
- (Ngfw с выдержками, proxy/balancer только header) Выдержка из статьи цифровых решений (dsol) о плюсах intel qat на базе cpu (тк у них нет продукта балансера с реализованным decrypt они это пиарят)
- Пакетные брокеры с функционалом балансировки. Часто встречаемое решение в последнее время, особенно в фин. секторе.
Nfware
- virtusl cgnat
- virtual load balancer – его использовал ОК
The industry's fastest software Load Balancer designed for high-loaded deployments NFWare Virtual Load Balancer is a next-gen software load balancer that significantly decreases network loads and prevents harmful DDoS-attacks. It demonstrates high performance while running on standard x86 servers. The speed ensures optimal hardware utilization, critical for high-load deployments. The NFWare Load Balancer could be easily integrated into any virtual and cloud infrastructure, or run as bare-metal. 240 Gbps per VM - the fastest performance among all existing solutions; It provides linear scalability for more than 20 vCPU. 40M CPS per VM, capable of being used for the most high-loaded deployments Achieve security protection with the use of multiple techniques such as SYN cookie, advanced connection live-time control, and drop entry mechanisms.
Big-ip f5
- (Сбер, балансировщики) BIG-IP F5 Топовые балансировщики, используются в сбере
- (Beeline, балансировщики) из вакансии hh.ru “Сетевой инженер (Эксплуатация средств балансировки приложений)”:
- OpenSource: HAProxy, Nginx, Apache HTTP Server (mod_proxy_balancer)
- коммерческие решения: F5 BIG‑IP, Citrix ADC, Radware Alteon
radware alteon
- (Beeline, балансировщики) из вакансии hh.ru “Сетевой инженер (Эксплуатация средств балансировки приложений)”:
- OpenSource: HAProxy, Nginx, Apache HTTP Server (mod_proxy_balancer)
- коммерческие решения: F5 BIG‑IP, Citrix ADC, Radware Alteon
Nginx balancer
- Про nginx как web сервер см. отдельная статья
- Посредстом балансировки на nginx иногда отдают статику backend серверов – т.е. балансировщик не форвардит запрос к backend серверам, а сам отдает статический контент, который может быть примонтирован как к балансеру, так и к бекендам (шара smb/gluster/etc)
- Балансировка и отказоустойчивость WEB приложения легко делается через nginx. Хуже если балансер через DNS, там время кеша 2 минуты. Бывает даже такой сценарий, что nginx находится на одном логическом сервере (в той же самой системе) с apache и выполняет функции redirect на apache.
Haproxy
- Пример более-менее реалистичного конфига https://github.com/kmmorozov/configs/blob/main/haproxy.cfg
- в среднем haproxy считается более производительный в сравнении с альтернативами, включая nginx (такой же опыт у коллег из практики)
- haproxy работает как типичный stateful балансировщик/nat (еще называют двуногий балансировщик) – при запросе от клиентов на fronend он балансирует их на сервера в группе backend и ответы от серверов идут так же через балансировщик, а не напрямую клиентам, что позволяет stateless балансирвка, но не stateful (на курсе lpic, кстати, рассказывали другое)
- HAProxy (like many load balancers) generally maintain two conversations. The Proxy has a session (tcp in this case) with the client, and another session with the server. Therefore with proxies you end up seeing 2x the connections on the load balancer. Therefore all traffic flows through the load balancer.
- В haproxy есть разные настройки балансировки (применимо как для группы fronend, так и для backend)
- mode – уровень балансировки
- tcp – балансировка по l4 портам
- http – балансировка по l7, например данным в http (поддерживаются и другие протоколы)
- balance – метод распределения
- roundrobin – чередование, пример для двух: первый запрос первому, второй второму, третий первому
- first – всегда отдавать первому, пока он доступен, если недоступен отдавать следующему доступному первому
- mode – уровень балансировки
- В haproxy есть поддержка blacklist – запросы от этих IP не обрабатываются haproxy (базовая security защита)
- В haproxy есть возможность включить сервер статистики в haproxy, там коллектится инфа по бекендам и фронтендам; к этой статистике можно обращаться по api/парсит/куда то складывать, так же есть prometheus exporter для нее
- (Haproxy, dns) хорошо иметь active-active haproxy (платная версия), но в совокупности с dns round robin потенциально можно использовать и бесплатную версию с учетом недостатка с кешами dns. community версия поддерживает схему резервирования только active-passive через использование pacemaker – пассивный включается при отказе активного и использует его “real ip”, с dns round robin долгие кеши приводят к обращению к упавшей ноде до истечения кеша, поэтому каждый балансер должен быть в active-passive кластере. Так же по хорошему все кластеры (как proxy, так и БД) должны состоять минимум из трех нод для кворума как метода защиты от split brain.
HAproxy – high available proxy, очень хороший прокси для создания отказоустойчивости TCP/HTTP приложений, который используется даже гигантами типа Twitter, Instagram, Github, Speedtest.net, avito и прочими. Может использоваться совместно с Corosync & pacemaker.
На одном haproxy могут одновременно использоваться разные группы балансировок – для mysql, для web server.
Конфигурация /etc/haproxy/haproxy.cfg простая состоит из двух частей:
-
- Frontend получение запросов на балансировку (от пользователя до прокси)
- Backend балансировка на пул серверов (от прокси до backend)
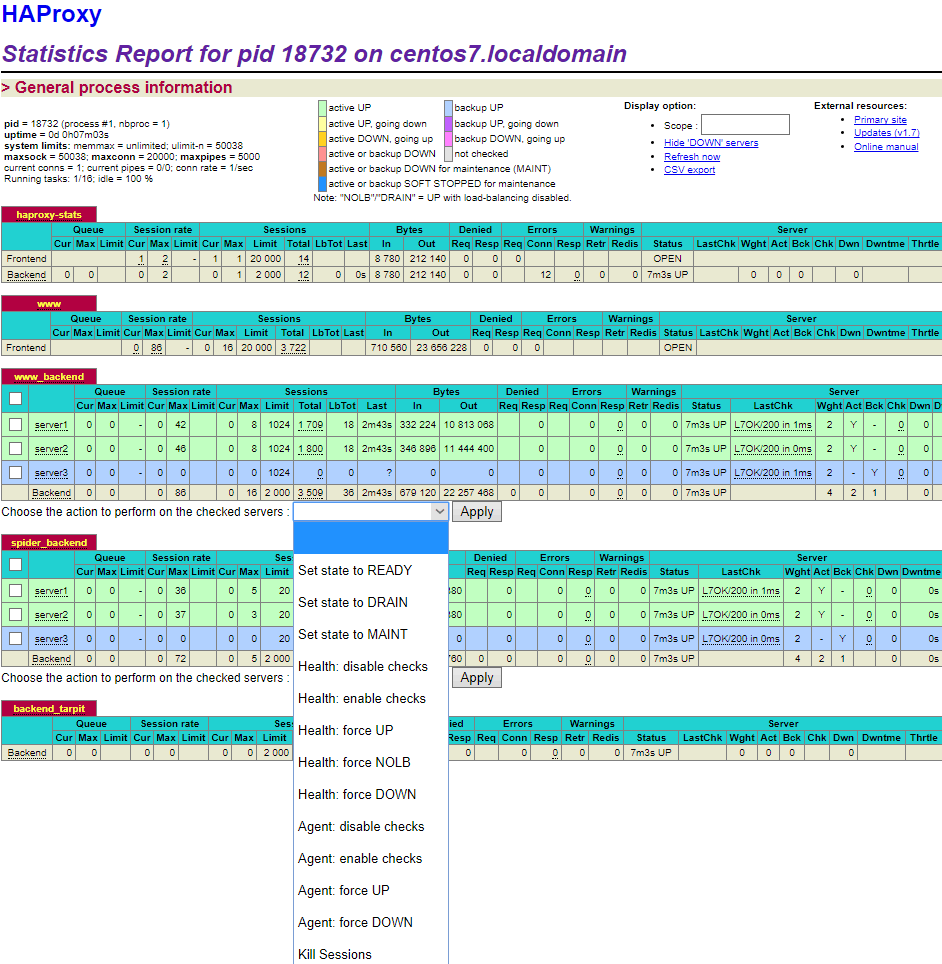
Пример простой схемы/конфига балансировки на два mysql сервера и два reverse proxy.
