
Конспект вебинаров 2, 3, 20 HonorCup E=DC2 для сдачи HCNA Storage.
OceAnStor OS
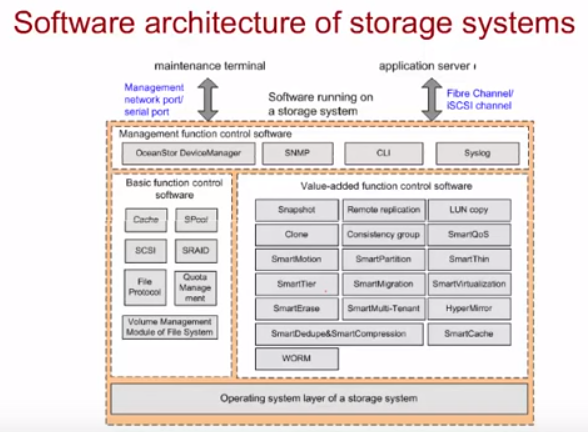
Функционал СХД контроллеров Huawei основывается на OceanStor OS – закрытой модульной Unix like ОС Huawei. В целом функционал сильно схож с RAID-контроллерами, но добавлен ряд фич.
Есть базовый функционал (Basic function control software) и есть функционал дополнительный (Value-added function control software), который докупается в виде лицензионных ключей. В ПО СХД ОС заложено много инструментов по backup/monitoring/восстановлению данных на ЖД (ЖД самый частый сбойный компонент СХД т.к. это элемент с механической компонентой).
Архитектура OceanStor OS
Технологии
Тут описаны технологии, которые не рассмотрены в RAID-контроллерах

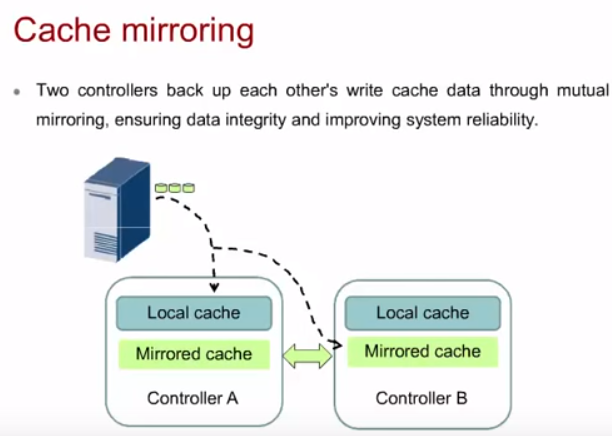
Cache mirroring
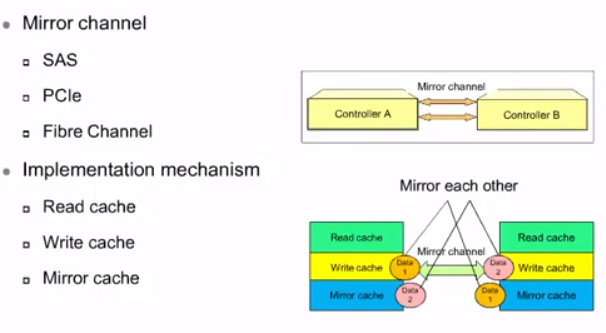
Cache mirroring используется при наличии нескольких контроллеров в СХД (у Huawei всегда несколько контроллеров, минимум 2). Данные между контроллерами по шине синхронизации синхронизируются для целостности данных в случае отказа одного из контроллеров. Cache mirroring делается всех типов операций – read/write/mirror. Причем главным считается write.
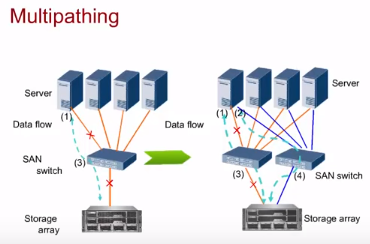
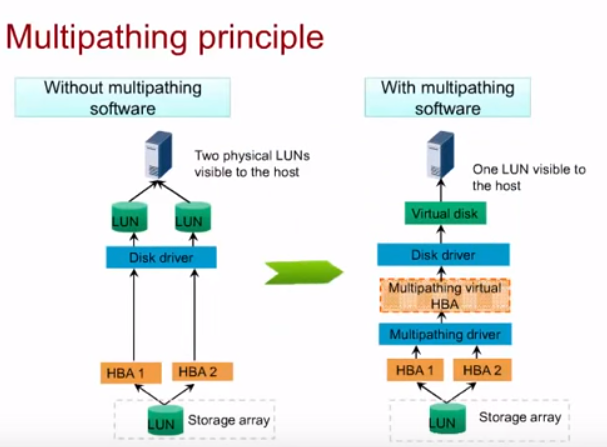
Multipathing
Multipathing – поддержка нескольких аплинк каналов от СХД до серверов. Нет зависимости от канала/промежуточного коммутатора. Особенность технологии еще и в том , что можно сделать так, чтобы для сервера оба канала виделись как один ЖД (LUN), а не по одному LUN на каждый канал.
