

- RAID 9 is not a valid RAID level, and LVM does not support RAID functionality. RAID is a technique that uses multiple disks to provide redundancy, performance, or both.
RAID can be implemented at the hardware level, by using a RAID controller, or at the software level, by using tools such as mdadm or dmraid. LVM can work on top of RAID devices, but it cannot create them.
Конспект вебинара HonorCup E=DC2 для сдачи HCNA Storage.
- (Disk, RAID) От компании datarc по восстановлению данных полезные советы
❗️А вот пользователям напоминание:⠀ Никакой RAID, и даже зеркало, не защищает от программных сбоев, вирусов, диверсий и ошибок пользователей (удалили, отформатировали и т.д.) В очередной раз вспоминаю, что ➢RAID даже с избыточностью 50% – это еще не бэкап. Его бы не мешало резервировать ➢Избыточность деградированных массивов лучше вовремя восстанавливать штатным ребилдом на новый диск, не пренебрегая неприятными возможностями, какими бы маловероятными они ни казались.
- RAID контроллер зачастую в виде чипсета есть в материнских платах – пример моей матринки за 3к рублей 2012 года
- Linux поддерживает создание софтовых RAID массивов.
# mdadm --verbose --create /dev/md0 --level=1 --raid-devices=2 /dev/sdc1 /dev/sdd1
- Windows поддерживает создание софтовых RAID массивов.
-
- RAID 0
- RAID 1 (с разным 2-3 копиями)
- RAID 5
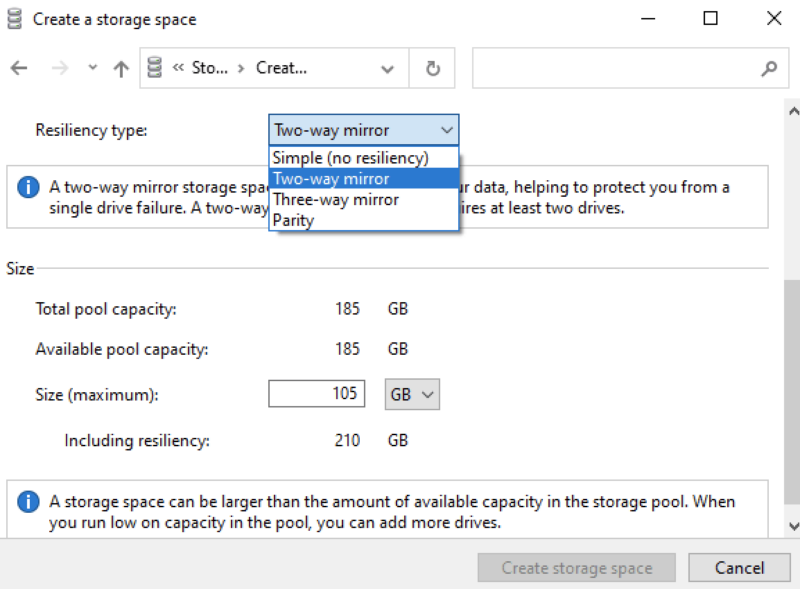
Что/зачем
RAID (Redundant Array of Independent Disks) – объединение дисков (не только жестких, можно и SSD) в один массив.
Основные решаемые задачи:
- отказоустойчивость (не RAID 0) – дублирование и/или восстановление данных посредством контроля четности, горячая замена дисков. НО везде подчеркивается, что RAID не является альтернативой или заменой решений по backup, он защищает только от довольно узкого кейса отказа диска/ов.
- повышение производительности – параллельный доступ к нескольким дискам

Контроллер
Бывают программные и аппаратные RAID контроллеры:
- аппаратный: отдельная плата с собственными CPU/RAM, в случае PCI-e SSD контроллер встроен в плату PCI-e SSD
- + производительность, – стоимость
- программный: приложение/ОС + ресурсы ПК CPU/RAM
- – производительность, + стоимость
- 50/50: на базе BIOS/материнской платы. Лучше таким не пользоваться, постоянные глюки по отзывам.
Обычно на контроллере реализуется только один тип интерфейса под ЖД: SAS/SCSI/SATA. В общем случае на один контроллер цепляется до 8 дисков, но на практике зачастую используется экспандер – может позволить до х3 подключить.