frontend mysql mode tcp bind :3306 default_backend mysql_servers backend mysql_servers mode tcp balance roundrobin server s1 172.16.30.236:3306 server s2 172.16.30.164:3306 backend reverse_proxy_serv mode tcp balance roundrobin server s1 172.16.30.200:30000 check send-proxy-v2 server s2 172.16.30.201:30000 check send-proxy-v2
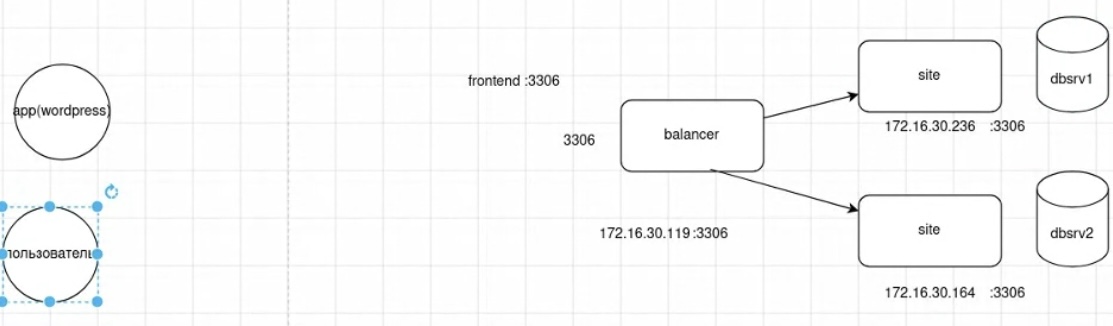
Подключение клиента к серверу через балансировщик (проверка через mysql -h, при round robin балансировке и проблемы со вторым сервером с учетом отсутствия healthcheck терялся каждый второй запрос):
Есть возможность включения сервера статистики haproxy
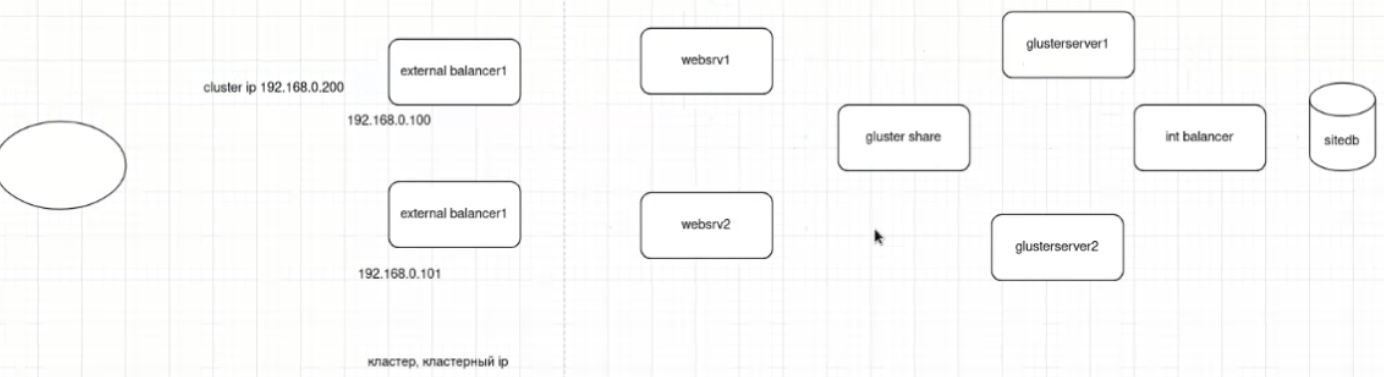
(haproxy, mysql, glusterfs) Взрослая реализация балансировки/отказоусточивости инфраструктуры web сервера включает несколько уровней балансировки – к примеру, сначала балансировка перед web фронт-серверами и последующая балансировка перед БД.
Схема балансировки:
-
- client ->
- (cluster) external proxy ->
- 2 x web apache (независимые) ->
- (cluster) glusterFS share/replica ->
- (cluster) internal proxy ->
- 2 x bd (master-master)
- крайне желателен кворум для всех кластеров – mysql/mariadb, haproxy и реплик glusterfs (по 3 сервера в кластере, а не два), для защиты от split brain через кворум/арбитра в виде третьей машины, иначе нужно шаманить с конфигами для обхода дефолтного ограничения на необходимость кворума (см. примеры ниже)
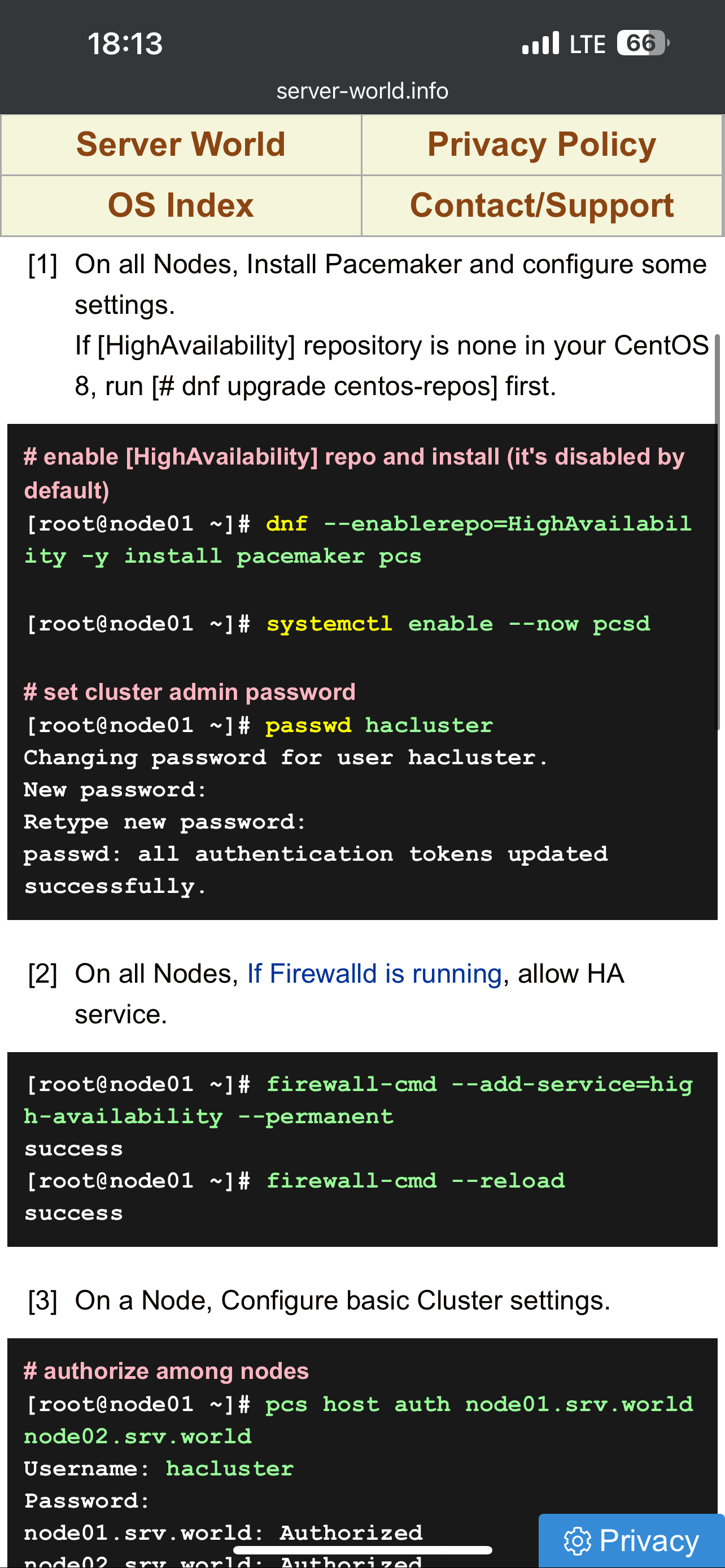
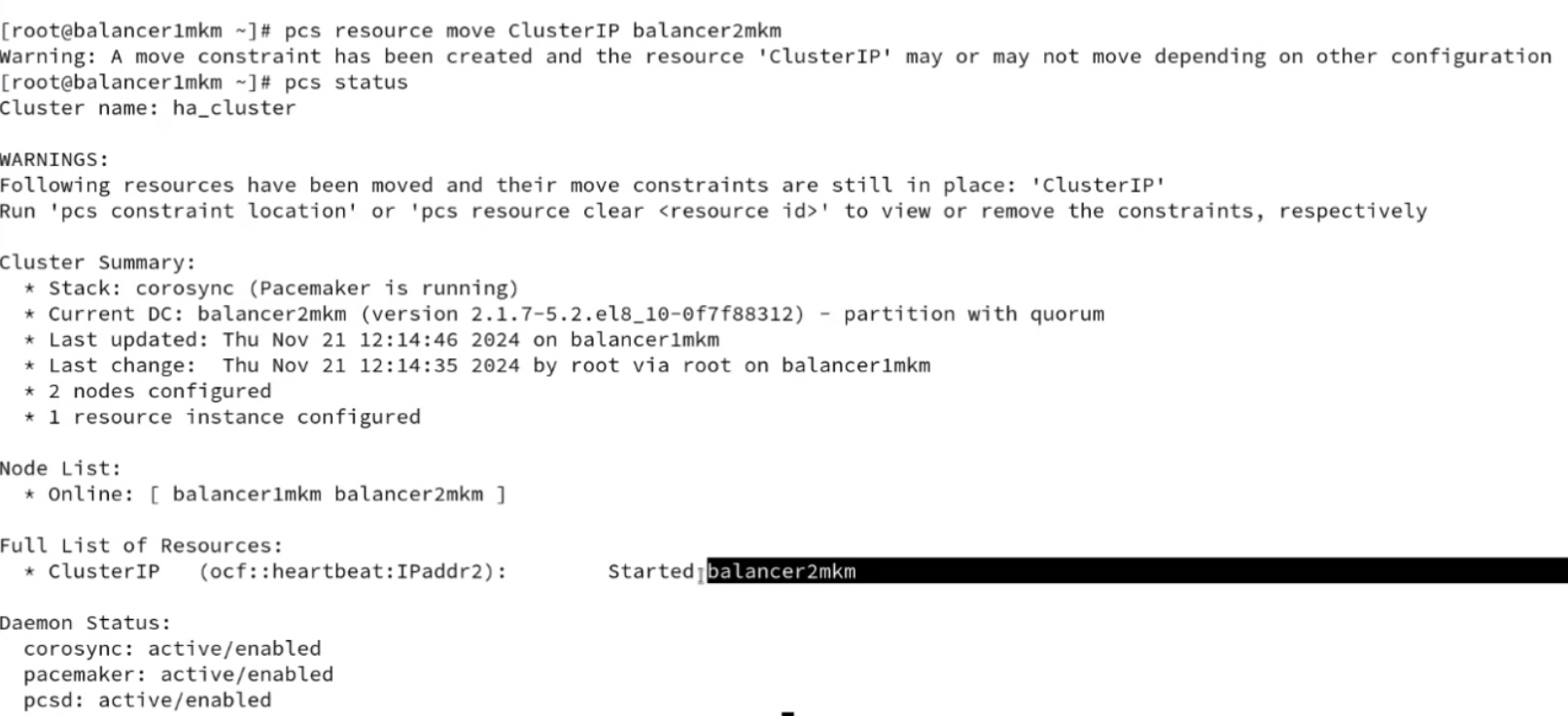
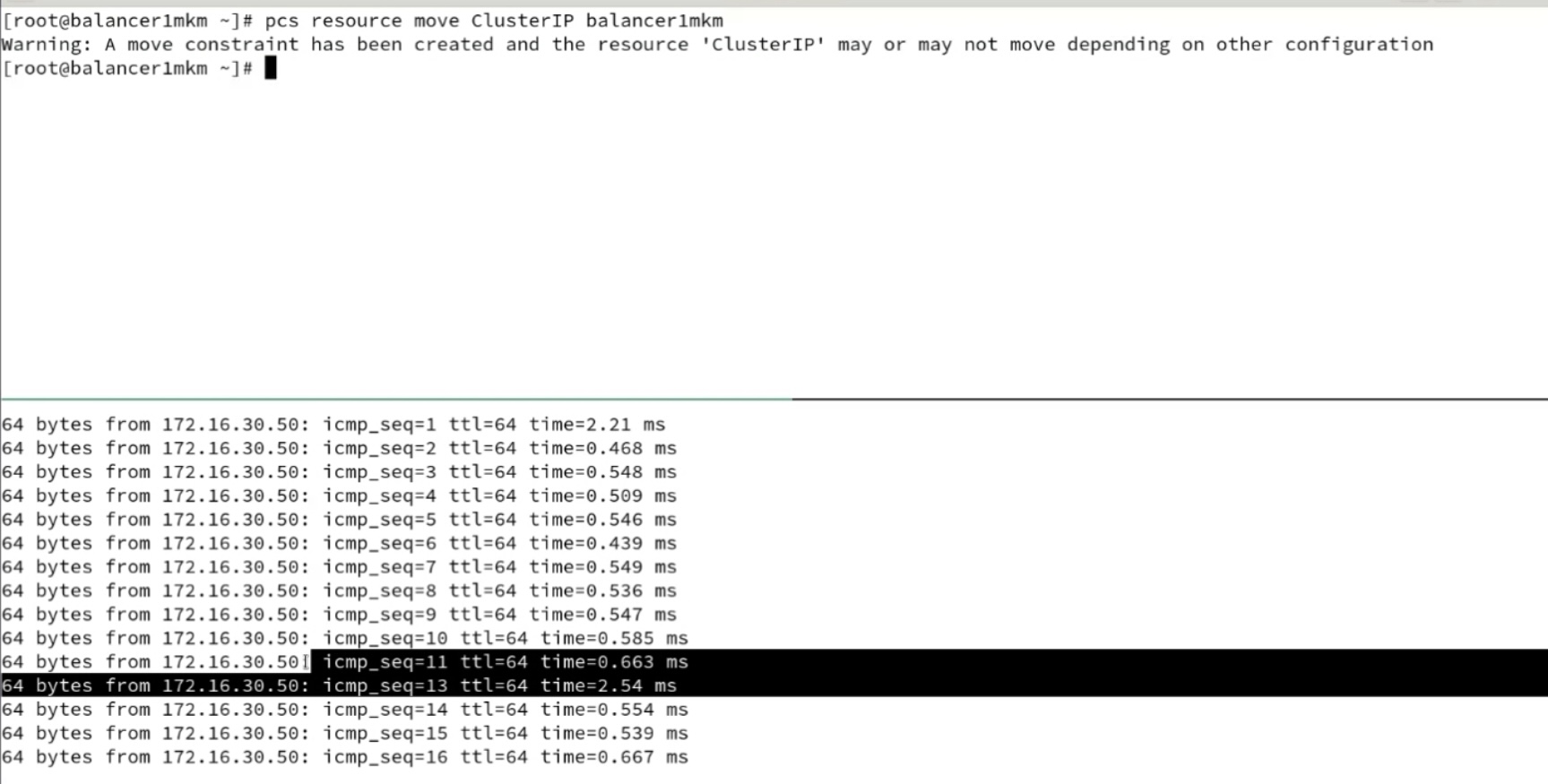
- haproxy для балансировки к нескольким незавимым web серверам wordpress; кластер haproxy active-passive реализуется за счет использования одинаковых конфигов (можно просто копипастить, а можно забирать с шары-smb/glusterfs или из git) между тремя (кворум) и использования специальных демонов, которые реализуют переключение: pacemaker (его юзали в курсе LPIC, проще настраивается и нет мультикаста) или keepalived (на базе vrrp, требует работающий мультикаст, желательно настройка отдельного vlan/аутентификации). IP активной ноды присваивается на пассивную в случае недоступности активной ноды. При этом pacemaker может в качестве разделяемой сущности использовать не только IP адрес, но и другие объекты (препод LINUX: блочные, демоны). И pacemaker и keepalived используется во взрослых промышленных эксплуатациях. Pacemaker без тюнинга позволяет сконвергироваться с секунды – пример потери одного ping при переключении (pcs rouserse move jниже👍
