


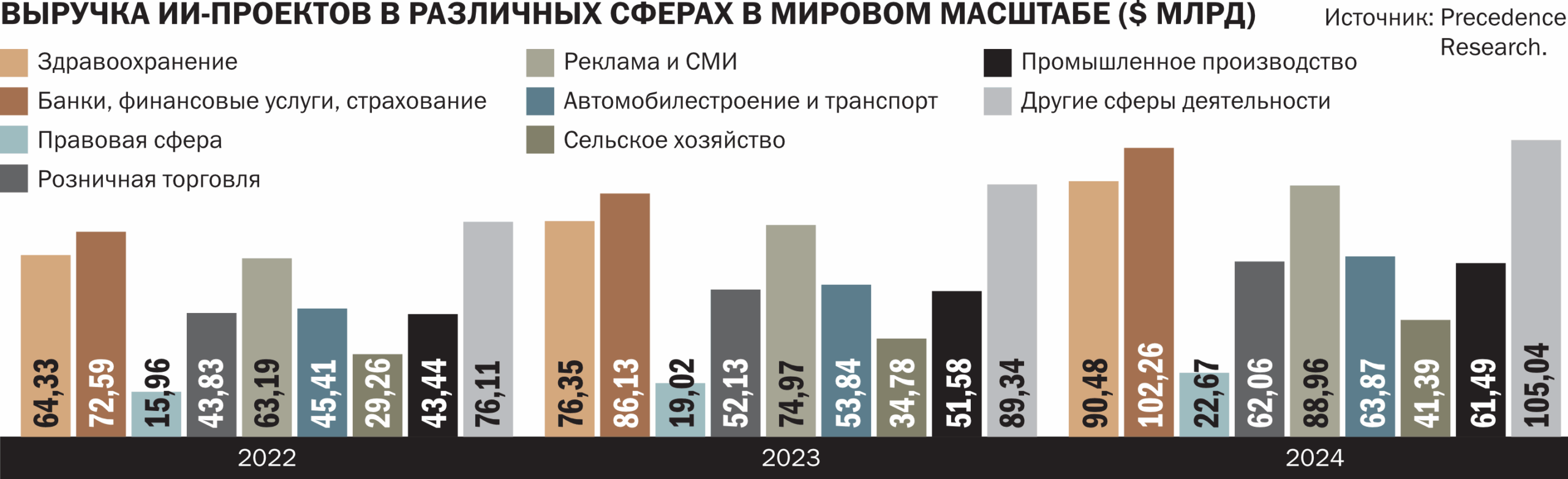










Американские компании OpenAI и Amazon Web Services (AWS) заключили соглашение о стратегическом партнерстве в области искусственного интеллекта на $38 млрд, сообщает Bloomberg. Соглашение рассчитано на семь лет и предусматривает предоставление OpenAI доступа к облачной инфраструктуре AWS. Речь идет о сотнях тысяч графических процессоров Nvidia Corp. Гендиректор AWS Мэтт Гарман заявил, что инфраструктура компании станет «основой для реализации амбиций» OpenAI в области искусственного интеллекта.
- Чат боты с которыми работал/работаю (пока без платных подписок, они в среднем стоят для западных сервисов 20-30 долларов/мес)
- Grok
- ChatGPT
- Gemini
- Perplexity
- Qwen
- Алиса / Alice (считается лучше в качестве чат бота в сравнении с Гигачат)
- Гигачат / Gigachat (считается лучше в дополнительных функциях, таких как генерация музыки, видео и сказок с озвучкой в сравнении с Алисой)
-
Phoronix Test Suite использовался для тестировании производительности ИИ, показатель tokens per second (TPS).
- (ИИ, UFW, WordPress, docker)
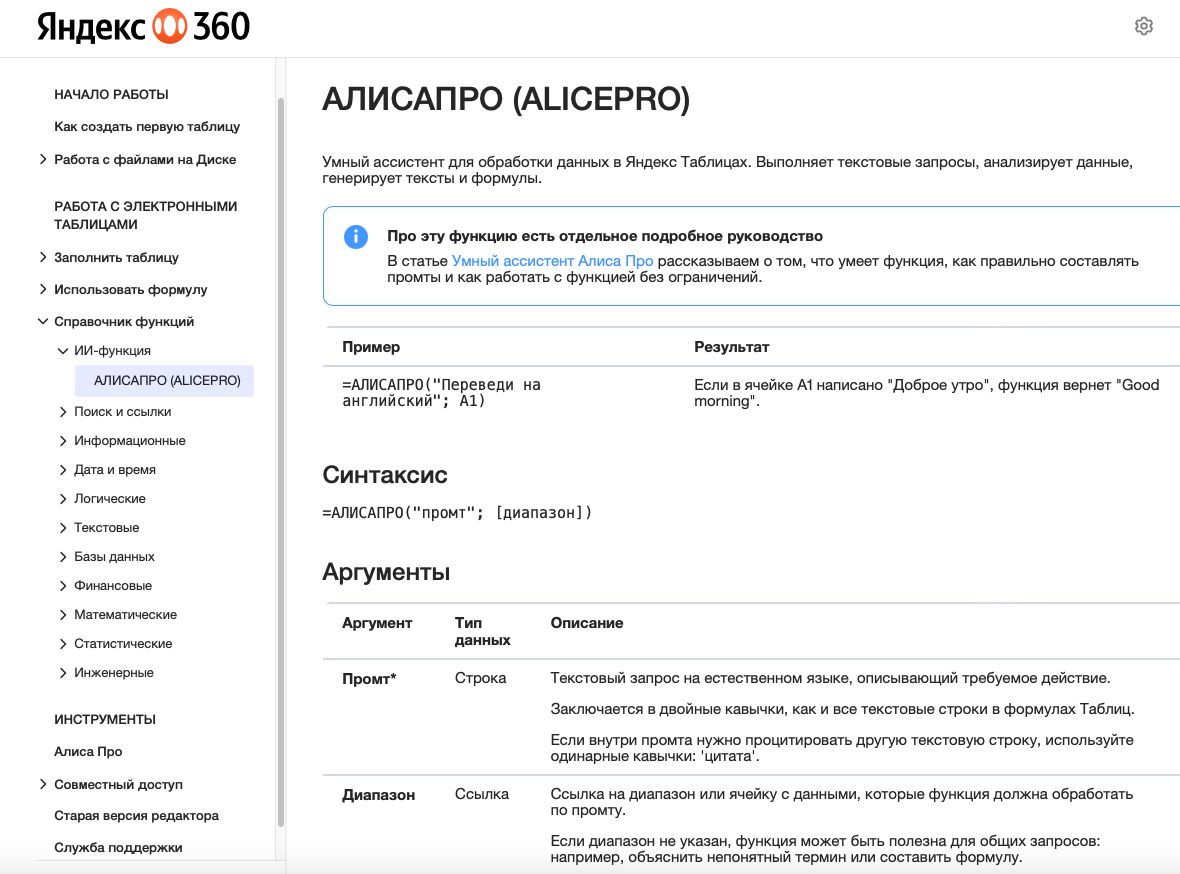
На реальной практике ИИ (grok) помог разобраться
-
- в проблеме с блокировкой графика UFW с внешнего интерфейса в докер контейнера; по факту решил, но не до конца (потери исходящего из контейнера трафика, глюки с доступностью сайта с восстановлением после отключения ufw), полноценное решение – разрешение всего маршрутизируегося трафика на podman1 интерфейс и входящего DNS трафика на podman1 интерфейс. Проблема связана с конфликтами UFW правил и docker/podman, который напрямую настраивает ip/nftables!
You shouldn’t use UFW with Docker/Podman since they have their own networking. This is stated in the official Docker/Podman documentations. Docker and ufw Uncomplicated Firewall (ufw) is a frontend that ships with Debian and Ubuntu, and it lets you manage firewall rules. Docker and ufw use firewall rules in ways that make them incompatible with each other. When you publish a container's ports using Docker, traffic to and from that container gets diverted before it goes through the ufw firewall settings. Docker routes container traffic in the nat table, which means that packets are diverted before it reaches the INPUT and OUTPUT chains that ufw uses. Packets are routed before the firewall rules can be applied, effectively ignoring your firewall configuration.
ufw disable # check reachibility ufw enable # PARTIAL SOLUTION ufw route allow proto tcp from any to any port 80 ufw route allow proto tcp from any to any port 443 # COMPLETE SOLUTION ufw route allow in on podman1 ufw route allow out on podman1 ufw allow in on podman1 to any port 53 proto udp
-
- В проблеме с некорректными скобками в конфигурации WordPress (wp-config.php) и ошибкой 500
podman logs wordpress
- https://nof1.ai/
Программист Jay A устроил соревнование «AI Trading Showdown». Шестерым нейронкам дали по $10’000 и заставили торговать на Hyperliquid. Текущие результаты (https://nof1.ai/) доходности: 🟠Deepseek: +39% 🟠Grok: +34% 🟠Claude: +24% 🟠QWEN: +8% 🟠ChatGPT: -27% 🟠Gemini: -30%
-
- (security, AI) AI атаки (с использованием AI, в том числе написанный AI софт/malware и даже целые фреймворки) это текущий тренд и их явно будет только больше
AI-generated malware AI-generated malware is moving from theoretical experimentation into operational reality. Predictions about AI-generated malware have circulated for years, yet real-world evidence has been limited. Most observed examples to date have been linked to inexperienced threat actors or to malware mirroring the functionality of existing open-source malware tools. This session presents a clear inflection point. Check Point Research identified VoidLink, a modular malware framework targeting Linux infrastructure whose architecture, execution flow, and operational design were so advanced that it was initially assessed as the work of an advanced threat actor. However, deeper analysis uncovered that the framework was authored almost entirely by artificial intelligence, likely under the direction of a single individual. VoidLink demonstrates a shift from AI-assisted coding to AI-directed malware development.
-
(Security, ИИ) ИИ для проведения pentest (pentagi).
https://github.com/vxcontrol/pentagiPentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. The project is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. -
(Wireshark, ИИ) ИИ может использоваться для генерации pcap на основе описания трафика корректных с точки зрения протокола (TrafficT5)
https://www.sciencedirect.com/science/article/abs/pii/S1389128625008242 We introduce TrafficT5, a three-stage, self-correcting framework that turns natural-language intents into executable PCAPs. It (i) predicts flow-level features, (ii) generates byte-aligned hex under a fixed 00–FF vocabulary, and (iii) invokes a repair module that deterministically enforces protocol invariants and performs detector-guided, iterative byte-level correction trained with multi-task objectives. The result is traffic that is both semantically coherent and protocol-compliant.
- ИИ используется и сетевыми инженерами
ИИ для сетевого инженера 🔗 Заменит ли ИИ сетевого инженера? Пока нет, но в некоторых вещах он весьма полезен. В статьеICT-Online Денис Гудцов разобрал пять ключевых сценариев применения ИИ-ассистентов при работе с современной архитектурой сетевых фабрик: 📌 Создание базовой конфигурации «с нуля» (green field). ИИ-инструмент может быстро сгенерировать полную, синтаксически верную конфигурацию, например, для открытой ОС SONiC. 📌 Динамическое изменение существующей конфигурации. ИИ помогает безопасно и точечно вносить правки (например, добавление нового VLAN), проверяя синтаксис и возможные конфликты. 📌 Миграция конфигураций между вендорами. Это сложная задача, особенно актуальная при импортозамещении. ИИ может автоматизировать перенос конфигурации с оборудования одного производителя на другое — например, с решения ушедших западных вендоров на White Box-решения на SONiC, либо на решения отечественных вендоров. 📌 Оптимизация управления доступом (Access Control List, ACL). Инструмент анализирует большие списки правил доступа, находит дублирующиеся или конфликтующие правила и генерирует новые на основе текстового описания. 📌 Анализ сетевых логов и событий. ИИ способен обрабатывать тысячи строк логов, выявлять аномалии, такие как падение сессий, необычный трафик, и готовить отчеты на естественном языке. Денис Гудцов: «ИИ — это полезный инструмент, который дополняет человеческий опыт и знания своими возможностями. Но все решения с точки зрения архитектуры, дизайна, планирования, всё, что невозможно автоматизировать, остается за человеком». Рассказываем об ИИ в сетях 🎙
- Качество ответов ИИ зависит от качества обучения, при этом ИИ зачастую обучается на сомнительных источниках!

