
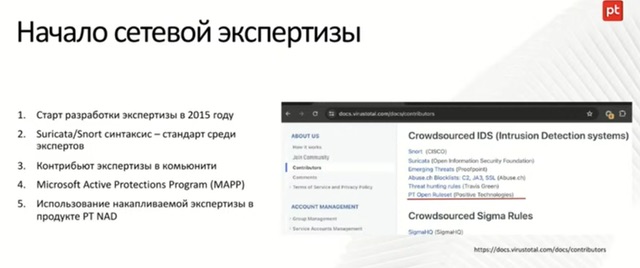
- Linux Performance Observability Tools: strace ltrace ss nstat gethostlatency sar proc dmesg dstat opensnoop laof fatrace filelife pcstat execsnoop mpstat profile runqlen offcputime softirqs turbostat show boost rmdsr perf fteace LTTng BCC bpftrace ext4dist ext4slower top atop ps pidstat vmstat slabtop free tiptop perf numastat hardirqs criticalstat nicstat netstat ip lldptool snmpget ethtool tcplife tcpretrans udpconnect tcpdump perf tiptop mdflush iostat biosnoop biolatency biotop blktrace swapon
- Мониторинг призван уменьшать значение времени исправления проблем (MTTR) или даже предотвращать возникновение аварийных ситуаций (подробнее ниже)
- Задача классического админа, решаемая мониторингом – сделать алерты в системе мониторинга на уменьшение количества краски в принтерах
- Существует разная глубина взросления «мониоринга» – реакция по негативному фидбеку/инцидента от пользователя, реакция на события мониторинга еще до обращения клиента, автоматизация на события мониторинга (напр. автоматом поднял backup), а самое последнее и грамотное — предсказание и предотвращение инцидентов, об этом о всем глубоко может рассказать SRE напр.
- на основе данных SMART,
- триггеры при 80% или 50% загрузке,
- данных по трендам памяти/проиводительности/задержки,
- запуск некой healing логики – напр. деплой с нуля нового компонента/виртуальной машины вместо упавшего, поднятие бекапа в кольце/полносвязной топологии
- В общем про api и методы взаимодействия с ними (rest, yang, soap, xml, json, restconf/netconf, etc) в отдельной статье
- Как мониторить устройства, которые перемещаются и могут быть за NAT (мобильные, планшеты, ноутбуки, корабли, дроны) – ключевое во всех случая что не мониторинг сервер, а сам мониторинг объект, инициализирует соединение (не pull, а push):
- поднимать с этих устройств соединение до сервера мониторинга
- ping
- tcp связность (nc)
- или что-то более сложное (REST/HTTP)
- поднимать на этих устройствах DDNS/Stun
- поднимать на этих устройствах SolarFlare zero trust – ставится агент на хост, он регистрируется и работает через CloudFlare CDN независимо из под белого или серого адреса поднят туннель
- подобное есть и у hashirocp, как понимаю реализуется через агент consul
- поднимать с этих устройств соединение до сервера мониторинга
- (дублируется в мониторинге и автоматизации сети) Автоматизация зачастую затрагивает интеграцию множества систем между собой. К примеру, на современные мониторинг системы зачастую ложится задача помимо самого мониторинга/оповещения/заведения инцидентов интеграция с системами провиженинга – напр. для реализаций сценариев по событию мониторинга:
- запуск некой healing логики – напр. деплой с нуля нового компонента/виртуальной машины вместо упавшего, поднятие бекапа в кольце/полносвязной топологии
- сбор доп.информации в инциденты
- проч автоматизированные интеграции
- В реальной жизни даже у крупного/успешного финансово Enterprise с развитым IT (кучей разных отделов) может не быть хорошего зонтичного мониторинга, хотя это не выглядит как rocket science
- определить ключевые приложения
- поставить на все/ключевые endpoint агенты-проберы
- отсылать проберами статистику на централизованный сервер
Monitoring – одна из самых ключевых частей работы с любой IT системой. Знания того что происходит/происходило с твоими системами и, особенно, проблемных мест позволяет решать кучу проблем, зачастую еще до их наступления или находить события, которые послужили причиной аварии. Использование систем мониторинга позволяет уменьшить вероятность silent failure – что является очень большой проблемой в IT-системах. Помимо этого можно анализировать исторические данные для понимания трендов (по загруженности, росту ошибок и т.д.), искать причины проблем, которые решены. Отсутствие мониторинга в крупных IT системах – это как езда на автомобиле с закрытыми боковыми зеркалами (глава United States Digital Service).
Ключевые задачи мониторинга:
-
- ad-hoc analysis
- debugging an issue in real time
- post-hoc analysis
- spotting trends over time
- capacity planning
Мониторинг зачастую сводится к следующим задачам:
– определением метрик/событий для мониторинга
– показание истории по метрикам
– настройка оповещения
Визуализация собранных данных в системах мониторинга может быть разной:
– графики, чаще всего показывающие изменение метрики относительно времени (по x откладывается время, по y – метрика). Бывают разные типы графиков:
– Line graphs – просто метрика по времени
– Hitmaps – группировка значений по времени, очень хороший тип для показания распределений. Каждая ячейка показывает группу значений по диапазону значений метрики, цвет показывает количество подпавших запросов
– Круговые диаграммы – показывают какой-то срез по типам
– таблицы
Основной принцип визуализации – простота. Чем проще для понимания данные, тем лучше. Так же данные должны быть легко доступны тем, кто с ними работает.
Группировка графиков в dashboard по типам (сетевые, системные, приложения или как нужно) – очень полезная штука для быстрого понимания ситуации, без необходимости переключения куда-либо.
Разных видоВ NMS огромное количество
Выбор зачастую сложен из-за разницы в функционале систем в нужном для тебе направлении мониторинга. Но при выборе никогда нельзя забывать вопросы: масштабирования по количеству метрик и узлов, поддержка системы (хотя бы что она не заброшена), надежность системы (истекает в том числе из первых двух вопросов). Кроме того зачастую по практике не надо забывать о мониторинге самой системы мониторинга.
Платные/промышленные:
-
- IBM Netcool
- Cisco PRIME
- Cisco FindIT (SMB segment from Linksys)
- Cisco StealthWatch – netflow
- Ciena blueplanet – подробнее ниже
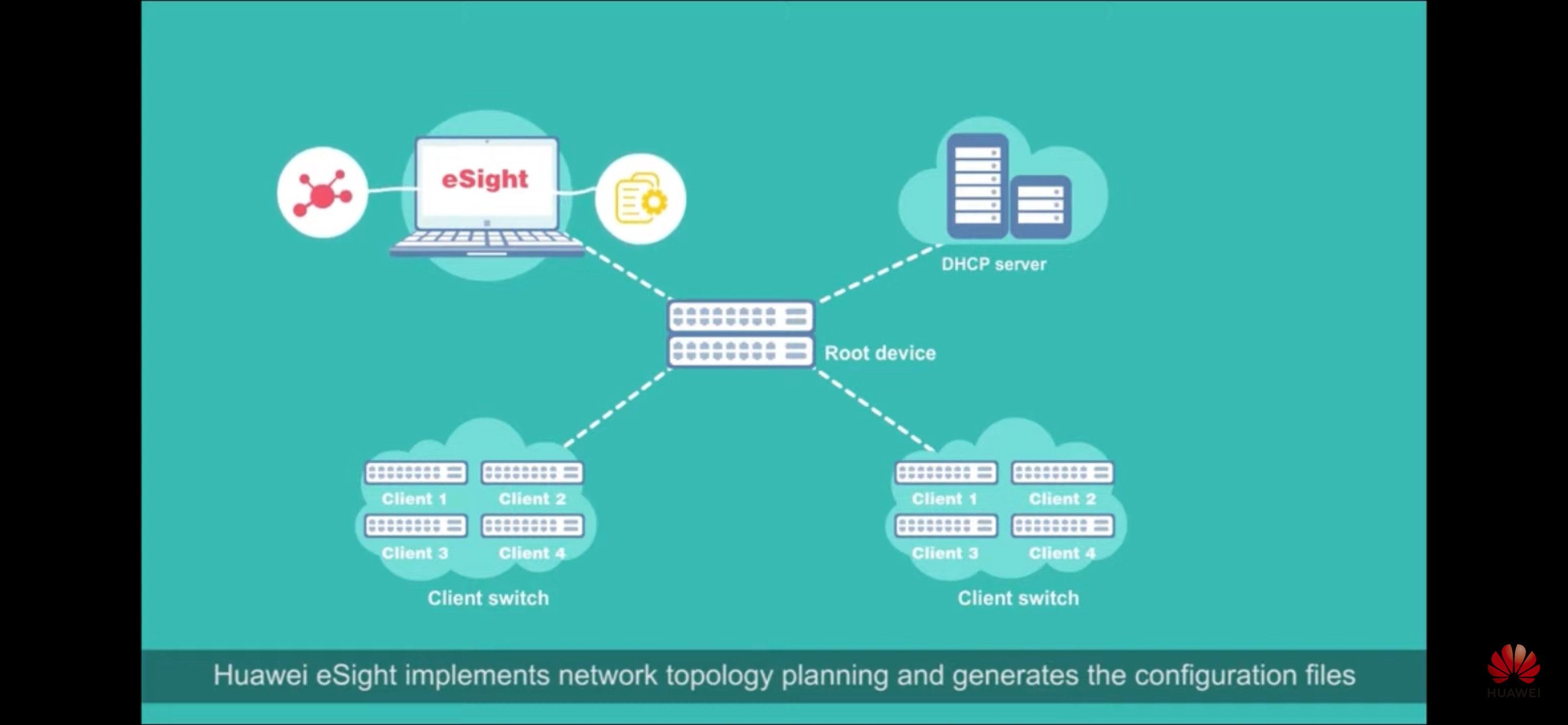
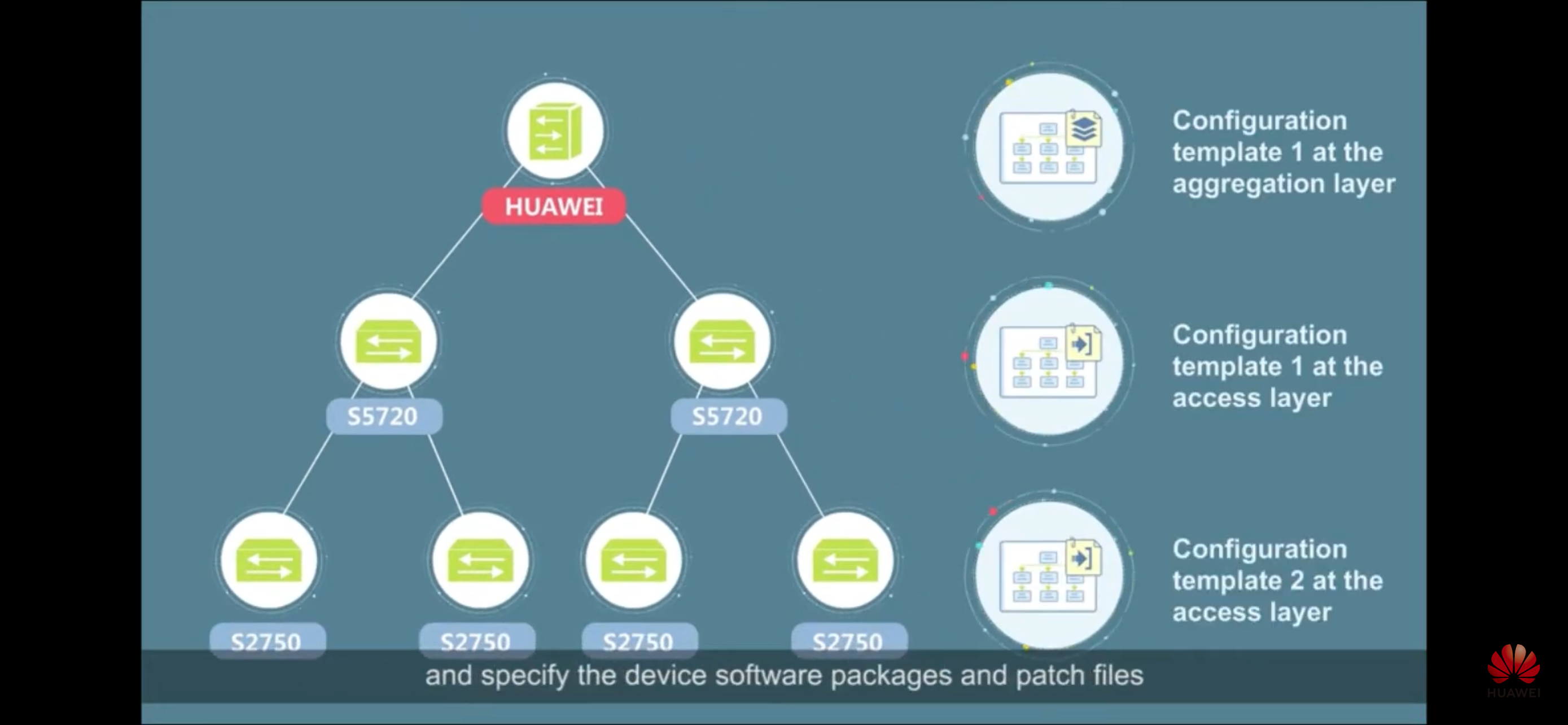
- Huawei eSight – есть в том числе topology planning, CMS, ZTP
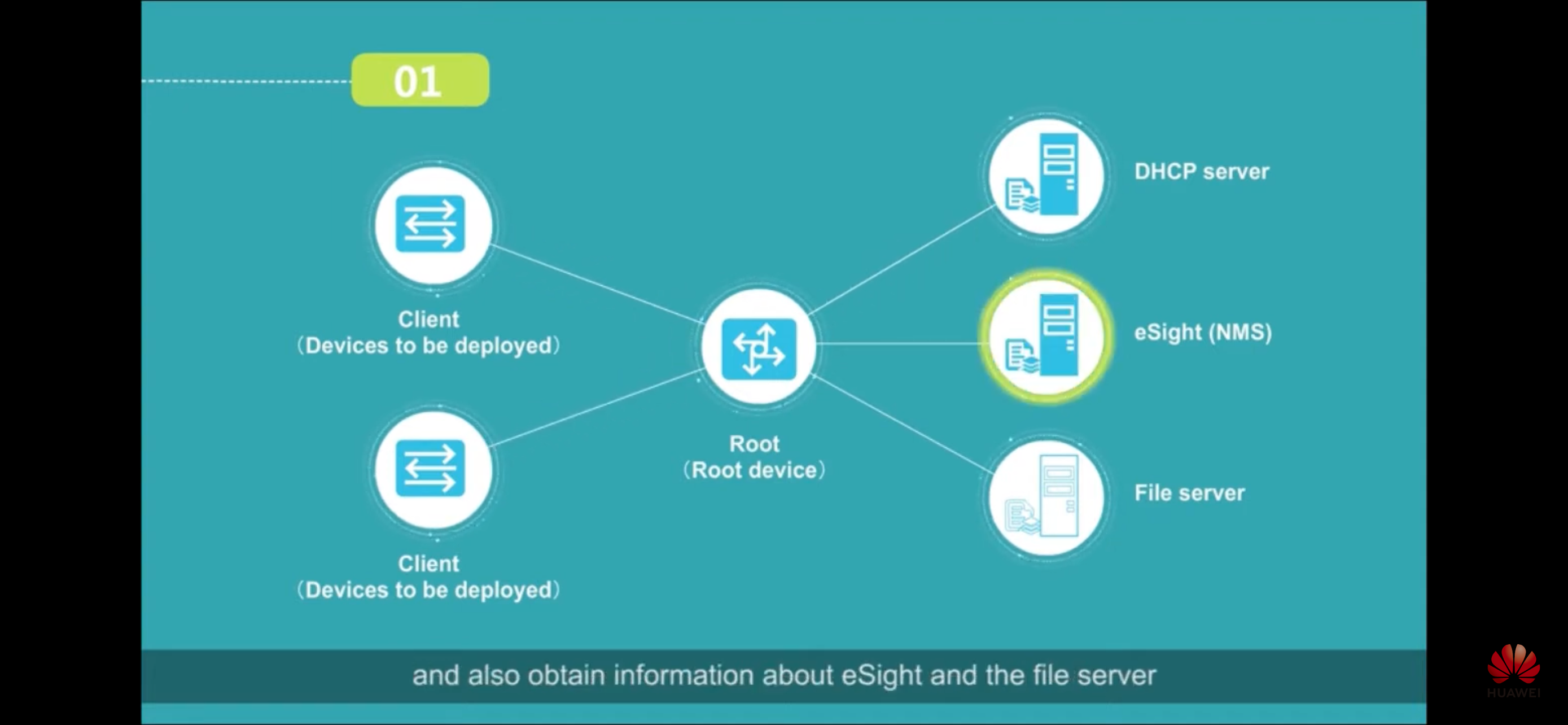
РФ:
-
- Orange
- Initi Solo
OpenSource/непромышленные платные
-
- LibreNMS
- NocProject
- Observium – красивый, достаточно удобный
- zabbix – старый проект, но до сих пор чаще других используется, при этом вполне эффективно, может быть задеплоен одновременно с prometheus (подробнее ниже в Zabbix vs Prometeus)
- Influxdb – современнее zabbix
- prometheus – часто используется с graphana
- victoriametrics (еще современнее): от grafana + influx зачастую уходят в пользу grafana + vmetrics, пример
https://habr.com/ru/articles/568090/
В какой-то момент мы заменили Prometheus на VictoriaMetrics (кластерную версию), благодаря чему сэкономили кучу ресурсов и начали хранить наши метрики глубиной в 1 год. Если кто-то еще не знаком с этим замечательным продуктом, советую почитать про него. Мы мигрировали на него практически безболезненно, даже не меняя свои конфиги. В результате Prometheus у нас был заменен на несколько компонентов: vmagent + amalert + vmselect + vminsert + vmstorage.
Большинство из описанных в статье конфигураций подходят как для VictoriaMetrics, так и для Prometheus.
-
- (реже) datadog
- (реже) new relic
- ElasticStack
- Ganglia
- statsd
- sysdig
- Cacti
- MRTG
- nagios, богат своими плагинами (из даже поддерживают другие решения типо icinga)
- D-Link D-VIEW
- Checkpoint SmartView Monitor
- AlgoSec Firewall Analyzer, RedSeal, SkyBox, FireMon Security Manager, ManageEngine Firewall Analyzer, CenturyLink Managed Firewall Service, SolarWinds Network Firewall Security Management Software.
- Gluware.com (не NMS, а configuration management, audit and discovery platform), подробнее ниже
- Netbox, Nautobot
We talked about monitoring platforms like Datadog, Wavefront, Prometheus and Ganglia, as well as software like Nagios and the Elastic Stack. Feel free to explore the links and compare and contrast the features these products provide.
We also went over some tools to collect metrics like Sysdig or collectD, and data visualization tools like Grafana. Finally, we mentioned the Pagerduty alert delivery system.
Опрос на habr.
Какой стек Вы используете для мониторинга?
36% Zabbix - 54
50.67% Prometheus - 76
2% Netdata - 3
4% Nagios - 6
7.33% другое - 11
Проголосовали 150 пользователей. Воздержались 23 пользователя.
Netbox, Nautobot
- в yandex используют racktables, не netbox
-
nautobot – Это форк Нетбокса, так что выбор его или netbox дело вкуса в основном.
-
Network2Code первые поняли, что на опенсорсе далеко не уедешь, и начали продавать поддержку и допфичи на свой форк – Nautobot. Нетбокс в те времена страдал от недостатка ресурсов на развитие и выезжал на энтузиазме создателя и комьюнити.
-
Сейчас за Нетбоксом стоят NetBoxLabs, которые активно пилят экосистему на венчурный капитал (недавно подняли $35M в Series B), и монетизируются через клауд версию и допфичи к open core модели.
-
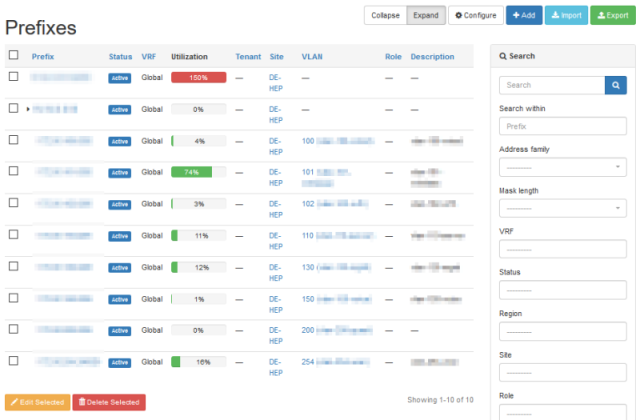
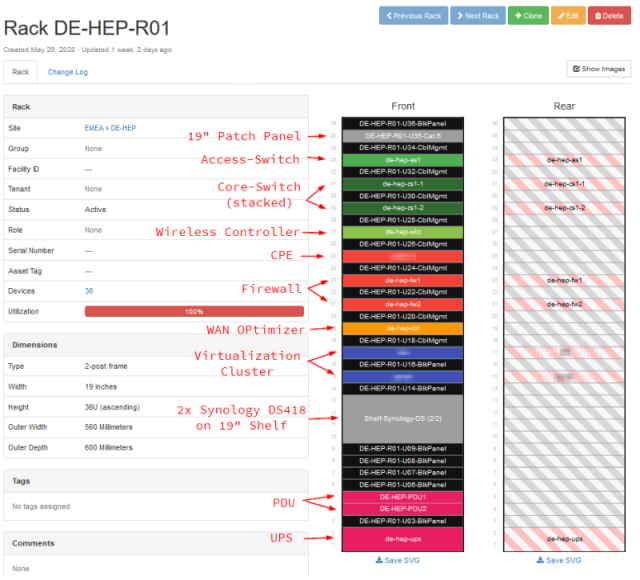
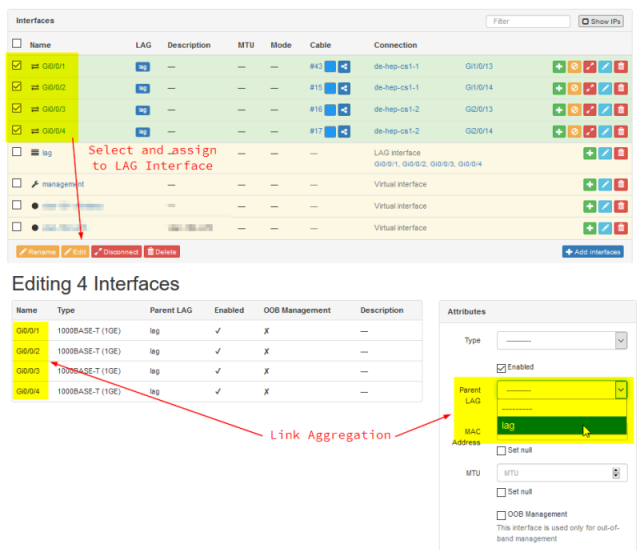
- netbox и его форк Nautobot – часто используется в ДЦ/IT компаниях для сетевой инфры; это в первую очередь inventory системы
- IPAM/VLAN management
- rack management
- cable management
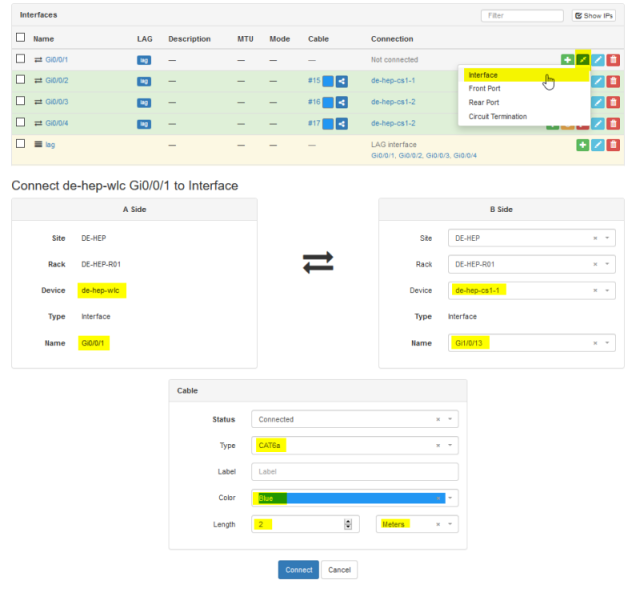
Gluware.com
Zabbix vs Prometeus
-
- Оба поддерживают как pull (опросы), так и push модель (agent)
-
Prometheus лучше подходит для мониторинга современных микросервисных архитектур и динамических сред, таких как Kubernetes, особенно если нужно отслеживать метрики производительности.