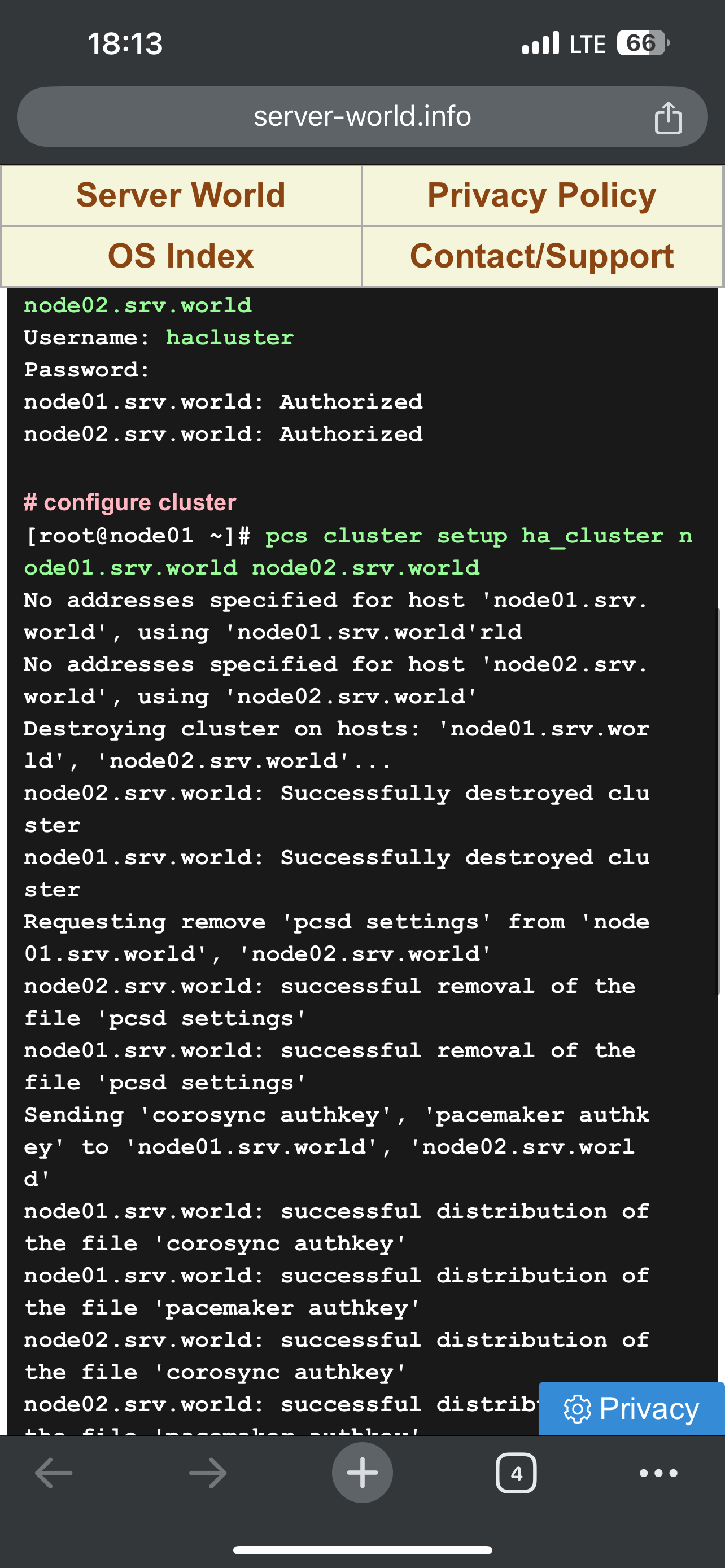
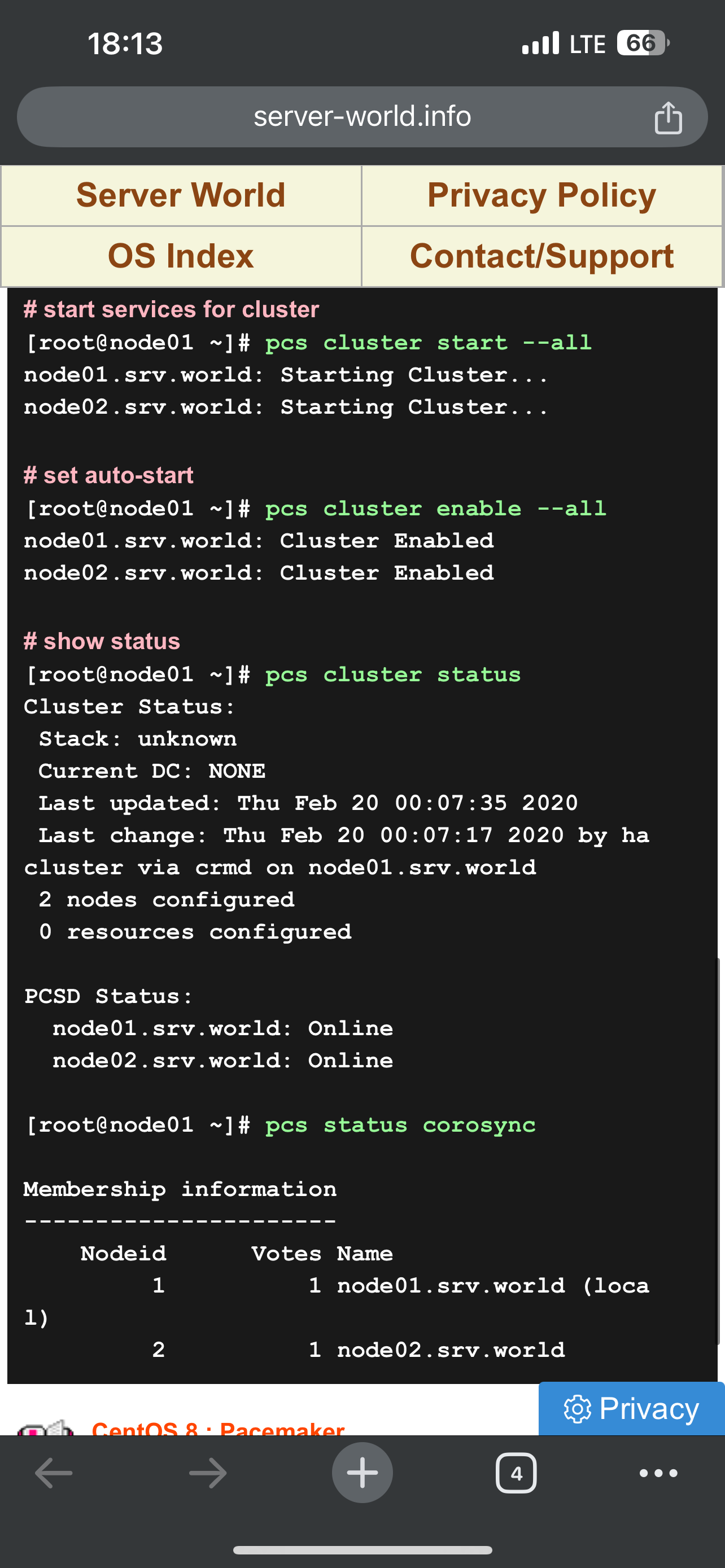
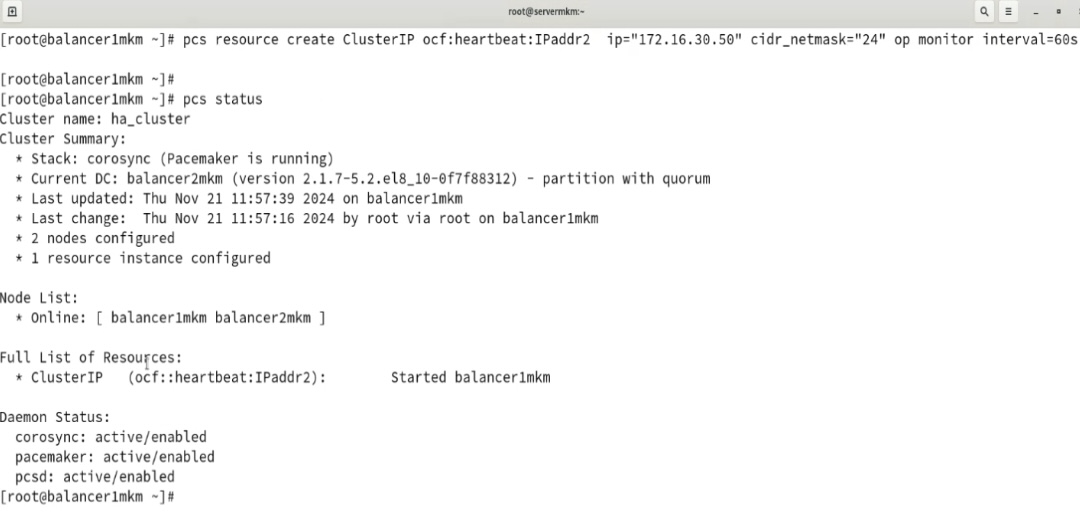
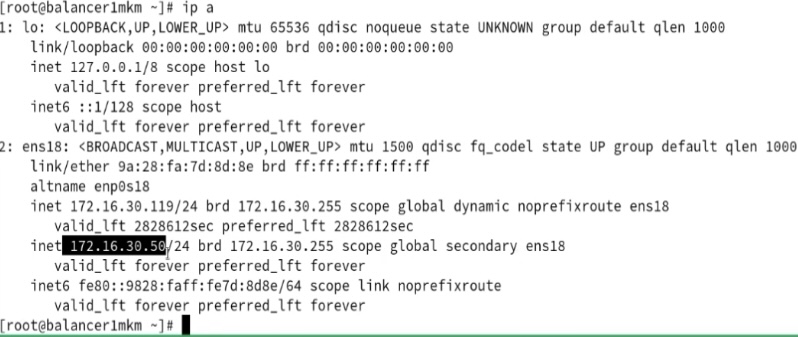
- Для pacemaker с двумя серверами нужно в конфиге pcs отключать проверку на кворум (pcs property set no-quorum-policy=ignore) и prevention по роли (когда две ноды могут постоянно друг у друга отнимать роль после восстановления связности pcs property set stonith-enable=fale). С точки зрения настройки (ниже скрины, базовая инструкция тут https://www.server-world.info/en/note?os=CentOS_8&p=pacemaker&f=1) сложного ничего нет – ставится/включается демон, меняется пароль на служебного юзара hacluster, делается связность через pcs команду между нодами через служебного пользователя, настраивается конфиг, организовывается кластер: pcs resource create ClusterIPocf:heartbeat:IPaddr2 ip=”172.16.30.50″ cidr_netmask=”24″ op monitor interval=60s
- glusterfs для общей шары/единого хранилища между web серверами – одно хранилище для файлов wordpress по /var/www/html, при этом glusterfs можно собрать в stripe (raid 0), а не только mirror (raid 1)
- mysql/mariadb с master-master репликацией, репликация через бинарный лог для запросов web серверов (через прокси т.к. самые стандартные cms не поддерживают failover sql)



L7 балансировщики
https://yandex.ru/news/story/Centrobank_opustil_klyuchevuyu_stavku_do17--601bc5ec66c5df7645cdd0b4a80a023c?lang=ru&from=main_portal&fan=1&stid=nFljArpY8qPmdvRgHWH5&t=1649442076&persistent_id=191863751&story=a3cbfaf4-c013-57d7-80c8-2a21d7cb9a3c&lr=213&msid=1649442758848230-3203246510001223466-vla1-5781-vla-l7-balancer-8080-BAL-1112&mlid=1649442076.glob_225.601bc5ec&utm_source=morda_desktop&utm_medium=topnews_news https://yandex.ru/news/story/Centrobank_opustil_klyuchevuyu_stavku_do17--601bc5ec66c5df7645cdd0b4a80a023c?lang=ru&rubric=business&fan=1&stid=nFljArpY8qPmdvRgHWH5&t=1649442076&tt=true&persistent_id=191863751&story=a3cbfaf4-c013-57d7-80c8-2a21d7cb9a3c