
Информация собрана из разных мест, часть как конспект вебинара HonorCup E=DC2 для сдачи HCNA Storage.
- DMA — это механизм, с помощью которого аппаратное устройство может передавать данные в память или из нее без использования процессора. Процессор требуется для настройки передачи, и устройство будет сигнализировать процессору, когда он завершит передачу.
- К1810ВМ86 – “свои” советские процессоры, причем выпускались “с Украиной”, сейчас это трудно себе представить; хотя потенциально Зеленоградские (обе компании) Ангстрем и/или Микрон могут аналоги скоро начать делать
- ASML во многом международный монополист как производитель фотолитографических машин. По слухам основатели русские, мигрировавшие в Голландию.
- AMD с Ryzen 7 судя по всему молодцы
https://www.ixbt.com/news/2021/03/07/intel-core-i7-11700k-125-291-ryzen-7-5800x.html Но пока Core i7-11700K выглядит очень бледно на фоне AMD Ryzen 7 5800X. И даже если производительность станет немного выше, ничто не компенсирует огромную разницу в энергопотреблении этих CPU. Так что и после выхода Core i7-11700K Ryzen 7 5800X по-прежнему будет более выгодной покупкой.
- Серверные модели CPU:
- Intel Xeon
- AMD Opteron
Temperature
Подробная статья пор перегрев.
Оптимально (в общем случае) температура CPU не должна превышать 60-70 °C во время нагрузки (игры, рендеринга), если только это не какое-то тестирование на стабильность/устойчивость под высокой нагрузкой.
В случае превышения температуры процессора
-
- вентилятор на кулере пррорцессора начинает повышать обороты до максимума,
- если это не помогает начинает работать throttling,
- если и это безуспешно – может происходить аварийное отключение ПАК
В моем практическом случае перегрев был из-за двух факторов:
-
- Высохла термопаста
- Недостаточный прижим радиатора к процессору
Потребление питания/мощность/тепловыведение
Очень отличается в зависимости от процессора (грубо от 100 до 200 Вт), пример:
Intel® Core™ i7-3770 https://ark.intel.com/content/www/ru/ru/ark/products/65719/intel-core-i73770-processor-8m-cache-up-to-3-90-ghz.html Расчетная мощность 77 W тепловыделение: 77 Вт Процессор Intel Core i7-12700KF LGA1700, 12 x 3600 МГц, OEM тепловыделение: 190 Вт Процессор AMD Ryzen 7 5800X AM4, 8 x 3800 МГц, OEM Процессор AMD Ryzen 9 3950X тепловыделение: 105 Вт тепловыделение: 105 Вт
Архитектура
Стандартная архитектура CPU: АЛУ, управление, память, шина.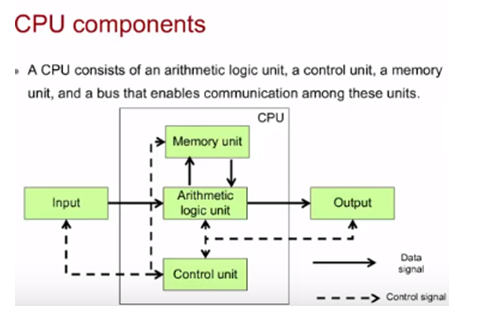
Три типа наборов команд CPU:
-
- CISC – Complex Instruction Set Computer (x86 CPU)
- RISC – Reduced Instruction Set Computer (IBM Power, ARM)
- EPIC – Explicitly Parallel Instruction Computers (Intel Itanium CPU)
КЭШ
У процессоров бывают несколько уровней кэша. Уровни отличаются скоростью и объемом: на первом уровне быстрый, на последнем – объемный. Пример для Core i7 Ivy Bridge:
-
Объем кэша L1 64 Кб Объем кэша L2 1024 Кб Объем кэша L3 10240 Кб
Intel Xeon
Intel Xeon – серверные процессоры, имеют четыре поколения.
