share (serialize) the use of the port to run the test.
- Мониторинг и нетнехнические характеристики продуктов
Это значение зависит от количества активных соединений в системе. Обратите внимание, что количество активных соединений одновременно, это соединение является нормальным для максимального количества соединений, которые система может нести, потому что большинство соединений не будут активными в то же время.
- В Linux 5.11 развивается MPTCP – возможность одновременного использования нескольких интерфейсов для одной TCP сессии.
Продолжена интеграция в ядро MPTCP (MultiPath TCP), расширения протокола TCP для организации работы TCP-соединения с доставкой пакетов одновременно по нескольким маршрутам через разные сетевые интерфейсы, привязанные к разным IP-адресам. В новом выпуске реализована поддержка опции ADD_ADDR для анонса доступных IP-адресов к которым возможно соединение при добавлении новых потоков к существующему соединению MPTCP.
Socket Buffer (SKB) is the most central data structure used in the Linux TCP/IP implementation. It is a linked list of buffers, which holds network packets. Such list can act as a Transmission queue, Receive queue, SACK’d queue, Retransmission queue, etc. SKB can hold packet data into fragments. Linux SKB can hold up to 17 fragments.
- Помимо 3whs (three way handshake) существует такая вещь как TCP three/four way close/shutdown (teardown). Про 3whs и решаемых задачах подробнее ниже.
- PUSH FLAG TCP используется для информирования получателя что больше данных нет (можно не ждать, тратить буфер, а сразу отправлять ACK, как понимаю).
Again, the PSH flag is used to inform the receiver that the sender has no further data to transmit (for now).
- крутое поле в Wireshark для траблшутинга конкретной TCP сессии в большом pcap, содержащим много сессий – сделать фильтр на основе поля time since previous frame in this tcp stream и отсортировать по задержке между пакетами одной сессии, можно напр. зафиксировать, что сервер очень долго отвечал на запрос клиента (с точки зрения дампа)
- так же можно выставить отчет времени с конкретного пакета (time reference) – полезно для расчета задержки от пакета X до пакета Y независимо от сессии
- какие проблемы с tcp показывает wireshark: tcp retransmissions, out of ordering, duplicated ack, zero windows.
- для tcp да и в целом для любого трафика всегда лучше перехватывать трафик как со стороны клиента, так и со стороны сервера – пример, потери на стороне клиента выглядят как tcp out of order (потому что потерянный сегмент в дампе отсутствует, но присутствует перепосланный после ряда других, на которыз клиент отсылал duplicated ack при включенном selective ack), а со стороны сервера как retransmission (потому что в pcacp как исходный сегмент, который по дороге к клиенту потерялся, так и перепосланный).
- previous segment not captured в wireshark при наличии последующих duplicated ack – это реальные потери, если же алерты previous segment not captured есть, а duplicated ack нет – вероятно ты просто не перехватил весь трафик (перегружен wireshark/tcpdump/span или в месте съема проходит не весь трафик – напр. Split route).
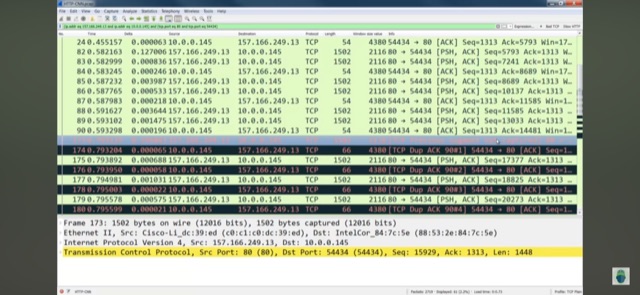
- reordering в рамках одной сессии – это проблема, то что это проблема (особенно для UDP-based протоколов, напр. Voice) подтверждается RFC 4737 Packet Reordering Metrics, статьями 1 2 Ivan Pepelnjak:
RFC
1.1. Motivation
A reordering metric is relevant for most applications, especially
when assessing network support for Real-Time media streams. The
extent of reordering may be sufficient to cause a received packet to
be discarded by functions above the IP layer.
Ivan Pepelnjak
1
TCP segment reassembly into a seamless stream is the job of the transport layer, but do keep in mind that the transport layer (TCP code in receiving host, to be more precise) can do its job better and faster if the packets are not reordered. Although (IIRC) people who know better told me it’s no longer a big problem with decent TCP stack, and I encountered a not-insignificant amount of reordered packets when I had to troubleshoot traffic traversing the Internet.
2
One of my regular readers who designs and builds networks supporting VoIP applications disagreed with that citing numerous real-life examples.
3
Using per-packet load balancing (where you’d send packets of the same session over multiple paths with different latencies) is rarely implemented in practice – it would generate too many unnecessary support calls.
Ожидать, что весь трафик между двумя IP не будет перемешиваться – глупость и плохое предположение. Но ожидать, что в рамках одной TCP/UDP сессии не будет перемешиваний – нормальное требование (особенно, когда речь идет о в целом не сети даже, а об одном устройстве).
Let’s define the problem first. Retaining strict source-to-destination packet ordering across a generic IP network is usually a Mission Impossible, and if your application requires that, you might be using the wrong transport technology. What we’re usually looking for is in-session packet order: packets of a single TCP or UDP session are not reordered while traversing a network.
Reordering может происходить из-за разных причин, но чаще всего этими причинами являются:
-
-
- балансировка без учета адресов транспортного уровня
- помещение пакетов одной сессии в одну очередь и соответственно разный приоритет обработки
-
packets from the same stream are queued differently, either due to different forwarding paths they take within a device or due to landing in different queues.
Reordering легко воспроизвести разными impairment инструментами.
- Assymetric routing (ассиметричная маршрутизация) – другая интересная проблема транспортного уровня, когда часть трафика передается по одному пути, а часть по другому. Firewall и IPS (напр. snort) чаще всего ожидают, что весь трафик сессии будет проходить через девайс и случай ассиметричной маршрутизации требует особые настройки (чистейшие костыли). Например.
- Fortigate – The FGSP enforces firewall policies for asymmetric traffic, including cases where the TCP 3-way handshake is split between two FortiGates. For example, FGT-A receives the TCP-SYN, FGT-B receives the TCP-SYN-ACK, and FGT-A receives the TCP-ACK. Under normal conditions a firewall will drop this connection since the 3-way handshake was not seen by the same firewall.
- Snort – ряд разных проблем и опций для их устранения, либо лучше починить сеть 🙂
https://www.ciscolive.com/c/dam/r/ciscolive/emea/docs/2020/pdf/R6BGArNQ/TECSEC-3004.pdf
https://github.com/johnjg12/snort-scripts
snort perfstats
Asymmetric output (BAD):
instance-1
Syns/Sec: 179.1 # ratio is far from 1:1
SynAcks/Sec: 2.3
Symmetric output (GOOD):
instance-1
Syns/Sec: 77.8 # ratio is almost 1:1
SynAcks/Sec: 79.1
- UDP > TCP
- UDP даже до прихода QUIC часто использовался для streaming данных (voice, video) и игр (gaming, Gamedev).
While measuring performance for UDP is great for gaming and voice (typically), TCP brings additional processing overhead which will make the box (typically) perform slower.
В записи же говорится, что работа Warp построена вокруг использования UDP-пакетов, которые, как мы помним, не требуют обратного ответа от целевого сервера и которые, по этой причине, активно используются в том же геймдеве для снижения пинга.
-
- Производительность TCP зависит от множества вещей – наибольшее влияние оказывают внешние факторы (RTT и потери), но влияют так же и внутренние – размер окон, размер MSS, congestion algorithm, поддержка SACK, метод закрытия сессий и прочие факторы (например, даже такие – как скорость expiration SYN, TIME_WAIT, FIN_WAIT, connection TTL TCP/UDP – подробнее в DoS). Про RTT & Win size и их зависимость на performance TCP ниже, так же ниже и про таймеры подробнее.
Разные размеры окна у разных генераторов: TRex = 32768, Ixia IxLoad = 2896 (scale OFF), BreakingPoint 5792 (scale OFF).
(tcp, impairment, metrics) Грубо говоря (взято отсюда) – по факту это очень спорные цифры и их изначальный источник не bi.zone!
-
- без задержек с 2% потерями полоса деградирует в 20 раз,
- с задержками 100мс и без потерь канал так же деградирует в 20 раз
- каждые 30мс уменьшают производительность в +5 раз от исходных эталонных
- когда в канале и задержки и потери – все, очевидно, еще печальней

О сложности TCP и недостатках из-за этой сложности рассказывает в том числе глава EANTC (изменение атрибутов, таких как размер окна/закрытия сессий и проч. изменяет кардинально результат тестирования). (BMWG IETF 111) К EANTC иногда приходят клиенты, которые удивляются, что результаты между ведущими тест вендорами разные (Ixia/Spirent явно имеются ввиду) и чаще всего ответ в разных параметрах TCP (tcp stack attributes), поэтому глава EANTC поддерживает полностью инициативу в well-defined в RFC netsecopen параметрах TCP чтобы можно было иметь reference для всех. Это даже зачастую проще реализовать open source утилитам т.к. им не нужно это реализовывать в виде accellerator/FPGA (комментарий Ixia или Spirent).
The most important factors affecting TCP throughput performance are TCP window size, packet loss, and RTT.
"testing with TCP is hard to begin with and it it's a mess to use different parameters" "initial congestion windows TCP = 2, 10 (default) on various test tools" "closing TCP sessions"
EANTC Carsten Rossenhoevel
We need to include the TCP stack attributes Window sizes, etc. Even the need to use the same way to close TCP connections.
EANTC Carsten Rossenhoevel
Configurable TCP parameters can highly influence benchmarking test results. With the goal to achieve reproducible test results we decided to specify TCP parameter values, by the way aligned with defaults of most of today's operating systems.
Hi Tommy,
Thanks for you reply. The general consensus amongst the authors and contributors is that there is a need to get into the weeds when it comes to TCP configuration of the test tools and elements of the test bed. This draft is meant to address the test tools in order to ensure (hopefully) results can be replicated. I can certainly understand your position when it comes to production environments. But that is not what we are concerned about. The various test tools we have looked at and worked with have varied default settings. Which is what led us to our approach.
That said however, Al Morton pointed us to RFC7414 (https://datatracker.ietf.org/doc/html/rfc7414) as a possible reference that lists/consolidates all the TCP requirements and defaults that are relevant or in-force today. We could reference that RFC and specific sections for the requirements we need. This RFC is over 7 years old. Is there anything more current?
Thoughts?
Brian
-
- В ряде RFC (RFC 2544, RFC 5180, RFC 8219) используют и рекомендуют использовать для тестового трафика именно UDP из-за его простоты: просто реализовать тест, просто повторить тест, проще найти генератор, который создаст необходимую нагрузку. При этом тестирования UDP не отменяет тестирование TCP, т.к. обработка разных протоколов может быть с разной скоростью.
The issue with any middle box is that vendors typically optimize processing for specific protocol.
RFC 8219
Because of the simplicity of UDP, UDP measurements offer a more
reliable basis for comparison than other transport-layer protocols.
Consequently, for the benchmarking tests described in Section 7 of
this document, UDP traffic SHOULD be employed.
Maillist IETF bmwg
Q
I recommend that the TCP considerations for such benchmarking methodology should not be left for a future document, as TCP still is the most used protocol. So, the details on TCP difficulties and an extension of this benchmark to consider TCP, should be in the scope of this document.
A
I would like to note regarding testing with TCP that all RFC 2544, RFC 5180 and also RFC 8219 recommends testing with UDP.
Additional testing with TCP seems to be feasible, but it requires some considerations and design decisions.
For example, whereas you can simply send UDP datagrams as test traffic, but you need to establish a TCP connection first.
The 3-way handshake may be done during the preliminary phase, and one can send TCP segments as test traffic in the real test phase.
However, it is does not seem trivial to me, how deeply the Tester should follow the TCP protocol.
On the one hand, perfectly implementing all the rules of the TCP protocol would impose a lot of limitations on the Tester, thus it would not be able to send test frames at the required rates.
This would prohibit the execution of the benchmarking tests like throughput, frame loss rate, latency etc, :-(
On the other hand, normal routers do not look into the TCP protocol header, but NAT boxes do.
Thus sending TCP segments with improper Sequence number, Acknowledgement number, etc. fields could result in different problems in the DUT depending on how deeply it follows the TCP protocol.