https://yandex.ru/news/story/Vrach_ZHuravleva_tonometr_obyazatelno_dolzhen_byt_vdomashnej_aptechke_ulyudej_starshe_35_let--d98f0906cdfdcd1f3eb603f8ff2459e3?lang=ru&from=reg_portal&fan=1&stid=Q1HKyU4lq9VzALucg6NS&t=1649321568&persistent_id=191810526&story=11fde233-b36c-5017-b22d-16a1b263591d&lr=213&msid=1649322116560800-16977679295608403134-vla1-0726-vla-l7-balancer-8080-BAL-4985&mlid=1649321568.geo_213.d98f0906&utm_source=morda_desktop&utm_medium=topnews_region https://yandex.ru/news/story/Poklonskaya_svyazala_sobytiya_vBuche_snenavistyu_kukraincam_i_russkim--e613013bf4207669cb906b5ec91882ed?lang=ru&from=main_portal&fan=1&stid=q3tat_5rx1J59pHqxYk3&t=1649243987&persistent_id=191778989&story=25164cc2-25a2-5d8b-97f4-e7cd362f9bf5&lr=213&msid=1649244516302469-9420224403173302044-sas6-5259-79d-sas-l7-balancer-8080-BAL-1180&mlid=1649243987.glob_225.e613013b&utm_source=morda_desktop&utm_medium=topnews_news
Gigamon
Ixia
Dedicated hardware acceleration provides a Zero packet loss architecture. - Forward traffic to the right tools, including load balancing: - security - monitoring - Deduplication - Filtering of traffic so that each monitoring or inline security tool receives exactly the right data - Aggregation of traffic from multiple TAPs or SPAN ports - L7 application awareness efficiently allows for packet processing based on unique applications - SSL decryption to quickly detect emerging threats encrypting exploits within application traffic

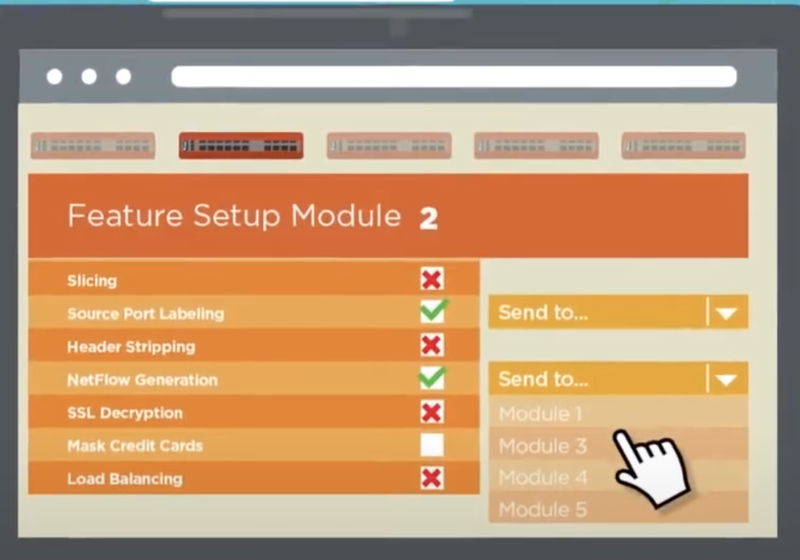
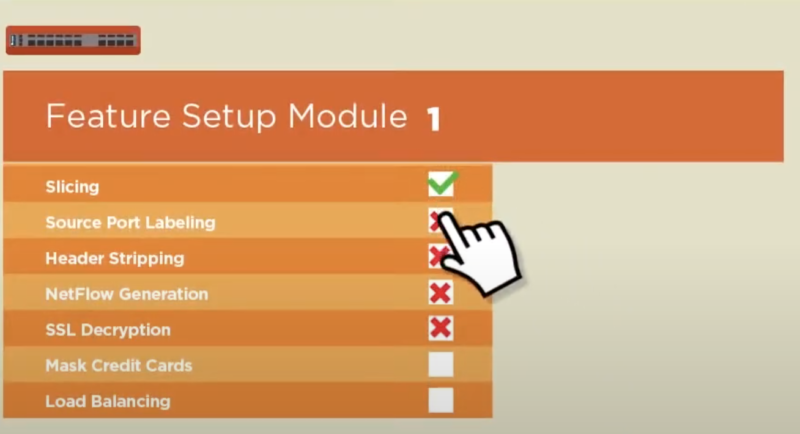 .
. 
Импортозамещение
НПП цифровые решения (dsol) – ds integrity

-
- Массовые серии продуктов начались недавно – подозреваю что СВО сделало большой вклад в спрос решений этого вендора
- Помимо пакетных брокеров так же выпускают коммутаторы Fenix
- каждый!!! серийный! свич проходит порядка 300 тестов -> комплекс тестирования занимает 24 часа на одно изделие!
- Разрабатывают схематехнику, ПО; этапы
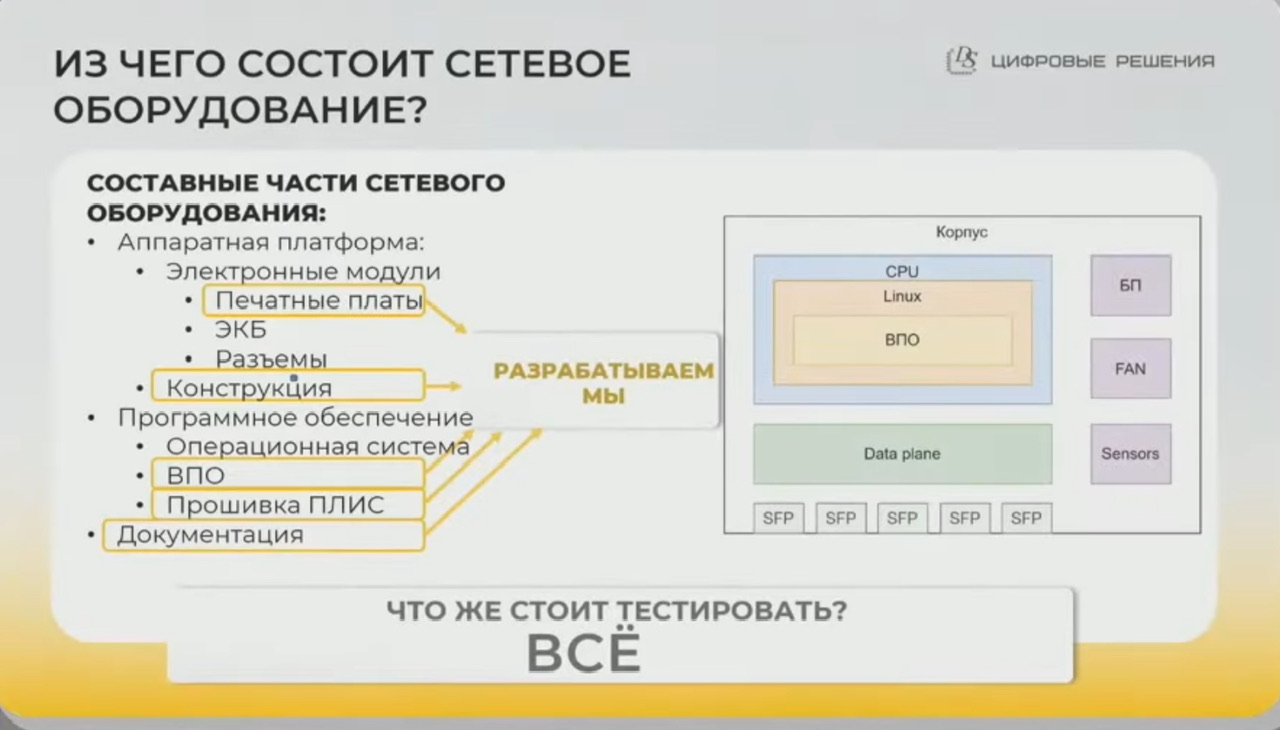
- разрабатывают структурную схему изделия, объединяют основные узлы
- разработка электрической принципиальной схемы
- разработка топологии печатных плат (тут проверяется качество разводки/тестирвание платы/отсутствие кз/входной контроль)
- закупка компонентов (экб – соответствие закупленному)
