
- Сюда переношу все, что связано со статистикой и нужно было на практике – в тестировании, разработке и в других инженерных задачах.
- Нужно уметь применять статистику (с этим часто проблема) и
- если задача найти максимальное расстояние между значениями ряда/выборки – то среднеквадратичное отклонение не подходит, нужно считать размах
- если задача найти максимальное расстояние от среднего – то среднеквадратичное отклонение тоже не подходит, нужно считать максимальное относительное отклонение
- Про метрологию / погрешность / неопределенность измерений подробнее в отдельной статье про нагрузочное тестирование
(статистика, python, сетевое тестирование)
В целом же можно порекомендовать делать pandas describe на выборку для получения разнообразной статистики:
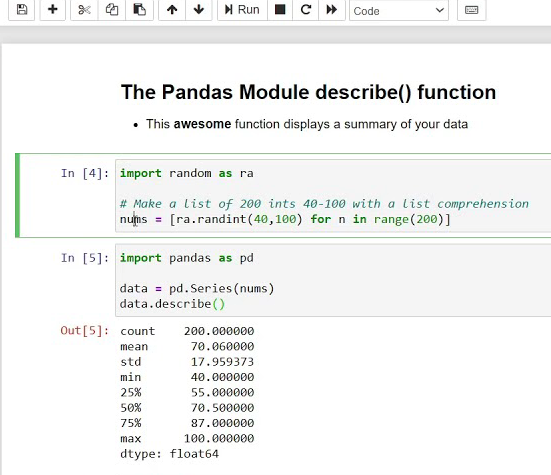
-
-
-
- count 94248.000000 – количество элементов (размер выборки)
- mean 1.691554 – среднее
- std 0.979690 – стандартное отклонение (величина высокая)
- min -0.108278 – меньше этого гарантировано (на основе выборки) не будет
- 25% 0.396944 – 25% выборки выше этого значения
- 50% 2.301407 – медиана (median)
- 75% 2.348383 – 75% выборки ниже этого значения
- max 6.486859 – больше этого гарантировано (на основе выборки) не будет
-
-
Так же может дополнительно быть необходимо:
-
-
-
- 1%
- https://www.rfc-editor.org/rfc/rfc9693.html
- 80% использовал для индикации высокого результата без spike/ramp up вверх и вниз. 80ый перцентиль пример для понимания:
- 20% выборки имею результат выше
- 80% имеют результат ниже
- 95% load testing app best practice
- 99% 99th percentile, for robustness against outliers
- https://www.rfc-editor.org/rfc/rfc9693.html
- https://datatracker.ietf.org/doc/html/rfc8238
- range статистический размах
- 1%
-
-
Арифметической прогрессией (арифметической последовательностью) – последовательность с фиксированным инкрементом. Для меня
Арифметической прогрессией (арифметической последовательностью) - называется последовательность чисел a1,a2,...,an, каждое из которых, начиная с a2, получается из предыдущего прибавлением к нему одного и того же постоянного числа d (разность прогрессии), то есть:An=An−1+D. - Если известен первый член прогрессии и её разность, то n-ый член арифметической прогрессии находится по формуле An=A1+D(n−1). - Сумма первых (т.е. только для последовательности integer с шагом 1) элементов находится по формуле n*(n+1)/2. Для меня наиболее интуитивно проще запоминаема "формула юного Гауса" - складываем последнее число и первое, умножаем на половину элементов. Действительно, числа от 1 до 100, можно разбить на 50 пар, сумма в которых равна 101: 1+100=101,2+99=101,3+98=101,…50+51=101. # example 100, 110, 120, 130, 140, 150, 160, 170, 180 # calc n-member a_9 = 100 + 10 * (9-1) = 180 # example2 1, 2, 3, 4, 5, 6, 7, 8, 9 # calc sum of members a_sum = (9 * 10)/2 = 45
Двоичным (булевым) n-мерным вектором – двоичная последовательность.
Двоичным (булевым) n-мерным вектором называют набор из n чисел (b1, b2, ..., bn), каждое из которых может принимать только значения в двоичной системе счисления – 0 или 1. Двоичный вектор является обратным (инвертированным), если он образован из заменой всех нулей единицами, а единиц – нулями. Например, если вектор равен (0,1,1,1,0,1), то инвертированный (1,0,0,0,1,0).
В позиционных системах счисления значение цифры зависит от ее положения — позиции — в числе. Например, число 15 обозначает пятнадцать, 51— пятьдесят один. Первая позиционная система счисления была придумана еще в Древнем Вавилоне, причем вавилонская нумерация была шестидесятеричная, т.е. в ней использовалось шестьдесят цифр. Мы до сих пор считаем, час – 60 минут, минута – 60 секунд, окружность – 360∘. Позиционные системы счисления позволяют легко производить арифметические расчеты. Представление чисел с помощью арабских цифр — самая распространенная позиционная система счисления, она называется десятичной системой счисления потому, что использует десять цифр: 0,1,2,3,4,5,6,7,8 и 9. Количество цифр, используемое в системе счисления, называется ее основанием. В десятичной системе основание равно десяти, в двоичной системе — двум, ну а в восьмеричной и шестнадцатеричной — соответственно, восьми и шестнадцати
Перевод в десятичную Перевести двоичное число 111111 в десятичную систему счисления. 2^5 + 2^4 + 2^3 + 2^ 2 + 2^1 + 2^0 = 127
Перевести число из шестнадцатеричной системы счисления 1AF2 в десятичную систему счисления.