-
- (Encryption) (wireguard) DTLS производительность на Cisco ASA (работает поверх UDP 443 порта) значительно превышает производительность на базе TLS/IKEv1-2. Если брать градацию, то, как понимаю, она такая DTLS > IKEv2 > IKEv1 > TLS. Кроме того производительность увеличивает использование шифров AES-GCM, которые есть для DTLS, TLS, IKEv2.
UDP’s lack of reliability would normally be a problem while browsing the Internet, but we are not simply sending UDP, we are sending a complete TCP packet _inside_ our UDP packets. If we instead wrapped our inner, encrypted, TCP session in another TCP packet as some other protocols do we would dramatically increase the number of network messages required, destroying performance.
DTLS is used for delay sensitive applications (voice and video) as its UDP based while TLS is TCP based
https://www.cisco.com/c/en/us/support/docs/security/anyconnect-secure-mobility-client/215331-anyconnect-implementation-and-performanc.html Tunnel Protocol Selection By default, group policies on ASAs are configured to attempt establishing a DTLS tunnel. If UDP 443 traffic is blocked between the VPN headend and the AnyConnect client, it will automatically fallback to TLS. It is recommended to use DTLS or IKEv2 to increase maximum VPN throughput performance. DTLS offers better performance than TLS due to less protocol overhead. IKEv2 also offers better throughput than TLS. Additionally, using AES-GCM ciphers may slightly improve performance. These ciphers are available in TLS 1.2, DTLS 1.2 and IKEv2.
-
-
QUIC. Подробнее ниже.
-
- Современные реализации TCP поддерживают pluggable механизм TCP congestion control API по переключению congestion algorithm без изменения кода ядра
- Приложение в общем случае передает TCP стеку данные, которые TCP стек хранит пока получатель не подтвердит их прием. Поэтому они переделали стек на выгрузку данных от приложения, а не загрузку данных от приложения в стек (из статьи TRex ASTF).
Most TCP stacks have an API that allow the user to provide his buffer for write (push) and the TCP module will save them until the packets are acknowledged by the remote side.
The mbuf resource is expensive and needs to be allocated ahead of time. the solution we chose for this problem (which from a traffic generator’s point of view) is to change the API to be a poll API, meaning TCP will request the buffers from the application layer only when packets need to be sent (lazy). Now because most of the traffic is constant in our case, we could save a lot of memory and have an unlimited scale (both of flows and tx window).
- tcp syncookies (cookies) – подробнее в DoS/DDoS
- Почему плохо перебирать все порты – потому что логика обработка на один порт может очень отличаться от логики обработки на другие порты. К примеру, RoCEv2 UDP пакеты могут вообще перехватываться сетевой картой и не отправляться в ОС.
RDMA over Converged Ethernet (RoCE) is a network protocol that allows remote direct memory access (RDMA) over an Ethernet network.
Remote direct memory access
In computing, remote direct memory access (RDMA) is a direct memory access from the memory of one computer into that of another without involving either one's operating system. This permits high-throughput, low-latency networking, which is especially useful in massively parallel computer clusters.
I wonder if you have already met the following problem.
RFC 4814 requires the usage of pseudorandom source and destination port numbers. The recommended range for the destination port numbers is: [1, 49151].
However the 4791 destination port number identifies RoCEv2 ( https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet ).
If you use a NIC that supports RoCEv2 (and it is enabled) then about 20 test frames disappear from every 1 million test frames. Here are the results of a 60s long throughput test at 4,000,000fps rate:
root@hp1:~/siitperf# ./build/siitperf-tp 84 4000000 60 2000 2 2
EAL: Detected 32 lcore(s)
EAL: No free hugepages reported in hugepages-2048kB
EAL: Probing VFIO support...
EAL: PCI device 0000:5d:00.0 on NUMA socket 0 EAL:?? probe driver: 14e4:16d7 net_bnxt
PMD: Broadcom Cumulus driver bnxt
PMD: 1.10.1:214.4.91
PMD: Driver HWRM version: 1.5.1
PMD: bnxt found at mem e6e10000, node addr 0x7f56c0000000M
EAL: PCI device 0000:5d:00.1 on NUMA socket 0 EAL:?? probe driver: 14e4:16d7 net_bnxt
PMD: 1.10.1:214.4.91
PMD: Driver HWRM version: 1.5.1
PMD: bnxt found at mem e6e00000, node addr 0x7f56c0112000M
PMD: Port 0 Link Down
PMD: Port 0 Link Up - speed 10000 Mbps - full-duplex
PMD: Port 1 Link Down
PMD: Port 1 Link Up - speed 10000 Mbps - full-duplex
Info: Left port and Left Sender CPU core belong to the same NUMA node: 0
Info: Right port and Right Receiver CPU core belong to the same NUMA node: 0
Info: Right port and Right Sender CPU core belong to the same NUMA node: 0
Info: Left port and Left Receiver CPU core belong to the same NUMA node: 0
Info: Testing started.
Info: Reverse sender's sending took 59.9999998300 seconds.
Reverse frames sent: *240000000*
Info: Forward sender's sending took 59.9999999983 seconds.
Forward frames sent: 240000000
Reverse frames received: *239995097*
Forward frames received: 239995159
Info: Test finished.
root@hp1:~/siitperf# echo $(((240000000-239995097)/240))
*20*
That is, about 20 frames are lost from every 1,000,000 frames. (First, I have found it very strange. Using fixed port numbers, there was no frame loss, but using pseudorandom port numbers, 20 of 1,000,000 frames were lost even at significantly lower frame rates.)
I have debugged the issue by halving the destination port range, and I have found that if the destination port number range was set to [4791, 4791] then ALL test frames were lost!
I just wanted to save you a few hours of debugging by letting you know this issue. :-)
Best regards,
G?bor
TCP
- TCP такой сложный и имеет такое количество настраиваемых параметров, что поиск оптимальных значений с точки зрения user experience и безопасности может занимать долгое время – пример таблица TrendMicro Deep Security 10.2 с настройками TCP стека
В отличии от UDP, TCP:
- Sequencing – пересобирает сегменты в первоначальный stream
- Acknowledgement – требует подтверждения на отправленные сегменты данных
- Retransmission – повторно пересылает данные в случае если подтверждение не было получено или фиксируется значительный уровень перемешиваний в виде duplicated ack от принимающей стороны т.е. не обязательно по таймауту (подробнее в duplicated ack)
Flow control (контроль потока) на уровне TCP подразумевает в том числе реализацию классического механизма flow control с отсылкой от получателя отправителю пакетов (slow down в случае полного буфера на прием) с просьбой прекратить передачу т.к. получатель не справляется с потоком данных. По сути используя flow control TCP может снижать скорость передачи.
TCP buffer full -- Source is instructing Destination to stop sending data
tcp.window_size == 0 && tcp.flags.reset != 1
People often think the main difference between TCP and UDP is that TCP gives us guaranteed packet delivery. This is one of the most important features of TCP, but TCP also gives us flow control. Flow control is all about fairness, and critical for the Internet to work, without some form of flow control, the Internet would collapse.
Session multiplexing (мультиплексирование сессий) на уровне TCP позволяет мультиплексировать несколько потоков в один логический линк.
Просмотр транспортных сессий в системе
Состояние сессии:
- Для TCP есть информация о состоянии сессии – напр. established , syn-sent, syn-recv, fin-wait-1, fin-wait-2, time-wait, closed, closed-wait, last-ack, listen и close
- Для UDP, т.к. он stateless только – UCONN/ESTABLISHED
Утилиты:
- netstat
- telnet/nc
-
nc -zv 10.10.0.1 22 — проверяем, открыт ли порт 22 на удаленной стороне (Open)
-
# nc -zv 10.10.0.1 22
10.10.0.1: inverse host lookup failed: Unknown host
(UNKNOWN) [10.10.0.1] 22 (ssh) open
- ss (напр. 21 пример команды ss) – может (-tim) вывести очень подробную с точки зрения TCP стека информацию о каждой сессии
- участники сессии и сокеты
- состояние сессии
- объем переданных и полученных данных в пакетах и байтах
- используемый TCP алгоритм
- размер TCP и congestion TCP окон
- RTO/RTT
- скриптами (напр. psutil.net_connections)
UDP is a connectionless protocol. SS probably won't show one in LISTEN state, only in UCONN or ESTAB.
# ss -l -n
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
nl UNCONN 0 0 0:0 *
nl UNCONN 768 0 4:0 *
nl UNCONN 4352 0 4:1493 *
tcp LISTEN 0 1 0.0.0.0:80 0.0.0.0:*
# ss -au |grep 2333
ESTAB 0 0 127.0.0.1:2333 127.0.0.1:58434
ESTAB 0 0 127.0.0.1:58434 127.0.0.1:2333
# ss
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 172.16.0.2:46617 80.0.0.2:58324
ESTAB 0 2198064 172.17.0.2:39439 80.1.0.2:53066
ESTAB 0 2657080 172.17.0.2:45026 80.1.0.2:56618
ESTAB 0 0 172.16.0.2:50250 80.0.0.2:42840
# ss -tim
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 172.19.194.155:60617 172.18.187.106:43229
mem:(r0,w0,f8192,t0) cubic wscale:10,10 rto:204 rtt:4/2 ato:40 cwnd:10 send 29.0Mbps rcv_rtt:4 rcv_space:306976
ESTAB 0 0 172.19.250.250:50863 172.18.144.12:48623
mem:(r0,w0,f24576,t0) cubic wscale:10,10 rto:204 rtt:4/2 ato:40 cwnd:10 send 29.0Mbps rcv_rtt:4 rcv_space:335936
ESTAB 0 2041792 172.19.144.12:34823 172.18.250.250:38470
mem:(r0,w2065024,f7970176,t0) cubic wscale:10,10 rto:204 rtt:7.5/3 ato:40 ssthresh:2 send 3.1Mbps rcv_space:14600
# смотрим, что слушает и какие порты на локалке (вплоть до process-name/pid)
# ss -tunlp
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 0.0.0.0:45300 0.0.0.0:* users:(("squid",pid=28695,fd=9))
udp UNCONN 0 0 *:59107 *:* users:(("squid",pid=28695,fd=5))
tcp LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users:(("sshd",pid=524,fd=3))
tcp LISTEN 0 128 [::]:22 [::]:* users:(("sshd",pid=524,fd=4))
tcp LISTEN 0 128 *:3128 *:* users:(("squid",pid=28695,fd=12))
tcp 3whs (tcp syncronization, handshake)
- Почему используется трехстороннее рукопожатие TCP (TCP 3-Way Handshake), а не двухстороннее?
Потому что по сути происходит два разных согласования - на syn от a к b нужен ответ и так же ответ нужен на syn от b к a
Из канала Chris Greer интересное о TCP (о специфике wireshark в отдельной статье tcpdump): в первичном TCP handshake (3whs) содержится очень много полезной информации о разрешенных опциях при согласовании TCP (TCP syn – synchronization) и другой инфы, которую можно извлечь только из него или почти только из него. Это в том числе упрощает автоматический анализ wireshark т.к. он извлекает информацию ниже из handhake и подставляет в доп. поля анализа (напр. реальное receive окно в каждом пакете) для удобства. А согласование может быть нестандартным – ядренно-настроенные/урезанные реализации TCP стека (напр. IOT устройств) могут не поддерживать SACK, не иметь никакой scale фактор для TCP receive window при минимальном его объеме, анонсить минимальный MSS – см. скрин (или вообще никакой). Что полезного есть в 3WHS.
