
- Аналитические платформы крайне востребованы в государственных задачах – пример Palantir Texhnologies
Palantir Technologies делает не «еще один искусственный интеллект» и не обычную базу данных. Компания продает платформы, которые соединяют разрозненные сведения, строят связи между людьми, объектами, событиями и процессами, а затем дают аналитикам интерфейс для решений. В государстве такой софт помогает искать угрозы, вести расследования, управлять военными операциями и связывать старые ведомственные базы. В бизнесе Palantir обещает навести порядок в поставках, производстве, финансах и рисках.
Palantir стоит понимать как сильного поставщика инфраструктуры для сложных данных, а не как мистическую корпорацию из конспирологических роликов.
Конспект вебинара HonorCup E=DC2 для сдачи HCNA Storage.
-
Data Warehouse (DWH) — хранилище, предназначенное для сбора и аналитической обработки исторических данных организации. Анализ помогает руководителям видеть цельную картину бизнеса и принимать решения, как развивать отдельные направления или бизнес в целом. В DWH данные из всех СУБД предприятия аккумулируют и очищают, формируя их единый источник. Благодаря этому Data Warehouse содержит самую точную информацию обо всех аспектах деятельности предприятия за годы работы. Данные из хранилища затем можно визуализировать и проанализировать с помощью систем бизнес-аналитики (BI). Отличия DWH от транзакционной БД: – Data Warehouse разворачивается поверх СУБД и способно быстро обрабатывать большие массивы данных, собранные за несколько лет. Это инструмент для комплексного анализа данных из множества источников. – СУБД в основном предназначены не для аналитики, а для повседневной работы. Информация в них обновляется в реальном времени. В основе CRM, ERP, 1C и многих других систем и программ лежит именно функциональность БД.
- (Bigdata, postgres) Broadcom закрыл git greenplum. СУБД Greenplum представляет собой распределённую редакцию открытой СУБД PostgreSQL, оптимизированную для выполнения аналитических запросов над большими массивами данных (Data Warehouse). Для параллельной обработки данных применяется массивно-параллельная архитектура MPP (massively parallel processing), обеспечивающая масштабируемость хранилища до петабайтных размеров за счёт разделения данных на сегменты и задействования для их хранения и обработки кластера из группы серверов.
- При этом Greenplum активно применяется в процессах замещения продуктов ушедших с российского рынка компаний, а также лежит в основе аналитической СУБД Arenadata DB (ADB) от российской компании Аренадата. По заявлению компании Аренадата сворачивание публичной разработки Greenplum не окажет негативного влияния на развитие Arenadata DB, так как компания была готова в подобному развитию событий и приступила к сопровождению собственного форка Greengage Database (GPDB), продолжающего развиваться под открытой лицензией Apache 2.0 (ранее разработчики из Аренадата передавали изменения в основной совместный проект и являлись одними из его активных участников).
- Google BigQuery – это быстрое, экономичное и масштабируемое хранилище для работы с Big Data, которое вы можете использовать, если у вас нет возможности или желания содержать собственные серверы. По сути Google BigData БД.
- 10 GB storage и до 1 TB запросов бесплатно
All customers get 10 GB storage and up to 1 TB queries/month, completely free of charge.
-
- Дешевле аналогов, которые, безусловно, есть:
- AWS redshift
- Azure SQL DW
- Snowflake
- Очень легко и быстро обрабатывает большое количество данных, например 10 GB данных обрабатывает за ±10 сек причем с кучей группировок и всякими вычислениями.
- Очень удобная аналитика Big Data при использовании BigQuery с Data Studio, с возможностью настройки фильтров “на лету”
- Дешевле аналогов, которые, безусловно, есть:
The Data Studio BigQuery connector allows you to access data from your BigQuery tables within Data Studio.
Big data – вся совокупность огромных объемов данных (структуированных и неструктуированных), которые не могут быть обработаны для получения воспринимаемых человеком результатов в рамках текущих программно-аппаратных средств.
Big data is a term for data sets that are so large or complex that traditional data processing application software is inadequate to deal with them.