Пример софтового контроллера рядом с нами 🙂 – Windows имеет встроенный программный RAID – может объединить диски в RAID 0, RAID 1 или RAID 5.
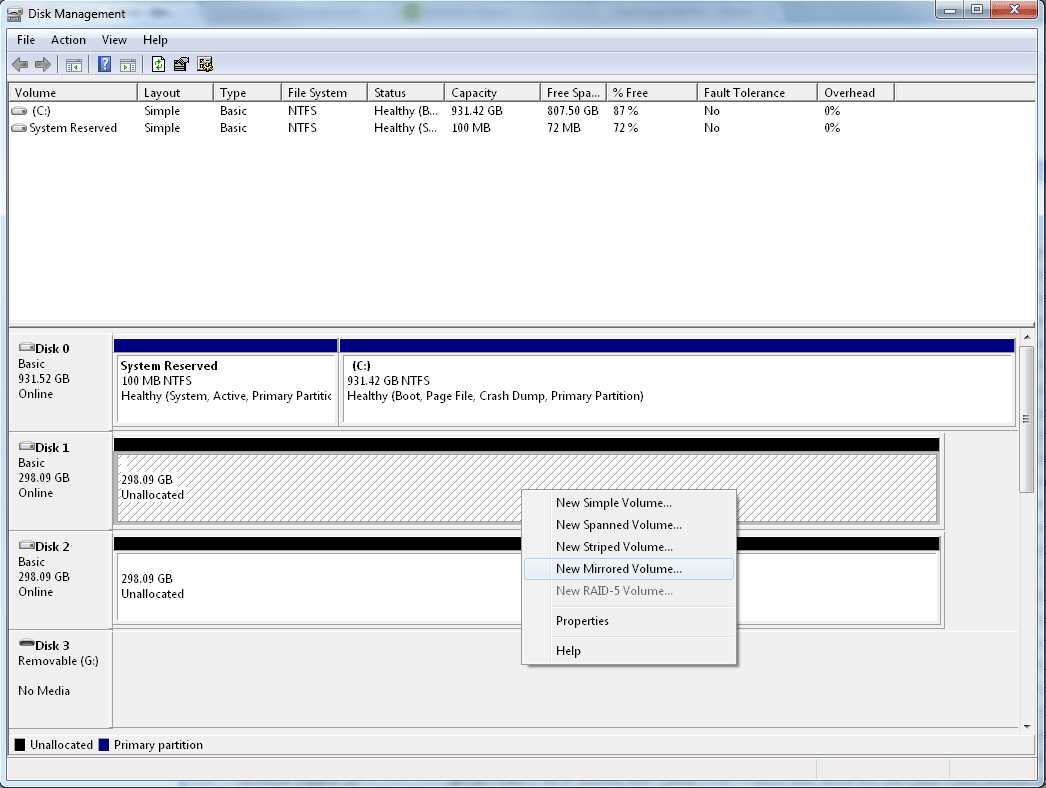
Hot Spare диски
В крупный RAID всегда должен быть включен HotSpare (горячий резерв) диск, на который пойдет автоматический ребилд при падении какого-то из дисков. Hot Spare бывают двух видов: глобальный (резерв под любой массив в системе хранения) и выделенный (выделенный диск под конкретный RAID в системе хранения).
К примеру, конфиг системы хранения: 20 дисков, разбитые на 5 рейдов и 1 диск как hot spare на все.

Политика по количеству hot spare исходя из количества дисков в домене – чем больше дисков, тем больше должно быть в резерве (логично, не правда ли :)).
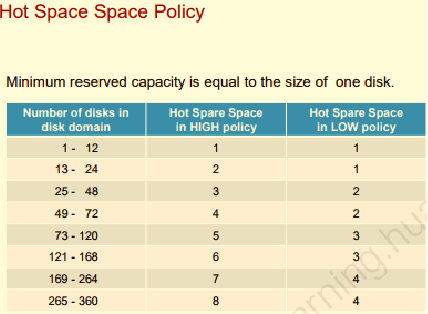
Статусы работы RAID
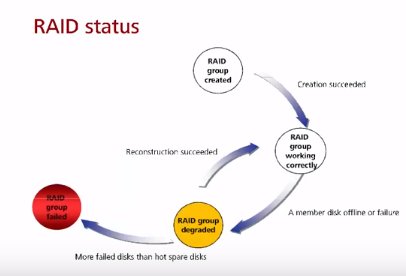
1) Создание массива
При создании массива диски записываются нулевыми данными.