-
Интегрировать сбор метрик из своего приложения в прометей гораздо проще чем в забикс
- Из-за подхода «не все в одной коробке» prometheus более гибок, но сложнее Zabbix
-
-
Zabbix — это мощный инструмент для комплексного мониторинга традиционной IT-инфраструктуры, включая серверы, сети, и устройства.
- Имеет почти все что нужно из одной коробки, в отличии от prometheus
- Из коробки лучше масштабируется
- хранение данных в БД
- прокси сервера
- Zabbix + Prometeus – оба инструмента могут быть использованы вместе для обеспечения более полного мониторинга, при этом Zabbix может следить за инфраструктурой, а Prometheus — за метриками производительности приложений.
zabbix
- Считается Legacy в сравнении с influx и prometheus/vicrotiametrics, при этом он врятли куда то денется в ближайшее время – напр. достаточно компетентный знакомый админ/devops выбрал его для рабочих задач т.к. в нем есть все нужное из коробки или очень легко добавляется
В Zabbix, в отличии от Cacti, есть возможность организации proxy server’ов. В результате архитектура намного более масштабируема – как вплане производительности, так и функциональности (какие то участки сети недоступны с одного сервера).
Zabbix agent
apt-get install zabbix-agent
vim.tiny /etc/zabbix/zabbix_agentd.conf
Server=192.168.1.11 # это адрес именно сервера, не агента! (можно указать несколько)
Hostname=ubuntuserver
service zabbix-agent restart
chmod 0777 /var/log/zabbix-agent/
При каких либо проблемах смотрим логи – примеры проблемы с конфигом (запросы от неизвестного сервера) и правами (отсутсвуют права на write у agent).
cat /var/log/zabbix-agent/zabbix_agentd.log
29495:20201201:120810.667 failed to accept an incoming connection: connection from "172.31.2.23" rejected, allowed hosts: "127.0.0.1"
29495:20201201:121122.882 failed to accept an incoming connection: connection from "172.31.2.23" rejected, allowed hosts: "127.0.0.1"
zabbix_agentd [29493]: failed to open log file: [13] Permission denied
zabbix_agentd [29493]: failed to write [Got signal [signal:15(SIGTERM),sender_pid:1,sender_uid:0,reason:0]. Exiting ...] into log file
В zabbix есть встроенный сервисы autodiscovery хостов:
- Network discovery – путем опроса объектов мониторинга с самого сервера zabbix,
- Active agent autoregistration – авторегистрация самим объектом мониторинг на zabbix за счет работы agent на объекте мониторинга
- Low-level discovery – механизм низкоуровнево discovery для авто-создания элементов (добавление хостов в группу, назначения на них метрик). К примеру, при обнаружении что хост соответствует какому то критерию – назначить ему определенные политики мониторинга.
Discovery
1 Network discovery
2 Active agent autoregistration
3 Low-level discovery
1 Network discovery
In this example, we would like to set up network discovery for the local network having an IP range of 192.168.1.1-192.168.1.254.
In our scenario we want to:
- discover those hosts that have Zabbix agent running
- run discovery every 10 minutes
- add a host to monitoring if the host uptime is more than 1 hour
- remove hosts if the host downtime is more than 24 hours
- add Linux hosts to the "Linux servers" group
- add Windows hosts to the "Windows servers" group
- use the template Linux for Linux hosts
- use the template Windows for Windows hosts
3 Low-level discovery
Low-level discovery provides a way to automatically create items, triggers, and graphs for different entities on a computer. For instance, Zabbix can automatically start monitoring file systems or network interfaces on your machine, without the need to create items for each file system or network interface manually. Additionally, it is possible to configure Zabbix to remove unneeded entities automatically based on the actual results of periodically performed discovery.
A user can define their own types of discovery, provided they follow a particular JSON protocol.
The general architecture of the discovery process is as follows.
First, a user creates a discovery rule in Data collection → Templates, in the Discovery column. A discovery rule consists of (1) an item that discovers the necessary entities (for instance, file systems or network interfaces) and (2) prototypes of items, triggers, and graphs that should be created based on the value of that item.
An item that discovers the necessary entities is like a regular item seen elsewhere: the server asks a Zabbix agent (or whatever the type of the item is set to) for a value of that item, the agent responds with a textual value. The difference is that the value the agent responds with should contain a list of discovered entities in a JSON format. While the details of this format are only important for implementers of custom discovery checks, it is necessary to know that the returned value contains a list of macro → value pairs. For instance, item "net.if.discovery" might return two pairs: "{#IFNAME}" → "lo" and "{#IFNAME}" → "eth0".
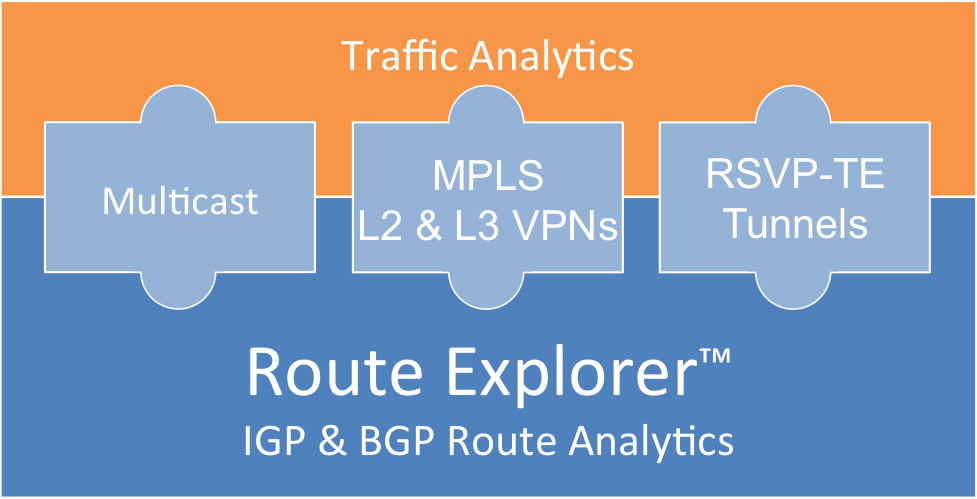
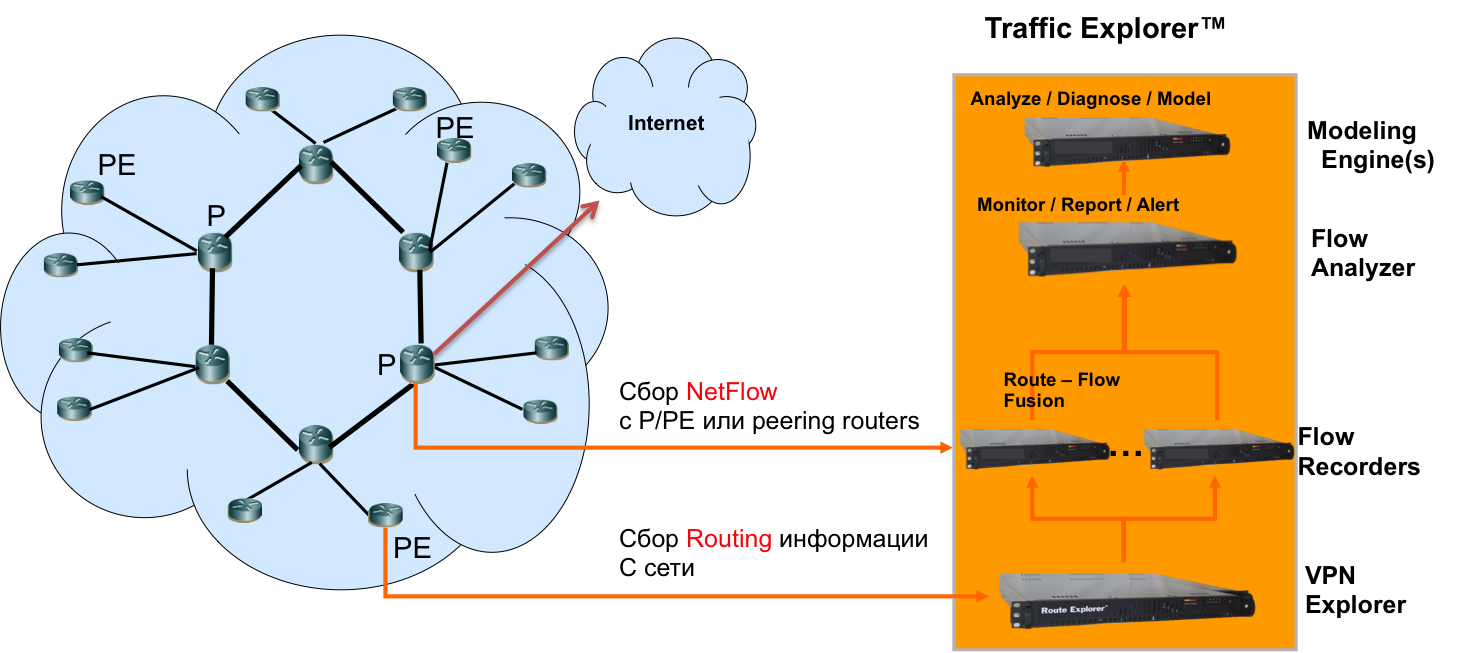
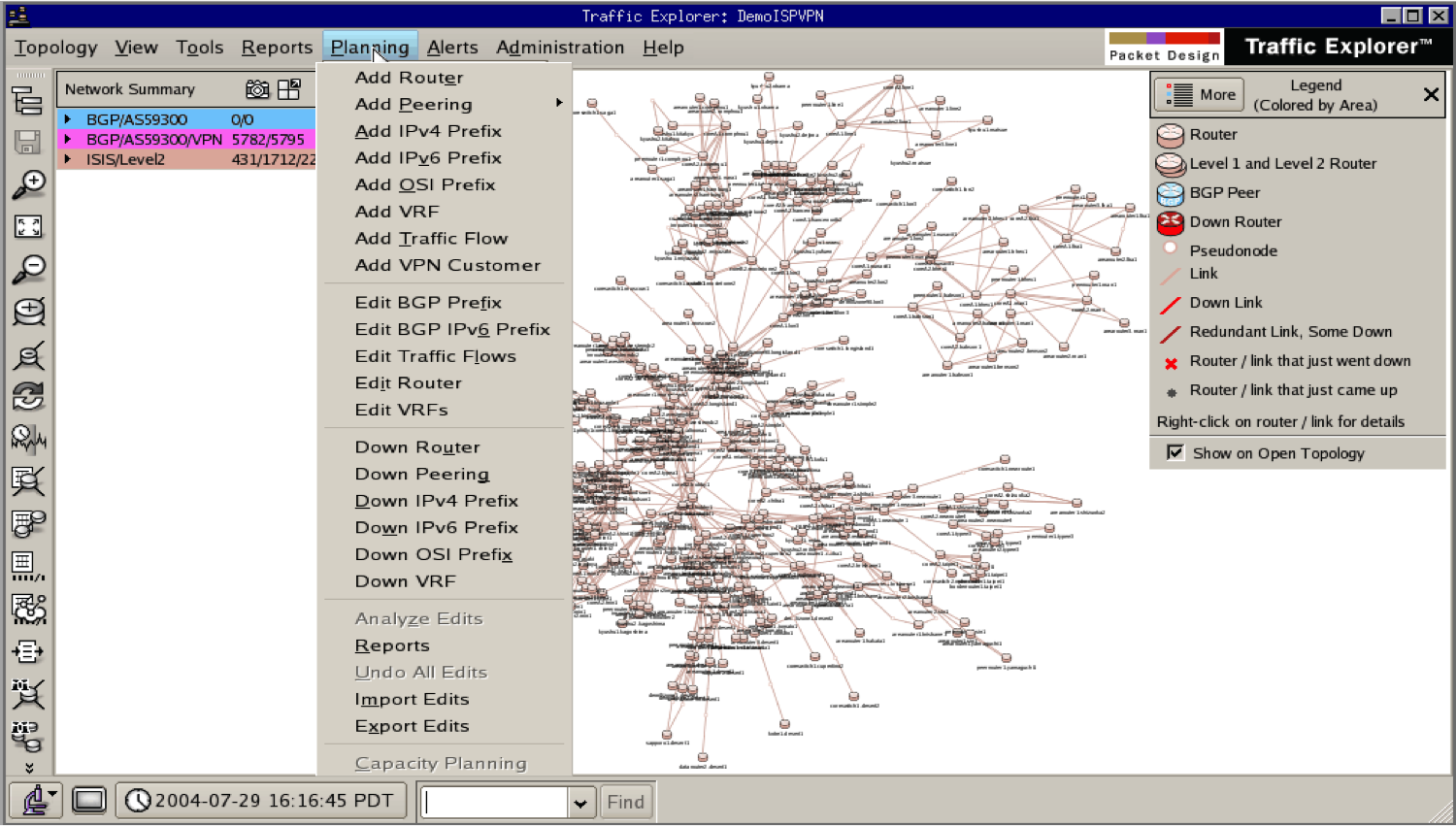
ciena blueplanet
Мощный модульный продукт. Составляющие:
- Ciena blueplanet Traffic Explorer – netflow, sflow
- Ciena blueplanet Route Explorer – bgp routes, multicast, MPLS (можно посмотреть откуда роутится, и сколько трафика льется)
- Ciena blueplanet Performance explorer – SNMP
- etc (Provisioning and Optimization Explorer, Multi-Layer Explorer)
route explorer
SFLOW
- sflow не является тем же самым, что netflow.
- SFlow коллекторов не мало , зачастую его функционал поддержан и NMS, а совместно с flow поддерживается и netflow, знакомые мне:
- (netflow, sflow) Примеры продуктов/коллекторов поддерживающих и netflow и flow
- ntop nProbe – netflow, sflow
- FlowMon Collector – netflow, sflow
- fastnetmon.com – netflow, sflow
- IBM Security QRadar – netflow, sflow
- Cisco StealthWatch – netflow, sflow; компания lancope, купленная cisco
- Scrutinizer – netflow, sflow
- Ciena blueplanet Traffic Explorer – netflow, sflow
- ELK logstash – netflow, sflow
- Akvorado (goflow2) – netflow, sflow; opensource go collector (см. скрины ниже отдельно)
- VIAVI Solutions Inc. Observer Analyzer – netflow, sflow
-
Сбор sflow поддерживается influxdb через Telegraf Plugin
- (netflow, sflow) Примеры продуктов/коллекторов поддерживающих и netflow и flow
- (NTA/Netflow/sflow) в своих продуктах Cisco делали как то хранение полной копии, но в итоге отказались от этого (вебинар ГАРДА)
- Пример influxdb
- Снимает непосредственные семплы трафика (хедеры пакетов, sampling size) с заданным sampling rate (напр. 1 на 2048 или 4096) и отправляет на коллектор. Именно поэтому SFlow – sampled flow. При этом этот sampling rate может увеличиваться при включении на всех портах, нужно смотреть конкретную реализацию.
- В каких то случаях (чаще всего это сценарии ИБ, именно там это интересно в первую очередь) возможно использовать sample rate 1 к 1, но безусловно это трафика не должно быть много/инфраструктура (сеть/обработка/хранение) вся должна быть к этому готова.
- Часто полезнее netflow для задачи обнаружения DDoS – он отправляет семплы трафика сразу, не ожидая какого то интервала типа 30/60 сек как netflow, что важно для реагирования (переключения на защиту от ddos свою или 3td party/анонс по bgp community) – плюс отправляет сами пакеты (полностью или усеченные), что важно для понимания какая конкретно атака осуществляется
- Часто аппаратно оффлоудится
- Пример работы на коммутаторе-сенсоре (чаще всего реализуется именно на них): на asic, отвечающий за некоторое количество портов, приходит пакет, asic в зависимости от настроенного sample rate отсылает пакет на cpu/супервизор для пересылки на коллектор, так же между asic и cpu часто реализован аппаратный rate limiter, защищающий CPU от излишних данных
- Подробное описание по настройке тут
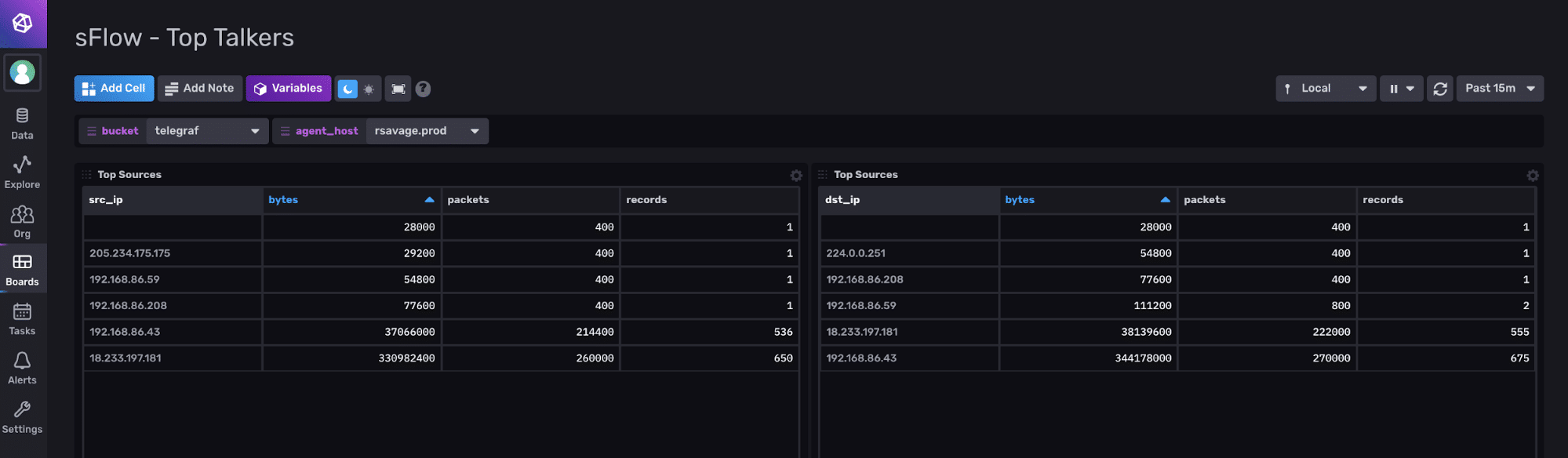
Parameters Default
sFlow sampling rate 2048
sFlow sampling size 116
sFlow counter poll interval 10
sFlow maximum datagram size 1024
sFlow collector port 6343
AIOps
AIOps — обнаружение аномалий в логах и метриках на основе AI.