- собирается плата – наносятся компоненты
- изготовление платы на заводе – как западные так и РФ
- Более 20 лет занимаются разработкой аппаратных решений, ошибались везде, поэтому рекомендуют тестировать все 😀 на этапе RnD тестируют именно так, при серийном производстве меньше тестов
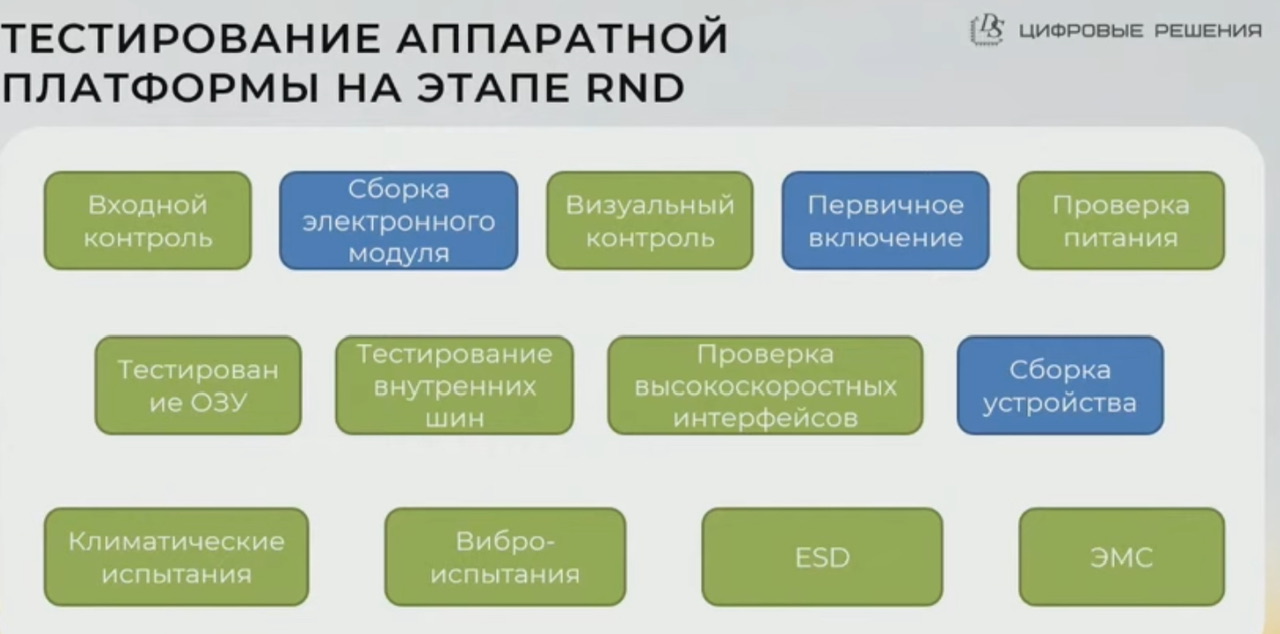
- схематехника – peer review (один разработал, другой инженер проверил на соответствие стандартов/унификацию элементной базы/типовые ошибки)
- тестирование стабильности питания
- тестирование отсутствия битовых ошибок в ОП – иначе могут бвть очень сложные для диагностики баги
- проверка шин i2c, spi – проверка связи между cpu и всеми комплнентами платы
- проверка высокоскоростных интерфейсов (более 10G) – про оценку см. глазковые диаграммы
- в климатической камере тестируют с максимальной нагрузкой по трафику сутки! при максимальной и минимальной температурах
- виброиспытания – тестирование перевозки ПАК
- тестирование к статическому разряду (ESD) – бывало такое, что из-за стат. разряда (свитер) на корпус девайса срабатывал датчик вскрытия и кирпичил девайс, пришел дорабатывать девайс чтобы избегать такого (улучшать заземление корпуса, добавлять фильтры на линию датчика вскрытия)
- электромагнитная совместимость – не мешает соседним устройствам работать
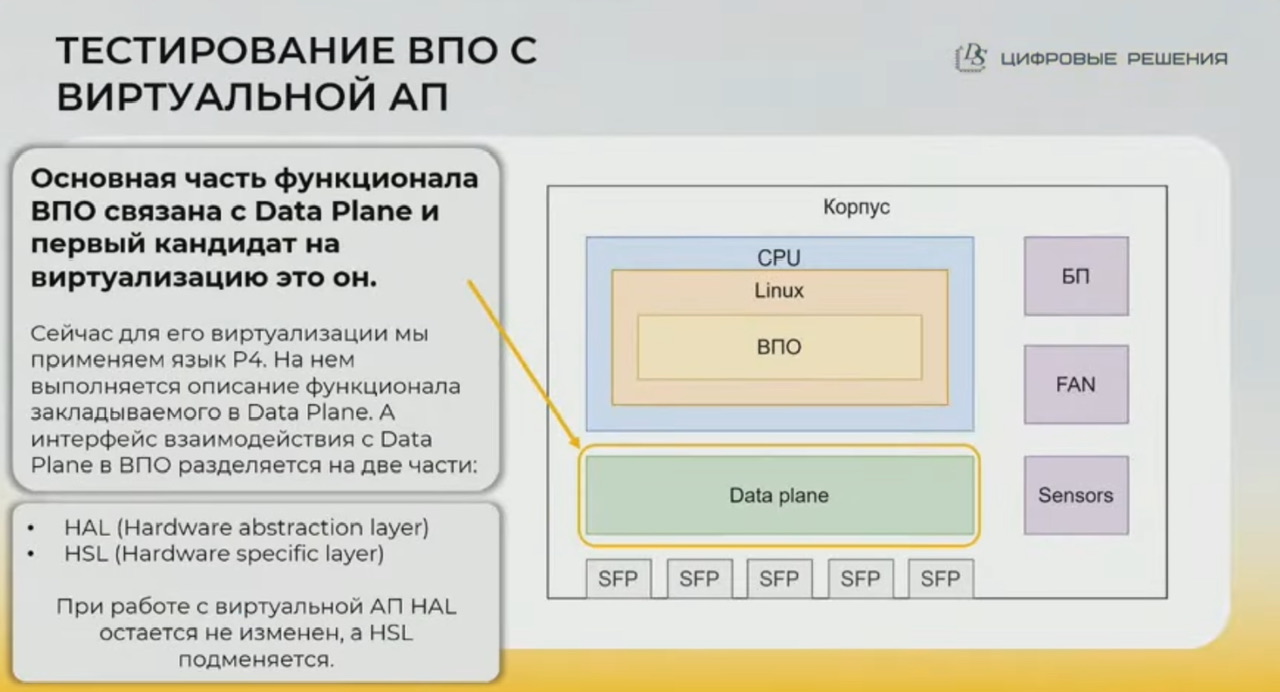
- тестирование ВПО (встраиваемое ПО) – встраиваемым считает то, что работает только применимо к конкретной платформе (ПЛИС/FPGA)
- ВПО тестируют совместно с целевой аппаратной платформой
- или для тестов эмулируя целевую аппаратную платформу (data plane) для ВПО через виртуализацию – конкретная платформа в таком случае у них описывается универсальным P4 коммутатором; пакуется в виде виртуальной машины, которую могут использовать тестировщики/разрабы; такой подход в том числе позволил
- ускорить разработку т.к. разработчики ПО (control/management plane) не ждут готовности прошивки data plane
- использовать созданные VM для тестирования в виртуализированных топологиях – EVE NG

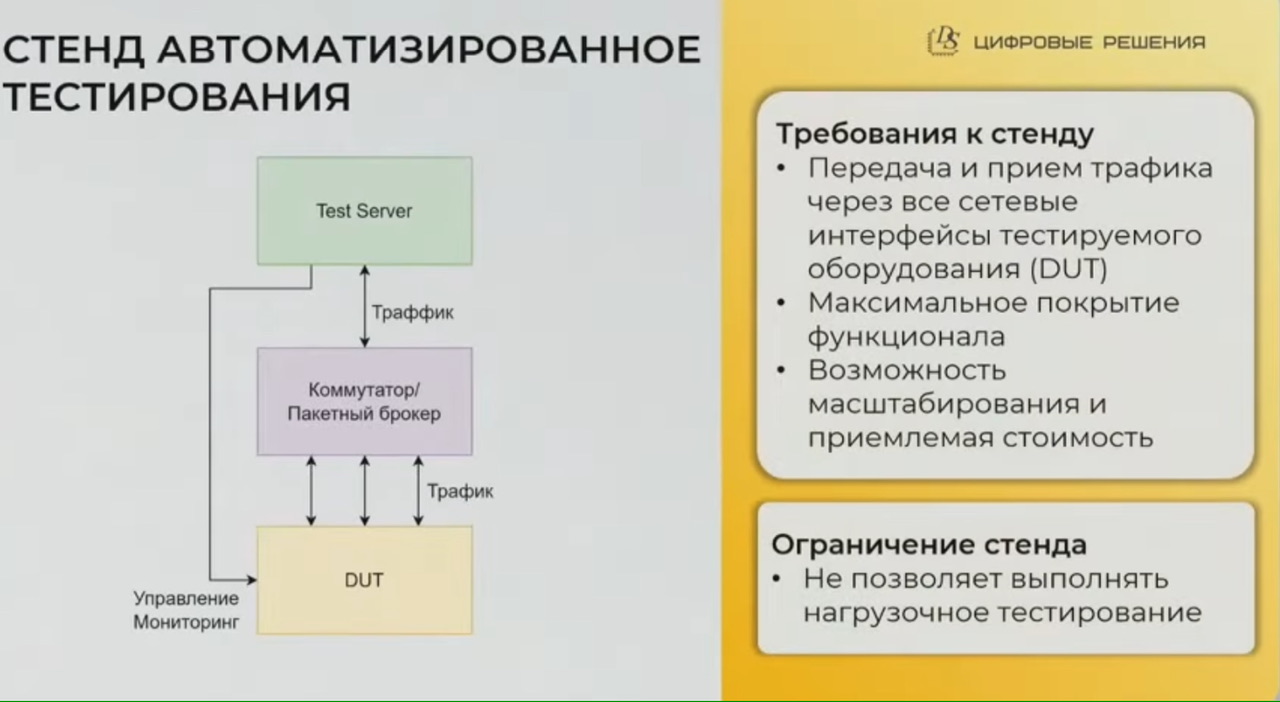
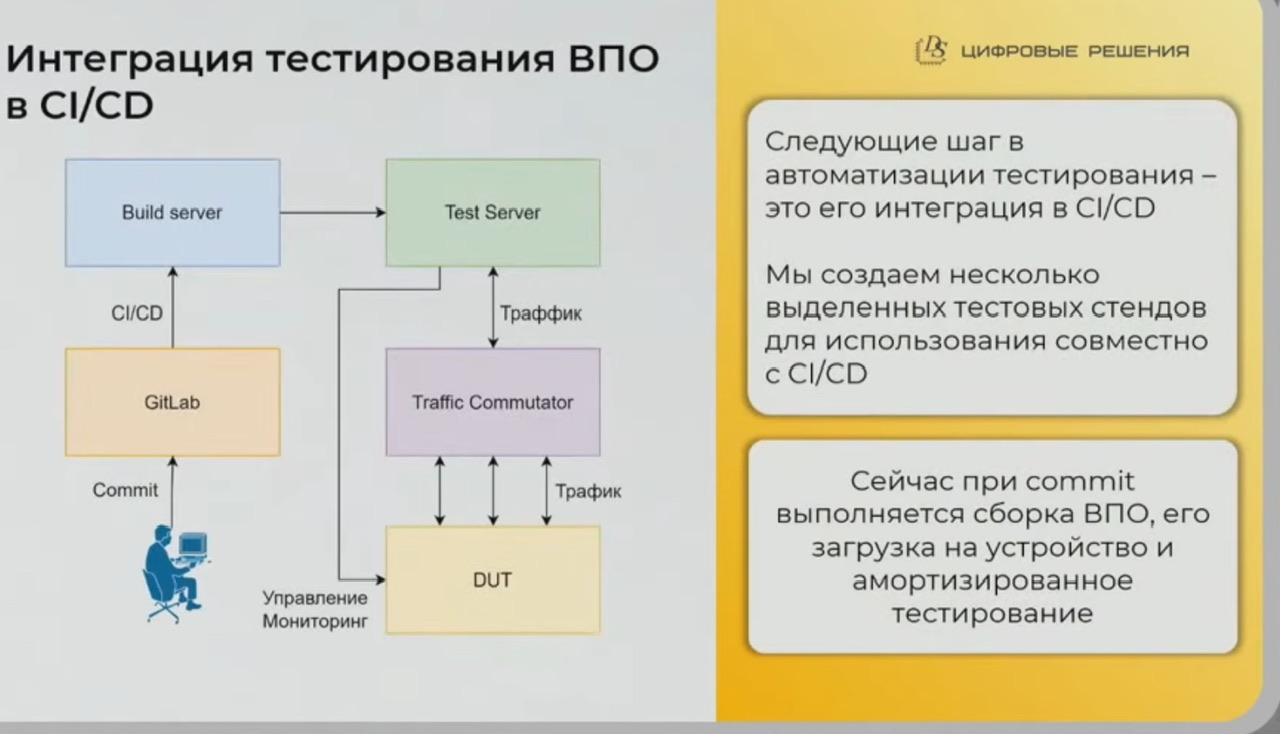