IRQ
QPI
QPI (Intel QuickPath Interconnect, QuickPath)— последовательная шина для соединения между CPU Intel. Такое соединение создает многопроцессорные системы.
Серверы обычно имеют многосокетные материнские платы с возможностью подключения нескольких CPU (2/4/8/high-end больше) связанных через интерфейс QPI. Причем qpi в общем случае не 1, а 2 (e5) или 3 (e7).
QPI есть на Intel Xeon E5/7, но на E3 нету – это процессоры для односокетных систем. Поэтому Huawei использует только E5/7.
Частота процессора (CLock speed, clock cycles)
Clock Cycles, Clock Speed, Instructions per clock cycle (IPC)
The speed of a computer processor, or CPU, is determined by the Clock Cycle, which is the amount of time between two pulses of an oscillator. Generally speaking, the higher number of pulses per second, the faster the computer processor will be able to process information. The clock speed is measured in Hz, typically either megahertz (MHz) or gigahertz (GHz). For example, a 4GHz processor performs 4,000,000,000 clock cycles per second. Computer processors can execute one or more instructions per clock cycle, depending on the type of processor. Early computer processors and slower processors can only execute one instruction per clock cycle, but faster, more advanced processors can execute multiple instructions per clock cycle, processing data more efficiently.
AES-NI
Включение AES-NI рекомендуется VMware для задачи шифрования данных на диске (at rest) в соответствии с FIPS 140-2. AES-NI регулируется в настройках BIOS (так же, как HyperThreading).
Encryption. For high security demands, data at rest encryption (FIPS 140-2 compliant) might be enabled as a cluster-wide setting. Our storage stress validation demonstrated the performance of overall IOPS is very similar between encrypted and non-encrypted runs, but it will add CPU overhead to encrypt and decrypt data. We highly recommend using physical CPUs supporting the AES-NI offloading and verifying that the AES-NI feature is enabled in the server BIOS. VM encryption does not impose any specific hardware requirements, and using a processor that supports the AES-NI instruction set speeds up the encryption/decryption operation.
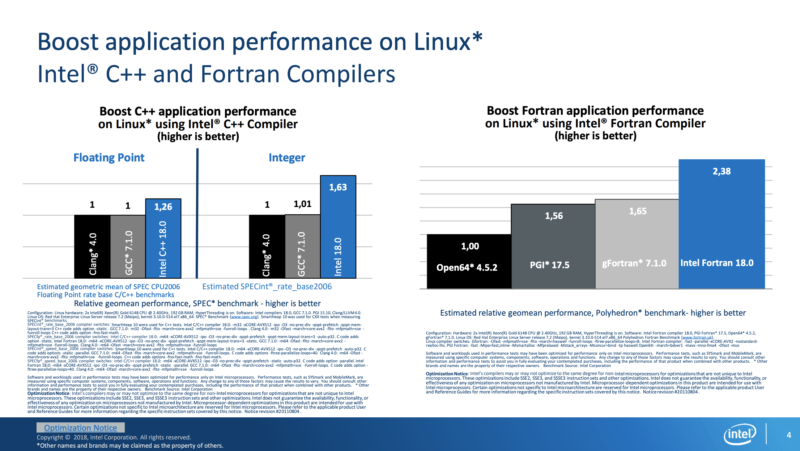
Данные ниже на основе Whitepaper Intel. Самые важные (как считаю) слайды и выводы:
- Есть две версии AES-NI: original и GCM. Original на больших фреймах проигрывает в производительности в 3-4 раза, на мелких фреймах такого проигрыша нет.