У разных продуктов разная основа:
-
- stat анализ ML
- DeepLearning
- прикрученный ChatGPT
Netflow
- (netflow, sflow) Примеры продуктов/коллекторов поддерживающих и netflow и flow
- ntop nProbe – netflow, sflow
- FlowMon Collector – netflow, sflow
- fastnetmon.com – netflow, sflow
- IBM Security QRadar – netflow, sflow
- Cisco StealthWatch – netflow, sflow; компания lancope, купленная cisco
- Scrutinizer – netflow, sflow
- Ciena blueplanet Traffic Explorer – netflow, sflow
- ELK logstash – netflow, sflow
- Akvorado (goflow2) – netflow, sflow; opensource go collector (см. скрины ниже отдельно)
- VIAVI Solutions Inc. Observer Analyzer – netflow, sflow
- (NMS, Kaspersy SD WAN) Kaspersky KUMA (SIEM) принимает Netflow потоки
- netflow есть далеко не на всех коммутаторах, даже Cisco
- (NTA/Netflow/sflow) в своих продуктах Cisco делали как то хранение полной копии, но в итоге отказались от этого (вебинар ГАРДА)
- до 5-10% занимает трафик netflow по отношению к исходному сырому трафику, но много зависит от характера трафика/настроек оборудования (вебинар ГАРДА)
- Пример akvorado
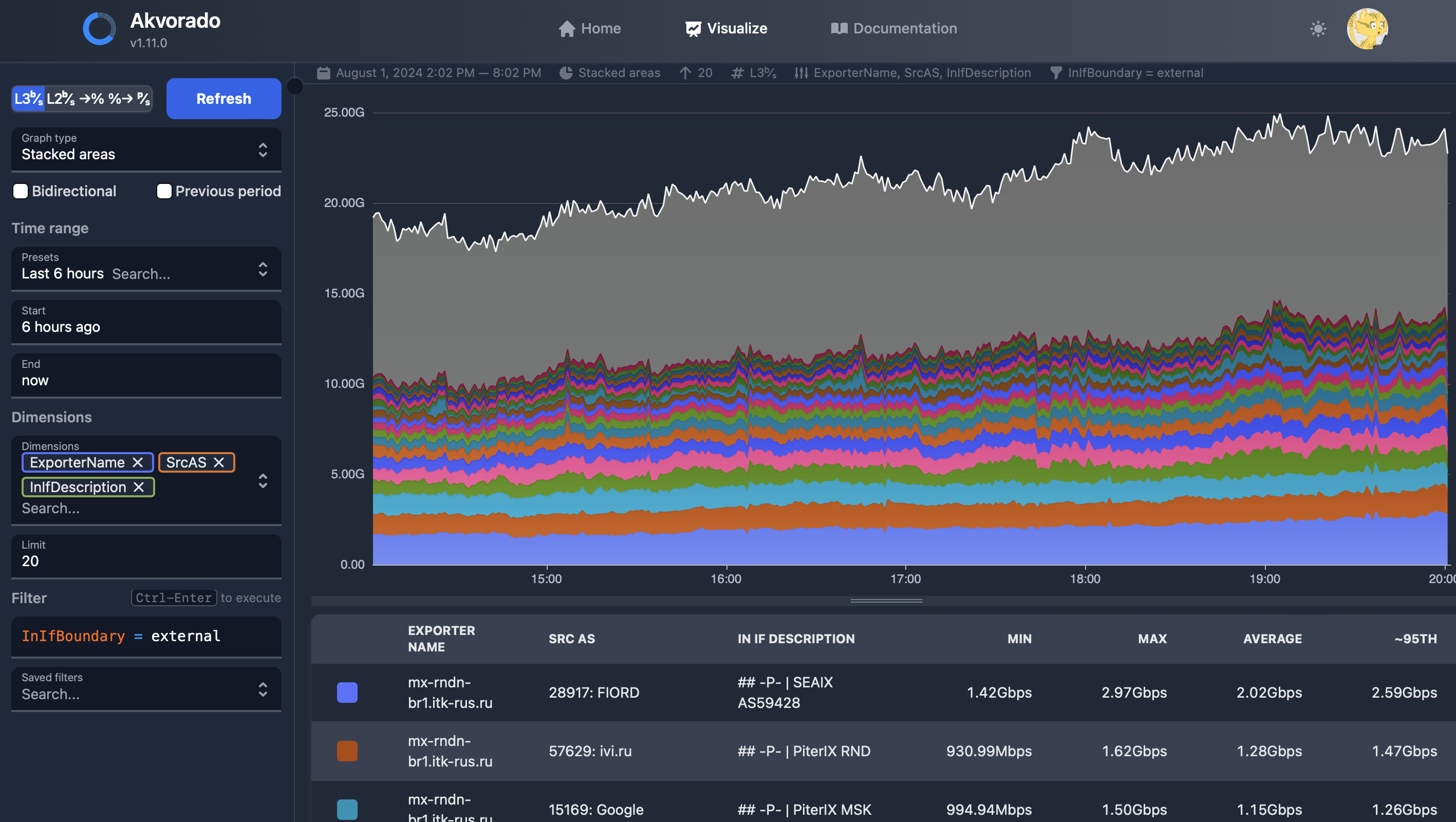
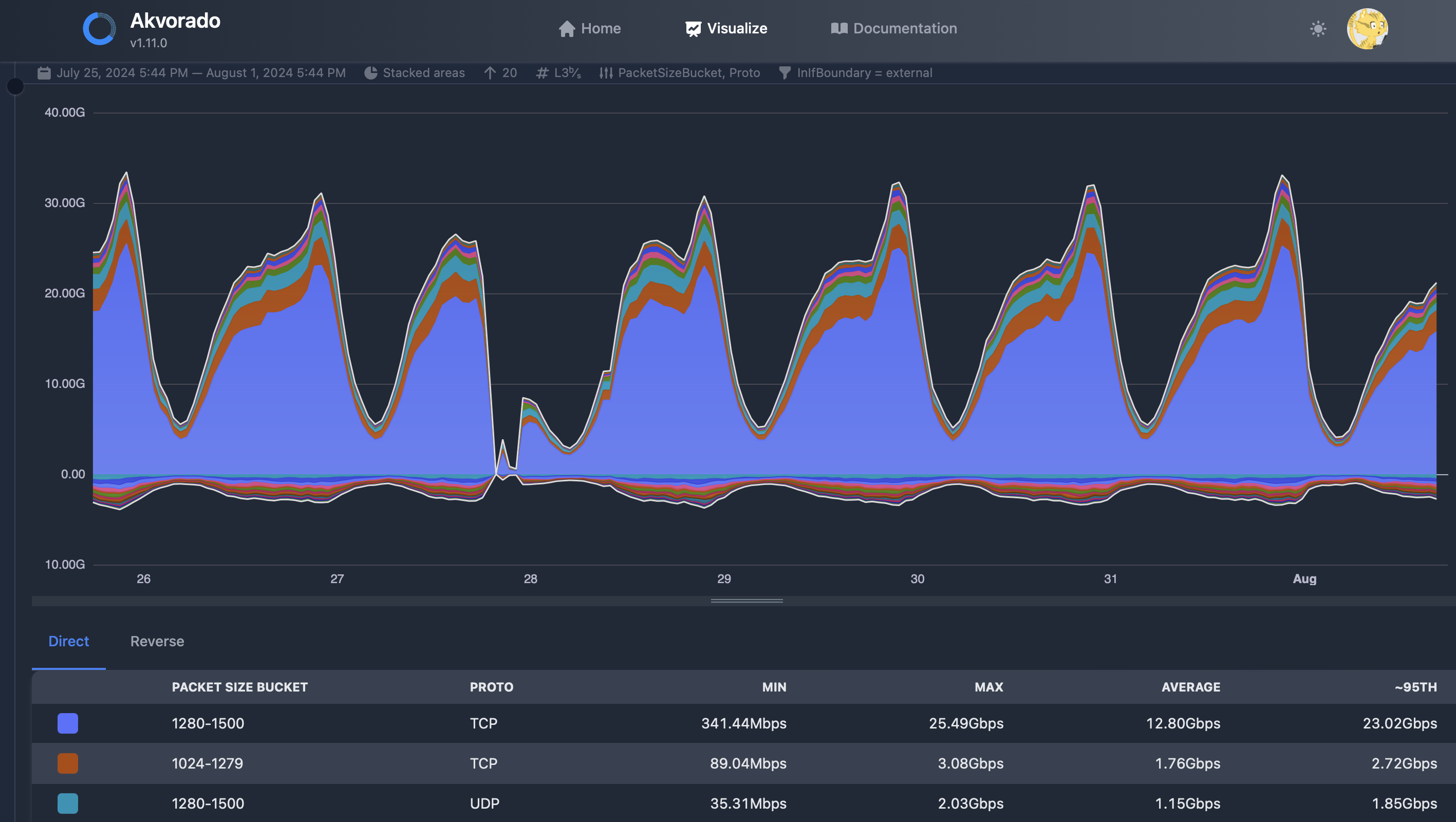
- opensource для flow collection зачастую не имеют gui и нужно самому поупражнятся чтобы добавить
- На ИБ девайсах чаще всего реализуется именно IPFIX/netflow и зачастую реализован аппаратно/заоффлоуджен т.к. он предоставляет для ИБ наиболее ценную информацию, sflow чаще даже не поддерживается, а если поддерживается, то чаще всего на базе CPU и можно столкнуться с проблематикой вплоть до – если вы включили sflow, то прощайтесь с аппаратным offload netflow потоков (Linkmeup flow podcast)
- Как везде в реализациях netflow бывают баги – напр. с vswitch забагованной версии гипервизора отправлялись фейковые петабайты данных; в агрегации с порта новой карты отправлялись корректные данные, а с порта старой карты кривые (Linkmeup flow podcast)
- Netflow v5 до сих пор используется, но он не поддерживает vlan/mpls/ipv6
- Netflow v9 = IPFIX, поддерживает шаблоны/templates (по сути возможность добавления любых, включая вендор-специфик, данных в сбор), но нужно учитывать, что их должен поддерживать не только сенсор, но и коллектор/парсер. В итоге коммерческие коллекторы могут поддерживать то, чего нет в open source версиях коллектора.
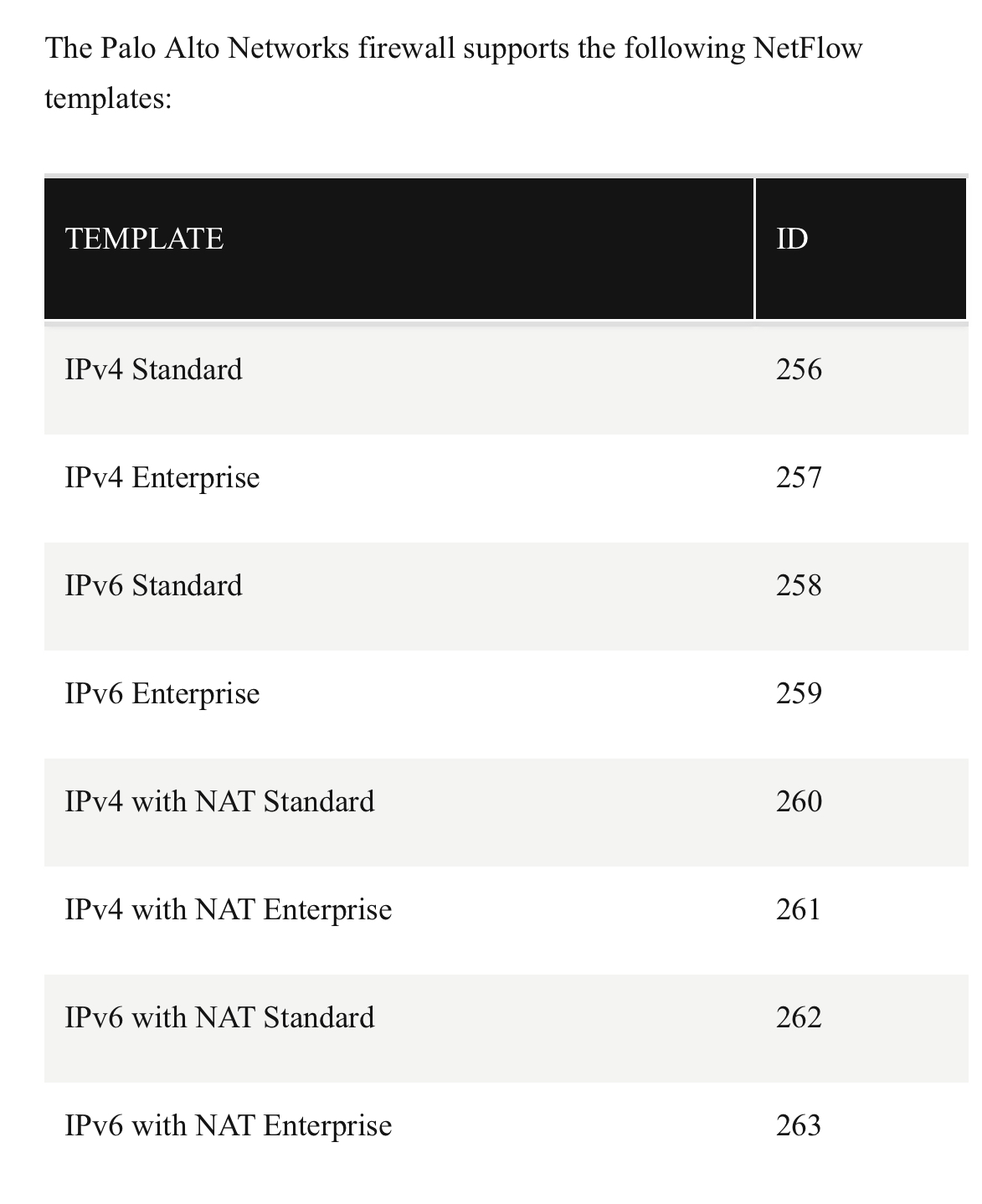
- В netflow некоторые вендоры на некоторых девайсах реализуют возможность отправки семплов пакетов с каким то sample rate (причем часто с рандомизацией семпла, чтобы не каждый условный тысячный выбирался, а рандом в рамках тысячи – чтобы не упустить отклонения в статистике, в том числе может быть полезно для задач ИБ), по аналогии с sflow, но надо смотреть конкретную реализацию, могут быть ограничения типо sample rate только один к одному 🤣 или отправка загружает CPU, так или иначе sflow чаще более подходит для решения этой задачи
- При реализации ipfix/netflow чаще всего данные с asic не отсылаются на cpu, asic обогощает flow таблицу/кеш, а cpu по какому то интервалу отсылает ее на коллектор в виде netflow. Т.е. коммутатор/asic мониторит проходящие потоки и занимается актуализацией данных в flow таблице – инкрементирует счетчики по активным потокам, создает новые потоки (no flow in current flows), удаляет старые (по tcp rst/timeout/etc).
- Нагрузка 30-50к flow на сеть из 10 роутеров и 30 firewall, причем на fw был настроен sampling 1 к 1 (Linkmeup flow podcast)
- IPFIX – IP flow information exporter. IPFIX является стандартом, описывающим экспорт flow информации с сетевых устройств, RFC 5103, RFC 7011 – 7015
- IPFIX, netflow, NEL, sflow сообщения передаются с использованием UDP
- Netflow широко используется по закону Яровой для экспорта NAT таблицы т.к. нужно сопоставлять какой абонент (серый IP) подключился к интернету
- Netflow иногда используются для задач биллинга по трафику
- В целом если говорить про netflow, то нужно понимать что сливается именно мета-информация по сессиям, а не полный поток данных этих сессий (span/tap/dump), в этом и
- преимущество
- только то, что надо
- значительно легче реализовать при крупных инсталляциях из-за огромной разницы в объеме данных (сотни/тысячи раз)
- значительно проще анализировать
- и недостаток
- может нехватать конкретных/всех пакетов с данными и проч
- преимущество
- Если говорить про облачных провайдеров, там зачастую реализуется свой flow протокол (свои сенсоры/коллекторы), который несовместим с netflow и требует отдельного управления; в итоге в гибридной инфраструктуре данные по on-premise и on-cloud могут быть в разных местах по умолчанию, хотя можно в общем случае внедрить в облако стандартные сенсоры netflow/ipfix с передачей данных на свои коллекторы
-
Netflow (а точнее телеметрия) на Nexus сливается на базе ASIC каждые 100мс.
https://www.cisco.com/c/en/us/products/collateral/switches/nexus-9000-series-switches/datasheet-c78-742283.html
https://www.cisco.com/c/dam/global/en_uk/products/switches/cisco_nexus_9300_ex_platform_switches_white_paper_uki.pdf
The platform has the capability to collect comprehensive Cisco Tetration Analytics™ telemetry information at line rate across all the ports without adding any latency to the packets or negatively affecting switch performance. This telemetry information is exported every 100 milliseconds by default directly from the switch’s Application-Specific Integrated Circuit (ASIC). This information consists of three types of data:
● Flow information: This information contains details about endpoints, protocols, ports, when the flow started, how long the flow was active, etc.
● Interpacket variation: This information captures any interpacket variations within the flow. Examples include variation in Time To Live (TTL), IP and TCP flags, payload length, etc.
● Context details: Context information is derived outside the packet header. It includes details about variation in buffer utilization, packet drops within a flow, association with tunnel endpoints, etc. -
Best practice netflow
-
включение netflow как можно ближе к конечным хостам (напр. на access layer – user access layer, vpn terminal points, dc access layer) – видимость
-
все netflow записи для потока должны отправляться на один коллектор – дедупликация
-
часто netflow деплоится на internet edge для просмотра того, что приходит из внешней сети и уходит из внутренней
-
Напр. в asr1k для medium/large организаций присутствует Cisco quantum flow processor, который обеспечивает ALG, l4/l7 zone based firewall, high speed nat/firewall, netflow event logging/NEL. NEL использует netflow v9 темплейты для логгирования binary syslog на NEL коллектор. NEL на ASR может логгировать netflow информацию nat/firewall (создание/завершение трансляций/сессии) на высокой производительности.

Видимость (network visibility) – крайне важный аспект безопасности. Ты не может полноценно организовать защиту, не имея видимости – до атаки, после, во время; какие приложения/какие хосты/сервера/страны/ASN и проч взаимодействуют/присутствуют в твоей инфраструктуре (shadow IT, asset management). Так же из важных применений это мониторинг ИБ, подготовка к compliance и расследование инцидентов. Обеспечение видимости – первый шаг при организации безопасности среды. Есть ряд способов обеспечения видимости и защиты от различных угроз как на уровне сети, так и на уровне конечных хостов – netflow/ipfix, ngids/ngips/nta, EPP, etc.
Помимо безопасности этот инструмент может быть полезен и для сетевых администраторов – напр.
- часто полезно понимать (напр. в рамках аварии или стандартного capacity planning) что конкретно передается в утилизированном линке с точки зрения мета-информации сессий и даже payload (планово утилизированном или DoS).
- знания о том, где проходят потоки по факту могут быть полезны – какие префиксы к каким обращаются, соответствует ли это ожидаемому (мб надо перебалансировать).
Netflow предоставляет видимость сети network visibility, которая позволяет избавится от blind spots в сети. Netflow позволяет проанализировать метаданные по трафику до/после и вовремя атаки. В итоге это позволяет создать более безопасную среду (network as a enforcer).
-
-
Разведка (recon)
-
Распространение вирусов (malware prolifiration)
-
Извлечение данных (data exfiltration)
-
Взаимодействие с управляющим сервером (command and control, CC)
-
Анализироваться/алертится может информация про количество трафика (DoS, восстановление трафика после работ), количество соединений, топы: хосты/протоколы/страны, IP адреса/порты/доменные имена (включая наложения на них гео-данных/индикаторов компрометации IoC), перемещения/действия злоумышленника по/в инфраструктуре, поведение пользователя/оценка необходимости расширения каналов (статистический анализ/machine learning).

-
-
Netflow collector/коллектор – сервер (физический или виртуальный), который собирает netflow данные от сетевых устройств. В collector решаются задачи дедупликации flow данных и нормализации данных разных вендоров/протоколов, поэтому в среднем (исключения типо гиперсейлеров/супер объемов типо одно устройство убивает инфраструктуру сбора flow) правильно, когда все данные одного флоу попадают на один коллектор.
- напр. нормализация данных в человеко-читаемый вид – резолвить коды/типы IP, TCP flags преобразовать из кодов в имена, имена интерфейсов из кодовых имен в конкретое название (в том числе путем опроса девайса по snmp).
-
напр. flow stitching, когда направления in/out объединяются используя симметричный hash на 5-tuple, при сохранении уникальной информации
-
напр. интерфейсах, через которые проходил поток или еще более важный кейс – поток 5-tuple проходит много устройств, нужно показывать один поток, а не несколько, при этом показывая все устройства, которые он проходил/откуда пришел и ушел
- напр. получение данных в вендор-специфик формале, но представление данных в классическом виде после нормализации
- так же коллектор (в данном случае парсер) может преобразовывать данные netflow в какой то формат (json, protobuf, etc), необходимый для интеграции netflow данных во внутренние системы компании и отсылать конвертированные данные без сохранения у себя на централизованное хранилище (возможно через промежуточные очереди/брокер типо kafka), а визуализация/анализ может работать поверх уже этих данных в БД; причем метаданные после парсинга могут как увеличить объем в сравнении с изначальным flow (обогащение доп.инфы подробнее ниже, несжатое хранение типо ElasticSearch), так и уменьшить (за счет сжатия данных в хранилище типа ClickHouse)
- коллектор часто отвечает за обогащение доп.инфы в данные напр. гео-IP maxmind с отображением на карте, NAT доп. инфы, инфы из AD, BGP info типо as path до IP клиентов за счет пассивной сессии коллектора с бордером/BMP; это умеют и opensource коллекторы типо akvorado (goflow2), pmacct
- очень важна продолжительность сохранения данных о flow (час/день/неделя/месяц) и хранятся ли семплы трафика/с каким sample rate (чем чаще тем больше детализация, но и больше занимаемый объем) – это повлияет на итоговую стоимость решения, зачастую правильно будет задать разный срок хранения для sample потоков и для агрегационных данных, возможно даже на разные сегменты задать разные настройки
-
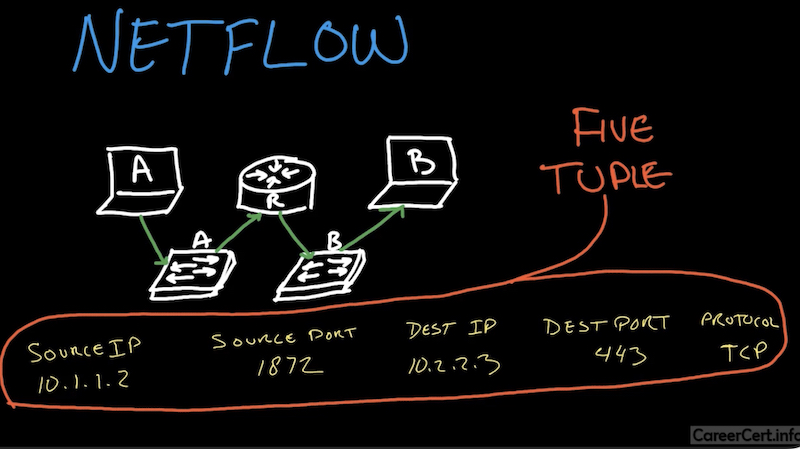
компоненты

-
-
Netflow sensor – собирает первичную информацию (мета информацию по сессиям) и передает на коллектор, чаще всего сенсор встроен непосредственно в передающие трафик устройства, но может быть и отдельным девайсом (напр. когда устройство не поддерживает или частично поддерживает netflow/ipfix). В таком случае сенсор должен получать потоки данных от основного/проблемного устройства – span, tap или netflow данные (обогащение). Может быть в виде VM или эту задачу может решать устройство типо брокера пакетов.
-
(Optional) netflow management controller/console – управляет всем решением netflow (сенсорами, коллекторами). Пример решения – stealthwatch management console (SMC).
- (Optional) analytics platform – позволяет анализировать данные с разных коллекторов при крупных инсталляциях со множеством коллекторов.
- (Optional) balancer – может быть отдельный балансировщик для netflow потоков, но функционал балансировки может быть включен и в replicator; главное чтобы балансировщик не был тем же, который используется для балансировки целевых сервисов, которые могут быть под DoS атакой – есть риск падения балансировщика совместно с потерей flow логов (на которые может быть завязана защита от DoS)
-
(Optional) netflow replicator – может осуществлять разные задачи – напр. дублирование (replicate) потоков netflow информации на разные коллекторы или наоборот разделение netflow потоков на разные коллекторы (напр. на основе ip отправителя/ip коллектора). Чаще всего используется когда сенсор не может отправить flow данные на все необходимые коллекторы – часто на свичах/роутерах можно отправить netflow данные лишь на ограниченное (один или два) количество коллекторов. В итоге на данных устройствах в качестве коллектора может указываться репликатор. Но кроме этого replicator может подменять адреса – напр. подставлять свой IP в качество source IP потока (хотя в среднем это не требуется т.к. во flow есть отдельное поле отправитель; которые некоторые коллекторы игнорируют используя данные о IP адреса источника), может подменять src порты для flow потоков, это обязательно нужно чтобы и для template и для непосредственно flow данных использовался один netflow коллектор – иначе если есть балансировка по 5 tuple на коллекторы, потоки попадут на разные коллекторы (у спикера из сбера в виде подов k8s). Производительность его в общем случае достаточно высокая т.к. он stateless обрабатывает трафик – на четырех ядрах VM обрабатывали порядка 500к flow с загрузкой CPU около 20%, причем подняли их много (пул виртуалок) и навесили на них адрес anycast и наоборот разделяли подети на разные коллекторы, а не дублировали потоки (подкаст netflow linkmeup; bottleneck у них в проде были не replicator, а парсеры/коллекторы потоков в json, а в теории могут быть где угодно – сеть, обработка/коллекторы-парсеры-брокеры очередей-репликаторы, хранение/БД). Есть некоторый риск amlification атаки на инфаструктуру сбора flow из-за репликации потоков т.к. по сути это встроенная возможность умножения нагрузки, но по факту с этим не сталкивались, потенциально т.к. Replicator разделяли на коллекторы нагрузку, а не домножали; плюс потенциально трафик отправлялся на очистку от DoS раньше, чем попадал в flow инфраструктуру. Так же от replicator до коллекторов в k8s сделали healthcheck, если репликаторы не могут достучаться до кубера в своем ДЦ – происходит отсылка flow данных в коллекторы/кубер другого ДЦ (подкаст netflow linkmeup).