Во многом понятие big data – маркетинговый булшит: многие процессы связанные сейчас с большими данными были и до этого (БД крупных контент провайдеров, биллинг крупных провайдеров связи и проч – распределенные системы хранения). Да и Hadoop появился в 2005, Google File System в 2000, а термин big data в 2008.
Зачем надо
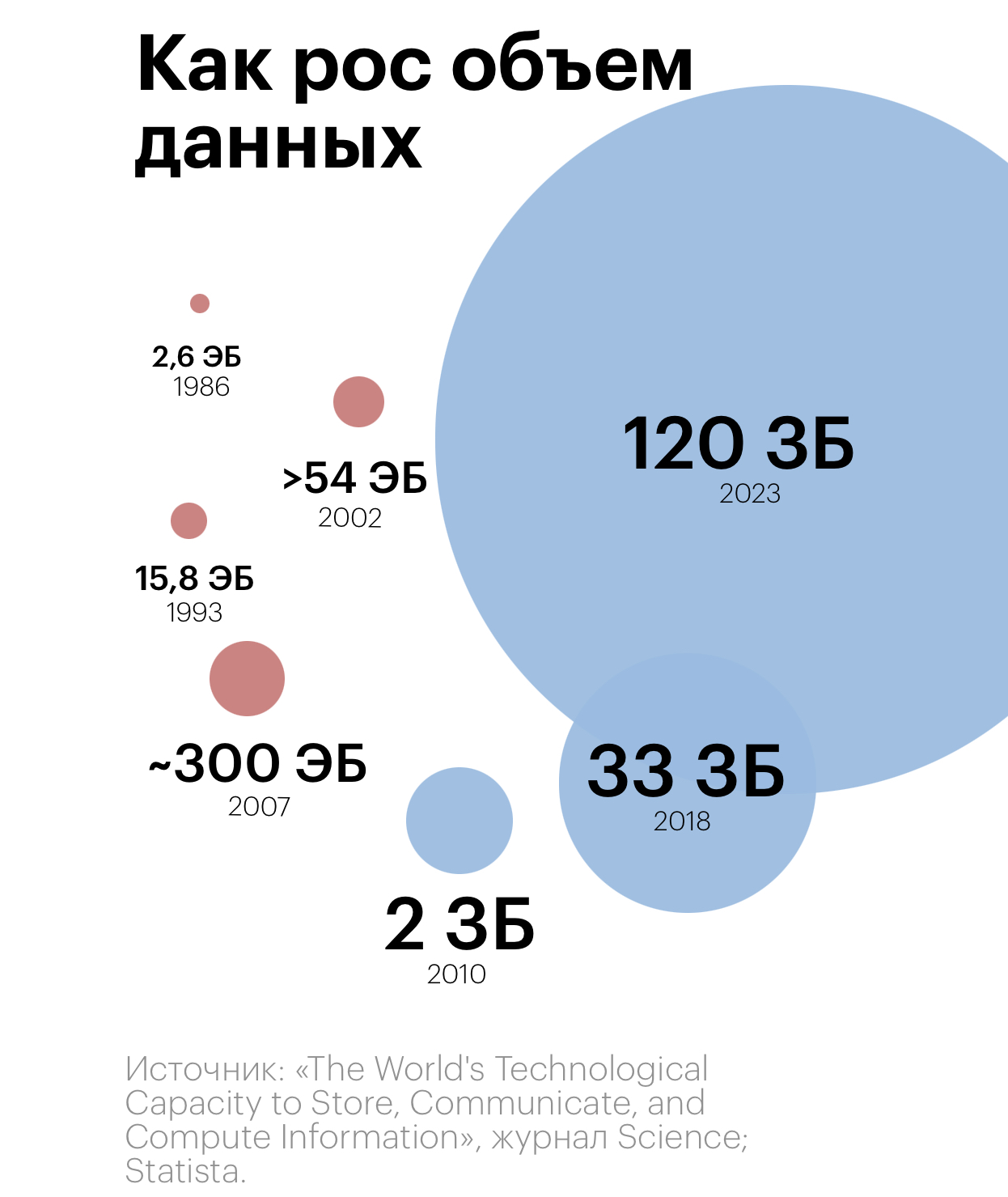
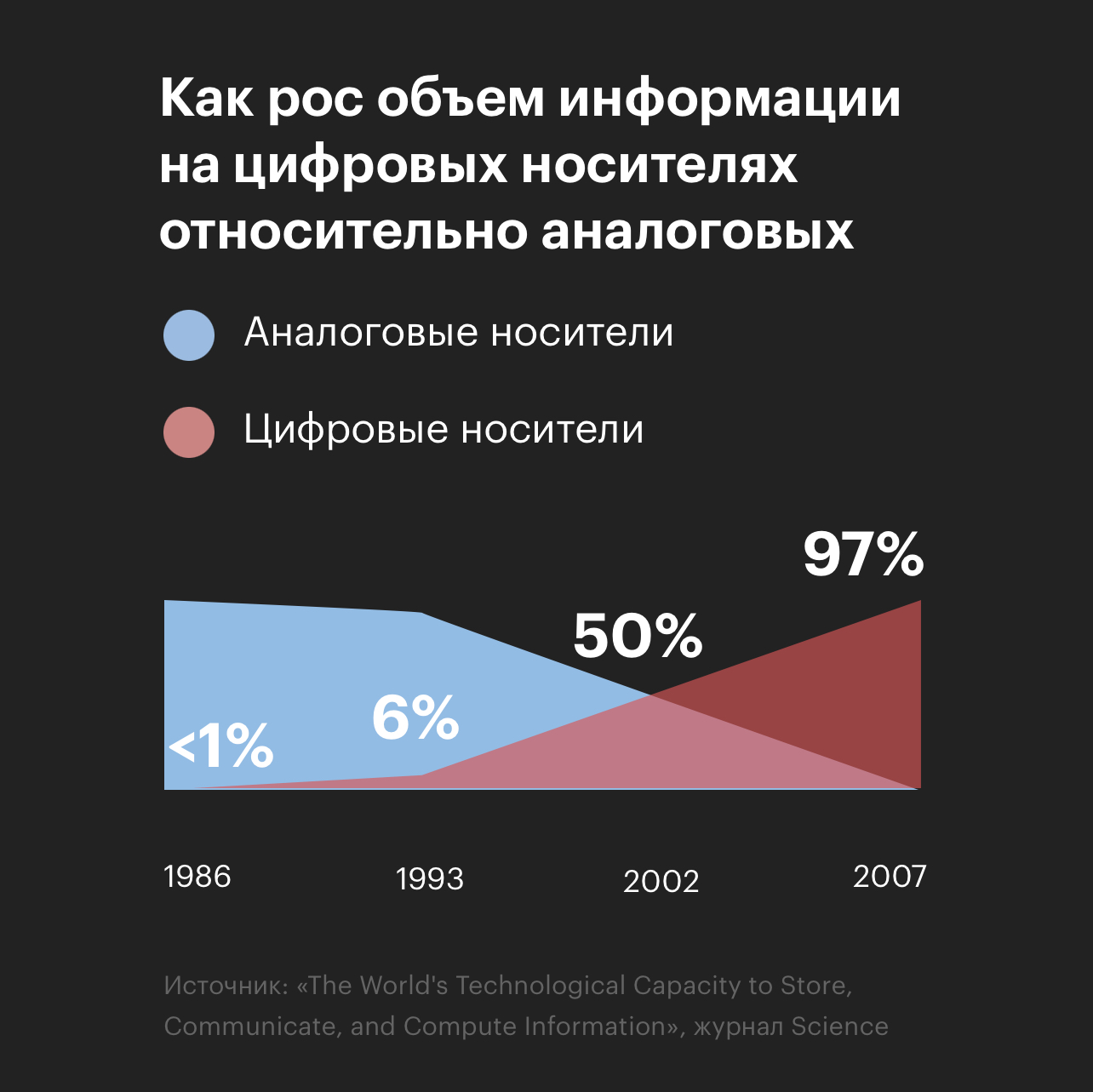
Проблема в том, что объем данных растет, причем особенно растет объем неструктуированных данных и сейчас их более ¾ от общего количества. По информации от gartner (исслед./консал. компания):
- 5 экзабайт (10^18 байт) до 2003 года было сгенерировано и сохранено данных
- 5 экзабайт в 2011 году генерировались за два дня
- 5 экзабайт в 2013 году генерировались за 10 минут
- к 2010 году объем глобальных данных преодолел 1 зетабайт (10^21 байт)
- к 2020 году общее количество сгенерированных данных будет 40 зетабайт (рост в 40 раз за 10 лет)

Факторы роста:
- Мобильные телефоны
- Рост коммуникаций (соцсети, мессенжеры, etc)
- Рост каналов передачи данных
- Изменение структуры данных
- Рост качества фото/видео и результирующий рост их объема

И в тоже время, текущие реляционные БД не способны справится с растущим объемом данных.
