
- http://sqlfiddle.com/ – очень удобный сайт по экспериментам с SQL (запросы, создание страниц и проч.)
- https://dbfiddle.uk/Gx3c6fmQ – аналогично, с примером
основные инструменты SQL/NoSQL; big data; analytics
-
- хранение
- mysql/oracle/postres (более в почете сейчас последний, в том числе для bigdata в виде greenplum и TSDB в виде TimescaleDB)
- OpenTSDB (Time Series Database)
- redis
- s3
- elk – часто используется для логов
- clickhouse
- log stash
- визуализация
- Kibana
- поиск по данным
- ElasticSearch
- хранение
Отдельные статьи
Time series database
В основном на основе статьи из habr
A time series database (TSDB) is a software system that is optimized for storing and serving time series through associated pairs of time(s) and value(s). InfluxDB: Open Source Time Series Database, Influx + Telegraf
Базы предназначены для хранения time series данных – какой то показатель и его динамика со временем – валюта, транспорт, метрики здоровья системы и прочее.
Time series данные или временные ряды — это данные, которые изменяются во времени, данные о процессе, которые собраны в разные моменты его жизни. Например, местоположение автомобиля: скорость, координаты, направление, или использование ресурсов на сервере с данными о нагрузке на CPU, используемой оперативной памяти и свободном месте на дисках. Котировки валют, телеметрия перемещения транспорта, статистика обращения к серверу или нагрузки на CPU — это time series данные. Чтобы их хранить требуются специфичные инструменты — темпоральные базы данных. «Первая Мониторинговая Компания» следит за передвижением транспорта с помощью спутников. Мы отслеживаем 20 000 транспортных средств и храним данные о перемещениях за два года. Суммарно у нас 10 ТБ актуальных телеметрических данных. В среднем, каждое транспортное средство во время движения отправляет 5 телеметрических записей в минуту. Данные отправляются с помощью навигационного оборудования на наши телематические серверы. В секунду они принимают 500 навигационных пакетов.
В целом специфика этих данных есть – временные метки с показателями, чаще всего append only режим, анализ ряда данных в динамике.
Временные ряды имеют несколько особенностей. - Время фиксации. Любая time series запись имеет поле с меткой времени, в которое было зафиксировано значение. - Характеристики процесса, которые называются уровнями ряда: скорость, координаты, данные о нагрузке. - Практически всегда с такими данными работают в append-only режиме. Это значит, что новые данные не заменяют старые. Удаляются только устаревшие данные. - Записи не рассматриваются отдельно друг от друга. Данные используются только в совокупности по временным окнам, интервалам или периодам.
Это самые популярные базы в последнее время.
Лидирующую позицию занимают time series хранилища, на втором месте — графовые БД, дальше — key-value и реляционные базы. Популярность специализированных хранилищ связана с интенсивным ростом интеграции информационных технологий: Big Data, социальные сети, IoT, мониторинг highload-инфраструктуры. Кроме полезных бизнес-данных, даже логи и метрики занимают огромное количество ресурсов.
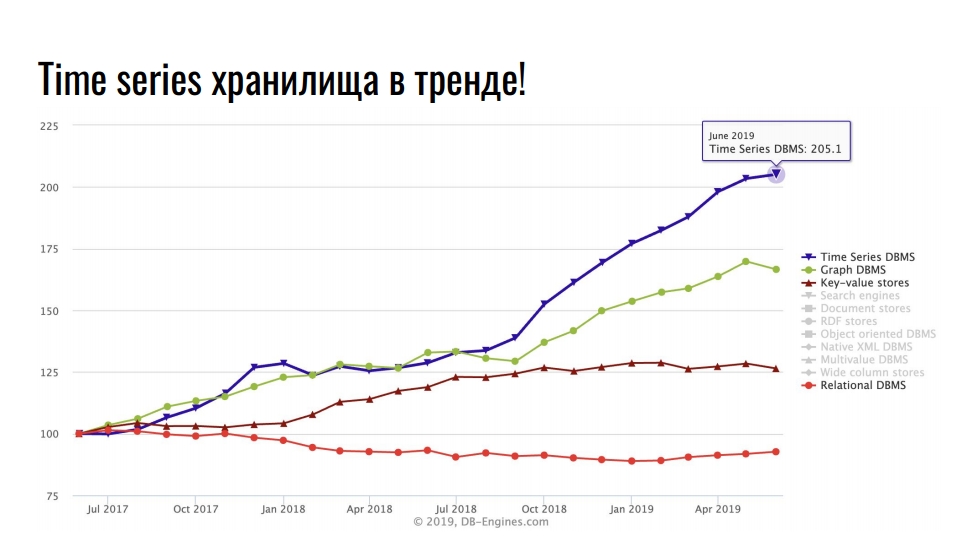
Баз данных решающих задачу хранения/аналитики подобных данных много, есть специализированные типо influx и OpenTSDB, есть крутые расширения к существующим базам типо TimescaleDB postgres, которые позволяют инсертить и анализировать в классической реляционной базе Time series данные.