- для тестирования основного функционала у них автостенды, в том числе включенные в CI/CD pipeline на базе gitlab (после commit разработчика запускаются тесты), причем используют промежуточный коммутатор на котором оценивают корректность коммутации трафика DUT, например трафик vlan при передаче на порт получен только с того порта, с которого ожидается
- нагрузочные тесты используют Spirent и закупили Xinertel (им нравится, явно stateless)
- релизные версии так же тестируют и вручную – сложные топологии, неправильные вводы команд, разные задержки ввода/отклика
- у них порядка 20 тестовых стендов, стараются в них использоваться разные SFP модули – разных производителей/аппаратных ревизий;
- по практике работы с разными модулями они не выдвигали рекомендаций по неиспользованию (т.е. бану) какого либо из модулей, обычно алгоритм ‘поддержки’ неработающего модуля был – они запрашивали модуль к себе в лабу, идентифицировали проблему и устраняли
- если проблема по физике диагностировали глазковой диаграммой (определяли что сигнал плохой/на грани/с минимальным запасом) и настраивали serdes – увеличение фронтов, условия “если модуль -вот_это_говно – то вгружаем. нестандартные настройки serdes”
- иногда выходили напрямую на вендора SFP модулей и общались с ними (ошибки бывали с обеих сторон)
- пример кейса – модули не работали/зависали в определенной группе портов, подключили модули, по сигналу на i2c шине SFP модуль реагирует (получает и “вешает” шину) на ту команду, которую должен игнорировать (она предназначена не ему)
- у трансивера есть EEPROM и часть параметров – большая часть параметров на read, но есть и read-write (управление). Они не используют никакой настройки модулей со стороны SFP модулей (берут все что отдается по read only по страницам A0/A2 и читают DOM, медь по DOM ничего не отдает) и в целом не встречали доступ к настройке serdes на модулях. Им кто-то предлагал перепрошивать модули, которые к ним подключаются, но они не стали это делать.
- по практике работы с разными модулями они не выдвигали рекомендаций по неиспользованию (т.е. бану) какого либо из модулей, обычно алгоритм ‘поддержки’ неработающего модуля был – они запрашивали модуль к себе в лабу, идентифицировали проблему и устраняли

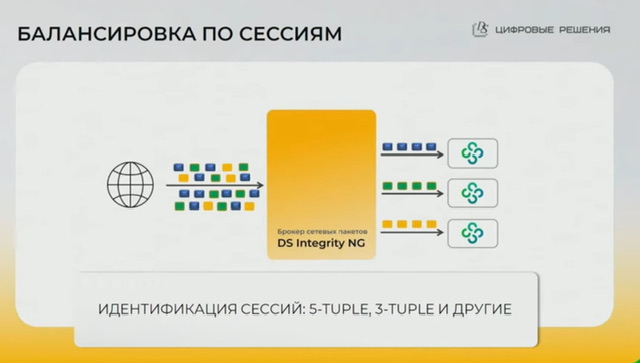
Брокеры сетевых пакетов (DS Integrity)
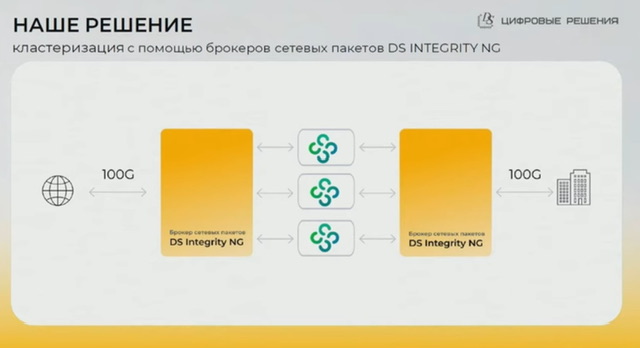
