
Конспект вебинара HonorCup E=DC2 для сдачи HCNA Storage.
Связанные по вебинару посты:
- Резервное копирование
- Резервное копирование, решение huawei
- Восстановление после катастроф (этот пост)
- Дедупликация
Крупные компании типо страховых/банков, гос. учреждения – основные пользователи решений восстановления после катастроф (Disaster Recovery, DR). Под катастрофой подразумеваются природные (наводнения, землетрясения) и техногенные (индустриальные, транспортные) катаклизмы, приводящие к нарушению функционирования или полному уничтожению крупных узлов связи или дата-центров.
Под Disaster Recovery подразумевается не только методы (процессы/процедуры/средства) восстановления после катастрофы, но и меры по обнаружению катастрофы и методы защиты от катастрофы.
A disaster recovery plan shouldn't only have recovery procedures; it should include detection measures so that you can be made aware of an incident, along with preventative measures to help avoid a disaster in the first place.
Непрерывность бизнеса (Business continuity) – процедуры и процессы для гарантии непрерывности работы компании. Применяется к физическим (здание, персонал) и операционным процедурам (рабочие процессы, планирование, человеческие ресурсы).
Компании начали задумываться о Business continuity и Disaster recovery после серьезных катастроф, терминам уже порядка 10 лет. В России тема постепенно развивается, хотя и не так популярна, как на “Западе”.

Основные факторы, способствующие поднятию темы:
- Централизация инфраструтуры привносит серьезные риски потери сервиса и данных
- Потеря сервиса и данных приносят серьезные финансовые (и не только) убытки
- Выходят правительственные постановления по необходимости принятия мер disaster recovery для определенных организаций (в России подобных гос. требований и стандартов пока нет)

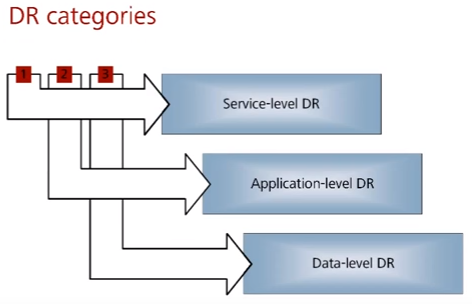
Категории восстановления после катастроф:
- Сервисы – восстановление данных + приложений + всего чего угодно, для полного восстановления сервисов
- Приложения – восстановление данных + приложений
- Данные – восстановление только данных (низкоуровневое)
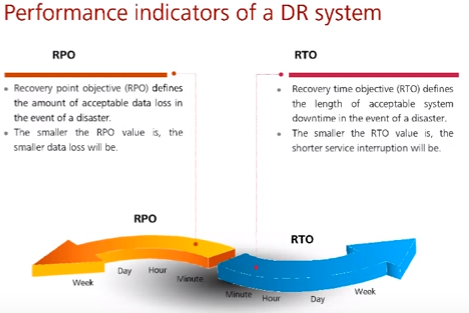
Показатели при восстановлении после катастроф:
- RPO – Recovery point objective – описывает количество данных в часах в прошлом (когда делался последний backup), которое допустимо для потери в случае катастрофы. Чем меньше, тем меньше данных будет потеряно.
- RTO – Recovery time objective – описывает количество времени простоя сервисов, которое допустимо в случае катастрофы. Чем меньше, тем меньше времени на восстановление потребуется.
- CTO – Cost of downtime – сколько времени стоит каждый час простоя. Основной показатель, который учитывается при выборе вариантов реализации backup/disaster recovery.
SHARE 78 – отраслевой стандарт инициативной группы в области защиты от катастроф. Там предложена 7-и уровневая градация защиты от катастроф в зависимости от количества потенциального времени восстановления сервисов:
- Tier 1 (более недели): PTAM – Pickap track access method – по сути на авто снимаем резервную копию и уезжаем в третьем месте для восстановления (нам нужно арендовать датацентр и доехать до него)
- Tier 2 (дни-недели): PRAM + hot site – на авто снимаем резервную копию и везем в резервный датацентр (нам нужно только доехать до резервного датацентра)
- Tier 3 (до суток): electronic vaulting – какая то часть очень критичных данных периодически реплицируется на резервный датацентр/ЦОД
- Tier 4 (до 12 часов): active secondary site – в резервном датацентре есть все необходимые данные для восстановления из-за асинхронной репликации
- Tier 5 (до 4 часов): two-site, two-phase commit (transaction integrity) – синхронизация датацентров на уровне транзакций
- Tier 6 (до часа): zero or little data loss – минимальные потери
- Tier 7 (до 15 мин): highly automated, business-integrated solution – автоматизированное решение по восстановлению (напр. при потери связи между ДЦ происходит включение резервных VM)