Data coffer
На случай полного фатала с питанием (выход из строя двух БП/обоих лучей питания) в controller enclosure встроен функционал сохранения данных RAID кэша. Реализуется не через BBU+ОЗУ или суперконденсаторы+flash, как на RAID-контроллерах серверов (и на старших моделях СХД), а используя батареи (батарейные блоки BBU) + служебное пространство 4 дисков.
При проблеме с питанием данные из кеша контроллера переносятся на специальные разделы coffer disk’ов (раздел равен кешу контроллера, 4 диска – 2х2 диска в RAID1). Остальная часть дисков, не отведенная под раздел coffer, используется стандартно. После включения контроллер выгружает данные из coffer куда нужно.

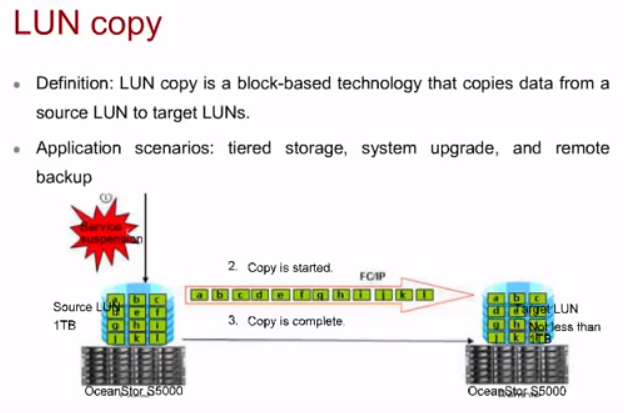
LUN copy
Копирование LUN. Требует запрет на запись (не на чтение) в данный LUN для корректного снятия копии в определенный момент времени.
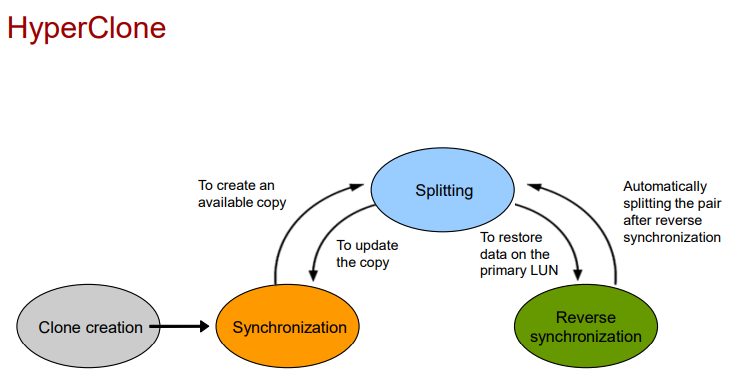
HyperClone (LUN clone) и Synchronization
Мгновенное копирование LUN используя синхронизацию (synchronization) между LUN. Не требует запрета на чтение, но занимает весь объем, отведенный под LUN, а не только объем данных LUN.
Синхронизация может происходить как между основным и резервным LUN, так и обратно. Для восстановление данных используется обратная синхронизация с клонированного LUN на основной (reverse synchronization). После синхронизации происходит обрыв синхронизации (split) и резервный LUN становится доступным для использования. Он имеет все данные основного LUN до split. Во время синхронизации все операции write будут дублироваться на клонированный LUN.
