
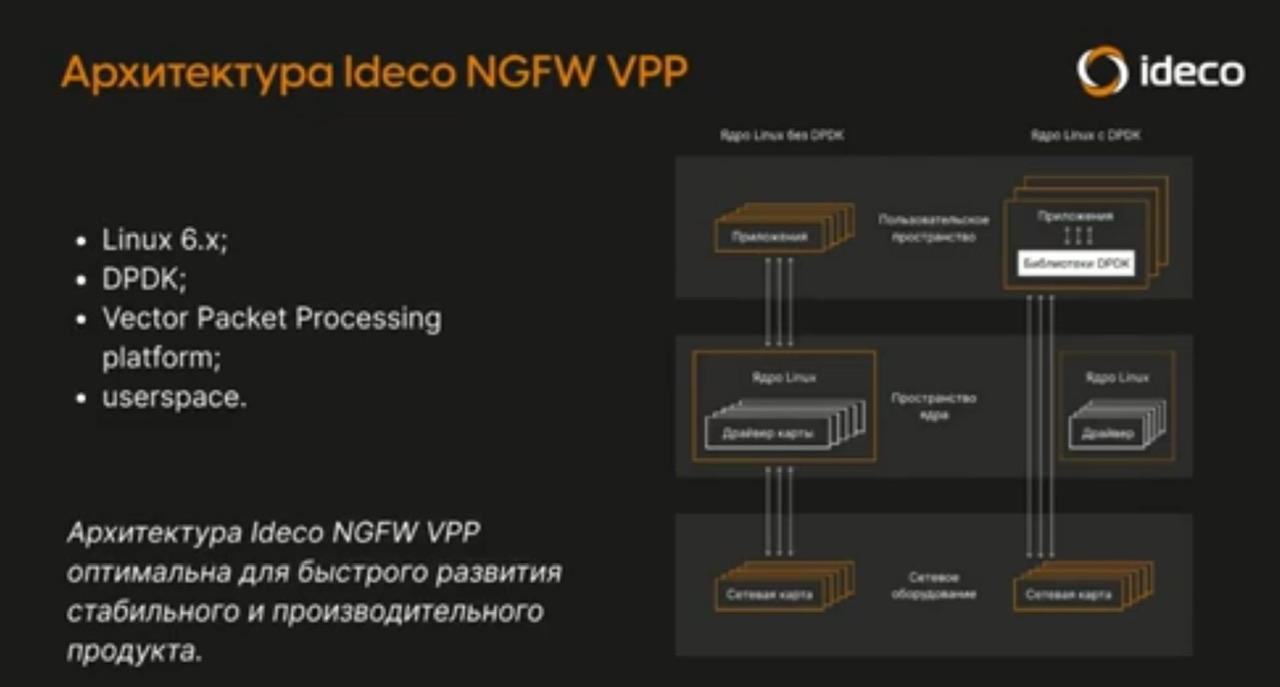
- Хорошие таблицы, взяты отсюда https://habr.com/ru/companies/garda/articles/985596/

| Производитель | Модель | Скорость | Ключевые особенности | Применение |
| NVIDIA | BlueField-3
DPU |
400 Gbps | 16x ARM Cortex-A78,
аппаратный eBPF |
Cloud security, Zero-Trust |
| Intel | IPU E2000 | 200 Gbps | Интеграция с Open vSwitch, поддержка QAT | Виртуализация,
SDN |
| AMD/Xilinx | Alveo SN1000 | 100 Gbps | FPGA + ARM-ядра,
анализ TLS/SSL |
Финансовый мониторинг |
| Marvell | OCTEON 10
DPU |
100 Gbps | 8x ARM Neoverse N2,
аппаратный DPI |
Телеком (5G UPF) |
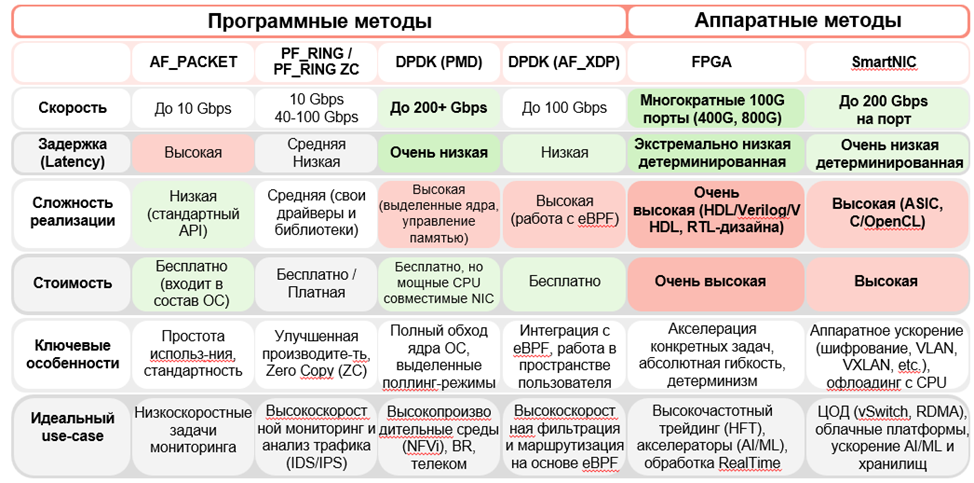
| Программные методы | Аппаратные методы | |||||
| AF_PACKET | PF_RING /
PF_RING ZC |
DPDK (PMD) | DPDK (AF_XDP) | FPGA | SmartNIC | |
| Скорость | До 10 Gbps | 10 Gbps
40-100 Gbps |
До 200+ Gbps | До 100 Gbps | Многократные 100G порты (400G, 800G) | До 200 Gbps
на порт |
| Задержка
(Latency) |
Высокая | Средняя
Низкая |
Очень низкая | Низкая | Экстремально низкая детерминированная | Очень низкая детерминированная |
| Сложность реализации | Низкая (стандартный
API) |
Средняя (свои драйверы и библиотеки) | Высокая (выделенные ядра, управление памятью) | Высокая
(работа с еВРЕ) |
Очень
высокая (HDL/Verilog/V HDL, RTL-дизайна) |
Высокая (ASIC,
C/OpenCL) |
| Стоимость | Бесплатно (входит в состав ОС) | Бесплатно /
Платная |
Бесплатно, но мощные CPU
совместимые NIC |
Бесплатно | Очень высокая | Высокая |
| Ключевые особенности | Простота использ-ниЯ, стандартность | Улучшенная производите-ть.
Zero Copy (ZC) |
Полный обход ядра ОС, выделенные поллинг-режимы | Интеграция с eBPF, работа в пространстве пользователя | Акселерация конкретных задач, абсолютная гибкость, детерминизм | Аппаратное ускорение (шифрование, VLAN,
VXLAN, etc.), офлоадинг с CPU |
| Идеальный
use-case |
Низкоскоростные задачи мониторинга | Высокоскорост
анализ трафика (IDS/IPS) |
Высокопроизво
ной мониторинг и дительные среды (NFVi), BR, телеком |
Высокоскорост ная фильтрация и маршрутизация на основе eBPF | Высокочастотный трейдинг (HFT), акселераторы (AI/ML), обработка Realllime | ЦОД (vSwitch, RDMA),
облачные платформы, ускорение AI/ML и хранилищ |
-
вот пример как nginx гонять поверх стека на VPP https://wiki.fd.io/view/VPP/HostStack/LDP/nginx
с точки зрения техники там производится ldpreload модуля, который подменяет необходимые сисколлы на свое ((аналогично встраивается и openonload))
- Сравнение Netmap DNA и PFRING. Довольно подробное есть тут.