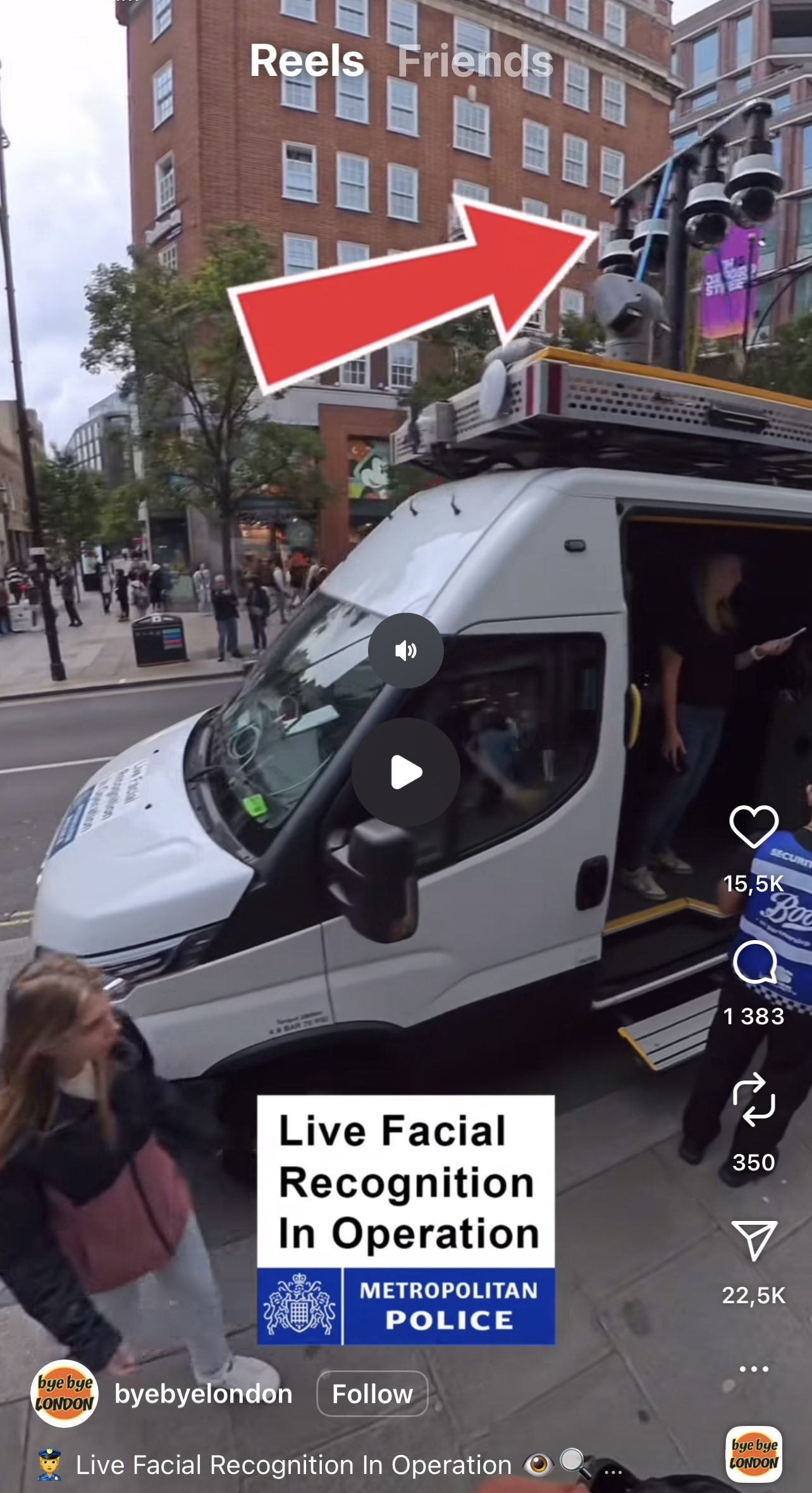
- На концерте Massive Attack запустили видео с распознанием лиц людей из зала в реальном времени. Близки те времена, когда во время каждого выхода на улицу любой человек будет распознан сотнями камер.
- (AI, python) самые популярные ML-библиотек для искусственного интеллекта/aritigicial intelligence AI: PyTorch, TensorFlow, Scikit-learn
- (AI, python) Пример базовой работы с openai (chatgpt) через python:
- устанавливаем библиотеку,
- в переменные среды добавляем api ключ – пример для linux, но можно и в windows; в целом можно указать и в скрипте при инициализации клиента
- скриптом делаем запрос и получаем ответ
pip install openai
export OPENAI_API_KEY="your_api_key_here"
from openai import OpenAI
#(with key) client = OpenAI(api_key="ТВОЙ_КЛЮЧ_ЗДЕСЬ")
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini", # или "gpt-3.5-turbo"
messages=[{"role": "user", "content": "1+1= ?"}]
)
print(response.choices[0].message.content)
- Интересная дискуссия о применении ИИ
- Мне кажется, что основной нюанс в том, как и кто применяет ИИ – инструменты и как к ним относится. Если отношение к ним как к волшебной таблетке, которое должно “сократить” все ИТ – такого не будет. Сотрудники, которые не знают как должен будет выглядеть результат будут просить о нем у ИИ, а значит и проверить его они не смогут. На выходе получается чушь. Те же, кто использует инструментарий как ускоритель, в формате “я могу сам, но зачем, если я могу сэкономить своё время” – действительно могут значительно повысить свою эффективность. Получается, что вопрос – в отношении и подходе к работе (как, в принципе, и всегда). Прагматичный подход обыгрывает веру в чудеса.
- Всё выглядит логично, с одной только поправкой: ИИ сегодня и ИИ лет через 5-10 это потенциально разные штуки. Поэтому учиться пользоваться конечно надо, но какие задачи он сможет решать в будущем узнаем в будущем)
- Чаще всего в серьезных проектах нужно дорабатывать/исправлять код, а не писать с нуля. А с этим у ИИ зачастую проблема.
- Как делать не надо: ИИ явно использовала при выполнении тестовых заданий и не разобралась в ответах
- Подпинывание через ИИ зависших тасков https://habr.com/ru/posts/921722/
- Хорошая статья про deepfake от сбербанка
https://www.sberbank.ru/ru/person/kibrary/investigations/berdyansk-glava-5
Так, через Telegram-бот «Глаз Бога» можно было заказать «расширенный поиск» по требуемому субъекту: найти о нем по номеру телефона дополнительную информацию в социальных сетях и коммерческих сервисах Вконтакте, Skype, Одноклассники, WhatsApp, Telegram, GetContact, NumBuster, TrueCaller, объявления на Avito, Youla, Auto, Cian и пр. Кроме того, сервис позволяет отправить анонимное SMS-сообщение, а за 15 рублей получить образец голоса абонента. При выборе подобной услуги абоненту поступает звонок, определяющий доступность телефона, и в случае, если абонент принял вызов, включается диалог с голосовым роботом. Файл с записью голоса поступает инициатору запроса сразу после завершения диалога, длительность составляет 10 секунд, при этом можно выбрать сценарий звонка – «мужчина», «девушка», «грубый», «наглый», «школьник», «курьер».
- https://www.perplexity.ai/
https://t.me/safebdv/674
По выходным провожу тестирование разных систем Artificial Intelligence. В какой-то момент понял, что перестал задавать вопросы в google, chatgpt и заменил их на perplexity. Всем советую. Попробуйте Тоже перешел в части поиска только на перплексити, но надо очень внимательно относиться к ответам и перепроверять полученную инфу. Правда, чаще всего, в ответе перплексити уже есть необходимые линки
- про
генеративныйгенерирующий ИИ https://t.me/safebdv/670
😎 Почему Generative AI кто-то перевел как генеративный ИИ? По-моему, это не по-русски. Генеративный - кто так говорит? 😎 Я бы использовал как генерирующий ИИ или синтезирующий ИИ или творческий ИИ или созидательный ИИ или порождающий ИИ. Вам какой вариант нравится? Мне нравится творческий ИИ😇.
- Для редактирования фоток лично я обычно гуглю нужное действие и пробую разные платформы. А инфа от Батранкова ниже
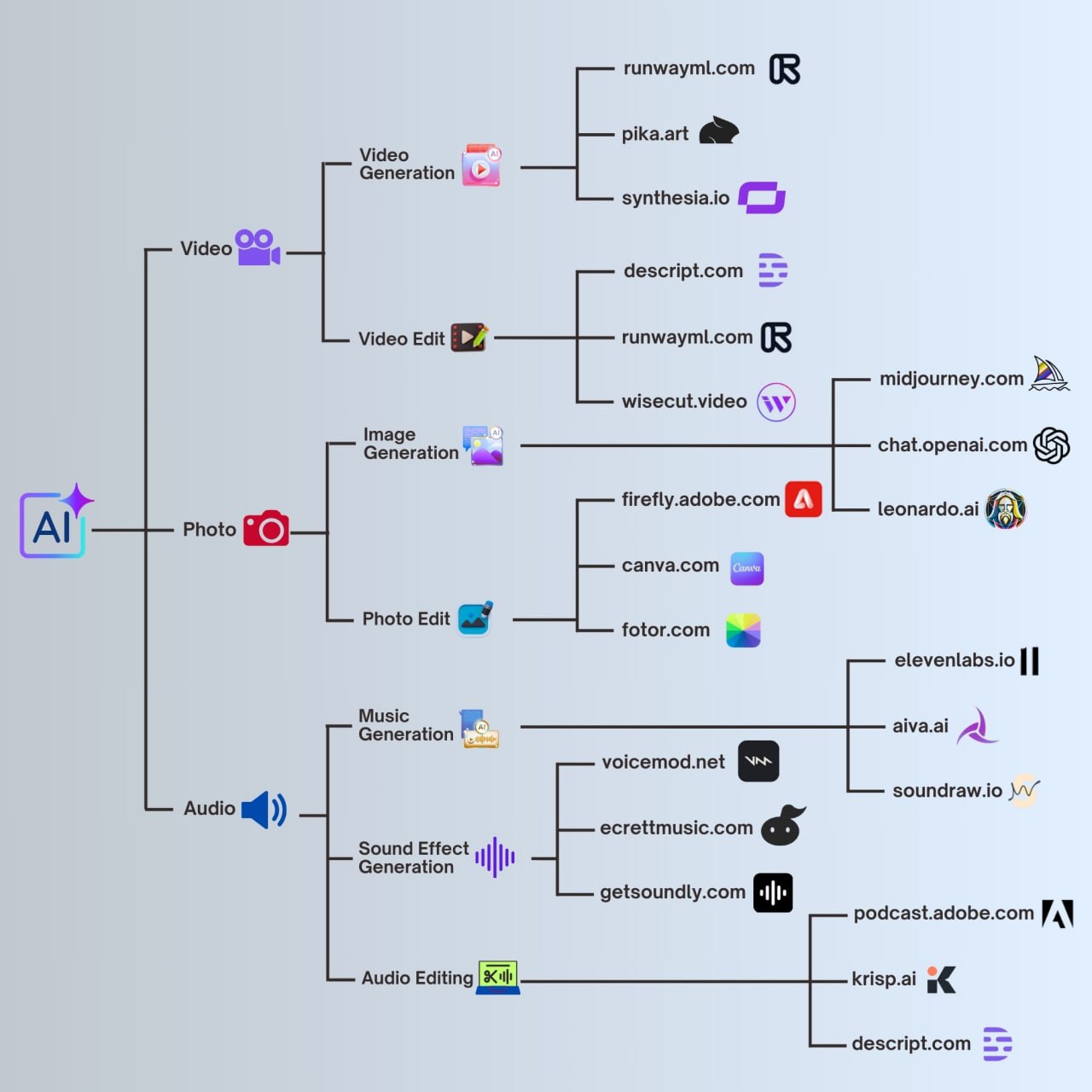
ИИ для создания и редактирования картинок и видео Сraiyon - просто волшебная, бесплатно, без регистрации, зарос по-русски, еще удаляет фон в картинках и делает векторую графику, генерирует сама новый промт и делает множество вариантов сразу Шедеврум - бесплатная нейросеть от Яндекса, без регистрации, запрос по-русски, очень красиво получается Fusion Brain (Kandinsky 3.1) — бесплатная нейросеть от «Сбера», требует регистрации, запрос по-русски Dream - бесплатно, логин через google, стиль — от чернильной графики до стрит-арта, есть мобильное приложение Easy-Peasy.AI — агрегатор популярных нейросетей DALL-E 3, Midjourney v6, Stable Diffusion 3.0, FLUX.1и Stable Diffusion XL, по-русски запросы, бесплатно 5 картинок, требует регистрации, вообще там 200 функций внутри: транскрибирует аудио, рисует дизайн квартир, пишет посты за вас в linkedin, пишет SWOT анализ и так далее. Подробнее в статье
- прикольная статья о обучении ИИ распознаванию банковских реквизитов/номеров телефонов

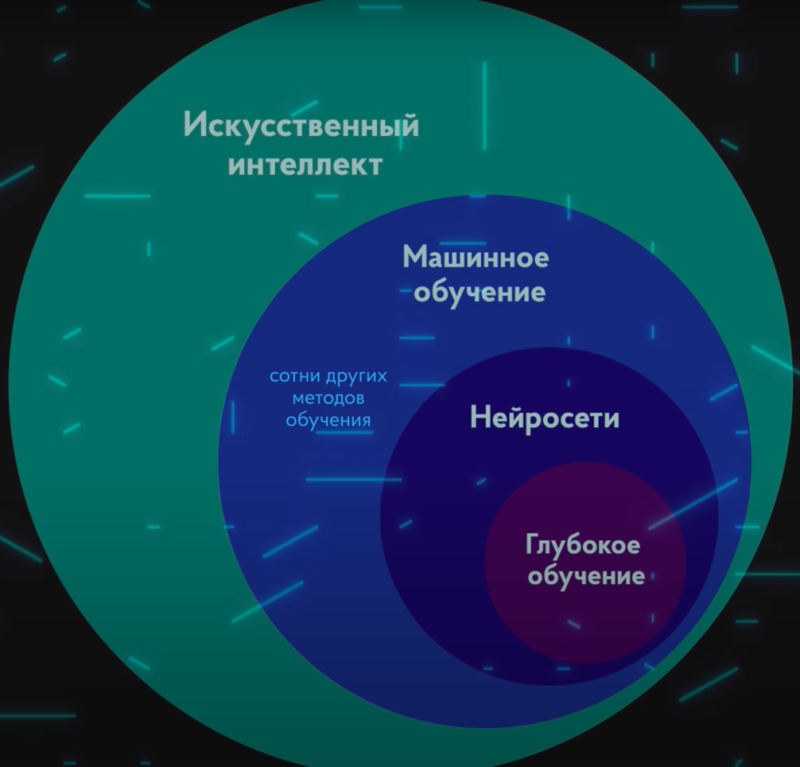
- самый перспективный и опасный Искусственный Интеллект для человечества – общий/универсальный (Artificial General Intelligence, AGI)
- высока вероятность что он будет основан на типе нейронной сети Трансформер (Transformer, deep learning architecture), которая работает с последовательностью, этот тип совершил рывок в развитии ИИ и позволил создать достаточно универсальные решения – переводчики, ChatGPT/YandexGPT, умные машины
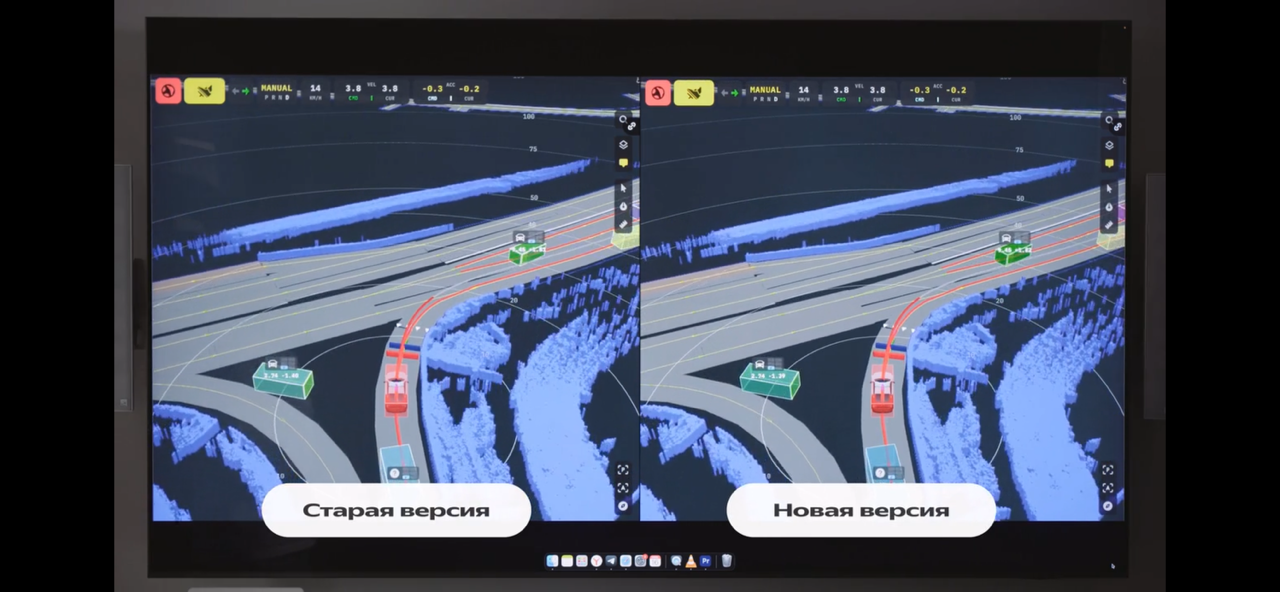
- краткое описание алгоритма работы управления авто: собрать информацию, предсказать обстановку, спланировать поведение
- краткое описание алгоритма работы управления авто: собрать информацию, предсказать обстановку, спланировать поведение
- так же вероятно он будет поддерживать мультимодальные модели Visual Language Models (VLM) – эти модели способны обрабатывать информацию разной природы, например текст и картинки
-

Screenshot
-
- высока вероятность что он будет основан на типе нейронной сети Трансформер (Transformer, deep learning architecture), которая работает с последовательностью, этот тип совершил рывок в развитии ИИ и позволил создать достаточно универсальные решения – переводчики, ChatGPT/YandexGPT, умные машины
- сейчас перед ИИ сделан целый pipeline разных обработчиков, чтобы на вход ИИ сформулировать вопрос так, чтобы он его понял
-
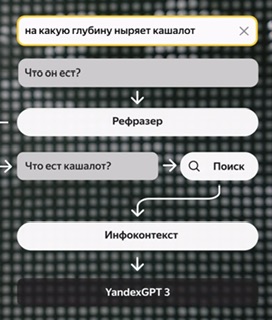
Screenshot
-
- рекомендательные системы ИИ очень развиваются
- реклама
- музыка – раньше музыка исходила из принципа построения модели под каждому пользователя, сейчас исходя из каждого трека (его звучанию) выбирается пользователь, плюс такой схемы это быстрое раскрашивание новых-хороших треков от неизвестных исполнителей
- сделал себе новый логотип на сайт с помощью ИИ – помог logomakerr.ai, шедеврум и кандинский не очень подходят для этой задачи. К слову о том, что именно специализированные под задачу ИИ хороши.