Все зависит от массива/контроллера, но в общем случае:
- В массиве не обязательно должно быть четное количество дисков (попарно)
- В массиве не обязательно диски одинакового размера. Чаще всего в таком случае мы просто теряем полезную емкость больших дисков (выравнивание объема по меньшему) и использовать его невозможно под другие задачи. Есть режим JBOD (Just buch of disks), в котором можно использовать всю емкость, но это не RAID.
- В массиве не обязательно диски должны иметь одну скорость, но производительность массива определяется по минимальной скорости.
- Обычно используется один тип дисков.
- Обычно в RAID можно на лету добавить еще диски.
2) Корректная работа массива – все ок
Следующие три статуса работы при отказе одного или несколько из дисков в массиве. Отказ определяется контроллером при попытке записи/чтения с диска.
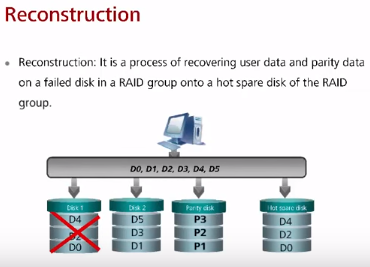
3) Реконструкция массива (RAID rebuilding/reconstruction)
Реконструкция – в наличии hot spare диск/и, утерянные данные восстанавливаются на hot spare.
Для RAID 10/1 операция не требует расчетов на основе четности, на остальных рейдах требует. Для восстановления данные считываются с “выживших” дисков, происходит расчет XOR и восстановление данных на основе операции. Время восстановления прямо пропорционально количеству потерянных данных – чем больше данных потерялось, тем больше времени восстанавливать. В момент восстановления производительность может заметно падать (при двух дисках) т.к. операция копирования идет с меньшим приоритетом, чем запросы от приложений и приостанавливается при запросе данных приложениями -> в результате восстановление RAID на активно-работающем сервере может занять долгое время
Время ребилда зависит от множества факторов – типа рейда и RAID контроллера, скорости/объема/количества дисков, нагрузки на систему. Ниже таблица для RAID 1 со стандартным рейдом, видно, что речь обычно идет о часах. В тестах Huawei 1TB диск в RAID 5 восстанавливался порядка 8-10 часов, RAID 2.0+ 30 мин (скрин тут).
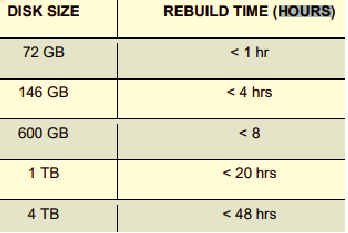
Так же реконструкция происходит, когда добавляется новый диск в RAID. Зависит от контроллера (в основном можно) можно ли добавлять на лету диск в рейд.
4) Деградация массива
Деградация – отказ члена/ов массива (в том числе диска четности) при отсутствии hot spare для запуска реконструкции. Процедура восстановления не может запустится из-за отсутствия носителя.
5) Авария массива
Аварией массива считается ситуация, когда отказало одновременно больше дисков, чем позволяет RAID технология.
За что еще отвечают контроллеры
Сохранение данных кэша при отключении питания
Кеш RAID/СХД контроллера обычно хранится в ОЗУ, а не ПЗУ (HDD/SSD). Поэтому при пропадании питания данные кэша могут быть потеряны.
- Традиционным способом защиты данных в кэше контроллера является BBU (Battery Backup Unit) модуль (батарея), обеспечивающий питание ОЗУ контроллера в течение некоторого времени после сбоя при помощи литий-ионного аккумулятора. При запуске сервера после восстановления питания контроллер сбрасывает сохранившееся содержимое кэша на дисковый массив. У BBU есть ряд существенных недостатков, связанных с наличием аккумулятора: ограниченное время защиты после сбоя (обычно не более 72 часов), ограниченный срок службы аккумуляторов (1-2 года), необходимость планирования закупок новых BBU модулей и утилизации вышедших из строя.
