



- Про системы конфигурации отдельная статья – CMS
- Про NMS отдельная статья – NMS
- (devnet, CMS annet) Нужно общаться с пользователям очень плотно если вы автоматизируете из работу – собирать требования/фидбеки, реагировать
- Опрос на habr.
Как Вы управляете конфигурацией?
33.61% Ручное редактирование конфигурационных файлов - 40
31.93% GitOps - 38
20.17% Web UI - 24
14.29% другое - 17
Проголосовали 119 пользователей. Воздержались 22 пользователя.
- Местами информация взята из собственного достаточно богатого опыта, местами из статьи habr и подкастов linkmeup
- `Автоматизация позволяет допускать меньше ошибок за счет учета алгоритмами типовых вещей, с другой стороны, если в самой автоматизации будет допущена ошибка, масштаб этой ошибки может быть очень глобальным (на моей памяти были примеры массовых окирпичиваний :)) – поэтому скорость деплоя зачастую не так важна при работе с сетевыми устройствами (в том числе поэтому от использования cli интерфейса для автоматизации не слишком страдают) и администраторы кучу раз перестраховываются перед массовым деплоем в прод, в том числе разнося изменения по времени.
- (дублируется в мониторинге и автоматизации сети) Автоматизация зачастую затрагивает интеграцию множества систем между собой. К примеру, на современные мониторинг системы зачастую ложится задача помимо самого мониторинга/оповещения/заведения инцидентов интеграция с системами провишенинга – напр. для реализаций сценариев по событию мониторинга:
- запускается некая healing логика (напр. деплой с нуля нового компонента/виртуальной машины вместо упавшего, поднятие бекапа)
- собирается доп.информация в инциденты
- проч автоматизированные интеграции
- Инструменты, часто используемые для автоматизации в целом и сети в частности: ansible, puppet, gitlab, jenkins, saltstack, chef (подробнее в отдельной статье, там же описаны плюсы python/python + nornir в сравнении с ansible)
- Протоколы и методы так же разные – от cli/snmp, до netconf/restconf (подробнее в отдельной статье)
- Костыль коммиты: если можно заложить скриптовую логику в загрузку конфига – можно сделать коммит без коммитов; загружает конфиг, далее чекает доступность сервисов и если ок применяет, если не ок ребутается в старый
- Билайн, амазон, яндекс, одноклассники, даже гугл – да по сути почти все используют самописные утилиты, в том числе, часть или все операции зачастую там реализуются через CLI интерфейс (зачастую через прослойки типо nornir или почти напрямую через paramiko) и ничего постыдного в этом нет.
- Главное это решение реальных задач, а не перфекционизм. Поэтому Expect/pexpect CLI – это зачастую нормальные/рабочие способы автоматизации! На тех же серверах так и делается зачастую. Можно даже сказать большее – зачастую средства самих вендоров по api под капотом предоставляя другой интерфейс снаружи по факту внутри используют cli 🙂 по сути просто метод доставки конфига/команд.
- ASA поддерживает REST (CRUD).
- У CUCM есть поддержка SOAP.
- Уже миллионы лет есть библиотеки по управлению сетевым оборудованием через CLI.
Для Perl существует модуль Net::Telnet Описание на www.cpan.org Для Python существует библиотека telnetlib Описание на www.python.org Также существуют аналогичные модули для работы с FTP, SSH и другими сетевыми протоколами.
- Программирование крайне важно сейчас для сетевых инженеров, которые поддерживают крупные сети. Используя api + скрипты можно изменять конфигурации максимально масштабируемо на современных устройствах Cisco. Скрипты можно писать на python, go и даже php, perl, javascript, swift. Первым и зачастую единственным языком рекомендуется python. При подключении к rest api очень часто используется связка python + requests library.
