
-
Про SDN отдельная статья
- Dragonfly yandex
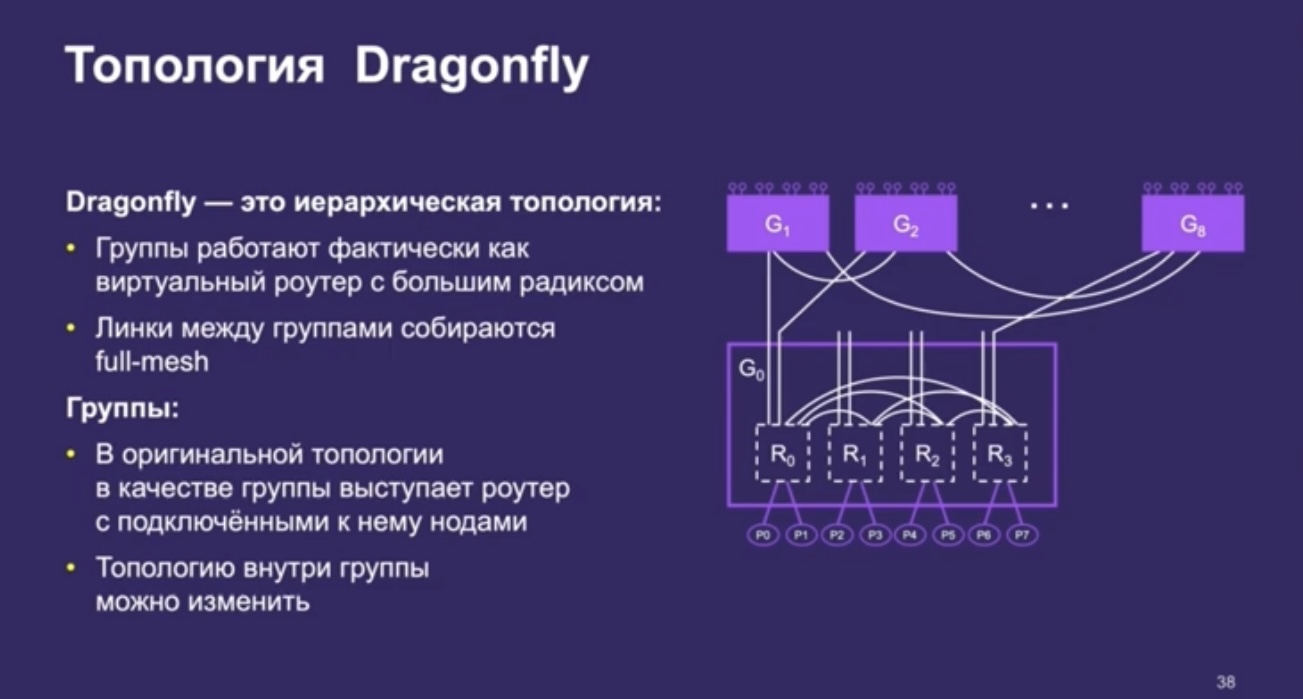
- Про электричество так же отдельная статья
- DATARK – компания продает модульные ЦОД, явно востребовано у производственных/добывающих предприятий
- Про охлаждение и СКУД пока тут, в будущем потенциально сплит
- Про используемые технологии в ЦОД яндекс в крупных IT компаниях
- Стоимость услуг ДЦ в СПБ на порядок ниже МСК.
- В не слишком богатых ДЦ (сплошь и рядом) эксплуатация на подряде, со стороны ДЦ прием работ и организация. Недостаток такой системы время реакции при авариях. Поэтому в богатых ДЦ (чаще в мск, не в питере), есть дежурный круглосуточный персонал, помимо подряда.
- Разрабы часто использовали и используют внешние вычислительные ресурсы для разработки, включая проектную работу – арендуешь инфраструктуру, разрабатываешь, по готовности отгружаешь образы заказчику, инфраструктуру удаляешь
- 2020 Cisco, Arista и Juniper – лидеры магического квадранта Gartner по рынку сетевых технологий для ЦОД
-
Пример организации ДЦ сети leaf-spine на базе оборудования Arista в Честном Знаке. (ниже выдержки поиском по честный знак)
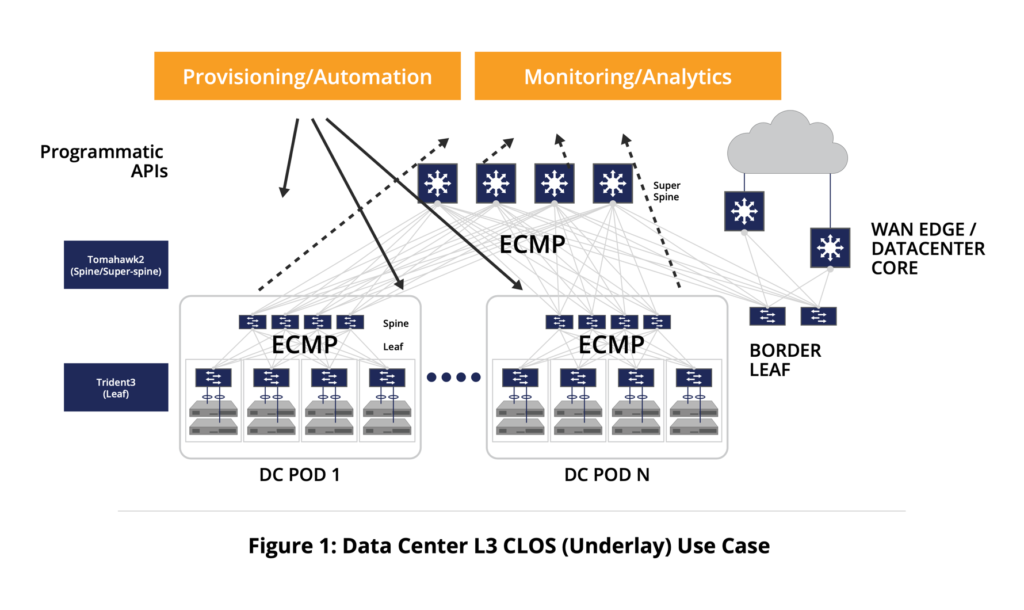
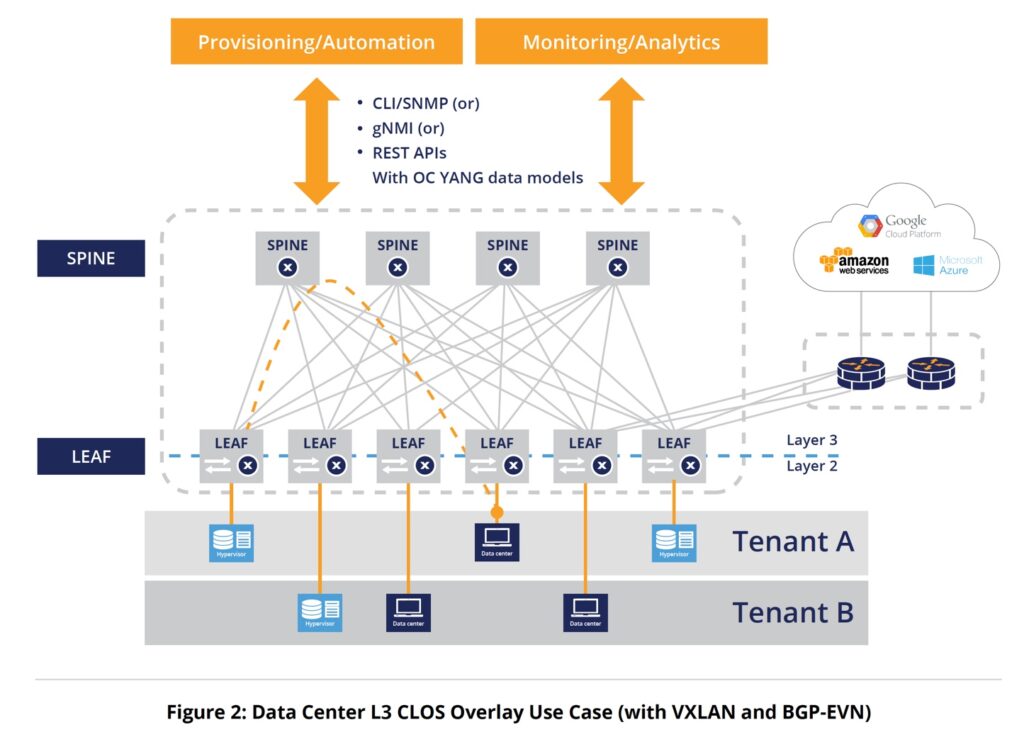
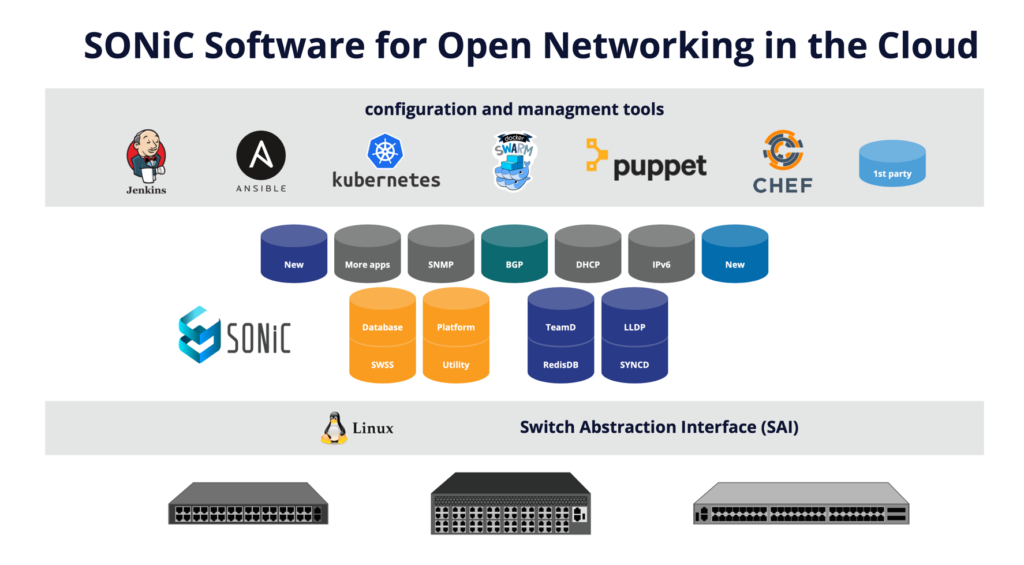
- Классическая топология DC из информации про Sonic
- DCNM – Cisco Data Center Network Manager (DCNM) – используется для деплоя/управления фабрикой на основе Nexus коммутаторов
- DCI каналы зачастую бывают небольшого (относительно других линков ЦОД и в целом) объема – 10-20GB
- При этом через DCI могут передаваться огромные массивы данных – Hadoop и другие big data приложения могут положить линк DCI даже в 100G.
- При этом же сейчас поверх волокна можно поднять и 100G и зачастую больше (пассивный или активный WDM с уплотнением в рамках нескольких лямбд/частот).
- Ассиметрия DCI канала (10G) и канала в фабрику (400G) может приводить к дропам на DCI канале.
- TRILL особо не использовался (fabric path cisco, был реализован на чипах broadcom), сейчас тем более – по сути мертв. Вендоросовместимость в том числе была плохая.
- RIFT – новый протокол, вендоры приглядываются, судьба его вероятро ждет по аналогии с TRILL
- Чем выше уровень Tier, тем круче в дата-центрах (обратная ситуация с провайдерами).
Принято считать, что ожидаемый уровень безотказной работы дата-центра Tier I составляет 99,671% (1729 минут годового простоя); Tier 2 — 99,741% (1361 минут годового простоя); Tier III — 99,982% (95 минут годового простоя); Tier IV — 99,995% (26 минут годового простоя).
ocp
- Open Compute Project (OCP) — это концепция, сообщество и организация, в рамках которых участники в форме открытого диалога делятся разработками в сфере программного, аппаратного и физического проектирования современных центров обработки данных (ЦОД) и оборудования для них. Основной задачей проекта является снижение CAPEX и OPEX инфраструктуры крупномасштабных ЦОД.
OCP – открытый стандарт для оборудования, facebook является во многом инициатором и двигателем стандарта. Профит частично в том, что стандартные размеры/формы запатентованы, кроме того они не являются зачастую оптимальными с точки зрения энергоэффективности, охлаждения и производительности. В России даже есть вендоры производящие по стандарту, у нас в 2025 даже требование размещаться в OCP у облачных провайдеров и они, соответственно, аналазируют сколько отдавать при расширении под OCP.
TOR/EOR TOPOLOGY
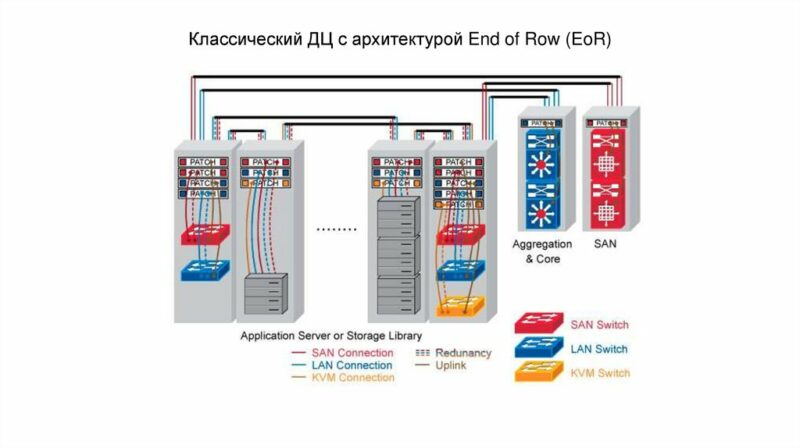
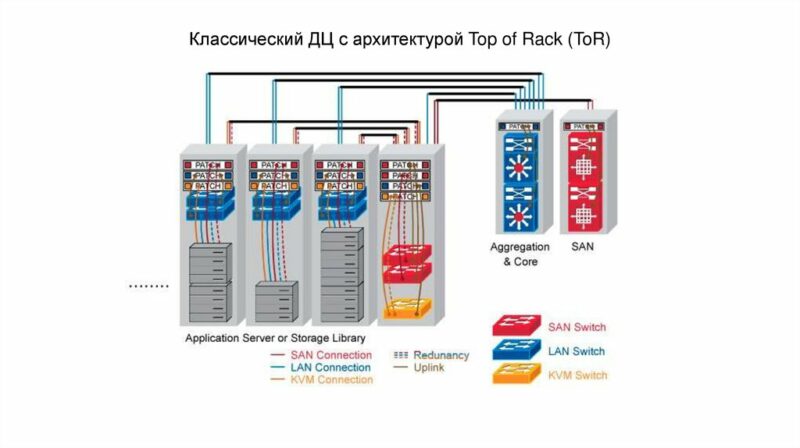