-
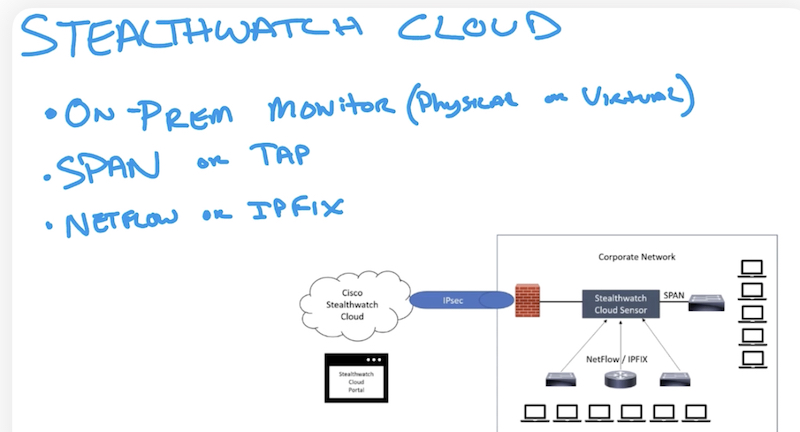
NETFLOW:stealthwatch cloud
-
-
Aws – vpc flow logs
-
Gcp – vpc/gpc flow logs
-
Azure – nsg (network security groups) flow logs network watcher
-
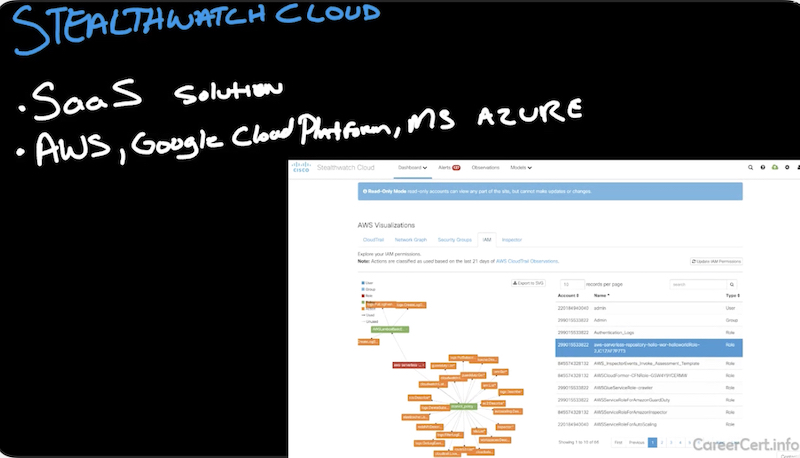
-
- дашборды и визуализация разных вещей
-
network graph (ноды задеплоенные в aws),
-
security groups (используемые security groups),
-
identity & access management (IAM, можно посмотреть разрешения IAM)
-
- дашборды и визуализация разных вещей
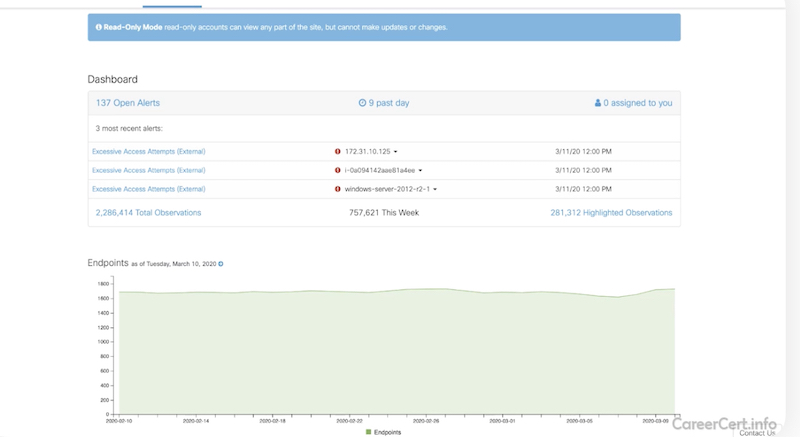
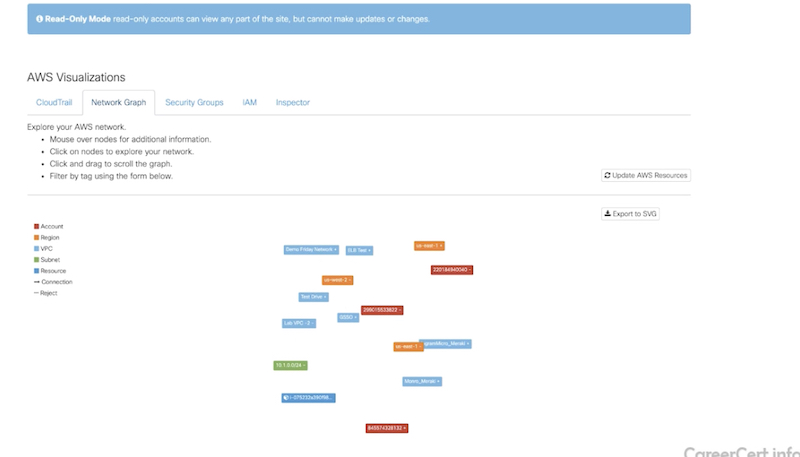
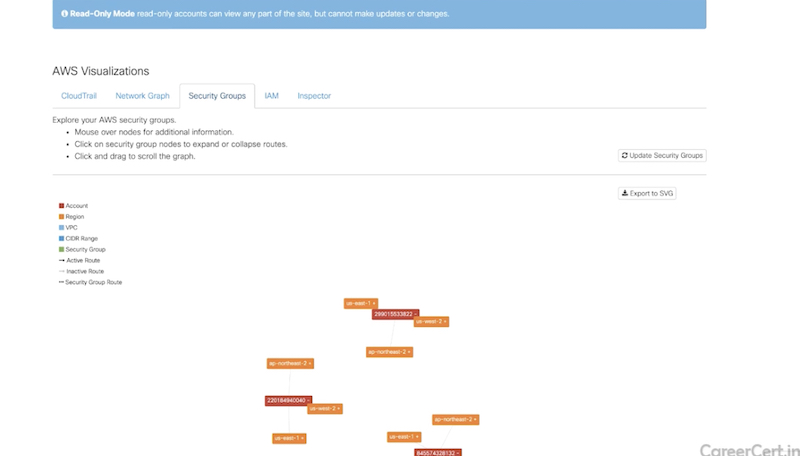
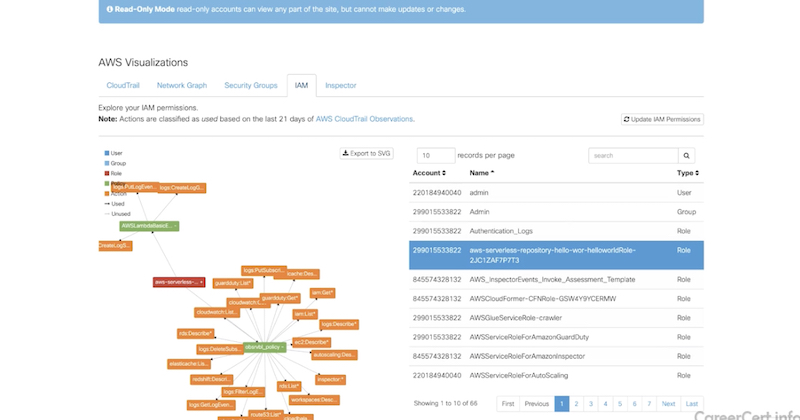
-
-
получение логов (напр. Alerts событий ИБ)
-
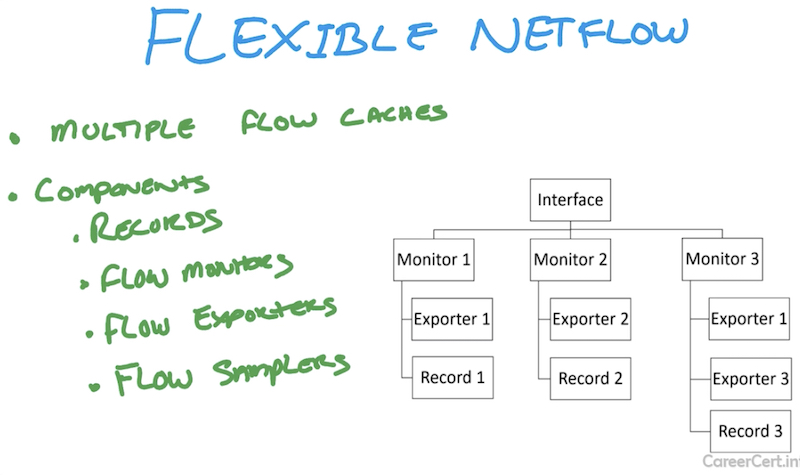
NETFLOW: Flexible netflow
-
-
сбор информации о ipv6
-
методах туннелированиях (overlay) ipv6 поверх ipv4 (teredo, 6to4, 6rd, etc)
-
приложениях nbar
-
-
-
Flow records – что отправляем на коллектор. Комбинация ключевых (5 tuple + tos + ttl + интерфейсы/влан + MAC и другие поля) и не-ключевых полей (tcp flags, number of bytes/packets, subnet mask). Ключевые поля задаются через опцию match в Cisco IOS, не ключевые – через опцию collect (подробнее в примере конфигурации ниже). Ключевые поля всегда экспортируются в «обычном» netflow, в отличии от не-ключевых. В flexible netflow ключевые поля конфигурируются. Records указывают на flow monitors и определяют cache/database, который хранит данные о flow.
-
Flow exporters – кому отправляем
-
Flow monitors – связываем exporters и records
-
Flow samplers
-
FLOW RECORD
flow record <record-name>
description <record-descr>
match datalink mac source address input # key field
match datalink mac destination address input
match datalink vlan input
match ipv4 ttl
match ipv4 tos
match ipv4 protocol
match ipv4 source address
match ipv4 destination address
match transport source-port
match transport destination-port
match interface input
collect transport tcp flags # non key field
collect counter
FLOW EXPORTER
flow exporter <export-name>
description <export-descrp>
destination 192.168.1.1
FLOW MONITOR
flow monitor <monitor-name>
record <record-name>
exporter <export-name>
cache timeout active 60
cache timeout inactive 60
POLICY APPLY
int gi1/1
ip flow monitor <monitor-name> input
cisco encrypted traffiC analytics (ETA), cisco cognitive threat analytics
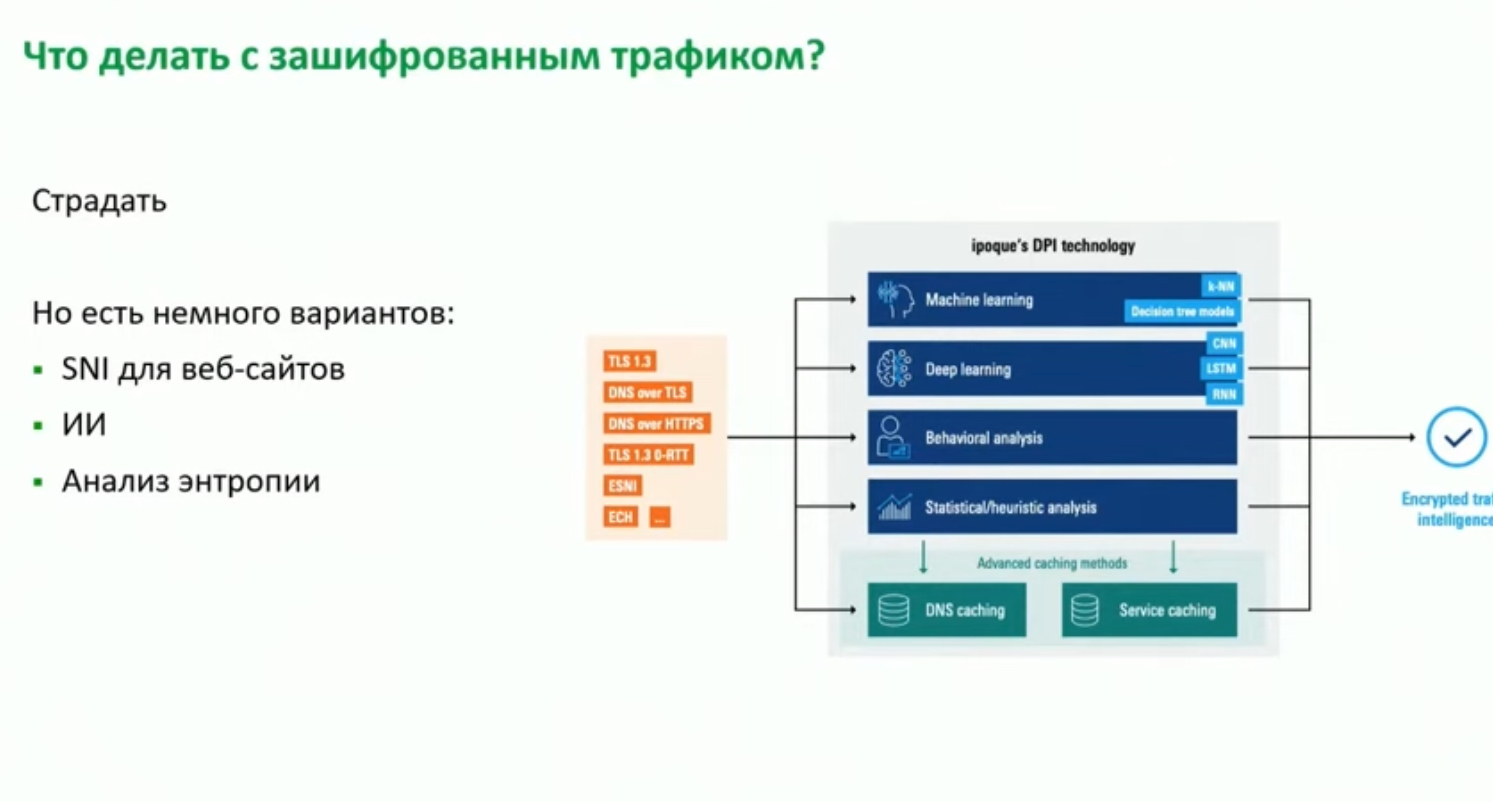
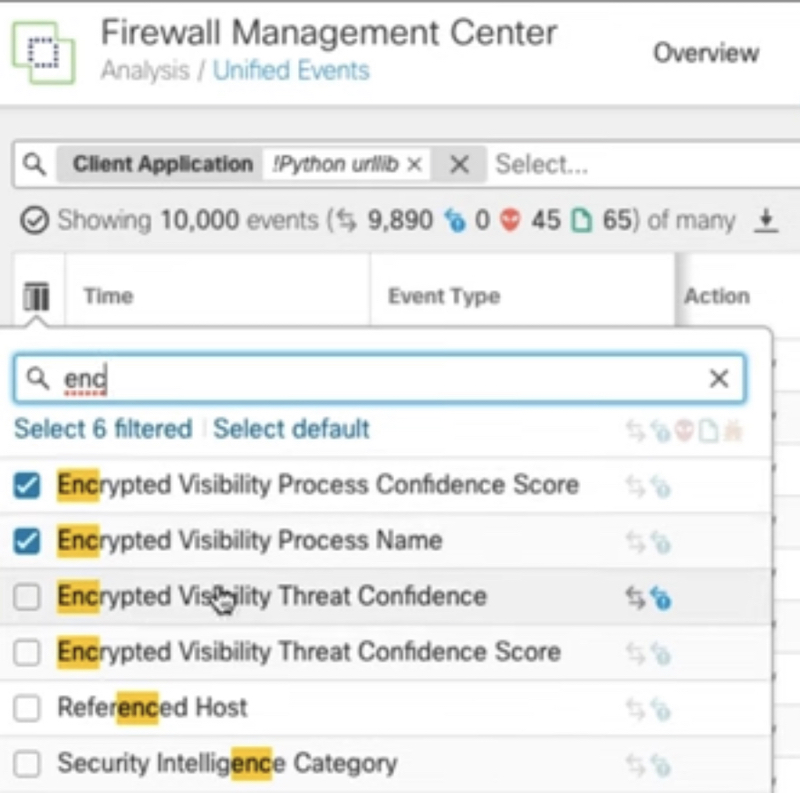
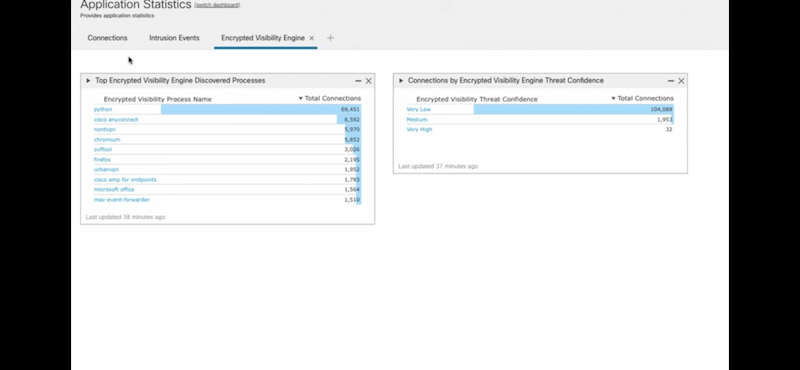
- (NGFW, NMS) Encrypted traffic analytics (ETA), Encrypted Visibility Engine (EVE) могут использоваться как для обнаружения угроз в зашифрованном трафике без расшифрования, так и распознавания приложений (159 APP в EVE – см. скриншот ACP).
- Помимо ETA обнаружение угроз в зашифрованном трафике реализуется за счет Threat Intelligence (TI) информации о IP/domain, с которыми происходит сетевое взаимодействие
-
Cisco cognitive threat analytics (CTA)
-
Cisco encrypted traffic analytics (ETA) – было безальтернативно для TLS 1.3 до добавления поддержки inspection 1.3, QUIC.
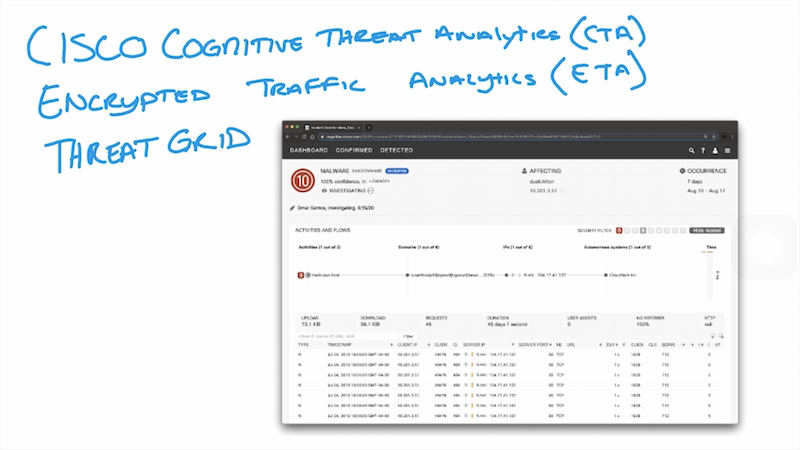 Можно комбинировать эти решения между собой – stealthwatch + CTA + ETA для реализации задачи видимости сети. При интеграции в stealthwatch dashboard появляются CTA/ETA widgets, которые можно использовать.
Можно комбинировать эти решения между собой – stealthwatch + CTA + ETA для реализации задачи видимости сети. При интеграции в stealthwatch dashboard появляются CTA/ETA widgets, которые можно использовать.
-
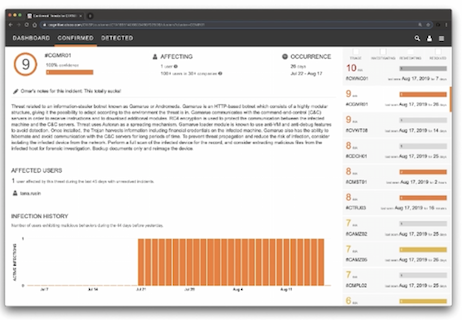
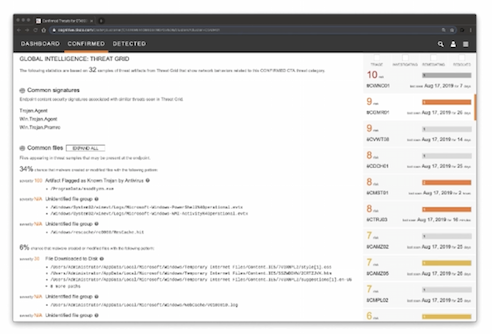
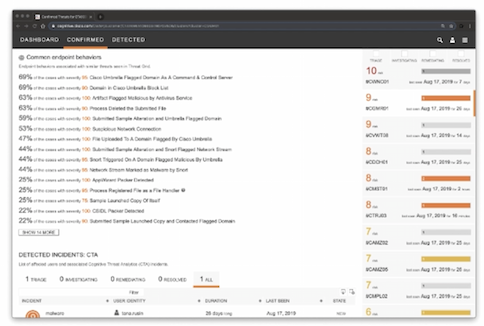
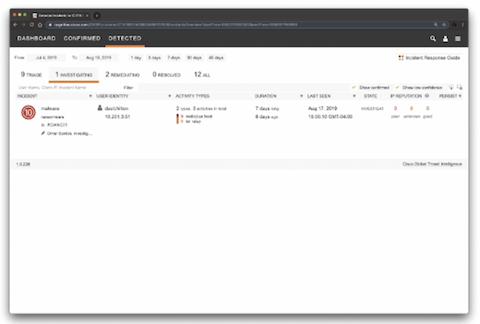
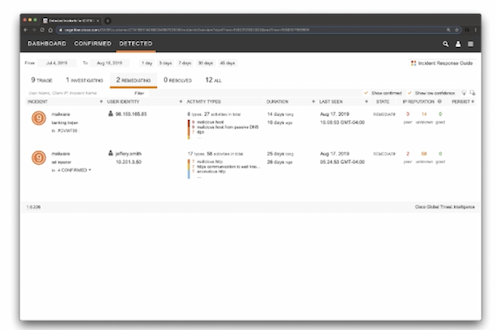
Cisco cognitive threat analytics (CTA) – cloud base решение, которое использует machine learning и статистическое моделирование сетей. CTA создает baseline трафика в вашей сети и идентифицирует аномалии. CTA так же может анализировать поведение пользователей/устройств для обнаружения CC взаимодействий и data exfiltration. CTA в dashboard stealthwatch показывает подозрительный трафик и количество/перечень затронутых пользователей/хостов с указанием уровня инцидента (есть high level incidents response guide, который описывает как CTA назначает приоритеты/уровень риска инцидентам на основе ожидаемого damage). Можно назначить человека на инцидент (в примере Omar Santos). Так же есть страница с конкретными угрозами – описание угрозы, ее severity, пользователи, которые под нее подпадают и когда угроза детектировалась в сети. Так же можно посмотреть:
-
глобальную threat grid статистику по угрозе (подобнее в threat grid)
-
статистику по инцидентам
-
-
Cisco encrypted traffic elanalytics (ETA), Encrypted Visibility Engine (EVE) – позволяет обнаружить приложения и malware в зашифрованном трафике путем пассивного мониторинга трафика без дешифрования. Извлекает из трафика служебные данные для работы (включая информацию о destination сервере). Далее эти данные накладываются на модель поведения и если модель сходится с приложением/malware при прогоне через machine learning – ETA/EVE выносит вердикт с каким то уровнем доверия (confidence score, вплоть до 100%).
