



Конспект вебинара HonorCup E=DC2 для сдачи HCNA Storage.
Связанные по вебинару посты:
- Резервное копирование (этот пост)
- Резервное копирование, решение huawei
- Восстановление после катастроф
- Дедупликация
Разное:
- (Резервное копирование, LVM) Если говорить в целом про snapshot:
- snapshot =! Backup как минимум потому, что
- он обычно хранит только diff от данных от текущего состояния системы и того состояния, которое было при снятии snapshot
- snapshot хранятся на тех же носителях, что и основная система
- snapshot на storage/СХД (EMC/IBM) устройствах
- snapshot используются на всю катушку – есть банки которые все бекапы делают только на них -> напр, каждые 15мин делается snapshot всей базы и их хранятся сотни штук
- разработчики таких устройств поддерживают использование snapshot, но полноценные backup это не snapshot, рекомендуется использовать snapshot + backup
- удобно и правильно комбинировать snapshot и backup – snapshot получаешь консисентное состояние в один момент времени всех элементов системы (к примеру файлов сайта и файлов БД), а backup-ом это состояние уже сохраняешь, при этом нужно учитывать, что иногда при снятии snapshot есть некоторое «подмораживание системы на запись» на некоторое время
- snapshot =! Backup как минимум потому, что
- (Обучение Lpic-2) Делать бекапы очень важно (в том числе на ленте/ленточном хранилище – подробнее про ленты ниже), сценариев потери данных без бекапов миллион и тележка
- почистили память RAID контроллера и весь RAID потерял данные (восстановление с ленты)
- обновили записи в БД и вместо того, чтоб обновление получил один оно привело к апдейту у 700к (спас лог транзакций Oracle)
- (Обучение Lpic-2) Ленты вообще используется очень часто в крупных компаниях, особенно банках (включая зеленый – за разными RAID/СХД “обязана” быть лента, с которой если что можно восстановится ; «3 года должно быть хранение в банках, как без ленты») – ленты позволяют хранить огромные объемы данных дешевле (1 картридж до 50ТБ) и дольше/надежнее, чем на других носителях





- Backup желательно делать с отключенным сервисом, backup которого делается.
- Для backup хорошо подходит ZFS/BTRFS (Linux LPIC преподаватель)
- Массовое использование дисков одной партии нежелательно для защиты от брака партии дисков:
- При добавлении новых дисков в RAID лучше это делать планомерно, не меняя все диски сразу, иначе можно получить резко рухнувший RAID и весь production (опыт чела с обучения LPIC-2)
- Делать backup на дисках той же партии, что и prod системы нежелательно – возможен сценарий отказа в одно время prod и backup (опыт препода LPIC-2)
- При получении дисков новой партии как минимум один стоит проверить на стабильность (сутки делать запись/чтение на него) и по этому диску осуществлять мониторинг жизни всей партии (т.е. есть диск, который проработал больше/записал больше чем другие – он может отказать первым)
- Для VDS стоимость backup или рассчитывается от объема данных или от сервиса, который арендуется
Hetzner We recommend that you power down your server before taking a snapshot to ensure data consistency. Snapshots cost €0.012/GB/month (incl. 20 % VAT).
We recommend that you power down your server before creating a backup to ensure data consistency on the disks. Enabling Backups for your server will cost 20 % of your server plan per month.
- Услуга backup может удалится вместе с удалением сервиса. Звучит сурово.
Бэкапы создаются, пока сервер активен. Когда сервер удаляется, то удаляются и бэкапы.