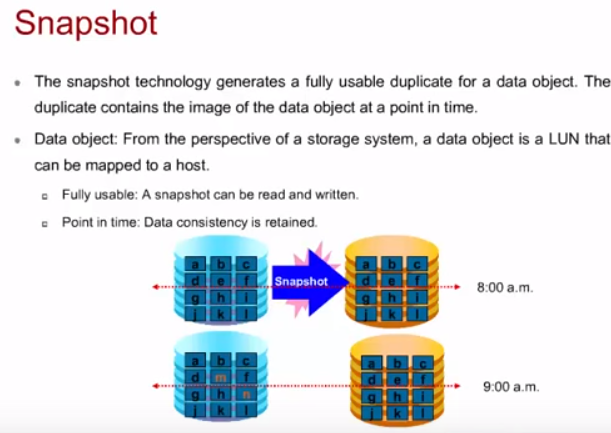
HyperSnap (Snapshot)
Позволяет снять копию системы (определенного LUN) в определенный момент времени. Есть у всех вендоров СХД. У Huawei основан на технологии copy-on-write (еще популярен у вендоров allocated-on-write).
- Для снятия snapshot не требуется остановка системы, в отличии от LUN copy.
- Snapshot занимает только пространство отведенное под ненулевые данные LUN, а не весь объем, отведенный под LUN, как это делает Clone.
В СХД типа OceanStor 9000 snapshot может быть сделан за одну секунду без влияния на сервис. Подробнее зачем нужны snapshot/replication см. в статье backup.
Существует два варианта восстановления из snapshot:
- side-by-side recovery: создается сопоставление snapshot LUN для хоста, который “видит” оригинальный LUN. В результате конкретные данные могут быть скопированы на уровне ОС.
- rollback function: оригинальный LUN (и все его данные) просто подменяется snapshot LUN.
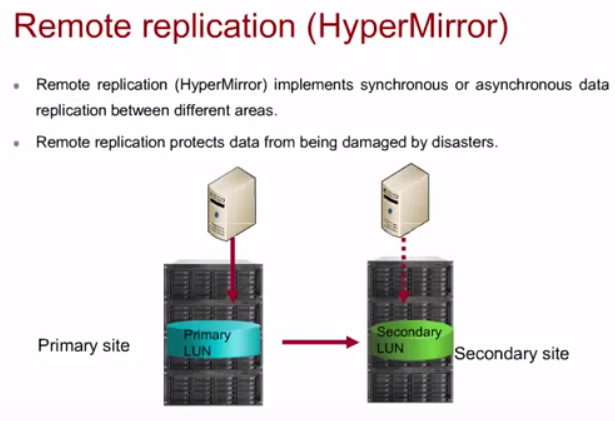
HyperReplication (Remote Replication)
Репликация данных с одного СХД на другой. Требует несколько одновременно работающих СХД в отличии от LUN copy/snapshot, которые могут быть сохранены на том же СХД. Репликация может быть синхронная или асинхронная (с задержкой), в зависимости от ширины канала и задержки:
- Синхронная репликация – при записи хоста на основной СХД хост не получит подтверждение успешности записи пока основной СХД не получит подтверждение от СХД, с которым происходит репликация.
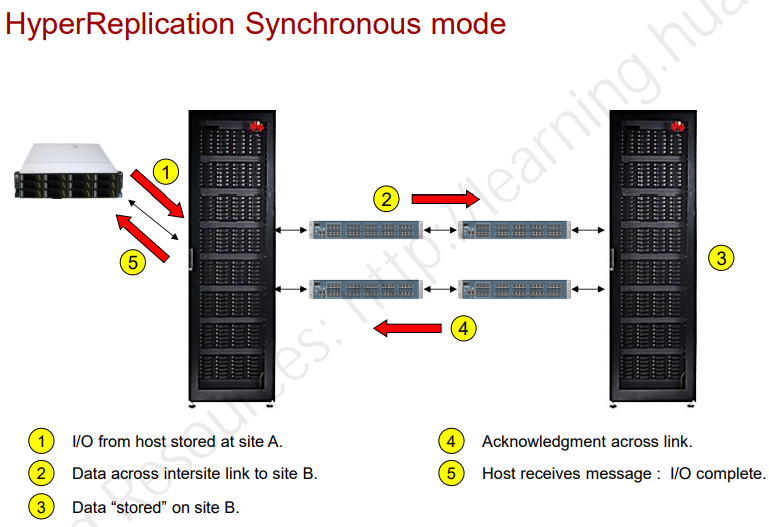
- Асинхронная репликация – основной СХД сразу отвечает хосту, а уже на фоне просто делается snapshot и далее данные передаются на второй СХД.