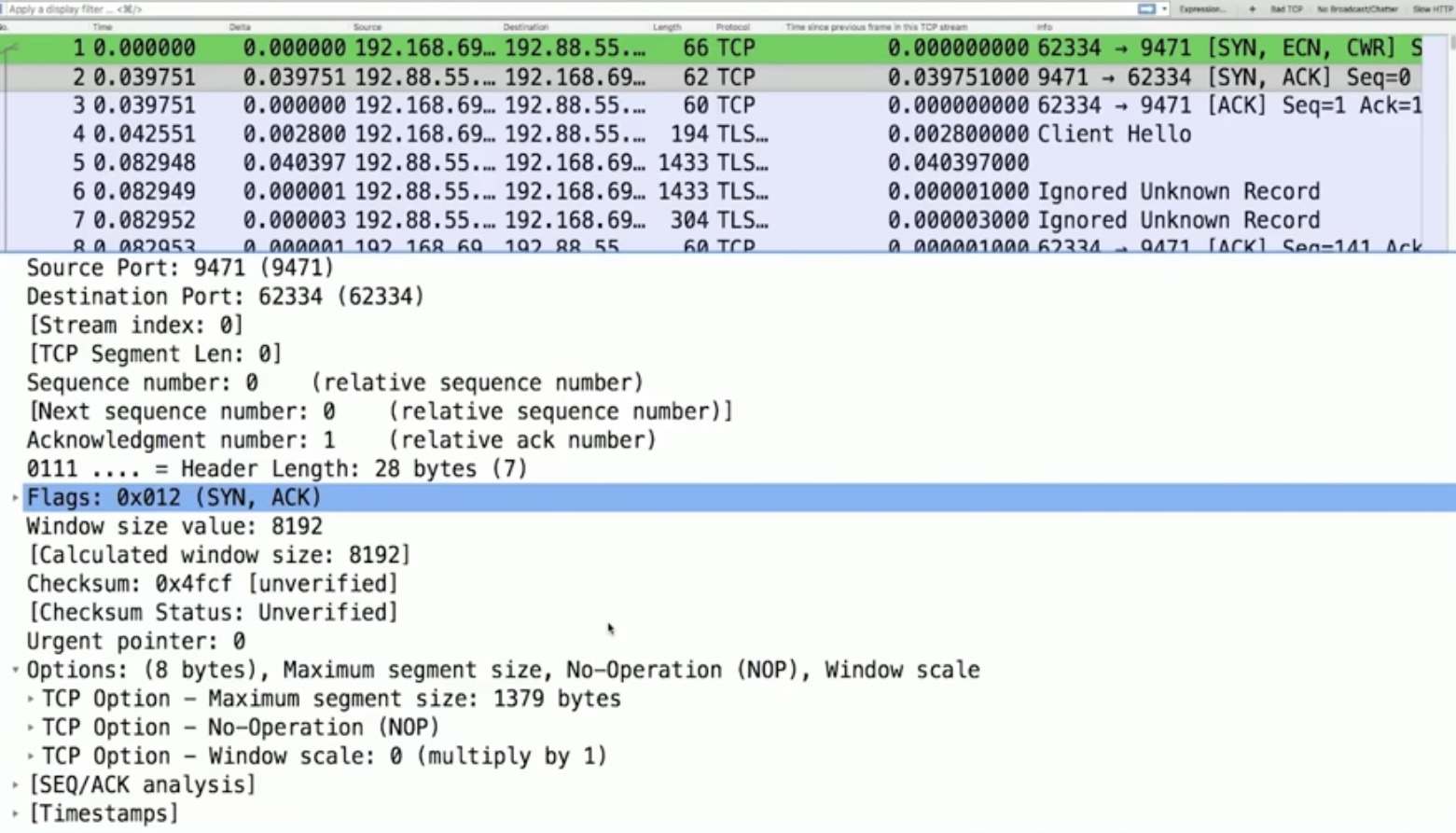
a) TCP RTT – TCP RTT определяется на основе задержки 3whs (при перехвате со стороны клиента разница первых двух пакетов, со стороны сервера – последних двух), либо по ответам сервера/клиента: отослали seqnumber xxx, смотрим когда придет ответ на данный запрос/sequence number).
b) TCP receive window вместе с scale factor – scale factor передается только в 3whs и точное окно можно знать по сути только имея хендшейк, иначе можно выяснить косвенно по макс. объему данных, отсылаемых без подтверждения. Косвенно о использовании scale фактора/множителя окна можно подозревать на основе небольшого размера самого окна.
c) анонсирование поддержки (клиент) и подтверждения поддержки (сервер) selective acknowledgement (SACK)/разрешение fast retransmissions (устройство без поддержки будет игнорить dup ack)
d) точное значение TCP MSS, иначе выяснять косвенно по макс. размеру отправляемых сегментов с данными. Подробнее про MSS ниже.
e) поддержка window scale – ты свой scale factor несмотря на твой анонс в handshake применить сможешь только после того как сосед подтвердит его поддержку при согласовании; косвенно есть ли поддержка scale factor можно понять (см. выше про receive window)
f) no operation (NOOP) в tcp header опциях это просто выравнивание header по целочисленному делению на 4 – header по байтам должен делиться на 4, если байт нехватает для этого отправитель добавляет/добивает поля NOOP до выравнивания.
tcp sequence, tcp acknowledgement numbers
Отправитель инкрементирует свое TCP Sequence значение при каждой отправке данных. Само значение sequence number обычно огромный псевдо-рандомный integer (который wireshark может любезно скрывать за обнуленным для каждой сессии relative sequence number), выбираемый на каждой стороне независимо в момент согласования 3WHS.
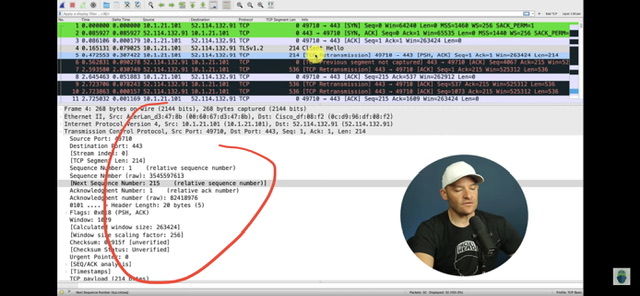
Acknowledge номера – это подтверждения на sequence номера соседа в виде sequence num + количество полученных данных (tcp len)/или один псевдо-байт при handshake. Называется этот псевдо-байт ghost byte т.к. по факту данных не передавалось, но мы инкрементировали ack на 1, как будто получили байт данных. По ack отправитель понимает какие данные получил получатель, а какие нужно переотправить т.к. ack не соответствует твоему актуальному sequence. Т.е. ты подтверждаешь ack-ами sequence номера/данные полученные от соседа, а он ack-ами подтвержает твои sequence номера. К слову – tcp segments not captured в wireshark означает, что wireshark увидел сдвиг по sequence numbers т.е. какие то сегменты с данными не попали в pcap.
tcp retransmissions
явным индикатором проблемы в сети чаще всего являются наличие TCP retransmission в дампах, хотя и помимо ретрансмиссий так же бывают проблемы с задержками, перемешиваниями и проч
1) retransmission timeout зачастую в стеках равен трем-четырем значениям TCP RTT
2) при получении 3 duplicated ack (в рамках selective acknowledgement) на один сегмент отправитель может сгенерировать fast retransmission (т.е. не ожидая retransmission таймаута), три, а не один, в расчете что dup ack зачастую генерируется в следствии перемешивания, а не потери сегментов и генерировать сразу на первый же – потенциально лишний раз нагружать сеть
3) spurious retransmission в wireshark – это wireshark задетектировал бесполезную ретрансмиссию вида – был отправлен сегмент и в дампе присутствует подтверждение на этот сегмент, при этом произошла ретрансмиссия (напр. подтверждение по факту не дошло до отправителя/дошло поздно)
tcp keepalive
Передаются в случае отсутствия сообщений в незакрытой tcp сессии чтобы понять жива ли вторая сторона – отвалилась ли она/сеть до нее. Если вторая сторона отвечает, что жива, то соединение не разрывается. Пример ниже приложение долго не отвечает, стек постоянно запрашивает keep alive’ами живость соседа и получает ответ. Потом наконец отвечает приложение.
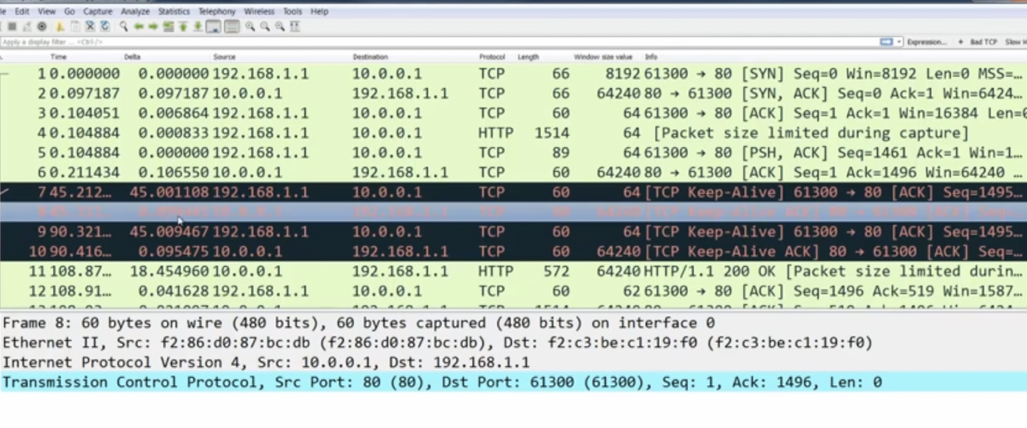
Window
- (tcp, iptables) Изменение TCP окна на промежуточном оборудовании – огромная редкость и должно быть использовано только для тестов в общем случае. Изменить можно добавив модуль ipt_tcpwin в iptables. Одна из причин, почему это делать не стоит – изменение требует пересчет TCP Checksum, хотя это и может быть реализовано на уровне offload, но не в данном случае судя по коду модуля.
https://serverfault.com/questions/528065/how-to-edit-tcp-window-size-from-iptables
To change TCP window from iptables you need to:
1) checkout https://github.com/p5n/ipt_tcpwin ((to use in POSTROUTING chain we should modify TCP checksum))
2) build both modules using "make"
3) add iptables rule, for example:
iptables -t mangle -I OUTPUT -p tcp --sport 80 --tcp-flags SYN,ACK SYN,ACK -j TCPWIN --tcpwin-set 1000
This iptables module changes TCP window header field. The purpose is only testing and debugging because of changing TCP window
usualy is very bad idea.
receive window
receive window – получатель (при этом каждая сторона и получатель и отправитель одновременно) анонсирует при установке TCP соединения сколько он может максимум принять без подтверждений (предел для congestion window отправителя). Серверная сторона, в отличии от клиентской, зачастую может не анонсировать большое значение TCP receive window, чтобы не аллоцировать под каждое соединение большой объем памяти (он же сервер и обслуживает много клиентов, плюс защита от некого DoS). Так же в начале окно может и клиентом анонсироваться небольшого размера по этой же причине (излишняя аллокация памяти).
receivew window может обновляться в ходе работы – напр. увеличиваться. Называется это window update. С точки зрения дампа выглядит как пакет без фалага ack, но содержащий новую информацию по окну.
Receive window не зависит от congestion алгоритма TCP, в отличии от congestion окна.
zero window это индикатор того, что окно заполнилось до предела – т.е. Wireshark фиксирует что для заанонсированного окна передано предельное кол-во сегментов без подтверждения.
zero window или полное/почти полное исчерпывание receive окна не равно тому, что проблема со стеком и значением окна – исчерпание окна в первую очередь говорит о том, что TCP буфер недостаточно быстро извлекается/обрабатывается приложением (scoop up) и даже если размер этого буфера (окна) увеличить – это не приведет к тому, что приложение быстрее начнет обрабатывать данные из буфера. Пример исчерпания окна:
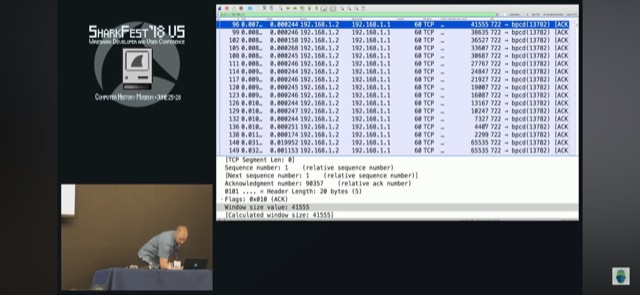
CONGESTION WINDOW, TCP slow start
congestion/sender windows cwin – не анонсируемый параметр сколько отправитель может максимум отослать не ожидая подтверждений. Именно управление значением congestion окна TCP реализует congestion management TCP и зависит от алогоритма TCP.
Размер congestion окна определяется по двум критириям:
1) сколько можно поместить максимум в провод (насколько можно максимум разогнать congestion окно), пока не начнутся проблемы (ретрансмиссии) или
2) до того как congestion окно достигло receive window. А cwin не превысит rwin т.к. cwin не может быть (если только не сознательное нарушение RFC) выше receive window получателя, даже если нет никаких потерь.