And it does this by using sophisticated fingerprinting system using data from the packets sent by the client along with the information about destination server.
EVE
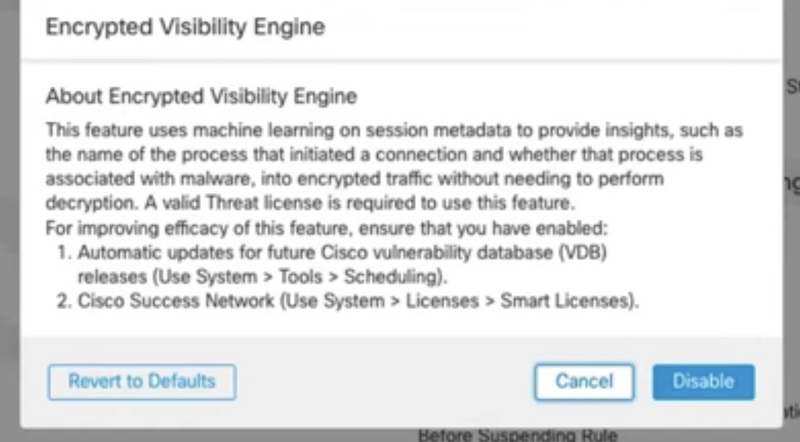
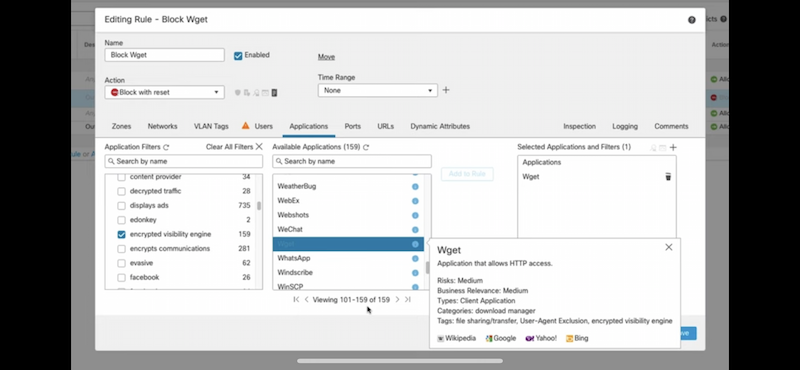

ETA
Статистический/big data анализ и machine learning судя по всему делают и в Китае для Китайского Great Firewall. В итоге DPI + анализ поведения трафика + дропы трафика (причем с уровнем рейта в зависимости от уровня доверия) если обнаружена “блокирующая” категория.
Since 2012, the GFW is able to "learn, filter and block" users based on traffic behavior, using deep packet inspection.[46] This method was originally developed for blocking VPNs and has been extended to become part of the standard filtering system of the GFW. The method works by mirroring all traffic (using a network tap) to a dedicated analytics unit, that will then deliver a score for each destination IP based on how suspicious the connection is. This score is then used to determine a packet loss rate to be implemented by routers of the Chinese firewall, resulting in a slowed connection on the client side. The method aims to slow down traffic to such an extent that the request times out on the client side, thus effectively having succeeded in blocking the service altogether.
It is believed that the analytics system is using side-channel (such as the handshake headers, and packet sizes) to estimate how suspicious a connection is.[47] It is able to detect traffic protocols (such as SSH tunneling, VPN or Tor protocols), and can measure the entropy of packets to detect encrypted-over-encrypted traffic (such as HTTPS over an SSL tunnel).
This attack may be resisted by using a pluggable transport in order to mimic 'innocent' traffic, and never connect to 'suspicious' IPs by always having the circumvention software turned on, yet not proxy unblocked content, and the software itself never directly connect to a central server.
Будущее после SNMP (yang, telegraf, influxdb, grafana, ELK stack – Elasticsearch, beats, Logstash, Kibana)
- Пример продукта, реализующего концепцию – Arista CVP, о нем ниже
- (будущее после SNMP, google malt/autorepair) google уже в 2021 на 80-90% мониторил девайсы за счет streaming telemetry, и только на тех девайсах, которые не поддерживают «классически»
- (google malt/autorepair, будущее после SNMP, ZTP, Capacity planning) Библиотека полезных статей от research Google:
Решения на базе SNMP планомерно замещались (netflow, sflow) и продолжают замещаться – pull модель с периодичностью 5-10 минут неприемлема для существующих сервисов. Новые концепции предлагают сливать данные устройствам самим (push model), без опроса с центрального сервера, причем сливаются только те данные, подписка на которые оформлена. Можно так же выбрать – сливать определенные данные периодически или при их изменении/событии (как SNMP трап/syslog).
SNMP polling can often be in the order of 5-10 minutes, CLIs are unstructured and prone to change which can often break scripts. The traditional use of the pull model, where the client requests data from the network does not scale when what you want is near real-time data. Moreover, in some use cases, there is the need to be notified only when some data changes, like interfaces status, protocol neighbors change etc.
Model-Driven Telemetry is a new approach for network monitoring in which data is streamed from network devices continuously using a push model and provides near real-time access to operational statistics. Applications can subscribe to specific data items they need, by using standard-based YANG data models over NETCONF-YANG. Cisco IOS XE streaming telemetry allows to push data off of the device to an external collector at a much higher frequency, more efficiently, as well as data on-change streaming.
In order to stream data from the device the application must set up a subscription to a data set in a YANG model. A subscription is a contract between a subscription service and a subscriber that specifies the type of data to be pushed. There are two types of subscriptions: periodic and on-change. With periodic subscription, data is streamed out to the destination at the configured interval. It continuously sends data for the lifetime of that subscription. With on-change, data is published only when a change in the data occurs such as when an interface or OSPF neighbor goes down.
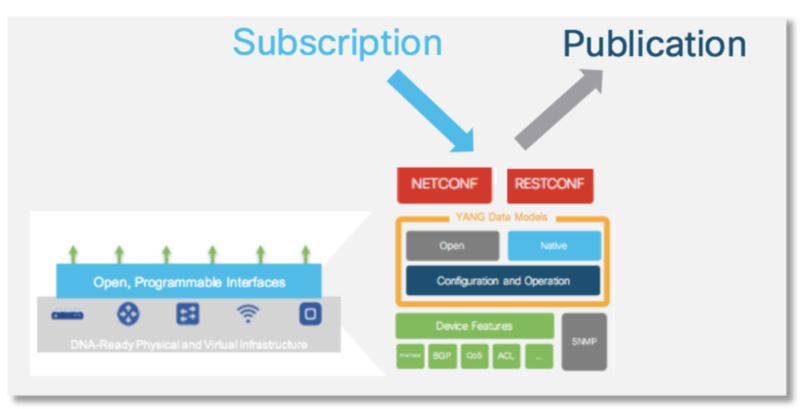
- Старый (good old) набор технологий: snmp (udp transport, snmp mib structure -> mib explorer) – rrdtool – php/perl/etc (cacti, zabbix, etc NMS)
- Пример нового набора (пример установки): grpc (tcp transport, yang structure -> yang explorer OR XML) – telegraf – influxdb – grafana. Пример так же есть ниже, еще больше примеров тут.
- Плюсы:
- более надежная доставка (TCP)
- большая частота отдачи метрик, в среднем при опросе она не такая частая
- меньшая нагрузка на сервер NMS и меньшая задержка на появление событий т.к. NMS не опрашивает/ожидает ответ, он сразу получает данные (push, а не pull модель)
- эвенты по событию (были трапы/сислог, но могли теряться/не на все настраиваться)
- Плюсы:
Subscriptions are created over existing NETCONF sessions and are created using XML RPCs. The establish-subscription RPC is sent from a client or collector to the network device. The following are the sample RPC messages with a configured periodic and on-change subscriptions and replies from the device.
The following is a sample RPC messages with a configured periodic subscription. In this example switch is subscribed to mdt-subscriptions table which has list of all the subscriptions.<rpc message-id="101" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <establish-subscription xmlns="urn:ietf:params:xml:ns:yang:ietf-event-notifications” xmlns:yp="urn:ietf:params:xml:ns:yang:ietf-yang-push"> <stream>yp:yang-push</stream> <yp:xpath-filter>/mdt-oper:mdt-oper-data/mdt-subscriptions</yp:xpath-filter> <yp:period>1000</yp:period> </establish-subscription> </rpc>

У Cisco Streaming Telemetry основан на IETF Pub/Sub стандарте и коллектором, как итог, может выступать любой поддерживающий это инструмент, например совокупность из Apache Kafka + ELK stack (вкратце ниже, подробнее в отдельных разделах):
-
- Beats – сбор данных и отправка в Elastic & Logstash
- Elasticsearch – поиск по данным, часто используется для поиска в сохраненных логах (напр. все контейнеры складывают в базу, а поверх нее elasticsearch)
- Logstash – сохранение данных
- Kibana – визуализация данных (веб интерфейс)
Cisco IOS XE Streaming Telemetry is based on the IETF Pub/Sub standard and any collector supporting this standard can be used. For instance, well known Open Source tools like the Apache Kafka messaging bus and the ELK stack (Elasticsearch, Logstash, and Kibana), can be used to build a reliable Streaming Telemetry infrastucture.
NATS
Так же может использоваться как замена SNMP.
NATS - The Cloud Native Messaging System
NATS is a simple, secure and performant communications system for digital systems, services and devices.
https://en.wikipedia.org/wiki/NATS_Messaging
https://docs.nats.io/nats-protocol/nats-protocol
https://github.com/nats-io
BMC Patrol
IBM tivoli Netcool
- (Мониторинг, devops) Как tivoli менеджер проникся puppet и практиками devops для эксплуатации


- (Listening probes) – Probes that listen on the network, for example the Probe for SNMP or the Socket Reader Probe
- (SSL termination on probes) – IBM Tivoli Netcool/OMNIbus Socket Java Probe supports Secure Sockets Layer (SSL) connections. SSL connections provide additional security when the probe retrieves alarms from the target systems.
https://www.ibm.com/docs/en/netcoolomnibus/8.1?topic=SSSHTQ_8.1.0/com.ibm.netcool_OMNIbus.doc_8.1.0/omnibus/wip/install/task/omn_pln_sizing.html https://www.ibm.com/docs/en/netcoolomnibus/8.1?topic=SSSHTQ_8.1.0/com.ibm.netcool_OMNIbus.doc_8.1.0/omnibus/wip/install/reference/omn_pln_sizingexamples.html
ARISTA CVP
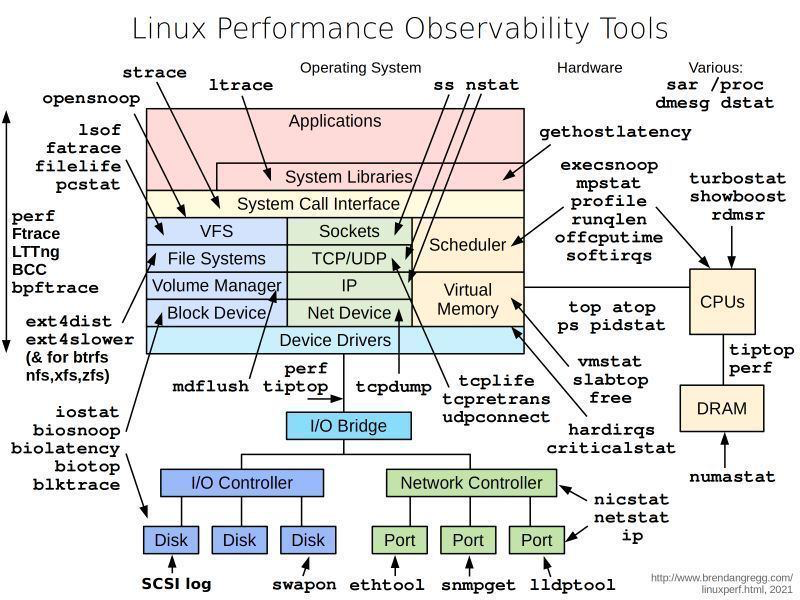
мониторинг производительности системы (sysstat)
SAR (System Activity Report) в Linux — это инструмент для мониторинга и анализа системных ресурсов. Он предоставляет подробную информацию об использовании CPU, загрузке памяти, устройствах ввода-вывода, мониторинге сети, использовании диска и другом. SAR помогает системным администраторам и разработчикам понять производительность системы, выявить узкие места и оптимизировать распределение ресурсов для повышения эффективности и стабильности.
# cat /proc/net/stat/ip_conntrack-bash-4.4# cat /proc/net/stat/ip_conntrack
entries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete search_restart
00000027 00082000 0a4c957c 00156632 000018c4 0a56dc4f 0015660b 00155d1f 00155d46 00000007 00000000 00000000 00000001 00000000 00000000 00000000 00000000
entries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete search_restart
00000027 00082000 0a4c957c 00156632 000018c4 0a56dc4f 0015660b 00155d1f 00155d46 00000007 00000000 00000000 00000001 00000000 00000000 00000000 00000000
sar -n TCP 1 5 – для отслеживания соединений в секунду (цифра 1) пять секунд (5). Active / s – исходящие TCP-соединения passive / s – входящие TCP-соединения.
# sar -n TCP 1 5
Linux 4.19.0-16-amd64 (spr) 01/10/2025 _x86_64_ (3 CPU)
10:25:03 PM active/s passive/s iseg/s oseg/s
10:25:04 PM 0.00 0.00 2.00 1.00
10:25:05 PM 0.00 0.00 6.00 7.00
10:25:06 PM 0.00 0.00 3.00 2.00
10:25:07 PM 0.00 0.00 1.00 2.00
10:25:08 PM 0.00 0.00 2.00 2.00
Average: 0.00 0.00 2.80 2.80
sar -n UDP 1 – для бесконечного отслеживания UDP пакетов (входящих/выходящих/ошибочных) в секунду (цифра 1).
# sar -n UDP 1
Linux 4.19.0-16-amd64 (spr) 01/10/2025 _x86_64_ (3 CPU)
04:14:30 PM idgm/s odgm/s noport/s idgmerr/s
04:14:31 PM 0.00 0.00 0.00 0.00
04:14:32 PM 0.00 0.00 0.00 0.00
04:14:33 PM 0.00 0.00 0.00 0.00
04:14:34 PM 0.00 0.00 0.00 0.00
04:14:35 PM 0.00 0.00 0.00 0.00
04:14:36 PM 0.00 0.00 0.00 0.00
04:14:37 PM 0.00 0.00 0.00 0.00
sar -n DEV 1 – для бесконечного просмотра пропускной способности сети (в пакетах/байтах) и утилизации интерфейса в секунду (цифра 1).
https://www.alibabacloud.com/help/en/ecs/support/query-and-case-analysis-of-linux-network-traffic-load
IFACE: the name of the network interface.
rxpck/s and txpck/s: the number of packets received or sent per second.
rxkB/s and txkB/s: the number of bytes received or sent per second, in kB/s.
rxcmp/s and txcmp/s: the number of compressed packets received or sent per second.
rxmcst/s: the number of multicast packets received per second.
# sar -n DEV 1
Linux 4.19.0-16-amd64 (spr) 01/10/2025 _x86_64_ (3 CPU)
04:16:58 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
04:16:59 PM ens34 2.00 1.00 0.12 0.16 0.00 0.00 0.00 0.00
04:16:59 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
04:16:59 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
04:17:00 PM ens34 3.00 6.00 0.18 2.16 0.00 0.00 0.00 0.00
04:17:00 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
04:17:00 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
04:17:01 PM ens34 5.00 6.00 0.29 1.52 0.00 0.00 0.00 0.00
04:17:01 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Elasticsearch
- Масштабируемый полнотекстовый поисковый и аналитический движок с открытым исходным кодом.
- Он позволяет хранить большие объемы данных, проводить среди них быстрый поиск и аналитику в режиме реального времени.
- Elasticsearch использует в качестве поисковой основы библиотеку Lucene, которая написана на языке Java и доступна для многих платформ.
- Все неструктурированные данные хранятся в формате JSON, что автоматически делает ES базой данных NoSQL.
- Но в отличие от других баз данных NoSQL, ES предоставляет возможности поиска и многие другие функции.
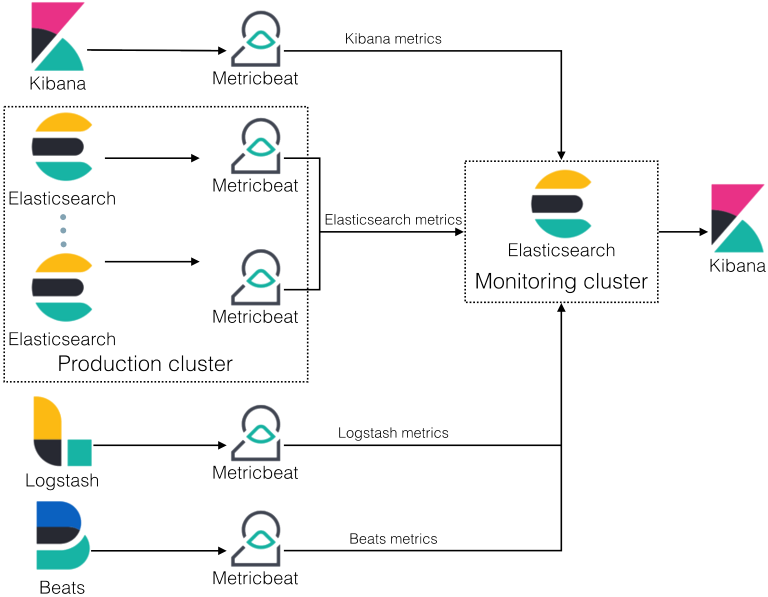
ElasticSearch Beats
Набор коллекторов данных с низкими требованиями к ресурсам, которые устанавливаются как на клиентских устройствах, так и на выделенном устройстве, для сбора системных журналов и файлов. Существуют широкий выбор коллекторов и расширений.
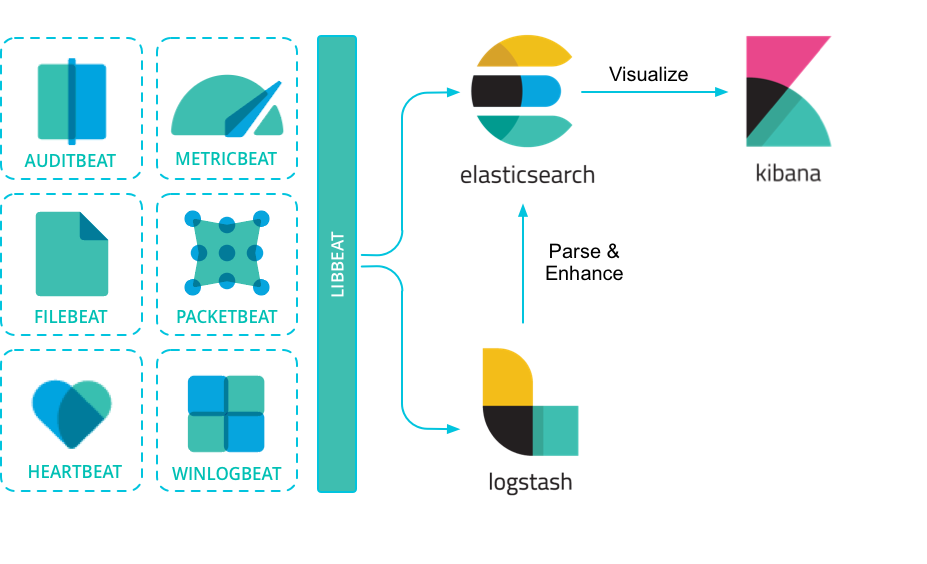
Транслирует на сервер информацию из динамических обновляемых журналов системы и файлов, содержащих текстовую информацию. Расширение CEF предназначено для получения данных CEF по syslog.
Собирает метрики операционных систем, характеризующие, например, использование CPU и памяти, количество переданных пакетов в сети, состояние системы и сервисов, запущенных на сервере.
Packetbeat
Cетевой анализатор пакетов, который отправляет информацию о сетевой активности между серверами приложений. Он перехватывает сетевой трафик, декодирует протоколы и извлекает необходимые данные.
Logstash
Logstash is part of the Elastic Stack along with Beats, Elasticsearch and Kibana.
KIBANA
Платформа для анализа и визуализации данных, предназначенная для работы с Elasticsearch. Используется для поиска, просмотра и взаимодействия с данными, хранящимися в индексах Elasticsearch. Вы можете легко выполнять расширенный анализ данных и визуализировать результаты в различных диаграммах, таблицах и картах.
goalert
Уведомление в мессенджерах/по смс с открытым кодом.
Victoriametrics / victorialogs
- victorialogs на практике очень хорош в сравнении с «конкурентами»
- VictoriaLogs - top performance
- elastic - хуже, но в целом работающий
- grafana loki - полное говно
Clickhouse - в исследовании у других был лучше victorialogs, в этом сравнении за кадром

- Считается (не единственный источник) лучше prometheus
VictoriaMetrics: fast, cost-effective monitoring solution and time series database
VictoriaMetrics is a powerful time-series database designed for high-performance monitoring and analytics. It is similar to Prometheus in many ways, but it offers several advantages, including better performance, scalability, and data compression.
prometheus
- Считается, что Prometheus не предназначен для долгосрочного хранения, для долгосрочного хранения используют напр. ELK, influxDB, Cortex, VictoriaMetrics (считается самым топом и зачастую ее используют вместо prometheus для всех задач; не единственный источник)
- Prometheus + Grafana = классический сейчас набор инструментов для сбора данных о нагрузке системы у IT-нагрузчиков.
Prometheus – open source система мониторинга, особенно прокачанная в whitebox application level мониторинге ((за счет коллекции time series данных)), а не в каком-то другом. Считается современнее influx и тем более Zabbix. В качестве конфигурации использует описание в yaml. В конфиге прописываются мониторинг хосты/таргеты/targets – т.е. Prometheus занимается пуллингом/pull хостов, которые мониторятся и забирает метрики. Так же у него Prometheus есть своего рода модули (exporters), которые значительно расширяют его функционал (они даже устанавливаются независимо от prometheus).