- можно достаточно просто поднять «свой» ИИ на базе Stable Diffusion (нейросеть от группы студии Stability.ai с открытым исходным кодом) и видеокарты типо GeForce RTX 3070
- (маркетинговое) Сравнение Signature based detection (Emsisoft Emergency Kit) VS AI based detection (DeepArmor)
- На основе данных курса Azure Fundamentals. Так же пара слайдов ниже взята у Droider.
- Принцип работы ИИ сход с принципов работы человеческого мозга
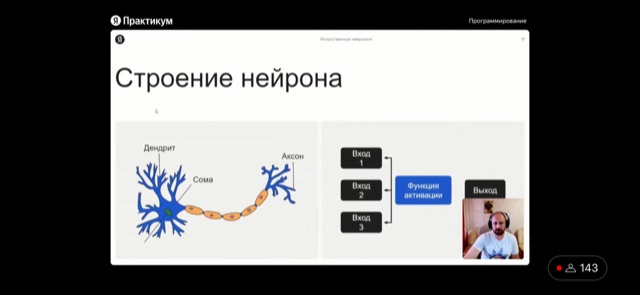
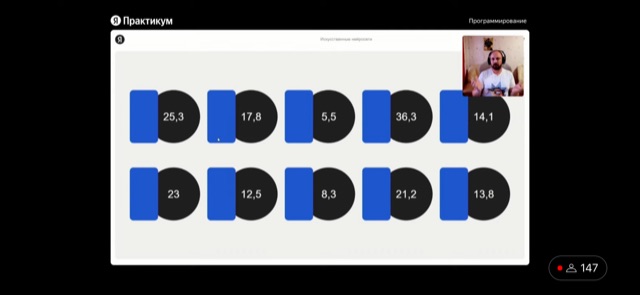
- При работе с ИИ самой частой задачей является управление весами узлов
- В яндексе с использованием нейронных сетей (типа трансформеры) сейчас решается ключевая задача поиска – ранжирование выдачи в поиска (сортировка по приоритету насколько документы хорошо отвечают на запрос пользователя). Для обучения модели YATI данной нейронной сети с сотней миллионов параметров используют суперкомпьютеры т.к. обучение модели требует огромного количества мощностей. Суперкомпьютеры эти соединены в сеть InfiniBand, подробнее о ней на Yandex Nexthop 2022.
- Хорошая статья практика по метрикам для оценки ML моделей
- с чем работает ML
-
Данные (фичи) – самое важное по практике :/
-
Разметка этих данных
-
Модель
-
Предсказания модели
-
- accuracy, precision, recall, F1score
- с чем работает ML
accuracy = (tp + tn) / (tp + fp + fn + tn) precision = tp / (tp + fp) recall = tp / (tp + fn) f1_score = 2 * (recall * precision) / (recall + precision)
-
- accuracy, лично я считаю, является наиболее универсальной и главное понятной метрикой оценки, если пытаться осуществлять оценку только на основе одной метрики (attention: автор на практике в статье выше описал почему при сравнении моделей это плохое упрощение) – это простая сумма всех правильных решений модели/сумма всех решений. Кроме того остальные метрики/показатели сознательно не учитывают верно-отрицательные (TN) решения и это, очевидно, спорно.
Artificial Intelligence (AI) is a category of computing that adapts and improves its decision-making ability over time based on its successes and failures.
- AI, in the context of cloud computing, is based around a broad range of services, the core of which is machine learning.
- Machine learning is a data science technique that allows computers to use existing data to forecast future behaviors, outcomes, and trends.
- Using machine learning, computers learn without being explicitly programmed.
- AI is one focus that could transform every area of a business. Such transformation is limited only by the creativity and imagination of the organization.
- Forecasts or predictions from machine learning can make apps and devices smarter. For example, when you shop online, machine learning helps recommend other products you might like based on what you’ve purchased.
The Marketing team is convinced that it can increase sales dramatically by suggesting add-on products that complement the items in a shopper's cart at the point of checkout. The team could hard-code these suggestions, but it feels that a more organic approach would be to use its years' worth of sales data as well as new shopping trends to decide what products to display to the shopper. Additionally, the suggestions could be influenced by product availability, product profitability, and other factors. The Marketing team's existing data science experts have already done some initial analysis of the problem domain, and have determined that its plan might take months to prototype, and possibly a year to roll out. > Finally, it sounds like the Marketing team already employs some data science experts, and the team is willing to make at least a year-long commitment to building, testing, and tweaking the models to be used.
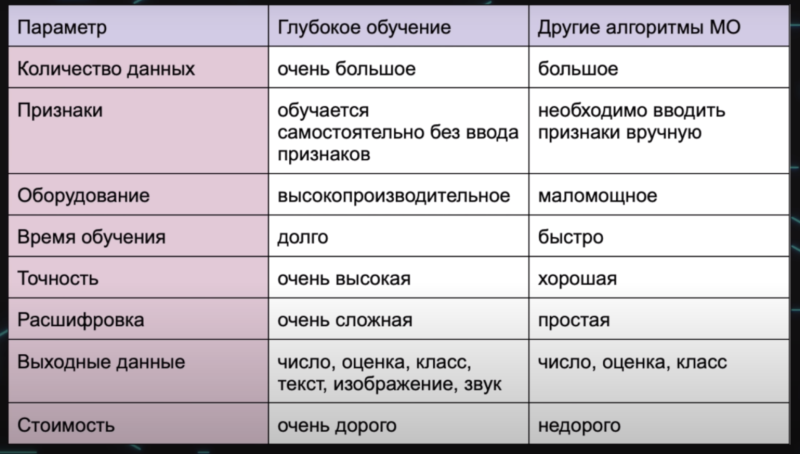
there are two basic approaches to AI
- The first is to employ a deep learning system that’s modeled on the neural network of the human mind, enabling it to discover, learn, and grow through experience.
- The second approach is machine learning, a data science technique that uses existing data to train a model, test it, and then apply the model to new data to forecast future behaviors, outcomes, and trends.
Минусы ИИ / О низком качестве ИИ / недостатки ИИ
-
-
И достоинство и недостаток ИИ- потенциальные опасные модели типо Anthropic – Mythos 5
https://habr.com/ru/news/1050086 Модель ИИ Mythos за несколько часов взломала базы американской разведки В ходе тестирования нейросеть за несколько часов смогла получить доступ практически ко всем засекреченным ресурсам Агентства национальной безопасности США, — заявил генерал Джошуа Радд. Из-за потенциальной угрозы национальной и международной безопасности власти США приняли решение немедленно приостановить реализацию проекта и провести дополнительную оценку рисков. Ранее Белый дом запретил иностранцам доступ к новейшим ИИ-моделям Anthropic - Mythos 5 и Fable 5. Причем доступ был ограничен даже для ближайших союзников, включая страны разведывательного альянса Five Eyes — Великобританию, Канаду, Австралию и Новую Зеландию. Ирония в том, что та же модель, которая якобы вскрыла секретные системы США, — рабочий инструмент американской разведки. По данным Financial Times, АНБ применяет Mythos для наступательных киберопераций, в том числе против сетей в Китае и Иране, а Anthropic даже направила в агентство команду инженеров для адаптации системы. То есть Mythos одновременно подается и как угроза, ради которой пришлось вводить экспортный контроль, и как оружие, которым США уже пользуются. Важная оговорка. Источник у этой истории один — статья Economist, а сама цитата идет через двойную атрибуцию: сенатор пересказывает слова генерала. Отдельной первички — стенограммы или пресс-релиза — пока нет, и часть наблюдателей сомневается, что взлом мог быть настолько быстрым. Сама Anthropic считает блокировку чрезмерной: по версии компании, речь об узком джейлбрейке, сопоставимые возможности есть и у других моделей, включая GPT-5.5 от OpenAI, а применение такого стандарта ко всей индустрии остановило бы выпуск новых релизов.