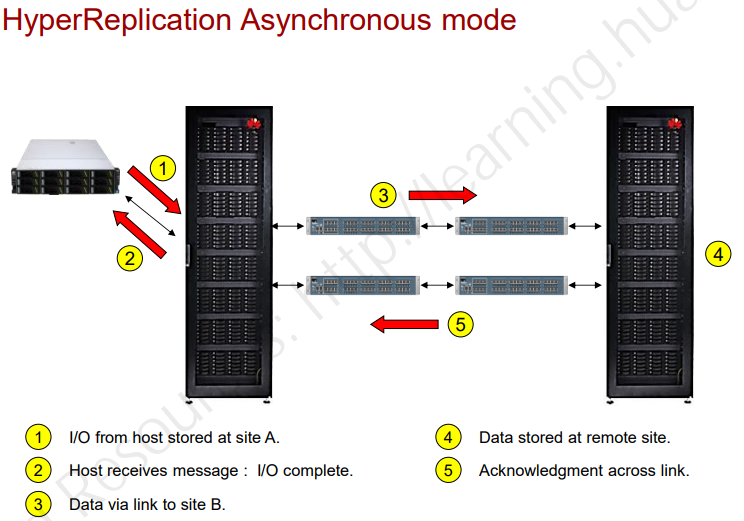
В настройках обычно можно задавать максимальную полосу канала, выделяемую под репликацию. Кроме того реплики могут быть полными или инкрементальными.
Могут быть разные варианты реализации репликации между СХД: один к одному/ко многим или двухсторонние реплики. Подробнее зачем нужны snapshot/replication см. в статье backup.
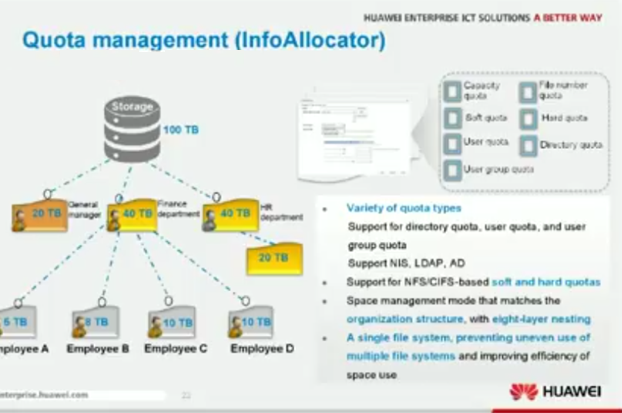
Квоты
Квоты позволяют сделать ограничение для определенных пользователей по объему выделяемого им пространства. Зачастую поддерживается интеграция с NIS/LDAP/AD (слайд для СХД OceanStor 9000).
WORM
WORM – write once read many. Система блокирует после создания файла его изменение и удаление. Таким образом обеспечивается неизменяемость информации (отчеты сотрудников, правовая или медицинская информация). Через определенный период, заданный админом, файл можно удалить или повторно заблокировать, но изменить нельзя.
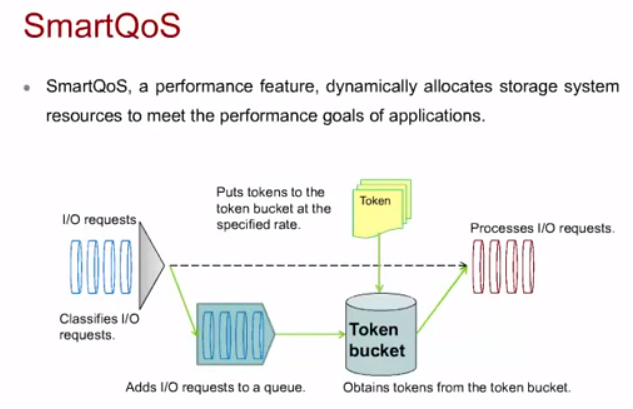
QoS
Аналогия QoS в IP-сетях, вместо пакетов используются I/O requests. Можно в системе настраивать приоритетность обработки тех или иных запросов на чтение/запись на определенный LUN. В зависимости от приоритета формируются очереди.