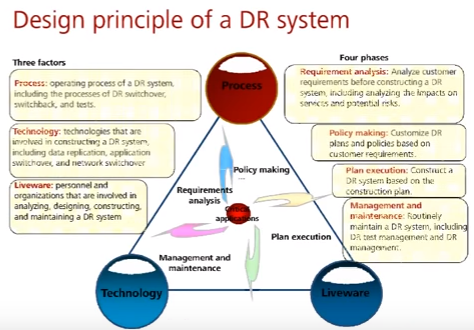
Принципы, на которые нужно полагаться при создании системы восстановления после катастроф.
Есть три важных фактора, которые нужно учитывать:
- Процессы (process) (не только IT, но и организационные) – процедуры переключения, тестов
- Технологии (technology) – какие технологии будем использовать, ширина канала оператора, наличие дополнительных мощностей
- Персонал (lifeware) – нельзя забывать потенциал утраты сотрудников и их замещения (системные интеграторы вместо текущих отделов по эксплуатации)
И четыре важных фазы создания DR:
- Анализ требований (requirement analysis) – что нужно защищать и как
- Создание политик на основе требований (policy making)
- Реализация решения DR на основе плана (plan execution)
- Управление и поддержка решения DR, включая обучение персонала, проверку процедур и технологий при тестовых отказах (management and maintenance)
По сути, создается непрерывный цикл восстановления после катастроф из определения политики, создания плана, поддержания плана и регулярном анализе требований.
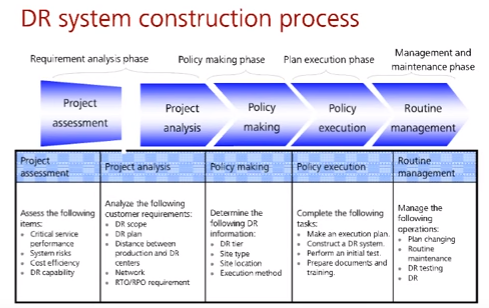
Стадии создания процесса DR
- Проектная группа производит первичную оценку, привлекает экспертов (project assessment)
- Производится детальный анализ (project analysis)
- объектов, которые входят/не входят в процесс восстановления после катастроф
- рисков (risk assessment)
- точек отказа (сети/IT систем, см. SPoF), которые нужно резервировать и на каких элекментах (важный узел сети/сервер)
- потенциальных угроз
- анализ требований RTO/RPO
- Создание политики, описывающей уровень, необходимый для восстановления, тип необходимого резервного сайта и его местоположение (policy making)
- Исполнение политик, создание инструкций/документов для персонала, проведение первичных тестов и обучения персонала (policy execution)
- Поддержание политик в актуальном состоянии и внесение изменений при необходимости. Например, в результате post-mortem (разбор аварии после катастрофы) или во время тестовой катастрофы выявились неучтенные (элементы, процессы, etc), постоянные проверки и тесты (routine management).
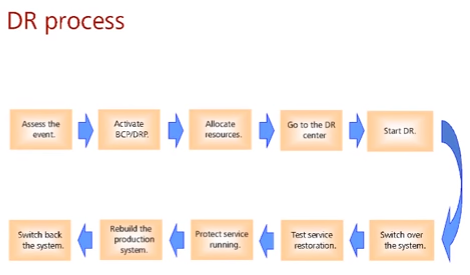
Пример последовательности действий при катастрофе:
- Оценка событий
- Принятие решения по началу процесса восстановления – BCP (business continuity plan) и DRP (disaster recovery plan)
- Выделение необходимых ресурсов, в том числе финансовых
- Работы на резервной площадке
- Старт процесса Disaster recovery
- Переключение систем на резерв
- Проверка сервисов
- Обеспечение защиты данных уже резервной площадки
- Восстановление основной системы (пострадавшей от disaster)
- Переключение обратно на основную систему/ЦОД
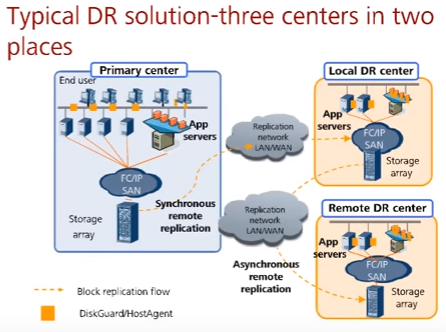
Бывают кейсы, когда используются несколько резервных площадок, например 3 дата центра (3DC). В кейсе ниже есть три дата-центра – основной, резервный рядом (local) с синхронной репликацией и резервный далеко (remote) с асинхронной репликацией.
Post-mortem
- https://github.com/danluu/post-mortems примем огромного количества post mortem
Post-mortem – разбор аварии после катастрофы. Он делается в первую очередь не для поиска виновного и его наказания, а для понимания истинных причин и возможности избежания их в будущем.
A post-mortem is meant to analyze what happened around an incident to identify what went wrong so it can be avoided in the future.
В начале формируется brief summary, который включает инфу о том что за инцидент произошел, какова его длительность и влияния, как был решен.

Далее в timeline описывается конкретно что происходило, какие действия предпринимались (подключение ответственных, действия ответственных) и т.д.

В следующей части post-mortem, Root Cause, описываются причина(ы) аварии.

В последней части описываются методы избежания подобных проблем в будущем. Так же тут могут описываться системы, которые сработали корректно при аварии и какое они влияние смогли избежать, если такие есть (во многом для того чтобы показать что не все так плохо).

Вопросы
все вопросы/ответы по теме тут