(1 * 16^ 3) + (10 * 16 ^ 2) + (15 * 16 ^ 1) + (2 * 16^ 0) = 6898
Перевод из десятичной
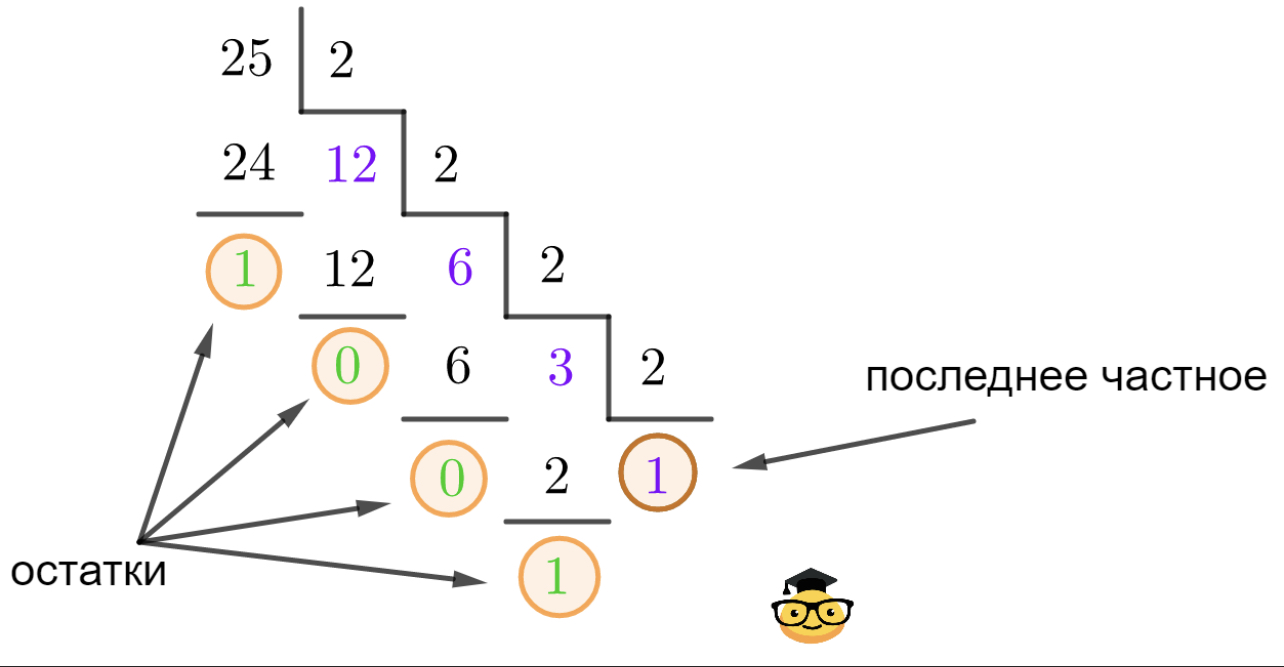
Перевести десятичное число 25 в двоичную систему счисления.
11001
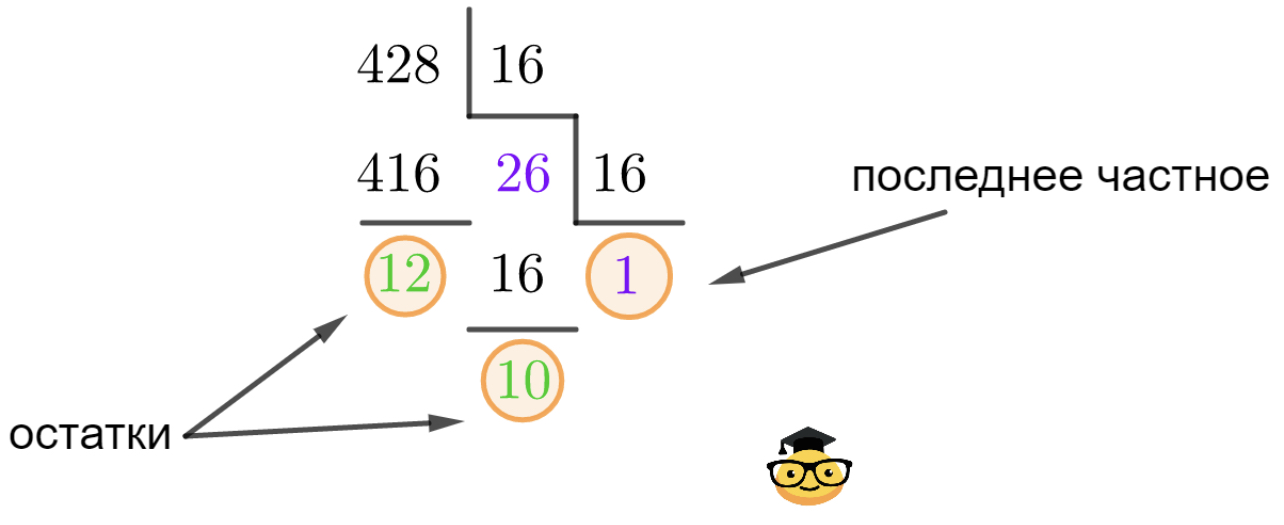
Перевести десятичное число 428 в шестнадцатеричную систему счисления.