Even if DNA and netmap have been developed in totally independent ways, they solve the same problem: how to move packets back/forth a network adapter without using too many CPU cycles. And I believe it’s no surprise that the performance of DNA and netmap is basically the same.
hyperscan
Библиотека intel, ускоряющая регулярные выражения, часто используется в IPS и других системах, использующих регулярки. Под капотом компилирует регулярные выражения в конечные автоматы, но делает это умно (в отличии напр. от похожих решений в виде pcre библиотеки, так же реализующец JIT компиляцию) – она не пытается скомпилировать все выражения в один автомат т.к. это может быть очень долгая компиляция и будет затрачено очень много занимает памяти, а разбивает регулярки на несколько автоматов, каждый из которых имеет ограничение по времени компиляции/объему.
XDP
- (xdp, ebpf) Хорошее описание работы eBPF и XDP
- Сам XDP использует eBPF, точнее представляет собой программу eBPF компилируемую в байт-код для последующего помещения в ядро (linkmeup telecom 98)
- (nic, dpdk) У solarflare есть свои проприетарные NIC, использующие свой (открытый) стек openonload реализованный на базе XDP. В том числе эти NIC позволяют реализовать TCP/IP decoding – полный offload по аналогии с fpga на базе NIC solarflare/mellanox (openonload/openoffload), когда после аппаратной обработки собирается/извлекается и передается payload дальше на обработку. У mellanox это называется openoffload.
openonload - по сути один заменяет связку dpdk + стек (f-stack / tldk / etc).
Оно сильно гибче dpdk и для своих задач сильно лучше/больше подходит
Если просто молотилку без стека - dpdk лучше, понятное дело
Так что вопрос в том, что надо :-)
Сравнение с dpdk:
- юзерспейсная обработка сетевого трафика? Да, похоже, ряд фундаментальных подходов (прямой доступ к устройству, мап памяти колец в юзерспейс, итд) одинаков
- имплементация стека? Нет, дпдк не имеет референсной имплементации стека, и скорее всего никогда не будет иметь по ряду причин
- XDP можно реализовать и базовый роутинг поверх XDP dataplane, но часто он используется именно как очень быстрый фильтр (см. график/описание ниже – 10 mpps фильтрации на одно ядро, iptables в два-пять раза хуже), быстрее может быть потенциально только на базе самой NIC и DPDK. XDP используют cloudflare для защиты от DoS/DDoS и это о многом говорит.
- XDP vs DPDK (linkmeup telecom 98)
- Используя AF_XDP можно приложением из userspace прочитать данные, полученные в XDP – по сути реализуема аналогия DPDK приложений
- По перфомансу в среднем хуже DPDK
- В целом считается сопоставимым по производительности с DPDK, вопросы выбора DPDK зачастую это удобство (PT), готовые/качественные DPDK библиотеки, опыт других и проч
- При этом в отличии от DPDK XDP использует стандартные драйвера NIC в ОС, что в свою очередь выглядит зачастую симпатичнее использования KNI и проч
XDP – еще один «kernel bypass», но по факту он реализует не полный bypass – сама работа XDP не реализует полный байпас ядра Linux, а реализует байпас большого количества операций внутри ядра, по сути получая пакет напрямую из DMA. Pipeline обработки пакетов (XDP, TC, NETFILTER, etc) можно посмотреть тут.
https://blog.tohojo.dk/media/bufferbloat-and-beyond.pdf
As we have seen in the previous subsections, XDP achieves significantly higher performance than the regular Linux networking stack. Even so, for most use cases XDP does not quite match the performance of DPDK. We believe this is primarily because DPDK has incorporated more performance optimisations at the lowest level of the code.
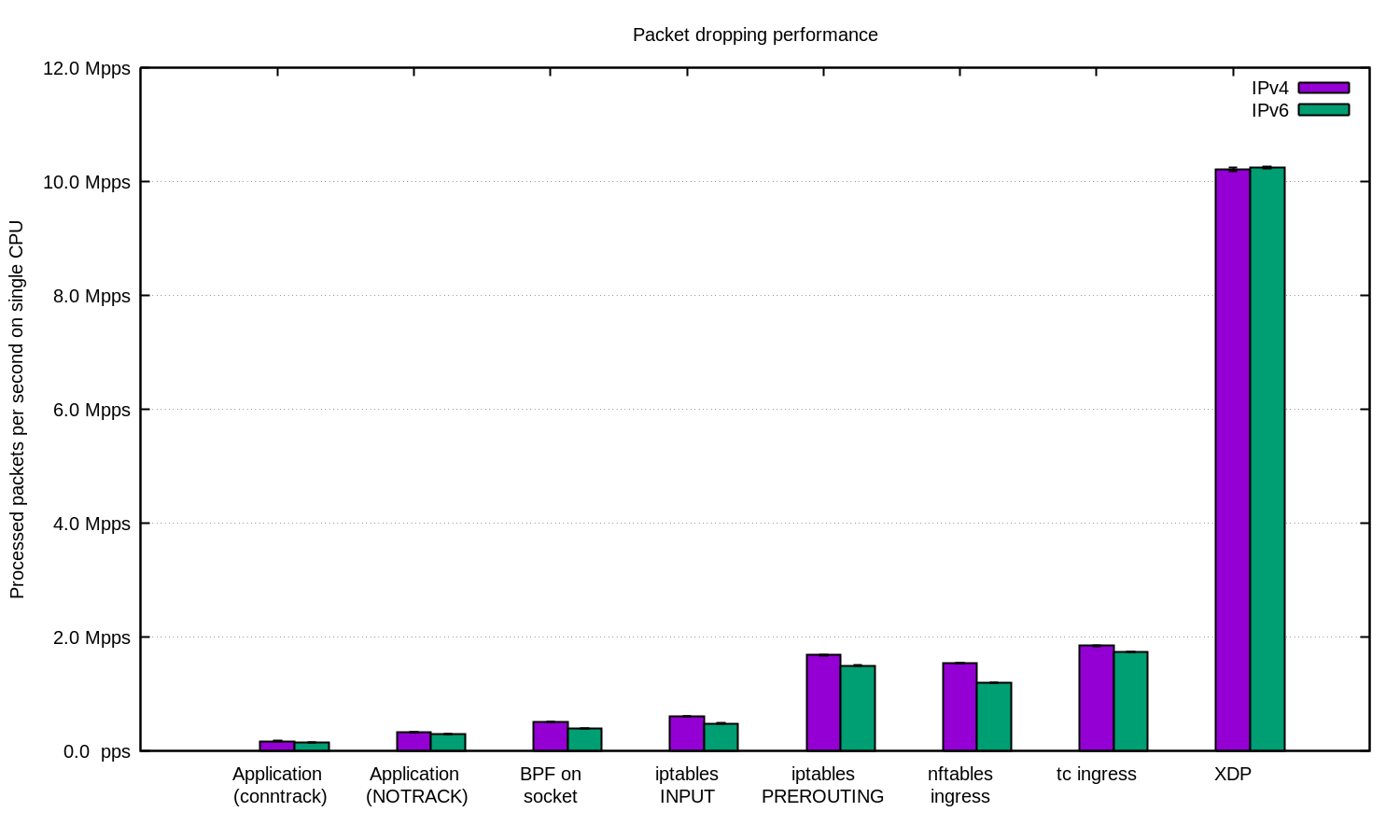
XDP причем более гибкий в сравнении с iptables – там ты можешь написать свою app.
performance
They wrote a filter that filters all UDP traffic (or some UDP traffic? unclear). They tried implementing the rule in iptables and compared it to their custom XDP approach.
iptables: 4.5 million packets/second (у cloudflare хуже результат выше)
XDP: 9.7 million packets/second
performance definitely isn’t the only benefit over iptables though – it’s definitely really important that with XDP you can write arbitrary code.