Предпосылки проблемы
Источники данных различны и они генерируются пользователями в повседневной жизни. Помимо пользователей данные генерируются и устройствами и этих устройств становится все больше (умные часы/холодильники/чайники, не говоря про IT оборудование/системы).
Без развития ИТ технологий появление новых устройств и контент услуг из-за повышающегося объема был бы невозможен. Поэтому развитие ИТ технологий сыграло большую роль в появлении проблематики Big Data – развитие обеспечило платформу для роста потребностей через планомерное повышение производительности, максимального объема, уменьшение стоимости, появление cloud технологий, технологий noSQL и newSQL.
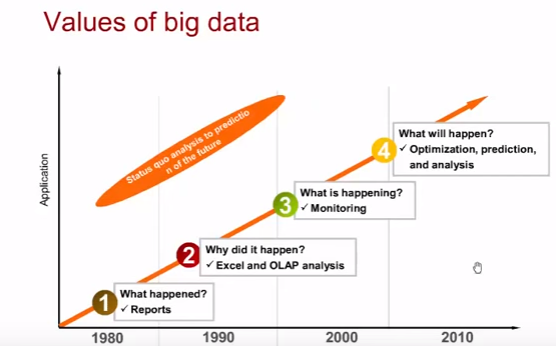
Работа с данными
Эволюция работы с данными или повышение ценности данных:
- Отчеты вида что произошло
- Excel/OLAP позволили отвечать на вопрос почему это произошло
- Мониторинг позволил знать, что происходит сейчас
- Анализ/предсказание/оптимизация позволили смотреть в будущее (предсказание эпидемий по запросам симптомов в google)
Процедура обработки big data по сути не отличается от обработки обычных данных: сбор данных, хранение, управление, аналитика данных. Источники/средства/методы сбора данных зависят в основном от источника.
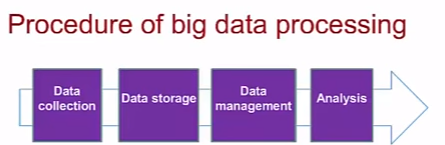
Структуированные и неструктуированные данные
Три типа данных по пригодности их для автоматизированной работы с данными (обработки/аналитики/оценки ценности/извлечения информации):
- Под структуированными (structured data) данными подразумеваются данные, пригодные для этих операций (записи в базах данных, таблицах).
- Неструктуированные (unstructured data) данные требуют новых баз и инструментов для возможности этих операций над ними (фото, аудио, видео, текстовые документы, веб-страницы).
- Различают так же полуструктуированные данные (semi-structured data), данные могут быть частично автоматизировано обработаны (текстовые документы, веб-страницы, логи).
С big data постоянно приходится работать двум типам IT-компаний:
- контент провайдеры
- телеком провайдеры
Уровень структуированности проходящих через них данных у обоих типов компаний довольно плох.