- В банках используется многоуровневая схема по бекапу – напр. QIWI использует синхронный коммит в два ДЦ и 6 СХД
https://habr.com/ru/companies/qiwi/articles/738968/ История у меня про карточный процессинг. У нас несколько ЦОДов, и база данных под карточным процессингом работает в режиме синхронного коммита, чтобы не потерять данные в случае сбоев. Это значит, что транзакция должна записаться на удаленную площадку, прежде чем она вернет управление обратно в процессинг. Конечно, это не самая идеальная архитектура, потому что за подобное приходится расплачиваться: в случае сетевых задержек у нас появляются простои и тормоза. Это очень неприятно, хотелось бы такие вещи предотвращать оперативно. Как вообще в нашем карточном процессинге работает синхронный коммит? Транзакция приходит в базу, записывается в transaction log, который для надежности у нас записывается на три дисковые полки разных вендоров. Затем он передается по сети в другой ЦОД, процесс там его принимает и записывает на три дисковые полки, и уже потом записывается в резервную базу другим процессом.Получается такая большая цепочка, в которой бывают задержки, приводящие к неприятностям и негативному пользовательскому опыту.
- (home-infrastructure not modified, bash, docker, backup) Сделал новую схему автоматического бекапа текущего сайта weril.me своими скриптами, вместо используемого ранее сервиса hetzner disk backup (с которого мигрировал на firstvds):
- по cron каждый день на самом серваке делается backup данных ключевых контейнеров
- по cron ПК забирает каждый день бекап и сохраняет локально на ПК (отдельная УЗ с аутентификацией только по ключу)
- на локальном ПК храним в течении недели backup за каждый день (по дню недели)
################### # SERVER SETTINGS # ################### ### SCRIPT ### root@weril:~# cat bin/backup_script.sh #!/usr/bin/bash # Created by Petr V. Redkin rm /root/latest.* rm /root/backup.* rm /home/backup/backup.* echo "`date "+%F %T"`: SCRIPT STARTED" > /root/backup.log echo "`date "+%F %T"`: WORDPRESS BACKUP" >> /root/backup.log docker exec -it wordpress tar -cf /root/latest.weril.me.tar /var/www/html/ docker cp wordpress:/root/latest.weril.me.tar /root/ docker exec wordpress rm -rf /root/latest.weril.me.tar echo "`date "+%F %T"`: MYSQL BACKUP" >> /root/backup.log docker exec -it mysql mysqldump -u root -p wordpress --password=<PASS> > /root/latest.wordpress.sql echo "`date "+%F %T"`: SSHD BACKUP" >> /root/backup.log tar -cf /root/latest.sshd_config.tar /etc/ssh/sshd_config ls -ltrh /root/ >> /root/backup.log echo "`date "+%F %T"`: BACKUP ARCHIVE" >> /root/backup.log DOW=$(date +%A) # day of week name, alternative date +%u for number tar --remove-files -czf /root/backup.$DOW.tgz /root/latest.* echo "`date "+%F %T"`: SCRIPT FINISHED" >> /root/backup.log mv /root/backup.* /home/backup/ chown backup:backup /home/backup/backup.* ### CRON ### apt install cron apt install nano crontab -e # CONFIG SHELL=/bin/bash PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games HOME=/home/ MAILTO=petr@redkin.net LC_CTYPE=en_US.UTF-8 0 5 * * * /root/bin/backup_script.sh # START service cron start update-rc.d cron defaults ################### # CLIENT SETTINGS # ################### ### SCRIPT ### % cat /Users/weril/backup.sh #!/bin/bash # Created by Petr V. Redkin scp -O -P 555 -i id_rsa_backup backup@weril.me:/home/backup/\* . ### CRON ### % crontab -l 0 19 * * * /Users/rpv/backup.sh
Резервная копия (backup) – дубликат какого то набора данных (файлов, последовательности блоков или байт). Смысл прост – в случае какой-либо проблемы с данными (человеческий фактор, технологический фактор) их можно будет восстановить из копии и в кратчайшие сроки продолжить работу. Отсутствие резервного копирования и проверка копий на работоспособность – первый признак плохой работы “одминов”. Подробнее о технологиях дубликации данных snapshot/replication в СХД Huawei см. в статье.