- В современных контроллерах используется другой способ защиты RAID кэша — при помощи модуля с флэш-памятью и питанием через суперконденсаторы (ионисторы). При возникновении сбоя батарея ионисторов питает модуль защиты кэша только на время копирования содержимого ОЗУ на флэш-память модуля.
Есть и другие варианты сохранения данных:
- Батареи + служебное пространство 4 дисков (2×2 coffer диска в RAID1) на СХД Huawei
- NVDIMM (non-volatile-DIMM: DIMM + батарейка + флешка) на BigData СХД OceanStor 9000
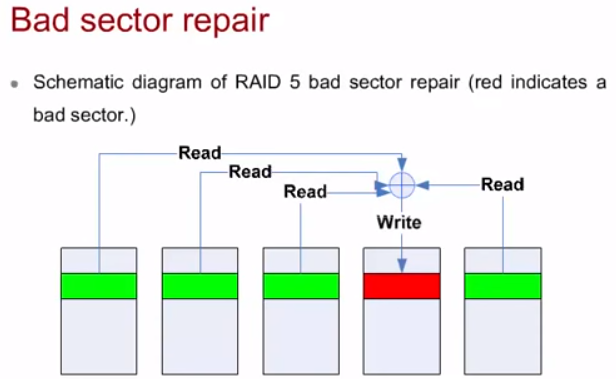
Анализ состояния дисков (SMART analysis – Self Monitoring Analysis Reporting Technology, Bad sector detection/repair)
Данные SMART постоянно анализируются RAID/СХД-контроллерами. Контроллер обнаруживает bad sector’а при операциях read/write и восстанавливает информацию, которая была на этом секторе используя технологию восстановления, применяемую в настроенном RAID.

pre-copy на hot-spare
В случае обнаружения плохого SMART/сбойный блок на диске, контроллер RAID/СХД копирует данные с потенциально сбойного диска на hot-spare. После замены потенциально сбойного диска данные с hot-spare копируются на новый диск.
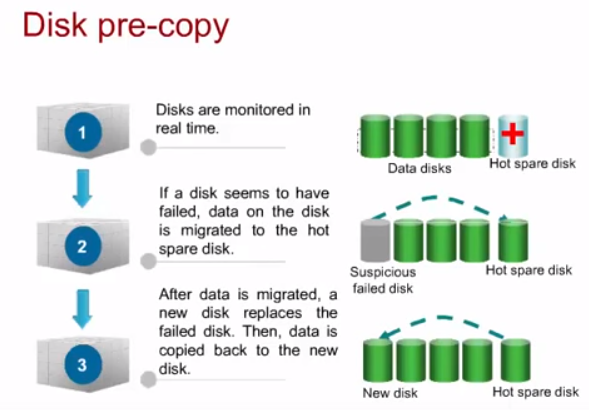
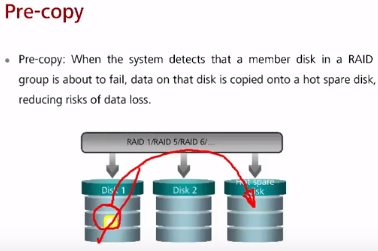
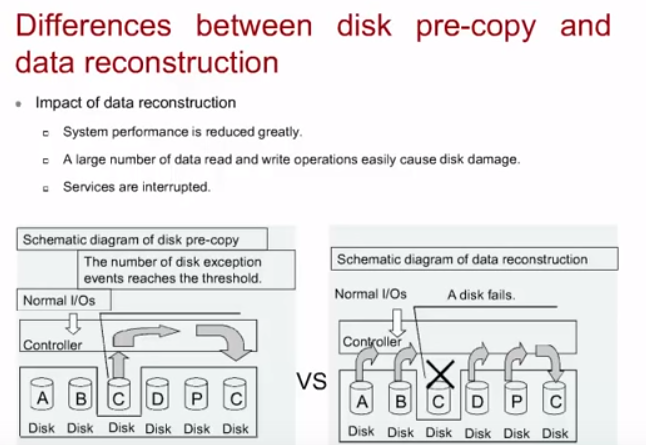
Такой подход считается лучше Data reconstruction в случае выхода из строя диска полностью т.к. он более быстрый, меньше влияет на производительность RAID/СХД и более надежен.