The Prometheus monitoring system and time series database.
Prometheus is a systems and service monitoring system. It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts when specified conditions are observed.
К примеру:
-
- AlertManager – заведует отправкой Alert по разным каналам (почты/пуши/смс/звонки), следит за состоянием алерта (напр. может в случае закрытия алерта так же отослать оповещение)
- Exporter отдают данные в prometheus формате prometheus, это может быть даже bash скрипт, конвертирующий данные в необходимый формат и передающий в prometheus. По сути это сервисы, которые представляют из себя прослойку между приложениями/системами, которые сами не умеют/не настроены отдавать метрики в prometheus. Лучше безусловно из самого приложения отдавать, но в жизни экспортеры востребованы.
- Node Exporter (Linux) или WMI (Windows) – по сбору системной информации с хоста.
- BlackBox Exporter – может генерировать HTTP и другие probe запросы.
blackbox_exporter -config.file=blackbox.yml
blackbox.yml
modules:
http_2xx:
prober: http
timeout: 5s
http:
valid_http_version: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: [] # defaults to 2xx
method: GET
headers:
Host: localhost:2345
Accept-Lenguage: en-US
- push gateway собирает метрики, а prometheus забирает с него как с обычных экспортеров/exporter; по сути это промежуточный relay (аля костыль) встраиваемый при необходимости между prometheus и хостами. Нужен по сути когда нельзя поднять сервис, отдающий в prometheus данные используя pull, но на которых можно поднять какой то скрипт, периодически сами/используя push отдающие на push gateway данные, а prometheus используя pull забирает с gateway метрики. Напр. на гипервизоре максимум можно поднять скрипт, оправшивающий состояние RAID массива и отдающий в push gateway данные.
Централизованный сервер собирает данные от программ (например, jobs от prometheus client в программе) и своих внешних модулей (типа blackbox exporter) и сохраняет их в базе вместе со временем их прихода. Информация из этой базы метрик уже используется для визуализации и генерации alarm.
Для установки prometheus может разворачиваться через компиляцию кода или из предварительно собранного image build в виде реализации prometheus в Docker.
Стандартный сценарий развертывания предполагает использование отдельного prometheus сервера, alert manager’а и exporter’ов.
Пример сбора данных о cpu хоста и диске и еще о ряде данных узла: node_exporter
Prometheus узнает о данных, которые ему нужно забирать и сохранять с targets и из конфига prometheus.yml. Пример конфига
scrape_configs:
- job_name: "node"
scrape_interval: "15s"
static_configs:
- targets:
- "localhost:9100"
Запускаем сервер:
sudo prometheus -config.file=prometheus.yml
Графики из систем мониторинга могут быть представлены специальными утилитами datadog, graphic primer, grafana (очень крутой инструмент представления данных в графики, понимает метрики, собираемые prometheus).
Prometheus может забирать данные не только сам (напр. из prometheus node exporter), но из разных мест, например из collectd демона, который берет данные из системы (по утилизации и hardware информации).
Метрики.
Чаще всего представляют собой численные данные о каком-то параметре системы (количество запросов, текущая утилизация, количество ошибок).
Из-за своей математической сущности к метрикам зачастую можно применять математические функции:
- по агрегации (по времени, по географии, по объекту)
- по группировке (напр. запросы менее 20мс – первая группа, менее 100мс – вторая)
- по выделению средних или крайних значений
- по статистике и выявлению закономерностей
Примеры типов метрик:
- Счетчики (counters) – накопительная метрика; самая частая метрика, мат. величина (int/float), которая только увеличивается (количество ошибок, запросов, трафика). Обычно очень полезна только в сопоставлении со временем (за какое время увеличился счетчик и т.д.).; метрика не поддерживается gateway (как понимаю pushgateway)
- Состояние (gauges) – результат измерения может как прибавляться, так и убавляться, напр. текущая загрузка CPU, текущая скорость чтения
- Распределение (distributions или histograms, языком prometheus; есть еще тип summary с похожим принципом работы, но он занимает больше места) – распределение/группировка данных по какому то правилу (напр. запросы менее 20мс – первая группа, менее 100мс – вторая). Очень хорошая метрика для индикаторов типа – время ответа, задержки, размеры файлов. Часто используется для задачи индикации response time в рамках разных групп:
- <200 мс = кол-во
- 200-500мс = кол-во
- 500-1000мс = кол-во
- >1000мс = кол-во
- Отклонение (standard deviation, отклонение от какого-то значения), Медиана (Median),
- Cреднее значение (Mean) – не так часто встречаются, но тоже бывают.
Уровень – тип метрики:
- уровень сети
– загрузка линков
– потери
– ошибки - уровень хоста
– загрузка CPU
– загрузка памяти
– количество процессов
– скорость записи на диск
– скорость чтения с диска - уровень приложения
Такие данные отправляются на систему мониторинга. Очень часто для сбора и отправки используются библиотеки систем мониторинга, а не полное написание взаимодействия между кодом и системой мониторинга. Зачастую специфичны для самих приложений, но есть общие:
- задержка (время отработки), причем как успешных отработок, так и неуспешных
- нагрузка приложения (количество одновременных запросов, количество одновременных сессий)
- количество и тип ошибок (зависит от типа приложения)
Пример включения и работы клиента по взаимодействию с централизованной системой мониторинга на основе gem prometheus-client.
Записываем время отработки http запросов в систему мониторинга. Система мониторинга уже записывает эти данные для визуализации и/или алармов.
require 'prometheus/client'
histogram = Prometheus::Client::Histogram.new(...)
# Serve an HTTP request, and record the latency.
def serve_http(request)
start = Time.now
handle(request) # process the request
stop = Time.now
elapsed_time = start - stop
histogram.observe(elapsed_time)
end
Alert – сгенерированное машиной уведомление о проблеме. Обычно правила по оповещения сохраняются каждое в отдельном файле и за этими файлами следит VCS. Очень важно Alert делать на непосредственные причины тех или иных событий, а не последствия или симптомы.
Мониториг, как тестирование, разделяется на Whitebox и blackbox мониторинг.
-
- Whitebox – анализ внутренности систем (ОС или приложений), позволяет залезть внутри системы и оценить конкретные характеристики внутри. Примеры: количество запросов, утилизация, количество connect.
- Blackbox – оценивает систему с точки зрения конечного потребителя, не заглядывая во внутренности системы. Примеры: эмуляция действий пользователя через prober и оценка результата (открытие страницы, submit, logging, переключение канала, etc).
Слишком много алертов так же плохо, как слишком мало. Нужно приоритизировать Alert. Кроме того слишком частый сбор данных может приводить к проблемам с сервисом, тут нужно быть аккуратным.
Стандартные параметры при создании Alert:
- условия alerts (expression)
- порог срабатывания (threshold) во времени или в количестве неуспешных запросов (как три потери пинга перед отправкой смс)
- длительность (duration) – как долго alert должен быть активен (в течении 20 минут)
- уровень (severity – page, ticket, email, etc – page это самый высокий уровень аля смс/push нотификация ответственному)
The process by which alerts fall out of sync with the systems they alert upon without regular updating is known by which of the following terms?
bit-rot
Although the physical bits don't rot, this term represents configuration that's no longer relevant to the current reality of the infrastructure it's supposed to configure.
Пример Prometheus Alert – сгенерировать paging событие (событие самого высокого приоритета) с указанным текстом если на хост-магине осталось меньше 500мб на основе файла alert.rules (можно указать другое название в конфиге .yml через секцию rule_files и перезагрузить сервер для применения конфига). Prometheus Server отдает alert AlertManager’у, который может группировать похожие события, принимает решение отправлять или нет нотификации, что это за нотификации и кому отправлять. В файле конфигурации AlertManager можно группировать группы по типам событий и отправлять определенные события определенной группе (database, network, manager, etc). AlertManager является отдельным приложением, нуждается в отдельном конфиге и запускается подобно prometheus – alertmanager -config.file=arlertmanager.yml. После запуска нужно перезапустить prometheus с указанием URL alertmanager.
# Alert for any node that has low memory for more than 30 minutes
ALERT LowNodeMemory
IF node_memory_available < 500000000
FOR 30m
LABELS { severity = "page" }
ANNOTATIONS {
summary = "Node is running out of RAM"
description = "The node has had less than 500MB of memory for more than 30 minutes"
}
XDR
- На западе с 2020 XDR (NDR, EDR) + NGFW вместо NTA. Основная разница в наличии реагирования (Response) через интеграцию с другими средствами.
- Сейчас задача как можно быстрее узнать, что злоумышленник уже в сети. Для этого нужны хорошие поведенческие алгоритмы и профилирование сотрудников. Поэтому сейчас рулят NDR, EDR и XDR. В связке с SOAR, TI и OSINT.
Extended Detection and Response – Связывает события и контекст из разных инструментов ИБ. Верифицирует факты атак, выявляет причины заражения или компрометации, отсеивает ложные срабатывания. Сокращает время устранения угрозы: дает необходимые данные для реагирования и расследования, автоматизирует реагирование, снижает требования к квалификации специалистов и их количеству.
Популярные продукты:
-
- Palo Alto Cortex DR
- Qualys EDR
- Checkpoint Harmony Endpoint
- Fortinet FortiXDR
- Sangfor XDDR
- McAfee MVISION DR
- SentinelOne EDR
- VMware Carbon Black EDR
- CrowdStrike Falcon Insight EDR
- Cisco AMP for Endpoints
- Trend Micro Vision One XDR
- Percept XDR
- Symantec EDR
SIEM
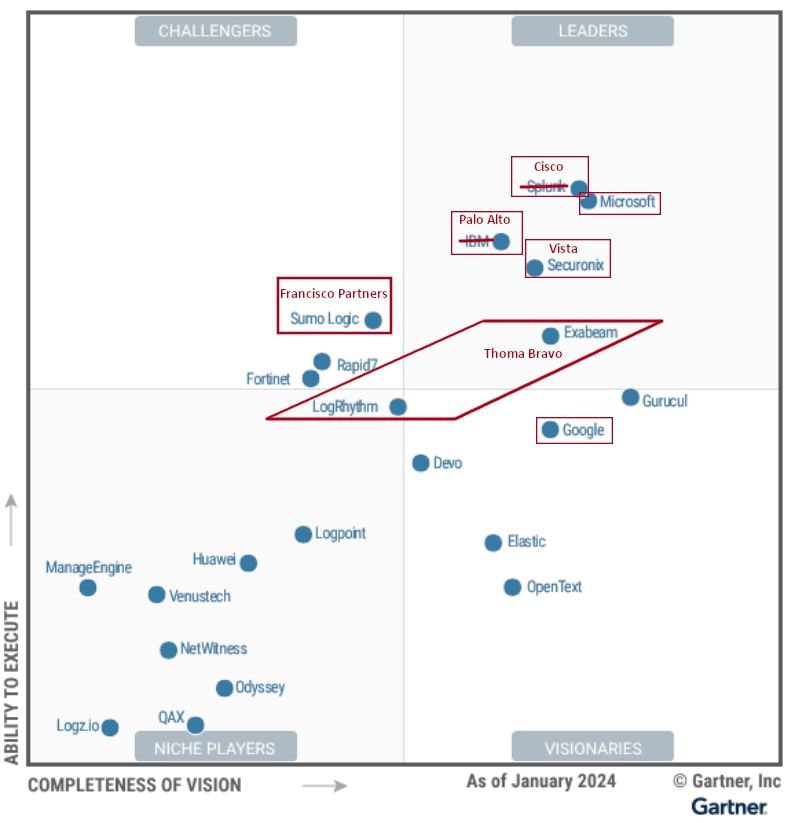
-
На рынке SIEM идут покупки лидеров лидерами. Краткие итоги. 🔥
💥 Cisco купила Splunk
💪 Palo Alto Networks купила QRadar у IBM
⭐️ Vista Equity Partners купили Securonix за 1 миллиард долларов
☀️ Francisco Partners купили Sumo Logic за 1.7 миллиарда долларов
😇 Thoma Bravo собрала вместе Exabeam и LogRhythm, останется только название Exabeam
Siem – системы выявления инцидентов
Топовые:
-
- IBM QRadar SIEM
- Micro Focus ArcSight ESM
- Splunk Enterprise
- FortiSIEM
- McAfee ESM
- Exabeam Fusion
- LogRhythm NextGen SIEM Platform
- Securonix Next-Gen SIEM
- Elastic (ELK) Stack
РФ:
-
- свои системы у СБЕР, Яндекс, VK
- PT SIEM MaxPatrol
- Kaspersky KUMA ((ответ зажравшимся PT; по слухам используют мегафон/мтс/солар))
-
сама KATA это просто IDS (суриката) + АВЗ для анализа сетевого трафика, +прослойка для передачи файлов в песок из прокси и почтового релея всего за 11 лямов или дороже… Но комплект правил для сурикаты весьма неплох…
- Большая часть всех SIEM систем работает поверх clickhouse
- Производительность SIEM чаще всего измеряется в RPS. Производительность обычно имеет предел в тысячах-десятках тысяч RPS (до 100к). Есть производительность лог-коллектора, а есть коррелятора (ниже).
MaxPatrol
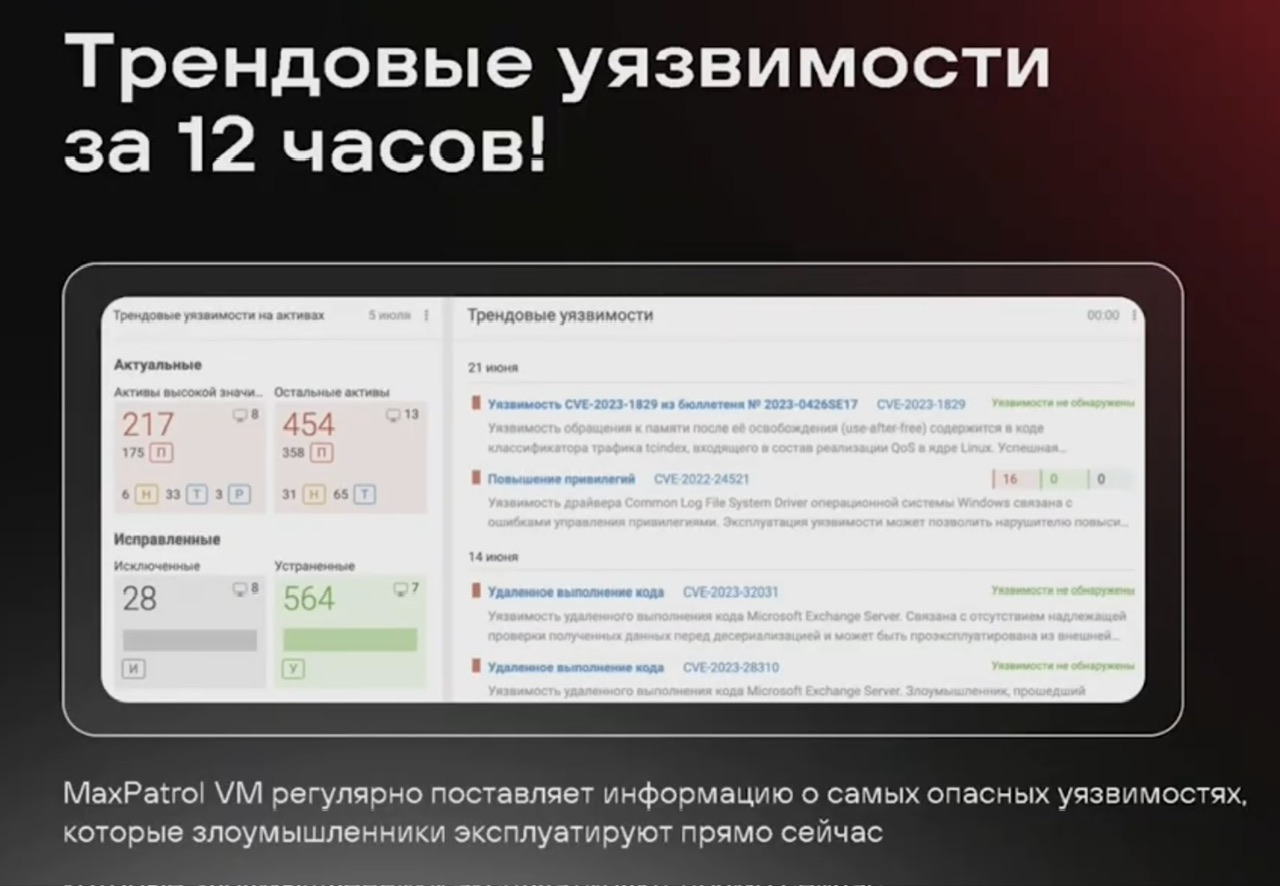
NTA, NAD
- Я вот решил посмотреть зарубежные материалы ((по NTA)), основной поток был в 2019, остатки в 2020. Есть подозрение, что NTA тогда примерно и убрали в ящик, а мы с ним носимся потому что он работать не мешает, а главный принцип по выбору импортозамещения – чтобы работать не мешало.
- На западе с 2020 XDR (NDR, EDR) + NGFW вместо NTA. Основная разница в наличии реагирования (Response) через интеграцию с другими средствами.
NTA
Система глубокого анализа сетевого трафика
Популярные продукты:
-
- Opensource: Arkime + suricata
- Cisco Stealthwatch
- Trendmicro Deep Discovery
- Darktrace Enterprise Immune System
- Plixer Scrutinizer
- Flowmon
- Vectra Al
- Awake Security Platform
- IBM Qradar Incident Forensics
- RSA NetWitness Network
- ExtraHop Reveal(x)
- Palo Alto Cortex XDR
- (NTA/Netflow/sflow) в своих продуктах Cisco делали как то хранение полной копии, но в итоге отказались от этого (вебинар ГАРДА)
- сомнительное сравнение, больше для инфы как pt пытается впарить продукты 🙂
Snort supports decoding of many tunneling protocols, including GRE, PPTP over GRE, MPLS, IP in IP, and ERSPAN, all of which are enabled by default.
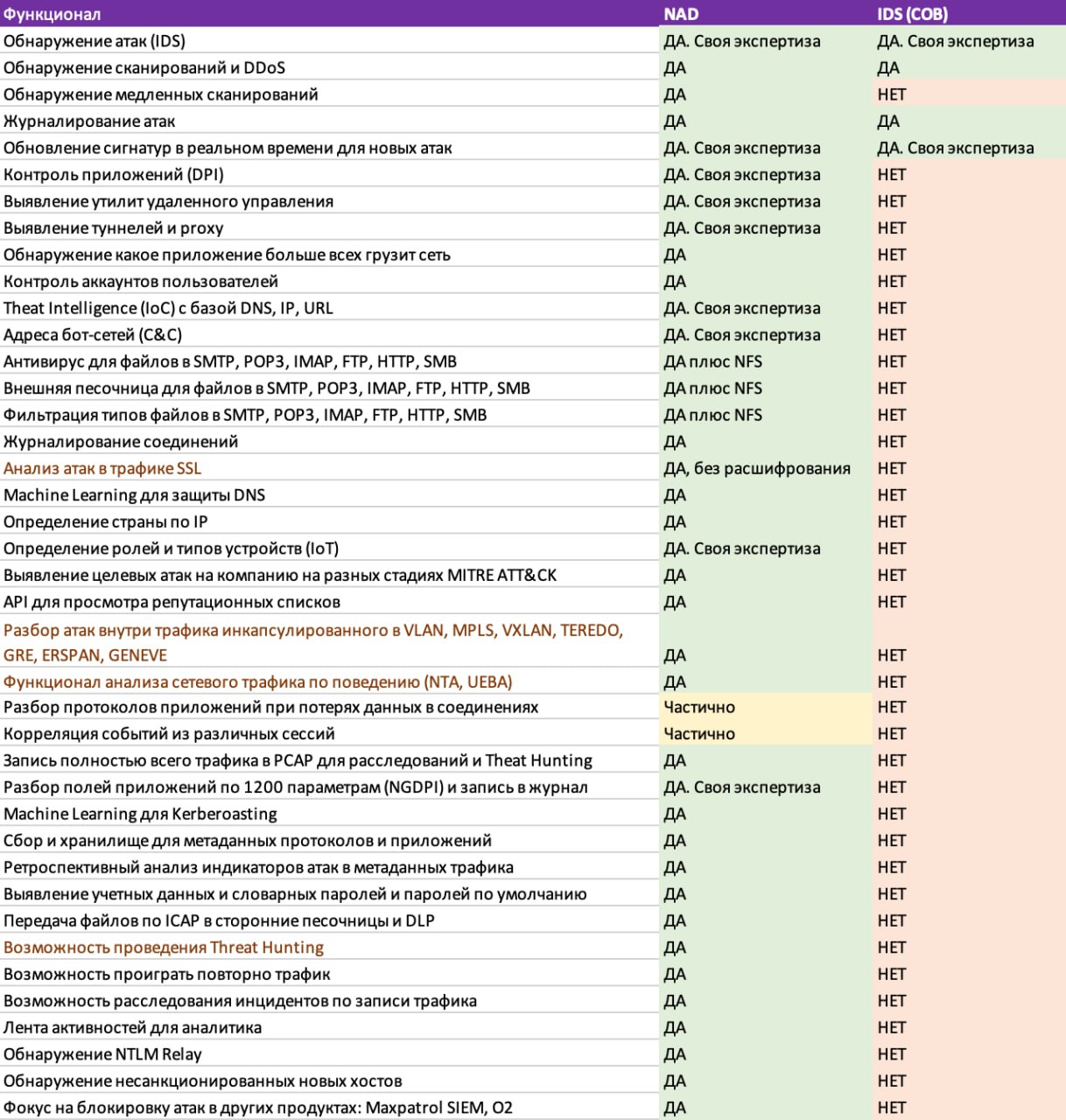
- (PT NGFW, PT NTA/PT NAD) В основе PT NAD suricata, в PT NGFW движок настолько переделан, что называют уже своим, но на входе он получает сигнатуры suricata; хотя приницип по сути остался тот же и основа hyperscan тоже. Из существенного:
- При миграции правил из PT NAD в NGFW часть правил пришлось доработать в контексте их срабатывания еще до прохождения атаки.
- Добавили возможность включения на разных правилах IPS, в разных VRF/virtual context, с разным профилем.
- Синхронизация сессий между нодами в кластере.