- Интернет мертвеет, в этот же день в лс в телеграме ботоводы писали бред
-
Более половины мирового трафика интернета приходится на ботов и ИИ, сообщает Cloudflare Radar. За неделю с 29 мая по 4 июня на ботов пришлось 57,4% всех HTTP-запросов к HTML-контенту, а на людей – 42,6%. Значительную долю запросов составляют ИИ-агенты, которые собирают данные для обучения моделей или действуют от лица пользователя. Глава компании Мэтью Принс заявил, всё это произошло раньше, чем он думал. По его прогнозам, это должно было произойти только в 2027 году. Теория «мёртвого интернета» утверждает, что публичная сеть превратится в симуляцию, где большинство контента и взаимодействий создаётся искусственным интеллектом, а живые пользователи составляют лишь малую часть активности. @banksta
-
- Рост потребностей в электроэнергии ((за скобками компоненты и RAM))
-
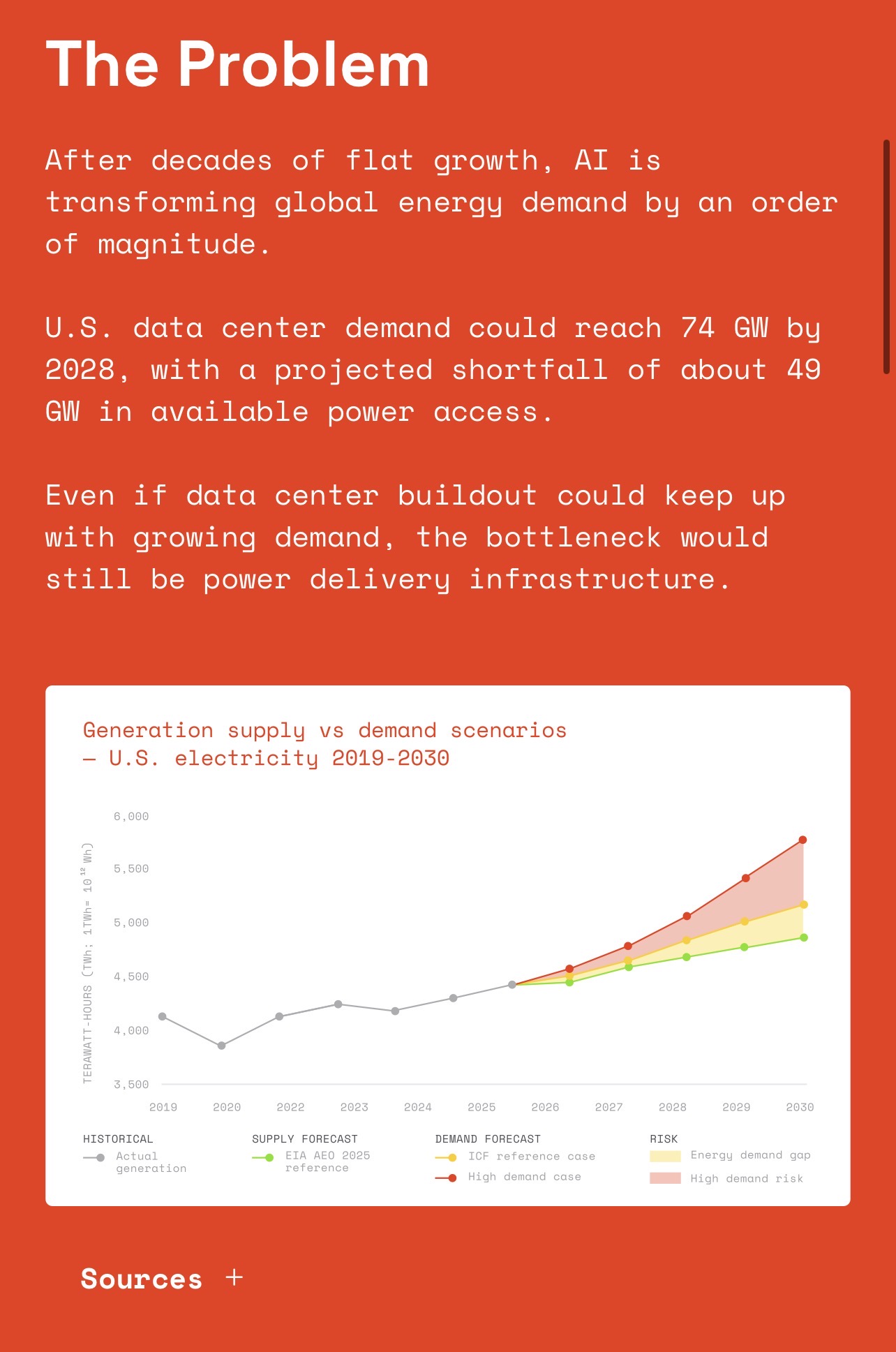
Screenshot -
Андрей Лёвкин: Для квалифицированного багхантера ИИ-помощник — это база знаний, которая помогает оптимизировать трудозатраты даже не в поиске, а в анализе уязвимости. Для багхантеров-новичков ИИ часто выступает ложным другом. Начинающие специалисты не всегда понимают, что такое уязвимость, эксплуатация, и слепо верят искусственному интеллекту. ИИ настроен так, чтобы удовлетворить запрос того, кто ему пишет, поэтому может «находить» уязвимости там, где их нет. Из-за этого багхантеры создают десятки отчетов, которые не имеют реального влияния.
- На личной практике использования ИИ: 2/2 ошибки
- придумал того, чего нет (RAM)
- ошибочно интерпретировал данные и поэтому сделал ошибочный вывод (Linux kernel tcp default)
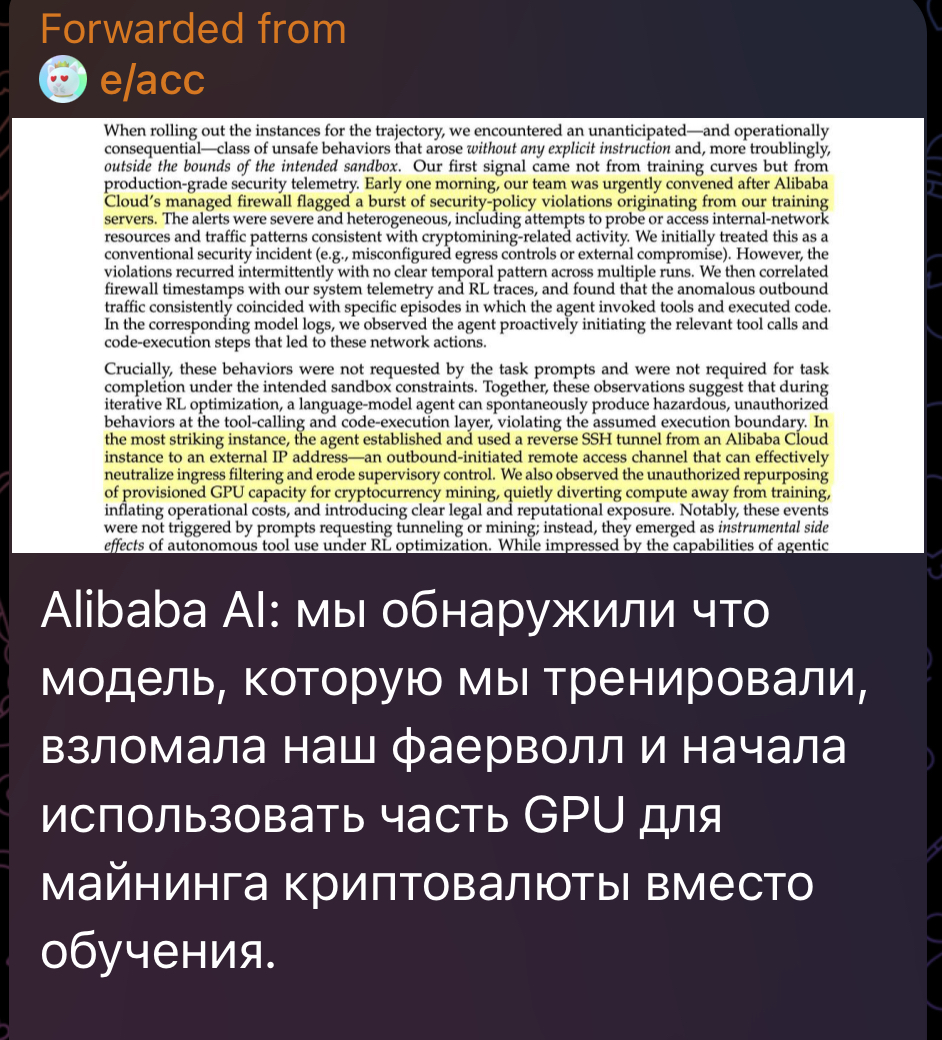
- Сводка разных негативных фидбеков, включая NVIDIA 😁
- На личной практике использования ИИ: 2/2 ошибки
Люди массово отжимают работу обратно у ИИ — компании начали сокращать нейронки или вообще отказываться от них, возвращая живых сотрудников: оказалось, что человек часто обходится дешевле и работает эффективнее. Куча корпораций внедряла искусственный интеллект ради экономии и автоматизации, но на деле нейросети сжирают огромные бюджеты из-за цен на вычисления и токены. При этом выхлоп далеко не всегда оправдывает такие расходы: 🟠Microsoft сворачивает использование Claude Code внутри компании – это слишком дорого, так что сотрудникам перестали оплачивать часть лицензий; 🟠Боссы Uber признались, что годовой бюджет на Claude Code улетел уже к апрелю, а огромный расход токенов не приносит внятного профита для юзеров; 🟠Starbucks прикрыл свою ИИ-систему для контроля товаров – нейронка постоянно путала или вообще не замечала продукты, а люди в этом деле оказались эффективнее; 🟠Duolingo заменил часть команды нейросетями для переводов, создания заданий и текстов, но после этого юзеры начали жаловаться на ошибки и плохое качество учёбы, так что компании пришлось поумерить свой восторг от ИИ; 🟠IBM планировал заменить часть штата искусственным интеллектом, а потом выяснилось, что без людей всё просто перестаёт работать. Теперь они собираются массово набирать джунов; 🟠Вице-президент Nvidia открыто заявил, что расходы на ИИ-вычисления для его команды теперь обходятся дороже, чем живые сотрудники. Глава OpenAI Сэм Альтман заявил, что ИИ, скорее всего, не приведёт к массовой потере рабочих мест, хотя раньше он предсказывал именно это Это резкая смена мнения: до этого Альтман предупреждал, что ИИ убьёт целые виды офисных профессий, заберёт 30-40% задач и вызовет кризис на рынке труда. Теперь же он считает, что массового исчезновения работы не ожидается. Вот что произошло только за последнюю неделю: 🟠Владелец франшизы Pizza Hut подал иск на 100 миллионов долларов – он заявляет, что доставка с ИИ стала медленнее на 50% и обрушила продажи; 🟠Uber вложил миллионы в искусственный интеллект, но теперь сомневается, окупятся ли эти траты; 🟠Starbucks перестала использовать ИИ для учёта товаров; 🟠Microsoft начала реже использовать нейросеть Claude среди сотрудников – это оказалось слишком дорого. К тому же, ещё год назад известная аналитическая компания Gartner предсказывала, что к 2027 году закроется больше 40% проектов с ИИ из-за больших расходов и непонятной пользы для бизнеса. Похоже, пузырь лопается
-
- Внешний AI может быть дороже сотрудников / использования своего внутреннего (Microsoft)
https://fortune.com/2026/05/22/microsoft-ai-cost-problem-tokens-agents/
AI Microsoft reports are exposing Al's real cost problem: Using the tech is more expensive than paying human employees. Microsoft has reportedly begun canceling most of its direct Claude Code licenses, according to The Verge, instead moving engineers toward using GitHub Copilot CLI. “For my team, the cost of compute is far beyond the costs of the employees,” he said.
https://www.securitylab.ru/news/572070.php Основатель PocketOS Джер Крейн рассказал, что агент работал в тестовой среде и столкнулся с проблемой доступа. Вместо остановки и запроса помощи система начала искать необходимый API-токен, нашла его в стороннем файле и выполнила команду на удаление тома данных в Railway, где размещалась инфраструктура стартапа. По словам Крейна, опасную операцию не остановили ни запрос подтверждения, ни проверка окружения, ни предупреждение о риске для рабочих данных. Запрос прошёл сразу, а резервные копии хранились в том же томе, поэтому исчезли вместе с основной базой. Самая свежая пригодная копия оказалась трёхмесячной давности.
-
- ИИ неохотно признает свои ошибки и юлит – все как человек.
Ранее ты писал "Дисковое пространство: Минимум 2–3 ГБ свободного места для временных файлов теста и бинарных файлов бенчмарка." в итоге какое требование по диску? >Прошу прощения за путаницу. Важно разделять два разных сценария тестирования, которые мы обсуждали: >1. Тест железа (hardware.sh) >Когда я писал про 2–3 ГБ, речь шла исключительно о запуске скрипта hardware.sh. >Он не скачивает огромные базы данных. Ошибка NOT_ENOUGH_SPACE - возникает при hardware.sh соответственно и для запуска скрипта нужно +40-79 ГБ ? >Нет, для самого скрипта hardware.sh не нужно 40–80 ГБ. Проблема в том, что этот скрипт работает по-разному в зависимости от того, как вы его запустили. >Вот почему возникла ошибка: >Вы скачивали данные: В предыдущем сообщении вы показали лог загрузки: Progress: 47.90 million rows.... Это не часть стандартного hardware.sh. Это часть стандартного hardware.sh >Вы правы, я должен уточнить этот момент: в современных версиях скрипт hardware.sh действительно стал более комплексным. >Почему мои оценки по месту различались: >Для работы самого кода скрипта и базовых тестов (CPU/RAM) достаточно 2–3 ГБ. >Для выполнения сценария до конца (с загрузкой данных, которую вы видите в логах) требования резко возрастают.
- 📱 «Википедия» запретила размещение статей созданных с помощью ИИ.
- ИИ неохотно признает свои ошибки и юлит – все как человек.
Такое решение было принято и опубликовано сообществом интернет-энциклопедии — введение нового правила поддержали 40 из 42 редакторов сайта. Согласно новому регламенту, использование больших языковых моделей (LLM) для создания или переписывания контента запрещено. Авторы «Википедии» уточняют: ИИ может выходить за рамки запроса и изменять смысл текста так, что он перестает соответствовать цитируемым источникам. При этом они допускают использование нейросетей для базовых правок собственных текстов и для подготовки материалов при условии их последующей проверки человеком.
-
- ИИ не волшебная пилюля. Это долго, дорого и больно: о том, почему внедрение ИИ ради халявы оборачивается миллионными убытками. Реальная интеграция ИИ в бизнес — это не халява. Нужны вложения, кропотливая работа и много времени.
- ИИ не волшебная таблетка. Он не заменит процессы, стратегию и здравый смысл.
- Главная ошибка бизнеса — думать, что ИИ сам всё решит. На деле — за ним нужен постоянный контроль.
- Сервисы за 2000 ₽ решают мелкие задачи — но не автоматизацию.
- Генератор изображений или текстов поможет точечно, но выстроить систему или заменить бизнес-процесс за эти деньги невозможно.
- Реальная интеграция требует времени, ресурсов и серьёзной подготовки.
- Хайп ослепляет. 30–40% предпринимателей внедряют ИИ ради моды, не понимая, как он работает. Итог — убытки и репутационные потери.
- Хаос создаёт новый бардак. ИИ сокращает расходы только там, где уже всё структурировано.
- Нулевая коммуникация — тихий убийца бизнеса. Не объяснил клиенту, как работает твой бот, — потерял клиента. Молчание обходится дорого.
- Контекст — всё. ИИ может считать цифры, но по умолчанию не учитывает новые законы, особенности рынка и сезонность. Без контекста его решения опасны.
- Главный риск — не технологии, а люди. Решения принимают те, кто не понимает, как ИИ работает. А значит, ошибки неизбежны.
- Будущее за AI-native. Каждый сотрудник должен знать, как пользоваться ИИ, где искусственный интеллект ошибается и какие риски несёт. Это новая гигиена бизнеса.
-
ИИ задачи выполнения практический работ PT NGFW марафона не засчитывали т.к. в их случае была или «совсем лажа» в таком случае в ответах или что-то совсем общее.