1AC
В непозиционных системах счисления значение цифры не зависит от ее положения — позиции — в записанном числе. Примером непозиционной системы счисления является римская система (см. примечание). При использовании непозиционных систем счисления очень сложно выполнять математические расчеты и необходимо большое количество различных знаков для записи чисел, особенно больших.
Для записи чисел в римской системе используются два правила:
- каждый меньший знак, поставленный слева от большего, вычитается из него;
- каждый меньший знак, поставленный справа от большего, прибавляется к нему.
число 444 в римской системе счисления будет записано в виде CDXLIV=(500−100)+(50−10)+(5−1)=400+40+4(три группы второго вида).
Денежные знаки — пример смешанной системы счисления. Сейчас в России используются монеты и купюры следующих номиналов: по 1, 2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000 рублей и по 5,10,50 копеек. Чтобы получить некоторую сумму в рублях, нужно использовать некоторое количество денежных знаков различного достоинства. Таким образом, у этой системы целый ряд оснований, равный достоинствам денежных знаков, также используется основание той системы, с помощью которой производится их счет.
Геометрической прогрессией – последовательность с фиксированным множетелем.
Геометрической прогрессией - это последовательность, первый член которой не равен нулю, а каждый последующий член равен произведению предыдущего члена на некоторое фиксированное ненулевое число (называемое знаменателем геометрической прогрессии q). Любой член геометрической прогрессии может быть вычислен по формуле Bn = B1*q^(n-1) # example 3, 12, 48, 192, 768, 3072 # calc n-member a_6 = 3 * 4^5 = 3072
Коэффициент корреляции (correlation coefficient) – Корреля́ция (от лат. correlatio «соотношение»), или корреляцио́нная зави́симость — статистическая взаимосвязь двух или более случайных величин (либо величин, которые можно с некоторой допустимой степенью точности считать таковыми). При этом изменения значений одной или нескольких из этих величин сопутствуют систематическому изменению значений другой или других величин ((почему это важно – в wiki)). Пример расчета в python.
| Количественная мера тесноты связи |
Качественная характеристика силы связи |
| 0,1-0,3 | Слабая |
| 0,3-0,5 | Умеренная |
| 0,5-0,7 | Заметная |
| 0,7-0,9 | Высокая |
| 0,9-0,99 | Весьма высокая |
Размах (range) – арифметическая разница между максимальным и минимальным значением выборки, максимальное расстояние между значениями ряда/выборки. Причем по моей практике чаще полезно не просто абсолютное значение размаха, а процент размаха от минимального до максимального (размах_в_% = (макс-мин)/мин * 100) – он показывает на сколько минимальная величина отклоняется от максимального в процентах или другими словами мы знаем сколько добавить к минимуму процентов от минимума, чтобы получить максимум (макс = мин + мин * размах_в_%). Размах в процентах одинаково нагляден как при небольшом размахе, так и при весомом, в отличии от “во сколько или на сколько раз”. Очень полезен в нагрузочном тестировании.
(excel, stat) Размах.
РАЗМАХ пример формулы в Excel для ряда данных. =(МАКС(A2:A1007)-МИН(A2:A1007))/МИН(A2:A1007)*100
https://en.wikipedia.org/wiki/Range_(statistics) In statistics, the range of a set of data is the difference between the largest and smallest values. Sample RANGE : The spread (distance or value) from the lowest to the highest value in the sample.
Если требуется перевести число из десятеричной системы в двоичную, необходимо сделать следующее:
1) Последовательно делить это число на два, каждый раз записывая результат в виде целого числа и остатка.
2) Деление продолжать до тех пор, пока в результате не останется единица.
Итоговое число получается путём последовательной записи результата последнего деления и остатков всех делений в обратном порядке. Пример кода см. тут.
Сложением отрицательных чисел в любом случае всегда будет являтся отрицательное число: -1 + -1 = -2
Средние величины

Среднее арифметическое числе A, B:
(A + B)/N
Среднее квадратичное числе A, B:
sqr((A^2 + B^2)/N)
Максимальное относительное отклонение (MRO) — это наибольшее процентное или долевое изменение между фактическим значением и базовым (плановым) значением, которое показывает, насколько сильно показатель отклонился от нормы в худшую или лучшую сторону (безразмерная величина), выражаясь в долях или процентах, а не абсолютных единицах, и часто используется для оценки максимального разброса данных относительно среднего.