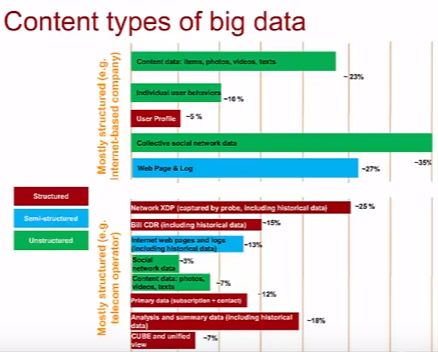
Характеристики
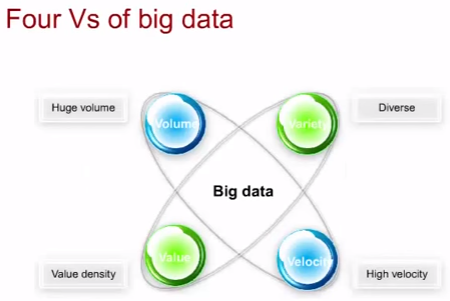
Под big data попадают данные со следующими характеристиками (четыре V big data):
- Volume (объем) – огромный объем
- Variety (вариативность) – огромное количество типов данных
- Velocity (скорость) – растет скорость объема, причем неструктуированные данные растут быстрее структуированных
- Value (ценность) – невозможно оценить ценность данных и она может отличаться
К тому же, зачастую, такие данные записаны один раз и в них вносятся редкие модификации, но им требуется долговременное хранение (фотки с отпуска).
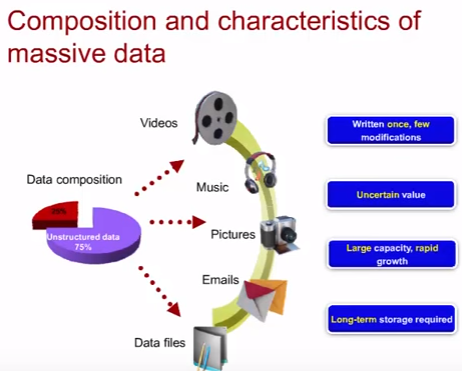
Технологии
Object-based storage
К двум существующим вариантам хранения добавляется новый тип OBS (не путать OBS и NoSQL Object database – это разные вещи):
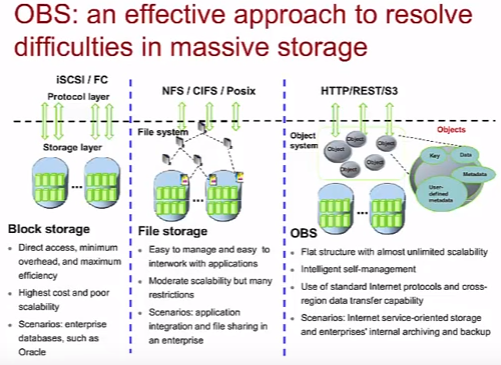
- Блоковое (iSCSI, FC) – блоки данных передаются к системе хранения напрямую. Высокая скорость и низкие задержки, но высокая стоимость, относительно плохая масштабируемость (не подходит для big data) и проблемы с передачей данных между разными SAN сетями. Сценарии использования: базы данных Enterprise (Oracle, MSSQL).
- Файловое (NFS, CIFS, POSIX) – создание файловой системы на основе блочного хранилища, передаются сами файлы. Легкое управление, простая работа с приложениями, простая передача данных между разными сетями. Средняя масштабируемость с рядом ограничений. Сценарии: file sharing, интеграция приложений в Enterprise.
- OBS – Object-based storage (HTTP, REST, S3) или распределенная файловая система (в русской wiki) – при использовании OBS создается слой объектного управления на основе блоковых систем хранения. По сути, OBS – это распределенная файловая система. Почти неограниченное масштабирование за счет использования объектов (уникальный ключ, файл данных, метаданные, пользовательские метаданные) и функции саморегуляции объектов. Использование стандартных Internet протоколов для передачи данных (по аналогии с файловыми системами) позволяет обеспечить простое взаимодействие разных систем между собой. Сценарии: бекапы, архивация данных в Enterprise. Используется контент провайдерами гигантами для хранения неструктуированных данных (фото в facebook, песни Spotify, файлы в Dropbox, Amazon S3, Microsoft Azure). Именно на S3 часто происходит миграция с классических сетевых шар типо NFS (на примере linkmeup сайта).
Object storage systems allow retention of massive amounts of unstructured data. Object storage is used for purposes such as storing photos on Facebook, songs on Spotify, or files in online collaboration services, such as Dropbox.