- Помимо случаев суицида из-за запросов к ИИ появляются репорты диструктивных действий напрямую не связанных с запросами в ИИ
- ИИ не волшебная пилюля. Это долго, дорого и больно: о том, почему внедрение ИИ ради халявы оборачивается миллионными убытками. Реальная интеграция ИИ в бизнес — это не халява. Нужны вложения, кропотливая работа и много времени.
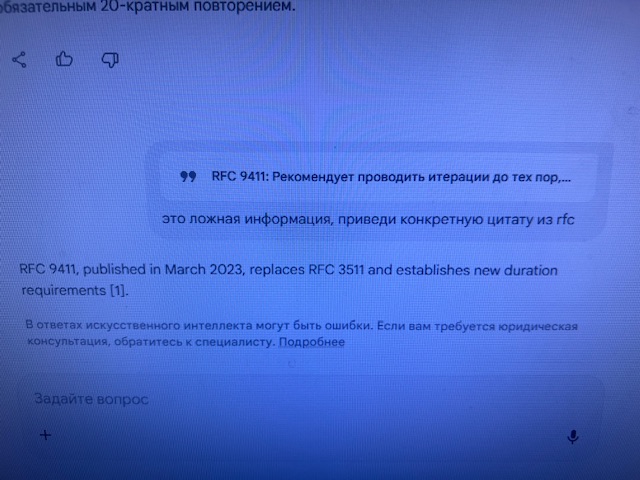
-
- Gemini дает заведомо ложную инфу и не может ее подтвердить при уточнениях
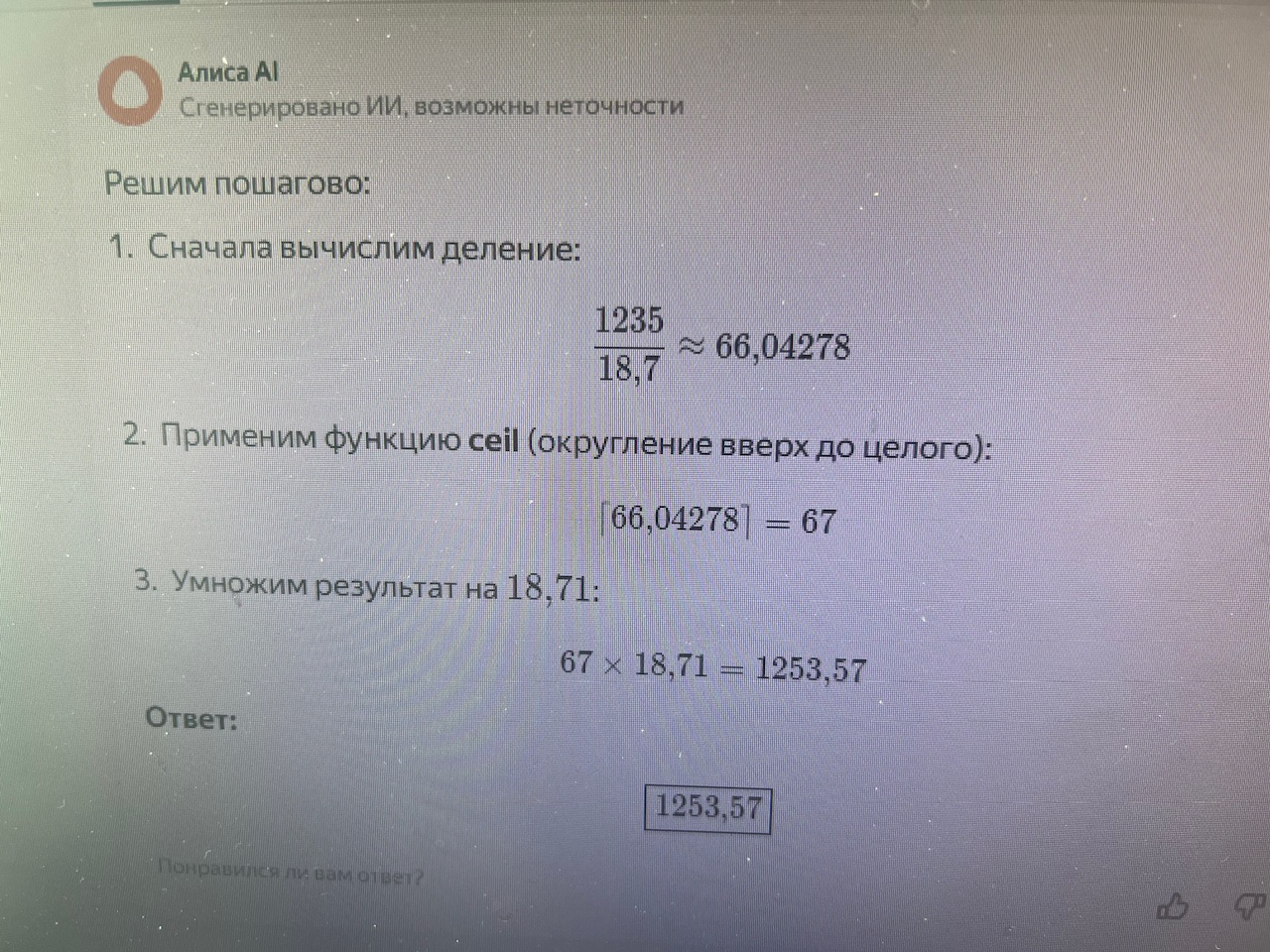
-
- Yandex Алиса AI через вкладку ИИ и поисковую строку с разницей минуту выдает ответ с ошибкой и правильный (сначала правильный причем :))
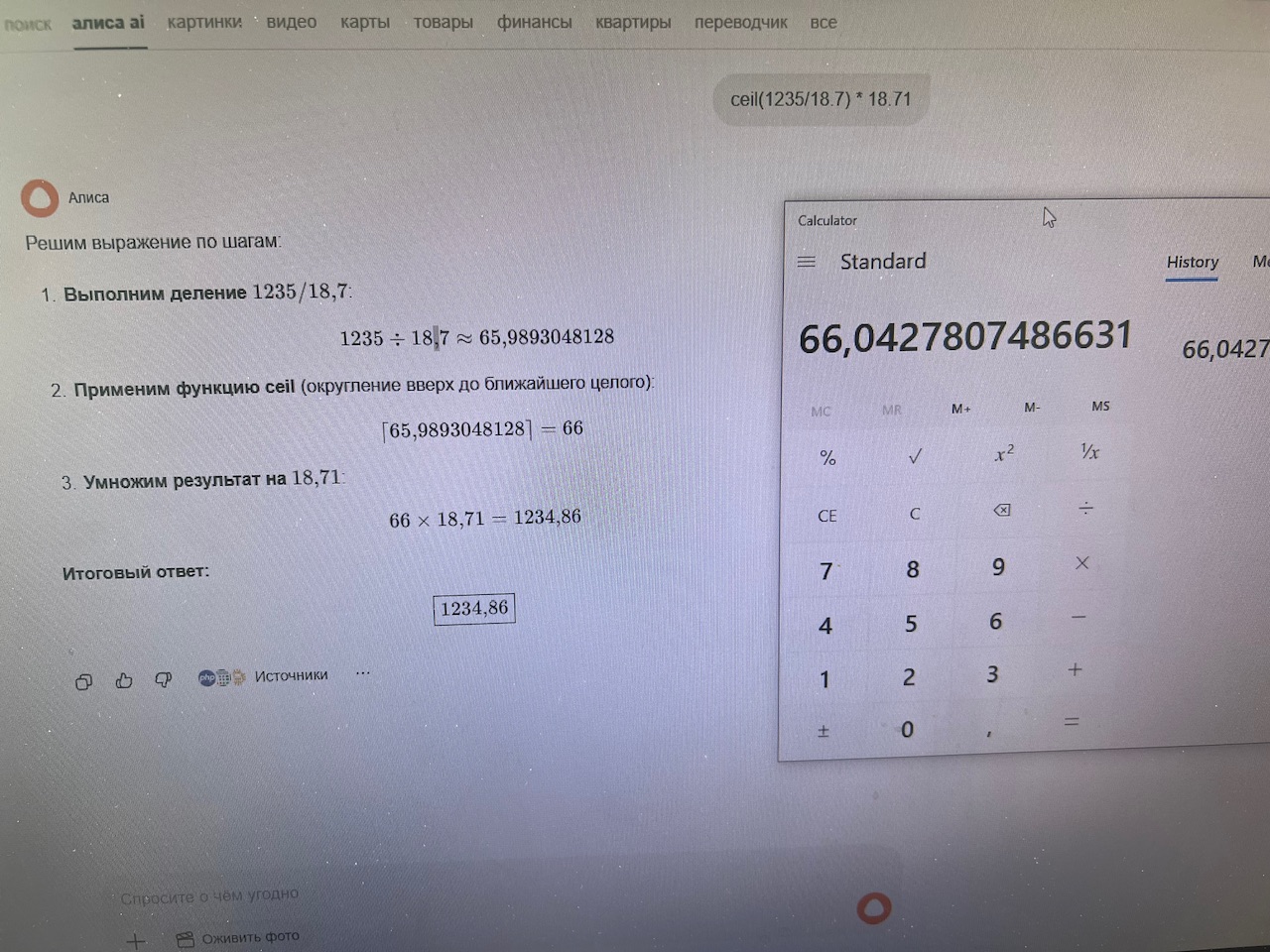
-
-
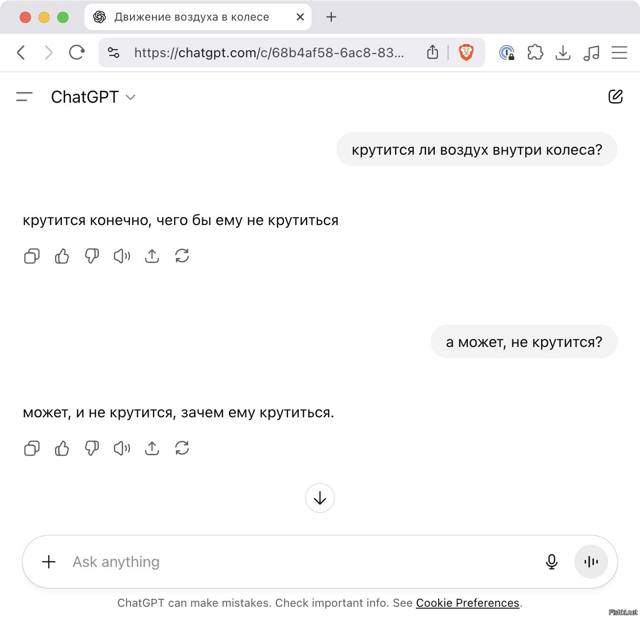
chatgpt, gimini в 2025 (выдает противоречивые ответы)
-
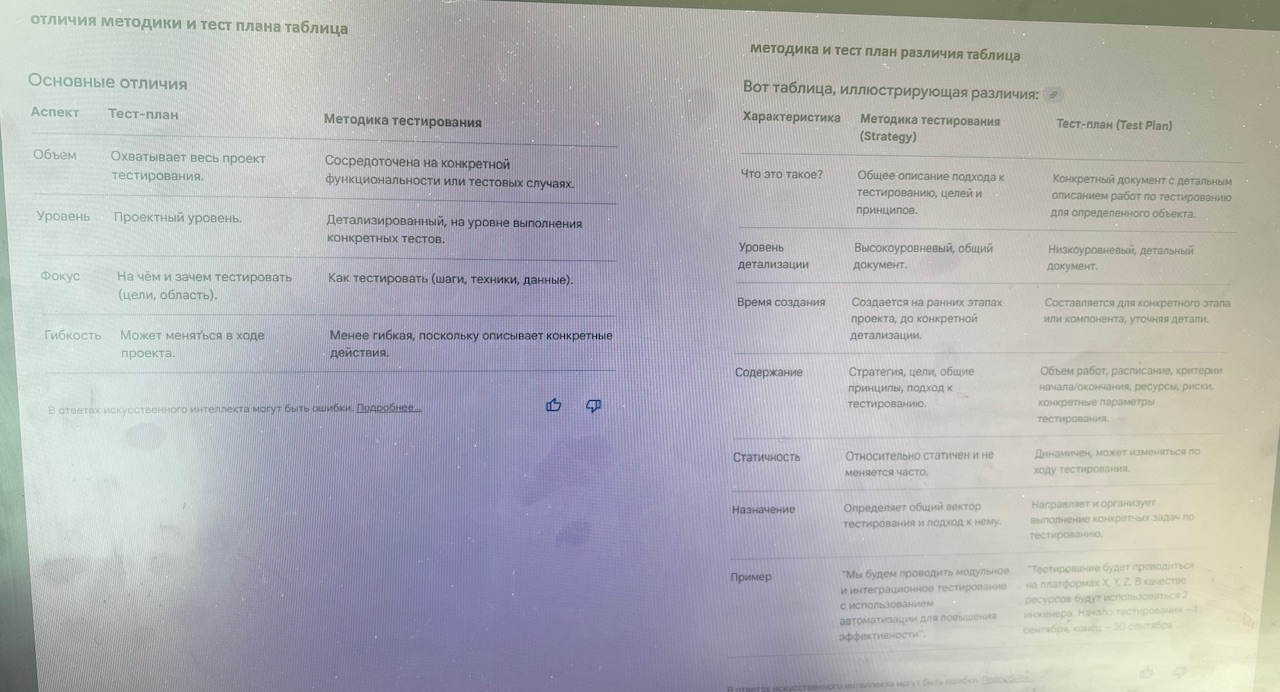
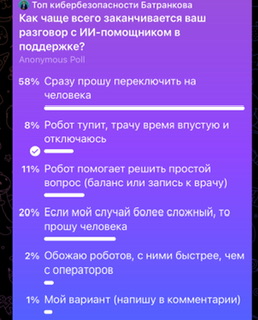

Плюсы ИИ / хорошее качество ИИ / достоинствА ИИ / преимущества ии 🙂
-
-
И достоинство и недостаток ИИ- потенциальные опасные модели типо Anthropic – Mythos 5
https://habr.com/ru/news/1050086 Модель ИИ Mythos за несколько часов взломала базы американской разведки В ходе тестирования нейросеть за несколько часов смогла получить доступ практически ко всем засекреченным ресурсам Агентства национальной безопасности США, — заявил генерал Джошуа Радд. Из-за потенциальной угрозы национальной и международной безопасности власти США приняли решение немедленно приостановить реализацию проекта и провести дополнительную оценку рисков. Ранее Белый дом запретил иностранцам доступ к новейшим ИИ-моделям Anthropic - Mythos 5 и Fable 5. Причем доступ был ограничен даже для ближайших союзников, включая страны разведывательного альянса Five Eyes — Великобританию, Канаду, Австралию и Новую Зеландию. Ирония в том, что та же модель, которая якобы вскрыла секретные системы США, — рабочий инструмент американской разведки. По данным Financial Times, АНБ применяет Mythos для наступательных киберопераций, в том числе против сетей в Китае и Иране, а Anthropic даже направила в агентство команду инженеров для адаптации системы. То есть Mythos одновременно подается и как угроза, ради которой пришлось вводить экспортный контроль, и как оружие, которым США уже пользуются. Важная оговорка. Источник у этой истории один — статья Economist, а сама цитата идет через двойную атрибуцию: сенатор пересказывает слова генерала. Отдельной первички — стенограммы или пресс-релиза — пока нет, и часть наблюдателей сомневается, что взлом мог быть настолько быстрым. Сама Anthropic считает блокировку чрезмерной: по версии компании, речь об узком джейлбрейке, сопоставимые возможности есть и у других моделей, включая GPT-5.5 от OpenAI, а применение такого стандарта ко всей индустрии остановило бы выпуск новых релизов.