Формулы в EXCEL:
- Расчет максимального отклонения от среднего по модулю:
=ABS(A3-СРЗНАЧ(A1:A100000))
- Максимальное относительное отклонение
=G7/СРЗНАЧ(A1:A100000)*100 =ABS(C1-СРЗНАЧ(C2:C31)) =ABS(C2-СРЗНАЧ(C2:C31)) =ABS(C3-СРЗНАЧ(C2:C31)) =ABS(C4-СРЗНАЧ(C2:C31)) =ABS(C5-СРЗНАЧ(C2:C31))
Среднеквадратическое отклонение (СКО) (оно же стандартное отклонение) – наиболее распространённый показатель рассеивания значений случайной величины относительно её математического ожидания ((среднего значения)), обычно фигурирует как среднее ± стандартное отклонение (в тех же единицах, что и среднее в отличии от вариации/дисперсии).
-
-
Mean ± Standard Deviation $50,000 ± $5,000 SD
-
Ноль это идеальное, отличное от нуля – присутствует отклонение. Стандартное отклонение измеряется в тех же единицах, что и сама случайная величина, а дисперсия измеряется в квадратах этой единицы измерения. Большее значение среднеквадратического отклонения показывает больший разброс значений в представленном множестве со средней величиной множества; меньшее значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Встречаются также синонимы словосочетания среднеквадрати́ческое отклоне́ние, как то́: среднее квадрати́ческое отклоне́ние; среднеквадрати́чное отклоне́ние; квадрати́чное отклоне́ние; станда́ртное отклоне́ние; станда́ртный разбро́с. GENERAL: Mean ± Standard Deviation (SD) is a common way to present data, showing the average (mean) and the typical spread or variability (SD) of data points around that average, indicating how dispersed the values are; a small SD means data is clustered near the mean, while a large SD means data is spread out. It's used to describe datasets, where the SD measures data's volatility or risk, and is calculated by finding the average, then the average of squared differences from the mean, and finally taking the square root. A mean income of $50,000 ± $5,000 SD means most incomes cluster around $50k, with typical variation of about $5k. Standard deviation is always measured in the same units as the original data, which makes it directly interpretable (e.g., if data is in meters, SD is in meters). This is a key advantage over variance, which is in squared units (e.g., square meters). When you change data units (e.g., meters to feet), the standard deviation scales proportionally with the data, maintaining its meaning.
(excel, stat)
=СТАНДОТКЛОН.В(E3:E10)
Пример расчета стандартного отклонения:
Low Standard Deviation Example (Consistent)
Data: {85, 88, 90, 92, 95}
Алгоритм расчёта:
Вычислить среднее значение: (85 + 90 + 92 + 88 + 95) / 5 = 90.
Рассчитать отклонение каждого значения от среднего: 85 - 90 = -5, 90 - 90 = 0, 92 - 90 = 2, 88 - 90 = -2, 95 - 90 = 5.
Возвести отклонения в квадрат: (-5)^2 = 25, 0^2 = 0, 2^2 = 4, (-2)^2 = 4, 5^2 = 25.
Рассчитать дисперсию: (25 + 0 + 4 + 4 + 25) / 5 = 10,6.
Вычислить стандартное отклонение: √10,6 ≈ 3,26. (Low SD, scores are close to 90).
High Standard Deviation Example (Variable)
Data: {70, 80, 90, 100, 110}
Mean: (70+80+90+100+110) / 5 = 90
Calculations (Variance first):
(70-90)² + (80-90)² + (90-90)² + (100-90)² + (110-90)² = 400 + 100 + 0 + 100 + 400 = 1000
Variance (σ²) = 1000 / (5-1) = 250
Standard Deviation (σ) = √250 ≈ 15.81 (High SD, scores are spread out from 90).
Очень хорошо описано в wiki, включая то, что не добавил сюда – пример расчета величины среднеквадратичного отклонения (расчет среднего, расчет квадрата отклонений каждой величины, расчет дисперсии в виде среднего от квадратов отклонений, расчет отклонения в виде корня дисперсии), примеры из жизни, когда оно может использоваться (погода, спорт, экономика).
Например, у нас есть три числовых множества: {0, 0, 14, 14}, {0, 6, 8, 14} и {6, 6, 8, 8}. У всех трёх множеств средние значения равны 7, а среднеквадратические отклонения, соответственно, равны 7, 5 и 1. У последнего множества среднеквадратическое отклонение маленькое, так как значения в множестве сгруппированы вокруг среднего значения; у первого множества самое большое значение среднеквадратического отклонения — значения внутри множества сильно расходятся со средним значением.
# Excel
=СТАНДОТКЛОН.Г(0;0;14;14) # 7
=СТАНДОТКЛОН.Г(0;6;8;14) # 5
=СТАНДОТКЛОН.Г(6;6;8;8) # 1
В общем смысле среднеквадратическое отклонение можно считать мерой неопределённости. К примеру, в физике среднеквадратическое отклонение используется для определения погрешности серии последовательных измерений какой-либо величины. Это значение очень важно для определения правдоподобности изучаемого явления в сравнении с предсказанным теорией значением: если среднее значение измерений сильно отличается от предсказанных теорией значений (большое значение среднеквадратического отклонения), то полученные значения или метод их получения следует перепроверить.