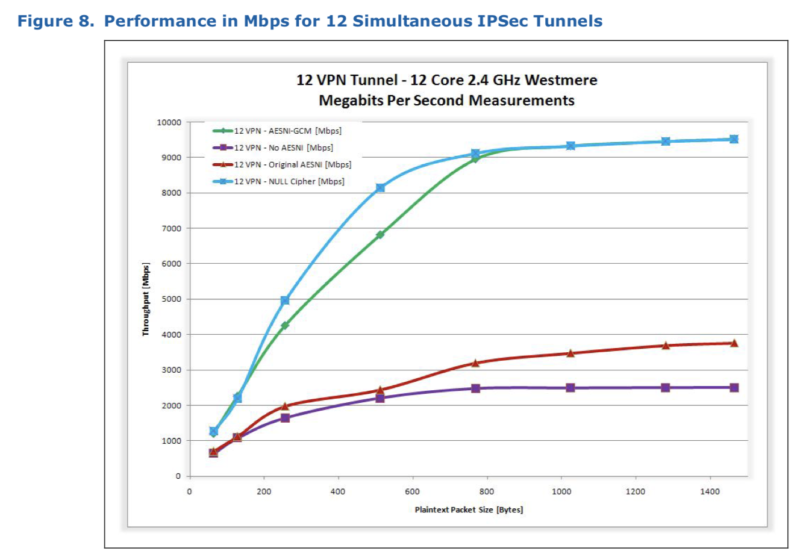
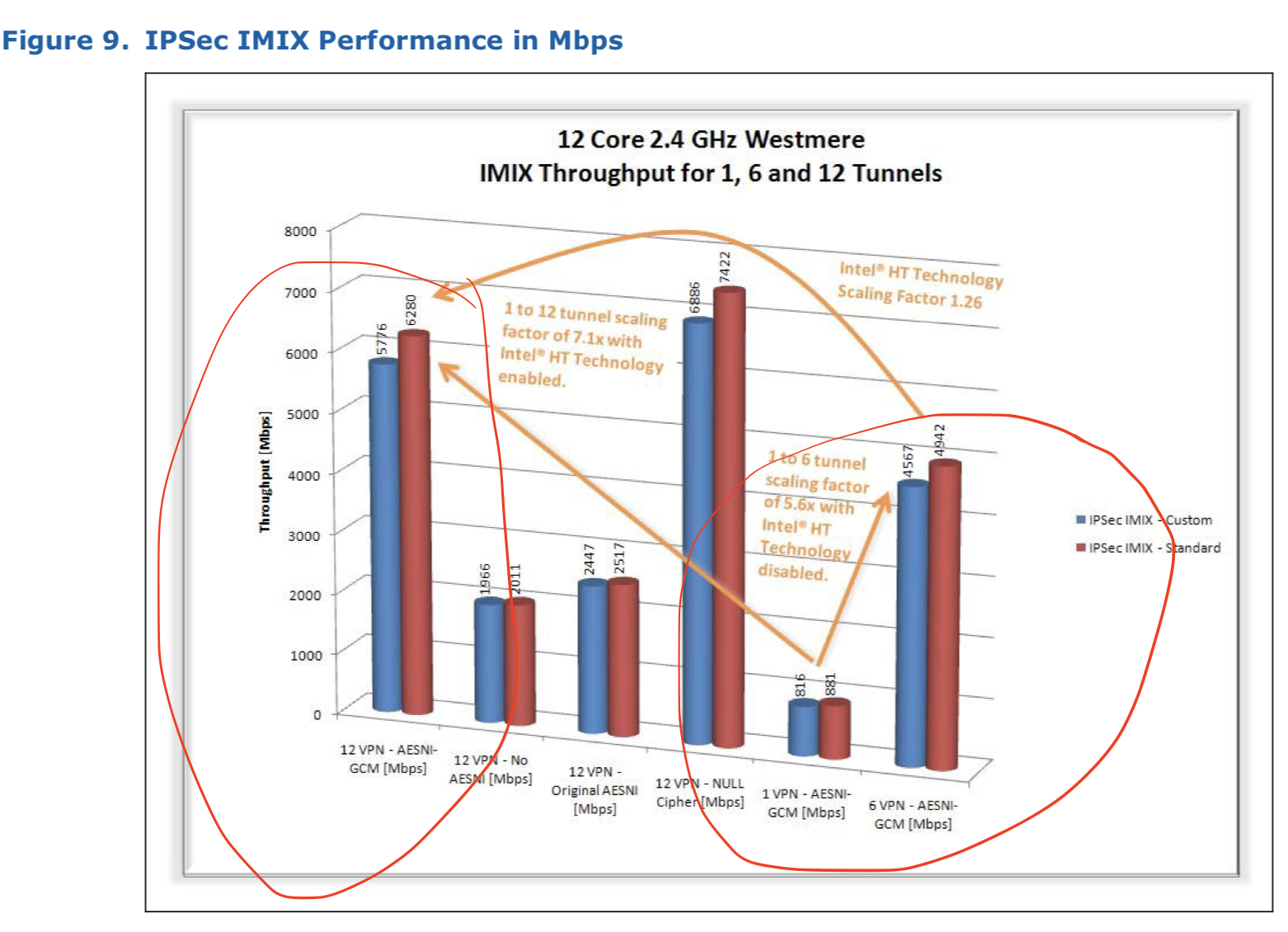
- Производительность с поддержкой AES-NI в общем случае масштабируется с ростом количества ядер и потоков. Особенно показателен последний в презентации слайд (ниже). Рост нелинейный (1 ядро = 1 Gbps; 6 ядер = 4.5 Gbps; 12 ядер = 6 Gbps), но и конфигурация между тестированиями была не эквивалентная – 6 ядер это были чистые ядра, а 12 – с HyperThreading. Т.е. по результату можно сказать, что HT приводит к нелинейному приросту в первую очередь, если бы тест был с 12 реальными ядрами – результаты явно были бы лучше.
For the tests described in this paper, Intel® HT Technology was enabled/disabled as follows: • Single tunnel test: Intel® HT Technology was enabled, however, it did not impact the result because all processing was performed on one core with all other cores idle. • Six tunnel test: each tunnel was allocated to a specific core. Intel® HT Technology was disabled to ensure that two tunnels were not inadvertently running on logical cores that mapped to the same physical core. • Twelve tunnel test: Intel® HT Technology was enabled to present twelve cores to the OS. Each tunnel was again allocated to a specific core. In this instant, pairs of tunnels were sharing the same physical core.
HyperThreading, Hyper-threading (HT)
Используя HT система создает виртуальные ядра, которые никак не равны фактическим – вычислительный прирост при использовании HT происходит за счет того, что задачи на обработку с разных виртуальных ядер передаются на физическое ядро процессора как только оно закончило обработку, без дополнительных ожиданий (сравнение – рот и две руки).
Индикатор включения HT (само включение в BIOS/UEFI).
I have always just used the following and looked at 'Thread(s) per core:'. hostname:~ # lscpu Architecture: x86_64 CPU(s): 24 Thread(s) per core: 2 <-- here
В некоторых особых случаях/для некоторых приложений эти виртуальные ядра могут создавать больше проблем, чем пользы.
1) It depends on the workload. Generally speaking, HT helps when you have IO bound loads and/or heavily congested CPU. If you are not overcomitting your CPU and have no disk/network bottlenecks, HT will probably not provide any advantages, and might, under certain conditions, even hinder performance. 2) В защиту AWS могу сказать, что он при создании машины позволяет отключать HyperThreading, что по крайней мере поможет исключить проблему с просадкой производительности у некоторых приложений.