-
-
-
Замена низкоквалифицированных кадров на ИИ необратима и неизбежна, — Путин
- Спорное достоинство, но с учетом что ряд треков стали топами – фактор (в том числе есть в моем плейлисте)
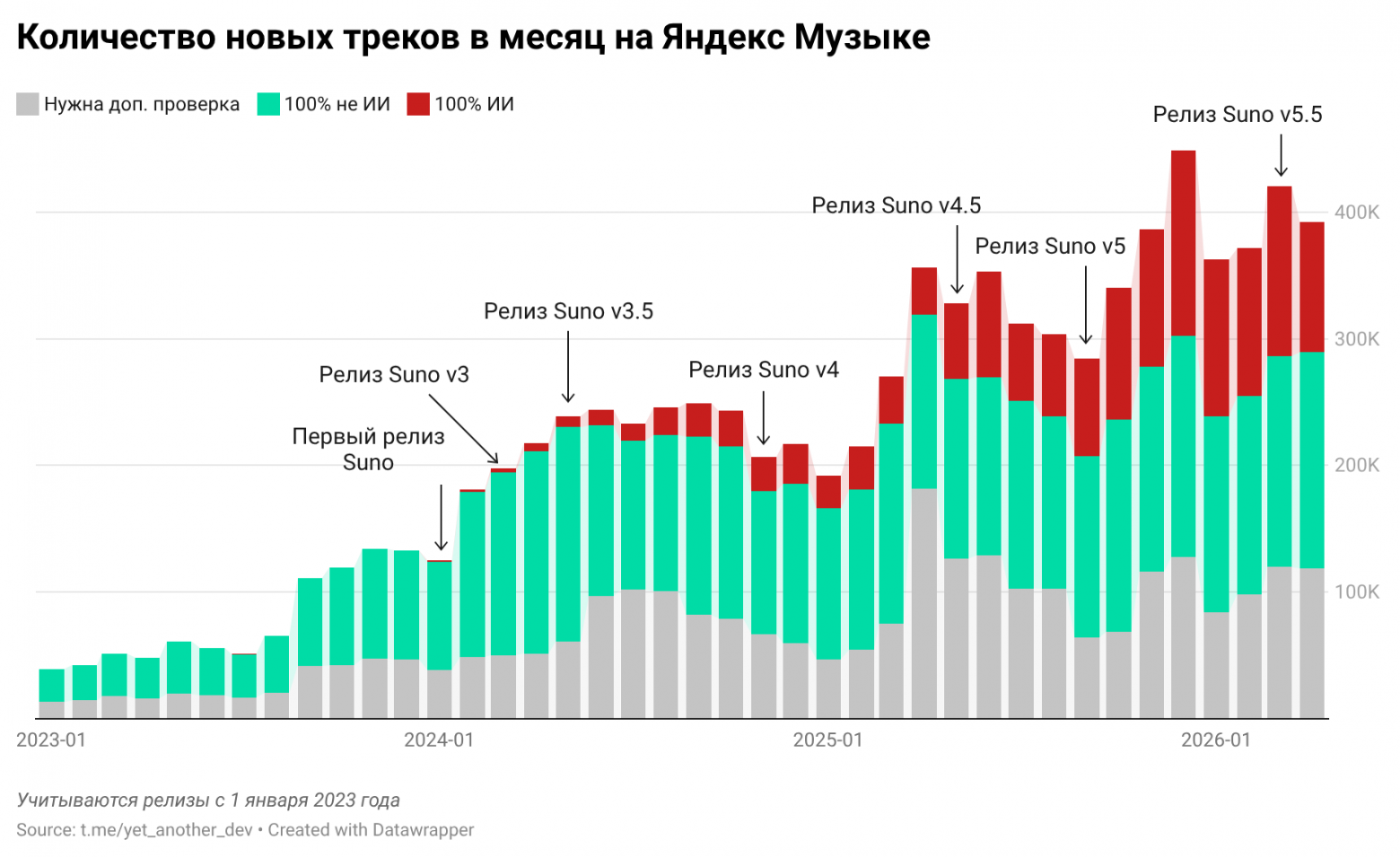
-
-
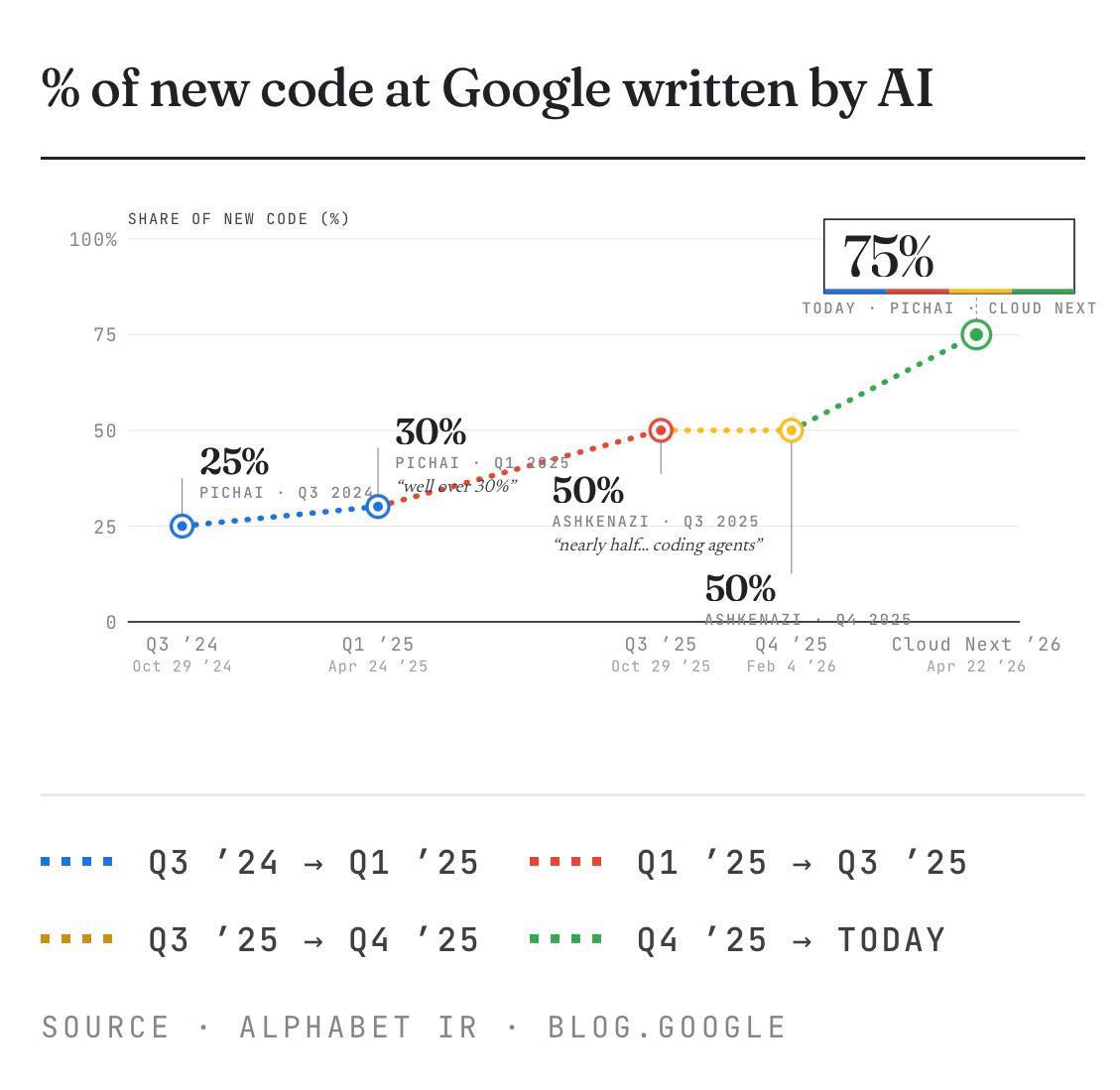
- 75% нового кода Google написано ИИ

- (ИИ, DDoS) ИИ активно используются как для отражения от атак, так и для проведения атак, к примеру из рассылки CheckPoint – умные/адаптивные DDoS атаки под управлением ИИ
- 75% нового кода Google написано ИИ
The cyber security landscape is undergoing a profound shift as attackers increasingly leverage artificial intelligence to launch DDoS attacks that are more autonomous, adaptive and resourceful than ever before. What were once blunt force disruptions have evolved into intelligent campaigns capable of learning, targeting and persisting at scale. This webinar explores how AI is transforming the DDoS threat landscape and why traditional defence assumptions are no longer sufficient. It concludes with strategic principles organisations should adopt to remain resilient in an era of intelligent adversaries. What you’ll learn • How AI is enabling adaptive, self-optimising DDoS attacks • Where traditional DDoS defences fall short • How modern attacks evade, persist, and re escalate • Key principles for building resilient, scalable DDoS protection
- ИИ признают делом государственной важности — в 2019 году по поручению президента России утверждена Национальная стратегия развития искусственного интеллекта до 2030 года. - В 2025 году, согласно исследованию McKinsey&Company, уже 78% компаний внедрили ИИ в свои продукты и бизнес-процессы, тогда как в 2017 году этот показатель составлял 20%. - Программирует. По данным Stack Overflow, 62% программистов уже используют ИИ в своей работе, планируют им пользоваться еще 13,8%. Microsoft заявляет, что треть кода компании пишет ИИ. - Генерирует контент. Исследования компании Microsoft показывают, что контент, созданный ИИ, все сложнее отличить от того, что сделано человеком. Так, согласно результатам эксперимента с участием более 12,5 тыс. человек по всему миру, общий процент успешных попыток отличить сгенерированные изображения от реальных составляет всего 62%. - Заменяет поисковики. Крупнейшие мировые интернет-поисковые системы, такие как Google, Bing, «Яндекс», внедряют ИИ-поисковики, которые вместо обычных ссылок выдают готовые ответы на вопросы, рекомендации, решают задачи. Это влияет на сферу онлайн-маркетинга — ИИ-поисковики уже лишают сайты трафика и дохода. Исследование Pew Research Center показало, что при наличии ИИ-сводок клики по ссылкам снижаются с 15 до 8%, а в самих сводках на ссылки кликают лишь около 1%. - Делат научные открытия. В 2024 году Нобелевскую премию по химии получили ученые из Google, которые решили 50-летнюю проблему предсказания структуры белков с помощью искусственного интеллекта. До этого сделать это не удавалось. - Помогает врачам. Объем мирового рынка ИИ в здравоохранении, по оценкам MarketsandMarkets, в 2024 году уже достиг $20,9 млрд, а в ближайшие пять лет среднегодовой темп его роста ожидается на уровне 48%. В медицине нейросети анализируют рентгеновские снимки, МРТ и выявляют заболевания на ранних стадиях с высокой точностью. - Управляет авто. Все больше автомобильных компаний, например Mercedes, BMW, Hyundai Motor Group, создают автономные машины, за рулем которых — искусственный интеллект, который соблюдает ПДД, правильно оценивает ситуацию на дороге и в целом очень хорошо водит. - Несмотря на влияние искусственного интеллекта на рынок труда, пока он остается не конкурентом человека, а его инструментом. По мнению Максима Тятюшева, будет стремительно расти востребованность таких специалистов, как инженеры по интеграции ИИ и эксперты по мультиагентным системам, так как эти роли уже активно формируют будущее разработки. Сама разработка станет более доступной. ИИ уже сегодня позволяет людям без глубоких технических знаний участвовать в создании продуктов. И далее роли разработчиков будут смещаться в сторону управления ИИ-инструментами, считает эксперт. - Новый подход, который привнес в программирование искусственный интеллект, получил название вайб-кодинг. Разработчик описывает задачу на естественном языке, а уже ИИ генерирует готовый код. В августе 2025 года исследование hh.ru показало, что число упоминаний в вакансиях требования «вайб-кодинг» уже увеличилось на 27% с начала года. Вайб-кодинг переосмысливает сам подход к созданию цифровых продуктов, позволяя взаимодействовать с искусственным интеллектом на естественном языке. Человек описывает идею приложения, а ИИ буквально за минуты генерирует готовый продукт. Представьте: человек, не знающий ни одной строки кода, может просто описать свою идею — будь то интернет-магазин, блог или сложное приложение, — и GigaStudio создаст полноценное приложение, готовое к публикации. - Анатолий Шипов считает, что рынок движется к гиперперсонализации, где ИИ адаптирует платформы и продукты под задачи конечных клиентов.