-
Screenshot 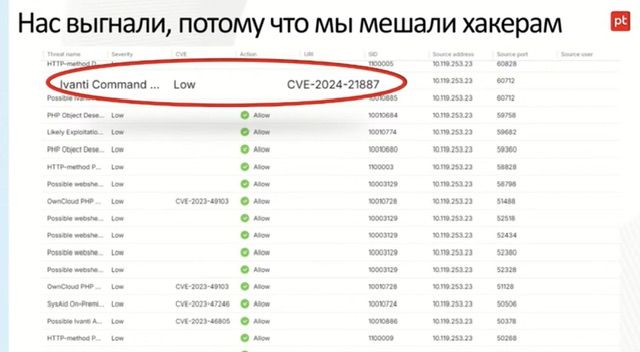
Screenshot 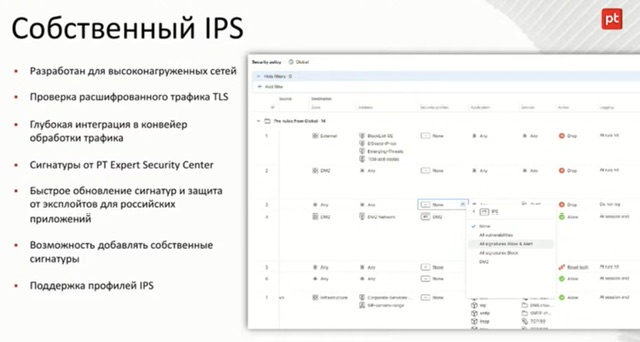
Screenshot 
Screenshot 
Screenshot
- Мое саммари – чистый nta 2.0/pt nta показался так себе историей, дорого и узко, а вот возможное комбо netflow+копия интересно; примерно аналогичное пишут и заказчики
а почему netflow плохо использовать ?
если это вопрос ИБ, фигануть его в отдельном сегменте делов то.
в случае если нетфлоу собирается туда же куда приходят логи с фаера и с едр и все это парсится и коррелируется это же прекрасно. И в таком случае даже что то типа NAD особо и не надо будет
- Решение ids может не сильно уступать по детект-рейту
Я думаю конечно с этим можно поспорить
Учти что он сранивает совсем тупое решение на базе netflow, а не ids на базе snort. B ids наверняка можно написать сигнатуры, которые все это или как минимум большую часть задетектят, но иметь копию трафика может быть полезно и в IDS.
Да и чуваку вроде РТ не занесли денег, по крайней мере так сказал, хотя и реклама по сути их решения идет
Так что правда думаю где то по середине, но видео полезное
NTA – аналитика сетевого трафика, важнейший поставщик информации о трафике.
По подкасту выше NTA в основном занимает место внутри сегмента заказчика/сеть внутри ЦОД, а не на периметре, как NGFW. Ставить везде NGFW может быть дорого, так же плюс NTA в отсутствии требования к серьезной отказоустойчивости/задержке/потерям решения (не inline, что позволяет использовать в сверх-критичных сегментах, недопускающих вмешательство в трафик), возможности длительной обработки трафика (сложные атаки), ретроспективный анализ.
NTA - относительно новый класс решений сетевой безопасности, уверенно занимающий место в корпоративных сетях - Не весь трафик проходит и регистрируется на NGFW (мягко говоря); - Внутренний злоумышленник не спит - Для расследований инцидентов нужна фактура - Регуляторы ИБ и отраслевые стандарты ИБ нужно соблюдать (сегодня, а не завтра)
Говоря про сегменты, в которых наиболее часто применяются NTA, выделяют три ключевых – АСУ ТП, IoT, legacy. 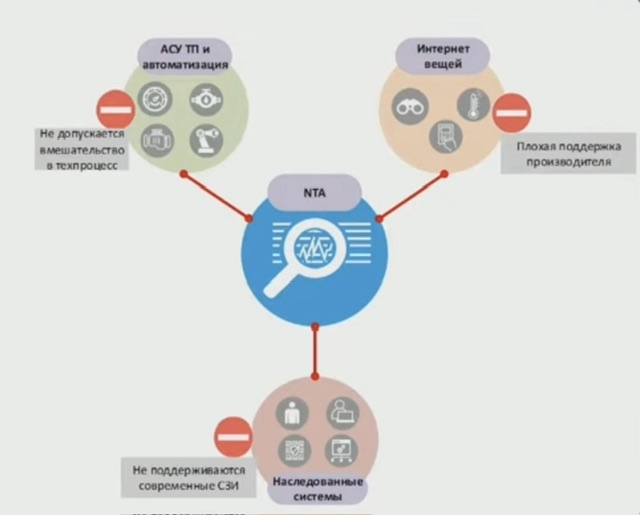
Есть места в сети где NTA - единственное средство безопасности - Legacy - там где устаревшие ОС и ПО - IOT - там где требования ИБ не выполняются на стадии проектирования устройств - АСУ ТП и промышленная автоматизация - там где сложно использовать средства ИБ
При этом автор видео непоследователен говоря про современный NTA 2.0 сам говорит:
-
- что трафик между сегментами (east-west) они NTA не собирают, т.к. это проблематично (явно очень дорого получается :D) Но другие аргументы за решение NTA действительно имеют смысл быть.
- по сути система копирования строит отдельный контур сети (называют это подсистема внеполосного снятия копии трафика) от текущей, стоить это не может дешево как с точки зрения разовых расходов, так и с точки зрения постоянных
Но спикер это и сам признает и считает (соглашаюсь) ответ в слиянии подхода производительного в виде netflow (для внутренних сегментов, east-west, горизонтального трафика) и детализированного в виде копии трафика (для внешнего трафика north-south, вертикального трафика).

Для себя коллеги различают две вехи развития NTA: NTA 1.0 на базе netflow и NTA 2.0 на базе копии трафика.
Достаточно субъективное сравнение, безусловно ряд пунктов спорный, но люди делали исходя из своего опыта/знаний.


NTA 1.0 (Cisco Stealthwatch) 2017-2018 на базе Netflow (с всеми плюсами и минусами этого подхода)
-
- + без существенных объемов фактического трафика т.к. фактический трафик представляется в виде агрегированных потоков, поэтому (и из-за аппаратной реализации netflow у ряда вендоров) производительно
- – недостаточно детализированно
NTA 1.0 - как мы выбирали решение
В 2017-2019 году мы проводили сравнительный анализ и пилотирование нескольких основных решений NTA и выбрали лучший вариант:
Принцип действия
- анализ Netflow (v5, v9);
- Наличие TI сервиса вендора
- Интеграция с системой ААА - возможность сопоставить сетевые сессии с пользователями
- Выявление некоторых типов атак в SSL/TLS ((ETA на основе адресов/статистики))
NTA 1.0 помогла решить следующие проблемы ((по сути плюсы использования netflow))
- Использование приложений, запрещенных политикой безопасности
- DDoS атаки на периметр и внутренние сканирования
- Неучтенные хосты и сервисы, о которых давно забыли (shadow IT)
- Потенциальные каналы утечки информации
При эксплуатации выяснились «узкие» места NTA 1.0 ((по сути узкие места netflow))
- Некоторые типы атак не регистрируются - в Netflow недостаточно информации
- Netflow недостаточно стандартизован - оборудование требует оптимизации конфигураций (приходилось допиливать конфиги/оборудование даже для части девайсов того вендора, который использовался для NTA решения - явно Cisco)
- Высоконагруженное оборудование может не отдавать весь объем телеметрии
- Сервисы ТІ перестали быть доверенными ((СВО)
NTA 1.0- Архитектура NTA 1.0 включает в себя:
- Коллекторы Netflow - сбор телеметрии с разных устройств
- БД коллекторов - долговременное хранение телеметрии ((особенно важны при расследованиях для сбора доказательств))
- Консоль управления - ведение статистики, выявление атак ((мозг/визуализация системы и интеграция между всеми компонентами, включая ААА для обогощения идентификаторами юзеров/устройств в данные и проч))
- Разное сетевое оборудование - поставщик Netflow ((любые сетевые девайсы))4 коллектора обеспечили отказо/катастрофоустойчивость - Телеметрия для сессий между зонами безопасности регистрируется минимум дважды
- Дедупликация обеспечивает отсутствие искажений данных
NTA 2.0 (PT NTA) современный
- – фактического трафика стало значительно больше, решение более дорогое и медленное в пересчете на количество трафика заказчика
- + большая детализация/выявление большего количества атак/событий
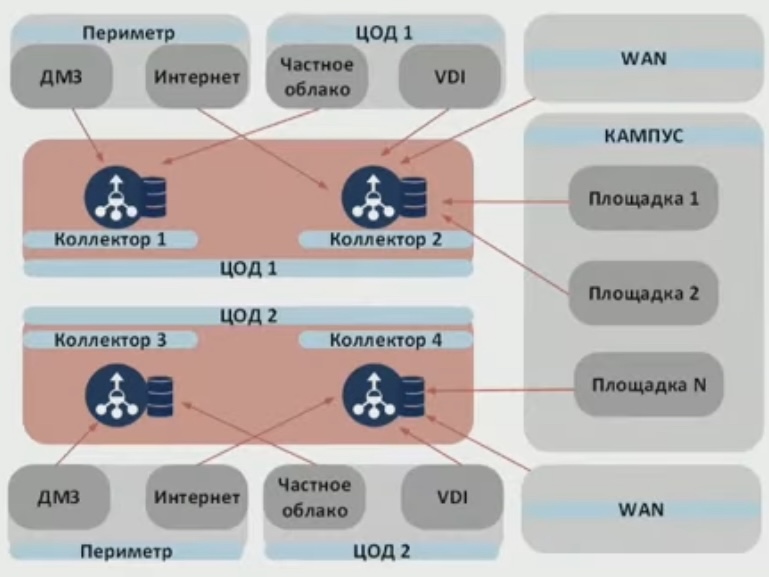
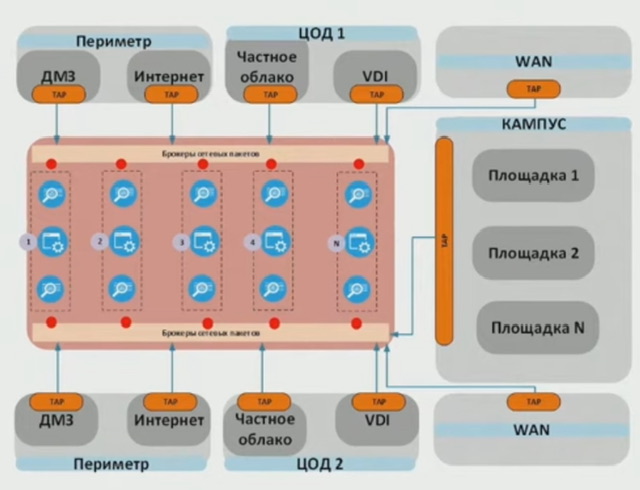
на базе съема копии всего трафика посредством использования брокера сетевых пакетов плюс TAP медные-оптические (SPAN не используют с аргументами о возможном влиянии на трафик прода/отсутствием дедупликации/разными ЗО – ИТ и ИБ) и отправки этого трафика на сенсор NTA решения (хранение обычно от нескольких дней до пары недель в зависимости от кол-ва дисков/кол-ва трафика; производительность сенсора обычно до 20 gbps, до 80TB HDD в топовом сенсоре 2RU); брокер занимается дедупликацией потоков + копированием трафика на разные системы анализа/сбора.
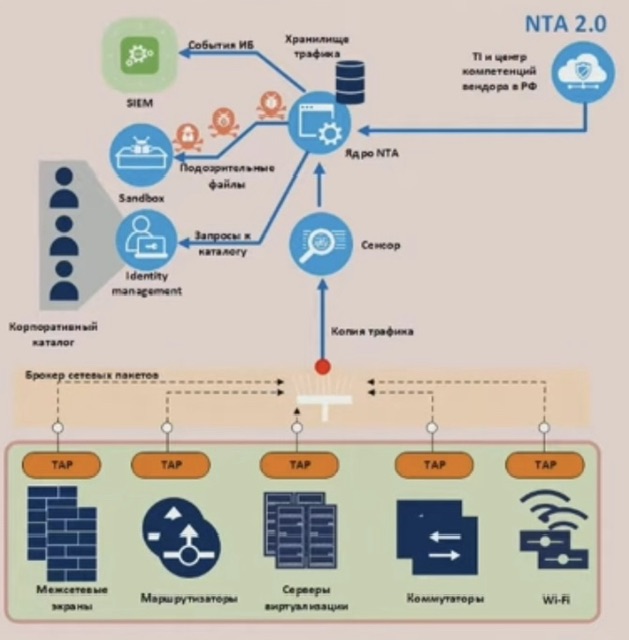
NTA 2.0- Архитектура NTA 2.0 включает в себя: - Сенсоры, прием, обработка и хранение копии трафика - Консоль управления/Ядро системы ((мозг)) - выявление атак, вредоносного ПО, интеграция с другими системами; создание из копии трафика индексов, которые хранятся долго и доступны для ретроспективного анализа (включая выгрузку атаки в виде pcap) - База данных индексированного трафика - долговременное (десятки дней) хранение для ретроспективного анализа ((elasticsearch) - Подсистема снятия копии трафика - крупная инсталляция включает в себя подсистему снятия копии трафика: * ТАР - медный или оптический внеполосный ответвитель; * Брокер сетевых пакетов - устройство обработки копии трафика; * Брокер передает трафик на сенсор, обрабатывающий до 20 Гбит/с трафика.
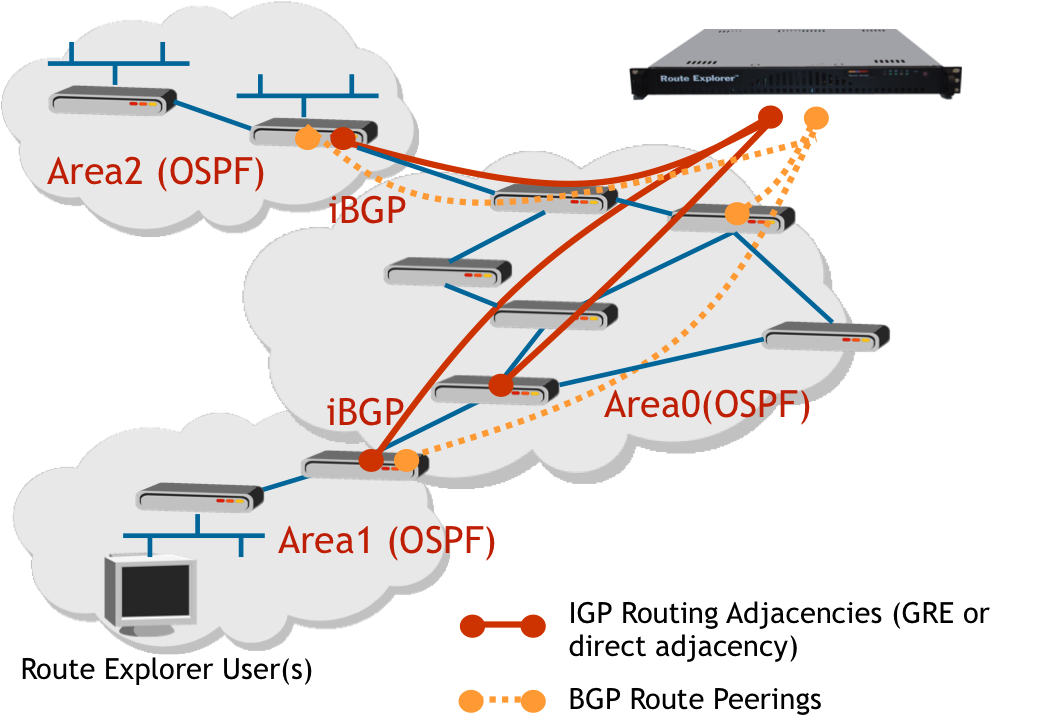
BGP BMP

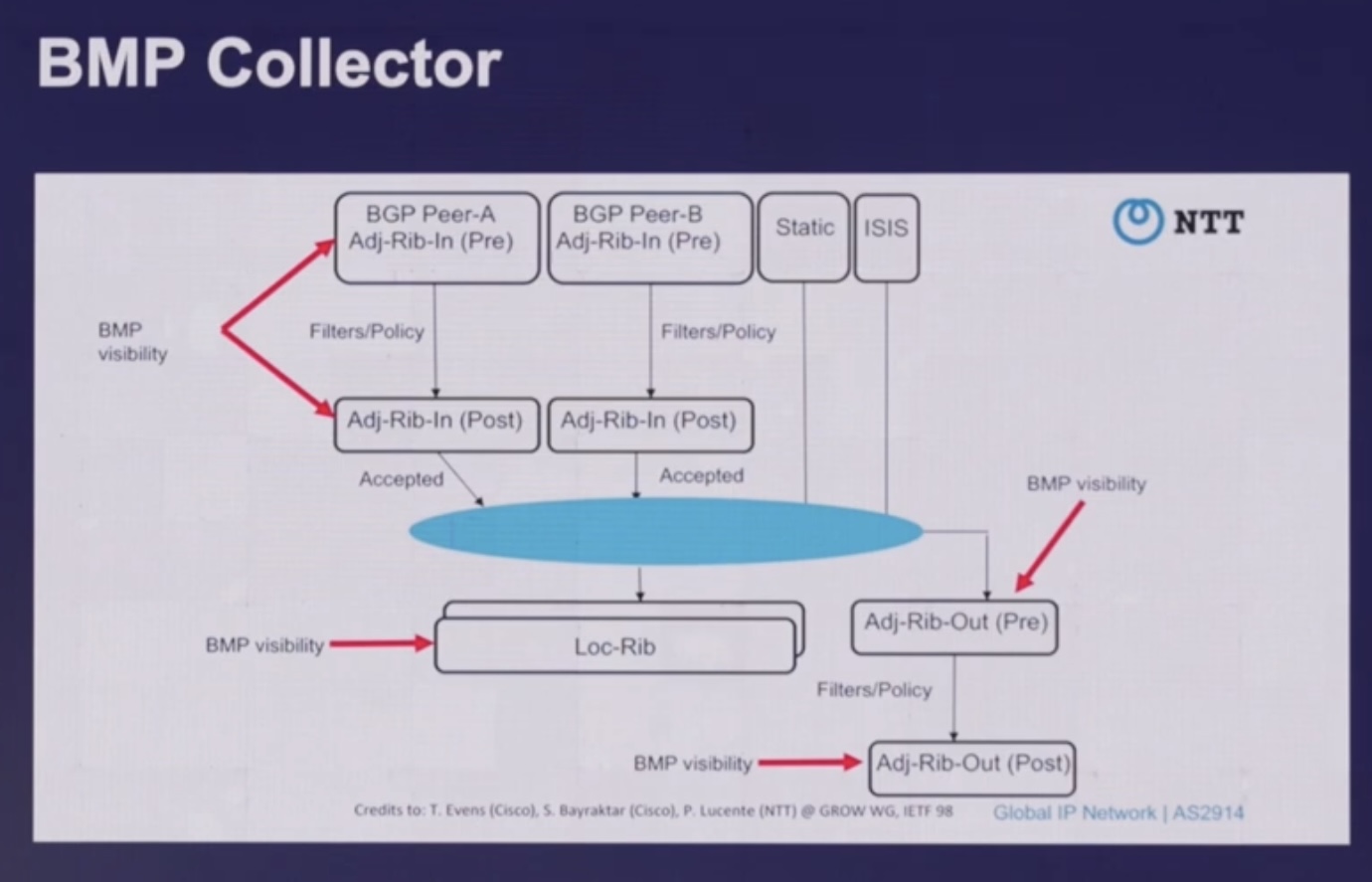

Инфа на основе презы мониторинга VXLAN/EVPN фабрики на базе BMP , подробнее про BMP в мониторинге, про OZON в big tech.