east/west
- Информационные потоки ЦОД принято разделять на два типа North-South и East-West. North-South информационные потоки описывают взаимодействие ЦОД с пользователями, сервисами, другими словами данные виды информационных потоков отвечают за взаимодействие ЦОДа с внешним миром. East-West информационные потоки описывают взаимодействие различных сервисов, служб внутри ЦОДа.
- Что касается объемов то по разным оценкам East-West трафик составляет до 80% всех информационных потоков в ЦОДах, в то время как North-South не превышает 20%.
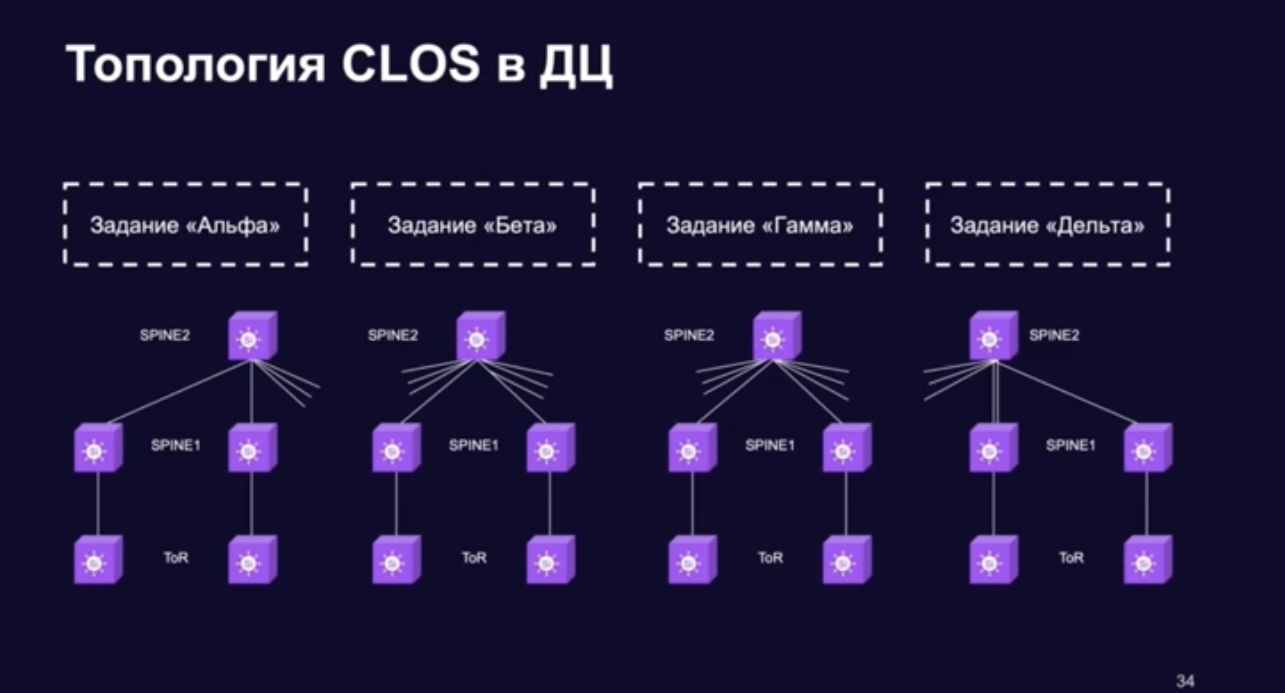
Leaf/Spine or clos topology
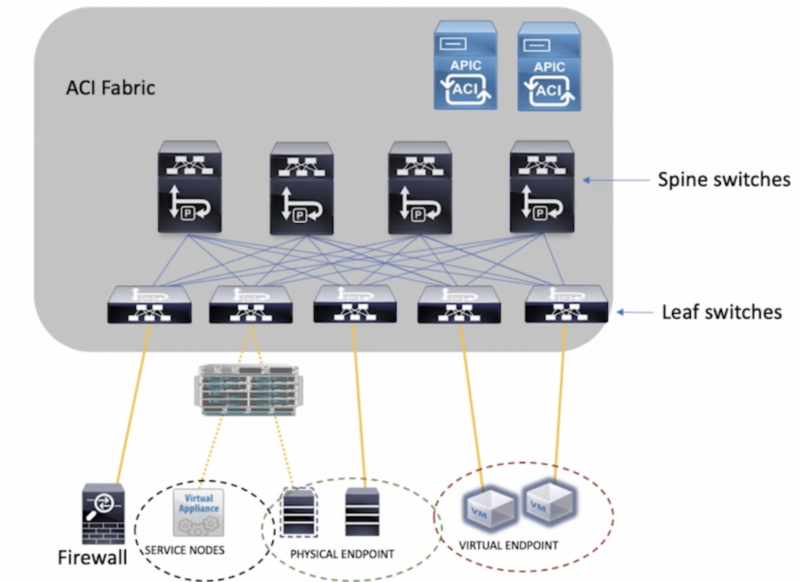
- Пример CISCO Aci leaf/spine topology. Подробнее о Cisco ACI в отдельной статье.
- Честный Знак (во многом копипасты базовой инфы/документации Arista)
-
- Spine – 100GE-коммутаторы, используемые для объединения коммутаторов каждого ЦОД в единую фабрику. Используются только как транзитные устройства, не терминируют VXLAN-туннели.
- Border Leaf – 10GE-коммутаторы с поддержкой MACSec. Используются для шифрования каналов связи между площадками ЦОД и подключения фабрики к внешнему контуру.
- Border Router – 10GE-маршрутизаторы с поддержкой полной таблицы BGP Full View. Используются для подключения каналов связи Интернет
- Балансировка
Значение Destination UDP Port зарезервировано IANA под VXLAN и равно 4789. Source UDP порт высчитывается на ingress VTEP на основе hash-функции по полям Original L2 frame (в том числе L3 и L4 заголовки оригинального пакета от сервера), таким образом достигается необходимая энтропия для эффективной балансировки на уровне Underlay топологии, в которой помимо полей IP заголовка также учитывается source UDP port.
- Yandex cloud, яндекс облако
-
Сеть клоза – leaf spine.
-
позволяли недорого подключить n входов к m выходам без блокировок и необходимости использовать n*mсоединений.
-
Однако наиболее важное для наших задач качество такой топологии — возможность практически неограниченно наращивать её, не принося в жертву ширину полосы. Именно поэтому она стала основой для всех гипер- и экзаскейлеров и клауд-титанов.
-
- У Yandex.Cloud 3 зоны доступности (Avialability Zone — AZ) и 5 точек присутствия (Point of Presence — POP). Внутри AZ — классическая для датацентров сеть Клоза. Между разными AZ и POP — магистральная DWDM-сеть.
- ToR свич = leaf свич = 400 GB uplink (линки по 100G в LAG). По факту свич занимает не TOP, а MIDDLE позицию в стойке. Он всего один этот свич, два ToR не используют из-за СКС, экономии и архитектурных причин (мало кто из крупных облаков использует двуторье/два ToR коммутатора).
-
creker Неужели крупные облака тоже ставят один ToR на хост? Никакие MLAG ничего не используют? Может подкинете источники, а то так сходу не найдешь. Я конечно понимаю, что в облаке полно ресурсов, чтобы быстренько перезапустить виртуалку в соседней стойке, но все равно как-то странно. При плановом обслуживании вполне реально на горячую мигрировать машины (хз делают ли так), а если отказ — даунтайм гарантированный на всю стойку? Это ж может быть большое число клиентов. --- --- --- Это если мы говорим о проприетарных свитч платформах. Если брать bare-metal и ставить sonic или cumulus, то MC-LAG вполне себе получается свободный. А с учетом, что у крупных игроков порой вообще софт и железо свои в этом месте, то тем более не проблема как по мне. По масштабам понятно. Просто любопытно, неужели люди выбирают риск потерять целую стойку и даунтайм для кучи клиентов. С ростом масштабов у нас соответственно и клиентов больше, и риск потерять свитч выше.
-
- Упрощение это хорошо: успели перед большим редизайном NOC Яндекса, целью которого было существенно упростить инфраструктуру. После него платформа Yandex.Cloud уже не могла работать по старой схеме.
- Автоматизация деплоя (NetBox, CM, мониторинга, etc)
- Мониторинг должен быть не шумным и однозначно указывать на существующую проблему.
- Например, мы проверяем сколько всего BGP-сессий настроено на ToR. Должно быть 4. Сколько из них в состоянии Established? А как давно — больше 5 минут или меньше? Если лежит хотя бы одна сессия, это WARN и сообщение в телеграм. 2 — уже CRIT и звонок –родителям– дежурному.
- На каждой машине стоит агент e2e-мониторинга, который веерно пингует по ICMP/UDP/TCP весь флот хостов и рисует матрицу связности, по которой мы можем в пару кликов понять характер проблемы и локализовать её.
- Также мы сравниваем число активных членов LAG с настроенным, иначе можно незаметно деградировать по полосе.
- Ещё мы отслеживаем количество анонсируемых и принимаемых маршрутов. Если оно внезапно выходит за допустимые пределы, это сигнал: что-то случилось. Нужно проверить, не упало ли какое-то устройство. Прилетела неожиданного размера пачка маршрутов — нет ли угрозы аппаратным ресурсам устройства?
- Используют whitebox свичи
- В AZ находятся стойки с серверами. Каждая, набитая более чем тридцатью машинами, подключена в сеть на скорости 400 ГБ/с. Внутри одной AZ мы можем прокачивать десятки терабит. Наружу — в совокупности между ДЦ, в большой Яндекс, в интернет — из каждого ДЦ мы сможем выпустить около 1 ТБ/с.
- Тут следует заметить, что мощности Yandex.Cloud располагаются в датацентрах Яндекса. Платформа использует такие же сервера и стойки внутренней разработки, такие же свитчи и маршрутизаторы, включается в ту же СКС.
-
Иметь единые с большим Яндексом инфраструктуру и инструментарий было бы очень удобно. Но ради этого нам пришлось бы пожертвовать скоростью развития платформы. Сеть NOC, строившаяся под задачи большого Яндекса и ориентированная на внутренних клиентов, плохо решала задачи Yandex.Cloud:
-
У них IPv6-only сеть — у нас IPv4: требования OpenContrail/Tungsten Fabric.
-
У них тенденция к отказу от MPLS — для нас это основной способ туннелирования трафика. Облачным платформам он необходим как составная часть нескольких решений. Но у этого механизма есть существенный минус — ограничения масштабируемости. Яндекс отказался от MPLS в пользу максимального упрощения сети.
-
У них автоматизация, заточенная под их задачи — у нас весьма специфический дизайн.
-
Их сервисы выдерживают выключение одной или нескольких стоек и даже всего ДЦ — наши сервисы для внешних клиентов и помышлять об этом не могут.
-
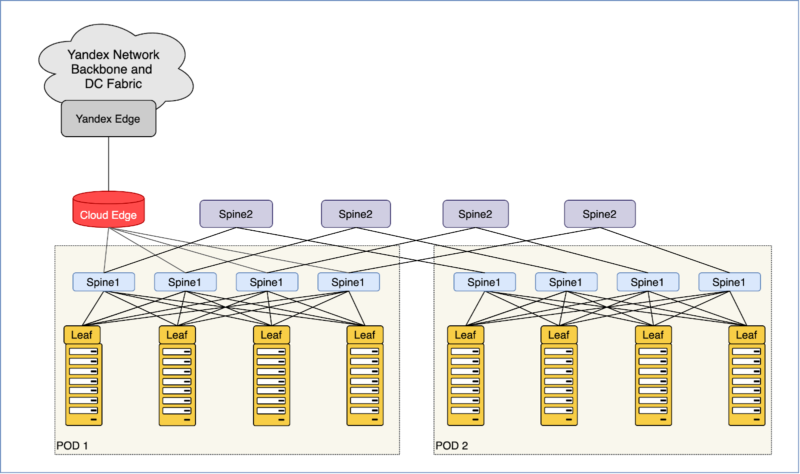
- Пример super spine в Yandex cloud
- Так мы добавили спайн для спайнов, он же суперспайн, он же Spine2, он же ToF (Top of Fabric) и подключили в него существующую сеть, после чего последняя стала лишь маленьким кусочком мозаики.
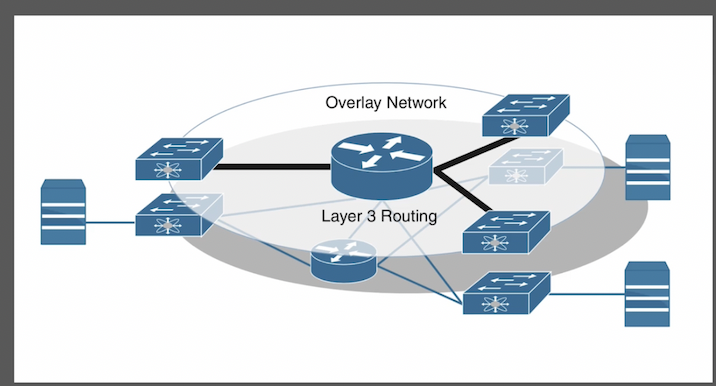
overlay network – подразумевает туннелирование пакетов поверх underlay network. Туннелирование может быть как l2 (чаще), так и l3.
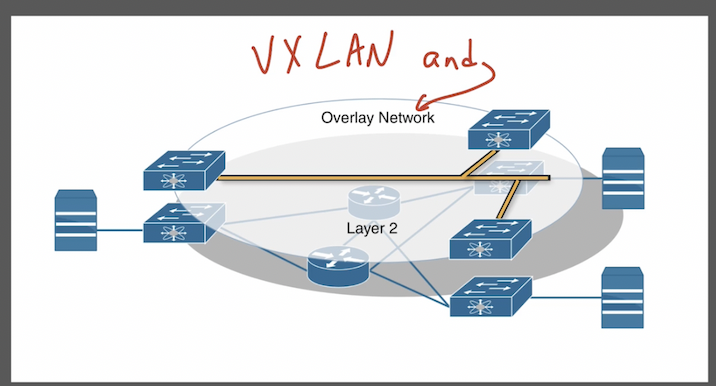
В качестве туннелирующего протокола overlay сети может использоваться:
-
- Vxlan (наиболее частый) – virtual extensible lan
- NVGRE – network virtualization using generic routing encapsulation
- STT – stateless transport tunneling
- GENEVE – generic network virtualization encapsulation