Есть примеры как роста сетевой производительности от включения hyperthreading (напр, тут на сетевом appliance в каком то универе с продакшн обработкой до 80 gbps) так и снижения. Чаще же всего по моей практике системного тюнинга сетевых обработчиков (IxChariot, IPSec) разницы нет или разница в пользу выключенного HyperThreading (см. пример ниже “при работе с сетевыми нагрузчиками”). А за счет большего количества процессоров и потенциальных очередей обработки (включая сетевых карт) это приводит к тому, что сама технология скорее плюс с точки зрения усредненной производительности, нежели минус. Если говорить не про мою практику – то авторитеты скорее отключают hyper-threading для сетевых обработчиков, пруфы ниже.
Есть множественные примеры, когда сетевые вендоры или лаборатории performance тестирования отключили или включили HT:
-
- Yandex nexthop 2021 отключили HT для Firewall 100G на основе DPDK
- fd.io отключили HT при тестировании VPP NAT44
- EANTC отключила HT при тестировании PaloAlto VM700 в соответствии с рекомендациями PaloAlto: “For the best performance from VM series firewalls, disable hyperthreading on ESXi hosts.”
- CheckPoint
- явно рекомендовал отключать Hyper-Threading для каких-то своих платформ.
- для каких-то blade включение Hyper-Threading увеличивает производительность до 30% для ряда софтовых NGFW модулей
4. Disable hyper-threading SMT (also called HyperThreading or HT) improves performance up to 30% on NGFW software blades such as IPS, Application & URL Filtering and Threat Prevention by increasing the number of CoreXL FW instances based on the number of logical CPUs.
-
- В IETF BMWG (Gabor) профессор так же отключал Hyper-Threading из-за нестабильности результатов с ним “To be honest,? I expected much more scattered results due to Hyper-Threading enabled. So it was a nice surprise to me. 🙂 I ask this, because I have noticed among the BIOS settings: “Intel(R) Hyper-Threading Tech Enabled”, which I always disable to avoid unstable results. ((bmwg Digest, Vol 221, Issue 12 bmwg <bmwg-bounces@ietf.org>; от имени; bmwg-request@ietf.org))”
- Некий системный инженер Вячеслав Гапон так же его отключал “Also, be sure to disable hyper-threading in the BIOS, since load balancing on virtual cores can greatly increase the load on some physical cores.”
- Из моей практики: при работе с сетевыми нагрузчиками
- конфигурация без HyperThreading показала более высокий (+10% производительности, 30 gbps вместо 27 gbps) и стабильный результат (стабильность между потоками трафика), при этом загрузка ядра CPU (единственного) достигала 80-100%
- конфигурация с HyperThreading показала более низкий результат, при этом загрузка CPU каждого ядра достигала 50-60% (т.е. для HyperThreading ядер нужно складывать нагрузку)
Кроме того, технология HT привносит в систему ряд уязвимостей, которые невозможно эксплуатировать без включенного HT.
С другой стороны, отключение HyperThreading позволяет сразу закрыть целую пачку уязвимостей, в том числе ещё не анонсированных и не найденных (да, я постулирую, что ещё не все найдены), так что, может, проще сразу от него отказаться... Тем паче что в некоторых случаях HT наоборот, снижает производительность.
