
GREP в отдельной статье
fmt
Форматирование данных на входе – к примеру по умолчанию fmt осуществит форматирование, которое приведет к лучшему чтению:
-
- объединение слов в одну строку если слов мало в каждой строке
- или наоборот, вместо одной длиной строки сделает несколько коротких
root@serv:~# cat >sw Hello world and not world root@serv:~# fmt sw Hello world and not world root@spr:~# cat >sw Hello world and not world Hello world and not world Hello world and not world Hello world and not world Hello world and not world Hello world and not world root@spr:~# fmt sw Hello world and not world Hello world and not world Hello world and not world Hello world and not world Hello world and not world Hello world and not world
tr ; CUT
- подмена всех символов на lower
echo <WoRd> | tr '[:upper:]' '[:lower:]'
- подмена всех пробелов на \n (все слова с новой строки)
echo <file> | tr ' ' '\n'
- The cut utility cuts out selected portions of each line (as specified by list) from each file and writes them to the standard output
# Print a range of each line with a specific delimiter: command | cut --delimiter="," --fields=1 # Print a specific character/field range of each line: command | cut --characters|fields=1|1,10|1-10|1-|-10
Подмена всех пробелов (в том числе повторяющихся) на одну запятую с использованием tr и опции -s
-s Squeeze multiple occurrences of the characters listed in the last operand (either string1 or string2) in the input into a single instance of the character. This occurs after all deletion and translation is completed.
$ ls -lh total 32 drwx------+ 7 petrredkin staff 224B Mar 24 18:33 Desktop drwx------+ 8 petrredkin staff 256B Mar 21 22:24 Documents drwx------+ 7 petrredkin staff 224B Apr 4 09:24 Downloads drwx------@ 90 petrredkin staff 2.8K Apr 1 08:34 Library drwx------ 4 petrredkin staff 128B Mar 24 16:20 Movies drwx------+ 3 petrredkin staff 96B Mar 21 20:08 Music drwx------+ 4 petrredkin staff 128B Mar 21 20:10 Pictures drwxr-xr-x+ 4 petrredkin staff 128B Mar 21 20:08 Public drwxr-xr-x@ 6 petrredkin staff 192B Mar 24 16:02 Yandex.Disk.localized $ ls -lh | tr -s " " "," total,32 drwx------+,7,petrredkin,staff,224B,Mar,24,18:33,Desktop drwx------+,8,petrredkin,staff,256B,Mar,21,22:24,Documents drwx------+,7,petrredkin,staff,224B,Apr,4,09:24,Downloads drwx------@,90,petrredkin,staff,2.8K,Apr,1,08:34,Library drwx------,4,petrredkin,staff,128B,Mar,24,16:20,Movies drwx------+,3,petrredkin,staff,96B,Mar,21,20:08,Music drwx------+,4,petrredkin,staff,128B,Mar,21,20:10,Pictures drwxr-xr-x+,4,petrredkin,staff,128B,Mar,21,20:08,Public
(Linux работа с текстом – tr, sort, cut, Linux спец. символы) в bash передача в консоль TAB делается через ctrl+v и после этого нажатия на TAB. С помощью tr можно подменить любой символ/последовательность на TAB, используя delimiter TAB можно отсортировать значения sort (-t), используя cut выделить столбцы по delimiter TAB (-d) (аналогично можно и AWK).
$ ls -ltr | tr -s ' ' ' ' | sort -t ' ' -k 5n | cut -d ' ' -f 5,9 15 dir_lst.txt 17 sw 32 ping_list.txt 32 ping_list2.txt 64 dir1 64 dir2 64 dir3 96 Music 128 Movies 128 Pictures 128 Public 192 Yandex.Disk.localized 224 Downloads 224 Desktop 256 Documents 2880 Library
Which of the following commands will reduce all consecutive spaces down to a single space?
A. tr ‘\s’ ‘ ‘ < a.txt > b.txt
B. tr -c ‘ ‘ < a.txt > b.txt
C. tr -d ‘ ‘ < a.txt > b.txt
D. tr -r ‘ ‘ ‘\n’ < a.txt > b.txt
E. tr -s ‘ ‘ < a.txt > b.txt
E % cat >sw r234324 tdfgdfg djtijert 6663 tggujht tret twwww tytry FFC^C % tr -s ' ' < sw > b.txt % cat b.txt r234324 tdfgdfg djtijert 6663 tggujht tret twwww tytry
Which of the following commands will change all CR-LF pairs in an imported text file, userlist.txt, to Linux standard LF characters and store it as newlist.txt?