underlay network – l3 сеть/фабрика:
-
- разделяет (vrf/vxlan) l3 сети или маршрутизирует трафик между ними в разных broadcast domain
- коммутирует пакеты внутри одного broadcast domain
- Все leaf коммутаторы в топологии vxlan связаны со всеми spine коммутаторами. При этом одноранговые соединения leaf-leaf и spine-spine не делаются.
No direct connectivity is allowed between spine nodes or between leaf nodes.
-
- VTEP (VXLAN Termination EndPoint) – точка терминации VXLAN туннелей, располагается на L3 Leaf и Border Leaf коммутаторах и обычно привязана к IP-адресу логического интерфейса (Loopback0 или Loopback1).
- VNI (VXLAN Network Identifier) – численный идентификатор VXLAN сегмента. Аналог VLAN ID в классической коммутации. Данный термин применяется в документе как обозначение всего VXLAN сегмента
- BUM (Broadcast, Unknown unicast and Multicast) – аббревиатура для обозначения широковещательного трафика в L2-сегменте;
- HER (Head-End Replication) – способ распространения BUM-трафика путем репликации фрейма перед VXLAN-инкапсуляцией на входном VTEP. Количество репликации зависит от размера VXLAN flood-list;
-
-
Leaf (по сути это Top of the rack, ToR свичи) свичи отвечают за маршрутизацию и коммутацию tenant packets в vxlan VNID, применение сетевых политик к трафику. На leaf свичах поднимается vxlan в виде VTEP. Ip адрес, который представляет VTEP на leaf называется PTEP (physical tunnel endpoint).
-
Leaf switches are responsible for routing or bridging tenant packets and for applying network policies. The ip address that represents the leaf VTEP is called the physical tunnel enpdoint (PTEP).
-
- Spine свичи связывают всю топологию – spine и leaf устройства, внешние сети или несколько aci инсталляций. Spine свичи сохраняют mapping endpoint (как понимаю связь MAC+VNI) – PTEP.
Spine nodes interconnect leaf devices, and they can also be used to establish connections from a cisco ACI pod to an ip network or to interconnect miltiple ACI pods.
Mellanox LINKMEUP
For co-packaged optics, the Barefoot Tofino 2 switch ships in a multi-die package that makes it easier to co-package the optical engine and to upgrade the SerDes for lower power or higher throughput. Today’s data center switches depend on pluggable optics installed in the switch faceplate that are connected to switch serializer/deserializer (SerDes) ports using an electrical trace. But as data center switch bandwidth grows, connecting the SerDes to pluggable optics electrically will be more complex and require more power. With co-packaged optics, the optical port is placed near the switch within the same package, thus reducing power and enabling continued switch bandwidth scalability.
ARISTA linkmeup
https://www.arista.com/assets/data/pdf/Datasheets/7150S_Datasheet.pdf
https://www.arista.com/assets/data/pdf/CaseStudies/Qrator_CaseStudy.pdf
О дизайн ДЦ и технологиях ниже можно почитать в доке Juniper. Как ни странно один из сотрудников Arista оттуда 😉
Позиционируют себя как компания инженеров для инженеров.
- Broadcom Trident – хуже Tomohawk
- Broadcom Tomahawk – вносимая задержка ~300нc
- Broadcom Jericho – по производиельности круче чипов установленных в ASR/MX, по функционал неплох (достаточен для многих заказчиков), но не ASR/MX.
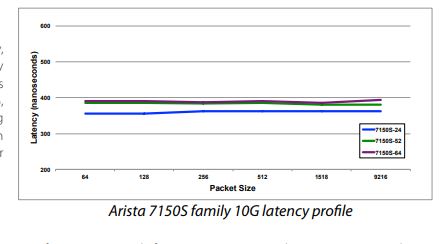
Arista купила вендора L1 оптических свичей. Там задержки десятки/единицы наносекунд, а не сотни.
Интеграция с VMWare. VMware vSphere есть такое же для OpenStack. Arista switch по SOAP у vCenter получает адреса VM на интерфейсе, конфигурацию VLAN и производит заливку VLAN – автоматически на свиче VLAN создается/добавляется в транк при прописывании на VM.
Есть свой SDN контроллер. На контроллере тот же EOS (OS Arista), что и на обычных свичах.
Один образ EOS на разные модели свичей – single image. Драйверы в image под все чипы. Ветка кодинга одна, коммит в эту ветку затрагивает все устройства!!!!
Arista делают не только свои свичи. Но могут и на whitebox железки заливать EOS – под спец проекты как понял, с допиливанием напильником (не обычному покупателю).
https://habr.com/ru/post/352564/ # хорошая статья о EVPN/VXLAN, тут так же затронуты “традиционные” методы построения ЦОД вида STP, MLAG, stacking.
EVPN/VXLAN позволяет “пробрасывать” L2 поверх L3. Это туннель – виртуальное соединение между коммутаторами. Часто используется в ЦОД – в ЦОДе это очень удобно, например, миграция ВМ обычно происходит в одном бродкаст домене.
В традиционной сети второго уровня OSI с множественными путями между коммутаторами мы обязаны использовать STP, MLAG или стекирование.