- Cisco добавила темы по автоматизации в сертификацию CCNA R&S. И отдельный трек по автоматизации devnet. Конечно во многом они пиарят там свои платформы – Cisco ACI (Application Centric Infrastructure), Cisco NSO (Network Services Orchestrator, на базе tail-f) для реализации сервисов OSS и говорят что кодинг (custom coding) с ними, по сути, не нужен. Но это безусловно в первую очередь касается стандартных кейсов использования поддерживаемых платформой устройств и чаще всего вендор лок в виде Cisco.
Automation and Programmability
Cisco has acquired Tail-f Systems, a leading provider of multi-vendor network service orchestration solutions for traditional and virtualized networks.
- Плагины в IDE поддерживают синтаксис оборудования передачи данных 🙂 Красота.
https://marketplace.visualstudio.com/items?itemName=codeout.vscode-junos
Общее
Автоматизация – замена ручной работы программой на основе алгоритма.
Плюсы
- убрать человеческий ресурс для решения задачи: не делать рутинные операции человеческими руками, иметь возможность развиваться в другие направления и масштабироваться без необходимости увеличения команды
- уменьшить количество ошибок из-за человеческих факторов
- Отсылки к чужим исследованиям gluware (источники надо проверять):
- The #1 cause of network outages is human error * Cisco/McKinsey
- Network misconfigurations cost businesses 9% of revenue ** Titania Research
- 60% of network outages and an even larger number of breaches are due to misconfiguration errors **** IBM
- A recent study by IBM reveals that human error is a leading cause of security breaches, accounting for 95% of incidents.
- Отсылки к чужим исследованиям gluware (источники надо проверять):
Что не автоматизировать

Самое плохое, когда автоматизируется неправильный изначально процесс, надо сначала разобраться/подумать над тем, правильно ли то, что автоматизируется, а только потом тратить ресурсы на автоматизацию. Еще хуже когда она не приносит пользы и делается только для kpi. На счет минусов бездумной автоматизации был доклад на perf conf с описанием кейсов, когда автоматизация использовалась там, где ее делать не надо было.


Автоматизация не является ответом на все задачи:
- в сфере творчества
- задача появляется слишком редко
- ресурсы (человеческие, временные, материальные), которые необходимы для автоматизации задачи и поддержки этой автоматизации (автоматизируемо часто меняется), слишком велики и не сравнимы с преимуществами ее автоматизации
Принимаем решение
С другой стороны, ни один из факторов не является “блокирующим” полностью возможность автоматизации, например, если задача критична и есть большая склонность к ошибкам при ее ручном исполнении.
Для принятия решения что автоматизировать, а что нет, можно использовать:
– расчет суммарного времени затрат без автоматизации (за какой то период времени) на количество времени необходимого для автоматизации. Если время для разработки автоматизации меньше – точно стоит делать.
– принцип Парето (pareto principle) – в нашем контексте 20% твоей работы генерируют 80% твоего результата. Нужно идентифицировать и фокусироваться на автоматизации этих самых важных 20% задач.
Разное
После автоматизации задачи и поломки средства автоматизации могут появится проблемы с тем, что люди забыли как делать задачу, которая была автоматизирована 🙂
Процедура автоматизации обязана логгироваться, быть покрыта rescue и кодами проверки, а в случае если что-то не так – слать алармы.
Почему именно так назван этот принцип? Здесь всё просто. Википедия говорит нам, что Пестици́д (лат. pestis «зараза» + caedo «убивать») – ядовитое вещество, используемое для уничтожения вредителей и различных паразитов. Возьмём пример из жизни. Если использовать один и тот же пестицид на протяжении долгого времени, например, для истребления тараканов, то со временем его эффективность упадёт, так как у этих насекомых выработается устойчивость к одному и тому же препарату.
То же самое относится и к багам и процессу тестирования. Если к какому-либо функционалу применять постоянно повторяющийся набор тестов – то эти проверки в скором времени будут неэффективны в нахождении новых дефектов.
Поэтому тест-кейсы должны постоянно обновляться и видоизменяться. Важно пользоваться такими рекомендациями:
- добавлять новые тесты;
- просматривать и изменять существующие;
- применять разные виды и техники тестирования;
- осуществлять тестирование новыми сотрудниками и др.