A. tr ‘\r\n’ ‘’ < userlist.txt > newlist.txt
B. tr –c ‘\n\r’ ‘’ < newlist.txt > userlist.txt
C. tr –d ‘\r’ < userlist.txt > newlist.txt
D. tr ‘\r’ ‘\n’ userlist.txt newlist.txt
E. tr –s ‘^M’ ‘^J’ userlist.txt newlist.txt
Answer: C To change CR-LF (“rn”, DOS newline) to LF (“n”, Linux newline) just delete the CR “r” part from the file. This is done by using tr with the -d (delete) option. http://www.cyberciti.biz/faq/howto-unix-linux-convert-dos-newlines-cr-lf-unix-text-format/
SED
- «sed лучший друг импортозамещения» (с)
Удаляем первую, первую + пятую строки
sed 1d <file> sed '1d;5d' <file>
Удаление пустых строк (Sed delete empty lines)
sed '/^ *$/d' sw # базовый вариант sed '/^[[:space:]]*$/d' # любой whitespace как пустое место sed -r '/^\s*$/d'
sed '/3007791/q'
sed с whitespace и cat -v + tr может использоваться для удаления ^M в разных выгрузках из Windows.
cat -v sw | tr "^M" " " sed 's/[[:space:]]$//g' sw
Groups с sed – не забываем про экранирование спец. символов. Например, добавляем пробелы после каждого символа:
# echo "12345" | sed 's/\(.\)/\1 /g' 1 2 3 4 5
(grep, sed) grep from pattern to pattern / from pattern to end
решается с помощью sed
I want to "grep" from "line 2A" to the end of file: sed -n '/2A/,$p' sed -n '/sendconfig/,$p' /etc/failover.ini I want to "grep" from "line 2A" to the next line that contains "A": sed -n '/2A/,/A/p' sed -n '/sendconfig/,/activeip/p' /etc/failover.ini
AWK
awk – очень сильный инструмент и полноценный скриптовый язык программирования.
Помимо “стандартного” отображения определенного столбца с возможностью задания delimiter с помощью него можно искать текст (замена grep), сортировать его (замена sort), исключать дубли (замена uniq), делать сводки, аналогичные excel.
В awk скриптах можно создавать массивы, циклы, условия.
Практика
delimeter
-F – указать разделитель ввода.
Разделитель может быть не символ, а целый набор символов и даже фраз:
awk -F'->' '{print $2}' test | awk -F'тест тест' '{print $1}'
OFS – указать разделитель вывода. По умолчанию AWK подменяет delimiter на пробел, даже при использовании -F. Используя OFS можно задать разделитель вывода или сохранить разделитель файла. Очень удобно при работе с CSV.
awk -F'\t' '{OFS=";"} {print $1,$2,$3}'
awk as a grep
Заменяем grep на awk (grep open = /open/):
nmap -T5 -PN -p 80 -oG - $1 | awk '/open/{print $2}'
last column
Удалить первый столбец из файла (вывода):
awk '{$1=""}1'
Удалить последний столбец из файла:
awk '{$NF=""}1'
Удалить три последних столбца из файла:
awk '{$NF="";$(NF-1)="";$(NF-2)="";$(NF-3)=""}1'
randomize string
cat <file> |awk '{print rand()"\t"$0}' |sort |awk -F'\t' '{print $2}'
чтение с конца
tac <file> # удобно для чтение лог-файла
агрегирующая функция
простейшая – складываем все значения в столбце
$ cat >123
1
2
3
4
5
55
$ cat 123 | awk '{ CNT +=$1 } END { print CNT; }'
70
аналог саммари сводного отчета Excel
awk '{a[$1]+=$2} END{for (i in a) print a[i],i}'
$ cat sw
str 5
btr 1
str 7
btt 4
btr 31
str 11
$ cat sw | awk '{a[$1]+=$2} END{for (i in a) print a[i],i}' | awk '{print $2,$1}' | sort -n -k 2 # с сортировкой по возрастанию
btt 4
str 23
btr 32
AWK + PRINTF + INTERACTIVE AWK – аналог нижестоящей функции Column – вывод данных в стобцах с фиксированных для столбцов размером с указанием размера каждого столбца. Кроме того испольуется interactive AWK, который позволяет работать с выводом tail без буфферизации (т.е. вывод попадает сразу на обработку без ожидания объема).