NETMAP
Появился раньше DPDK и изначально был во FreeBSD. Не использует системные hugepages/superpages, а создает сам себе большую страницу – аналог hugepages. Все сетевые netmap интерфейсы находятся в этой области памяти.
Процесс, использующий NETMAP, даже если делает, что-то неправильно, не имеет возможности сделать крах системы, в отличие от некоторых других систем, например, таких как UIO-IXGBE, PF_RING_DNA. Фактически, область памяти, экспортируемая NETMAP в user space не содержит критических областей, все индексы и размеры пакетных и других буферов легко проверяются на валидность ядром OS перед использованием.
В результате такого подхода, для работы с любой структурой данных, включая пакетные буферы, используется указатель на начало выделенной области и смещение (offset). Такая техника показывает очень высокое быстродействие. Соответственно, superpages netmap не использует, т.к. он сам делает один большой superpage для себя.
PFRING
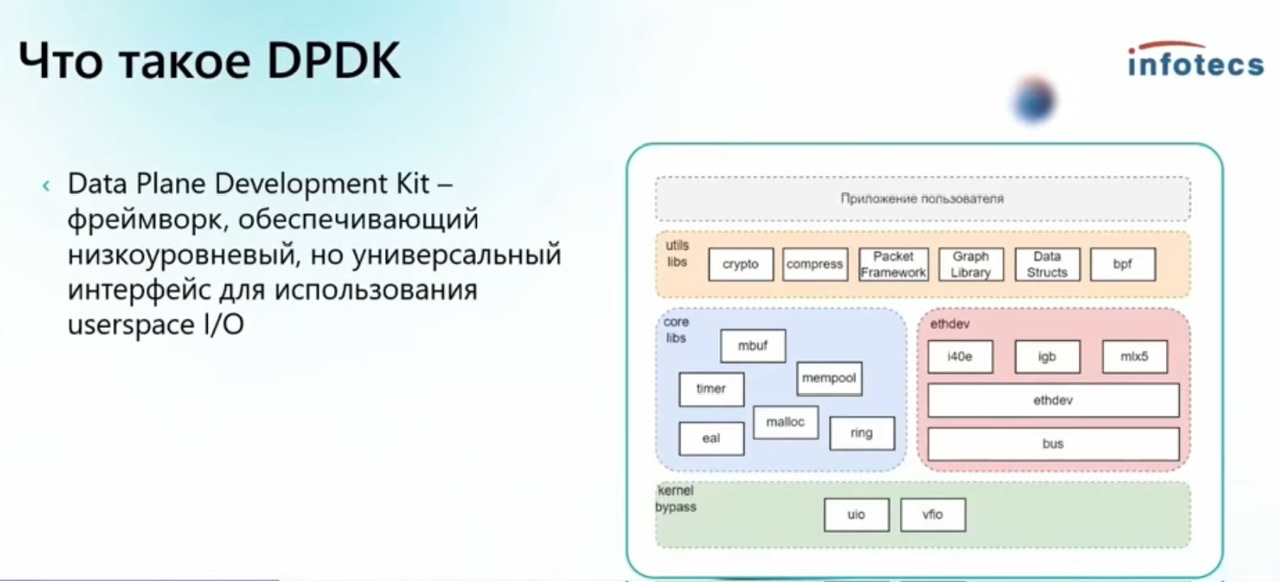
DPDK





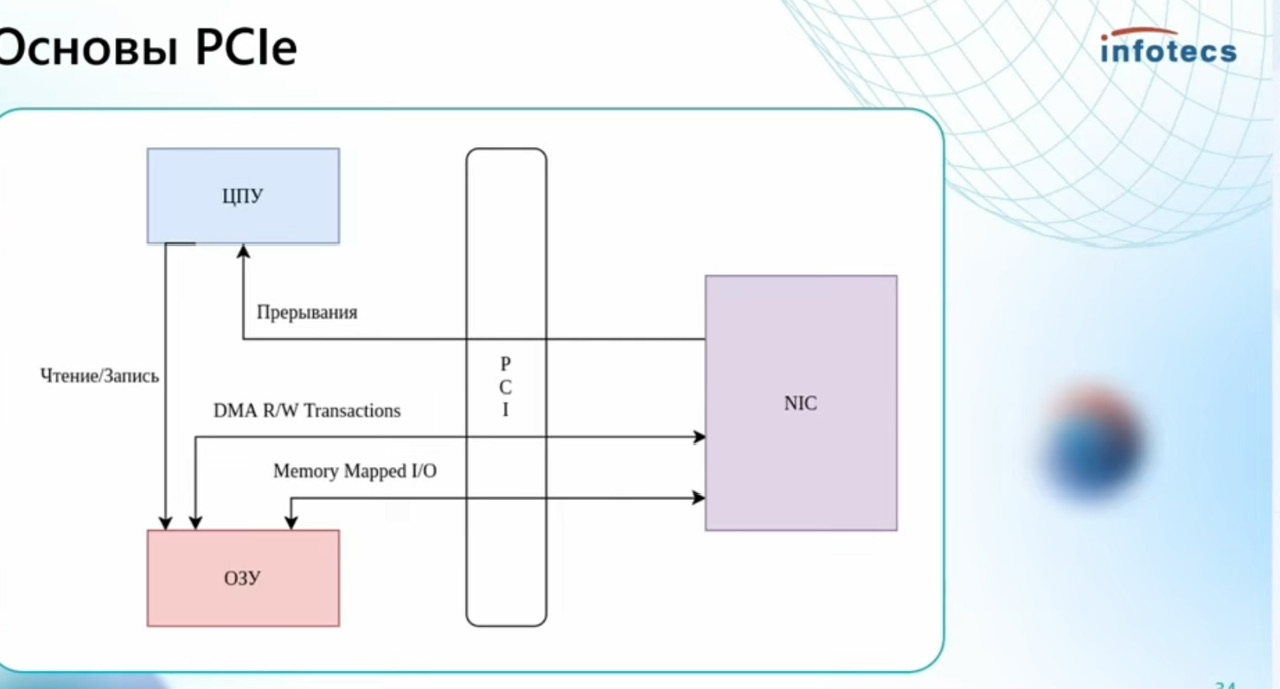