Так же:
1) первичное cwin окно обычно является некоторым множетелем к TCP MSS – от 1 до ~10 (чаще всего 10)
# Windows
Win> Get-NetTCPSetting
SettingName : Internet
MinRto(ms) : 300
InitialCongestionWindow(MSS) : 10
# Linux
root@trex:~# ss -nli|fgrep cwnd
cubic cwnd:10
cubic cwnd:10/usr/src/linux/include/net/tcp.h: /* TCP initial congestion window as per draft-hkchu-tcpm-initcwnd-01 */ #define TCP_INIT_CWND 10
2) далее в случае успешной передачи (называется это успешным RTT) без потерь оно может инкрементироваться или домножаться, а не сразу становится равным receive window – это называется slow start. например, сначала домнажаться на два каждый раз до потерь и до достижения slow start threshold и только после достижения ssthresh инкрементироваться
3) в случае потерь оно может откатываться в первичное окно или уменьшаться более плавно
Чем отличается congestion window (сколько отправляем без подтверждения) от receive window (сколько готовы получить без подтверждения). CDN провайдеры зачастую выкручивают congestion window в отличные от default (10*MSS) значения – т.е. делают более 10, при этом в draft netsecopen явно прописали, чтобы congestion windows не превышал 10*MSS (т. е. кейс с выкруткой в большие значения like CdN рассматривается как не типовой). В случае “стандартного” MSS в 1460 congestion window = 14600.
https://blog.stackpath.com/glossary-cwnd-and-rwnd/
Congestion Window (cwnd) is a TCP state variable that limits the amount of data the TCP can send into the network before receiving an ACK. The Receiver Window (rwnd) is a variable that advertises the amount of data that the destination side can receive.
https://datatracker.ietf.org/doc/draft-ietf-bmwg-ngfw-performance/
In addition, server initial congestion window MUST NOT exceed 10 times the MSS.
https://www.cdnplanet.com/blog/tune-tcp-initcwnd-for-optimum-performance/
https://www.cdnplanet.com/blog/initcwnd-settings-major-cdn-providers/
As illustrated in the video and as you have seen in our example transaction in the section above, a server does not necessarily adhere to the client's RWIN (receivers advertised window size).
The client told the server it can receive a maximum of 65,535 bytes of un-acknowledged data (before ACK), but the server only sent about 4 KB and then waited for ACK.
This is because the initial congestion window (initcwnd) on the server is set to 3. The server is being cautious.
Rather than throw a burst of packets into a fresh connection, the server chooses to ease into it gradually, making sure that the entire network route is not congested.
The more congested a network is, the higher is the chances for packet loss. Packet loss results in retransmissions which means more round trips, resulting in higher download times.
Step 1: Client sends SYN to server - "How are you? My receive window is 65,535 bytes."
Step 2: Server sends SYN, ACK - "Great! How are you? My receive window is 4,236 bytes"
Step 3: Client sends ACK, SEQ - "Great as well... Please send me the webpage https://www.example.com/"
Step 4: Server sends 3 data packets. Roughly 4 - 4.3 kb (3*MSS1) of data
Step 5: Client acknowledges the segment (sends ACK)
Step 6: Server sends the remaining bytes to the client
Slow start begins initially with a congestion window size (CWND) of 1, 2, 4 or 10 MSS.[5][3]:1 The value for the congestion window size will be increased by one with each acknowledgement (ACK) received, effectively doubling the window size each round-trip time.[c] The transmission rate will be increased by the slow-start algorithm until either a loss is detected, or the receiver's advertised window (rwnd) is the limiting factor, or ssthresh is reached. If a loss event occurs, TCP assumes that it is due to network congestion and takes steps to reduce the offered load on the network. These measurements depend on the exact TCP congestion avoidance algorithm used.
Так же на stackoverflow.
https://stackoverflow.com/questions/11555662/tcp-difference-between-congestion-window-and-receive-window
To give a short answer: the receive window is managed by the receiver, who sends out window sizes to the sender. The window sizes announce the number of bytes still free in the receiver buffer, i.e. the number of bytes the sender can still send without needing an acknowledgement from the receiver.
The congestion window is a sender imposed window that was implemented to avoid overrunning some routers in the middle of the network path. The sender, with each segment sent, increases the congestion window slightly, i.e. the sender will allow itself more outstanding sent data. But if the sender detects packet loss, it will cut the window in half. The rationale behind this is that the sender assumes that packet loss has occurred because of a buffer overflow somewhere (which is almost always true), so the sender wants to keep less data "in flight" to avoid further packet loss in the future.
(дублируется в TCP, TRex)
TRex позволяет настроить как размер TCP TX/RX окна (через буферы rxbufsize, txbufsize), так и размер TCP congestion окна (initcwnd, initwnd, cwnd). По умолчанию TX/RX окно = 32к, congestion окно = 10 MSS. По netsecopen значение не должно превышать 10. Значение default подтверждается default linux и соответствует методике netsecopen. Подробнее о TCP slow start в tcp.
https://datatracker.ietf.org/doc/draft-ietf-bmwg-ngfw-performance/
Client initial congestion window SHOULD NOT exceed 10 times the MSS.
In addition, server initial congestion window MUST NOT exceed 10 times the MSS.
https://trex-tgn.cisco.com/trex/doc/trex_astf.html
tcp.initwnd 1-20 10 init window value in MSS units.
root@trex:~# ss -nli|fgrep cwnd
cubic cwnd:10
cubic cwnd:10
-bash-4.4# ss -nli|fgrep cwnd
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
cubic rto:1000 mss:536 cwnd:10 lastsnd:500100680 lastrcv:500100680 lastack:500100680
Окно initcwnd кастомизируют хостеры CDN, но я “сходу” изменения поведения стека от изменения настройки initcwnd не обнаружил.
- Провел эксперимент по изменению congestion window (cwnd) в TRex – в дампе НЕ фиксирую корректную работу конфигурации – НЕ отправляется меньше данных после 3whs (сервер отправляет burst из 10 пакетов после запроса клиента).
- Эксперимент со стеком ОС – он тоже игнорирует congestion window. Как отсылал после первого ACK так и продолжает.
Congestion window можно настроить для определенных подсетей.
ip netns exec VRF2 sudo nc -l -p 80
ip netns exec VRF1 telnet 172.17.0.2 80
PASTE LONG TEXT
ip netns exec VRF1 ip route add default via 172.0.0.1 dev enp3s0f0 onlink initcwnd 1
ip netns exec VRF2 ip route add default via 172.17.0.1 dev enp3s0f1 onlink initcwnd 1
ip netns exec VRF1 ip route add default via 172.0.0.1 dev enp3s0f0 onlink initcwnd 100
ip netns exec VRF2 ip route add default via 172.17.0.1 dev enp3s0f1 onlink initcwnd 100
TX/RX WINDOW
- Размер буфера на прием и на передачу определяет размер RX окна. Оптимальный усредненный буфер 64КБ. И в среднем чем больше – тем лучше, рекомендация настраивать MAX размер буфера (предел разгона окна; net.ipv4.tcp_rmem и net.ipv4.tcp_wmem) 16MB и выше для 10G каналов – по факту выше сейчас по умолчанию на Debian 10 (wmem 32, rmem 48 MB по умолчанию). Oracle в контексте своего Java APP Coherence рекомендует высокие значения буфера для защиты потери приходящих данных во время garbage collection.
To help minimization of packet loss, the OS socket buffers need to be large enough to handle the incoming network traffic while your Java application is paused during garbage collection.
Выбор при этом идеального размера буфера для конкретных сценариев – вопрос не такой простой, с одной стороны больший буфер возможность меньше задейcтвовать CPU (за счет минимизации включения flow control из-за переполнений буфера), с другой есть риск попасть под paging (перемещение в SWAP) не используемых страниц если система не использует выделенные буферы. Поэтому при изменении размера окна нужно мониторить CPU утилизацию и paging rate.
Описание net.ipv4.tcp_rmem и net.ipv4.tcp_wmem:
-
- Минимальный размер ограничен минимальным размером страницы (page) в 4096 байт
- Средний размер определяет размер TCP окна (первичного до разгона, насколько понимаю)
- Максимальный определяет максимальный размер TCP окна
https://www.ibm.com/docs/en/linux-on-systems?topic=tuning-tcpip-ipv4-settings
Contains three values that represent the minimum, default and maximum size of the TCP socket receive buffer:
- The minimum represents the smallest receive buffer size guaranteed, even under memory pressure. The minimum value defaults to 1 page or 4096 bytes.
- The default value represents the initial size of a TCP sockets receive buffer. This value supersedes net.core.rmem_default used by other protocols.
-- net.ipv4.tcp_rmem: The default value for this setting is 87380 bytes. It also sets the tcp_adv_win_scale and initializes the TCP window size to 65535 bytes.
-- net.ipv4.tcp_wmem: The default value for this setting is 16K bytes.
- The maximum represents the largest receive buffer size automatically selected for TCP sockets. This value does not override net.core.rmem_max. The recommendation is to use the maximum value of 16M bytes or higher (kernel level dependent) especially for 10 Gigabit adapters.
-- net.ipv4.tcp_rmem: The default value for this setting is somewhere between 87380 bytes and 6M bytes based on the amount of memory in the system.
-- net.ipv4.tcp_wmem: The default value for this setting is somewhere between 64K bytes and 4M bytes based on the amount of memory available in the system.
DEFAULT (Debian 10)
net.ipv4.tcp_rmem = 4096 87380 6291456
net.ipv4.tcp_wmem = 4096 16384 4194304
https://www.ibm.com/docs/en/was-zos/8.5.5?topic=SS7K4U_8.5.5/com.ibm.websphere.nd.multiplatform.doc/ae/tprf_tunetcpip.html
For a TCP/IP socket connection, the send and receive buffer sizes define the receive window.
Buffer sizes for the socket connections between the web server and WebSphere Application Server are set at 64KB. In most cases this value is adequate.
If the receive window size for TCP/IP buffers is too small, the receive window buffer is frequently overrun, and the flow control mechanism stops the data transfer until the receive buffer is empty.
Flow control can consume a significant amount of CPU time and result in additional network latency as a result of data transfer interruptions. It is recommended that you increase buffer sizes to avoid flow control under normal operating conditions. A larger buffer size reduces the potential for flow control to occur, and results in improved CPU utilization. However, a large buffer size can have a negative effect on performance in some cases. If the TCP/IP buffers are too large and applications are not processing data fast enough, paging can increase. The goal is to specify a value large enough to avoid flow control, but not so large that the buffer accumulates more data than the system can process.
The optimal buffer size depends on several network environment factors including types of switches and systems, acknowledgment timing, error rates and network topology, memory size, and data transfer size. When data transfer size is extremely large, you might want to set the buffer sizes up to the maximum value to improve throughput, reduce the occurrence of flow control, and reduce CPU cost.
Recycle TCP/IP, then monitor CPU and paging rates to determine if they are within recommended system guidelines.
Window size определяет максимальный размер окна, который может передать отправитель без подтверждения о получении от получателя. Стандартный размер окна варьируется между 32768 и 65535 байта (64 KByte netsecopen). Управление размером окна делается через настройку буфера на отправку (сколько мы можем максимум отослать) и прием (сколько мы можем максимум получить – наше значение RCV BUF). Пример управления окном на базе Cisco TRex и python socket.
tcp.txbufsize # TRex
tcp.rxbufsize # TRex
# python socket rewrite tcp_rmem/tcp_wmem (Linux) (не rmem_max/wmem_max)
s.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF, 2048)
s.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 2048)
# default from tcp_rmem/tcp_wmem (Linux) (не rmem_max/wmem_max)
>>> print(s.getsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF))
131072
>>> print(s.getsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF))
16384
Пример 4 рандомных 3whs с разными ресурсами с MacOS youtube, Mojave - debian, yandex, avito:
Пример 3whs с Google с Windows Win10:


Можно настроить и в ОС. Эффекта в python приложении может не быть по практике от этой настройки; особенно, если приложение не перезапустить (не перечитать переменные).
They contain three numbers, which are minimum, default and maximum memory size values (in byte), respectively.
# cat /proc/sys/net/ipv4/tcp_rmem # net.ipv4.tcp_rmem
4096 131072 6291456
# cat /proc/sys/net/ipv4/tcp_wmem # net.ipv4.tcp_wmem
4096 16384 4194304
# cat /proc/sys/net/ipv4/tcp_window_scaling
1
# sysctl -w net.ipv4.tcp_rmem="4096 4096 4096"
# sysctl -w net.ipv4.tcp_wmem="4096 4096 4096"
# sysctl -w net.ipv4.tcp_rmem="4096 131072 6291456"
# sysctl -w net.ipv4.tcp_wmem="4096 16384 4194304"
По факту указанное значение будет умножено на два в Linux в сравнении с фактически передаваемым значением byte – ядро Linux умножает на два значения SO_SNDBUF и SO_RCVBUF и это судя по всему корректное поведение.