vxlan
- Vxlan – virtual extensible lan
- Vxlan обычно (если не настроить другое) работает на udp порту 4789
- Vxlan использует идентификатор локального L2 сегмента в виде VXLAN network identifier (VNI/VNID)
- Логический сегмент, идентифицируемый с VNID является бродкаст доменом, который туннелируется поверх vxlan tunnel endpoint (VTEP) туннелей.
- VXLAN поддерживается на уровне гипервизора – хост может поднимать туннель.
- В разработке VXLAN принимал участие vmware.
- OTV – проприетарная аналогия vxlan на девайсах cisco (nexus) и для задачи DCI.
- Использование udp в vxlan позволяет роутерам применять операцию хеширования на внешний udp заголовок (т.е. на заголовок добавленный vxlan) для балансировки сетевого трафика по ECMP. В итоге:
-
- сетевой трафик, передаваемый по overlay network туннелям балансируется на множество линков с использованием ECMP
- есть возможность сделать балансировку (выше) и отказоустойчивость на l3 для l2 трафика, с явными преимуществами в сравнении с l2 решениями по типу stp и erps
-
- Vxlan uses an identifier or a tag that represents a logical segment that is called the VXLAN Network Identifier (VNID). - The logical segment identified with the VNID is a layer 2 broadcast domain that is tunneled over the VTEP tunnels. - The use of UDP in VXLAN enables routers to apply hashing algorithms on the outer UDP header to load balance network traffic. Network traffic that is riding the overlay network tunnels is load balanced over multiple links using equal-cost multi-path routing (ECMP). - In traditional network designs, access switches connect to distribution switches. This causes redundant links to block due to spanning tree.
VXLAN – это вложение ethernet фрейма в UDP. VXLAN Segment – логический L2 сегмент (широковещательный домен) поверх Underlay сети ЦОД. Аналог VLAN в классической коммутации. При передаче данных через VXLAN-туннель оригинальный Ethernet-фрейм (с VLAN tag или без) инкапсулируется в VXLAN заголовок и далее в UDP заголовок длиной 8 байт.

Evpn
https://teacherbox.ru/kompseti/osnovy-evpn/.html?ysclid=m6quw04rsa75368941&
EVPN или Ethernet VPN — это основанный на BGP механизм управления для VXLAN для объявления MAC-адресов, привязки MAC-IP и IP-префиксов. Помимо VPN существует множество механизмов управления, которые существуют сегодня для VXLAN, такие как Multicast, механизмы Head End Replication и Controller Based.
Multicast: вы узнаете MAC в с помощью подкладывания флуда в группу многоадресной рассылки. При наличии других механизмов управления этот метод сегодня устарел и редко используется.
Head-End-Replication: в этом методе вам придется вручную определить удаленные VTEPs при конфигурации туннеля VXLAN. BUM (Broadcast, Unknown Unicast и Multicast) трафик будет отправляться только на те VTEP, которые настроены вручную.
EVPN: в этом методе управления мы используем MP-BGP для динамического заполнения flood-list для трафика BUM и последующего динамического обнаружения, а затем объявляем MAC-адреса, привязки MAC-IP и префиксы IP. MAC-адреса не изучаются с помощью механизма Flood and Learn, и поэтому этот метод менее интенсивен в BW, но в то же время сложен в настройке и устранении неполадок.
BUM трафик по особому обрабатывается напр. Unknown unicast не передается, но можно настроить исключения для определенных MAC
EVPN как я понял может быть поверх MPLS, а может быть поверх VXLAN, чаще сейчас используется второй. Зачастую используется моновендорно из-за проблем с совместимостью между разными вендорами. В EVPN (https://tools.ietf.org/html/rfc7432) VXLAN есть похожий на стандартный storm control. Петли и мак флап лочатся через EVPN MAC MOBILITY (есть RFC) – extended community вешается на каждый L2 маршрут. При появлении маршрута его sequence = 0, как только выучится через EVPN -> sequence увеличивается. На основе этого работает MAC dumping (или как то так) – если свич переучивает MAC с локального порта на EVPN-VXLAN, то через какое-то время (по таймеру/количеству флапов, аля 5 раз за минуту), мы лочим этот мак в одном из состояний.
MLAG с EVPN поддерживается и в целом рекомендуется на leaf. Так же в MLAG паре (пара свичей с настроенным MLAG ) поддерживается обнаружение петель по STP. Кроме того BPGU guard + errdisable на access портах.
Interoperability крайне важно рассматривается т.к. Arista догоняющие.
На Arista встречается IMIX packet loss при большой нагрузке – многие жаловались во время подкаста.
- Tony Lee – какой-то мега крутой network programmer. Как я понял он описывал решения по оптимизации протоколов isis/ospf под кейсы ДЦ (основная проблема какие-то флаги или флапы)
- Vxlan – почему? Broadcom и другие вендоры за него топят. Нет сигнализации ldp/rsvp (возможно плюс). Есть MPLS, но в меньших масштабах. Простая интеграция с гипервизорами/хостами по vxlan. RSVP крут, но не прост. Дизайн сложный. Сейчас не тренд. Современный ответ на него – сегмент роутинг.
• Позволяет нарезать L2 домены на subVLAN (VXLAN) – вместо 4094 бродкаст доменов 16 млн.• Передавать информацию subVLAN (VXLAN) через туннель – можно переносить виртуальную машину между ЦОД (VM Mobility) и сохранить ее в старом.
- по слухам где-то уже делают попытки использование segment routing как “замены” сигналинга на базе RSVP-TE/LDP для MPLS
- Evpn – Evpn часто плохо совместим между вендорами
- EBGP автономка на свич – cloud titans так делают, другие подражают. Есть плюсы в просмотре маршрута и рулении. Варианты:
- EBGP over EBGP + нет необходимости в rr и BGP clusters
- IBGP over EBGP + есть auto rd/rt
- Как понимаю частое явление поднятие bgp непосредственно на leaf:
- Leaf-коммутатор должен иметь BGP-сессии со всем подключенными Spine-коммутаторами, импортировать в процесс подключенные сети
- В свою очередь спайны держат сессии со всеми подключенными лифами, выступая в качестве рут-рефлекторов, и принимают от них только маршруты определённой длины и с определённым коммунити.
- Mclag (без vxlan или с)
- Anycast gateway
- Есть интегрированные решения с безопасностью – с PaloAlto
- Трафик до FW обычно идет в своем vrf (vxlan tenant), заходит на firewall, инспектируется, уходит в другой vrf (tenant)
- VMWARE любит LACP
- SPAN session бывает трех вариантов – обычная сессия, на CPU или с заворотом в GRE (в VMWARE distribute switch такое тоже реализовано)
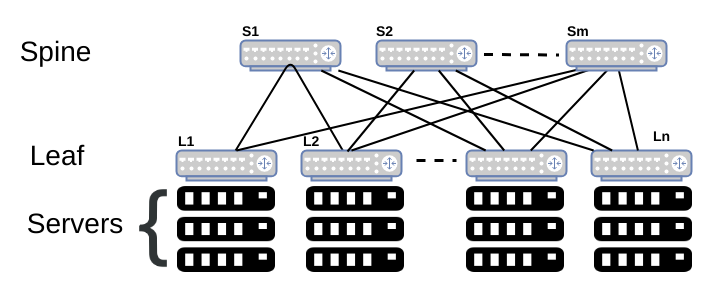
- Архитектура Leaf/spine (clos topology). Пришла из за повышенного обмена между серверами в одном ДЦ/стойке. Масштабируема. Leaf ниже по топологии, spine выше. Роутинг рекомендуется делать уже на leaf (ECMP), но можно и на spine. Каждый leaf (часто называется ToR – top of rack switch) должен быть подключен как минимум к двум spine для отказоустойчивости. В лучшем случае (как на картинке) каждый leaf подключен ко всем spine (или другими словами – каждый spine соединен со всеми leaf).
Интересное описание clos топологий. Пример чипа для DC сетей (clos topology) – Broadcom Tomahawk 4, 256x100G. Он ставит вопрос в необходимости шассийных коммутаторов в DC.
Its worth reconsidering the need for a chassis switch in most data centers, at least in just about every enterprise data center.