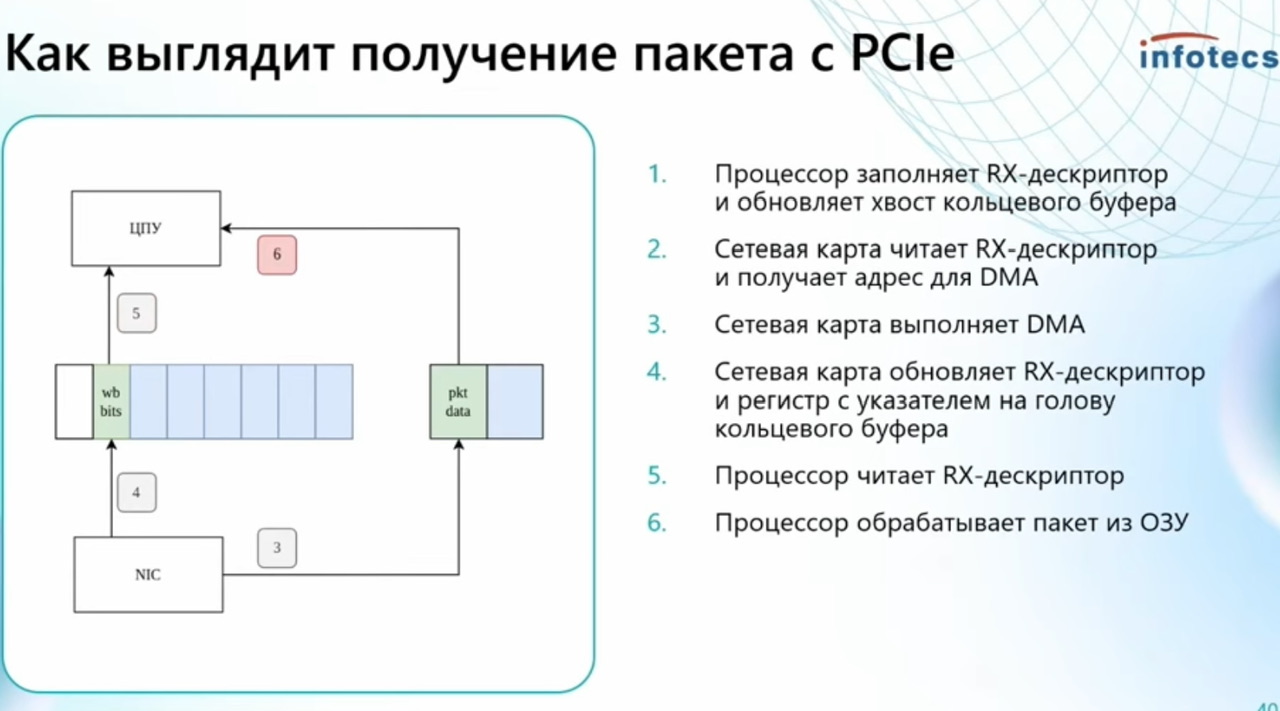

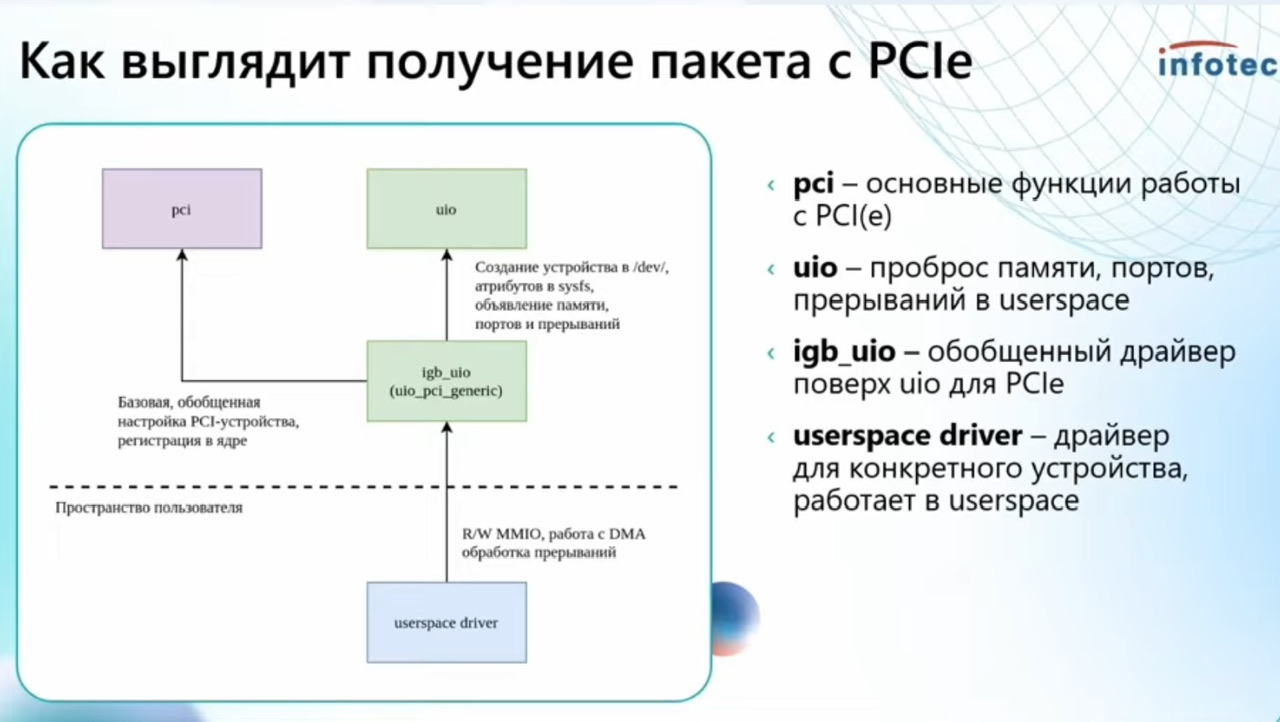



-
(dpdk, bpf) dpdk + bpf
-
rte_bpf позволяет применять к пакетикам eBPF код. Предполагается, видимо, что такие фильтры будут предварительно составляться на С и отдельно транслироваться в ebpf программу, которую потом можно будет применить в DPDK. А вот если хочется применять привычные фильтры, написанные в синтаксисе tcpdump (pcap-filter), то возникает проблема: с одной стороны, их умеет транслировать в cBPF библиотека libpcap. А с другой стороны, dpdk rte_bpf не умеет загружать cBPF. Кажется, что глобально вариантов ровно 2: 1) как-то транслировать прямо pcap-filter -> eBPF 2) транслировать cBPF -> eBPF . Было бы интересно узнать, если кто-то решал такую задачу.
-
Есть более простой вариант. В main есть функция rte_bpf_convert(). Она принимает c BPF опкеды, которые из тестового фильтра можно получить через libpcap. Будет работать и jit: Имеем опкоды cBPF. Получаем опкоды EBPF через rte_bpf_convert(). Отдаем их в rte_bpf_load(), получаем struct rte_bpf* с JIT.