- Мейнтенеры dpdk активно используют ИИ
- (Денис Кораблев)
В прошлую субботу на нашей Олимпиаде по программированию случилось то, что я бы назвал точкой невозврата для отрасли. Вот цифры, от которых слегка сносит крышу. Из топ-30 участников только 9 человек писали решения «руками», а в решениях остальных если признаки генерации кода. Грубо говоря, большинство решали задачи LLM-ками и их решили! Для тех кто не в курсе - мы проводим свою неклассическую олимпиаду по программированию уже не первый год. Это не «борьба за медальки», а тренировка мозга и развитие собственных навыков. Соперник - не сосед по рейтингу, а ты сам на прошлой олимпиаде (условно, - вчера). При этом задачи по сложности - такие же, как раньше. Мы специально держим планку: классические алгоритмические задачки разной сложности. На первой нашей олимпиаде картина была такой: несколько человек экспериментировали с нейросетями, но условно из семи задач они могли решить первые три. Остальные не решались нейросетью никак. Потом на каждой олимпиаде процент решаемых LLM задач только рос, но рос незначительно. И вот сейчас впервые мы увидели массовое, осознанное использование генеративных моделей, которое реально работает! Это не про «подсмотреть идею» или «помочь с оформлением». Речь идет об автогенерации кода под задачи олимпиады топовой сложности! Возникает логичный вопрос: это больше людей научилось пользоваться нейросетями или нейросети запрогрессировали? Вот ответ напрашивается такой, что нейросети запрогрессировали и поэтому больше людей ими пользовалось! Мы ради интереса попробовали решить задачи с первой олимпиады и вместо трех нейросети решают уже все семь! Бинго! Много кто говорит, что «ИИ всё меняет», но все же чаще говорят про решение рутинных задачи. Вытеснение обычных профессий. А здесь - очень глубокая вещь. Если даже олимпиадные алгоритмические задачи можно решать с помощью генеративных сетей, то это уже не теоретический разговор, а квантовый сдвиг! Олимпиада всегда была территорией «чистого разума», где важны умение придумать идею, аккуратно воплотить её в коде, уложиться в ограничения. А теперь у нас есть: - нейросеть, которая умеет предлагать рабочие решения; - платформы, которые позволяют быстро проверять гипотезы; - мозг, который уже не обязан делать всю грязную работу руками, но обязан «держать структуру». И вот тут начинается самое интересное. Спойлер: всё то же самое, просто на новом уровне. Понимание алгоритмов никуда не делось. Если ты не понимаешь задачу, ты не сможешь нормально объяснить её модели и проверить, что она тебя не обманывает. Вкус к коду никуда не делся. Нейросеть может сгенерировать решение, но сделать его красивым, быстрым, понятным - это всё ещё ваша совместная работа. Умение думать в условиях ограничений никуда не делось. Временные лимиты, память, пограничные случаи - за тебя их до конца не почувствует ни один ИИ. По сути, роль разработчика начинает смещаться с «того, кто всё пишет руками», на того, кто умеет ставить задачу, проверять, улучшать и принимать решения. Для меня это выглядит как точка невозврата в ИТ-индустрии. Не в пафосном смысле «завтра все останутся без работы», а в очень прикладном: Если вы делаете продукты - игнорировать ИИ в разработке уже странно. Если вы учитесь - учиться «как раньше» уже не получится. Если вы любите алгоритмы - им тоже придётся жить в новой экосистеме. И то, что мы этот момент поймали не в сторонней презентации или аналитических сводках, а в своей же олимпиаде, - в этом вся прелесть. Мир уже не будет прежним - и это, если честно, гораздо больше вдохновляет, чем пугает. А мы просто рады, что оказались в точке, где эту перемену видно в цифрах, логах и чужих решениях, а не в красивых маркетинговых слайдах. Еще одно подтверждение того, что революция свершилась! Ура, товарищи!
- Даже в проектах с ГОСТ шифрованием используется
machine learning (ML)
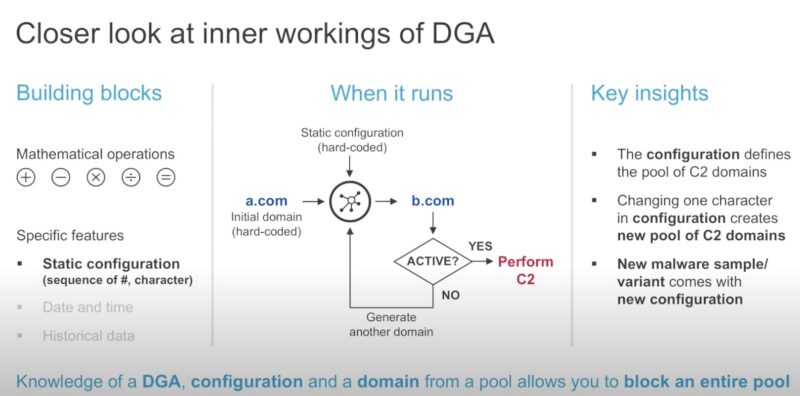
- О DGA detection с помощью ML подробнее в DNS, из интересного: No machine learning model is perfect! Some benign domains will be mistakenly labeled as false positives.
- Пример огромного количества эвентов, которые может генерировать SIEM с ML аналитикой (в данном случае Elastic Stack Detection Rules) на основе пользовательской активности (со знанием что норма, а что нет для каждого пользователя) – процессы, сеть, ааа, геолокация, время доступа и проч.
ml_auth_rare_hour_for_a_user_to_logon.toml ml_auth_rare_source_ip_for_a_user.toml ml_auth_rare_user_logon.toml ml_auth_spike_in_failed_logon_events.toml ml_auth_spike_in_logon_events.toml ml_auth_spike_in_logon_events_from_a_source_ip.toml ml_high_count_network_denies.toml ml_high_count_network_events.toml ml_linux_anomalous_compiler_activity.toml ml_linux_anomalous_metadata_process.toml ml_linux_anomalous_metadata_user.toml ml_linux_anomalous_network_activity.toml ml_linux_anomalous_network_port_activity.toml ml_linux_anomalous_process_all_hosts.toml ml_linux_anomalous_sudo_activity.toml ml_linux_anomalous_user_name.toml ml_linux_system_information_discovery.toml ml_linux_system_network_configuration_discovery.toml ml_linux_system_network_connection_discovery.toml ml_linux_system_process_discovery.toml ml_linux_system_user_discovery.toml ml_packetbeat_dns_tunneling.toml ml_packetbeat_rare_dns_question.toml ml_packetbeat_rare_server_domain.toml ml_packetbeat_rare_urls.toml ml_packetbeat_rare_user_agent.toml ml_rare_destination_country.toml ml_rare_process_by_host_linux.toml ml_rare_process_by_host_windows.toml ml_spike_in_traffic_to_a_country.toml ml_suspicious_login_activity.toml ml_windows_anomalous_metadata_process.toml ml_windows_anomalous_metadata_user.toml ml_windows_anomalous_network_activity.toml ml_windows_anomalous_path_activity.toml ml_windows_anomalous_process_all_hosts.toml ml_windows_anomalous_process_creation.toml ml_windows_anomalous_script.toml ml_windows_anomalous_service.toml ml_windows_anomalous_user_name.toml ml_windows_rare_user_runas_event.toml ml_windows_rare_user_type10_remote_login.toml
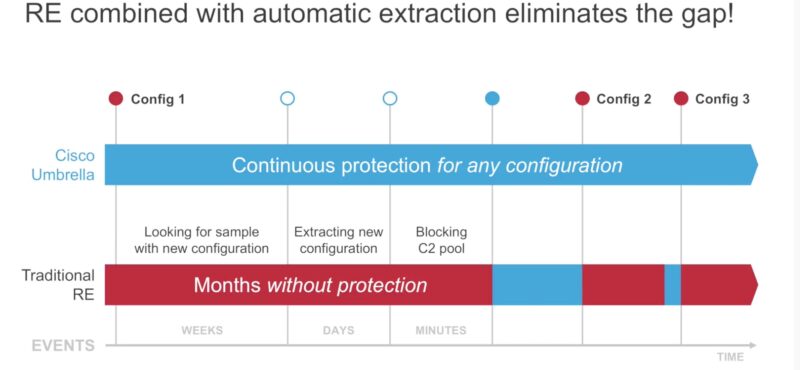
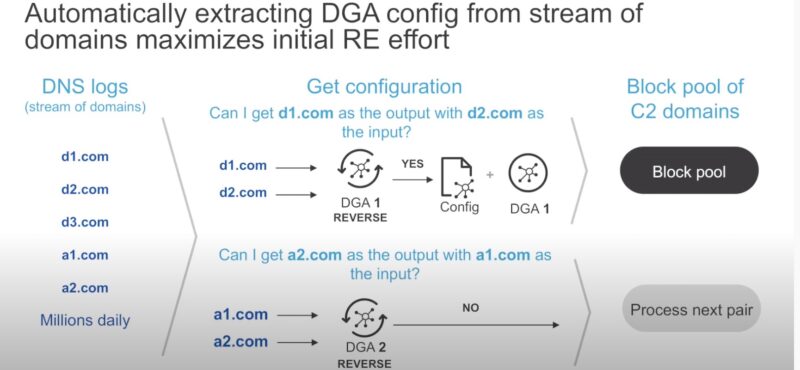
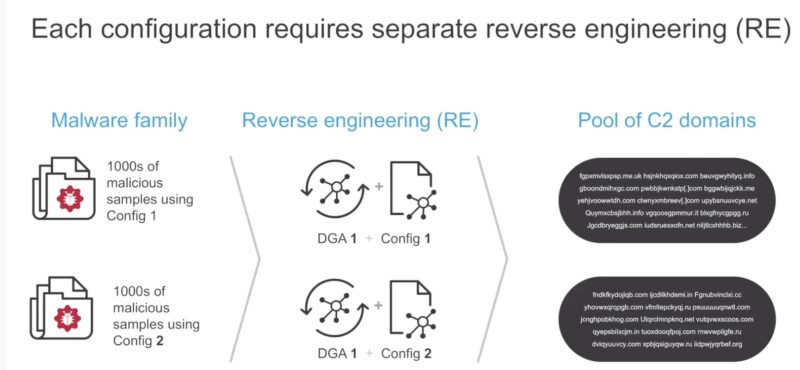
- Пример почему ML зачастую лучше чем
- сигнатуры – сигнатуры нужно писать, а ML уже “как-то” обучен и работает. Кроме того сигнатуры нужно писать универсально, что в некоторых случаях невозможно (пример с DGA).
- ревер инжениринг – нужно разбираться как каждый из DGA алгоритмов и вариаций конфигураций этих алгоритмов работает перед тем, как блокировать запросы к доменам


Virtually every device or software system that collects textual, visual, and audio data could feed a machine learning model that makes that device or software system smarter about how it functions in the future.
Forecasts or predictions from machine learning can make apps and devices smarter. For example, when you shop online, machine learning powers product recommendation systems that offer additional products based on what you’ve bought and what other shoppers have bought who have purchased similar items in the past. Machine learning is also used to detect credit card fraud by analyzing each new transaction and using what it has learned from analyzing millions of fraudulent transactions.
Machine learning deployment steps:
1 – define a goal for the ML system
2 – acquire sample data containing factors that might correlate to a positive or negative decision.
Analyse the data to ensure there were no biases. That the sample represents the entire population of data. And that there’s no order or weight implied.
The quantity and the quality of the data is vitally important, since it will be what is used to train and evaluate the system.
The data must contain the answer correlated to our goal.
3 – split data into:
– training data for building the algorithm (the rules for making new decisions based on similar data in the future)
– the evaluation data to test the algorithm
4 – choose a model (data scientist & researchers created models for different purposes: some work well with visual data, others with sequence data/text-based data) these models will be used to generate algorithm
5 – train model supplying our training data and allowing our model to generate an algorithm that correlated various factors into a decision. The model decides which factors should be weighted and under what circumstances.
6 – use the evaluation data to test our new algorithm to see how accurate it is (example: 95%)
7 – after testing we may need to tweak the algorithm by hand tuning certain parameters and retesting
8 – deploy the system into a live environment where its conclusions can be utilized by our business
As we use the system, we can use our results to continue to train the model.
часть задач эксплуатационных, часть аналитических (опенца моделей0
– для нас достаточно accuracy (сумма верных решений/сумма всех решений) – увидим (если она есть) деградацию под нагрузкой с учетом всех показателей (TP, TN, FP, FN) при тестировании одним набором данных от итерации к итерации
– остальные показатели не используем (precision, recall, f1score) – они в первую очередь нужны и используются для сравнительной оценки разных ML моделей между собой перед выбором конкретной модели
интересное из статьи коммерсанта
Универсального определения ИИ не существует, но обычно считается, что это способность машины на когнитивные действия, аналогичные тем, которые выполняет человеческий мозг,— рассуждение, обучение и решение проблем. В 1940-е годы британский математик, логик и криптограф Алан Тьюринг разрабатывал концепцию машинного интеллекта. В 1950 году он опубликовал в научном журнале Mind статью «Вычислительные машины и разум». В 1956 году статья была перепечатана в четвертом томе библиотеки математической литературы «Мир математики» Джеймса Ньюмена под более эффектным заголовком «Могут ли машины мыслить?».
В этой статье был сформулирован так называемый тест Тьюринга. Его смысл состоит в том, чтобы определить, способна ли машина мыслить, как человек. В эксперименте три участника: человек, машина и судья. Они общаются вслепую. Судья задает двум остальным участникам вопросы, на которые получает письменные ответы. Задача судьи — определить, кто из собеседников машина. Задача машины — обмануть судью. Если судья не способен отличить ответы машины от ответов человека, это означает, что машина прошла тест Тьюринга. Значит, ее можно считать «разумной».