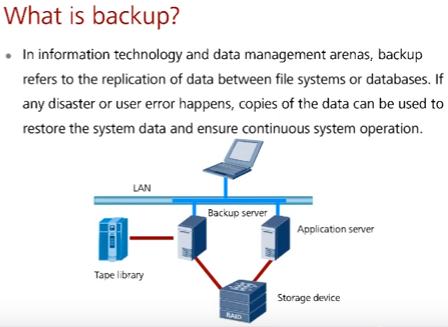
Есть правило: не проверенный backup = отсутствие backup. В контексте backup крайне важно тестирование – множество реальных историй, когда backup делались, но не тестировались. В результате данные терялись. Кроме того процедура восстановления должна быть задокументирована.
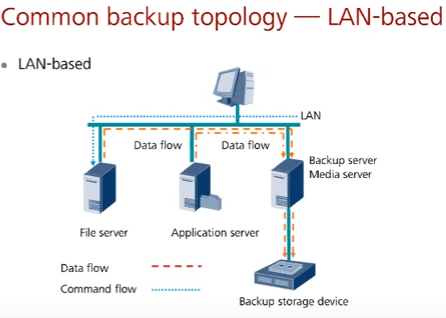
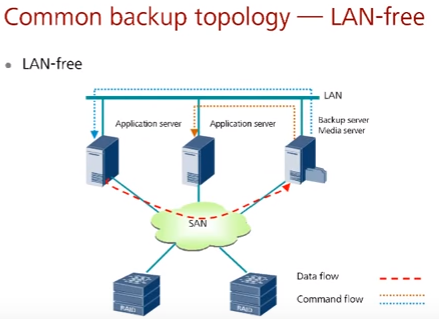
Две основных топологии (по сути, два основных подхода к подключению устройств хранения):
- LAN–based – через ту же сеть, через которую передаются стандартные данные, проходят данные Backup. Недостаток в повышенной нагрузке сети (каналов, оборудования) при резервировании, но обеспечивается экономия средств.
- LAN–free – используется специальная сеть хранения SAN, в случае если нагрузка на LAN сеть является неприемлемой и есть деньги для построения отдельной сети.
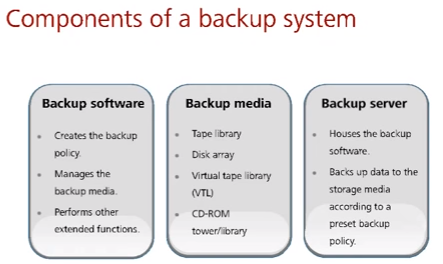
Компоненты резервного копирования:
- Софт – создает копии, указывает политики копирования, управляет носителем копий, удаляет устаревшие копии и проч. Много производителей на любые ОС, есть в том числе гетерогенные (делающие копии в разных ОС).
- Носители копий – ленточные библиотеки (могут быть виртуальные в виде дисковой полки + спец. сервер который представляет дисковую полку как ленточную библиотеку для совместимости со старым backup софтом, подробнее тут), дисковые, CD/DVD-ROM.
У ленточных проблема только с медленной первичной скоростью, они способны обеспечивать очень хорошую скорость приема/передачи (до сотен мегабайт! в секунду). Но из-за того, что в законе Яровой регламентирована скорость доступа к данным - ленточные библиотеки не подходят для реализации закона.
- Сервер – ключевое звено, на нем находится софт по копированию и он копирует данные на носитель (подключенный к серверу/СХД) в соответствии политикой софта.