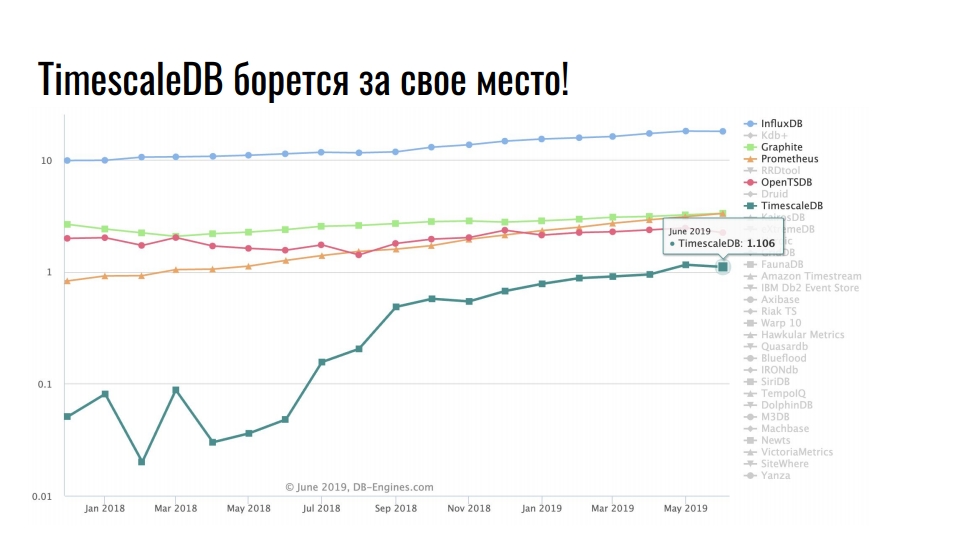
На графике показаны специализированные решения для хранения time series данных. Шкала логарифмическая.
Инструментов — десятки, например, InfluxDB или ClickHouse. Но даже у самых лучших решений для хранения временных рядов есть недостатки. Все time series хранилища низкоуровневые, подходят только для time series данных, а обкатка и внедрение в текущий стек — дорого и больно. Стабильно лидирует InfluxDB. Все кто сталкивался с time series данными, слышали про этот продукт. Но на графике заметен десятикратный рост у TimescaleDB — расширение к реляционной СУБД борется за место под солнцем среди продуктов, которые изначально разрабатывались под time series. Но, если у вас стек PostgreSQL, то можете забыть о InfluxDB и всех остальных темпоральных БД. Ставите себе два расширения TimescaleDB и PipelineDB и храните, обрабатываете и проводите аналитику time series данных прямо в экосистеме PostgreSQL. Без внедрения сторонних решений, без недостатков темпоральных хранилищ и без проблем их обкатки. Итого PostgreSQL позволяет комбинировать различные расширения, а также добавлять свои типы данных и функции для решения конкретных задач. В нашем случае, использование расширений TimescaleDB и PostGIS практически полностью покрывают потребности в хранении time series данных и гео-пространственных расчетах. С расширением PipelineDB мы можем проводить непрерывные вычисления для различной аналитики и статистики, а использование JSONB-столбцов позволяет хранить в реляционной базе слабоструктурированные данные. Open Source решений хватает с головой — коммерческие решения не используем. Эти расширения практически не накладывают ограничения на экосистему вокруг PostgreSQL, такие как High Availability решения, системы резервного копирования, средства мониторинга и анализа логов. Нам не нужен MongoDB, если есть JSONB-столбцы, и не нужен InfluxDB, если есть TimescaleDB.
масштабирование/балансировка БД
- Разделение по базам данных и использование database links (oracle)
- Для мелких/средних инсталляций зачастую не надо разделять базу и лучше это и не делать 🙂 либо используется только репликация в схеме запись только в мастер, а чтение со всех слейвов
1. Распределенные БД сильно сложнее не распределенных. Несколько раз подумай, будет ли твой барбершоп настолько популярным, прежде чем туда лезть.