-
- (dpdk, vpp) VPP не обязательно использует DPDK, у него есть свои native драйвера, с которыми он даже работает лучше, но в основном все используют с DPDK (и яндекс, но поглядывают на native; linkmeup telecom 98)
- vpp больше фреймворк
- dpdk больше набор библиотек, причем некоторые функции dpdk поддерживают векторизацию
- igb_uio драйвер может быть заменен стандартным механизмом vf_io, который позволяет любое pci устройство безопасно читать в userspace и последние версии это используют (linkmeup telecom 98)
- dpdk и quic реализованы в userspace потенциально т.к. Intel/google не хотели договариваться с ядерщиками Linux
Фреймворк/набор библиотек Intel, написан на достаточно кондовом C (linkmeup telecom 98) и этого кода много, предоставляет hook’и с помощью которых можно приложение встроить в фреймворк, приложения обычно так же пишутся на C. В контексте своей задачи считается «state of the art”, при том что конкурентов было много, даже в VPP была и есть своя аналогия (с native драйверами, которые позволяют работать еще быстрее). Для общего представления того, как он работает есть проект на базе python ixi.py (?) в котором на базе python реализованы базовые вещи DPDK – отвязка от драйвера системы, polling, Что это (выдержка из группы DPDK).
ну это библиотека от интела которая позволяет зохавать сетевую карту в юзерспейс и её оттуда дрочить, в теории получая большую производительность и больший геморрой (с)
Спорное утверждение
Intel DPDK гораздо перспективнее любой реализации хаков (netmap, pf_ring) минуя TCP/IP стек. Так как оптимизирован под конкретное железо.
На основе DPDK делаются
ANS – Accelerated Network Stack
BESS – Berkeley Extensible Software Switch
Butterfly – Connects Virtual Machines
DPVS – Layer-4 load balancer
FD.io/VPP – Fast Data Project
FastClick – Highspeed dataplane
Lagopus – software OpenFlow 1.3 switch
MoonGen – Packet generator
mTCP – User-level TCP Stack
OPNFV – Open Platform for NFV
OpenDataPlane
Open vSwitch – Multilayer Open Virtual Switch
Packet-journey – Userland router
Pktgen-dpdk – Packet generator
PcapPlusPlus – C++ packet parsing framework
Ruru – Real-time TCP latency monitoring
Seastar – open-source C++ framework
SPDK – Storage Performance Development Kit
TRex – Stateful Traffic Generator
WARP17 – Stateful Traffic Generator
YANFF – NFF-Go -Network Function Framework for GO (former YANFF)
YAStack – DPDK with L7 Envoy Proxy
- секьюрити девайсы
- fortinet Delivers industry’s best threat protection performance with DPDK+vNP offloading and SR-IOV technologies
- Cisco SD-WAN vEdges
- он используется в тестировании:
- pktgen-dpdk
- ixia
- spirent. DPDK использует Spirent для ускорения своих продуктов TestCenter.
https://networkbuilders.intel.com/ecosystem/spirent
Many of Spirent's products are powered by multi-core Intel® processors, enabling simultaneously scale up on multiple dimensions by assigning separate cores to different functions/protocols. The Intel® Data Plane Development Kit (Intel® DPDK) drivers vastly improve the data-plane performance of Spirent offerings such as TestCenter* and Avalanche.*
- stateless NAT 100gbit Natasha на 64 bytes пакетах
-
the_router роутер/bras/nat на базе dpdk, крутой, но проблема в том, что только один контрибьютор
ПРОФИТ: Производительность и Откуда она
Зачем нужно
-
- Горизонтальный скейлинг невсегда оправдан архитектурно и п поэтому производительность одной коробки как была важной, так и остается – поэтому нужны аппаратные решения (повышение частоты CPU, ASIC, FPGA, SmartNIC) и около-аппаратные (напр. DPDK) решения
- Без DPDK средняя по больнице предельная производительность обработки условным тазиком (сервер на базе FreeBSD) около 1 MPPS на ядро или 9 MPPS на сервер XEON 5x с 8 ядрами

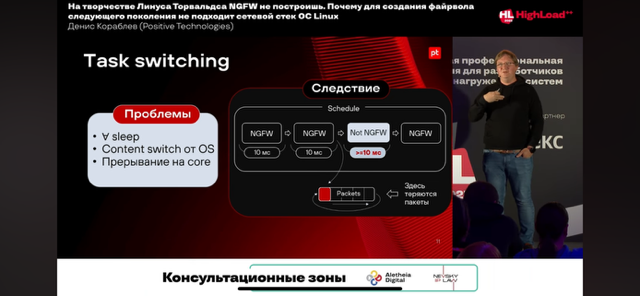
- Минимизация использования ЯППК:
- Ядра (kernel) – прямой доступ приложения к NIC, в обход ядра ОС
- Переключений контекста (context switch) – отсутствие task/context switching
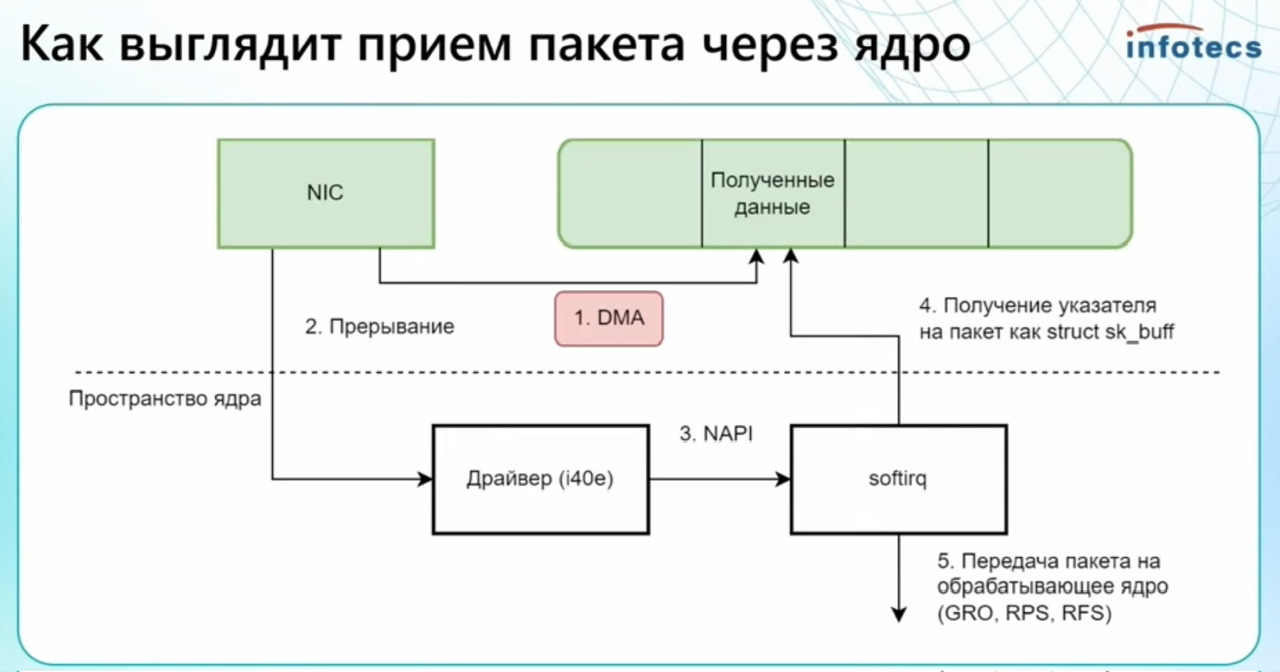
- Прерываний (interrupts) – полное отсутствие прерываний (Poll-Mode Drivers, PMD) – while true пулл (polling) или как минимум interrupt throttling (обработка множества пакетов за один системный вызов). DPDK драйверы работают в режиме опроса (polling) вместо прерываний, что снижает задержки и обеспечивает детерминированную производительность.