Коэффициент вариации ((Относительное стандартное отклонение (ОСО) / relative standard deviation (RSD)) — это, по сути, процент стандартного отклонения от среднего значения, выражающий степень разброса данных относительно среднего в относительных единицах (часто в процентах), что удобно для сравнения изменчивости разных наборов данных. Его рассчитывают как отношение стандартного отклонения к среднему арифметическому и умножают на 100%, чтобы получить процент:
ОСО = (Стандартное отклонение / Среднее значение) × 100%. RSD = (Standard Deviation / Mean) × 100%
Натуральные числа – числа, которые могут быть получены в результате счета предметов (целочисленные неотрицательные от одного). Натуральные числа можно разделить на три класса (как простых, так и составных чисел бесконечно много):
-
- единица (имеет один натуральный делитель),
- простое число (имеет два натуральных делителя) – число является простым, если оно не имеет делителей, кроме 1 и самого себя.
- составное число (имеет более двух натуральных делителей)[1].
Цифровой корень числа n получается следующим образом: если сложить все цифры этого числа, затем все цифры найденной суммы и повторять этот процесс до тех пор, пока в результате не будет получено однозначное число (цифра), которое и называется цифровым корнем изначального числа. Используется в нумералогии.
Извлечение корня – операция, обратная возведению в степень. По умолчанию в python вычисляется квадратный корень – какое число (9) нужно возвести во ^2 степень, чтобы получить передаваемое (81).
>>> math.sqrt(4) 2.0 >>> math.sqrt(81) 9.0 >>> math.sqrt(100) 10.0
Процент от числа – самая частая и самая простая задача узнать как поменяется число относительно определенного процента, к примеру 80% от числа 100 или 90% от 555:
100 * 0.80 = 80 555 * 0.90 = 499.5
Процент одного числа от другого – часто есть задача сколько составляет число X от числа Y. Формула расчета простейшая, но зачастую (float, большие значения int) быстрее скопипастить. Удобный калькулятор.
Формула: (x/y) * 100
Человеческого вида (human readable) процент как число при программировании – полученный в human readable форме процент с точки зрения кода проще всего представлять как 25/77/99% = 25/100, 77/100, 99/100. Если же логика процента встроена в код/хранится в базе в нормальном виде – то более логично использовать уже сам результат этого деления 25/77/99% = 0.25/0.77/0.99.
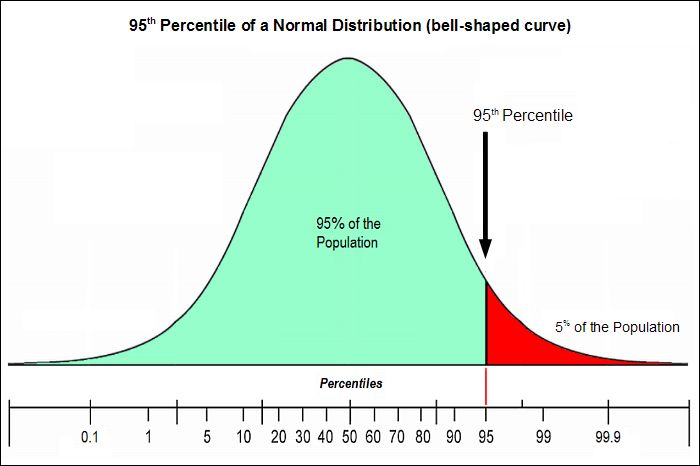
Перцентиль, процентиль (percentile) – это сотая доля объема измеренной совокупности, выраженная в процентах. Процентиль позволяет понять как данные распределены разделив их на 100 долей. Частные случаи:
-
- Медиана – это 50ый процентиль.
- Cамое большое значение в исходном наборе данных – 100-й процентиль.
- Самое малое значение – 0-й.
Например, пятый процентиль охватывает 5% объема выборки. Предположим, показатель Ивана равен пятому процентилю. Это означает, что Иван написал тест лучше, чем 5% студентов. Процентиль (или центиль ) - это показатель, используемый в статистике , указывающий значение, ниже которого падает данный процент наблюдений в группе наблюдений. Например, - 20-й процентиль - это значение (или балл), ниже которого могут быть обнаружены 20% наблюдений. Эквивалентно 80% наблюдений находятся выше 20-го процентиля. - 80-й процентиль - 20% наблюдений находятся выше 80-го процентиля.
Используется в нагрузочном тестировании (напр. JMeter) как метрика, не скрывающая всплески/выбросы (outliers), в отличии от среднего значения.
Пример расчета перцентиля/процентиля
-
- Логика расчета и три разных способа расчета (могут давать разный результат!) хорошо описаны тут
- Расчет самый простой в Excel, автоматизация расчета возможна с использованием python + numpy, python + pandas. Пример расчета перцентиля 80,90,95,99 поведение в случае выборки с “выбросом”.