NOTES
Linux assumes that half of the send/receive buffer is used for internal kernel structures; thus the sysctls are twice what can be observed on the wire.
Так же в ОС в общем случае включен scaling механизм, который позволяет “разогнать” окно – вплоть до нескольких мегабайт (скрины 1.44 МБ и 2.4 МБ с окном как на MacOS Mojave, так и 2.17 МБ на Win10).


TCP socket reuse
Полезная настройка, хотя по умолчанию выключена – позволяет использовать созданные сокеты находящиеся в полумертвом состоянии для работы с новыми соединениями. На практике использовал в python, в том числе опция есть для UDP сокетов, подробнее там же в python.
https://www.ibm.com/docs/en/linux-on-systems?topic=tuning-tcpip-ipv4-settings
net.ipv4.tcp_tw_reuse
Permits sockets in the “time-wait” state to be reused for new connections.
In high traffic environments, sockets are created and destroyed at very high rates. This parameter, when set, allows “no longer needed” and “about to be destroyed” sockets to be used for new connections. When enabled, this parameter can bypass the allocation and initialization overhead normally associated with socket creation saving CPU cycles, system load and time.
The default value is 0 (off). The recommended value is 1 (on).
TCP PERFORMANCE and RTT & TCP WIN SIZE
Latency and round-trip time effects on TCP
Round-trip time has a direct effect on maximum TCP throughput. In TCP protocol, window size is the maximum amount of traffic that can be sent over a TCP connection before the sender needs to receive acknowledgement from the receiver.
If the TCP MSS is set to 1,460 and the TCP window size is set to 65,535, the sender can send 45 packets before it has to receive acknowledgement from the receiver. If the sender doesn’t get acknowledgement, it will retransmit the data. Here’s the formula:
TCP window size / TCP MSS = packets sent
In this example, 65,535 / 1,460 is rounded up to 45.
This “waiting for acknowledgement” state, a mechanism to ensure reliable delivery of data, is what causes RTT to affect TCP throughput. The longer the sender waits for acknowledgement, the longer it needs to wait before sending more data.
Here’s the formula for calculating the maximum throughput of a single TCP connection:
Window size / (RTT latency in milliseconds / 1,000) = maximum bytes/second
Windows size 65K
RTT 1 ms = 500 mbps
RTT 30 ms = 20 mbps
RTT 60 ms = 10 mbps
RTT 90 ms = 5 mbps
If packets are lost, the maximum throughput of a TCP connection will be reduced while the sender retransmits data it has already sent.
TCP window scaling is a technique that dynamically increases the TCP window size to allow more data to be sent before an acknowledgement is required. In the previous example, 45 packets would be sent before an acknowledgement was required.
If you increase the number of packets that can be sent before an acknowledgement is needed, you’re reducing the number of times a sender is waiting for acknowledgement, which increases the TCP maximum throughput.
The scale factor is also a setting that you can configure in an operating system.
A scale factor of 14 results in a TCP window size of 14 (2^14 the maximum offset allowed; default 2^8). The TCP window size will be 1,073,725,440 bytes (8.5 gigabits).
RTT 30 ms Win 130k = 40 mbps
RTT 30 ms Win 260k = 70 mbps
RTT 30 ms Win 520k = 140 mbps
TCP timers
TCP таймеры/таймауты влияют как на производительность, так и на устойчивость системы от DoS атак. Важно быстро закрывать сессии:
-
- полуоткрытые (TCP start/syn timeout),
- полузакрытые (TCP fin timeout),
- полностью закрытые (TCP end timeout: TIME_WAIT, FIN_WAIT)
- неиспользуемые (TCP, UDP idle timeout)
К примеру, в контексте TCP end/fin timeout:
У Cisco timeout включается после закрытия хотя бы одной из сторон (но обновляется при обмене пакетами), у Checkpoint таймер включается только после закрытия с обеих сторон.
Cisco
TCP provides the ability for one end of a connection to terminate its output, while still receiving data from
the other end of the connection. This TCP state is called the half-close state. A session enters the half-close
state when it receives the first TCP finish (FIN) segment and starts a timer. If another segment is received
before the session timeout occurs, then the timer is restarted. You can set the timeout value for a half-close
session by using the tcp finwait-time command. The default timeout value for half-close sessions is 30
seconds.
Checkpoint
The End (connection) Timeout describes the connection expiration once the connection reaches both FIN (received FIN from both sides or RST) – aka, terminated. This timeout allow us to handle retransmissions post connection termination. We found that most of the connections found in the connection table are terminated connections that wait to be expired. In order to improve gateway performance (reduce memory consumption and improve table lookup), we reduced the timeout to 5 sec (from 20).
IBM предлагает по умолчанию не менять таймеры, но говорит о том, что возможны случаи, когда это будет оправдано и это разговор о конечном приложении работающем между клиентом и сервером, не о промежуточном сетевом оборудовании!
In the most demanding benchmarks you may find that even defining 65K sockets and file descriptors does not give you enough 'free' sockets to run 100%. When a socket is closed abnormally (for example, no longer needed) it is not made available immediately. Instead it is placed into a state called finwait2 (this is what shows up in the netstat -s command). It waits there for a period of time before it is made available in the free pool. The default for this is 600 seconds.
If you are using z/OS® Version 1.2 or later you can control the amount of time the socket stays in finwait2 state by specifying the following in the configuration file:
FINWAIT2TIME 60
TIME_WAIT по сути это “сколько ждать мало ли после закрытия еще прилетят пакеты”. С TIME_WAIT счетчиком нужно аккуратно, о том, что он может повлиять на performance пишут и в MS в документации Azure – но можно “перекрутить” и рассинхронизировать его между сторонами и одна из сторон будет отправлять сегменты, когда вторая уже закрыла сокет.
TCP TIME_WAIT is another common setting that affects network and application performance. On busy VMs that are opening and closing many sockets, either as clients or as servers (Source IP:Source Port + Destination IP:Destination Port), during the normal operation of TCP, a given socket can end up in a TIME_WAIT state for a long time. The TIME_WAIT state is meant to allow any additional data to be delivered on a socket before closing it. So TCP/IP stacks generally prevent the reuse of a socket by silently dropping the client's TCP SYN packet.
Изменение значений таймеров в Linux.
Независимо от того, менять значение переменной в <ipv4> или <netfilter> дереве изменяются оба таймаута сразу.
serv# sysctl -a | grep _conntrack_udp_time
net.ipv4.netfilter.ip_conntrack_udp_timeout = 30
net.ipv4.netfilter.ip_conntrack_udp_timeout_stream = 300
net.netfilter.nf_conntrack_udp_timeout = 30
net.netfilter.nf_conntrack_udp_timeout_stream = 300
serv# sysctl -w net.netfilter.nf_conntrack_udp_timeout=300
net.netfilter.nf_conntrack_udp_timeout = 300
serv# sysctl -a | grep _conntrack_udp_time
net.ipv4.netfilter.ip_conntrack_udp_timeout = 300
net.ipv4.netfilter.ip_conntrack_udp_timeout_stream = 300
net.netfilter.nf_conntrack_udp_timeout = 300
net.netfilter.nf_conntrack_udp_timeout_stream = 300
RFC 879, 1122, 2581 TCP MSS
-
TCP MSS – анонс от получателя отправителю «сколько TCP данных ты мне можешь послать в одном пакете» (подробнее ниже в отдельном разделе)
- MSS не согласовывается между TCP пирами, это НЕ согласование.
- MSS не обязан указываться в 3whs или в последующих сегментах (хотя может указываться хоть в каждом), в таком случае по умолчанию он считается равным 536
TCP SHOULD send an MSS (Maximum Segment Size) option in every SYN segment when its receive MSS differs from the default 536, and MAY send it always.
- MSS изменяется при изменении MTU – при уменьшении MTU уменьшается и MSS.
- PMTUD – Path MTU Discovery

- MSS анонс отправляется получателем в сторону отправителя и говорит о том, сколько получатель данных в виде TCP сегмента может максимум получить.
- Значение MSS может быть разным по каждому направлению (на прием, свое, одно, на отправку в сторону соседа другое).
- MSS считается только для TCP payload (tcp len), MSS не включает данные TCP/IP/ethernet header.
Maximum Segment Size (MSS) announcement (often mistakenly called a negotiation) is sent from the data receiver to the data sender and says "I can accept TCP segments up to size X". The size (X) may be larger or smaller than the default. The MSS can be used completely independently in each direction of data flow. The result may be quite different maximum sizes in the two directions.
The MSS counts only data octets in the segment, it does not count the TCP header or the IP header. A footnote: The MSS value counts only data octets, thus it does not count the TCP SYN and FIN control bits even though SYN and FIN do consume TCP sequence numbers.
- Классическая проблема с MSS, когда один хост может получить по факту меньше данных, чем ему отправляется (в сторону клиента по факту MSS меньше, чем он анонсирует т.к. устройство посередине роутер/wan optimization/tunnel добавляет данные) выглядит в дампе я бы сказал не просто для того, кто не знает как это выглядит
- Происходит 3whs
- Клиент отправляет HTTP (any) request на сервер и получает от сервера ack на этот request
- Далее на сервере и клиенте видим разное:
- На клиент прилетает один пакет небольшого размера со сдвигом sequence number, сдвиг детектирует стек клиента (и wireshark в виде previous segment uncaptured) и отсылает dullicated ack на смещенный сегмент данных и только через ~20 секунд получает несколько сегментов среднего размера, включающих нужные данные! Причем получает клиент их не в виде одного пакета, а в виде трех пакетов среднего размера ~550 байт каждый. Весь последующий трафик от сервера прилетает с максимальным MSS в 536 байт, происходит нормальный обмен без потерь.
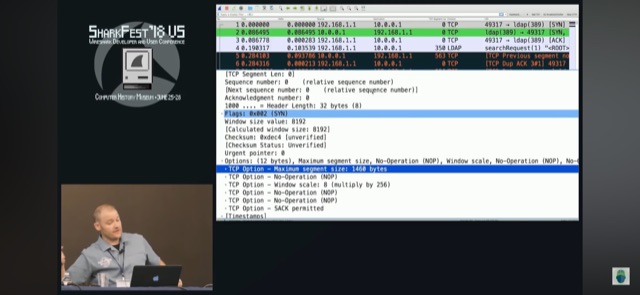
- Первично со стороны сервера отсылается два пакета, один максимального размера, превышающий фактический mss (не доходит до клиента) и небольшого размера (доходит до клиента). Далее сервер получае подтверждение на небольшой сегмент и dupack на большой, но т.к. Dupack всего один, а не три и сервер только по retransmission timer (3 секунды) отсылает повторно большой пакет с максимальным MSS, он не доходит до клиента и как ack, так и duplicated ack по этому сегменту не приходят серверу, поэтому сервер удваивает retransmission timer (до 6 сек) и отсылает еще раз, потом еще раз (до 12 сек), но так же сервер пробует последнюю меру – он уменьшает TCP MSS до минимума/дефолта в 536 байт. В итоге серверные ответы доходят до клиента, клиент их подтверждает и начинается полноценное взаимодействие без потерь, при этом TCP MSS не увеличивается более 536 байт.
tcp connection timeouts
TCP таймауты разные в зависимости от состояния сессии/передачи данных по ней:
- При установке сессии незначительный timeout (до минуты)
- Для установленной сессии при отсутствии подтверждения на отправленные данные timeout чуть больше (до нескольких минут)
- Для установленной сессии без потерь данных по ней по умолчанию значительный timeout (3600 секунд/час)
-
1) If a TCP session doesn’t fully establish. For example you attempt to go to a web site that’s full down. That will trigger something called the exponential back off using the default RTO, in Linux that’s equal to 1 second. This will re-transmit the SYN packet 5 times and doubling the time interval between each re-transmit. This results in a timeout after roughly 31 seconds. This is known as the exponential backoff.
-
2) If you do establish the connection where data is sent and the connection suddenly drops, the exponential back off will begin but with a different RTO calculation. The same 5 re-transmits will occurs timing out in roughly 30 seconds give or take a few seconds
Default TCP session timeout:- Minimum of 60 seconds and a maximum of 86400 seconds (24 hours), although the default 3600 seconds (1 hour)
checksum (контрольная сумма)
- TCP Header,
- TCP body,
- Pseudo IP header:
- IP of the Source
- IP of the Destination
- TCP/UDP segment Length
- Protocol (stating the type of the protocol used)
- Fixed of 8-bits
SS (socket statistics)
Полезный инструмент для дебага TCP. Показывает очень много информации.