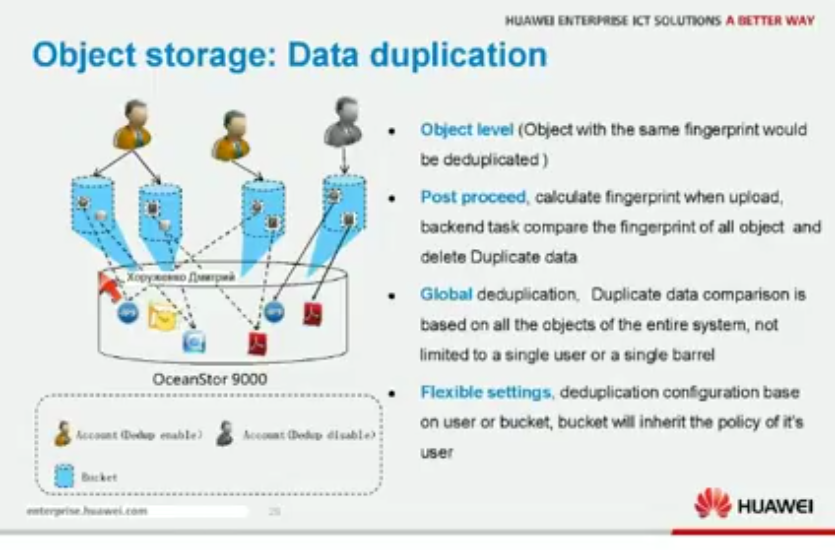
Дедупликация
В СХД может быть реализован функционал глобальной дедупликации данных (защиты от дублирования) путем сравнения файлов или объектов между собой (OceanStor 9000). Подробнее о дедупликации см. в отдельной статье.
HyperThin/SmartThin
Thin LUN – динамический LUN, который автоматически расширяется при заполнении. ОС видит такой LUN как обычный Thick LUN, но по факту контроллер предоставляет меньше объема, чем размер LUN и автоматически расширяет его при потребности ОС. Thin LUN – по сути аналог динамически расширяющегося образа в гипервизорах типа VirtualBox.
Пространство без данных можно использовать для другого LUN. В результате пространство используется эффективнее, но в случае полной забивки динамического LUN может произойти коллапс. При создании Thin LUN отжирает 64МБ под свои задачи и по мере появления данных в Thin LUN потребует еще служебного пространства, помимо основных данных. Если выделили слишком много пространства или оно нам просто теперь не необходимо в таком количестве – зачастую, если ОС поддерживает, можно сделать возврат объема (space reclamation).

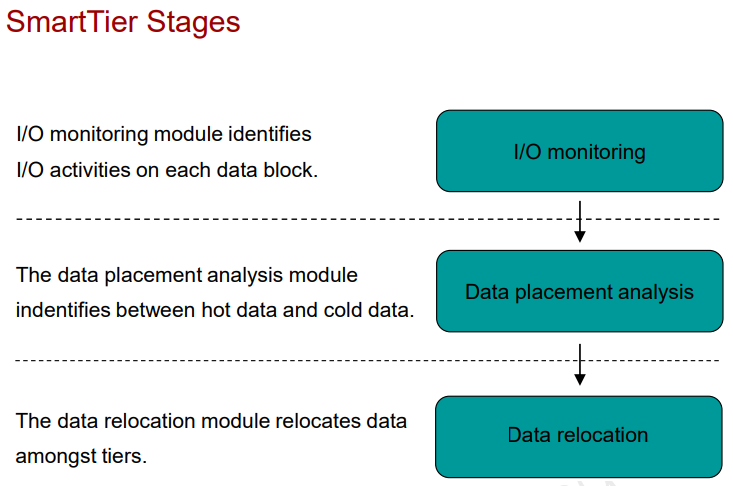
SmartTier
У вендоров может быть реализована поддержка разных типов дисков (SSD, SAS, NL-SAS). В результате разные по типу диски могут стоять в одной полке. В случае Huawei технология называется SmartTier и поддерживается на RAID 2.0+ и СХД OceanStor 9000 (тут она InfoTier). Для работы SmarTier на Disk Domain нужно чтобы в нем были диски разных типов (не обязательно три типа, можно и два).