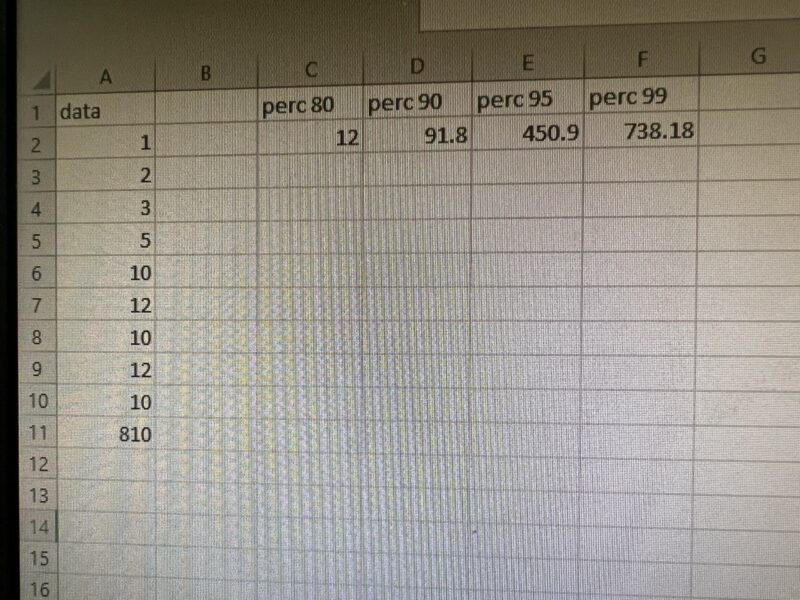
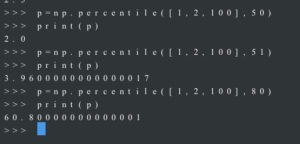
- Сложнее посчитать самому, но вполне возможно
Пример расчета значения 50-го процентиля (медианы) для набора 1, 2, 3, 4, 5 разными способами.
# EXCEL
=PERCENTILE.INC({1;2;3;4;5};0,5) = 3
=PERCENTILE.EXC({1;2;3;4;5};0,5) = 3
=ПРОЦЕНТИЛЬ.ВКЛ({1;2;3;4;5};0,5) = 3
=ПРОЦЕНТИЛЬ.ВЫКЛ({1;2;3;4;5};0,5) = 3
# PYTHON
>>> import numpy as np
>>> a = np.array([1,2,3,4,5])
>>> p = np.percentile(a, 50)
>>> print(p)
3.0
# Ручной расчет - самый простой (не точный, но значения будут близки или равны получаемым в excel/python):
1) Сортируем массив данных по возрастанию и нумеруем (ранжируем, присваиваем номер) результат сортировки 2) Определяем номер/ранг на основе заданного процентиля n = ceil(P/100 * N) 2.1) P - искомый процентиль 2.2) N - общее количество номеров/рангов 3.3) n - ранг 3) Значение соответствующее рангу считаем процентилем
1 значение - 1 ранг
2 значение - 2 ранг
3 значение - 3 ранг
4 значение - 4 ранг
5 значение - 5 ранг
n = 50/100 * 5 = ceil(2.5) = 3
Доверительный интервал – интервал, в котором с заданной вероятностью (доверительной вероятностью) заключен параметр генеральной совокупности (напр. генеральное среднее). Доверительная вероятность выражается числом от 0 до 1 или в процентах, например 90%, 95%, 99% и показывает вероятность того, что действительное значение исследуемой переменной будет лежать в принятом (указанном) диапазоне.
Среднее значение (average/mean) – в общем случае под этим позразумевается сумма значений элементов поделенная на два:
(N1 + N2 + N3)/2 In ordinary language, an average is a single number or value that best represents a set of data. The type of average taken as most typically representative of a list of numbers is the arithmetic mean – the sum of the numbers divided by how many numbers are in the list. For example, the mean or average of the numbers 2, 3, 4, 7, and 9 (summing to 25) is 5.
Именно среднее используется в международных RFC по сетевому нагрузочному тестированию, таких, как RFC 9411, RFC 2544. Так же используется в законодательной практике (РМГ 29-2013), множестве практик НТ (Intel LKP) и инструментов (tcp ss). Использование среднего и медианы так же имеет преимущество в стабилизации (за счет усреднения) результатов, т.е. их использование уменьшает неопределенность измерения.
Средневзвешанное значение (weighed average/mean) – когда элементы не равноценны т.к. если веса всех элементов равны – это простое среднее. Используется часто на практике – например, расчет NSS LABS throughput, расчет IMDB score. Пример расчет, когда вес первого 0.9, второго 1.2, третьего 2.2:
(N1*0.9 + N2*1.2 + N3*2.2)/2
NSS Labs The weighted arithmetic mean is similar to an ordinary arithmetic mean (the most common type of average), except that instead of each of the data points contributing equally to the final average, some data points contribute more than others. The notion of weighted mean plays a role in descriptive statistics and also occurs in a more general form in several other areas of mathematics. If all the weights are equal, then the weighted mean is the same as the arithmetic mean. IMDb Weighted Average Ratings IMDb publishes weighted vote averages rather than raw data averages. The simplest way to explain it is that although we accept and consider all votes received by users, not all votes have the same impact (or ‘weight’) on the final rating. When unusual voting activity is detected, an alternate weighting calculation may be applied in order to preserve the reliability of our system. To ensure that our rating mechanism remains effective, we do not disclose the exact method used to generate the rating.