As you’re exploring tuning TCP performance, make sure to use socket statistics, or ss, like below. This tool displays a ton of socket information, including the TCP flow control algorithm used, the round trip time per TCP session as well as the calculated bandwidth and actual delivery rate between the two peers.
root@compute-000:~# ss -tniState Recv-Q Send-Q Local Address:Port Peer Address:PortESTAB 0 9172816 [::ffff:147.75.71.47]:5201 [::ffff:147.75.69.253]:37482
bbr wscale:8,8 rto:344 rtt:141.401/0.073 ato:40 mss:1448 pmtu:1500 rcvmss:536 advmss:1448 cwnd:3502 ssthresh:4368 bytes_acked:149233776 bytes_received:37 segs_out:110460 segs_in:4312 data_segs_out:110459 data_segs_in:1 bbr:(bw:354.1Mbps,mrtt:140,pacing_gain:1,cwnd_gain:2) send 286.9Mbps lastsnd:8 lastrcv:11008 pacing_rate 366.8Mbps delivery_rate 133.9Mbps busy:11008ms rwnd_limited:4828ms(43.9%) unacked:4345 retrans:7/3030 lost:7 sacked:1197 reordering:300 rcv_space:28960 rcv_ssthresh:28960 notsent:2881360 minrtt:140
AlGORITHMS
Разные алгоритмы работают по разному, особенно в условиях проблем в сети (задержки и потери). Алгоритмы определяют как быстро передает отправитель данные, адаптируясь под сетевые изменения.
What these algorithms do is determining how fast the sender should send data while adapting to network changes.
Причем нет необходимости использования одного алгоритма между участниками TCP-сессии. Они спокойно могут использовать разные. Просто передающий с лучшим алгоритмом будет передавать данные быстрее.
Note: the congestion control algorithm used for a TCP session is only locally relevant. So, two TCP speakers can use different congestion control algorithms on each side of the TCP session. In other words: the server (sender), can enable BBR locally; there is no need for the client to be BBR aware or support BBR.
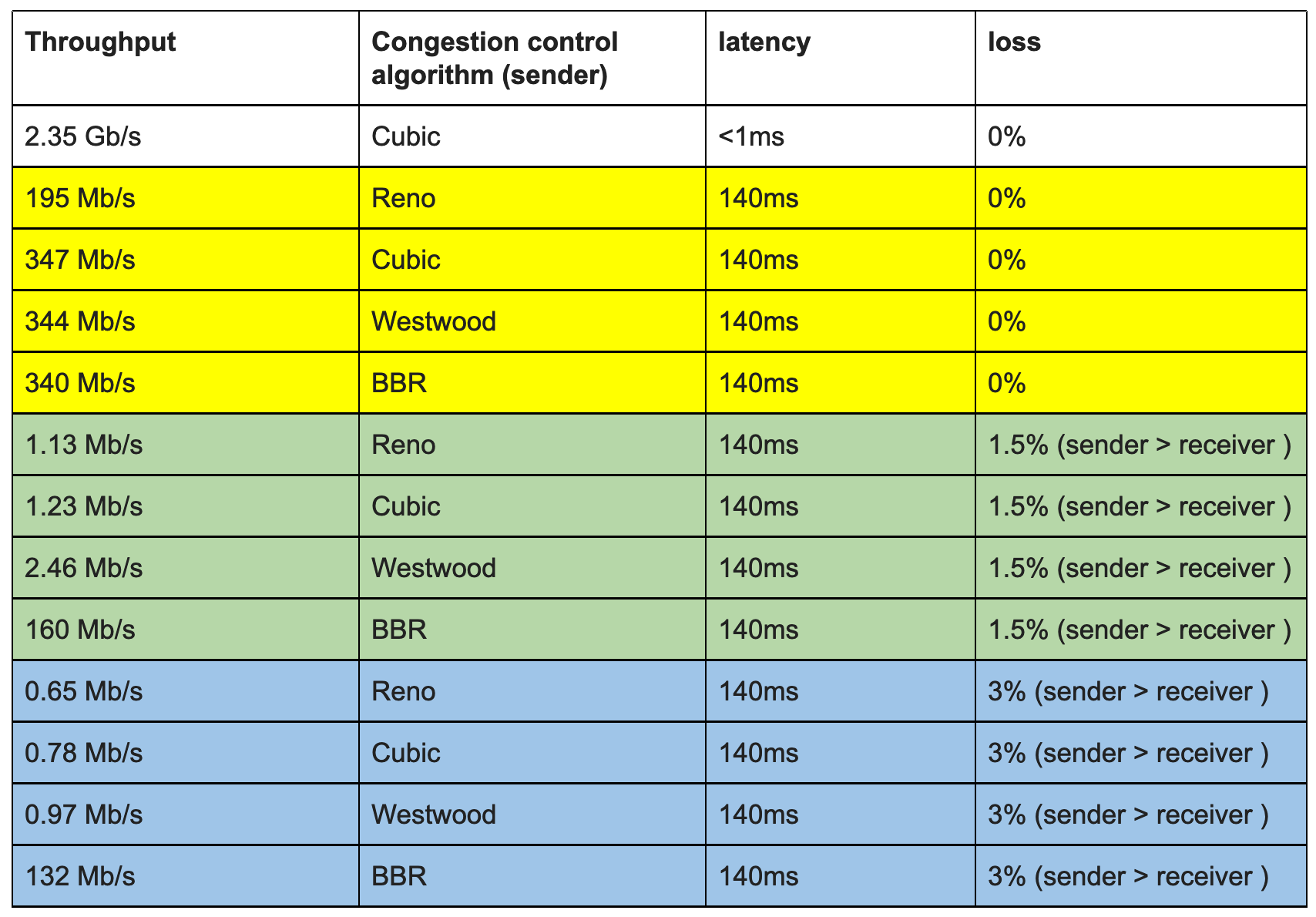
Пример сравнения в домашнем ценарии.
- Cubic – is the most common TCP congestion control algorithm used today. И это действительно так – его используют и Windows 10 и Linux и MAC и генераторы трафика (напр. Ixia IxLoad).
sysctl -w net.ipv4.tcp_congestion_control=cubic
# sysctl -a | grep congest
net.ipv4.tcp_allowed_congestion_control = reno cubic
net.ipv4.tcp_available_congestion_control = reno cubic
net.ipv4.tcp_congestion_control = cubic
# MAC OS
sysctl net | grep net.inet.tcp | egrep -i "cubic|reno"
net.inet.tcp.newreno_sockets: 0
net.inet.tcp.cubic_sockets: 92
net.inet.tcp.use_newreno: 0
net.inet.tcp.cubic_tcp_friendliness: 0
net.inet.tcp.cubic_fast_convergence: 0
net.inet.tcp.cubic_use_minrtt: 0
$ uname -a
Linux ubnt-small1 5.4.0-1061-azure #64~18.04.1-Ubuntu SMP Thu Oct 7 21:00:58 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
~$ cat /proc/sys/net/ipv4/tcp_congestion_control
cubic
# Windows
Win> Get-NetTCPSetting
SettingName : Internet
MinRto(ms) : 300
InitialCongestionWindow(MSS) : 10
CongestionProvider : CUBIC
CwndRestart : False
DelayedAckTimeout(ms) : 40
DelayedAckFrequency : 2
MemoryPressureProtection : Disabled
AutoTuningLevelLocal : Normal
AutoTuningLevelGroupPolicy : NotConfigured
AutoTuningLevelEffective : Local
EcnCapability : Disabled
Timestamps : Disabled
InitialRto(ms) : 1000
ScalingHeuristics : Disabled
DynamicPortRangeStartPort : 49152
DynamicPortRangeNumberOfPorts : 16384
AutomaticUseCustom : Disabled
NonSackRttResiliency : Disabled
ForceWS : Enabled
MaxSynRetransmissions : 4
AutoReusePortRangeStartPort : 0
AutoReusePortRangeNumberOfPorts : 0
- Reno – им предлагали тестировать по RFC draft netsecopen (в последующем отказались от “жесткого” указания RFC). По факту “The default algorithm for most kernels is reno ((не актуально, см. выше)). The recommended algorithm is cubic.”.
The TCP stack SHOULD use a TCP Reno [RFC5681] variant, which include congestion avoidance, back off and windowing, fast retransmission, and fast recovery on every TCP connection between client and server endpoints.
- Westwood
- BBR/BBR2 – новый и очень эффективный алгоритм по многим тестам. Создан Google. Использует не потери как индикатор проблем (классический подход), а задержку. Так же есть инфа, что он и разгоняется быстрее. Недостаток – он жадный и потребляет всю полосу, что по идее должен решить BBR2.
sysctl -w net.ipv4.tcp_congestion_control=bbr
BBR allows the 500,000 WordPress sites on our digital experience platform to load at lightning speed. According to Google’s tests, BBR's throughput can reach as much as 2,700x higher than today's best loss-based congestion control; queueing delays can be 25x lower. Network innovations like BBR are just one of the many reasons we partner with GCP.
Bottleneck Bandwidth and Round-trip propagation time (BBR) is a TCP congestion control algorithm developed at Google in 2016. Up until recently, the Internet has primarily used loss-based congestion control, relying only on indications of lost packets as the signal to slow down the sending rate. This worked decently well, but the networks have changed. We have much more bandwidth than ever before; The Internet is generally more reliable now, and we see new things such as bufferbloat that impact latency. BBR tackles this with a ground-up rewrite of congestion control, and it uses latency, instead of lost packets as a primary factor to determine the sending rate.
BBR ramps up to the optimal sending rate aggressively, causing your video stream to load even faster.
Well, BBR has received some criticism due to its tendency to consume all available bandwidth and pushing out other TCP streams that use say Cubic or different congestion algorithms. This is something to be mindful of when testing BBR in your environment. BBRv2 is supposed to resolve some of these challenges.
PORT RANGES (TCP & UDP)
Диапазоны описаны тут.
o the System Ports, also known as the Well Known Ports, from 0-1023
(assigned by IANA)
o the User Ports, also known as the Registered Ports, from 1024-
49151 (assigned by IANA)
o the Dynamic Ports, also known as the Private or Ephemeral Ports,
from 49152-65535 (never assigned)
Насколько понимаю, логиа по User Ports такая – они не должны использоваться для серверов до тех пор, пока IANA вам не разрешит.
Ports in the User Ports range (1024-49151) are available for assignment through IANA, and MAY be used as service identifiers upon successful assignment.
Ephemeral порты по своей логике должны использовать приложения как src. Порт может выдаваться как системой (в приложении не указан конкретный), так и приложением (указан).
ack
nagle и tcp delayed ack – конкурирующие подходы (придуманы примерно в одно время), вместе не работают и срались между собой. Одновременно работают плохо.
https://en.wikipedia.org/wiki/Nagle%27s_algorithm
https://en.wikipedia.org/wiki/TCP_delayed_acknowledgment
https://stackoverflow.com/questions/3761276/when-should-i-use-tcp-nodelay-and-when-tcp-cork
Nagle's algorithm is for reducing more number of small network packets in wire. The algorithm is: if data is smaller than a limit (usually MSS), wait until receiving ACK for previously sent packets and in the mean time accumulate data from user. Then send the accumulated data.
This will help in applications like telnet. However, waiting for the ACK may increase latency when sending streaming data.
Additionally, if the receiver implements the 'delayed ACK policy', it will cause a temporary deadlock situation. In such cases, disabling Nagle's algorithm is a better option.
nagle – Nagle algorithm (отключение/включение через опцию TCP_NODELAY – отключение =1, включение =0) увеличивает производительность сети за счет склейки мелких (менее MSS) пакетов в один. Недостаток в росте delay для каждого из склеянных пакетов. Обычно включен по умолчанию в стеке ОС, но сейчас есть тенденции по отключению nagle как на отдельных socket, так и на уровне всей системы. На моей практике в коротких экспериментах вкл/выкл nagle не влияло на производительность.
Nagle algorithm is usually enabled by default in the TCP stack and reduces the bandwidth overhead when sending small packets, by combining them into larger packets.