tail -f Test.csv | awk -W interactive -F ';' '{printf "%20s %20s %20s %20s \n", $1,$3,$6,$12}'
COLUMN
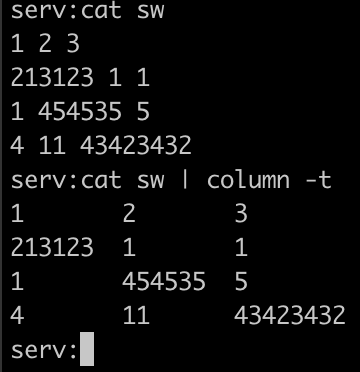
column -t – крайне полезная утилита и опция для представления данных в табличном виде.
cat sw 1 2 3 213123 1 1 1 454535 5 4 11 43423432
uniq
sort -u – сортировка и сохраненик уникальных записей
uniq – сохранение уникальных записей без сортировки
awk '!a[$0]++'
Sort
sort -t \; -k 4n -k 5 -k 8 /home/user/report.csv
(Linux работа с текстом – tr, sort, cut, Linux спец. символы) в bash передача в консоль TAB делается через ctrl+v и после этого нажатия на TAB. С помощью tr можно подменить любой символ/последовательность на TAB, используя delimiter TAB можно отсортировать значения sort (-t), используя cut выделить столбцы по delimiter TAB (-d) (аналогично можно и AWK).
$ ls -ltr | tr -s ' ' ' ' | sort -t ' ' -k 5n | cut -d ' ' -f 5,9 15 dir_lst.txt 17 sw 32 ping_list.txt 32 ping_list2.txt 64 dir1 64 dir2 64 dir3 96 Music 128 Movies 128 Pictures 128 Public 192 Yandex.Disk.localized 224 Downloads 224 Desktop 256 Documents 2880 Library
TEE
Tee – очень удобная, но часто забываемая утилита (по крайней мере мной). Удобство в том, что она позволяет как отображать STDOUT в shell, так и писать в файл одновременно. При использовании совместно с python скриптами для того чтобы вывод появлялся сразу, а не по исполнению скрипта добавляем python -u перед исполняемым файлом.
$ cat ping_list.txt | tee ping_list2.txt 1.1.1.1 8.8.8.8 4.4.8.8 8.8.4.4 $ cat ping_list2.txt 1.1.1.1 8.8.8.8 4.4.8.8 8.8.4.4
echo "<html><body><h2>Welcome to Azure! My name is $(hostname).</h2></body></html>" | tee -a index.html
Questions
When given the following command line. echo “foo bar” | tee bar | cat Which of the following output is created?
A. cat
B. foo bar
C. tee bar
D. bar
E. foo
Answer: B # echo "foo bar" | tee bar | cat foo bar Here's how the command works: 1. `echo "foo bar"` prints "foo bar" to the standard output. 2. `tee bar` copies the input it receives to both the standard output (which is piped to the next command) and to a file named "bar." 3. `cat` reads from the standard input and prints what it receives. So, "foo bar" is the content that is printed to the standard output and displayed in your terminal.
Which of the following commands will send output from the program myapp to both standard output (stdout) and the file file1.log?
A. cat < myapp | cat > file1.log
B. myapp 0>&1 | cat > file1.log
C. myapp | cat > file1.log
D. myapp | tee file1.log
E. tee myapp file1.log
Answer: D
Which of the following commands converts spaces in a file to tab characters and prints the result to standard output?
A. iconv
B. expand
C. unexpand
D. tab
Answer: C The unexpand command converts spaces in a file to tab characters and prints the result to standard output. It can take an option -t to specify the number of spaces per tab, otherwise it uses the default value of 8. The unexpand command is the opposite of the expand command, which converts tabs to spaces. Both commands are useful for formatting text files according to different coding standards or preferences. man: UNEXPAND(1) User Commands UNEXPAND(1) NAME unexpand - convert spaces to tabs
Which of the following command lines creates or, in case it already exists, overwrites a file called data with the output of ls?
A. ls 3> data
B. ls >& data
C. ls > data
D. ls >> data
Answer: C
Which of the following keys can be pressed to exit less?
- q
- x
- !
- l
- e
@ q «q» - сокращение от «quit» (=выход). Поэтому это клавиша для выхода из утилиты less (как и из многих других программ в терминале Linux)