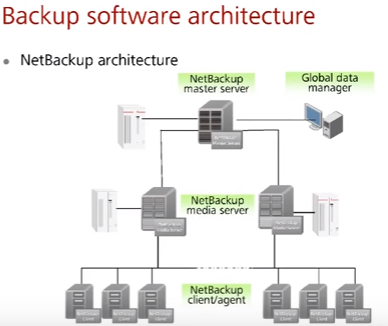
Резервное копирование бывает ручное (через файл менеджер или утилиты) или автоматизированное (например, Symantec NetBackup). Чаще всего происходит автоматизация backup. Из чего состоят автоматизированные системы backup, типа NetBackup:
- Client/Agent – устанавливается на сервера/рабочие станции, получает команды от серверов backup
- Media Server – сервер (или несколько серверов, могут быть разнесены) в настроенный момент времени отсылает агенту команду на передачу запрошенных данных от агента на накопитель сервера (может быть даже ленточным) или СХД
- Master Server – управляет заданиями для Media Server и удалениями устаревших резервных копий
- Data Manager – администратор резервного копирования, настраивает Master Server, проверяет корректность работы системы (наличие и корректность копий)
Backup-ы различаются на local (on-site) и off-site
Local backup имеют преймущество в том, что создание и восстановление backup происходит быстрее, не требуется шифрование данных. off-site backup имеют преймущество в том, что они надежнее. Обычно делаются оба типа backup – из-за скорости первые и из-за надежности вторые.
A combination of on- and off-site backups is optimal recommended backup storage strategy.
Microsoft вообще не рекомендует делать backup на тот же жесткий диск, но я бы не был так категоричен, если это не единственное место.
Do not back up files to the same hard disk.

Off-site backup могут делаться как на твоих IT-системах (собственный СХД в том же или другом ДЦ), так и в облачных. Причем для большой надежности может быть и так и так – у каждого подхода свои плюсы и минусы.
Существует классификация резервного копирования на основе того, с какого на какой off-site носитель происходит резервное копирование данных.
- D2D
- D2T
- D2VTL
- D2D2T
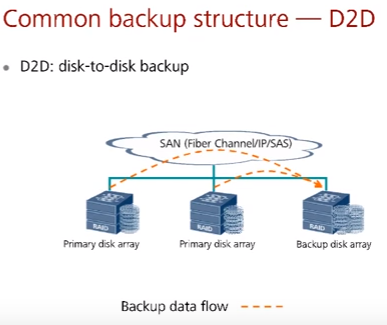
D2D – Disk to Disk backup – данные с production дисковых массивов переносятся на backup дисковые массивы
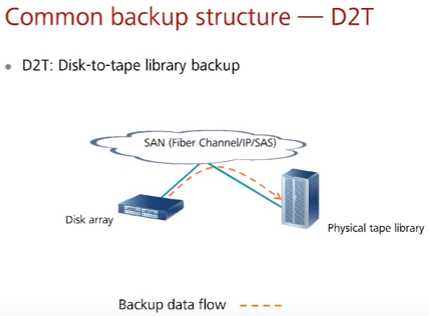
D2T – Disk to Tape backup – данные с production дисковых массивов переносятся на backup ленточные библиотеки
D2VTL – Disk to Virtual Tape backup – данные с production дисковых массивов переносятся на backup дисковые массивы, которые выглядят как ленточные библиотеки (подробнее тут)
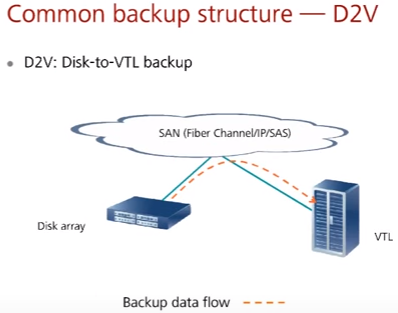
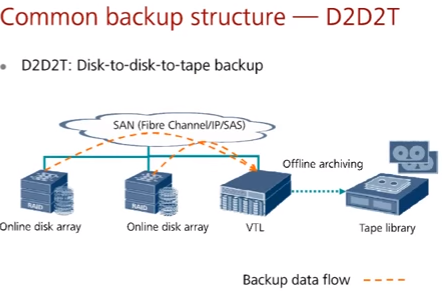
D2D2T – Disk to Disk to Tape backup – данные с production дисковых массивов переносятся на промежуточные скоростные backup дисковые массивы (которые выглядят как ленточные библиотеки), а потом на реальные медленные ленточные библиотеки. Применяется при недостаточной скорости ленточных библиотек и/или необходимости быстрого резервного копирования и/или восстановления (пример работы в схеме см. тут)
Политика резервного копирования должна быть письменной (во избежание конфликтов), что она обычно включает в себя:
- Типы данных (data type) – файлы, ОС, БД, логи
- Тип хранилища (backup media) – диски, ленты
- Тип бекапа (backup type) – полный, дифференциальный, инкрементальный
- Время хранения (data retention period) – неделя/месяц/год/etc
- Периодичность backup (backup period) – каждый день/неделю/месяц/etc, определяется из потребностей
- Окно backup (backup window) – период осуществления backup

Типы данных – что backup’им (файлы ОС, базы данных, логи), а что нет (картинки, видео) или делаем полный бекап (снимаем образ raw device backup). Проверка типов файлов backup софтом может быть не только по расширению.

