
Конспект вебинара HonorCup E=DC2 для сдачи HCNA Storage.
UKSM – пример технологии, использующей дедупликацию для ускорения работы.
Связанные по вебинару посты:
- Резервное копирование
- Резервное копирование, решение huawei
- Восстановление после катастроф
- Дедупликация (этот пост)
Определение из wiki:
Дедупликация (также дедубликация; от лат. deduplicatio — устранение дубликатов) — специализированный метод сжатия массива данных, использующий в качестве алгоритма сжатия исключение дублирующих копий повторяющихся данных.
Отброс дублирующихся данных имеет очень важное значение при хранении данных, в том числе при резервном копировании. Без использования дедупликации и/или сжатия избыточных данных во многих сценариях будет больше в разы, что может потребовать дополнительных инвестиций для хранения.
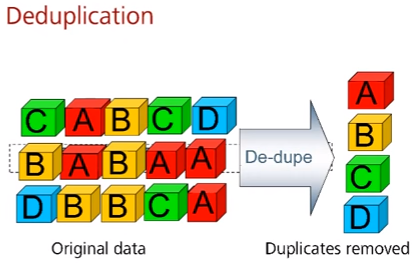
Таблица сравнения сжатия и дедупликации. По факту не знаю, как это можно сравнивать (разве что только в контексте экономии места) – можно же на дедуплицированные данные спокойно запускать еще и алгоритмы сжатия (автор в последующем подтвердил, обозначив что на СХД Huawei такая возможность есть в последовательности дедупликация -> сжатие).
| Операция | Функция | Реализация | Содержимое | Условие |
| Дедупликация | Сохранение пространства | Сравнение блоков данных и сохранение только уникальных | Сохранение только уникальных данных | Нужно сравнение блоков между собой |
| Сжатие | Сохранение пространства | Сжатие на основе алгоритма | Не модифицирует оригинальные данные (если сжатие без потерь) | Софт для компрессии |
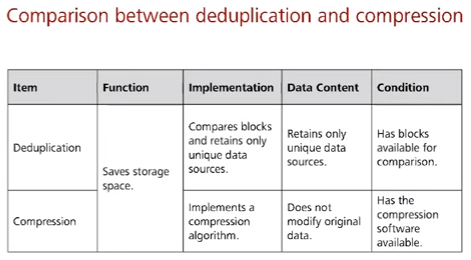
Категории дедупликации
- По месту исполнения (location)
- на источнике (at source end) – сравнение производится на самой системе (напр. ноутбуке) и в результате на сервер хранения передается только одна копия из множества, падает нагрузка на сеть
- на сервере (at target end) – получаем все копии от источника, сравниваем и сохраняем только нужные
- По моменту времени (time)
- пост-дедупликация (post-processing) – записываем данные на диск, затем делаем резервную копию от этих данных, а уже потом делаем дедупликацию (ускорение backup, но требуется больший объем для хранения)
- онлайн-дедупликация (inline) – при получении новых файлов сравниваем файл (а точнее его hash, а при совпадении hash еще и блоков для защиты от коллизии) в оперативной памяти с существующими файлами (а точнее их hash/блоков) на жестких дисках и не записываем на жесткие диски, если такие файлы уже есть (медленный backup, но объема хранения требуется меньше)
- По объекту дедупликации (granularity)
- на уровне файлов (file-level)
- на уровне блоков (block-level)
- на уровне байт (byte-level)
- По масштабу (scope)
- локальная дедупликация (local) – при наличии нескольких серверов дедупликации на каждом своя независимая таблица хешей с которой происходит сравнение хешей
- глобальная дедупликация (global) – при наличии нескольких серверов дедупликации есть еще один сервер, на котором находится единая таблица хешей с которой происходит сравнение (усложнение архитектуры, но меньше дублированных данных)
Показатели технологии дедупликации (key indexes):
- Коэффициент дедупликации (ratio) – отношение между исходными данными и данными после дедупликации. Напрямую влияет на стоимость т.к. чем лучше дедуплицируем, тем меньше денег требуется на покупку устройств хранения.
- Скорость дедупликации (deduplication perfomance) – время, необходимое для дедупликации. Чем меньше времени, тем лучше т.к. может влиять на скорость backup.
- Надежность дедупликации (data reliability) – дедупликация не должна ломать файлы и backup’ы (кто бы подумал).
- Скорость репликации после дедупликации (replication perfomance) – сколько времени будет происходить передача дедуплицированного backup в другой дата центр для защиты от disaster (disaster recovery).
- Скорость восстановления после дедупликации (recovery perfomance) – сколько времени будет происходить восстановление данных из дедуплицированного backup.

дедупликация в btrfs
Существует два основных типа дедупликации:
-
- In-band (онлайн) — когда данные перед записью проверяются на существование дубликатов. Такой метод требует значительных вычислительных ресурсов и памяти.
- Out-of-band (офлайн) — дедупликация происходит после записи и является менее затратной по ресурсам.
Btrfs, в отличие от ZFS, реализует только офлайн-дедупликацию.
Сам Btrfs (обычно пакет btrfs-progs) не имеет встроенных утилит для дедупликации, но предоставляет все необходимые средства для ее реализации сторонними утилитами.
Дедупликация бывает на уровне файлов и на уровне блоков. Чтобы найти и удалить одинаковые файлы, вы, конечно, можете использовать duperemove. Но у него применение довольно специфическое, что делает его практически бесполезным для наших целей, тем более cp в Btrfs не приводит к реальному копированию данных (копии файлов ничего не весят). Строго говоря, Btrfs работает не с файлами, а с блоками данных (экстентами), поэтому и дедупликацию в ней нужно проводить на этом уровне. Для этих целей и существует bees — блочный дедупликатор.
Вопросы
все вопросы/ответы по теме тут