В целом посмотреть на продукт под другим углом.
Можно отметить здесь ещё тот факт, что в наибольшей степени парадокс пестицида может проявляться в регрессе и автотестах.
Network: сетевое тестирование. Автоматизация.
This also allows it to fully automate the full test setup for example by integrating TRex scripts with the RobotFramework test that also takes care of the configuration of the device under test and generating reports.
DEVNET: как делать ролбек/узнавать автоматизировано о проблемах после работ
++++ я так и делал чисто своим кодом – выгружал всю нужную инфу перед работами и сравнивал diff после работ. Но без авто ролбеков ((не junos)) и заливку даже минорных изменений делал обычно аккуратно-пачками ((так делают даже в amazon :)) с инкрементом с проверкой перед следующей заливки успешности предыдущей – один свич, 3 свича, 10 свичей… 10000 свичей ++++
Поделитесь, пожалуйста, экспертизой в плане сетевых тестов, не знаю как сделать нормально. Вот есть у меня ансибл деплой который сначала катит дифф конфигурации, а затем после того как я просмотрел дифф и убедился, что там всё ок - прожал кнопку, затем катится боевая конфигурация на свитчи. В момент деплоя боевой конфигураци я хочу понимать, что у меня доступы никуда не теряются, прод стабильно работает и нигде никакие стойки не отвалились. Я качу изменение на свитчи и хочу автоматикой убеждаться, что у нас все хорошо после деплоя и в случае если не хорошо автоматический роллбек делать (благо джуниперы мне дают такую возможность). У нас есть мониторинг и с ним всё ок, тут имеется ввиду импакт на прод в процессе деплоя.
То есть понятно, что я могу открыть дашборд и смотреть в него, но хочу чтобы это делала автоматика и как-то считывала проблему и роллбечила.
У меня будут тесты перед деплоем, типа собрать конфигурацию в контейнерлабе и потестить какой-то базовый функционал, что есть связанность между свитчами там и т.п. Но это никак не защищает меня от каких-то ошибок на проде в момент деплоя.
Какие тесты я могу прикрутить кроме условного чека icmp, tcp до свитчей/серверов?
Имхо я бы посмотрел в сторону подергать системы мониторинга через апишку сохранить в стейт до change, после change сделать то же самое просмотреть diff и если есть отличия то опциально запустить rollback
Если хотите делать через ansible то придется писать Python модуля для ansible для такого функционала, либо что лучше взять pytest с testinfra. Suzieq и batfish выше предлагали - тоже стоит на них посмотреть.
Ответ на вопрос сильно зависит от того, что вы вкладываете в понятие "все хорошо" и еще более зависит от того что вы вкладываете в понятие "нормально".
- доступность определенных узлов из определенного места?
- процент потери пакетов (откуда-куда)?
- jitter/latency ?
- определенные stp cost для определнных портов?
- наличие или отсутствие:
- маршрутов в таблице маршрутиации?
- определенных маков в определенном влане?
список можно продолжить.
Желательно определиться с тем что конкретно вы хотите проверять и какими средствами (везде ли есть доступ и по каким каналам (serial, snmp, ssh, grpc etc)), тогда под ваши запросы можно выбрать инструменты.
Дальше субьективное мнение:
Деплоить конфиг целиком в свичи есть смысл только в случае когда из коробки есть нормальный rollback. Если вам повезло и у вас так, то поздравляю. В таком разе да, можно накатить любую дичь и автоматом откатить обратно если не взлетело. (ну если вам все равно что будет простой конечно).