On the other hand, it increases the latency of the small packets, as the algorithm attempts to combine them in larger packets.
https://www.opennet.ru/opennews/art.shtml?num=61176
Снейдерс придерживается мнения, что в современных реалиях алгоритм Нейгла, разработанный во времена, когда несколько пользователей конкурировали за полосу пропускания 1200 бод, устарел, и в высокоскоростных сетях от него больше вреда чем пользы. Недавно подобную позицию также высказал Марк Брукер (Marc Brooker) из компании Amazon Web Services (AWS). С доводами в пользу отключения алгоритма Нейгла по умолчанию можно ознакомиться в опубликованной несколько дней назад заметке. Для отключения алгоритма Нейгла предусмотрена опция TCP_NODELAY, которая может быть выставлена для отдельных сетевых сокетов. Режим TCP_NODELAY давно выставляется во многих приложениях OpenBSD, среди которых openssh, httpd, iscsid, relayd, bgpd и unwind, и, по мнению Снейдерса, настало время для предоставления возможности его включения для всех TCP-сокетов на уровне всей системы. Снейдерс предлагает обсудить вопрос включения TCP_NODELAY по умолчанию и перевода алгоритма Нейгла в разряд отдельной включаемой опции.
delayed ack – откладываем подтверждение сегмента в пользу подтверждения сразу нескольких сегментов за раз, тем самым уменьшая количество подтверждений. По стандарту задержка перед отправкой ack (в таком случае это называется forced ack) до 500ms на каждый сегмент и на каждый второй полный сегмент (RFC 1122, RFC 2581; под полным сегментом имеется ввиду сегмент с размером равным MSS) . В windows дефолт меняется – был 200ms (IETF BMWG), сейчас 40ms (вывод из powershell). В Linux судя по всему 200ms. В RFC netsecopen сделали более гибкий подход – должно быть подтверждение (forced ack) когда объем неподтвержденных данных достигает 10 MSS, но он судя по всему не соответствует RFC (подробнее ниже). IBM для своей APP WebSphere рекомендуют включать NODELAYACKS (т.е. отключать delayed ack).
from RFC 1122
A TCP SHOULD implement a delayed ACK, but an ACK should not be excessively delayed; in particular, the delay MUST be less than 0.5 seconds, and in a stream of full-sized segments there SHOULD be an ACK for at least every second segment.
from RFC 2581
The delayed ACK algorithm specified in [Bra89] SHOULD be used by a
TCP receiver. When used, a TCP receiver MUST NOT excessively delay
acknowledgments. Specifically, an ACK SHOULD be generated for at
least every second full-sized segment, and MUST be generated within
500 ms of the arrival of the first unacknowledged packet.
FULL-SIZED SEGMENT: A segment that contains the maximum number of
data bytes permitted (i.e., a segment containing SMSS bytes of
data). ((по сути это MSS))
from windows powershell
DelayedAckTimeout(ms) : 40
DelayedAckFrequency : 2
from IETF BMWG
A typical value would be 200 ms (Windows OS default).
from netsecopen RFC draft
Delayed ACKs are permitted and the maximum client delayed ACK SHOULD NOT exceed 10 times the MSS before a forced ACK.
Delayed ACKs are permitted and the maximum server delayed ACK MUST NOT exceed 10 times the MSS before a forced ACK.
Martin,
Here is a response to your second comment. The authors have discussed the Delayed ACK statement once more. In general, it would be possible to specify the limit in time in addition. However, it is unclear to us if such a limit would cover any corner cases and whether it would generally reduce confusion instead of increasing it (problems with inclusive vs.
exclusive "or" in normative statements).
If you would still like us to add a delayed ack limit in time, could you please suggest specific text that - given your experience with IETF documents - would be consistent and represent the normative statements correctly?
A pologies, it is not my plan to delegate our work to you :), but we
are really unsure how to formulate this precisely.
Thank you, Carsten
(4.3.1.1), (4.3.2.1) Is there a reason that delayed ack limits are defined only in terms of number of bytes, instead of time? What if an HTTP request (for example) ends, and the delayed ack is very long? Note also that the specification for delayed acks limits it to every two packets, although in the real world many endpoints use much higher thresholds. It's OK to keep it at 10*MSS if you prefer.
Martin Duke <martin.h.duke@gmail.com>
piggyback ack – это когда клиент вместо отправки простого ACK, завершающего 3whs (three way handshake) отправляет этот ACK с данными для application layer (напр. http get). TRex по умолчанию отправляет piggybacking ack, чтобы изменить – нужно использовать connect функцию в конфигурации (коде) (дублируется в TRex).
In two-way communication, whenever a frame is received, the receiver waits and does not send the control frame (acknowledgement or ACK) back to the sender immediately. The receiver waits until its network layer passes in the next data packet. The delayed acknowledgement is then attached to this outgoing data frame.
By default, when the L7 emulation program is started the sending buffer waits inside the socket. This is seen as SYN/SYN-ACK/GET-ACK in the trace (piggyback ack in the GET requests). To force the client side to send ACK and only then send the data use the connect() command.
selective ack (SACK, RFC 2018) – нужен для кейса, когда в рамках одного окна потеряно несколько сегментов данных. При поддержке Selective ACK получающая сторона отправляет отправителю те TCP-сегменты, которые он успешно получил. Таким образом отправителю нужно отправить только недостающие (потерянные) сегменты, а не все окно сегментов начиная с первого потерянного сегмента. В итоге это увеличивает производительность.
The TCP selective acknowledgment mechanism helps improve performance. The receiving TCP host returns selective acknowledgment packets to the sender, informing the sender of data that has been received. In other words, the receiver can acknowledge packets received out of order. The sender can then resend only missing data segments (instead of everything since the first missing packet). Prior to selective acknowledgment, if TCPlost packets 4 and 7 out of an 8-packet window, TCP would receive acknowledgment of only packets 1, 2, and 3. Packets 4 through 8 would need to be re-sent. With selective acknowledgment, TCP receives acknowledgment of packets 1, 2, 3, 5, 6, and 8. Only packets 4 and 7 must be re-sent.
TCP may experience poor performance when multiple packets are lost from one window of data. With the limited information available from cumulative acknowledgments, a TCP sender can only learn about a single lost packet per round trip time. An aggressive sender could choose to retransmit packets early, but such retransmitted segments may have already been successfully received. A Selective Acknowledgment (SACK) mechanism, combined with a selective repeat retransmission policy, can help to overcome these limitations. The receiving TCP sends back SACK packets to the sender informing the sender of data that has been received. The sender can then retransmit only the missing data segments.
With selective acknowledgements enabled, less data is retransmitted across the WAN when packets are lost.
tcp reset – способ закрытия соединения, сигнализирующий о проблеме (на сервере/клиенте/посередине). Используется в IPS – обеим сторонам при обнаружении атаки отправляется TCP RST. Так же используется в Китайском Great Firewall для блокировки ресурсов. Некорректно использовать TCP RESET (RST) для закрытия сессий при “стандартном” тестировании – напр. измерении производительности при условиях работы обычной сети (netsecopen).
The Chinese firewall may arbitrarily terminate TCP transmissions, using packet forging. The blocking is performed using a TCP reset attack. This attack does not block TCP requests nor TCP replies, but send a malicious TCP RST packet to the sender, simulating an end-of-connection.
Side channel analysis seems to indicate that TCP Reset are coming from an infrastructure collocated or shared with QoS filtering routers.[48] This infrastructure seems to update the scoring system: if a previous TCP connection is blocked by the filter, future connection attempts from both sides may also be blocked for short period of times (up to few hours).
An efficient circumvention method is to ignore the reset packet sent by the firewall.[49] A patch for FreeBSD has been developed for this purpose.[50]
The TCP session MUST be closed via either a TCP three way close (FIN, FIN/ACK, ACK), or a TCP four way close (FIN, ACK, FIN, ACK), and not by a RST.
duplicated ack – признак reordering или потери пакетов в сети. До трех duplicated ack для одного сегмента чаще всего допустимы алгоритмами TCP. Более – нужно пересылать сегмент (запускать retransmission).
При перемешивании duplicated ack генерируется когда получатель получает сегмент n+1 до того как получил сегмент n (индикатор потери или перемешивания), причем не один раз, а на каждый принятый сегмент до того момента, как получатель не получит сегмент n, поэтому можно фиксировать много dupack в дампе трафика.
tcps_rcvdupack
rcvd duplicate acks
https://tools.ietf.org/html/rfc2001#section-3
Since TCP does not know whether a duplicate ACK is caused by a lost segment or just a reordering of segments, it waits for a small number of duplicate ACKs to be received. It is assumed that if there is just a reordering of the segments, there will be only one or two duplicate ACKs before the reordered segment is processed, which will then generate a new ACK. If three or more duplicate ACKs are received in a row, it is a strong indication that a segment has been lost. TCP then performs a retransmission of what appears to be the missing segment, without waiting for a retransmission timer to expire.
DupACKs are part of a failure recovery mechanism called: TCP Fast retransmit, ensuring the reliability of TCP protocol. A duplicate acknowledgment is sent when a receiver receives out-of-order packets (let say sequence 2-4-3).
Upon receiving packet #4 the receiver starts sending duplicate acks so the sender would start the fast-retransmit process. Another situation is packet loss.
Keep in mind - packet loss is quite normal in TCP networks. TCP actually regulates itself with packet loss as a feedback mechanism.
The behavior of Tahoe and Reno differ primarily in how they react to duplicate ACKs:
Tahoe: if three duplicate ACKs are received (i.e. four ACKs acknowledging the same packet, which are not piggybacked on data and do not change the receiver's advertised window), Tahoe performs a fast retransmit, sets the slow start threshold to half of the current congestion window, reduces the congestion window to 1 MSS, and resets to slow start state.[13]
Reno: if three duplicate ACKs are received, Reno will perform a fast retransmit and skip the slow start phase by instead halving the congestion window (instead of setting it to 1 MSS like Tahoe), setting the slow start threshold equal to the new congestion window, and enter a phase called fast recovery.[14]
Low latency TCP
Алгоритмы TCP на уровне хостов по умолчанию работают с целью максимизации полосы пропускания, а не минимизации задержки, но это зависимые вещи. К примеру, сложно обеспечить высокую полосу пропускания не используя большого размера очереди, при этом большого размера очереди негативно влияют на задержку.
-
- net.ipv4.tcp_limit_output_bytes – setting limits the number of bytes on a device to reduce the latency effects caused by a larger queue size. The default value is 262,144 bytes. For workloads or environments where latency is higher priority than throughput, lowering this value can improve latency.
# sysctl -a | grep tcp_limit_output_bytes
net.ipv4.tcp_limit_output_bytes = 262144
-
- net.ipv4.tcp_low_latency – the normal TCP stack behavior is set to favor decisions that maximize network throughput. This parameter, when set, tells TCP to instead make decisions that would prefer lower latency.
# sysctl -a | grep tcp_low_latency
net.ipv4.tcp_low_latency = 0
PAWS
PAWS (Protect Against Wrapped Sequences) – ошибки PAWS являются признаком reordering, по аналогии с tcps_rcvoopack, tcps_rcvoobyte, tcps_rcvdupack, tcps_rcvduppack.
DEBUG!!!!!!!! error_flag True, errors {'client': {u'tcps_pawsdrop': u'segments dropped due to PAWS'}, 'server': {}}
The basic idea is that a segment can be discarded as an old duplicate if it is received with a timestamp SEG.TSval less than some timestamp recently received on this connection.
SYSCTL, RETRANSMISSION, REORDERING
Примеры sysctl настроек Linux (Debian 10) в контексте retransmission, reordering:
# sysctl -a | grep -i tcp | grep -i retr
net.ipv4.tcp_early_retrans = 3
net.ipv4.tcp_orphan_retries = 0
net.ipv4.tcp_retrans_collapse = 1
net.ipv4.tcp_retries1 = 3
net.ipv4.tcp_retries2 = 15
net.ipv4.tcp_syn_retries = 6
net.ipv4.tcp_synack_retries = 5
net.netfilter.nf_conntrack_tcp_max_retrans = 3
net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
# sysctl -a | grep -i tcp | grep -i ord
net.ipv4.tcp_max_reordering = 300
net.ipv4.tcp_reordering = 3
В draft netsecopen заложен допуск до 3 ретрансмиссий до timeout сессии. Это не особо соответствует RFC 1122 – там минимум 3 ретрансмиссии только для Retries1 (R1 измеряется в количестве ретрансмиссий), но только при Retries2 (R2 измеряется во времени) происходит разрыв коннекции (минимум 100 секунд).
Netsecopen
Up to three retries SHOULD be allowed before a timeout event is declared.
RFC 1122
R1 and R2 might be measured in time units or as a count of retransmissions.
The value of R1 SHOULD correspond to at least 3 retransmissions, at the current RTO. The value of R2 SHOULD correspond to at least 100 seconds.