NUMA
A single NUMA node represents a pool of CPU cores, memory, and PCI slots (containing NICs)
https://documentation.nokia.com/cgi-bin/dbaccessfilename.cgi/3HE15837AAAATQZZA01_V1_VSR%20Installation%20and%20Setup%20Guide%2020.2.R1.pdf NUMA allocation has a strong impact on high-performance VNFs. NUMA misalignment can result in VSR instability and high traffic latency. A single NUMA node represents a pool of CPU cores, memory, and PCI slots (containing NICs); these virtualized components perform best when the latency in communication between components is minimized. Allocating components (such as CPU cores and NICs) from different NUMA nodes requires communication to cross a QPU/UPI link, which is limited in bandwidth and can cause delays. These resources should reside on the same NUMA. Border violations may occur if this requirement is not observed. The tests found that having such a misalignment can denigrate DPI throughput performance by 25.4%: Overall, the impact of the test is that a misaligned NUMA worker thread can cause up to a 25.4% drop in throughput on a server powered by an Intel Xeon Scalable Gold 6230N CPU. https://www.ipoque.com/media/whitepapers/rohde-schwarz-tests-deep-packet-inspection-for-5g-networks.pdf A dual-socket server brings added performance to a DPI processing, and the proper configuration of DPI thread instances towards the NUMA-aligned memory banks is imperative. NUMA is a shared memory architecture that describes the placement of main memory modules with respect to processors in a multiprocessor system. Like most every other processor architectural feature, ignorance of NUMA can result in sub-par application memory performance. This is recommended on NUMA architectures to allocate requested memory that is directly associated with the node of the thread. Not making these allocations can result in all necessary processing data, such as tracking tables, being misplaced on the wrong memory location. In this case, the remaining processing threads are distributed over all nodes of a system, and the necessary data for processing has to be transferred over the Intel® QuickPath Interconnect (Intel® QPI) bus to be available on the processing CPU. This results in a higher workload of the bus and lower overall performance of the system.
(Cisco TRex, CPU NUMA)
Для избежания проблем с производительностью на многопроцессорных платформах – необходимо использовать различные NUMA-ноды для разных сетевых карт.
- Посмотреть, каким образом распределяются сетевые интерфейсы по NUMA нодам – необходимо установить программу hwloc и вывести информацию lstopo:
megalloid@trex:~$ sudo apt install hwloc megalloid@trex:~$ lstopo For operating high speed throughput (example: several Intel XL710 40Gb/sec), use different NUMAnodes for different NICs. To verify NUMA and NIC topology: lstopo (yum install hwloc). To display CPU info, including NUMA node: lscpu. NUMA usage: example
- Или lspci -t -vv – выдаст иерархию устройств PCI-E, можно убедиться, что сетевые карты “висят” на рут-комплексах разных ЦПУ.
компиляторы
- https://godbolt.org/ Крутой сайт по анализу работы компиляторов – как они работают, как оптимизируют код и проч. Compiler Explorer was started in 2012 to show how C++ constructs are translated to assembly code.
- Компиляторы оптимизируют код и зачастую чем проще ты кго напишешь, тем лучше, пример дискуссии, что массивы подстановок это только на первый взгляд хорошая замена case/if-elif
- код можно оптимизировать по производительности со страшной силой.. просто вместо case и elseif использовать массив подстановок… а ведь это то что от DPDK хотели – скорости
- Компилятор это сделает сам скорее всего. Зависит от значений констант. Массив может быть большим. И как раз ручная оптимизация таким методом может сделать только хуже.
- Кстати вызов по таблице, особенно динамической, – будет медленнее. Так как надо сначала адрес загрузить, потом по нему перейти. Этот else-if, как впрочем и switch – это переходы по статически известным смещениям. Самое быстрое и удобное для оптимизации что существует для компилятора.
- Современные компиляторы достаточно неплохо пытаются оптимизировать код. Просто, разработка высокопроизводительных приложений, это своя наука, в которой нужно предсказывать в какое количество машинных инструкций будет скомпилирован код, иногда такой код выглядит достаточно грязным и вызвать боль для статанализа, но зато будет работать быстрее)
Оптимизации для компиляторов
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors.
CPU Counters
fd.io (авторы VPP) пишут, что у современных CPU огромное количество счетчиков (в том числе performance), но 1) интерпретация этих счетчиков без информации от CPU vendors – challenge 2) у счетчиков есть проблема с повторяемостью.
Problem: • Modern computers/CPUs provide lots of telemetry data and performance counters • Challenge – readings not always repeatible, which ones do you trust • Resolution (work in progress) • Work with CPU hardware vendors to interpret the counters • Work with community and vendors on improving network-centric telemetry tools for computers/CPUs • Counters accuracy • Reporting clarity • Measurements repeatibility • Drive development of open-source SW tools for computer/CPU performance monitoring and reporting