Эмпирическая закономерность (от греч. εμπειρια — опыт; см. Эмпирические данные), правило большого пальца (англ. rule of thumb) — зависимость, основанная на экспериментальных данных и позволяющая получить приблизительный результат, в типичных ситуациях близкий к точному[1].
- выборка из более чем 30 элементов (n>=30) (магическое число) является минимально достаточной согласно Центральной предельной теореме (ЦПТ) – это один из самых распространенных ориентиров. ЦПТ гласит, что:
- если вы берете множество выборок даже из нестабильного набора данных, средние значения этих выборок будут стремиться к нормальному распределению по мере увеличения размера выборки
- что n>=30 минимально достаточен чтобы распределение начало приближаться к нормальному даже для ненормальных популяций, что позволяет использовать многие стандартные статистические тесты на выборку
- выборка из 44 элементов (Метод отдельновой)
-
Размер выборки = 44 для задачи ОРИЕНТИРОВОЧНОГО ЗНАКОМСТВА (исследование низкой точности) Размер выборки = 400 для задачи ИССЛЕДОВАНИЯ ПОВЫШЕННОЙ ТОЧНОСТИ
-
- многие статистики рекомендуют n>=100 при ожидании высокого значения выбросов (высокая вариативность/низкая стабильность) и для анализа слабых эффектов (заметить тонкое различие).
- 4 и более измерения в среднем эмпирически можно считать многократными измерениями и обрабатывать их результаты статистически
И эмпирическая закономерность полезна и нужна на практике т.к. она позволяет начать отвечать на вопрос “Сколько измерений нужно провести чтобы собрать статистически значимую выборку с учетом неизвестной стабильности результатов выборки“. Без знания дисперсии (разброса стабильности результатов) нельзя заранее точно предсказать размер необходимой выборки т.к. в общем случае если результаты различаются сильно -> нужно больше тестирований и наоборот. Алгоритм на практике: начать с 30 тестов в качестве пилотного тестирования (минимум ЦПТ), по итогу оценить среднее значение, стандартное отклонение (СКО); если доверительный интервал слишком широк, решить нужно ли добавлять тесты.
Согласно центральной предельной теореме, если размер выборки больше или равен 30, то можно считать, что выборочное среднее приблизительно нормально распределено. fin-accounting.ru Однако в некоторых случаях теорема работает и при объёме выборки менее 30, но для этого распределение совокупности должно быть близким к нормальному или симметричному. uproger.com Что означает "30" Размер выборки: Число 30 используется как "достаточно большой" размер выборки для того, чтобы центральная предельная теорема начала действовать. Приближение к нормальному распределению: С увеличением размера выборки распределение выборочных средних все больше приближается к нормальному распределению (гауссову), даже если исходные данные распределены ненормально. Практическое правило: Это правило не является абсолютным. Чем более асимметрично или "толстохвостое" исходное распределение, тем больше выборка должна быть больше 30, чтобы нормальное приближение было точным. В целом, 30 — это удобное практическое правило, которое часто используется, но важно понимать, что это лишь ориентир, а не строгое математическое правило. При многократных измерениях возникает вопрос, начиная с какого числа измерений можно считать измерение многократным. Строгого ответа нет. Однако известно, что при числе отдельных измерений п > 4, ряд измерений может быть обработан в соответствии с требованиями математической статистики. Это означает, что при четырех измерениях и более, входящих в ряд, измерение можно считать многократным. За результат многократного измерения обычно принимают среднее арифметическое значение из отдельных измерений.
--confidence=N — Уровень доверия для t-теста. Возможные значения: 0 (80%), 1 (90%), 2 (95%), 3 (98%), 4 (99%), 5 (99.5%). Значение по умолчанию: 5. В режиме сравнения clickhouse-benchmark выполняет t-тест Стьюдента для двух независимых выборок, чтобы определить, не различаются ли две выборки при выбранном уровне доверия. T-критерий Стьюдента для двух независимых выборок (двухвыборочный t-тест) — статистический критерий, используемый для проверки гипотезы о равенстве средних значений двух независимых генеральных совокупностей на основе выборок из них. «Независимые» означает, что измерения в одной выборке не связаны с измерениями в другой (например, детали произведены на двух разных линиях, разными сменами или с разными настройками). Для корректного использования t-критерия Стьюдента необходимо, чтобы: 1. Данные имели нормальное распределение. При маленьких выборках это означает требование нормальности исходных значений. 2. Дисперсии выборок были примерно равны (гомоскедастичность). При неравных дисперсиях применяется t-критерий в модификации Уэлча.
Медиана — это значение признака, справа и слева от которого находится равное число наблюдений (по 50%, 50ый процентиль). Для получения значения, которое находится по середине выборки правильнее использовать медиану, а не среднее значение. Потому что среднее (average) не учитывает выбросы (outliers), в отличии от медианы.
The basic feature of the median in describing data compared to the mean (often simply described as the "average") is that it is not skewed by a small proportion of extremely large or small values, and therefore provides a better representation of the center. Median income, for example, may be a better way to describe the center of the income distribution because increases in the largest incomes alone have no effect on the median.