Интересная статистика:
- в большей части DC между leaf-spine (uplink) 100G, на сервера 25G
- в старых сетях 40G (не 10G) между leaf-spine, на сервера 10G
- spine коммутаторы обычно не имеют переподписку (сопоставление uplink + summary downlink bandwidth), spine коммутатор в общем случае подключает от 500 до 25к серверов (от 32 до 256 портов на spine коммутаторе и зависимости от плотности серверов в стойке, ниже)
- leaf коммутаторы часто имеют переподписку от 2 до 4ех раз – в общем случае к leaf свичу подключается от 20 (наиболее часто в DC) до 100 серверов (power, потребители)
- Spine может иметь несколько уровней (по сути ядро spine), если сеть DC по настоящему крупная.
- cabling стоит больше всего, поэтому 1) многоуровневый подход зачастую не выгоден 2) нужны большие скорости т.к. в общем случае 4х100G стоят дороже 1x400G.
The current generation of data centers are standardizing 25GbE links towards the servers and 100GbE towards the spine switches. Some of the older cloud native data centers used 10GbE as the server link speed and 40GbE as the inter-switch links (ISL, also called uplink). Hyperscalars, the main target of Tomahawk 4, are going beyond with 200GbE and 400GbE for ISLs. The ratio of input to output bandwidth — going in the direction of servers to the upper layers — is called the oversubscription ratio. A non-oversubscribed switch has equal input and output bandwidth. In other words, a non-oversubscribed switch has as much bandwidth towards the spine switches as the bandwidth from the servers. Most data centers, hyperscalar or otherwise, use non-oversubscribed switches from the spine upwards. The leaf switches are usually oversubscribed, with the oversubscription ratio varying between two (i.e. two server ports have one uplink port) to four. The leaf switch (also called ToR for Top of Rack), the layer of switches to which servers are connected, has ports with two different link speeds: one set devoted to connecting servers, and the other set is for interconnecting switches. Power typically dictates how many servers are in a rack. 40 servers per rack is common in hyperscalars while 20 ports per rack is more common in the enterprise data centers. I have also encountered dense 96 server racks. The number of uplink ports is determined by the oversubscription ratio. 40 server-facing ports of 25GbE is 1 Tbps of input bandwidth. Assuming an uplink speed of 100GbE, we need 10 uplink ports for a non-oversubscribed switch. Thus, we have 40+10 ports as the ideal switch port for such deployments. In case of the 96 server rack, 96 ports of 25G gives a bandwidth of 2.4Tbps (25*96). A non-oversubscribed switch needs 2.4Tbps of uplink bandwidth or 24 ports of 100GbE. A 4.8 Tbps switch would be very good for most data centers. Its also well known that except for the hyperscalars, most data center switches run empty a lot of the time. 4.8Tbps is 48 ports of 100GbE. Some racks are dedicated to storage and may push higher bandwidths such as 32 storage facing ports of 100GbE and use an oversubscription ratio of 1:1 and thus desire 32 ports of 100GbE as uplink ports. In such a case, a leaf switch needs to support at least 6.4 Tbps for a non-oversubscribed model. A spine switch on the other hand connects leaf switches. Thus a spine switch with 32 ports can hook up 32 racks. A spine switch with 64 ports can connect upto 64 racks. Assuming even 20 servers per rack, 64 racks represents about 1,280 servers, a large number for many enterprises. With 96 servers per rack, 64 racks represents 7,104 servers. With 256 ports, this number varies from 5,120 servers (for 20 servers per rack) to 24,576 servers (with 96 servers per rack). We’re now talking mighty large numbers in a single data center for anyone but the hyperscalars. As you move up the Clos topology, you can use a third tier of 256 port switches to interconnect 256 two-tier Clos topologies. This means with even 20 servers per port, you can connect 256*5,120 = 1,310,720 servers. With a four tier Clos topology, you get even higher numbers than this. These are ginormous numbers. Thus, we see that the use of a high port count switch makes a lot of sense as we move up the Clos topology, especially for larger networks. From a cost perspective, cabling is the biggest expense on the networking side. Reducing the number of tiers helps reduce the amount of cables used and therefore translates directly to reducing the cost of capital expenditure on a data center. The cost of optics for 400GbE can be lower than four 100GbE ports and this is another factor driving the use of Tomahawk 4 by the hyperscalars.
Протоколы DC, которые поддерживает IxNetwork IXIA.

Если листья ip фабрики не умеют л3 гейтвей то самое правильное докинуть вхлан до спайна, убрать там в врф и дать интернетик там. Еще варианты: Поднять ибгп для ипв4 уникаст с листа до спайна и поставить полиси что анонсится через ебгп андерлей, что через ибгп оверлей. третий вариант - тянуть вхлан до дцэдж, который в моем случае - в другом дц четвёртый вариант - тупо забить и отдать с андерлея. И передавать л3 клиентов через андерлей ебгп
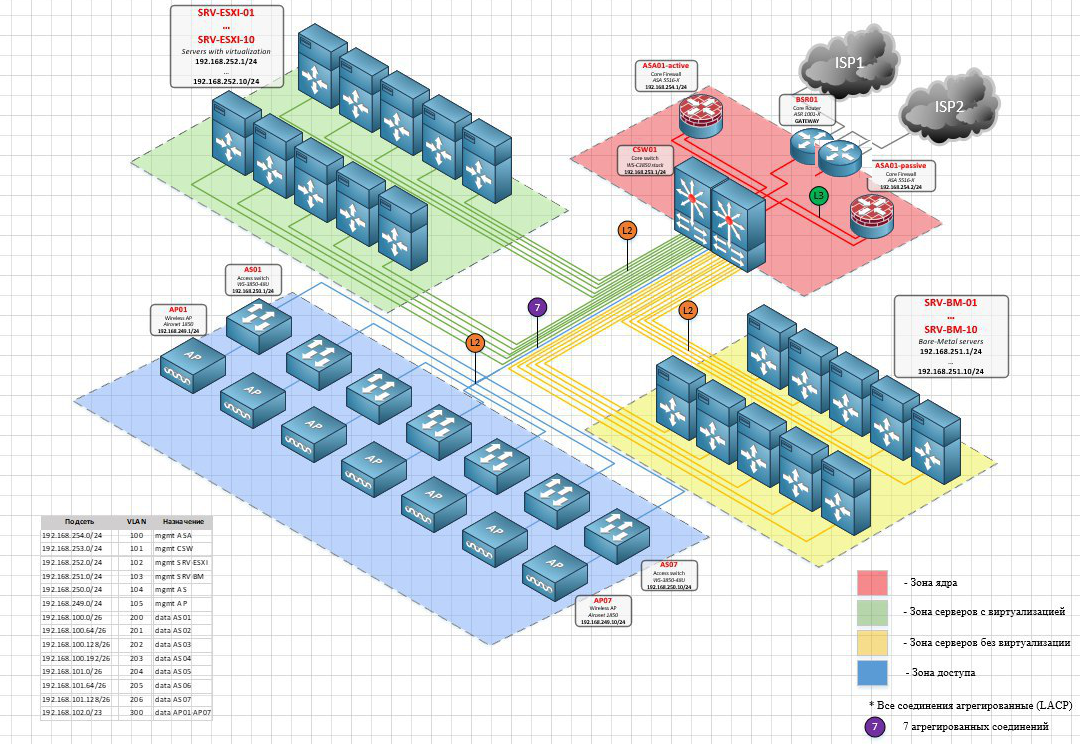
- два бордера ASR-1001 у каждого по линку в сеть
- две ASA в active/standby
- два свича L3 в стеке в качестве ядра – соединяют ASA, бордеры, сервера, свичи доступа.
- свичи доступа – в сторону access свичей (как понимаю и top of the rack на каждый сервер в стойках с поддержкой bonding – там не стойки) L2 lag канал с L3 свичей в стеке
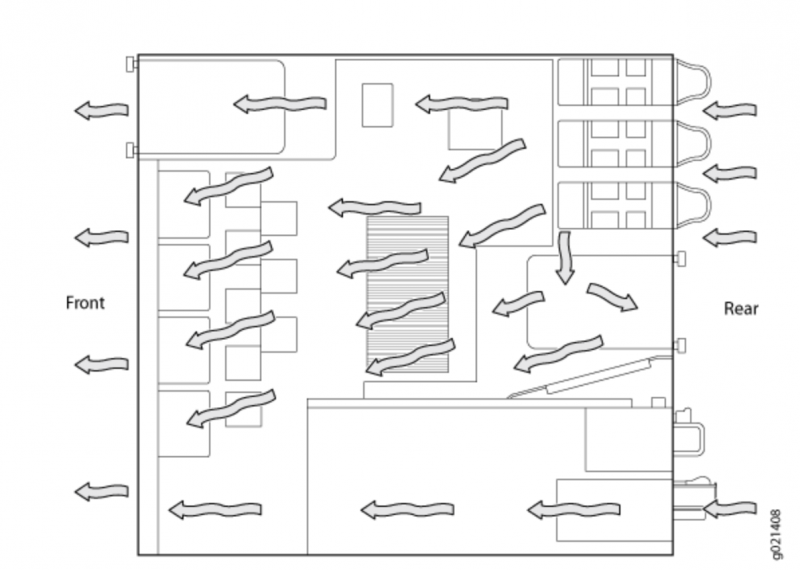
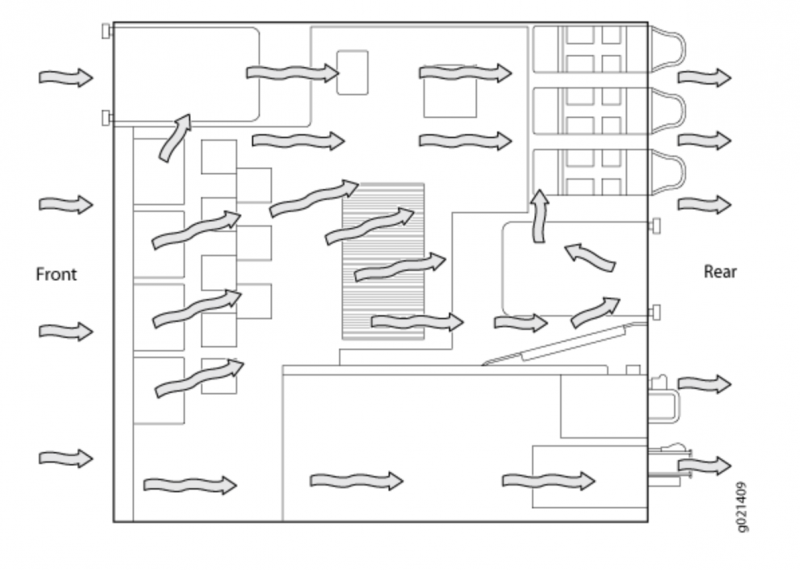
Охлаждение (cooling)
Стандартные схемы охлаждения:
- Back-to-Front Airflow – холодный воздух поступает сзади устройства, горячий выходит спереди
- Front-to-Back Airflow – холодный воздух поступает спереди устройства, горячий выходит сзади
https://www.juniper.net/documentation/en_US/release-independent/junos/topics/reference/general/cooling-system-ex4550.html
|
EX4550-FAN-AFI |
|
Back-to-front—air comes in from the back of the switch. |
|
EX4550-FAN-AFO |
|
Front-to-back—air exhausts from the back of the switch. |
Back-to-front—air intake to cool the chassis is through the vents on the rear panel of the chassis, and hot air exhausts through the vents on the front panel of the chassis. Front-to-back—air intake to cool the chassis is through the vents on the front panel of the chassis, and hot air exhausts through the vents on the rear panel of the chassis.
Back-to-Front Airflow
Front-to-Back Airflow
Вендоры ДЦ
- Cisco
- Mellanox
- Arista
- Juniper
- fs.com (как ни странно)
fs.com продает spine свичи 32x100G (N8560-32C) и даже один 32х400G (N9500-32D). С поддержкой VXLAN, EVPN, netconf, MCLAG, ECNF/PFC (сквозной flow control через фабрику).
https://www.fs.com/ru/products_support/c/100g-switches-3503?model=N8550-48B8C https://www.fs.com/ru/products_support/c/400g-switches-3255?model=N9500-32Dh ttps://www.fs.com/ru/products/96982.htmlhttps://www.fs.com/ru/products/109930.html https://www.fs.com/ru/?main_page=advanced_search_result&keyword=white+box&searchSubmit=%D0%9D%D0%B0%D0%B9%D1%82%D0%B8
Прикладывают результаты тестирования по RFC2544 (тестирования Ixia XGS 12, IxNetwork 9.0) – line rate 200G, задержка в пределах микросекунды (700-1200 ns). 400G коммутатор не протестировали Ixia, по крайней мере репорта нет 🙂 (видимо нет Ares/карт под XGS).
https://www.fs.com/ru/products/110480.htmlhttps://img-en.fs.com/file/report/nc8200-4td-switch-performance-test-report.pdfhttps://img-en.fs.com/file/report/nc8400-4th-switch-performance-test-report.pdfhttps://img-en.fs.com/file/user_manual/n5860-and-n8560-and-nc8200-series-switches-configuration-guide.pdfhttps://www.youtube.com/watch?v=gMsawLJzALI&t=2s
Софт может быть свой Cisco like (FSOS), но может быть и white box (ONIE like Cumulus) – напр. для 400G свича (only ONIE). Какие-то свичи продают уже с Cumulus с лицензией на 3 года. На какие-то можно и Cumulus и FSOS.
СКУД
- Камеры, датчики, система контроля доступа, сканеры
- нормальная практика оповещение на телефон (смс/мессенжер/звонок) в случае открытия (датчик) стойки
- нормальная так же практика (разделяемые цод, ведомственные, биржи и проч) многоуровневых контроль доступа с разными ответственными – на входе в дц, в автозал, в стойку и даже к конкретному серверу
Активно внедряют QR-коды даже сюда. Впринципе норм как дополнительный фактор, но считаю точно не как основной и врятли как замена карточек, хотя плюс возможности перевыпуска хоть каждый день существенный.
Компания Uni-Ubi реализовала поддержку распознавания QR-кода в свои биометрические терминалы. Теперь любой терминал Uni-Ubi — это не только устройство биометрической идентификации, но и устройство для считывания и обработки QR-кода. Внедрение функции идентификации по QR-коду позволяет расширить возможности СКУД, не прибегая к использованию дополнительных устройств, кроме самого терминала Uni-Ubi, который стал еще более функциональным. Преимущества идентификации по QR-коду: • Возможность полного отказа от RFID-карт • Дополнительный уровень безопасности • Не нужно согласие на сбор и обработку персональных биометрических данных • Никаких фотографий • Экономия времени и удобство Говоря об отказе от карт в пользу QR-кода нельзя не сказать, что QR-код также может быть элементом 2-х факторной идентификации. И если на вашем предприятии вчера использовалась схема «лицо + карта» или «карта+лицо», то сегодня вы можете внедрить систему «лицо + QR-код» или «QR-код + лицо». Причем, в отличие от карт, вы сможете из соображений безопасности менять QR-код для каждого сотрудника так часто как считаете это нужным.
Интересное:
-
-
This outage was triggered by the system that manages our global backbone network capacity. During one of these routine maintenance jobs, a command was issued with the intention to assess the availability of global backbone capacity, which unintentionally took down all the connections in our backbone network, effectively disconnecting Facebook data centers globally. Our systems are designed to audit commands like these to prevent mistakes like this, but a bug in that audit tool prevented it from properly stopping the command.
- Причина аварии на этой неделе (NextHop 2021 facebook engineer): стечение обстоятельств умноженные на особенности имплементации некоторых систем автоматизации. Нет злого умысла и скрытых смыслов. Извлечем все уроки, включая – минимизацию таких ситуаций в будущем, улучшим скорость поднятия сервисов.
-
Используется bgp. Топология leaf spine трехуровневая, верхние spine в одной BGP AS, нижние ноды (оба уровня) в разных.
- Упал и in-band канал и out-of band.
-
Полиси апдейты сначала проходят тесты перед деплоем в прод.
-
Написали свой урезанный bgp agent, он совместим со стандартным, но в нем только нужное
-
Честный знак
- Потенциальные косяки/троллинг
- А почему не настроили MAC Cisco на Arista? Поддерживается Arista.
Время необходимое на «переучивание» ARP-записей всеми серверами, как известно, зависит от настроек ARP refresh timeout на каждом из них. -
Вот это объемы 😀Большой объем данных, когда, при физическом переключении хостов одного сервиса, требовалось инициализировать изменения в конфигах до сорока коммутаторах одновременно, многократно увеличивал вероятность ошибки.
-
Смысл, насколько я понял, в отказе от multichassis исполнений, особенно с несколькими мозгами, но не forwarding ASIC, да и что такое forwarding ASIC? Насколько мне известно тяжелая логика forwarding реализуется на базе FPGA/CPU, а ASIC используются как port-ASIC или switch-fabric asic для тупых задач.Используя в своей сетевой инфраструктуре оборудование, имеющее на своем борту несколько forwarding ASIC вы рискуете попасть в ситуацию, когда функционал коммутатора деградирует, но он продолжает стягивать на себя трафик порождая, значительно более серьезные и трудно локализуемые проблемы, нежели те, что возникли бы, просто выйди он из строя окончательно. Поэтому hardware-design сетевого оборудования должен быть простым и надежным как автомат Калашникова, а значит один ASIC на борту – обязательное условие.
- А почему не настроили MAC Cisco на Arista? Поддерживается Arista.
- – Активное использование Arista CVP (CloudVision Portal), подробнее в статье про NMS. Хотят заинтегрировать Netbox и Arista CVP.
Например, следующим логичным шагом нам видится интеграция нашей системы IPAM Netbox и Ansible AVD для автоматической подготовки разливки серверов при их добавлении в Netbox
- – Современные реалии в области сетевых технологий для центров обработки данных таковы, что открытый стандарт VXLAN ((внедрили EVPN + VXLAN)) является рыночным эталоном и его поддержка жизненно нам необходима.
- – Пропускная способность сети полностью соответствовала нашим ожиданиям, каждый хост мог рассчитывать на 20 Гбит/с до любого своего соседа по ЦОД без переподписки
- – Фабрика была развернута автоматически с помощью модуля в CVP Zero-Touch Provisioning;
- – Централизованная система управления CVP была имплементирована в наш ИТ-ландшафт для реализации IaaC-концепции. Описание всей сетевой инфраструктуры: подключения серверов, описание VLAN/SVI, IP VRF, было выполнено в текстовом виде с использованием языка YAML. Это позволило нам заложить основу для дальнейшей подготовки конфигураций оборудования Arista для миграции основного ЦОД.
- – В пилотном ЦОД мы использовали 2 коммутатора на уровне Spine. Каждый 10/25GE Leaf коммутатор подключался с помощью 2x100GE аплинков. В основном ЦОДе в последствии были использованы 4 Spine и, соответственно, 4x100GE аплинков.
- – Leaf: Arista 7050TX3-48C8: 48x 10GBaseT and 8x 100G QSFP ports.
- – Выбранное решение Arista EVPN-VXLAN позволило нам также перейти на IP MTU для серверов равное 9000.
- – По факту в итоге реализова сеть не leaf-spine, а leaf-spine + к spine подключается старый уровень агрегации и access 😀