Во всех остальных случаях есть смысл пользоваться тем что в ansible назывется идемпотентностью и катить каждую технологию в отдельности (т.е. делать конфигурацию чуть более гранулярной). Тогда и площать поражения в случае факапа меньше и можно разделить условно "опасные" и условно "безопасные" части конфиграции.
ci/cd pipeline / IaC подхода для сетевой инфраструктуры
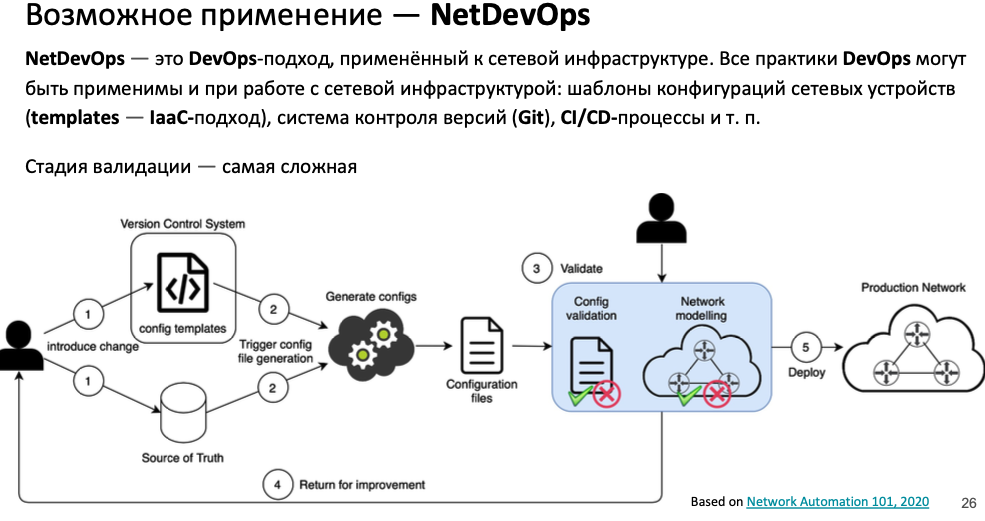
Сетевики с навыками кодинга нужны/есть во всех крупных компаниях – google, microsoft, facebook, amazon. За автоматизицию с опенсорсом сетевик может зарабатывать вплоть до 350к долларов (silicon valley). Автоматизация в таких компаниях достигает зачастую такого уровня, что исключает ручной ввод команд на устройстве полностью – между администратором и устройством есть прослойки, реализующие множество вещей, которые в сопокупности называются Ci/cd в сети – проверка необходимости изменения, деплой в тестовом контуре и автоматизированный анализ результатов, деплой в проде с кучей проверок:
-
- не привязанные к вендору абстракции, управляющие модулями/драйверами, заточенными под конкретных вендоров
- коммит изменений в VCS через пул реквест с бранча, ревью изменений как самим коммитчиком, так и peer-review
- (devnet, CMS annet) помимо юнит тестов (должны всегда проходить) в pipeline сделана автогенерация конфигов относительно шаблона и можно посмотреть на перечне эталонных/репрезентативных девайсов (которые имеют какие то отличия от других) к каким изменениям в конфиге девайса приведет заливка шаблона ((проверка и инструмента и инженера))
- Тесты/проверка настройки устройств по типу: нужно проводить как можно больше тестов перед заливкой – разгребать фолсы не так обидно, как участвовать в разборе инцидентов; коммиты в мастер пример фейсбука,которые по слухам проигнорили какой то алерт авто-оценки заливаевомо перед деплоем и положили всю свою сеть на несколько часов
- static analysis: синтаксис команд средствами типо ansible checkconfig
- dynamic analysis
- проверки / фиксации первичного состояния прода
- доступность узлов
- latency/jitter, включая возможно end-to-end метрики хостов (Яндекс)
- деплой в проде
- проверки корректности деплоя и при необходимости быстрый откат на предыдущую версию
- (devnet, CMS annet) После заливки есть возможность быстрого отката на предыдущее состояние – перед и после заливки с хостов собираются метрики связности с хостов! ((на практике зачастую достаточно и самого узла)) потерь/rtt/jitter (есть интеграция с nms) и если они ухудшились возвращают конфиг/останавливают заливку ((аналог опции prolif check)), вообще проверки до/после (как тестов/так и после деплоя) зависят от обьекта/сегмента сети ((лиф например только базовые чеки)); в целом нет ничего сверхестественного ((prolif check)), чем больше инфы будет для сравнения ((и перед заливкой изменений)), тем лучше
Пример создания ci/cd pipeline / IaC подхода для сетевой инфраструктуры ((что-то реализовано спорно))
Если +- коротко то вот так сейчас работает
⁃ Всё в нетбоксе (свитчи, айпишники, порты и т.п.)