SCTP
QUIC, HTTP/3
- https://www.opennet.ru/opennews/art.shtml?num=55226
- https://datatracker.ietf.org/doc/rfc9000/
- https://www.fastly.com/blog/quic-is-now-rfc-9000
- https://www.fastly.com/quic-http-3
- https://www.fastly.com/blog/why-fastly-loves-quic-http3
- Многие считают, включая ко-авторов некоторых TCP RFC, что QUIC может заменить TCP
- Использование QUIC возможно по текущему draft RFC netsecopen
- QUIC поддерживается NGINX
- В качестве простого клиента и сервера можно использовать ngtcp2
- Проверка браузера
- Название не сокращается
Although its name was initially proposed as the acronym for "Quick UDP Internet Connections",[4][9] IETF's use of the word QUIC is not an acronym; it is simply the name of the protocol.[2]
-
Но в квике очень дешёвый хендшейк(по сравнению с 3 way tcp + tls).
- HTTP3 = HTTP over QUIC
HTTP/3 is definitionally HTTP over QUIC, so this normative requirement is unnecessary just as it would be unnecessary to say that HTTP/2 MUST run over TCP.
- Понижение версии – классический способ инспекции quic, но насколько надолго он актуален и логичен вопрос.
Хоть отвечать вопросом на вопрос не очень вежливо , но я попробую
Очень хороший вопрос. Периодический слышу такой запрос и возникает встречный вопрос: для чего расшифровывать QUIC если можно его заблокировать, браузер перейдет на HTTPS, который будет благополучно расшифрован и проверен?
1. Помните ли вы времена, когда такой же аргумент был про tls 1.3 ( что можно сделать понижение версии). Кстати полагаю до сих пор процентов в 70 работает?
2. И из смежной области про инспекцию http/2 - зачем анализировать, если можно сделать понижение версии? Опять же большинство сайтов такой трюк поддерживают
Отследить CnC например, состав данных, куда и что сливает ваш сторадж от делл. Я придерживаюсь идеи, что quic это инструмент одной кибер группировки (АНБ) по противодействию развездки и контрразведки других кибер группировок (Китай, Россия). В таком случае переход на quic может быть принудительным, допустим на уровне ядра линикус и модулей, туда же Гугл, Эппл и Майкрософт. Выкатят 10000 уязвимостей для tls ниже 1.3 и все.
> Такой подход конечно может иметь вероятность, но из того что я слышал - основной смысл использования "большими" ребятами квика сводился к оптимизации и возможности внедрять свои фишки без необходимости лезть в ядро. Одна из таких фишек это борьба за полосу при плохих или загруженных каналах ( когда другие будут ее отдавать в квике можно сделать агрессивный захват полосы путем избыточного кодирование и прочими хитростями)
QUIC RFC 9000, 9001, 9002, 8999
I 100% agree that TCP remains for a long time, but with recent QUIC RFC, world will move slowly but surely to UDP as part of HTTP/3. We won't see this happening massively this year, but so won't IPv6 adoption.
- Высокая безопасность, аналогичная TLS (по сути, QUIC предоставляет возможность использования TLS поверх UDP);
- Контроль за целостностью потока, предотвращающий потерю пакетов;
- Возможность мгновенно установить соединение (0-RTT, примерно в 75% случаев данные можно передавать сразу после отправки пакета установки соединения) и обеспечить минимальные задержки между отправкой запроса и получением ответа (RTT, Round Trip Time);
- Использование при повторной передаче пакета другого номера последовательности, что позволяет избежать двусмысленности при определении полученных пакетов и избавиться от таймаутов;
- Потеря пакета влияет на доставку только связанного с ним потока и не останавливает доставку данных в параллельно передаваемых через текущее соединение потоках;
- Средства коррекции ошибок, минимизирующие задержки из-за повторной передачи потерянных пакетов. Использование специальных кодов коррекции ошибок на уровне пакета для сокращения ситуаций, требующих повторной передачи данных потерянного пакета.
- Границы криптографических блоков выравнены с границами пакетов QUIC, что уменьшает влияние потерь пакетов на декодирование содержимого следующих пакетов;
- Отсутствие проблем с блокировкой очереди TCP;
- Поддержка идентификатора соединения, позволяющего сократить время на установку повторного соединения для мобильных клиентов;
- Возможность подключения расширенных механизмов контроля перегрузки соединения;
- Использование техники прогнозирования пропускной способности в каждом направлении для обеспечения оптимальной интенсивности отправки пакетов, предотвращая скатывание в состояние перегрузки, при которой наблюдается потеря пакетов;
- Заметный прирост производительности и пропускной способности по сравнению с TCP. Для видеосервисов, таких как YouTube, применение QUIC показало сокращение операций повторной буферизации при просмотре видео на 30%.
Broadly speaking, QUIC is a replacement for the Transmission Control Protocol (TCP), one of the main protocols for internet communication. QUIC was originally developed internally by Google as Google QUIC, or gQUIC, and was presented to the IETF in 2015. Since then, it has been redesigned and improved by the broader IETF community, forming a new protocol we now call QUIC. HTTP/3 is the next iteration of HTTP, the standard protocol for web-based applications and servers. Together, QUIC and HTTP/3 represent the latest and greatest in internet-focused protocols, incorporating decades of best practices and lessons that we, Google, and the IETF community learned through running protocols on the internet.
QUIC and HTTP/3 generally outperform TCP and HTTP/2, which in turn outperform TCP and HTTP/1.1.
Google maps/youtube/drive при работе с MacOS Mojave + Chrome 85.0.4183.83 отдает контент по UDP, при этом при работе на той же ОС в Safari контент льется по TCP с того же самого IP адреса (смотрим один URL), что и в случае с UDP. Во всех других экспериментах (изменяем ресурс, изменяем ОС, изменяем браузер) всегда видел только TCP - Yandex/avito; youtube на Windows + Chrome (версия неизвестна) везде используют TCP.
2) fastly помогает в деплое/саппорте WEB сайтов на базе HTTP/3 (HTTP over QUIC) на своей edge cloud platform (за деньги или в рамках своего пиара/реального ускорения)
QUIC has been available on our edge cloud platform for customers to use, and many of our customers are already experimenting and deploying live traffic on it.
HTTP/3 and QUIC are now available on our edge cloud platform. Connect with our team to learn more.
Fastly can help you enable HTTP/3 and QUIC within our edge cloud platform. Contact an expert to learn more about HTTP/3 and QUIC and if you’re already a Fastly customer, reach out to your support team to have them enable HTTP/3 and QUIC for you.
Big tcp
Функционал Big TCP в новых версиях ядра Linux – доработка от google для поддержки обработки «одним махом» более 64КБ данных одного сокета в виде skb (ограничения LRO/TSO) для IPv6 на базе «костыля» добавления в пакет extension header поля IPv6 jumbogram (RFC 2675). Из интересного про сетевые карты в Google в статье о ethtool.
https://lwn.net/Articles/883713/







STATISTICS
- UDP stats
serv:~# netstat -us
IcmpMsg:
InType0: 10144
InType3: 2514
InType8: 540567
OutType0: 540567
OutType3: 2472
OutType8: 10224
Udp:
290284 packets received
0 packets to unknown port received
0 packet receive errors
292837 packets sent
0 receive buffer errors
0 send buffer errors
IgnoredMulti: 1059
UdpLite:
IpExt:
InBcastPkts: 257782
InOctets: 10073927212
OutOctets: 198082048012
InBcastOctets: 26058556
InNoECTPkts: 111681739
- TCP stats
serv:~# netstat -ts
IcmpMsg:
InType0: 12559
InType3: 3532
InType8: 645858
OutType0: 645858
OutType3: 3467
OutType8: 12651
Tcp:
1404394 active connection openings
5383158 passive connection openings
753532 failed connection attempts
799 connection resets received
14 connections established
136356132 segments received
219502759 segments sent out
798325 segments retransmitted
58 bad segments received
834551 resets sent
UdpLite:
TcpExt:
98 resets received for embryonic SYN_RECV sockets
63 ICMP packets dropped because they were out-of-window
5134340 TCP sockets finished time wait in fast timer
3 packetes rejected in established connections because of timestamp
1034240 delayed acks sent
558 delayed acks further delayed because of locked socket
Quick ack mode was activated 8367 times
8003866 packet headers predicted
37913340 acknowledgments not containing data payload received
68166212 predicted acknowledgments
TCPSackRecovery: 435759
Detected reordering 38400 times using SACK
Detected reordering 1 times using time stamp
33 congestion windows fully recovered without slow start
1 congestion windows partially recovered using Hoe heuristic
TCPDSACKUndo: 6627
13351 congestion windows recovered without slow start after partial ack
TCPLostRetransmit: 23531
TCPSackFailures: 2555
19 timeouts in loss state
643374 fast retransmits
57490 retransmits in slow start
TCPTimeouts: 18208
TCPLossProbes: 115591
TCPLossProbeRecovery: 1269
TCPSackRecoveryFail: 4908
TCPDSACKOldSent: 9368
TCPDSACKOfoSent: 1
TCPDSACKRecv: 134549
TCPDSACKOfoRecv: 164
3 connections reset due to unexpected data
94 connections aborted due to timeout
TCPDSACKIgnoredOld: 5495
TCPDSACKIgnoredNoUndo: 56257
TCPSpuriousRTOs: 10697
TCPSackShifted: 6806110
TCPSackMerged: 3789102
TCPSackShiftFallback: 930943
TCPRcvCoalesce: 284592
TCPOFOQueue: 111621
TCPOFOMerge: 1
TCPChallengeACK: 59
TCPSYNChallenge: 58
TCPSpuriousRtxHostQueues: 1105
TCPAutoCorking: 645898
TCPSynRetrans: 11170
TCPOrigDataSent: 192854882
TCPHystartTrainDetect: 6638
TCPHystartTrainCwnd: 115240
TCPHystartDelayDetect: 2869
TCPHystartDelayCwnd: 54476
TCPACKSkippedSynRecv: 33
TCPACKSkippedSeq: 383
TCPACKSkippedChallenge: 1
TCPWinProbe: 46
TCPKeepAlive: 498
TCPDelivered: 193197747
TCPAckCompressed: 93586
IpExt:
InBcastPkts: 339147
InOctets: 12034196618
OutOctets: 250471112915
InBcastOctets: 42799155
InNoECTPkts: 138175185
Из канала network quiz:
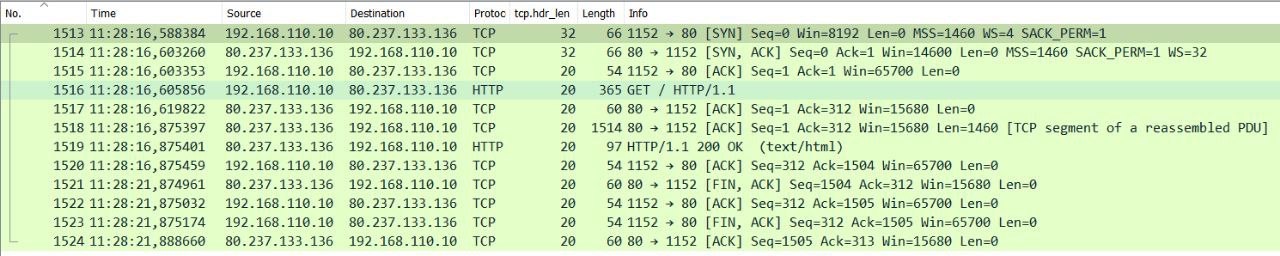
На изображении выше вы видите дамп ТСР сессии. В отдельную колонку выведена длина ТСР заголовка (tcp.hdr_len). Почему длина ТСР заголовка в первых двух пакетах больше, чем в остальных?
1) Увеличение длины заголовка нужно для передачи Initial Sequence Number сторонами при 3-way- handshake
2) Увеличение длины заголовка нужно для передачи TCP Options сторонами при 3-way-handshake
3) Увеличение длины заголовка нужно для передачи ключей шифрования сторонами при 3-way-handshake
4) Заголовок ТСР сегмента с флагом SYN всегда составляет 32 байта (согласно RFC)
2
Зачем при установлении ТСР-сессии используется случайное значение Initial Sequence Number (ISN)?
1) Для предотвращения атак, основанных на угадывании или подделке Sequence Number
2) Для повышения скорости передачи данных
3) Для синхронизации временных меток между клиентом и сервером
4) Для предотвращения повторного использования одного и того же номера при новых соединениях
1
Случайное значение ISN делает последовательность номеров непредсказуемой, что мешает злоумышленникам угадывать номера и вмешиваться в ТСР-соединение.