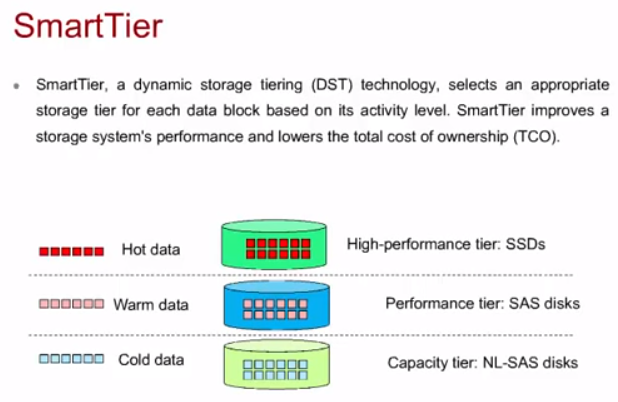
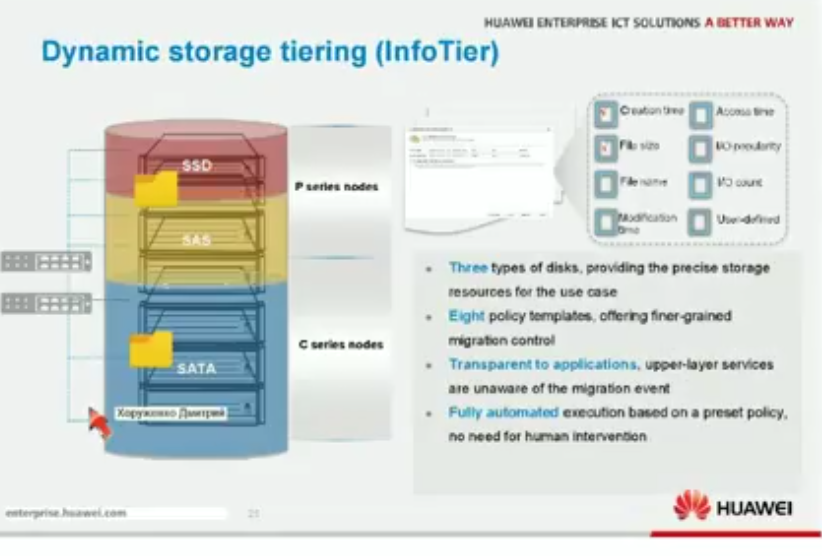
SmartTier на основе технологии dynamic storage tiering (DST) определяет, какие данные более востребованы и переносит их на SSD (high-perfomance tier), менее же востребованные же переносит на HDD (perfomance tier: SAS, capacity tier: NL-SAS). Происходит это в три этапа:
- Анализ входящих/исходящих операций (i/o monitoring)
- Анализ возможностей размещения данных (data placement analysis)
- Перемещение данных (data relocation)
Перемещение происходит в ненагружанные часы (можно задать вручную или использовать автоматический выбор на основе i/o), потому что потребляет ресурсы СХД . Определенные файлы можно закрепить за каким то уровнем. По умолчанию функционал выключен, даже если лицензия куплена – нужно задавать настройки политик перемещения для определенного LUN (automatic, highest, lowest, no relocation).
Специфические утилиты восстановления
Могут быть реализованы специфические утилиты восстановления данных, например, функционал по восстановлению видео (в OceanStor 9000). Как говорит автор до такого лучше не доводить – лучше следить за состоянием RAID/ЖД в нем, делать snapshot и прочее.

RAID 2.0+
RAID 2.0+ – программный RAID на основе ОС СХД Huawei (OceanStor OS), появился в 2013 году. Работает на всех актуальных СХД Huawei. На серверах Huawei RAID2.0+ функционала нет т.к. они реализуются на аппаратных RAID-картах не Huawei (напр. LSI SAS 3108). Презентация RAID2.0+.