⁃ В гитхабэкшен запускается джоба, которая собирает все данные из нетбокса и на их основе генерирует конфигурацию
⁃ Конфигурация попадает в дев бранч
⁃ Делаешь пул реквест из дев бранча в мастер для ревью
⁃ После ревью код пушится в мастер
⁃ Создаётся релиз в системе CI/CD
⁃ Запускает деплой в котором ансибл запускает плейбук с конфигурацией в check режиме и с выводом diff
⁃ После завершения генерируется вывод изменений которые нужно подвердить прожатием кнопки
⁃ Деплой конфигурации на свитчи без check мода
** в гитхабе только генерация конфига. Деплоится у нас другой системой.
- У нас для этого ((судя по всему имеется ввиду выработка конфигурации)) есть виртуальные стейджинг свитчи, там проверяешь функционал и потом уже код пишешь который потом зальётся так же на эти стейджинги а затем в прод.
- Это виртуальный стейджинг повторят полностью прод? Ответ нет.
- Если не секрет как в этом пайплайне вы проверяете, что строчки которые вы скормите ansible реально можно загрузить на устройство? check-mode ведь изменений не вносит, он только генерит эти самые изменения и показывает вам... Мы используем модуль вот этот https://docs.ansible.com/ansible/latest/collections/junipernetworks/junos/junos_config_module.html#parameter-check_commit и он умеет в check
Благодарю. Документация прямо говорт. Умеет синтаксис проверять без загурзки в железо. Что огромый плюс.
check_commit (bool): This argument will check correctness of syntax; do not apply changes. Note that this argument can be used to confirm verified configuration done via commit confirmed operation
Netbox из коробки все в конфигурации не поддерживает, приходится делать костыль в виде использования local config context data.
Я так понимаю, что Вы не полностью генерите конфигурацию, у Вас деплой это слияние части конфиги с dcbox с конфигой на железке? нет, фулл конфиг генерируем из нетбокса, в локальный контекст мы добавляем только тот функционал которого нет в нетбоксе типа статической маршрутизации, юзерменеджмента, различных vcp,vlt и т.п
Заранее прошу прощения за возможно дилетантский вопрос, но возможно ли в нетбоксе описать всю конфигурацию роутера/свича, с интерфейсами и айпи еще ладно, а как быть с конструкциями типа туннельных интерфейсов, bgp пирингов, IPsec туннелей?
Для бгп есть классный плагин https://github.com/k01ek/netbox-bgp
А остальное можно сделать через какие-нибудь доп поля или local config context data на девайсе
>> Представляю себе редактирование local config context data в веб формочке нетбокса не видя как железка отреагирует на эти изменения, инженерам эксплуатации нужно медаль за это давать 😁 - это не комфортная эксплуатация от слова совсем
Заливка полного конфига плохой вариант (кто бы мог подумать а🤣)
И самое главное крутить целиком конфиг, если нужно поправить например description на интерфейсе или syslog destination - не очень вариант.