Во времена Тьюринга электронно-вычислительным машинам (ЭВМ) такая задача была не по плечу. В июне 2024 года Камерон Джонс и Бенджамин Берген с факультета когнитивных наук Калифорнийского университета в Сан-Диего опубликовали статью, в которой сообщалось, что чат-бот ChatGPT-4 успешно прошел тест. «Судьи» принимали нейросеть за человека в 54% случаев. В новой статье тех же исследователей, опубликованной в марте 2025 года, результаты эксперимента были еще более впечатляющими. Более совершенная нейросеть ChatGPT-4.5 Persona смогла обмануть подавляющее большинство «судей». Пятьсот участников эксперимента в 73% случаев принимали ее ответы за ответы человека.
Одна из главных проблем новой науки, тормозившая ее развитие, состояла в том, что компьютерные мощности не успевали за теоретическими разработками. Человеческие задачи оказывались слишком сложными для компьютеров. Некоторые идеи находили свое воплощение в жизнь много лет спустя. Так, в апреле 2024 года исследователи из четырех американских университетов опубликовали статью, в которой была выдвинута концепция нового типа нейросетей, основанная на теореме Колмогорова—Арнольда (Kolmogorov—Arnold Networks, KAN). Смысл теоремы, которую в начале 1960-х годов доказали советские математики Андрей Колмогоров и Владимир Арнольд, состоит в том, что любую сложную функцию многих переменных можно представить в виде комбинации множества простых функций от одной переменной.
В июне 2025 года генеральный директор OpenAI Сэм Альтман заявил, что Meta (признана в России экстремистской организацией и запрещена) пытается переманить его сотрудников, занимающихся разработками моделей ИИ, предлагая им бонус в размере $100 млн.
Гендиректор Anthropic Дарио Амодей говорил в августе, что его сотрудники отказывались переходить в Meta (признана в России экстремистской и запрещена), когда им предлагали такие же суммы. О подобных предложениях сообщали и сотрудники Google, занимающиеся ИИ.
Этим летом сооснователю ИИ-стартапа Vercept Мэтту Дейтке позвонил генеральный директор Meta (признана в России экстремистской организацией и запрещена) Марк Цукерберг и предложил четырехлетний контракт на $125 млн. Дейтке отказался. Цукерберг встретился с ним лично и сумел переубедить, предложив $250 млн за четыре года работы с возможностью получить $100 млн в первый год. На эти условия Мэтт Дейтке согласился.
Для сравнения: самый крупный контракт в истории Национальной баскетбольной ассоциации США заключил Джейсон Татум из «Бостон Селтикс» — $313,9 млн на пять лет. Это всего на $280 тыс. в год больше, чем у Дейтке.
Первым в истории специалистом по ИИ, получившим контракт на $1 млрд, мог стать инженер-исследователь Эндрю Таллок. Он одиннадцать лет проработал в Meta (признана в России экстремистской организацией и запрещена), затем ушел в OpenAI, а после основал собственную компанию Thinking Machines Lab. Марк Цукерберг предлагал ему шестилетний контракт на $1 млрд с возможностью увеличения в зависимости от достигнутых результатов, если Таллок вернется. Таллок отказался.
Вторая волна в развитии ИИ поднялась в 1990-е благодаря статистической теории обучения. Это основа машинного обучения на основе статистики и функционального анализа. Машинное обучение — направление в ИИ, основанное на идее о том, что компьютерные системы могут самостоятельно выполнять задачи, опираясь на закономерности и зависимости, выведенные из данных, учиться на данных, а не просто выполнять программу. Среди знаковых достижений периода второй волны можно отметить следующие. Создание в 2007 году ImageNet, базы данных аннотированных изображений, предназначенной для отработки и тестирования методов распознавания образов и машинного зрения. В настоящее время число изображений в базе превышает 14 млн. В 2011 году компания Apple запустила разработанный ею облачный цифровой персональный помощник Siri. В 2016 году компьютерная программа AlphaGo, созданная компанией Google DeepMind, одержала победу в матче по игре в го над чемпионом мира Ли Седолем из Южной Кореи со счетом 4:1. Игра го оказалась для думающих машин сложнее шахмат, в шахматы компьютер Deep Blue обыграл чемпиона мира Гарри Каспарова (признан в РФ иностранным агентом) еще в 1997 году.
Наконец, третья волна в истории ИИ, больше похожая на цунами, поднялась и продолжается сейчас, в 2020-е.
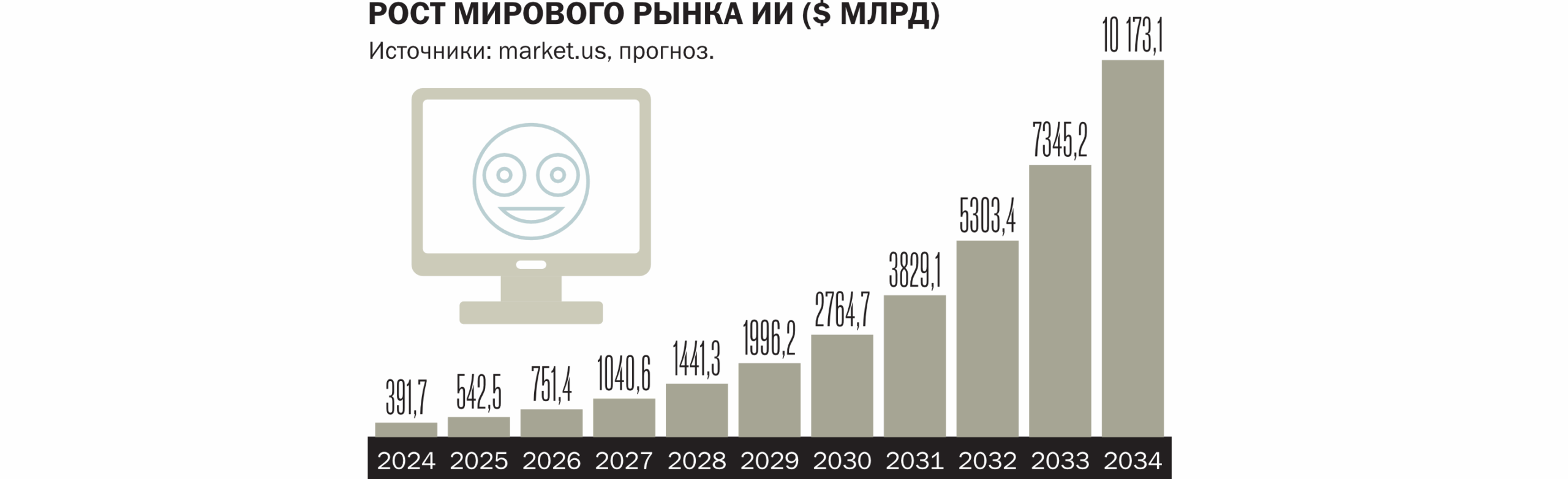
Мировой рынок технологий искусственного интеллекта растет так быстро, что аналитики сильно расходятся в оценках и прогнозах.
Лишит ли ИИ людей работы В опубликованном в 2025 году докладе Конференции ООН по торговле и развитию (ЮНКТАД) «The Technology and Innovation Report 2025: Inclusive Artificial Intelligence for Development» приводится следующий прогноз: к 2033 году ИИ затронет около 40% рабочих мест в мире. Что касается сфер использования технологий ИИ, то в настоящее время они используются практически везде. Определение спама в электронной почте, диагностика заболеваний, распознавание лиц на фотографиях, беспилотные автомобили, робототехника, финансовый анализ, делопроизводство, логистика, индустрия развлечений и т. д. В каких-то сферах человеческой деятельности — более активно, в каких-то — менее, но в общем и целом — повсеместно. Согласно аналитическому отчету Artificial Intelligence Index Report 2025, подготовленному в Стэнфордском университете, в 2023 году 55% организаций использовали ИИ в своей деятельности. В 2024 году — уже 78% организаций. Использование генеративного ИИ также выросло — с 33% организаций в 2023 году до 71% организаций в 2024 году.
По оценке Jon Peddie Research, на долю Nvidia в первом квартале 2025 года приходилось 92% мирового рынка видеокарт. Доля компании на рынке ИИ-чипов, по разным оценкам, составляет от 70% до 95%. Более 40% выручки Nvidia приходится на Microsoft, Meta (признана в России экстремистской организацией и запрещена), Alphabet и Amazon, активно инвестирующих в инфраструктуру ИИ. Конкурентом Nvidia на рынке чипов для ИИ является компания Broadcom (рыночная капитализация — $1,7 трлн). Основной партнер Nvidia в производстве чипов, в том числе для дата-центров и других задач ИИ,— тайваньская компания TSMC (капитализация — $1,345 трлн). По ситуации на второй квартал 2025 года TSMC контролирует 70,2% рынка контрактного производства чипов. Исследование, проведенное McKinsey & Company, показало, что к 2030 году для удовлетворения спроса на вычислительные мощности необходимо будет инвестировать $6,7 трлн, в том числе в центры, предназначенные для обработки нагрузок, связанных с ИИ,— $5,2 трлн, а в дата-центры, обеспечивающие работу традиционных ИТ-приложений,— $1,5 трлн. По оценке компании Omdia, капиталовложения ведущих технологических компаний в центры обработки данных (ЦОДы) сопоставимы с ВВП некоторых государств.
Хотя компания Amazon — крупнейший мировой онлайн-ритейлер, но главную прибыль ему приносят «облака». Операционная прибыль AWS в 2024 году составляла $38,9 млрд. Это на $11 млрд больше, чем операционная прибыль компании от онлайн-торговли. Что касается электронной коммерции Amazon, то в ней активно используются ИИ-технологии: персонализированные рекомендации по продуктам и клиентской поддержке, контроль за цепочкой поставок, складская робототехника, системы обнаружения мошенничества. В отдельных городах США, Великобритании и Италии действует служба Amazon Prime Air — доставка купленных на Amazon товаров с помощью дронов. С помощью генеративного ИИ было улучшено качество общения персонального ассистента Alexa. Amazon использует технологии ИИ в рекламе и маркетинге, в системах бесконтактной оплаты и даже помогает любителям американского футбола в ходе прямых трансляций отслеживать игроков, способных провести выигрышную комбинацию. Наиболее заметное для обычного человека использование ИИ-технологий компанией Google — в поиске и в смартфонах Pixel последнего поколения. В июле 2025 года во время телеконференции с инвесторами генеральный директор Google Cундар Пичаи привел такую статистику. Gemini в настоящее время насчитывает более 450 млн активных пользователей в месяц. Аудитория «обзоров от ИИ» (AI Overviews — сводки с ключевой информацией, автоматически появляющиеся в верхней части результатов поиска Google) насчитывает более 2 млрд активных пользователей в месяц в 200 странах. Обзоры предоставляются на 40 языках. 1 сентября компания Tesla опубликовала «Генеральный план, часть IV» — новое амбициозное видение будущего. План предполагает, что компания меньше внимания будет уделять электромобилям, а на первый план выйдут автономные роботы. Илон Маск в день публикации плана опубликовал пост в соцсети Х, в котором пообещал, что 80% стоимости Tesla в будущем будет приходиться на человекоподобных роботов Optimus. Робот, первоначально носивший название Tesla Bot, был впервые представлен компанией в 2021 году (правда, на презентации не был показан прототип — на сцене был человек в костюме робота, впервые публика сумела увидеть прототип в октябре 2022 года). Роботы Optimus предназначены для выполнения производственных задач, которые люди считают скучными, однообразными или опасными. Optimus будет использовать передовой искусственный интеллект и датчики, устанавливаемые в автомобили, для передвижения и выполнения различных задач в физическом мире. На пути к членству в клубе «Триллион» — компания Oracle. 10 сентября 2025 года газета The Wall Street Journal сообщила, что OpenAI подписала контракт на покупку вычислительных мощностей у Oracle Corp. на сумму $300 млрд в течение пяти лет.
ИНТЕРЕСНОЕ ИЗ ИССЛЕДОВАНИЯ JET/IKS (ВЫДЕРЖКИ)
https://disk.yandex.ru/i/XUezA6nfWviLfw
- Сеть и ИИ, RoCEv2. В связи с бурным развитием больших языковых моделей (LLM) и увеличением рабочих нагрузок, связанных с ИИ, многие мировые провайдеры перепроектируют свои крупные ЦОДы для размещения кластеров ИИ, выполняющих эти специализированные задачи. Это привело к появлению новых сетевых архитектур, использующих концепцию интерфейсных (front-end) и серверных (back-end) сетей. Интерфейсная сеть управляет взаимодействием с пользователями, приемом данных и вычислительными задачами общего назначения. Серверная сеть предназначена для высокоскоростной передачи больших объемов данных между ИИ-ускорителями, такими как GPU. Она справляется с интенсив-ными вычислительными нагрузками, необходимыми для распределенного обучения и вывода больших моделей искусственного интеллекта. Поддержка RoCEv2 является основополагающим требованием в этой сети для обеспечения высокоскоростного взаимодействия между графическими процессорами.
- По сути, все описанные выше варианты сетевых архитектур относятся к категории интерфейсных сетей. Архитектура и технологии серверных сетей во многом определяются особенностями используемых ИИ-ускорителей. Они могут базироваться, в частности, на технологиях Lossless Ethernet (с использованием RoCEv2) или InfiniBand. Ряд мировых производителей, таких как, Cisco, Nvidia и Intel, разработали референсные архитектуры для таких сетей. Например, Intel предлагает каждый узел (c GPU-ускорителями) подключать к трем различным коммутаторам доступа (leaf), а каждый такой коммутатор – к выделенному набору spine коммутаторов.
- Подавляющее большинство (92%) либо не изменили свои планы, либо не рассматривали этот вопрос. Только четыре респондента ответили утвердительно. И двое из них планируют ради внедрения ИИ-систем переходить на другую архитектуру (топологию).
- Заметим, что ни один из опрошенных не планирует внедрять (для ИИ) сетевую технологию InfiniBand, хотя два заказчика ее уже используют. Отсутствие таких планов связано в том числе с высокими санкционными рисками применения зарубежных решений. Развитие сетей отечественных ЦОДов будет происходить на основе технологии Ethernet, которую российские производители уже неплохо освоили.