- Универсального способа масштабироваться не существует. Всегда присутствует trade-off. Выбор между репликацией, горизонтальным и вертикальным шардированием нужно делать, опираясь на предметную область и статистику использования БД. Но можно в среднем придумать некие гайдлайны по выбору:
Шардирование vs Репликация • отказоустойчивость -> репликация • много чтения -> репликация или шардирование • много записи -> шардирование
- Зачастую в крупных инсталляциях используется одновременно и шардирование и репликация
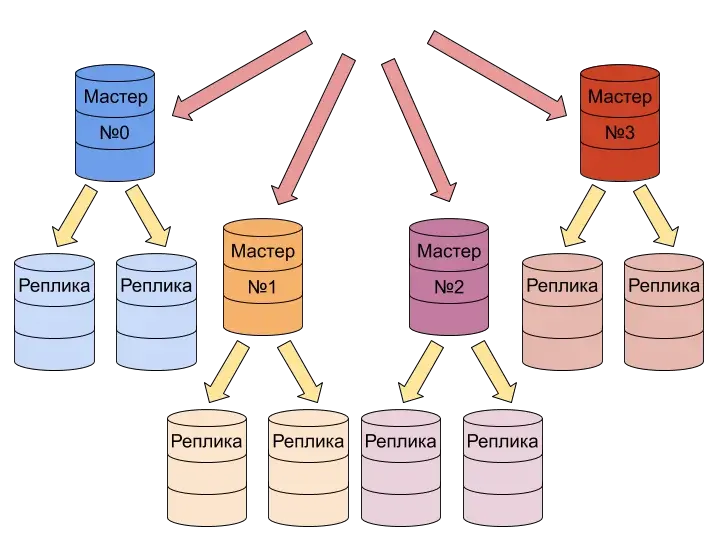
- Репликация обычно реализуется в виде мастер-слейв реплики: запись только в мастер, а чтение со всех реплик.
- Шардирование: в отличии от реплик использует не копии базы, а разделение – каждый шард имеет свою часть разделенной БД; у шардов одна схема таблицы/БД, но шарды хранят разные данные (пользователь n1 хранится в первом шарде, пользователь n2 во втором), сами шарды выбираются по принципу хеширования от данных – т.е. куда записать/откуда прочитать данные выбирается на основе хеша
Шардинг (sharding). Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер.
Осуществить шардирование можно несколькими способами: - Средствами БД. Некоторые базы — MongoDB, Elasticsearch, ClickHouse и другие — умеют самостоятельно распределять данные между своими экземплярами. ((Считается наилучшим способом - если есть возможность без боли перейти на шардируемую БД, то конечно лучше сделать так. )) - Надстройками к БД. - Клиентскими средствами. Методы работы в этих способах схожи: мы выбираем ключ для распределения данных (это может быть идентификатор, временная метка или хеш записи) и в соответствии с ним записываем информацию в нужный шард. Как правило, ключи стараются выбирать так, чтобы данные были равномерно распределены по шардам.