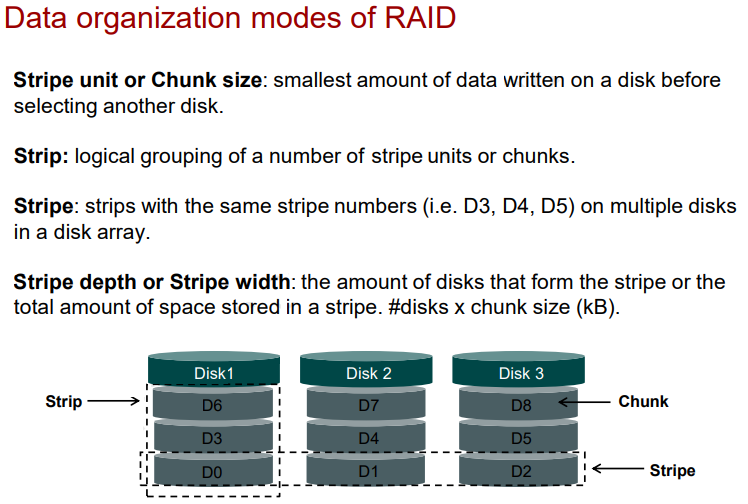
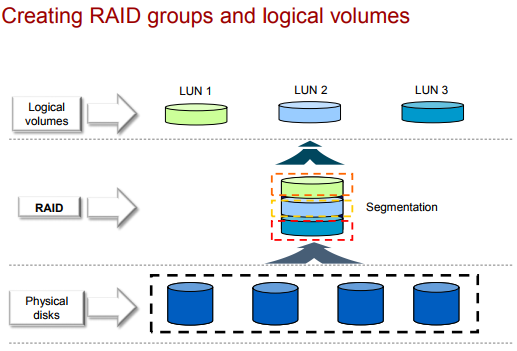
ОБЪЕКТЫ ДАННЫХ RAID (Strip, Stripe, LUN)
Контроллер RAID оперирует объектами данных:
- Stripe unit или chunk size – минимальная единица данных, записываемая на один диск, перед записью на другой диск.
- Strip (лента) – один или несколько последовательных секторов на диске (логическая группировка chunk).
- Stripe (полоса) – сектора на одном месте (или с одним номером Stripe) на нескольких ЖД в RAID.
- Stripe width/depth (ширина ленты) – суммарная емкость секторов на одной ленте: количество данных в chunk одного stripe * количество дисков под данные в RAID.
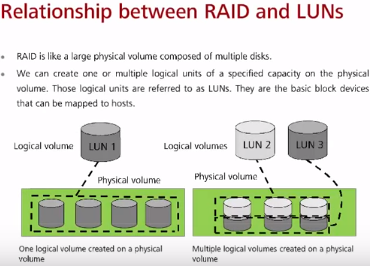
В общем случае RAID-контроллер не знает что такое файловая система (не говоря про бюджетные варианты), а создает LUN.
LUN (Logical Unit, Logical Volume) – логический объект, состоящий из физических секторов (или логических структуры, которые полагаются на сектора). Чаще всего системы хранения/рейд контроллеры предоставляют ОС LUN в виде неформатированного диска (raw capacity), а уже ОС определяет какая файловая система будет использоваться для этого LUN. Новые контроллеры могут создавать несколько LUN на базе одного RAID.
Восстановление данных
Восстановление данных в RAID основывается на replication (mirroring) в случае RAID 1 (и его производных) или на базе булевой функции сложения по модулю (XOR) в случае RAID 3, 5, 6.