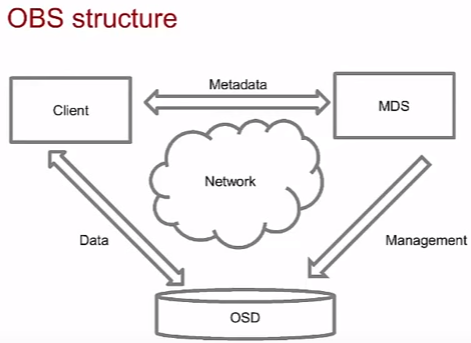
Структура технологии хранения OBS.
- OSD – Object storage device – хранилище данных.
- MDS – MetaData server, по сути name сервер. По имени файла находит OSD и дает ее ссылку Client. Хранит связующую информацию между файлами и OSD.
- Client – обращается к MDS для логического доступа к данным OSD по полученному от MDS адресу.
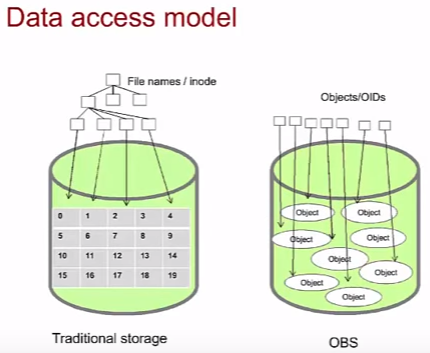
Сравнение доступа к данным в файловой и OBS моделях.
- В файловой системе традиционных систем хранения используется дерево-каталог (иерархическая структура). Если много файлов и файловая структура многоуровневая, нагрузка на корневой каталог высока, что влияет на производительность.
- В случае ODS используется плоская, децентрализованная структура, что хорошо сказывается на производительности при больших объемах данных.
Если свести к одному, то вот основные преимущества OBS:
- Плоская архитектура, позволяющая простой доступ и масштабирование
- Автоматическое управление – OBS может настраивать политики атрибутов (метаданных) на основе потребности со стороны приложений
- Множество пользователей (арендаторов) – при использовании OBS ее могут использовать разные клиенты
- Безопасность и целостность данных на основе текущих технологий

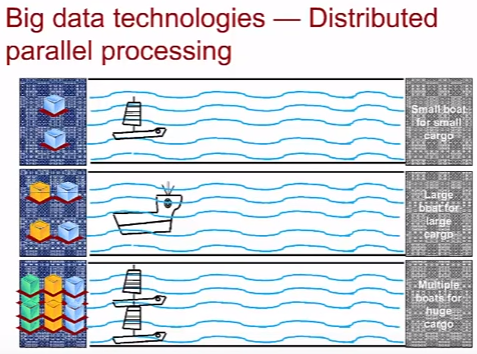
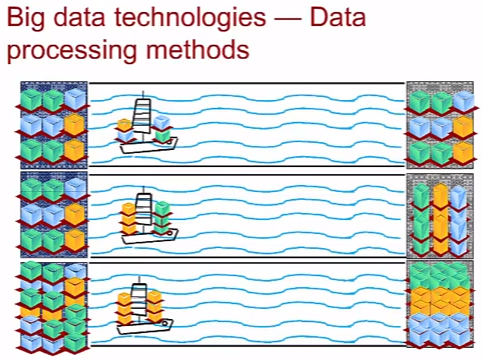
Distributed Parallel Processing
DPP (Distributed Parallel Processing) или MPP (massively parallel processing) – параллельная обработка данных, важный аспект в контексте Big data. К примеру, приходит запрос на чтение объекта в хранилище OBS, MPP используя вычислительные мощности нескольких серверов находит объект в конкретном хранилище. Практической реализацией параллельной обработки является технология MapReduce, используемая в Hadoop (о нем ниже). Причем сам Google от нее уже давно отказался в силу ограничений в масштабировании (ой лол) и проблем в автоматизации внедрения и эксплуатации в пользу Cloud Dataflow.
Количество данных определяет способ хранения и доставки (по картинке – количество грузов определяет грузоподъемность кораблей или использование нескольких). Причем одна большая система (лодка) в какой то момент не справится с растущим объемом данных (грузов) и расширяться не может – поэтому нужно использовать ряд систем вместо одной, но в таком случае появляются вопросы архитектуры по взаимодействию систем (столкновение кораблей), инфрастуктуры (несколько причалов).