SQL Clients
- Toad – enterprise продукт, работает с популярными в крупном enterprise как SQL, так и noSQL базами
The Toad toolset runs against Oracle, SQL Server, IBM DB2(LUW & z/OS), SAP ((sybase)) and MySQL
- DBeaver
- Community версия – работает с большим количеством relational databases (по сути всеми известными популярными), используя JDBC
- Enterprise – поддерживает работу с noSQL базами типа MongoDB, Cassandra, Redis
- phpmyadmin, MySQL workbench – для работы только с MySQL, второй более продвинутый
- консольные для каждой базы
- mysql
- sqlite
- psql
BASIC SQL
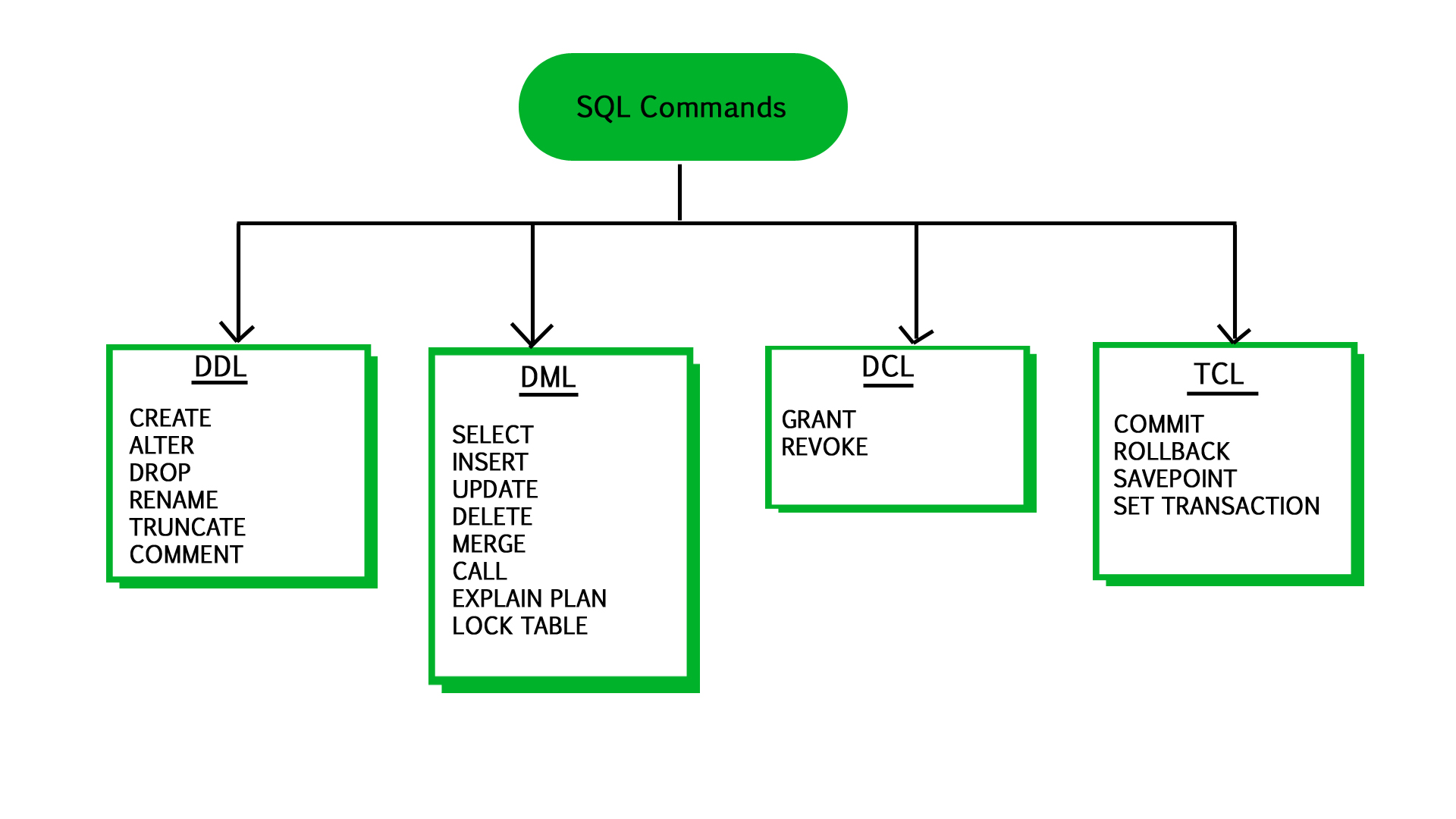
DDL – Data Definition Language
CREATE ALTER DROP RENAME TRUNCATE COMMENT
DML – Data Manipulation Language
SELECT INSERT UPDATE DELETE MERGE CALL EXPLAIN PLAN LOCK TABLE
DCL – Data Control Message
GRANT REVOKE
TCL – Transaction Control Language
COMMIT ROLLBACK SAVEPOINT SET TRANSACTION
ТРАНЗАКЦИТ/TRANSACTIONS
Транзакция — это набор операций по работе с базой данных (БД), объединенных в одну атомарную пачку. Транзакции БД позволяют защититься от частичного исполнения группы запросов – транзакция или будет исполнена полностью или не будет вообще. Это крайне важно во многих сценариях, самое очевидное – перевод денег между счетами. С точки зрения практики, до коммита, но после изменения сделанные, но не примененные изменения можно посмотреть и что еще более важно – откатить эти изменения по rollback. Не откатывать потенциально проблемные изменения и просто отключаться от базы некорректно – в случае отключения транзакция не откатывается, а следующий кто подключится при коммите применит и старые действия транзакции.