In typical packet processing that uses the kernel network stack, the process is interrupt-driven. When the network interface receives incoming packets, there is a kernel interrupt to process the packet and a context switch from the kernel space to the user space. DPDK eliminates context switching and the interrupt-driven method in favor of a user-space implementation that uses poll mode drivers for fast packet processing.
-
- Копий (copy) Zerocopy – существенный прирост и на этом. Это реализовано в DPDK, NETMAP, PFRING. В какой то мере могут помогать сетевые карты (вебинар IDECO VPP). По факту в реальном продукте типо NGFW невозможно (по словам спикера PT; шифрование/дешифрование и часть вещей в обработке/анализе требуют копирование) избавится от копирований полностью, но минимизация в сравнении с ядром, где копирования на каждом шагу – безусловно нужное. Из презентации google о BIG TCP (сама преза по ссылке) – “Copy of the data (memory copy) is the main bottleneck, use zero copy for both send & receive or at least for one side” – в google используют, но еще что-то пилят для полноценной реализации без копирований.
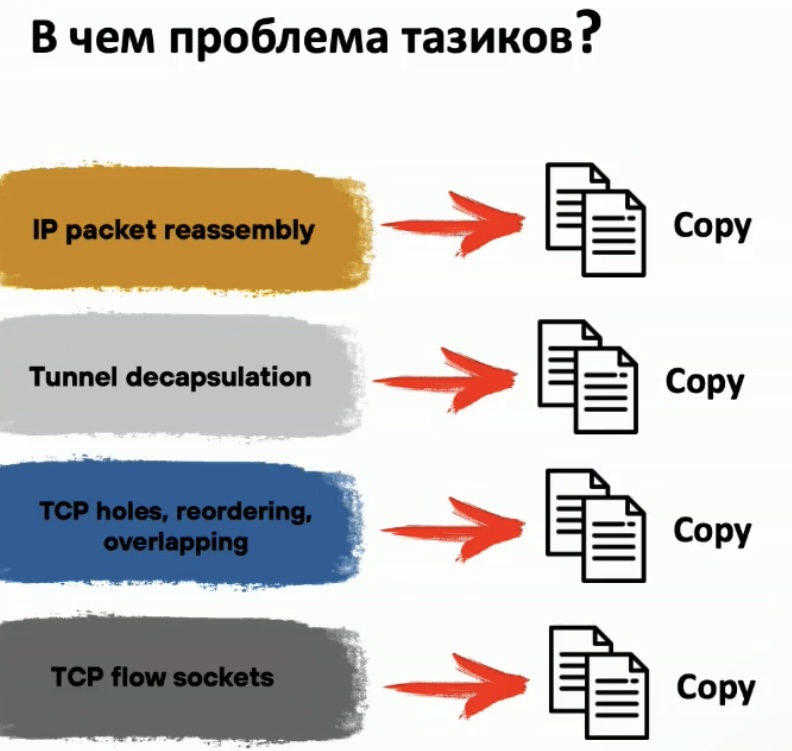

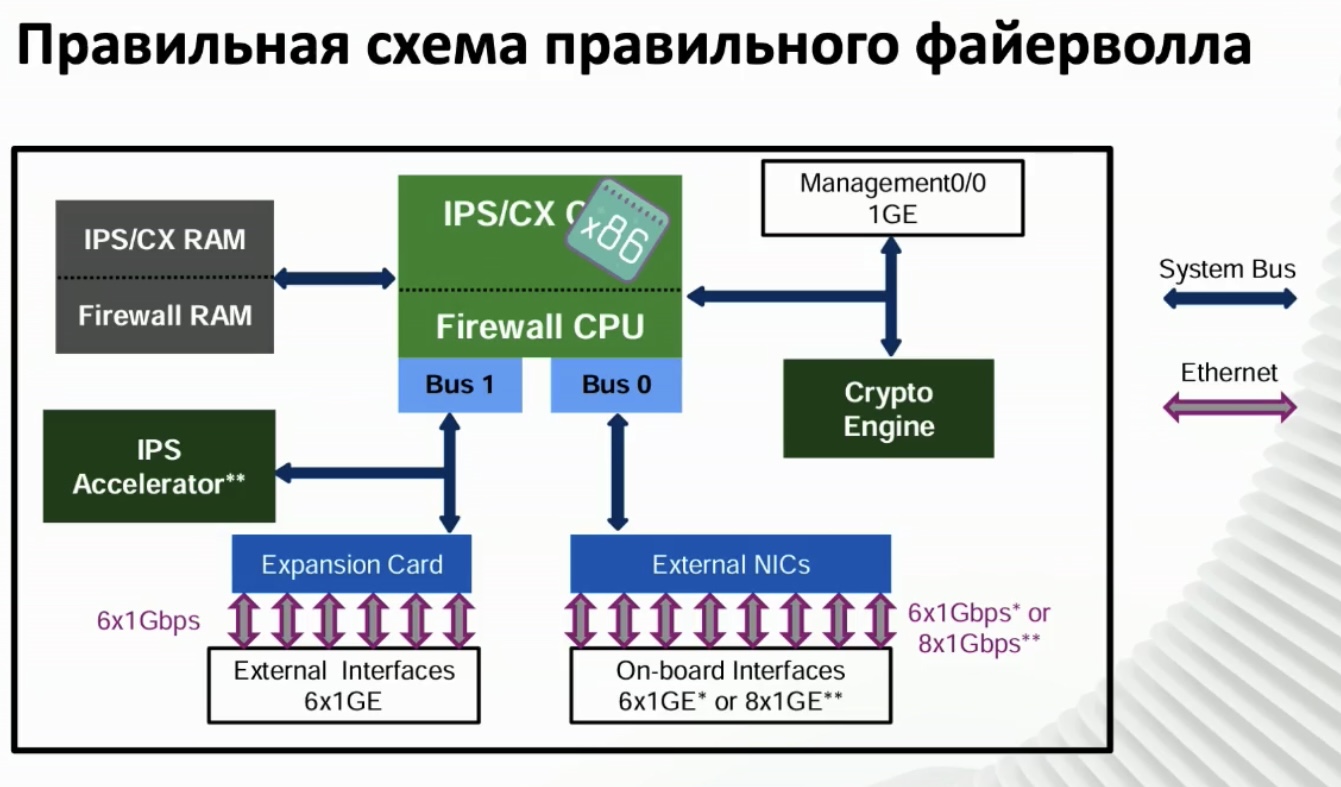
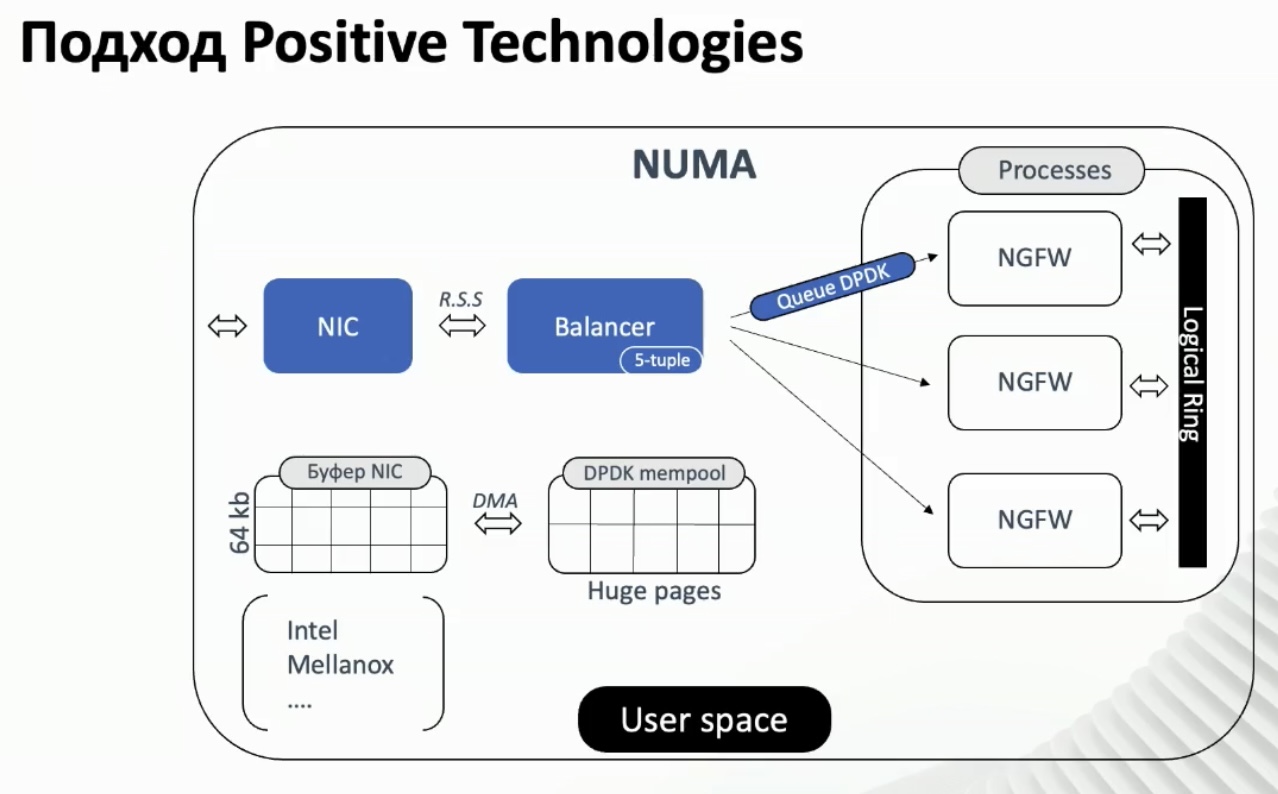
рецепт один — zerocopy all the way и не делать лишних телодвижений там где это не нужно
Наличие всех буферов для всех сетевых карт в одной и той же области разделяемой памяти позволяет осуществлять очень быструю (zero copy) передачу пакетов с одного интерфейса на другой или в host stack.
- Huge Pages/Preallocated память/буферы: Используются огромные страницы памяти (2MB/1GB) для уменьшения TLB-misses и ускорения доступа к пакетным буферам.
-
TLB and Address Translation:
The TLB is a cache within the CPU that stores recent translations of virtual memory addresses to physical memory addresses. When the CPU needs to access a memory location, it first checks the TLB. If the translation is found (TLB hit), access is fast. If not (TLB miss), the system needs to consult the page tables, which is a slower process, leading to performance degradation. Huge Pages Reduce TLB Misses:
With regular 4KB pages, a large amount of memory requires many TLB entries. If an application frequently accesses a large dataset, it can lead to many TLB misses. Huge pages, being larger, reduce the number of pages needed to map the same amount of memory. For example, on x86-64, 2MB and 1GB huge pages are common.
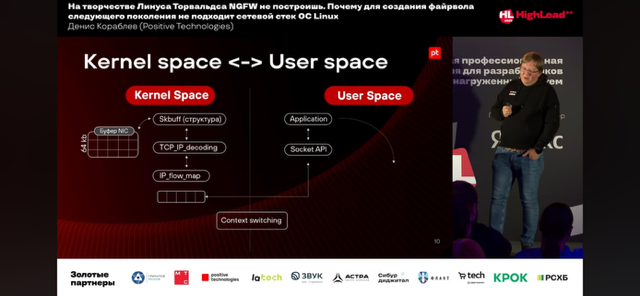
Используя уже эти подходы можно получить значительное ускорение.
КАК РАБОТАЕТ DPDK
При использовании DPDK происходит kernal bypass и невозможно использовать утилиты к трафику – ip route, iptables/nftables, conntrack, etc Для их интеграции КБ поменяло немного код в утилитах и связало утилиты через netlink с DPDK.