ZTP

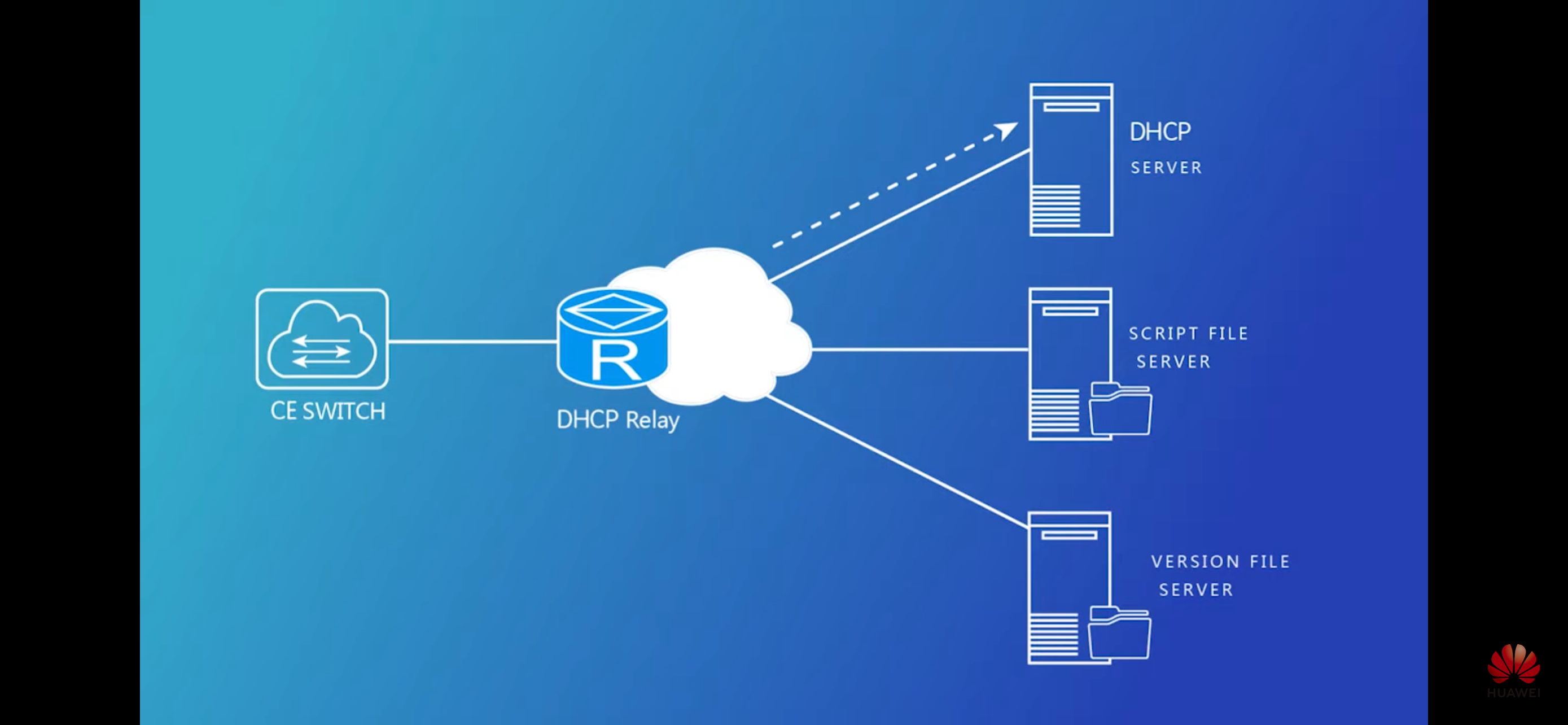


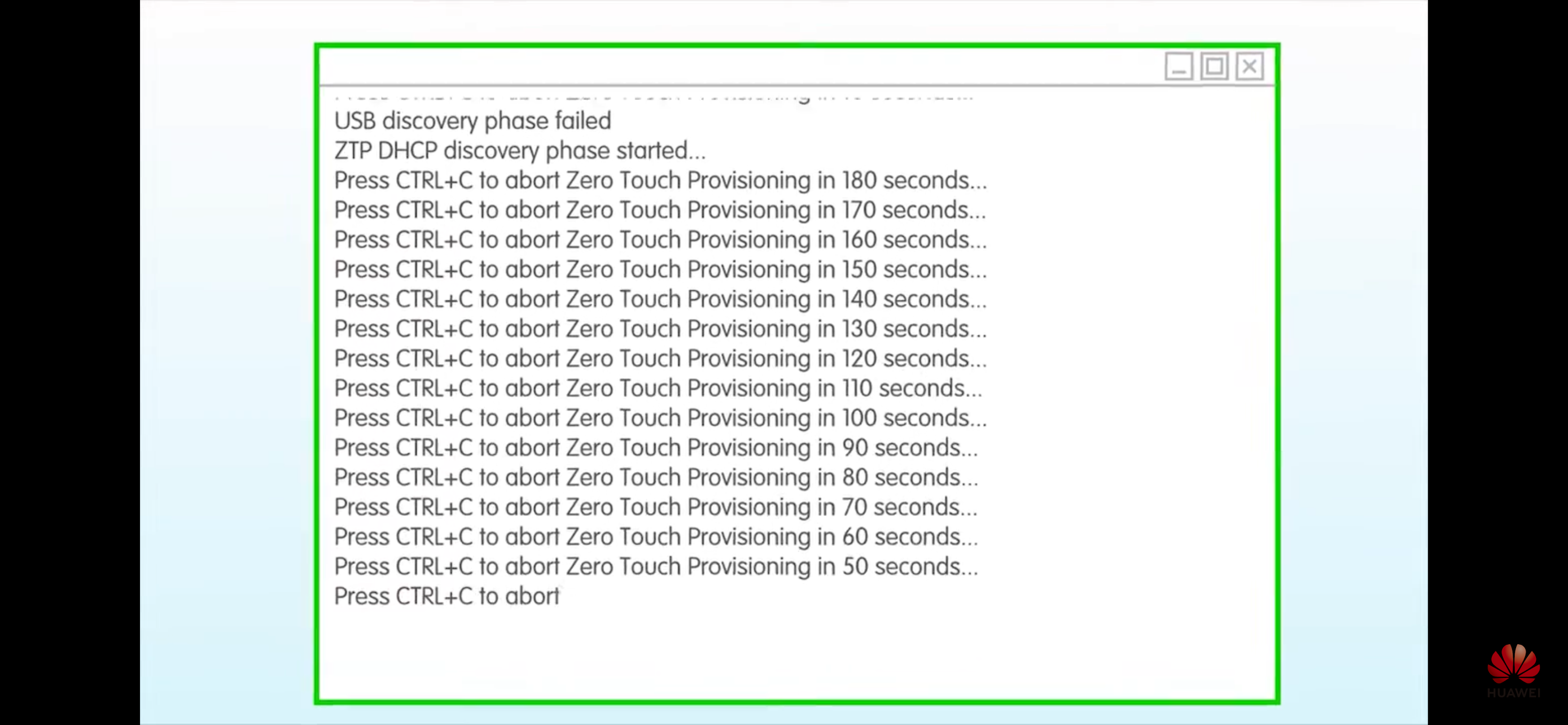
- Полный ZTP – от автовыделения адреса в IPAM до заливки прошивки и прод конфигурации и маршрутизация трафика девайсом в проде
- Возможные реализации сетевого ZTP могут быть разными
- через консольный интерфейс
- DHCP + TFTP/FTP/SFTP/etc
- PXE
- Onie
- CloneZilla
- TR-069
- Любые реализации зависят от настроек по умолчанию вендора:
- Cisco – чаще всего на взрослом железе (routers/switches catalyst family)
- IP адрес отсутствует + доступ не настроен удаленный (VTY), скорее исключение – smb модели с дефолтным адресом и наличием доступа (Linksys)
- При этом же: адрес получается по dhcp и есть вариант деплоя через ztp: к примеру dhcp + tftp с отправкой на Cisco необходимого конфига с включением удаленного доступа
- huawei (пример 5735) – есть ZTP (USB based, DHCP based), по умолчанию 192.168.1.253
- eltex (пример mes2348) – по умолчанию dhcp; если провал 192.168.1.239
- Cisco – чаще всего на взрослом железе (routers/switches catalyst family)
- На Arista удобный ZTP, основан на DHCP опциях (как и многие другие, даже VOIP телефоны)
- Популярные для whitebox вариации описаны в статье Cumulus
- ZTP Over USB
- ZTP Over DHCP (Option 60 + Option 239)
ZTP over DHCP
Request:
Option 60 – Vendor ID
Option 61 – Device ID
Reply:
Option 67 (66) – отдать имя tftp/ftp/sftp файла с конфигурацией или python файла для исполнения железкой
Option 150 – отдать адрес tftp/ftp/sftp сервера
Option 239 – URL со скриптом (ZTP service downloaded the provisioning script using the URL specified in the DHCP option 239 received by the switch when it obtained an IP address.)