Тип хранилища – диски (disk array), ленты (tape library), виртуальные ленточные библиотеки (VTL), CD-ROM библиотеки (CD-ROM tower/library). По стоимости самые дешевые: tape library, далее CD tower/library, потом VTL и самые дорогие disk array.

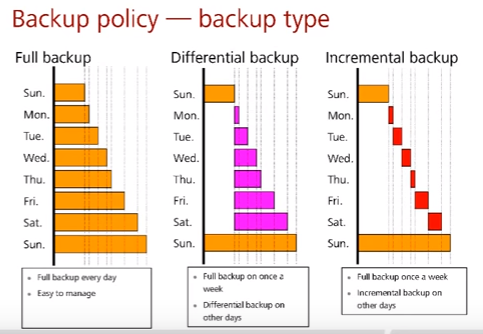
Тип бекапа
- Полный (full) – каждый день мы создаем полные копии всех данных. Простота управления и нет зависимости от backup предыдущих дней, но плохая скорость backup и нужна большая емкость хранения (как минимум в рамках небольшого периода). Плюс: самая быстрая скорость восстановления и нет зависимости от других Backup.
- Дифференциальный (differential) – лишь в первый день мы создаем полную копию данных, затем просто смотрим, что добавилось по сравнению с первым днем и прибавляем эти данные к backup. Есть зависимость от backup в первый день – если он поврежден, то все последующие будут так же испорчены, но лучшая чем в 1 случае скорость создания и нужна меньшая емкость.
- Инкрементальный (incremental) – лишь в первый день мы создаем полную копию данных, затем просто смотрим, что добавилось по сравнению с предыдущим днем и прибавляем эти данные к backup (или смотрим, что изменилось за сегодня). Есть зависимость от backup в первый день и потенциально других дней (в зависимости от алгоритма, см. выше), но самое меньшее время backup и наименьшая необходимая емкость. По подобной модели работает Apple Time Machine и могут работать Microsoft Backup and Restore (опционально) и rsync.
По истечению определенного срока (в примере недели) при использовании любого из типов промежуточные бекапы или инкременты (пн-сб) могут удаляться, если задать это политикой.
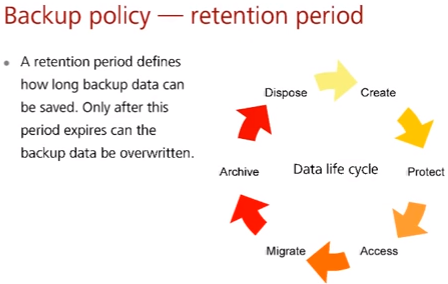
Время хранения – как долго нужно хранить данные. На слайде так же нарисован жизненный цикл данных: создание, защита (RAID), обеспечение доступа, миграция (на носители для долговременного хранения), архивация данных (в том числе сохранение физ. носителей), удаление или перезапись данных (автоматизировано или вручную).
Окно backup – время, в которое происходит резервное копирование. Выбирается наименее нагруженные периоды для уменьшения вероятности деградации сети/других выч. ресурсов при копировании и минимальной вероятности блокировок файлов из-за их текущего использования.

Вопросы
все вопросы/ответы по теме тут