#mysql start transaction
insert into clients (name, surname) values ('Иван', 'Иванов');
insert into clients (name, surname) values ('Вася', 'Пупкин');
commit;
INDEX (индексы)
Ускорение select/join может быть достигнуто за счет использования индексов. Нужно учитывать, что index’ы
- могут негативно влиять на write, т.е. если в таблицу ожидается большое количество write при меньшем количестве read – в среднем лучше индексы не использовать и наоборот
- так же по сути создается вспомогательная таблица – это доп. память
- не гарантируют ускорение чтения напр. если неудачно выбрано поле для индексации, хотя и вероятность что индексы приведут к деградации read низка
Применение индексов представляет собой компромисс между ускорением получения результатов запросов и замедлением обновлений и вставок данных. Первая часть этого компромисса – ускорение запросов – довольно очевидна: если поиск выполняется по отсортированному индексу вместо полного сканирования всей таблиц, то запрос проходит намного быстрее. Но всякий раз, когда вы обновляете, вставляете или удаляете строку таблицы с индексами, индексы также должны быть обновлены соответствующим образом. То есть такие операции на таблицах с индексами обходятся дороже.
Сами индексы работают быстрее за счет оптимизации структуры хранения данных – в виде отсортированных/сбалансированного дерева (проиндексирорванных) данных по которым проще осуществлять поиск.

Жизненный пример – поиск в базе 4 млн записей:
-
- часы до индексирования
- после индексирования 3 секунды
Как проиндексировать таблицу по полю.
CREATE INDEX <table>_index ON <table>(<field>)
DROP
В современных базах (MS SQL, MySQL, да даже sqlite3 python) поддерживается полезная функция DROP, но только в случае exist объекта (базы).
DROP TABLE if exists <table>
SELECT
Сопоставление таблиц (join, multiple where, вложенные запросы)
В Where плохо добавлять вложенный select т.к. по каждому результату будет дополнительный select. В общем случае всегда лучше сопоставлять данные в таблицах.
Данные в Oracle из нескольких таблиц можно выбрать и сопоставить не только с помощью стандартного join (ANSI синтаксис), но и с помощью указания нескольких таблиц в поле from (в базе, сделанных как вложенный запрос или временных таблиц). Это традицонный синтаксис Oracle.
Данные в таком случае могут выбираться в таблицы по разному, но сопоставление в любом случае идет через WHERE. Если в условиях WHERE указать (+) – это позволяет добавить данные, в случае если подпадение нулевое – т.е. отсутствие данных в одной из таблиц считается подпадением.
#1 JOIN
SELECT w.n,w.employee,w.emp_phone,wbox.equip_type,wbox.entrance,wbox.place
FROM walli_theft w
LEFT JOIN walli_theft_box wbox on w.n=wbox.n
WHERE w.h_id='119783'
ORDER BY theft_date
#2 MULTIPLE FROM
SELECT w.n,w.employee,w.emp_phone,wbox.equip_type,wbox.entrance,wbox.place
FROM walli_theft w, walli_theft_box wbox
WHERE 1=1
AND w.h_id='119783'
AND w.n=wbox.n
ORDER BY theft_date
#3 TEMP TABLE
with
wbox as (
select * from walli_theft_box
)
SELECT w.n,w.employee,w.emp_phone,wbox.equip_type,wbox.entrance,wbox.place
FROM walli_theft w, wbox
WHERE 1=1
AND w.h_id='119783'
AND w.n=wbox.n
ORDER BY theft_date
#4 ENCLOSED
SELECT w.n,w.employee,w.emp_phone,wbox.equip_type,wbox.entrance,wbox.place
FROM walli_theft w, (select * from walli_theft_box) wbox
WHERE 1=1
AND w.h_id='119783'
AND w.n=wbox.n
ORDER BY theft_date
временная таблица, формируемая на время запроса
Очень полезно, когда есть справочники и ты их сначала объединяешь в нужный вид между собой, а потом select’ишь из каждой временной таблицы данные.
with reg as ( select distinct l.region, d.name from dict_one l, dict_two d where 1=1 and d.id=1 and d.code=l.region ), bra as ( select distinct l.branch, d.name from dict_one l, dict_two d where 1=1 and d.id=2 and d.code=l.branch ), distr as ( select distinct l.id, d.name from dict_one l, dict_two d where 1=1 and d.id=3 and d.code=l.district ) SELECT tb.data,reg.name reg,bra.name bra,distr.name distr FROM tb t, reg, bra, distr WHERE 1=1 AND t.region=reg.region AND t.branch=bra.branch AND t.area=distr.id
distinct, group by, join
Простой GROUP BY где мы имеем некоторый ID и счетчик повторений этого ID с использованием COUNT (или сумму значений для этого ID с использованием SUM) для одной таблицы.