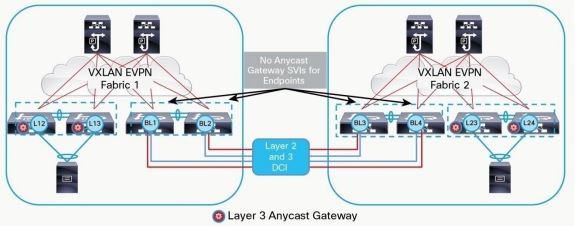
- – Использовали Anycast Gateway – Использование распределенной маршрутизации на коммутаторах уровня Leaf с использованием технологии Anycast Gateway – Единый EVPN Symmetric IRB домен с Anycast GW распределенного на уровне Leaf;
- – Обеспечение сегментации с помощью наложенных (Overlay) L2/L3 сетей, растянутых как внутри ЦОД, так и между двух ЦОД;
- – L2-сегменты изолированы в рамках одного ЦОД, связность между ЦОД по EVPN Type5; НО на момент миграции пробрасывали трафик из фабрики Arista на старую точку терминации, после физической миграции назначали на Arista Leaf IP Anycast Gateway, который ранее был на Cisco, при этом на Cisco ренамберили адрес на свободный – в итоге до истечения ARP хосты маршрутизировались за счет DST MAC CISCO через стык фабрики с Cisco, а после истечения ARP уже полностью через новую фабрику за счет DST MAC Arista Anycast Gateway:
- Требовалось не просто развернуть сетевую инфраструктуру на Arista рядом с существующей, но и интегрировать их между собой на уровне L2 и L3 для бесшовной миграции. Для этого мы «растянули» существующие VLAN между фабриками Arista и Cisco и получили возможность физически переключить сервера.
- Завершив этап физического переключения, мы оказались в ситуации, когда серверы были уже подключены к новой сетевой инфраструктуре, но маршрутизация трафика все еще выполнялась на старом ядре. На этом шаге важным моментом была пропускная способность стыка между старой и новой инфраструктурой, так как весь inter-VLAN трафик теперь маршрутизировался через этот него. Нам требовалось, незаметно для приложений, перенести точки маршрутизации на новую фабрику с использованием следующей методики:
- На коммутаторах Arista уровня Leaf настраивался SVI (EVPN IRB) для мигрирующего VLAN с IP-адресом Anycast Gateway совпадающим с существующим Cisco IP Gateway.
- На оборудовании Cisco IP Gateway менялся на любой свободный IP-адрес этой подсети.
В такой ситуации трафик по-прежнему продолжал передаваться через оборудование Cisco, так как сервера продолжают считать, что MAC-адрес шлюза это Cisco MAC. Но все последующие за этим широковещательные ARP-запросы на серверах (по истечение ARP timeout) обрабатывались только коммутаторами Arista, которые отправляли ARP Reply уже с Arista VMAC. При этом, оборудование Cisco игнорировало такие запросы, так как IP-адрес в ARP-запросе не совпадал ни с каким из настроенных на интерфейсе IP-адресов.
- – Использование выделенной сети внеполосного управления (Out-of-Band Management) максимально независящей от основной сетевой инфраструктуры ЦОД;
- Незаметным немного ложь конечно.
Как и ожидалось, самым продолжительным, хотя и незаметным для приложений, шагом стало переключение физических линков продуктивных хостов. Оно заняло четыре месяца так как 95% объема работ, с участием инженеров вендора, было выполнено в дневное рабочее время, на случай аварийной ситуации. Методика переключений была проста:- Переключаем один data-link сервера;
- Проверяем, что на коммутаторах Arista сервер виден, но Port-Channel еще не поднят;
- Переключаем второй data-link сервера – в этот момент bond-интерфейс на сервере быстро падает и поднимается уже с коммутатором Arista.
- Оптимальное распространение маршрутной информации в топологиях с плотной связностью (dense Clos topologies);
- Поддержка балансировки Equal Cost Multi Path (ECMP) для равномерной загрузки;
- Использование единственного протокола для организации Underlay и Overlay.
- Общая ASN на уровень Spine для сокращения генерации излишних копий маршрутов;
- Уникальные ASN на каждый EVPN-VXLAN коммутатор; ((на практике может не соблюдаться и все leaf в одной AS))
EVPN/VxLAN (инфа отсюда, не проверена)
В качестве Leaf-коммутаторов будут использоваться коммутаторы L2 CS2100 от B4COM В качестве Spine-коммутаторов будут использоваться коммутаторы L3 CS4100 от B4COM