Erasure Code
На первый взгляд Erasure Code напоминает защиту технологии посредством использования XOR на RAID массивах. EC используются Huawei в продукте OceanStor 9000 для защиты данных. Большие файлы (более 4ГБ) рубятся на мелкие, части файлов могут быть распределены между разными устройствами OceanStor 9000. Используя EC можно задать настройки уровня избыточности N+M (1/2/3/4).

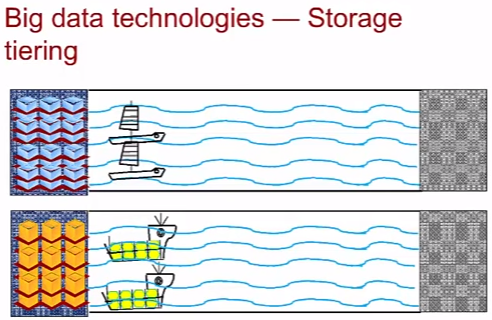
Storage Tiering
Еще одно понятие в Big data – разделение данных по категориям. Какие-то данные целесообразно хранить на SSD т.к. к ним часто обращаются, а какие-то можно положить на HDD или даже в ленточную библиотеку. Практической реализацией гибкого многоуровневого подхода по хранению данных является технология SmartTier, используемая в СХД Huawei на RAID 2.0+.
QoS
Обработка данных должна происходить с тем или иным приоритетом – QoS. Практической реализацией гибкого многоуровневого подхода по хранению данных является технология SmartQoS, используемая в СХД Huawei.
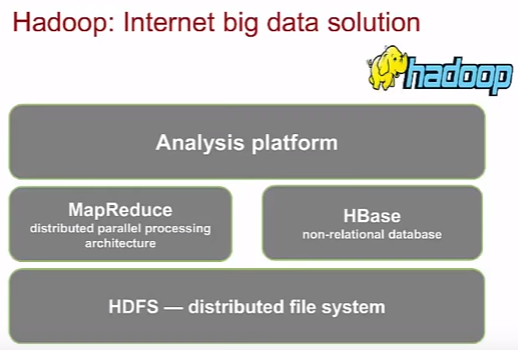
Hadoop
Hadoop – продукт Apache foundation с открытым кодом. Представляет собой набор утилит/библиотек для разработки и выполнения программ, работающих на кластерах из сотен и тысяч узлов. Hadoop широко используется для обработки неструктуированных данных. Появился еще в далеком 2005 году.
Hadoop состоит из (картинка не совсем актуальна):
- HDFS (Hadoop distributed file system) – файловая система для хранения файлов больших размеров в формате OBS
- Hadoop Common – набор библиотек управления файловыми системами
- YARN – сценарии создания инфраструктуры, планирование ресурсов кластеров
- MapReduce (о нем было выше)
Новые базы данных
В вебинаре не сказали о NoSQL/New, но несколько раз сказали о проблемах при работе с большими данными традиционных реляционных баз из-за их слишком сложной архитектуры. Cказал А, говори Б. БД для big data являются NoSQL/NewSQL БД, хотя даже в случае NoSQL не подразумевается во всех реализациях полный отказ от SQL (not only SQL – что-то похожее на SQL NoSQL БД может поддерживать).
Причем для применения в BigData такие базы должны иметь на своем борту технологии параллельной обработки (MapReduce), платформу по аналитике данных и зачастую основываются на распределенной файловой системе (HDFS).
NoSQL
Смотрим англоязычную вики Wiki, есть куча разных типов построения NoSQL баз и по каждому типу есть отдельная статья, выпишу только наиболее популярные типы и примеры:
- Key-value database: Redis, Oracle NoSQL Database, Amazon DynamoDB, DBM
- Document-oriented database & XML database: MongoDB, CouchDB, Elasticsearch, Amazon SimpleDB
- Graph database: ArangoDB, OrientDB, SAP HANA (еще и IN-memory)
- Object database. БД: Amazon Simple Storage Service, ObjectDB, db4o, GemStone
- И еще множество типов, куда подпадает Mnesia на Erlang
NewSQL
Определение из Wiki:
NewSQL (англ. новый SQL) — класс современных реляционных СУБД, стремящихся совместить в себе преимущества NoSQL и транзакционные требования классических баз данных. Потребность в данных системах возникла в первую очередь у компаний, работающих с критическими данными (например, финансового сектора), которым требовались масштабируемые решения, в то время как решения NoSQL не могли предоставить транзакций и не отвечали требованиям надёжности данных.