Типовая конфигурация брокеров для балансировки на кластер NGFW
-
- Hash
- между разными ПАК-брокерами используется один алгоритм хеширования, поэтому синхронизация сессий при отказоустойчивости не нужна
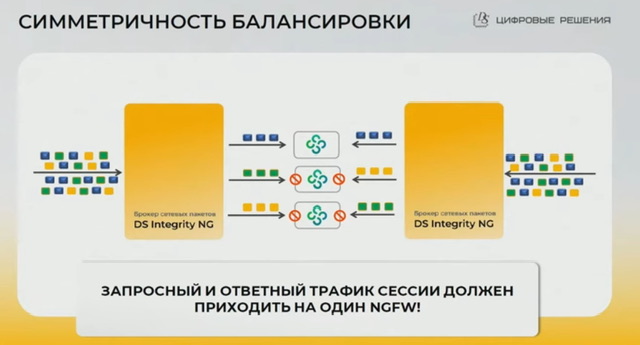
- symmetric hash
- resilient hash
- есть возможность настройки балансировки как 5tuple, так и 3tuple (полезно для ftp когда контрольная и дата сессия имеют разные порты), так и только по src или только по dst
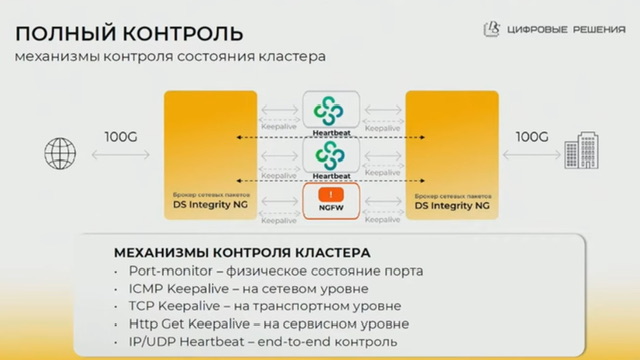
- heartbeat между брокерами (помимо других способов детекции проблем – падение линка/активные запросы icmp-tcp-http) для контроля отказа ноды кластера, причем он двухсторонний (т.е. оба брокера отсылают) – в итоге отвал на одной стороне приведет к полному отключения с обеих
- на схемах нарисовано по два брокера с двух сторон (четыре брокера всего), но в целом отказоустойчивость реализуема и на двух брокерах всего, если на каждом брокере держать и in и out трафик (главное чтобы портов хватало)
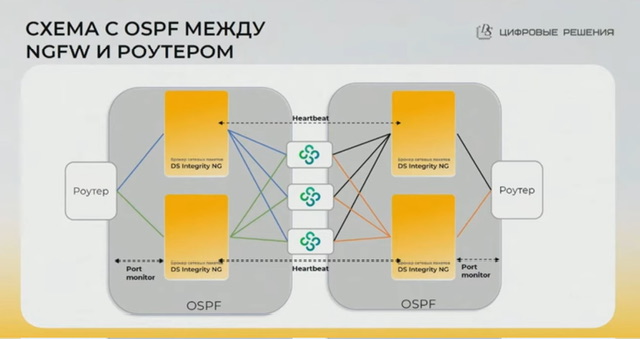
- отказоустойчивая схема с резервными брокерами между кластером ngfw и роутером обеспечивается за счет
- L3: ospf, поэтому скорость сходимости при отказе брокера зависит от настроенных таймеров ospf на файрволах и роутере/поддержки на них bfd; можно было бы чисто за счет поднятия/падения линков на брокере – но соседям нужно явно дать сигнал на переключение, схема с роутингом это нативно обеспечивает; брокер подменяет DST MAC на корректный для балансируемой ноды; есть так же fault propagation (по сути простой скрипт), когда падение аплинка на брокере приводит к принудительному отключению всех даунлинков
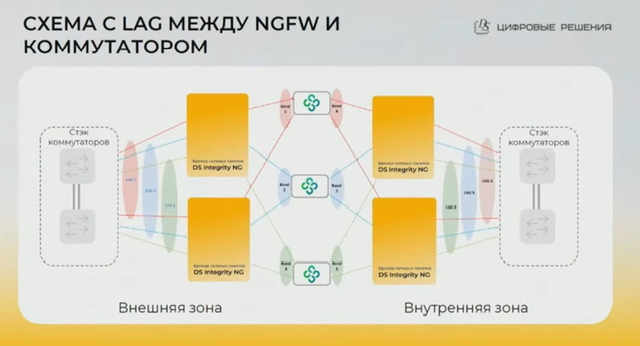
- L2: за счет lag с lacp – по сути lag между коммутатором и файрволом насквозь брокер. Схема для тех кто не хочет по каким либо причинам L3 (нет/мало роутеров, не хотят ospf и проч). Клиенты терминируются по L3 на NGFW. Все служебные пакеты (включая lacp) пролетают прозрачно через брокер (он прикидывается для них проводом, с точки зрения lag его по сути нет), для основного трафика (можно по определенному критерию ip/tcp/etc создать группу балансировки) брокер балансирует его и подменяет DST MAC на корректный для балансируемой ноды.