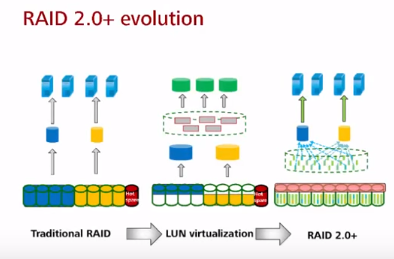
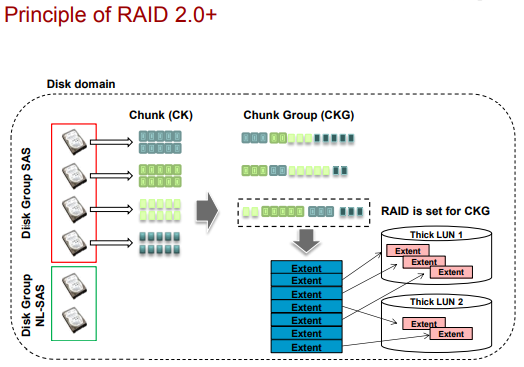
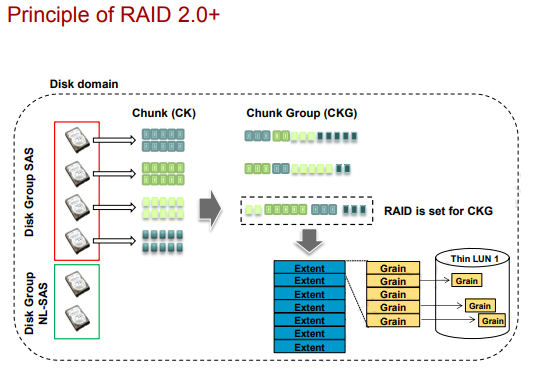
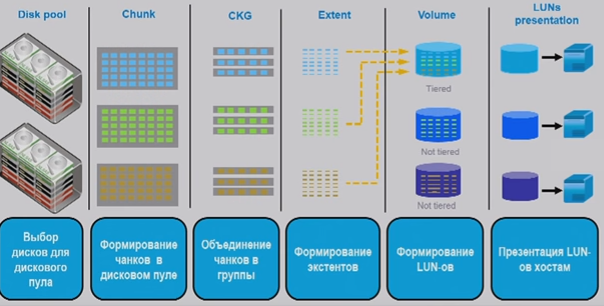
Принцип создания LUN в технологии RAID 2.0+ (тут на английском основные определения):
- внутри дисков происходит разбиение на небольшие логические блоки по 64мб chunk (CK, размер не меняется и такой большой чтобы не разрасталась таблица соответствия chunk – диск). Из-за использования логических блоков технология и называется Block Virtualizaion (данные разных LUN по сути в “перемешку” на ЖД).
- CKg – группа таких chunk. Стандартный RAID может объединять несколько CKg.
- extent/grain используют пространство CKg для адресации минимального объема данных:
- extent имеют размер от 512кб до 64мб (по умолчанию 4мб, можно поменять при создании Storage pool). Используются в Thick Lun.
- grain имеют размер в 64кб. Используются в Thin Lun.
- поверх extent/grain создаются LUN
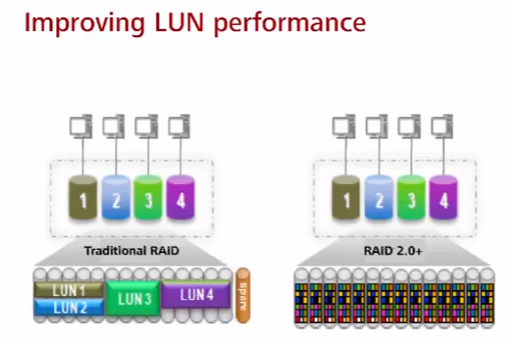
Преимущества RAID 2.0+ (помимо описанного выше функционала Huawei СХД, который работает в связке с RAID 2.0+):
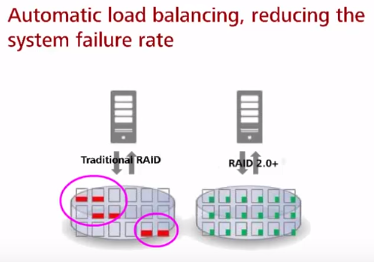
* все диски находятся в одном дисковом домене (грубо говоря, одном RAID), а не пачке разных RAID под разные задачи. Нарубление LUN по большому количеству ЖД (вместо выделенных), позволяет параллельно запрашивать данные сразу с большого количества ЖД (вместо выделенных), ускоряя тем самым работу и плавно распределяя нагрузку на все ЖД (не унося в полку одни, приводя в том числе к повышенному их износу, при том что другие ЖД мало нагружены).