Таблица истинности XOR:
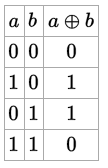
- когда вход одинаков – результат ложь (1×1, 0x0 -> 1)
- когда вход отличается – результат истина (0x1, 1×0 -> 0)
Пример с одним контрольным битом: при использовании трех ЖД на одном ЖД хранится один набор бит, на втором – другой, а на третьем (специальный parity disk) хранится результат XOR от первых двух. В результате при выходе любого из ЖД используя тот же XOR можно восстановить данные этого диска.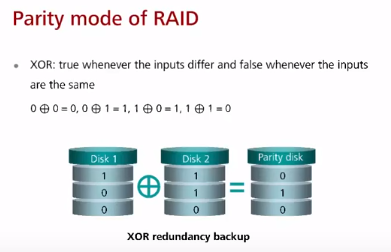
Parity data is used by some RAID levels to achieve redundancy. If a drive in the array fails, remaining data on the other drives can be combined with the parity data (using the Boolean XORfunction) to reconstruct the missing data. For example, suppose two drives in a three-drive RAID 5 array contained the following data: Drive 1: 01101101 Drive 2: 11010100 To calculate parity data for the two drives, an XOR is performed on their data: 01101101 XOR 11010100 _____________ 10111001 The resulting parity data, 10111001, is then stored on Drive 3. Should any of the three drives fail, the contents of the failed drive can be reconstructed on a replacement drive by subjecting the data from the remaining drives to the same XOR operation.
ЗАПИСЬ НА RAID
Два вида:
Зеркалирование (Mirroring) – RAID контроллер дублирует блок данных. RAID 1, 10, 01.
Страйпинг (Striping) – первый блок данных контроллер кладет на первый диск, второй блок – на второй, третий – на первый и т.д. Таким образом нагрузка при последовательной записи распределяется между дисками. RAID 3, 5, 6, 50, 10, 01.
Уровни RAID

Сравнение уровней, есть так же в куче мест: wiki, огромная дока (не только сравнение), небольшая статья на nix. При выборе защиты нужно всегда помнить, что методы защищающие от отказа одного ЖД (RAID 3/5) хороши, но всегда надо учитывать, что вероятность отказа двух дисков (второго диска в момент rebuilding после отказа первого) выше вероятности отказа одного т.к. после отказа одного нагрузка на RAID увеличивается и увеличивается вероятность отказа.
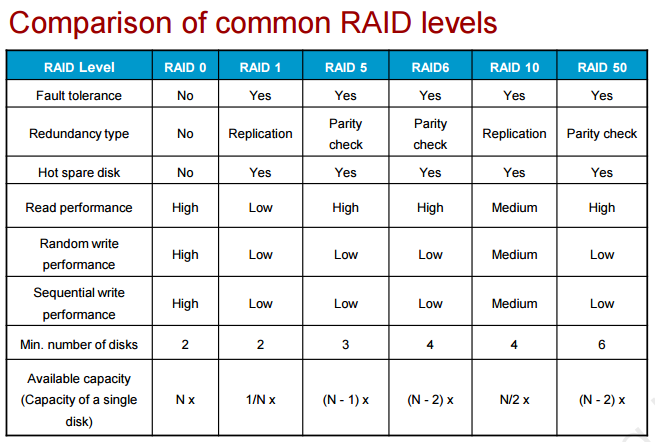
Чаще всего используемые массивы:
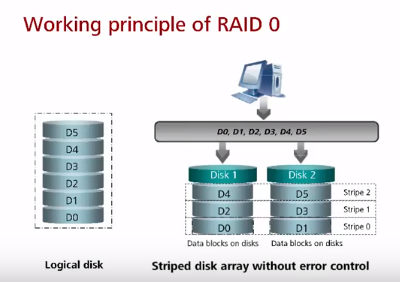
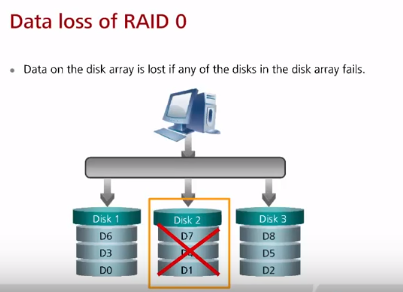
RAID 0 (чисто он сейчас используется редко, если только в связке с резервной копией или если данные не важны – являются копией, например работа с графикой). RAID 0 предоставляет максимальную скорость чтения/записи, но без отказоустойчивости и чем больше дисков, тем больше риск сбоя всего рейда (в случае сбоя только попытка восстановления, но это всегда), причем нет возможности даже использовать диски горячей замены, в отличии от других RAID! Дисков не обязательно два, можно больше. Помимо RAID 0 при поиске методов ускорения нужно не забывать рассматривать шины, к которым подключен дисковый контроллер и производительность самого контроллера, возможно есть bottleneck в них (добавление второго контроллера по отдельной pci-e шине). Это не говоря про оптимизацию приложения (базы данных и индексы), уменьшение использование swap путем добавления RAM.