Есть исключение – Mellanox карточки по особому работают с DPDK. Они переводятся в режим hybrid и продолжают фиксироваться в системе, несмотря на возможность их использования и для DPDK applications. Вот описание от автора TRex. Mellanox карточки широко используют в Azure.
https://github.com/cisco-system-traffic-generator/trex-core/wiki/Azure-with-netvsc-DPDK-driver-(v2.89)
https://trex-tgn.cisco.com/trex/doc/trex_appendix_mellanox.html
Hi Lior,
Mellanox driver works in a different way than the other DPDK driver, try to read about that.
It is a hybrid mode that only the software queue is there. You should see the kernel driver in case of mlx5.
This is the reason for the dependency hell that requires a specific kernel driver and specific ipv library (OFED version)
Thanks
Hanoh
Mellanox ConnectX-4/5 adapter family supports 100/56/40/25/10 Gb/s Ethernet speeds.
Its DPDK support is a bit different from Intel DPDK support, more information can be found here.
Intel NICs do not require additional kernel drivers (except for igb_uio which is already supported in most distributions).
ConnectX-4 works on top of Infiniband API (verbs) and requires special kernel modules/user space libs.
This means that it is required to install OFED package to be able to work with this NIC.
Installing the full OFED package is the simplest way to make it work (trying to install part of the package can work too but didn’t work for us).
The advantage of this model is that you can control it using standard Linux tools (ethtool and ifconfig will work).
The disadvantage is the OFED dependency.
Distro Installation
OFED Installation
DPDK загружает в ядро свой драйвер PMD (poll mode driver) и на очень низком уровне забирает все пакеты из карточки устройства (не ядра Linux) и отдает вам в user space, тем самым заменяя обработку сетевую Linux ядром.
В DPDK нет прерываний и не нужно балансировать эти прерывания. Сами прерывания это медленный процесс и плохо масштабируемый в какой то момент. DPDK опрашивает сетевую while true – пришло что нибудь? Ядра которые отдал под DPDK поэтому используются под 100% даже если не нагружены. DPDK больше заточен по C, не C++. Если ты хочешь какие-то пакеты передать через ядро – DPDK позволит это сделать (напр. через tap Интерфейс). Поэтому не нужно все приложения переписывать, все что нереализовано можно отдать в ядро (VPN, MPLS, OSPF, etc etc etc). Недостаток – такого трафика много быть не должно (хотя конкретные паттерны типо vpn/mpls можно на входе рано наверно как то выкидывать сразу в ядро), иначе он будет дважды обрабатываться. Кроме того производительность ядра ниже DPDK (из-за чего мы все это начинали) и ядро может загнуться если мы много ему будет отправлять.