http://habrahabr.ru/company/etegro/blog/242575
1 - The first time you boot Cumulus Linux, eth0 makes a DHCP request. By default, Cumulus Linux sends DHCP option 60 (the vendor class identifier) with the value cumulus-linux x86_64 to identify itself to the DHCP server.
2 - The DHCP server offers a lease to the switch.
3 - If option 239 is in the response, the ZTP process starts.
https://docs.nvidia.com/networking-ethernet-software/cumulus-linux-59/Installation-Management/Zero-Touch-Provisioning-ZTP/
Автоматизация начинается уже на этапе подключения коммутатора в сетевую среду. И за это стоит благодарить установочную среду ONIE, пришедшую на смену PXE. При первой загрузке при помощи опции 239 DHCP запрашивается URL-адрес, с которого будет получаться образ системы. А вместе с ним запрашивается скрипт, который будет выполнен при установке. В список поддерживаемых языков входят Bash (Shell), Perl, Python, Ruby.




верификация сетей, batfish
- batfish
- (batfish/hadal)
- batfish работает на основе анализа конфига, собираются конфиги, на их основе строится модель – верификация control plane
- hadal снимает состояние коробок и строит модель – верификация Data Plane
- кто использует верификацию сетей – amazon, google, microsoft, alibaba, bytedance
- Мнения паблика (по сути относится к обоим продуктам, но написано для batfish)
- Звучит как какое-то очень амбициозное и, скорее всего, практически нерабочее (за вычетом самых примитивных случаев, когда и без него всё понятно) говно. Впрочем я, как огурец, всегда уважаю хороший компост. Он нужен для резюме)))
- Была надежда что если скормить в batfish конфиги и выхлопы всяких bgp то он покажет где петли, но конечно же это было наивным предположением
-
Да нет вполне рабочее было еще года 4 назад когда я в него тыкал питоном Загружал в него конфиги железок и оно исправно чекало все ацлы пройдет ли пакет по 5-тапл сквозь сеть И избыточность в ацл показывало когда одно правило перекрывает другие
- Batfish is a network configuration analysis tool that can find bugs and guarantee the correctness of (planned or current) network configurations. It enables network engineers to rapidly and safely evolve their network, without fear of outages or security breaches.
-
-
- A10 Networks
Arista
AWS (VPCs, Network ACLs, VPN GW, NAT GW, Internet GW, Security Groups, etc…)
Cisco (All Cisco NX-OS, IOS, IOS-XE, IOS-XR and ASA devices)
Check Point
Cumulus
F5 BIG-IP
Fortinet
Free-Range Routing (FRR)
iptables (on hosts)
Juniper (All JunOS platforms: MX, EX, QFX, SRX, T-series, PTX)
Palo Alto Networks
SONiC - Aruba
Dell Force10
Foundry
- A10 Networks
-
-
- Flag undefined-but-referenced or defined-but-unreferenced structures (e.g., ACLs, route maps)
- Configuration settings for MTUs, AAA, NTP, logging, etc. match templates
- Devices can only be accessed using SSHv2 and password is not null
- End-to-end reachability is not impacted for any flow after any single-link or single-device failure
- Certain services (e.g., DNS) are globally reachable
- Sensitive services can be reached only from specific subnets or devices
- Paths between endpoints are as expected (e.g., traverse a firewall, have at least 2 way ECMP, etc…)
- End-to-end reachability is identical across the current and a planned configuration
- Planned ACL or firewall changes are provably correct and causes no collateral damage for other traffic
- Two configurations, potentially from different vendors, are functionally equivalent