При этом медиана далеко не всегда является “лучшей” заменой среднего. Да, среднее может завышать/занижать результат из-за чувствительности среднего к выбросам, но это занижение/завышение может являться значимым и важным настолько, что показатель к примеру “средней производительности” более честным/менее рискованным с использованием среднего, а не медиана т.к. медиана может скрыть проблемы. Особенно это часто видно на малых выборках т.к. медиана по сути учитывает только порядок элементов и изменение крайних значений выборки никак не меняет медиану.
Пример: Тестирование скорости загрузки сайта (5 пользователей). Выборка А: 1, 2, 3, 4, 5 секунд. Выборка Б: 1, 2, 3, 10, 50 секунд. Проблема: - В обоих случаях медиана равна 3 секундам. Она полностью скрывает факт катастрофического замедления сайта для части пользователей. - Среднее арифметическое (3 и 13.2 секунды) сразу покажет ухудшение ситуации.
Рассчитать медиану для числового ряда просто (не говоря про python функции, с ними пример ниже): Например, медианой набора {11, 9, 3, 5, 5} является число 5, так как оно стоит в середине этого набора после его упорядочивания: {3, 5, 5, 9, 11}. Если в выборке чётное число элементов, медиана может быть не определена однозначно: тогда для числовых данных чаще всего используют полусумму двух соседних значений – то есть медиану набора {1, 3, 5, 7} принимают равной 4 (пример №2 расчета в Excel для такого случае ниже). Можно также сказать, что медиана является 50-м персентилем, 0,5-квантилем или вторым квартилем выборки или распределения.
Медиа́на (от лат.mediāna «середина») набора чисел — число, которое находится в середине этого набора, если его упорядочить по возрастанию, то есть такое число, что половина из элементов набора не меньше него, а другая половина не больше. Пример №1 (python) Среднее для ряда 1 2 6 = 3 Медиана для ряда 1 2 6 = 2 >>> import statistics >>> l = [1,2,6] >>> statistics.mean(l) 3 >>> statistics.median(l) 2 Пример №2 (excel) Медиана для ряда 1 2 3 4 5 6 7 8 9 10 = 5.5 ((5+6/2)) =MEDIAN(1;2;3;4;5;6;7;8;9;10) =PERCENTILE.INC(A1:A10; 0,5) =PERCENTILE.EXC(A1:A10; 0,5) Пример №3 (python) Дано: список зарплат рядовых медицинских сотрудников больницы (в тыс. руб.): 25, 17, 23, 18, 24, 23, 16, а также зарплата главврача – 85 и его заместителя – 50. Каков средний уровень зарплаты в больнице? Согласно среднему арифметическому, средняя зарплата по больнице – 31,2 тыс. рублей. Если же мы посчитаем вместо среднего арифметического медиану, то получим 23 тыс. рублей. Что, по-вашему, ближе к правде? Пример расчет в python: >>> import statistics >>> l = [25, 17, 23, 18, 24, 23, 16, 85, 50] >>> statistics.mean(l) 31.22222222222222 >>> statistics.median(l) 23 Наглядно между какими значениями находится среднее (23) и медиана (31): 16 17 18 23 23 24 25 50 85 В случае же отклонения распределения от нормального закона среднее значение использовать некорректно, так как оно является слишком чувствительным параметром к так называемым «выбросам» — нехарактерным для изучаемой выборки,слишком большим или слишком малым значением (рис. 2). В этом случае для характеристики центральной тенденции в выборке должен применяться другой параметр — медиана. Медиана — это значение признака, справа и слева от которого находится равное число наблюдений (по 50%). Этот параметр (в отличие от среднего значения) устойчив к «выбросам». Заметим также,что медиана может использоваться и в случае нормального распределения — в этом случае медиана совпадает со средним значением.
Нормальное распределение – это не тоже самое что равномерное распределение т.к. при нормальном распределении выборка сосредоточена вокруг среднего, а при равномерном, она равномерно распределена по диапазону выборки.
(excel, stat) Нормальное распределение.
=norm.dist(value; mean; STD; probability_mass_function/cumulative_distribution_function)
Требуется анализ именно на равномерность распределения (равномерные значения в выборке), а не на нормальность/закон Гаусса (выборка сосредоточена вокруг среднего) https://thecode.media/gauss/ Короткая версия статьи Закон нормального распределения — это статистический закон, который описывает большие наборы данных — например 10 тысяч бросков кубика. Закон говорит: есть среднее значение, оно встречается чаще всего; чем дальше от среднего — тем реже оно встречается. Нормальное распределение представляют в виде графика, который похож на плавную кривую (как холм такая). Закон нормального распределения работает почти во всех областях, где происходят случайные события: от игральных костей до макроэкономических процессов. В названии закона слово «нормальное» означает то, что в данных нет сильного отклонения от средних значений, которое принимается за норму. Это не значит, что есть «нормальное», а есть «ненормальное» распределение — это просто название закона.
Если сформулировать суть закона распределения Гаусса, то она будет звучать примерно так:
значения случайной величины будут сгруппированы вокруг среднего значения, и чем дальше от среднего значения, тем меньше вероятность того, что такое значение %