КЕЙСЫ
Кейс использования Кода Безопасности – замена netfilter и ядра Linux в пользу DPDK и префиксного дерева. Маркетингово (слайды ниже оттуда) описано тут.
В общем они преобразуют правила ip tables в свои префиксные деревья (ТМ) на dpdk. Я так понял big deal в том, чтобы представить сразу все в виде префиксных деревьев. Говорят, все круто, но перестраивать мы их быстро не можем потому динамик routing’а нет) – там судя по объяснениям от lookup ушли, сразу строят все возможные варианты.
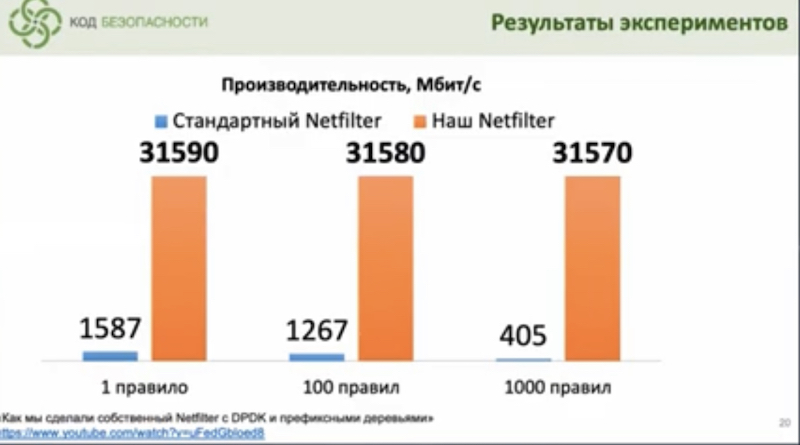
Заменили стандартный netfilter на свой на основе DPDK (производительность выросла в 20 раз) + префиксных деревьев на основе библиотеки DPDK rte_acl. С помощью деревьев сохраняют производительность DPDK, несмотря на рост правил. Для работы DPDK (и как понимаю не только) сделали миграцию с FreeBSD на CentOS.
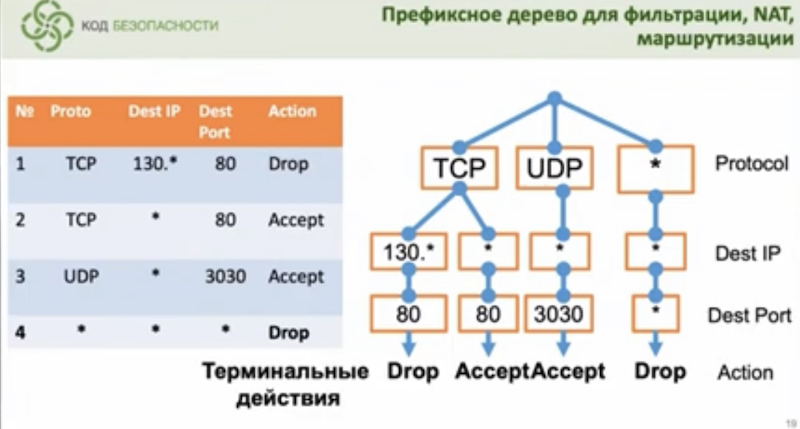
В итоге с ростом количества правил нет деградации по производительности.
kni/virtio/tun-tap interface
Позволяют пользователю управлять интерфейсами в dpdk, как обычными в ядре.
kni интерфейсы на практике используются чаще всего, но они deprecated 🙂
There are other alternatives to KNI, all are available in the upstream Linux:
Virtio_user as Exception Path
Tun|Tap Poll Mode Driver as wrapper to Linux tun/tap
HugePages/superpages (большие страницы)
DPDK приложениям обычно требуется включение hugepages. Большие страницы позволяют реализовать zerocopy – все объекты всех сетевых интерфейсов находятся в одной области разделяемой памяти. Поэтому huge обычно – это порядка гигабайта, хотя и не всегда – можно запустить и использовать DPDK app и с 2MB страницами (это дефолт, например при конфигурации OVS + DPDK).
(подробнее в статье про генераторы трафика)
Интересная ин-ия о performance тестировании DPDK NIC в Intel:
1) используется Ixia, а не генератор DPDK-based
2) конфигурация DPDK с hugepagesz=1G и 2M страницами ((не всегда, чаще только с 1G)), с пометкой, что именно 1G страницы обычно используются для performance test
hugepagesz=1G hugepages=16 hugepagesz=2M hugepages=2048
Generally, 1G huge pages are used for performance test.
Наиболее простое создание больших страниц – указанием в GRUB.
1. Edit /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="default_hugepagesz=1G hugepagesz=1G hugepages=16"
2. Update GRUB
sudo update-grub
3. Mount hugetlbfs
/etc/fstab
none /mnt/huge hugetlbfs pagesize=1G,size=4G 0 0
4. Reboot
reboot
grep -i huge /proc/meminfo
Так же их можно создать временно.
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
mkdir -p /mnt/huge
mount -t hugetlbfs nodev /mnt/huge
Еще одна альтернатива:
For persistent allocation of huge pages, write to hugepages.conf file in /etc/sysctl.d:
$ echo 'vm.nr_hugepages=2048' > /etc/sysctl.d/hugepages.conf
For run-time allocation of huge pages, use thesysctlutility:
$ sysctl -w vm.nr_hugepages=N # where N = No. of 2M huge pages
mount -t hugetlbfs none /dev/hugepages``
Примеры созданных больших страниц:
# одна страница 1GB
# cat /proc/meminfo | grep -i huge
AnonHugePages: 26624 kB
ShmemHugePages: 0 kB
HugePages_Total: 1
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 1048576 kB
Hugetlb: 1048576 kB
# две страницы 1GB
# grep -i huge /proc/meminfo
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
HugePages_Total: 2
HugePages_Free: 1
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 1048576 kB
Hugetlb: 2097152 kB
Смотрим примонтированы ли они:
# mount | grep huge
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,pagesize=1024M)
nodev on /mnt/huge_1GB type hugetlbfs (rw,relatime,pagesize=1024M)
Настройки созданных hugepages находятся тут.
/sys/kernel/mm/hugepages/hugepages-1048576kB/nr_hugepages
kernel parameters
grep huge /proc/cmdline
Snabb
https://github.com/snabbco/snabb
http://highscalability.com/blog/2014/2/13/snabb-switch-skip-the-os-and-get-40-million-requests-per-sec.html
https://www.reddit.com/r/snabb/
https://m.youtube.com/watch?v=v9cfDbdOjnc
https://m.youtube.com/watch?v=C5Sdl2ifpcA
Snabb switch busybox for networking (packetgen, ipv4/6 gateway, virtual switch for vm, high performance stateful firewall snabbwall)
- проект vita – ipsec vpn
- проект packetblaster – load generator на основе pcap для любого cpu
Vita is a high-performance IPsec VPN gateway designed with medium and large network operators in mind. It is written in a high-level language (Lua) and achieves high performance via networking in userspace, i.e. bypassing the kernel network stack.
packetblaster generates load by replaying a pcap format trace file onto any number of Intel 82599 10-Gigabit network interfaces. This is very efficient: only a small % of one core per CPU is required even for hundreds of Gbps of traffic. Because so little CPU resources are required you can run packetblaster on a small server or even directly on a Device Under Test.