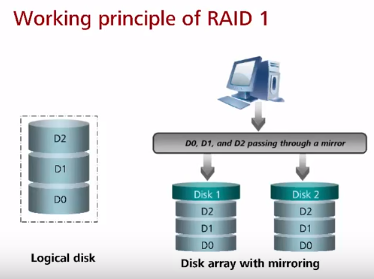
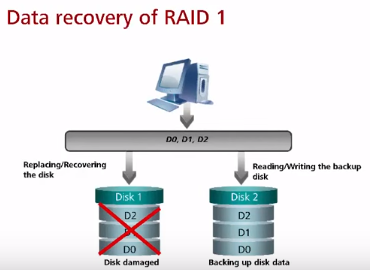
RAID 1 (может использоваться для БД и других важных данных, но чаще для них используется RAID 10) – зеркалирование дисков. Все диски являются копиями всех – контроллер дублирует данные при записи. Чаще всего в RAID 1 находятся всего 2 диска из-за роста стоимости решения без фактического роста объема. Общий объем данных не должен превышать объем одного диска. Скорость считывания увеличивается за счет того, что контроллер может забирать данные с разных дисков. В случае выхода из строя диска и замены диска на новый диск происходит копия с выжившего ЖД на новый.
RAID 3 (чаще всего вместо него используется RAID 5, может быть даже не реализован на новых контроллерах) – массив дисков с использованием выделенного диска четности. Данные контроллером записываются последовательно на диски в основной массив дисков, а данные о контрольной сумме от данных по XOR записываются на диск четности. При чтении осуществляется операция read только с дисков данных, четность не проверяется. Компьютеру не будет доступна емкость диска четности (n-1 полезная емкость). При этом коэффициент полезного объема повышается с увеличением количества дисков. Производительность всего RAID может иметь узким местом диск четности т.к. на него невозможно “распараллелить” запись. В случае поломки данных, после замены, восстановление данных происходит с помощью диска четности и данных с других (выживших) дисков. Отказ диска четности не критичен, но в случае отказа любых двух дисков (четности или нечетности – не важно) данные потеряны, защита только от отказа одного диска в один момент.
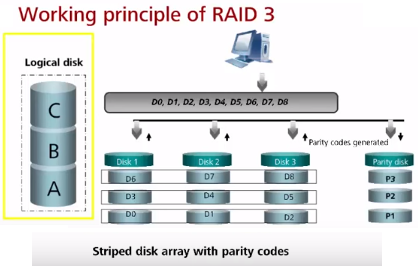
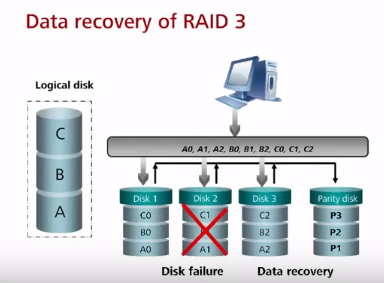
RAID 5 (часто используется, например в файловых/почтовых серверах, обычно до 12 дисков) – частая ошибка что в RAID 5 максимум 5 дисков, по факту в RAID 5 можно включить минимум 3 диска (можно и 4). Данные по четности равномерно распределены между всеми дисками (на первый диск четность по первому stripe, на второй диск четность по второму stripe, etc; блоки четности равномерно распределяются по массиву). Плюс по сравнению с RAID 3 – отсутствие расхода всего диска под четность, нет завязки на производительность диска четности. Достоинства – хорошая скорость считывания данных (как параллельного, так и последовательного). Недостатки – низкая скорость случайной записи и чем больше дисков, тем большее время восстановления, поэтому RAID 5 чаще всего состоит максимум из 10-12 дисков. По аналогии с RAID3 в случае отказа любых двух дисков данные потеряны, защита только от отказа одного диска в один момент.