SELECT <field>, COUNT(<field>) FROM <table> GROUP BY <field> EXMPL: SELECT Customer, SUM(OrderPrice) FROM orders GROUP BY Customer Так же можно присвоить имя полю со счетчиком Count/Sum. SELECT <field>, COUNT(<field>) AS CountOf FROM <table> GROUP BY <field> EXMPL: SELECT Customer, SUM(OrderPrice) AS sums FROM orders GROUP BY Customer
На выборку GROUP BY получившую имя с использованием AS можно применить фильтр с использованием HAVING, но не WHERE. Альтернативой HAVING может быть использование вложенных запросов, но читаемость такого кода хуже.
SELECT Customer, SUM(OrderPrice) AS sums FROM orders GROUP BY Customer HAVING sums < 2000
Если все что нужно это исключение дублей (уникальные записи) – нужно использовать DISTINCT, он работает быстрее. Но если нужно исключение дублей (уникальные записи) в рамках нескольких полей – зачастую проще использовать GROUP BY. К примеру, в запросе ниже мы объединяем таблицу пользователей и покупок с использованием LEFT JOIN и отображаем только Имена и Фамилии пользователей, которые имеют заказы с использованием WHERE и GROUP BY.
SELECT p.FirstName, p.LastName FROM persons p LEFT JOIN orders o on p.P_id=o.P_id WHERE o.OrderNo IS NOT NULL GROUP BY p.FirstName, p.LastName
стилистика
операции нужно писать с большой буквы, а переменные с малой. В таком случае sublime сможет подсветить синтаксис (должен быть большими SELECT в начале запроса)
date
mysql за три (n) последних месяца (с текущего дня)
select * from table where date >= now()-interval 3 month
mysql за последние тридцать (n) дней
SELECT * FROM table WHERE exec_datetime BETWEEN DATE_SUB(NOW(), INTERVAL 30 DAY) AND NOW();
like
В Oracle можно спокойно указывать в качестве объекта LIKE переменную, конкатенцию переменной и спец-символа % делаем через ||.
AND gg.gp_text LIKE '%' || na.net_address || '%'
сумма значений выборки (столбца)
SELECT sum(ticket_counts) FROM ticket_films WHERE film='GoT'
вложенные запросы
Пример вложенного SQL – на базе результатов делаем последующие запросы.
-- FIND SWITCHES BY SY_ID overall
select device_id, device_name, serial_number from devices@orange dv where dv.group_id in (
select device_group_id from os_eqm.device_groups@orange where group_type_id='605' and par_group_id in (
select device_group_id from os_eqm.device_groups@orange where group_type_id='1190' and par_group_id=(select header_id from groups_604@orange g4 where g4.adres='554') -- TKD by SY_ID
) -- YASHIK by TKD;
); -- DEVICES_ID + NAME + SERIAL by yashik
базовый performance тест SQLITE speedtest1
unzip sqlite-src-3530000.zip cd sqlite-src-3530000 ./configure make sqlite3.c gcc -O3 -static test/speedtest1.c sqlite3.c -o speedtest1 -lpthread -ldl -lm time ./speedtest1
clickhouse / clickbench
# install curl https://clickhouse.com/ | sh # basic clickbench benchmark (includes install) wget https://raw.githubusercontent.com/ClickHouse/ClickBench/main/hardware/hardware.sh chmod a+x ./hardware.sh ./hardware.sh
Партиционирование таблиц
Партиционирование (partitioning) — это разбиение больших таблиц на логические части по выбранным критериям. Разбиение таблицы на разделы очень полезно, если таблица содержит большое количество данных. Разбиение ускорит выборку и запись в таблицу. Разбивать на разделы нужно только большие таблицы и лишь в том случае, если исключение или сокращение партиций может быть достигнуто на основе критериев SQL-запроса Вот некоторые преимущества партиционирования: - Можно сохранять большее количество данных в одной таблице, чем может быть записано на одиночном диске или файловой системе. - Некоторые запросы могут быть значительно оптимизированы в том, что данные, удовлетворяющие предложению WHERE могут быть сохранены только на одном или большем количестве разделов, таким образом исключая любые остающиеся разделы из поиска.