Рисунок 1 – Схема
Для поднятия iBGP сессии первично настраивается IGP протокол – OSPF. Leaf-to-Spine соотносятся как client-to-RR. Для повышенной отказоусточивости между Leaf-коммутаторами настроен EVPN Multihoming
Ниже приведена конфигурация настройки EVPN Multihoming
evpn esi hold-time 60
!
evpn vxlan multihoming enable
!
interface po1
switchport
description Link to SRV
evpn multi-homed system-mac 0000.0000.5555
!
interface xe57
channel-group 1 mode activeПосле активации возможности multihoming перезагрузка оборудования обязательна. Для защиты от flap используется таймер esi hold. На интерфейсе-агрегате в сторону клиента также создается мак для ESI. Аналогичная настройка на втором Leaf-коммутаторе. Со стороны клиента настраивается обычный LACP.
Для защиты от blackholing будет использована функция TFO (Trigger FailOver) – в случае падения каналов в сторону spine, клиент не будет оповещен и продолжить отправлять трафик, который будет уходить в blackhole. При включенном TFO в случае падения каналов на стыке Leaf-Spine автоматически будут выключены интерфейсы в сторону SRV (т.е po1).
tfo Enable
fog 1 enable
!
interface po1
link-type downlink
fog 1 type cpg
!
interface ce49
link-type uplink
fog 1 type mpg
!
interface ce50
link-type uplink
fog 1 type mpgДля уменьшения таймеров BGP-сессий и незамедлительного реагирования на изменения физической среды будет настроен BFD (Bidirectional Forwarding Detection)
bfd notification enable
!
// В случае если устройства подключены не напрямую
bfd multihop-peer 172.16.0.71 interval 300 minrx 300 multiplier 3
!
router bgp 65100
neighbor 172.16.0.71 fall-over bfd multihopДля обеспечения маршрутизации между L2 overlay сегментами необходимо использовать IRB-интерфейсы. IRB могут работать в двух режимах – симметричном и асимметричном. Ниже приведена конфигурация IRB в асимметричном режиме.
nvo vxlan irb
!
ip vrf L3VRF1
rd 172.16.0.51:1111
route-target both 1111:1111
l3vni 2005001
!
evpn irb-forwarding anycastgateway-mac 0000.2222.1111
!
interface irb1
ip vrf forwarding L3VRF1
evpn irb-if-forwarding anycastgateway-mac
ip address 172.16.145.1 255.255.255.0 anycast
!
nvo vxlan id 145 ingress-replication inner-vid-disabled
vxlan host-reachability-protocol evpn-bgp L2VRF
evpn irb5
vni-name L2VRF
!
nvo vxlan access-if port-vlan po1 145
map vni-name L2VRF
!
router bgp 65100
address-family ipv4 vrf L3VRF1
redistribute connectedПосле активации IRB-интерфейса на устройстве перезагрузка обязательна. Для таблиц маршрутизациия используется L3 VRF. К IRB-интерфейсу привязывается L3VRF и указывается MAC-адрес. Непосредственно для L2 VNI привязывается IRB-интерфейс в качестве шлюза по умолчанию. К VLAN привязывается L2 VRF. Редистрибьюция подключенных сетей в BGP также обязательна. На клиенте указывается шлюз по умолчанию – IRB интерфейс, который должен быть настроен с таким же IP адресом на втором Leaf-коммутаторе.
Полезные отладочные команды для EVPN и VxLAN указаны ниже
show nvo vxlan
!
show nvo vxlan mac-table
!
show nvo vxlan tunnel
!
show bgp l2vpn evpn summary
!
show bgp l2vpn evpn vrf <VRF>
!
show bgp l2vpn evpn multihoming es-routeИнтересное из исследования Jet/IKS (выдержки)
https://disk.yandex.ru/i/XUezA6nfWviLfw
- По оценке экспертов, в России на коммерческие ЦОДы приходится около 18% всех ИТ-стоек – остальные установлены в корпоративных дата-центрах (в западных странах это соотношение, по данным Uptime Institute, примерно 50 на 50).
- Общую емкость ЦОДов в России можно оценить в 450 тыс. стоек.
- Объем российского рынка коммутаторов для ЦОДов эксперты «ИКС» оценивают в $100 млн. Оценка приводится в долларах США, поскольку в ЦОДах требуются высокопроизводительные коммутаторы, которые до 2022 г. поставлялись на российский рынок небольшим числом зарубежных вендоров, прекративших работу в стране. Сейчас на этом рынке работают в основном российские производители, оборудование которых находится в стадии активной доработки, но пока по своим характеристикам не достигло уровня ведущих мировых образцов.
- Основной технологией построения сетевых инфраструктур, в том числе в ЦОДах, является Ethernet.
- Однако около 60% заказчиков также применяют Fibre Channel для организации сетей СХД. Ранее выбор Fibre Channel для этих задач был очевиден: нестабильные IP-сети с потерями пакетов и высокими задержками не могли обеспечить необходимый уровень производительности и надежности. Инфраструктура Fibre Channel решала эти проблемы, предоставляя выделенную сеть с гарантированной пропускной способностью. Однако за последние двадцать лет ситуация кардинально изменилась. Появление массивов All-Flash и NVMe-накопителей трансформировало требования к СХД. Традиционные проблемы производительности ушли на второй план, а ключевыми факторами стали гибкость инфраструктуры, простота масштабирования и технологическая неза-висимость. Экономика также говорит в пользу Ethernet: 100-гигабитный порт Ethernet стоит вдвое дешевле 32-гигабитного порта Fibre Channel при троекратном преимуществе в пропускной способности. В условиях, когда весь рынок FC контролируют только два американских вендора, а российские производители активно развивают Ethernet-решения для IP-сетей, выбор технологии становится вопросом стратегической важности. Поэтому можно прогнозировать снижениеиспользования технологии Fibre Channel.
- Из опрошенных только две компании ис-пользуют технологию InfiniBand. Эта тех-нология в основном применяется для вы-сокопроизводительных кластеров и для суперкомпьютеров, где требуется очень низкая задержка. В типовых ЦОДах она применяется крайне редко, но имеет определенные перспективы на объектах нового поколения, оптимизированных под приложения с искусственным интеллектом. Как и в случае с Fibre Channel, санкционные риски применения InfiniBand российскими заказ-чиками довольно велики, поэтому более перспективными выглядят высокоскоростные варианты Ethernet, особенно с технологией прямого доступа к памяти (RDMA over Converged Ethernet, RoCE). Однако данную технологию пока применяет лишь один из респондентов.
- Довольно низок уровень внедрения и технологии SDN – ее применяет лишь каждый десятый. Согласно приведенным выше дан-ным Global Market Insights, в 2024 г. примерно две трети проданных в мире коммутаторов для ЦОДов имели поддержку SDN. Таким образом по внедрению SDN в сетях ЦОДов российский рынок существенно отстает от мирового. Возможно, это связано со слабой поддержкой соответствующего функционала в продуктах российских производителей. Международные эксперты GMI разделяют рынок коммутаторов для ЦОДов на традиционные коммутаторы и решения для программно определяемых сетей (SDN). Интерес заказчиков к SDN эксперты связывают с необходимостью повышения гибкости сети и ее масштабируемости. SDN позволяет централизованно контролировать сетевые ресурсы и динамически управлять ими, облегчая адаптацию к изменяющимся рабочим нагрузкам и требованиям приложений. Кроме того, соответствующие технологии предполагают возможность автоматизации конфигурирования сети, оптимизации маршрутизации трафика и повышения общей эффективности сети, что имеет решающее значение в современных средах ЦОДов с меняющимися требованиями к виртуализации, облачным вычислениям и эффективному использованию ресурсов.
- Главная причина доминирования трафика «запад – восток» – особен-ности архитектуры приложений, которые обычно разворачиваются на оборудовании, размещенном в ЦОДе. Например, пользователь, заходя на сайт, хостинг которого обеспечивает ЦОД, порождает всего один внешний запрос к веб-серверу (трафик «север – юг»). Но внутри ЦОДа он создает целый набор подключений: например, от балансиров-щика нагрузки к одному серверу, от того к другому, затем к базе данных и обратно (трафик «запад – восток»)
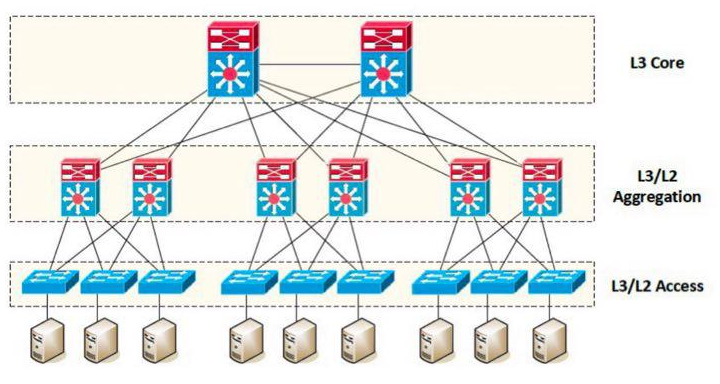
- Широкое применение виртуализации и облачных вычислений привело к тому, что для ЦОДов потребовалась новая сетевая архитектура, способная обеспечить меньшее время задержки и большую пропускную способность. Такая архитектура (рис. 5), получившая название сетевой фабрики, основана на соединениях между коммутаторами доступа (leaf) и ядра (spine). В ней каждый коммутатор нижне-го уровня (leaf) соединен выделенной неблокируемой связью с каждым коммутатором верхнего уровня (spine). Основное достоинство такой архитектуры в том, что при обмене данными между двумя произвольно взятыми серверами трафик проходит только через один коммутатор spine,и задержка сигнала становится предсказуемой.
- Однако, несмотря на все преимущества архитектуры leaf — spine, как показал проведенный опрос, часть респондентов продолжают использовать для подключения серверов классические технологии VSS/Stack/MCLAG или коммутаторы ядра своей кампусной (campus) сети. Ряд заказчиков сочетают в своей инфраструктуре оба подхода (рис. 6).