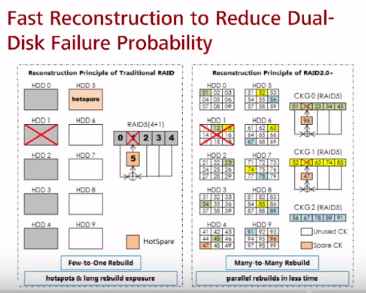
* нет выделенного диска горячей замены. Пространство под горячую замену равномерно распределено на всех дисках. Подход использования пространства всех ЖД под диски горячей замены позволяет значительно (в разы) ускорить восстановление при сбое (данные пишутся не с большого количества ЖД на один, а с большого количества ЖД на эти же ЖД). При восстановлении считываются только конкретные chunk (не на всех ЖД есть данные, которые затрагивают упавший ЖД) и с бОльшего количества дисков параллельно, чем в традиционных RAID, которые обычно имеют меньше дисков, чем 2.0+. В тестах Huawei 1TB диск в RAID 5 восстанавливался порядка 8-10 часов, а RAID 2.0+ 30 мин.
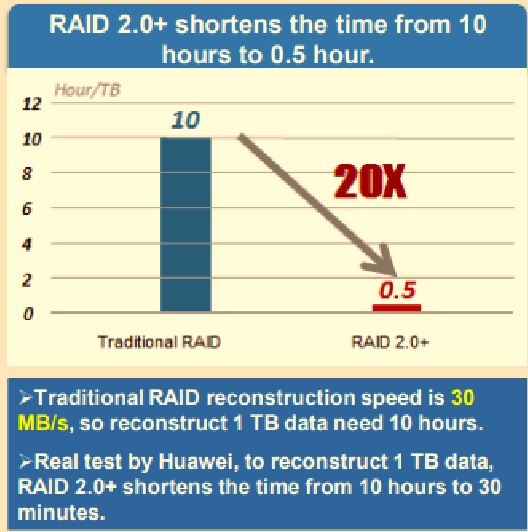
* не нужно следить за наличием дисков горячей замены – пространство под горячую замену распределено между всеми дисками.
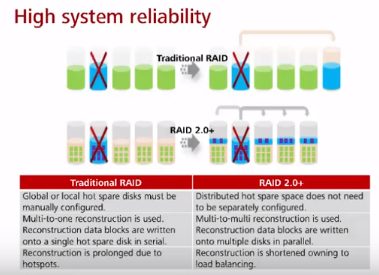
Аналоги RAID 2.0+ у других вендоров.
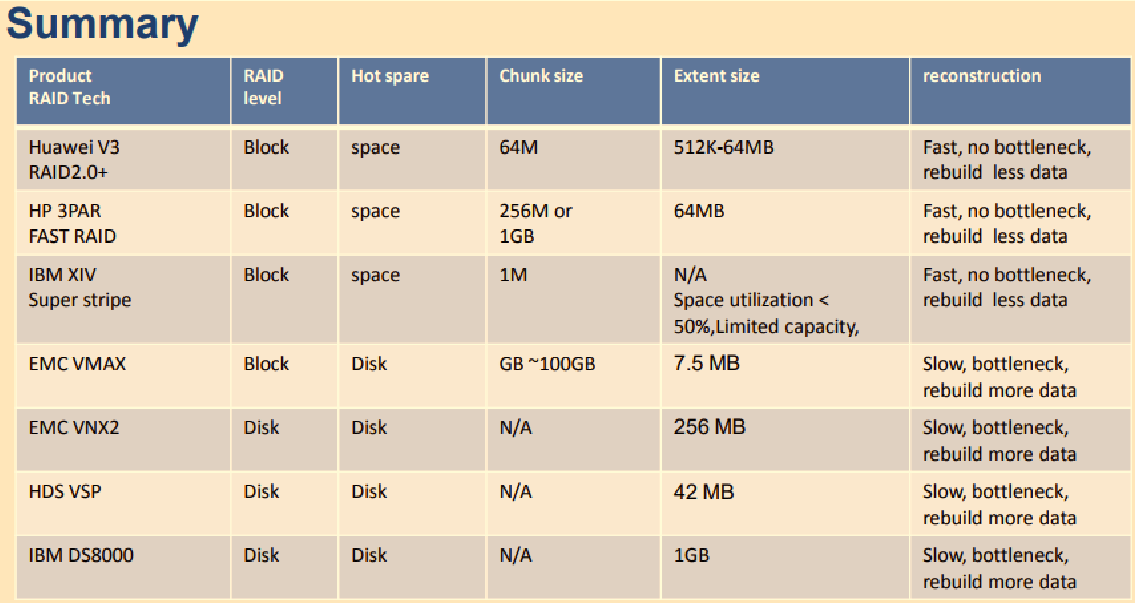
Summary


Вопросы
все вопросы/ответы по теме тут