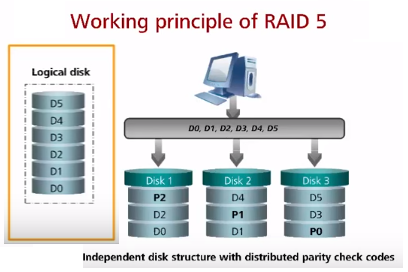
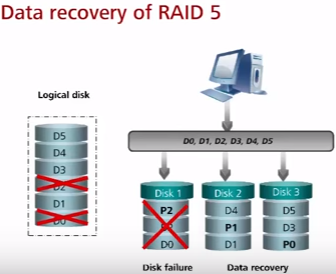
RAID 6 (при необходимости большой надежности в сравнении с R3/R5; в файловых/почтовых серверах, встречается, но не часто) – RAID 6 похож на RAID 3 и RAID 5 с той разницей что используется две контрольные суммы четности вместо одной. Повышается надежность (защита от отказа до двух дисков одновременно) и производительность, но записываются две суммы на диски. Минимум 4 диска и потеря полезной емкости 2 дисков из них гарантирована. RAID 6 работает немного медленнее RAID 5 из-за необходимости расчета и записи двух контрольных сумм при записи и rebuild. Используется не на очень объемных дисках из-за долго rebuild (не более 1ТБ).

У вендоров существует две основных технологии реализации RAID 6:
RAID 6 DP (double parity) (NetAPP) – похож на RAID 3. Используется двойная контрольная сумма (две суммы, обе рассчитаны используя xor). Первая контрольная сумма рассчитывается по stripe и кладется на основной диск четности, вторая контрольная сумма рассчитывается на основе данных о четности блоков данных разных stripes, включая четность основного диска четности (диагональная четность) и кладется на второй диск четности.

RAID 6 P+Q (Huawei, HDS) – похож на RAID 5. Вычисляются две контрольных суммы (xor + вторая через коды Рида-Соломона) и обе суммы для одного stripe кладутся на все ЖД последовательно.

RAID 2.0+ – проприетарный RAID на СХД Huawei, подробнее в статье про технологии СХД Huawei.
Комбинации
Если в наименовании две цифры (RAID 10/50) – значит происходит одновременное использование нескольких RAID методов:
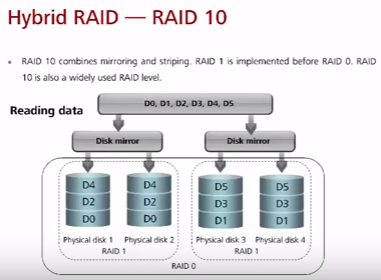
RAID 10: RAID 1 (внутри) + RAID 0 (поверх первого) RAID 50: RAID 5 + RAID 0
RAID 01 (редко) – минимум 4 диска. Состоит из stripe, поверх которых осуществляется mirror (массив RAID1 из массивов RAID0). В общем случае не делается больше 2 групп зеркал.
RAID 10 (часто используется, особенно для БД и других важных данных) – минимум 4 диска и общее количество должно быть четным. Состоит из зеркал, поверх которых осуществляется striping (массив RAID0 из массивов RAID1). Частично заимствует скоростные преимущества RAID0 и преимущество надежности RAID1. При этом частично сохраняется основной недостаток RAID1 – высокая стоимость дискового массива. В общем случае в группе зеркал по два диска – они дублируют друг друга, а запись проходит последовательно на несколько групп зеркал. При отказе двух дисков в RAID 10 в разных Disk Mirror групп данные восстанавливаются от соседей выживших Mirror групп. В случае отказа двух дисков в одной Mirror группе – RAID ломается.
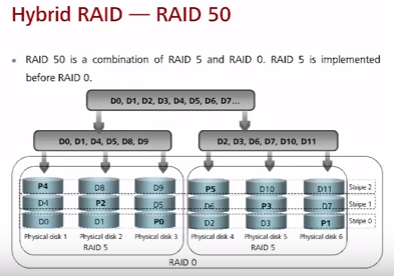
RAID 50 (редко) – минимум 6 дисков. Состоит из групп RAID 5 поверх которых осуществляется striping. Лучше RAID 5 при большом количестве дисков. Проще восстановление и лучше скорость доступа.
Вопросы
все вопросы/ответы по теме тут