- L3: ospf, поэтому скорость сходимости при отказе брокера зависит от настроенных таймеров ospf на файрволах и роутере/поддержки на них bfd; можно было бы чисто за счет поднятия/падения линков на брокере – но соседям нужно явно дать сигнал на переключение, схема с роутингом это нативно обеспечивает; брокер подменяет DST MAC на корректный для балансируемой ноды; есть так же fault propagation (по сути простой скрипт), когда падение аплинка на брокере приводит к принудительному отключению всех даунлинков
- Hash
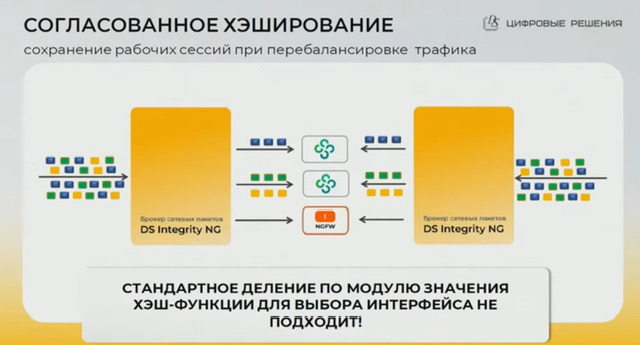
общее описание

- текущая платформа брокера
- до 4х100G
- до 8х40G
- до 32х10G
- есть вариация с оптическим байпасом – в случае отказа питания происходит замыкание в байпасе и линк через упавший брокер продолжает работать
- защита от всплесков при передачи от многих к одному линку за счет как понимаю буфферизации (весь объем RAM как буфер)
- изначально брокер делался для снятия зеркала трафика с сети, его предобработки и отправки на системы аналитики ИБ (см. пример кейса в NTA)
- можно делать сразу несколько действий – помимо балансирования трафика на mgfw часть трафика ответвлять на NTA
Агрегация Сбор трафика различных точек сети c 32 линков в один выходной порт для обработки единого потока одной системой DPI

Фильтрация на основании внешних и вложенных заголовков для обеспечения передачи на средства DPI только целевого трафика
- Удаление дублирующихся пакетов для уменьшения объема трафика (в 2 и более раз), обрабатываемого системами DPI

- Оптимизация пакетов (детуннелирование vlan/mpls/vxlan/gre, удаление заданного количества байт/поля данных) для снижения нагрузки на системы DPI; в том числе может балансировать по вложенным пакетам в туннели

- Инкапсуляция трафика в туннель GRE для безопасной передачи между несколькими офисами или центрами обработки данных

- Формирование и передача статистических данных об информационных потоках системам DPI без установки дополнительных сенсоров
-
-
Ответвители сетевого трафика (TAP)
-
Коммутаторы 3 уровня
-
DS proxima
В 2025 выпустили апаратный балансировщик
-
- 20 gbps считают это зона софтварных балансировщиков, они нацелены на болшие скорости (от 20 до сотни gbps) с учетом аппаратного решения
- балансировка не только на основе hash пакета, но и на основе текущей загрузки девайсов в кластере (не обязательно firewall, возможно и обычные сервера приложений) – напр. по времени отклика на http запрос; при этом уже сейчас есть статические веса для балансировки – подходит, когда заранее знаешь, что один сервер в 2 раза более производительнее чем другой
- (как и сейчас) контроль живости нод кластера на уровнях от L1 (линк) до L7 (http get)
- Conntrack – помимо resilient hashing нужен контроль того, что при восстановлении ноды на нее не балансировались активные сессии, а только новые
- использование не отдельных мелких lag между коммутатором и файрволами (с точки зрения согласования lacp насквозь через брокер), а один большой lag между коммутатором и балансировщиком
- возможно поддержка MC Lag
- поддержка vrrp
- поддержка HA
- не будет прозрачным девайсом, это L3 девайс с поддержкой BGP/OSPF, будет терминировать на себя трафик, который должен балансироваться с анонсом от себя балансируемого адреса.
| Пропускная способность, Тбит/с | 1,44 | |
|---|---|---|
| Поддерживаемые интерфейсы | 100 G | 4 (QSFP28) |
| 40 G | 4 (QSFP+) | |
| 10 G | 32 (SFP+) | |
| Функциональные возможности | ||
| Поддержка отдельных Virtual IP для различных балансируемых приложений | ||
| Балансировка с подменой IP-адресов или с инкапсуляцией в GRE-туннель | ||
| Симметричная балансировка для двунаправленных потоков трафика | ||
| Гибкое распределение трафика по отдельным группам балансировки по полям L2, L3, L4 и их комбинации | ||
| Устойчивость к изменениям при удалении или добавлении устройств в кластере с функцией согласованного хэширования до уровня L4 | ||
| Поддержка механизма отслеживания сессий для динамической балансировки трафика | ||
| Поддержка плавного ввода/вывода устройств из кластера без прерывания сервиса | ||
| Поддержка работы в режиме L2 коммутатора | Поддержка VLAN с одинарным (802.1Q) и двойным (QinQ) тегированием | |
| Поддержка Jumbo Frame до 16000 байт | ||
| Поддержка работы в режиме L3 маршрутизатора | OSPF, BGP, статическая маршрутизация | |
| Алгоритмы балансировки | Hash (5-tuple, 3-tuple, Source IP/Destination IP) | |
| Round Robin | ||
| Weighted Round Robin | ||
| Least Connections | ||
| Weighted Least Connections | ||
| Least Response Time | ||
| Механизмы проверки доступности | Keepalive на уровнях L3/L4/L7 для контроля состояния устройств кластера | |
| HeartBeat для сквозного контроля соединений в кластере | ||
| BFD для контроля сетевых соединений BGP и OSPF | ||
| Механизмы отказоустойчивости | Работа балансировщика в режиме кластера высокой доступности – поддержка VRRP, MC-LAG, LAG LACP | |
| Синхронизация состояния таблиц сессий | ||
| Управление и мониторинг |
WEB-интерфейс | |
| SSH v2 | ||
| Syslog | ||
| Telnet | ||
| SNMP v2/v3 и SNMP Trap | ||
| NTP | ||
| Интерфейсы управления | RS-232, USB Type A, mini USB для локального доступа | |
| RJ-45 для удаленного управления | ||
| Безопасность | Поддержка нескольких уровней прав доступа | |
| Поддержка протоколов аутентификации LDAP, TACACS+, RADIUS | ||
| Дополнительные сведения | Потребляемая мощность до 200 Вт 2 блока питания 220 В AC / 48 B DC c возможностью горячей замены 4 блока вентиляторов с возможностью горячей замены, резервированные по схеме N+1 Форм-фактор 1U, 555x483x44 мм |
|



Гарда NPB
- 12 Тбит/сек высокая производительность до 12,8 Тбит/сек на комплекс
- P4 язык P4 обеспечивает гибкую программируемость брокера, снижает время и стоимость разработки
- layer 1 простой режим Layer1 интеграции: трафик передается на систему сетевой обработки, подключенную к Гарда NPB
Есть у кого опыт эксплуатации брокеров от Гарды? Интересует в качестве съема трафика - достаточно ли правил фильтрации по l3 и l4, работает ли дедупликация, маскирование, усечение payload ну и т.п. Может есть явные нюансы и минусы на которых нужно заострить внимание
@kroppet > Отвечу от лица Гарды. Записей в TCAM суммарно 7k. Делятся между двумя типами политик: map - 6k , copy-map -1k. Copy-map это механизм доставки копии с копии. Полезно при ситуативном разборе трафика чтобы не менять основные политики. Дедупликация поддерживается на модели D5148Y8C-T с DPU картами. Маскирование появляется в ближайшем релизе также для модели D5148Y8C-T с DPU картами. Слайсинг поддерживается на всех моделях.
rdp
RDP. Есть даже решение от RDP 1RU 8x100G, 48x10G. По факту аппаратная база вся на базе Inventec, ПО видимо RDP.
https://shop.nag.ru/catalog/15596.servisnye-shlyuzy/47785.paketnye-brokery/44824.elb-1020 Пакетный брокер ELB-1020 обеспечивает доступ к сетевому трафику для систем анализа и мониторинга, таких как DPI, СОРМ, URL-фильтрация и аналитика, системы безопасности и т.д. Автоматизированная система управления и мониторинга с функцией перенаправления трафика EcoDPI Balancer c ПО EcoDPIOS-LB, ELB-1020, 48 x 10GE SFP+, 8 x 100GE QSFP28.