Самам известным примером NewSQL является SAP HANA – in-memory newSQL DB.
redis кратко
🤔 В чём плюсы redis?
Это открытая база данных в памяти, работающая по принципу ключ-значение. Она широко используется благодаря своим уникальным возможностям и производительности.
🚩Плюсы
➕Высокая производительность
Быстродействие: Redis хранит данные в оперативной памяти, что обеспечивает очень низкую задержку при доступе к данным. Операции чтения и записи могут выполняться за миллисекунды.
Поддержка миллионов запросов в секунду: Благодаря своему дизайну и хранению данных в памяти, Redis может обрабатывать миллионы запросов в секунду на мощном оборудовании.
➕Простая и гибкая модель данных
Простота использования: Redis поддерживает простую модель данных ключ-значение, что делает его легким в освоении и использовании.
Разнообразие типов данных: Помимо стандартных строк, Redis поддерживает такие типы данных, как списки, множества, упорядоченные множества, хеши, битовые карты и гиперлоги, что позволяет решать широкий спектр задач.
➕Функции для сложных сценариев
Публикация/подписка (Pub/Sub): Redis поддерживает механизм публикации/подписки, что позволяет использовать его для создания систем обмена сообщениями в реальном времени.
Транзакции: Redis поддерживает атомарные операции через механизм транзакций, что позволяет группировать несколько команд в одну транзакцию.
Lua-скрипты: Возможность выполнения скриптов на языке Lua непосредственно на сервере позволяет оптимизировать выполнение сложных операций.
➕Поддержка распределённых систем
Репликация: Redis поддерживает асинхронную мастеровую репликацию, что позволяет создавать отказоустойчивые и высокодоступные конфигурации.
Сентинел (Sentinel): Redis Sentinel обеспечивает автоматическое обнаружение сбоев и автоматическое переключение на резервные узлы, что повышает надежность системы.
Кластеризация: Redis Cluster позволяет распределять данные по нескольким узлам, обеспечивая масштабируемость и высокую доступность.
➕Настройка и масштабируемость
Гибкость настройки: Redis предоставляет множество опций для настройки, что позволяет оптимизировать его под конкретные рабочие нагрузки.
Масштабируемость: Возможность горизонтального масштабирования через Redis Cluster делает его подходящим для использования в крупных распределенных системах.
➕Поддержка долговременного хранения данных
Снапшоты и журналы изменений (AOF): Redis поддерживает создание снапшотов (RDB) и журналов изменений (AOF) для обеспечения долговременного хранения данных и восстановления после сбоев.
Персистентность: Эти механизмы позволяют сохранять данные на диск, что обеспечивает долговременное хранение и восстановление данных после перезапуска.
➕Активное сообщество и развитие
Открытый исходный код: Redis является проектом с открытым исходным кодом, что позволяет сообществу активно участвовать в его развитии и улучшении.
Поддержка и документация: Широкая поддержка и обширная документация делают Redis доступным для использования и внедрения в различных проектах.
🚩Примеры использования
🟠Кэширование
Быстрое кэширование данных для ускорения доступа и уменьшения нагрузки на базу данных.
🟠Сеансовое хранилище
Хранение данных сеансов пользователей в веб-приложениях.
🟠Очереди задач
Использование списков и множества для создания очередей задач и обработки фоновых задач.
🟠Системы обмена сообщениями
Реализация систем реального времени для чатов и уведомлений через механизм Pub/Sub.
🟠Аналитика и мониторинг
Хранение и обработка временных рядов данных для аналитики и мониторинга.
Ставь 👍 и забирай 📚 Базу знаний
Вопросы
все вопросы/ответы по теме тут