- На периферии сети, на уровне серверов, сегодня задействуются в основном интерфейсы 1, 10 и 25 Гбит/с, причем более 60% используют каналы 10 Гбит/с (рис. 7). Здесь еще применяют медножильные подключения: шнуры СКС или шнуры прямого подключения (DAС) – особенно когда коммутаторы доступа (leaf-коммутаторы) установлены в стойки с серверами (в архитектуре ToR). Если же такие коммутаторы располагаются в середине ряда стоек (MoR) или в его конце (EoR), то для подключения серверов чаще применяют оптику. Следует заметить, что архитектуры MoR и EoR становятся все более популярными, поскольку позволяют уменьшить число коммутаторов и таким образом снизить сложность сети и задержку при передаче трафика. В ряде ЦОДов на уровне доступа применяют каналы 40 и 100 Гбит/c (см. рис. 7). А в одномзадействуют даже более скоростные каналы. В схожем исследовании, проведенном журналом LAN в 2012 г., большая часть респондентов (64%) использовала для подключения серверов каналы 1 Гбит/с. Сегодня доля таких ответов упала втрое – до 20%. Также примерно втрое, но выросла, доля опрошенных, применяющих технологию 10 Гбит/с. В 2012 г. примерно четверть компаний для подключения серверов в ЦОДах задействовала каналы 100 Мбит/с, сегодня про такие каналы не упомянул ни один из респондентов.

- При скоростях на уровне доступа 10 и 25 Гбит/с для взаимодействия между коммутаторами обычно применяют каналы 40 и 100 Гбит/c соответственно.При повышении скорости подключения до 50 и 100 Гбит/с каналы межкоммутаторного взаимодействия расширяют до 100 и 400 Гбит/с и более (рис. 8).

- Производители. На сегодняшний день в российских ЦОДах доминируют сетевые коммутаторы зарубежных производителей. Очевидный лидер – Cisco, продукцию этой американской корпорации используют более 70% опрошенных. На втором месте из зарубежных вендоров – китайская Huawei (39%). Далее идут HPE (Hewlett Packard Enterprise), Juniper Networks и Extreme Networks (рис. 9). Высокое место заняла новосибирская компания Eltex («Элтекс») – об использовании ее продукции заявили 50% опрошенных. В целом отечественные коммутаторы уже применяют 60% компаний (рис. 10). Это также очень высокий показатель для рынка, где еще несколько лет назад доминировали зарубежные вендоры. Помимо Eltex респонденты также упомянуликомпании B4Com («Бифорком Текнолоджис»), «Аквариус», YADRO, «Сила» и «Т-КОМ».

- В техническом аспекте у большинства российских компаний не возникает особых проблем, связанных с сетевой инфраструктурой ЦОДов. Так, всего четыре компании пожаловались на недостаточную скорость портов досту-па, и три – на ограничения используемой архитектуры сети. Вдвое больше опрошенных испытывают проблемы,обусловленные недостаточным функционалом коммутаторов (рис. 11). При этом респонденты упоминают отсутствие функционала кластеризации (MCLAG, Stack, VSS), SDN/микро-сегментации, а также функций прямого доступа к памяти по сети Ethernet (RoCE). Вариант «Недостаточная производительность коммутаторов», который был указан как один из возможных, не выбрал никто. Более 40% опрошенных столкнулись с проблемами, связанными с поддержкой/модернизацией используемого ими оборудования ушедших с рынка вендоров. Характерные комментарии:«Все было отлично, пока не ушли с рынка (зарубежные) вендоры, самое главное – не хватает поддержки» или «С зарубежными вендорами проблем не было, сейчас с российскими – “сырое” и недоработанное оборудование». Ряд компаний также упомянули дефицит оборудования.Схема параллельного импорта имеет определенные недостатки в виде увеличенного времени доставки и отсутствия официальной сервисной поддержки. Но для многих компаний технологические преимущества продукции мировых лидеров и возможность покупки их по конкурентной цене перевешивают недостатки. Так, треть опрошенных продолжат закупать оборудование тех ушедшихс рынка РФ зарубежных вендоров, решения которых они уже используют(рис. 14). Еще 16% планируют перейти на оборудование зарубежных вендоров, которые по-прежнему работают в России. Видимо, речь идет в первую очередь о китайских производителях. Таким образом, половина компаний намерена и дальше использовать зарубежное оборудование. Немало и тех, кто собирается перейти на оборудование российских производителей (42%). При этом одно не исключает другое. Очевидно, что многие будут совмещать в своей сетевой инфраструктуре оборудование зарубежных и отечественных производителей. Вот, например, характерный ответ одного из респондентов: «Где критично, там Cisco, где не критично, там Eltex». Видимо, пока немногие готовы доверять российским коммутаторам «критичные участки», в том числе из-за недостатков,о которых говорилось выше.

- Если исходить из планов заказчиков, то компания Eltex («Элтекс») уверенно сохранит лидерство – ее коммутаторы будут закупать 52% опрошенных. Найдут своих заказчиков и продукты Qtech (8% опрошенных планируют закупки), B4Com (8%) и «Т-КОМ» (6%). Также среди российских компаний, чьи коммутаторы будут закупать для инфраструктуры ЦОДов, в нашем опросе названы «Аквариус», YADRO и «Сила».

- В числе основных недостатков сетевых решений российских производителей (рис. 12) компании называют недостаточный функционал (18% респондентов), высокую стоимость (14%), сильную зависимость от зарубежной элементной базы (12%) и недостаточный уровень сервисной поддержки (12%). Многие респонденты жалуются на ПО: «много ошибок», «недостаточно гибкое», «слабые возможности настройки», «непродуманный синтаксис, неудобно управлять». Примечательно, что хотя у респондентов в явном виде спрашивали, испытывали ли они проблемы из-за недостаточной скорости интерфейсов или недостаточной производительности отечественных коммутаторов, никто не выбрал эти варианты. Правда, жалоба на «слабый процессор» в ответах присутстуют. Отдельно был изучен вопрос, какого функционала в отечественных коммутаторах не хватает для их использования в сетевых инфраструктурах ЦОДов. И здесь респонденты в первую очередь назвали отсутствие функционала кластеризации (на это указали 22% опрошенных), который реализуется с помощью таких технологий, как MCLAG, Stack и VSS. Также ряду заказчиков не хватает функции SDN/микросегментации (4%).


- Большинство опрошенных планируют эволюционное развитие своих сетей: их масштабирование с увеличением числа коммутаторов (50%), расширение каналов связи (22%) – как для подключения серверов, так и для связи между коммутаторами.

- Сеть и ИИ, RoCEv2. В связи с бурным развитием больших языковых моделей (LLM) и увеличением рабочих нагрузок, связанных с ИИ, многие мировые провайдеры перепроектируют свои крупные ЦОДы для размещения кластеров ИИ, выполняющих эти специализированные задачи. Это привело к появлению новых сетевых архитектур, использующих концепцию интерфейсных (front-end) и серверных (back-end) сетей. Интерфейсная сеть управляет взаимодействием с пользователями, приемом данных и вычислительными задачами общего назначения. Серверная сеть предназначена для высокоскоростной передачи больших объемов данных между ИИ-ускорителями, такими как GPU. Она справляется с интенсив-ными вычислительными нагрузками, необходимыми для распределенного обучения и вывода больших моделей искусственного интеллекта. Поддержка RoCEv2 является основополагающим требованием в этой сети для обеспечения высокоскоростного взаимодействия между графическими процессорами.
- По сути, все описанные выше варианты сетевых архитектур относятся к категории интерфейсных сетей. Архитектура и технологии серверных сетей во многом определяются особенностями используемых ИИ-ускорителей. Они могут базироваться, в частности, на технологиях Lossless Ethernet (с использованием RoCEv2) или InfiniBand. Ряд мировых производителей, таких как, Cisco, Nvidia и Intel, разработали референсные архитектуры для таких сетей. Например, Intel предлагает каждый узел (c GPU-ускорителями) подключать к трем различным коммутаторам доступа (leaf), а каждый такой коммутатор – к выделенному набору spine коммутаторов.
- Подавляющее большинство (92%) либо не изменили свои планы, либо не рассматривали этот вопрос. Только четыре респондента ответили утвердительно.И двое из них планируют ради внедрения ИИ-систем переходить на другую архитектуру (топологию).
- Заметим, что ни один из опрошенных не планирует внедрять (для ИИ) сетевую технологию InfiniBand, хотя два заказчика ее уже используют. Отсутствие таких планов связано в том числе с высокими санкционными рисками применения зарубежных решений. Развитие сетей отечественных ЦОДов будет происходить на основе технологии Ethernet, которую российские производители уже неплохо освоили.
Cdn
- Для балансировки плохо использовать методы, которые полагаются на source ip в dns запросе (GSLB) т.к. многие сидят на провайдерских dns (рекурсия) и запросы идут от него. Для таких сценариев лучше когда пользователи используют public dns, а в рф их по сути только яндекс и распространенность его низкая.
- Так же есть проблема миграции между регионами пользовательских пулов ipv4 адресов у мобильных операторов.
- Anycast для балансировки на уровне cdn работает и большинство этим пользуется – у мтс все на anycast (планируют частично отказаться; проблема к примеру с тем что провайдеры зачастую футболят «я хер знает как этот эникаст у нас работает, разбирайтесь сами»), у яндекса только статический контент anycast раздается (js, xml, css и проч).
Мтс в своем cdn использует:
- Балансировка по 302 (redirect) с шардированием
- Все балансирует Anycast
Яндекс
- Cdn это серый кардинал интернета – 80% трафика яндекса раздается именно cdn, а не через цод (у google через их google cdn cache/pni в приватных стыках более половины их трафика) и интернет был бы другим без cdn т.к. стыки это очень дорого и большая политика (оба фактора очень весомы). Операторы очень ценят разгрузку своих аплинков, а провайдеры сервисов/девайсов/игр спасают свою инфру от перегрузов/обеспечивают пользовательский опыт (патчи игр, патчи ОС, прошивки колонок и других iot, видео включая порно).
- Сами cdn ноды устанавливаются на узел связи оператора, это обычно 1-2 сервера (реже 3), которые занимаются только раздачей, без каких то вычислений на них. Ставить туда mini цод ввиде контейнера/много серверов (китайская схема с china telecom) это большие накладные расходы как на яндекс (закупка серверов), так и на оператора (питание/охлаждение/место).
- Приватный cdn (т.е. для обслуживание сервисов самого яндекса) намного больше, чем публичный
- в своем cdn использует:
- Балансировка в основном всего контента (в частности видео/музыка/прошивки колонок, которые весят до гигабайта – раньше лежало без cdn в s3 и пока не стала нагрузка в виде ~сотни gbps) через через центральную ноду по unicast (“можем себе позволить» имеют ввиду объемы в виде терабитов/низкого latency ДЦ каналов) – она выдает умному клиенту адрес ноды cdn, на который нужно обратится за дальнейшим (тяжелым) контентом, при этом из пула исключаются те ноды, которые загружены более 90% по cpu или bandwidth. Умность – если клиент не смог подключится к основному серверу, он обращается к бекапному и отправляет телеметрию.
- Anycast для статики причем rps запросов огромный (в mbps немного – менее 100 gbps), но в целом основной способ это unicast