- В провайдерах используют BMP для мониторинга IPv4/IPv6 связности
- Классическая схема похожа на работу BGP с BGP сессией
- у оборудования с коллектором поднимается BMP сессия (поверх TCP) с настройкой передачи информации о маршрутных обновления в коллектор
- коллектор принимает эти апдейты и разбирает их в файл/базу
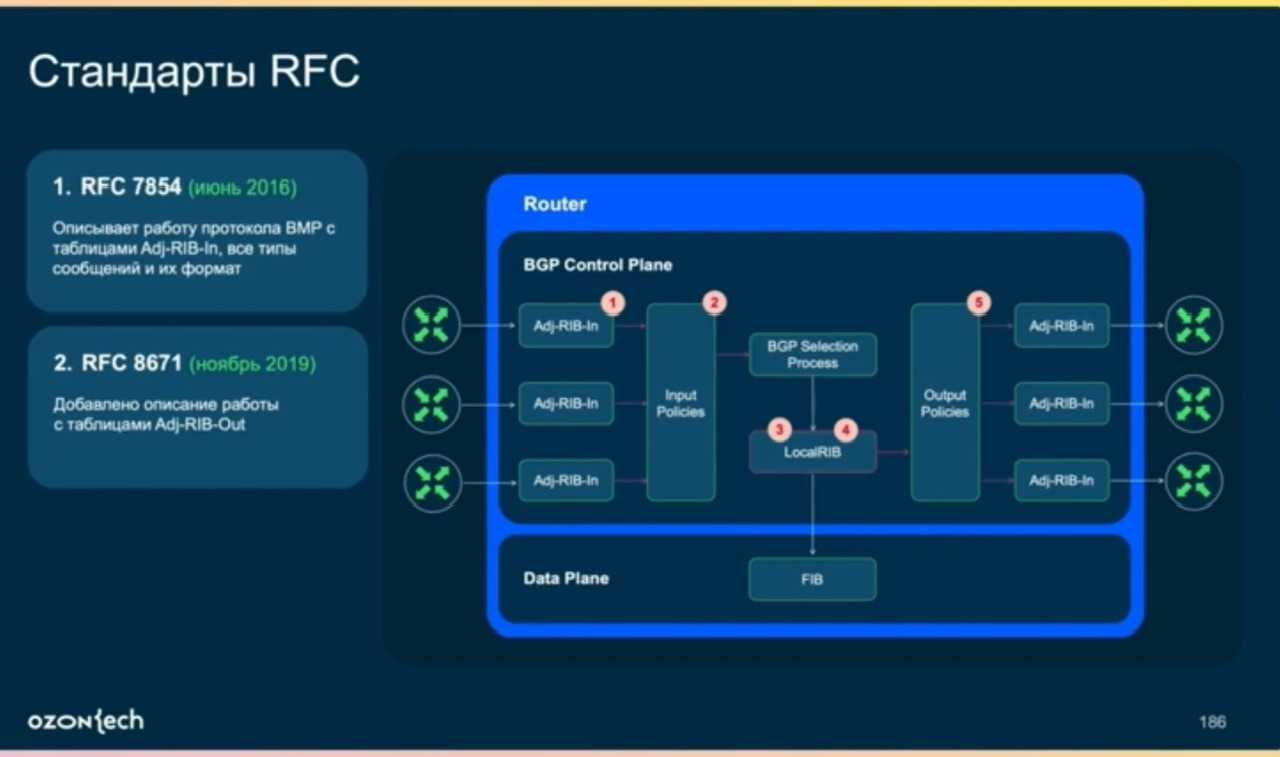
- В целом BMP протокол достаточно свежий (первый RFC 7854 от 2016, с local RIB RFC 9069 от 2022!),
- из-за этого на “железном” оборудовании куча разнообразных багов
- к примеру бордеры BGP (на них стыки с провайдерами) отсылали по 4 млн (4 full view) обновлений каждые 30 секунд
- в итоге они поднимаются BMP сессию с FRR (у которых EVPN сессия с LEAF девайсами) – схема ниже
- но он нужный т.к. с точки зрения концепции намного лучше подходит для мониторинга BGP, чем альтернативные решения (подробнее сравнение ниже)
- Работает по модели push
- Отправляется только DIFF инфы
- Не затрагивает продовый трафик (более безопасен)
- BGP девайс отправляет на BMP коллектор информацию по BGP update по каждому пиру/каждой BGP сессии, сам же коллектор ничего не отправляет на BGP девайс
- Меньше загружает потенциально оборудование (в сравнении с SNMP)
- из-за этого на “железном” оборудовании куча разнообразных багов
Кейсы, полезные для сохранения истории изменений маршрутов:
-
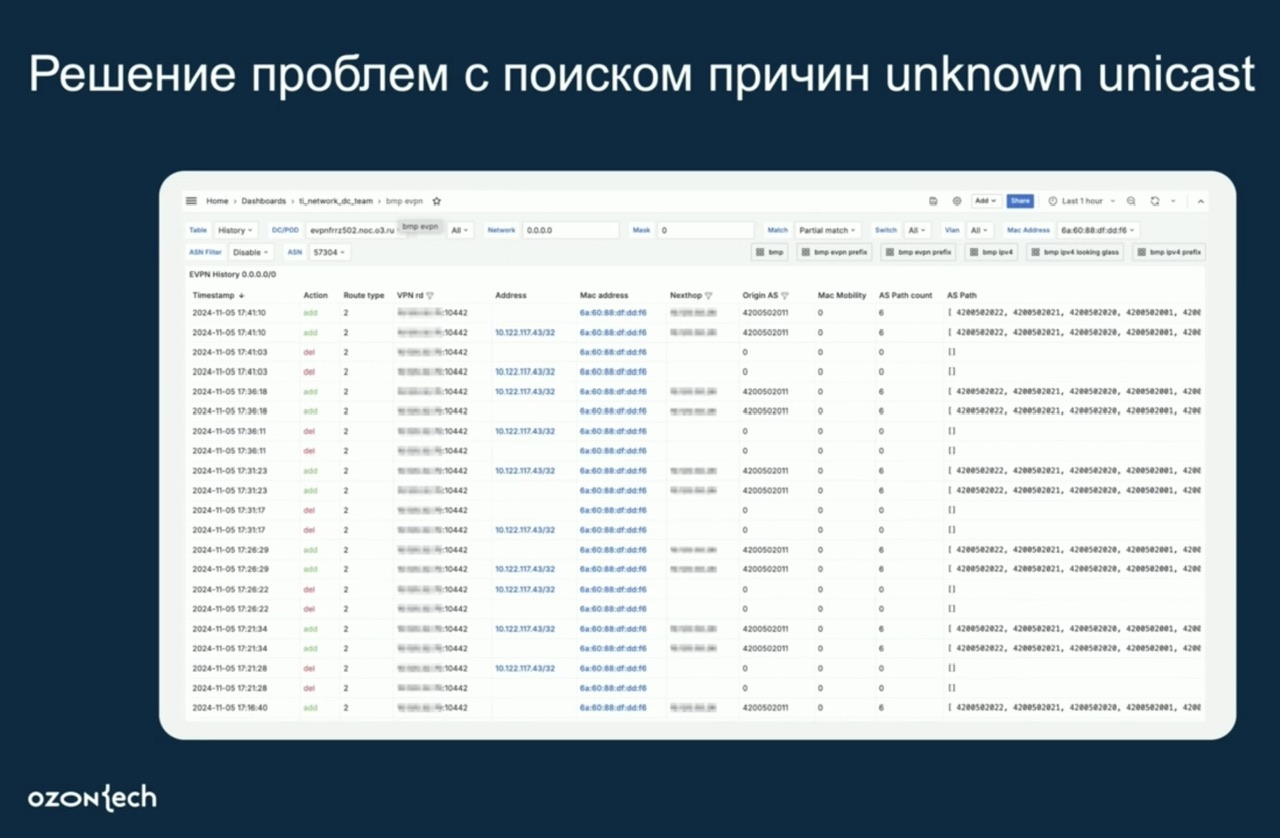
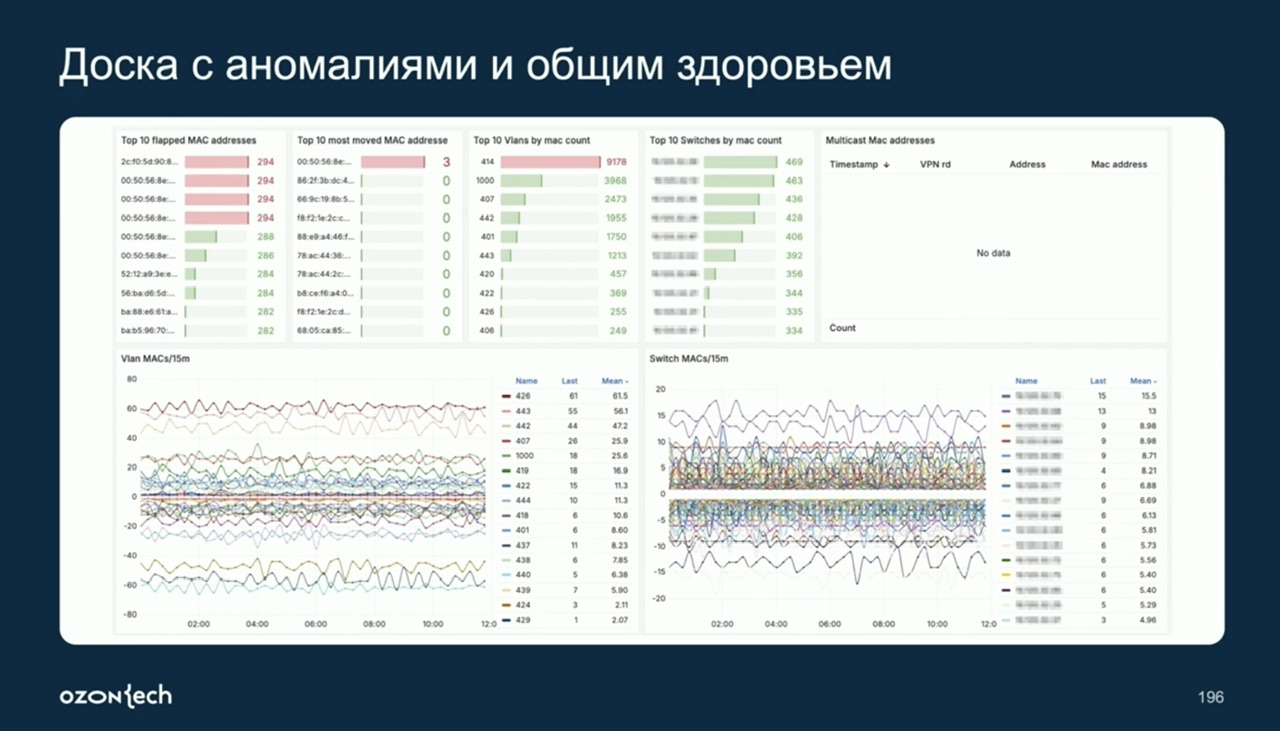
- (OZON, NMS) В сети OZON много маршрутной информации, хотят знать как она изменяется, используют растянутые L2 кластеры внутри ЦОД, поэтому мониторить изменение/миграцию MAC адресов важно. К примеру когда появляются и пропадают mac адреса в фабрике (таким образов выявили проблемы с периодическим флудом unknown unicast), строить top адресов, который мигрируют.
- Поиск причин unknown unicast
- Проблемы с anycast
- Применение политик маршрутизации
- История миграции IP-адресов
- Можно следить за переполнением сегментов по IP/MAC адресам
- Можно посмотреть по конкретному MAC адресу статистику где он был в фабрике
Альтернативы BMP значимо хуже
-
- BGP сессия с пиром и коллектором
- есть высокий риск нарушить продуктивный трафик т.к. поднимается сессия в продуктивном VRF
- SNMP мониторинг
- BMP, так же как и BGP сессия к коллектору позволяет получить только DIFF на коллектор (около 30-100 сообщений в секунду у них), при SNMP же приходится забирать/опрашивать full view по миллиону маршрутов (у них 4 FULL VIEW – 4 млн. маршрутов в сумме) раз в какой то интервал
- получать информацию по событию не получится, только с каким то достаточно большим по значению интервалом
- это стрессовая операция как для того, кто опрашивается, так и для того, кто опрашивает
- BMP, так же как и BGP сессия к коллектору позволяет получить только DIFF на коллектор (около 30-100 сообщений в секунду у них), при SNMP же приходится забирать/опрашивать full view по миллиону маршрутов (у них 4 FULL VIEW – 4 млн. маршрутов в сумме) раз в какой то интервал
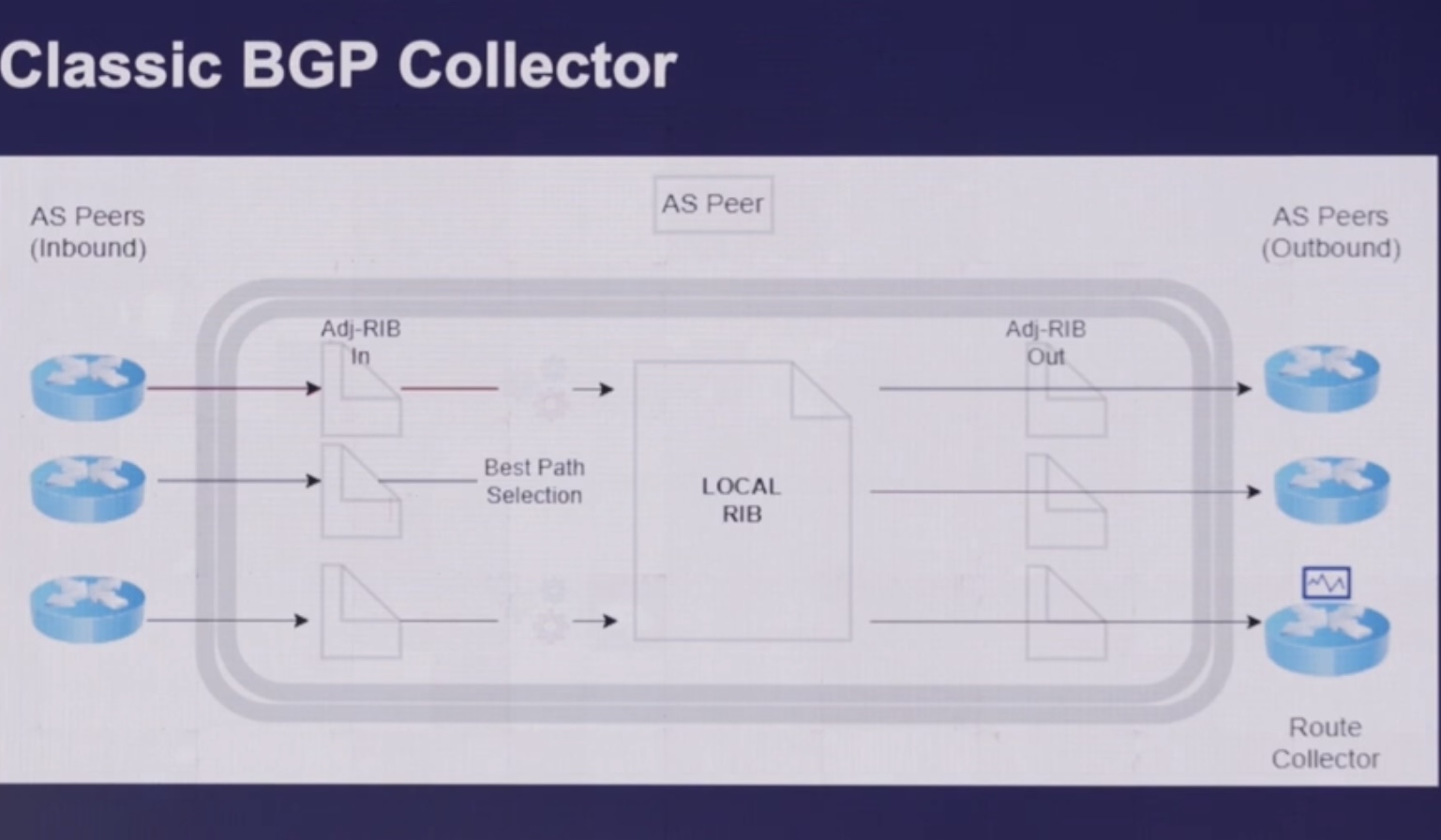
- (BGP, NMS) на коллекторе при использовании SNMP/BGP сессии собирается только информация из LOCAL RIB устройства (то, что используется для локальной маршрутизации), при этом, в отличии от использования BGP BMP нет информации о
- ADJ-RIB-in – adjacency RIB inbound (PRE POLICY) – входящих маршрутах/апдейтах до применения локальных/своих политик
- ADJ-RIB-out – adjacency RIB outbound (POST POLICY) – исходящих маршрутах/апдейтах после применения локальных/своих локальных политик
- BGP сессия с пиром и коллектором


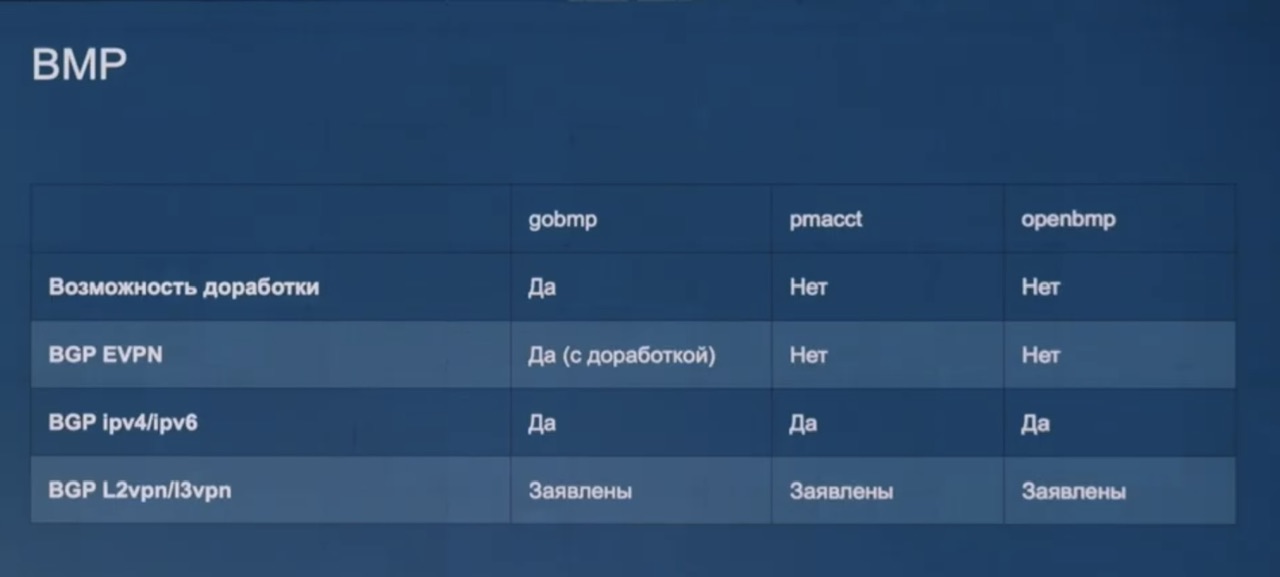
Они остановились на goBMP, остальные для EVPN не подошли, но даже goBMP пришлось дорабатывать под себя (подробнее на habr), например:
-
- Убрали склейку маршрутных апдейтов, которая происходила из-за отсутствия информации по идентификаторам сторон инциации/терминации – добавили всю инфу по анонсирующей стороне (в виде route distinguisher) и в итоге получили в апдейтах с AS path/origin/MAC/IP адресами информацию от того, где все это происходило
- Четырехбайтный AS number
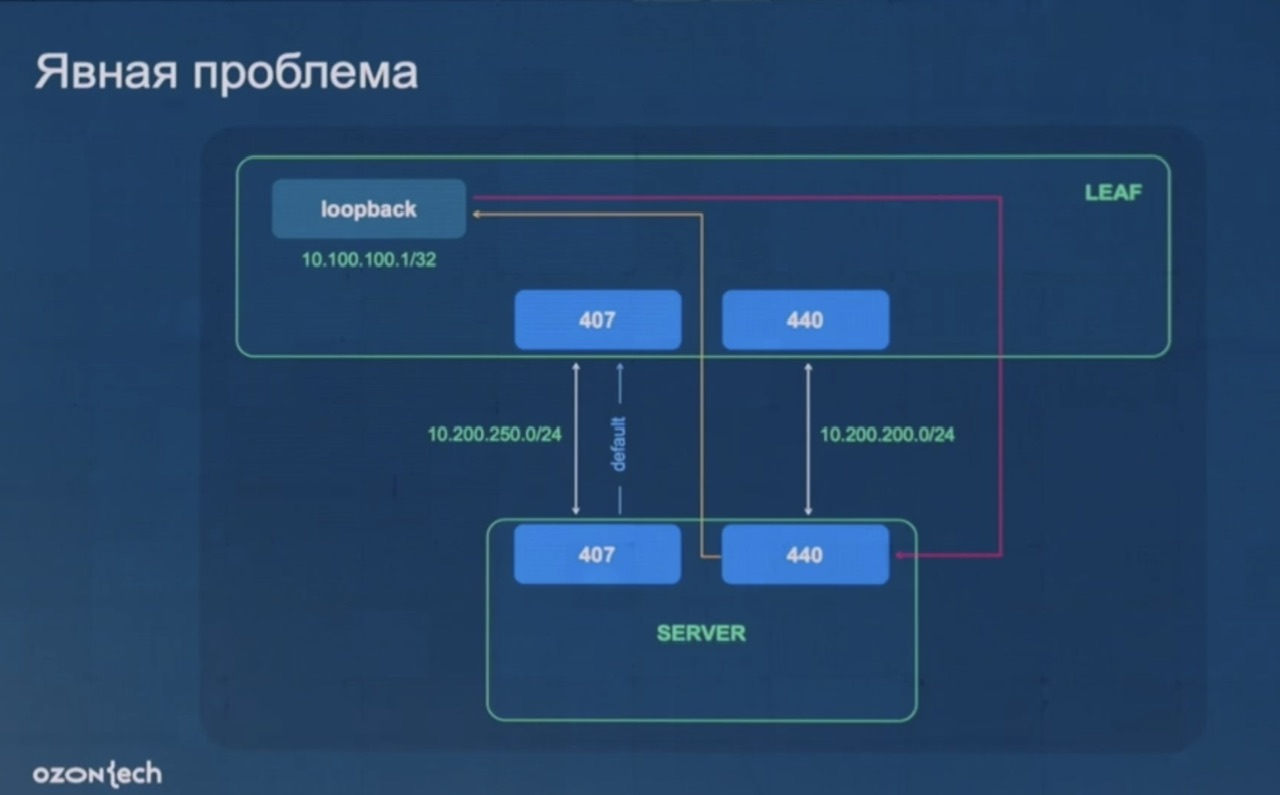

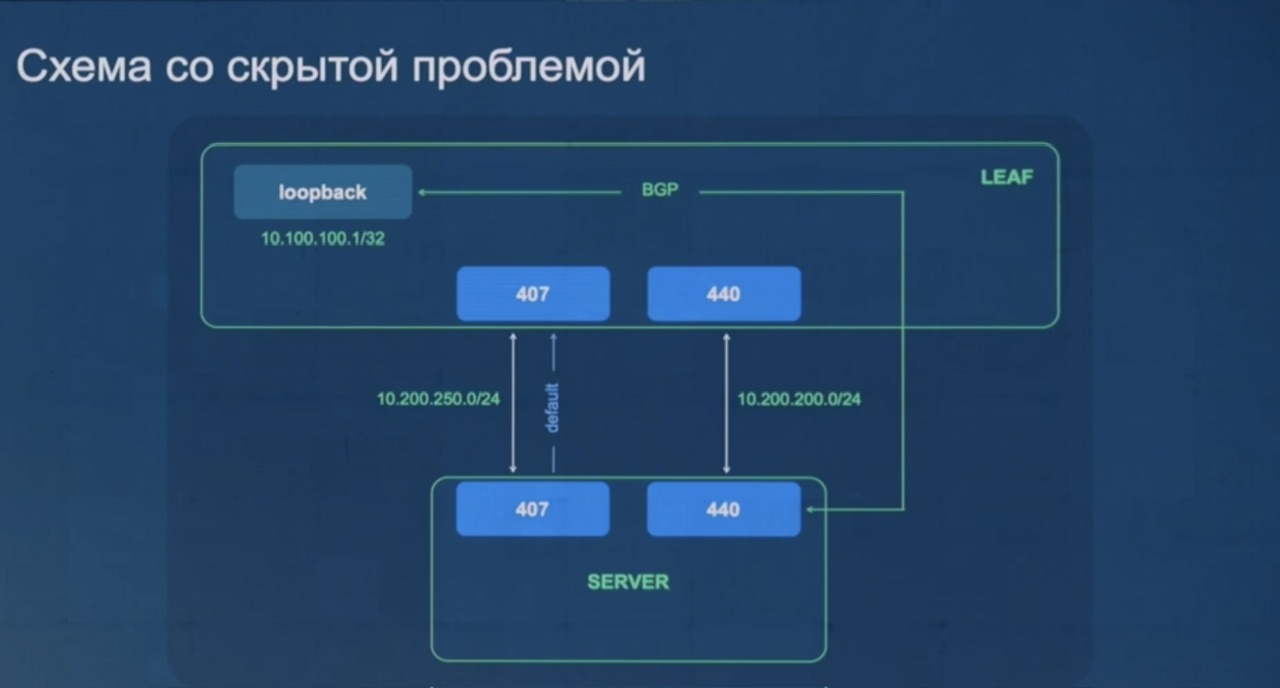
Итоговая схема. В изначальной вместо clickhouse cluster был Postgres (PG), но он работал плохо – для сценария флапа всех 4 МЛН. маршрутов ((сценарий – отключение/включение ЦОД)) не подходил т.к. имеет проблемы с такими большим вставкам. После перехода на clickhouse такие вставки работали нормально.


google malt/autorepair
- (google malt/autorepair, будущее после SNMP, ZTP, Capacity planning) Библиотека полезных статей от research Google:
- (Hadal, Google MALT/AutoRepair) 3) Google MALT (autoRepair, Usenix 2020 Paper MALT). В google любое взаимодействие с сетью происходит черед MALT (эксплуатация/планирование/моделирование и проч). Полного описания модели в открытом доступе нет.
- (будущее после SNMP, google malt/autorepair) google уже в 2021 на 80-90% мониторил девайсы за счет streaming telemetry, и только на тех девайсах, которые не поддерживают «классически»
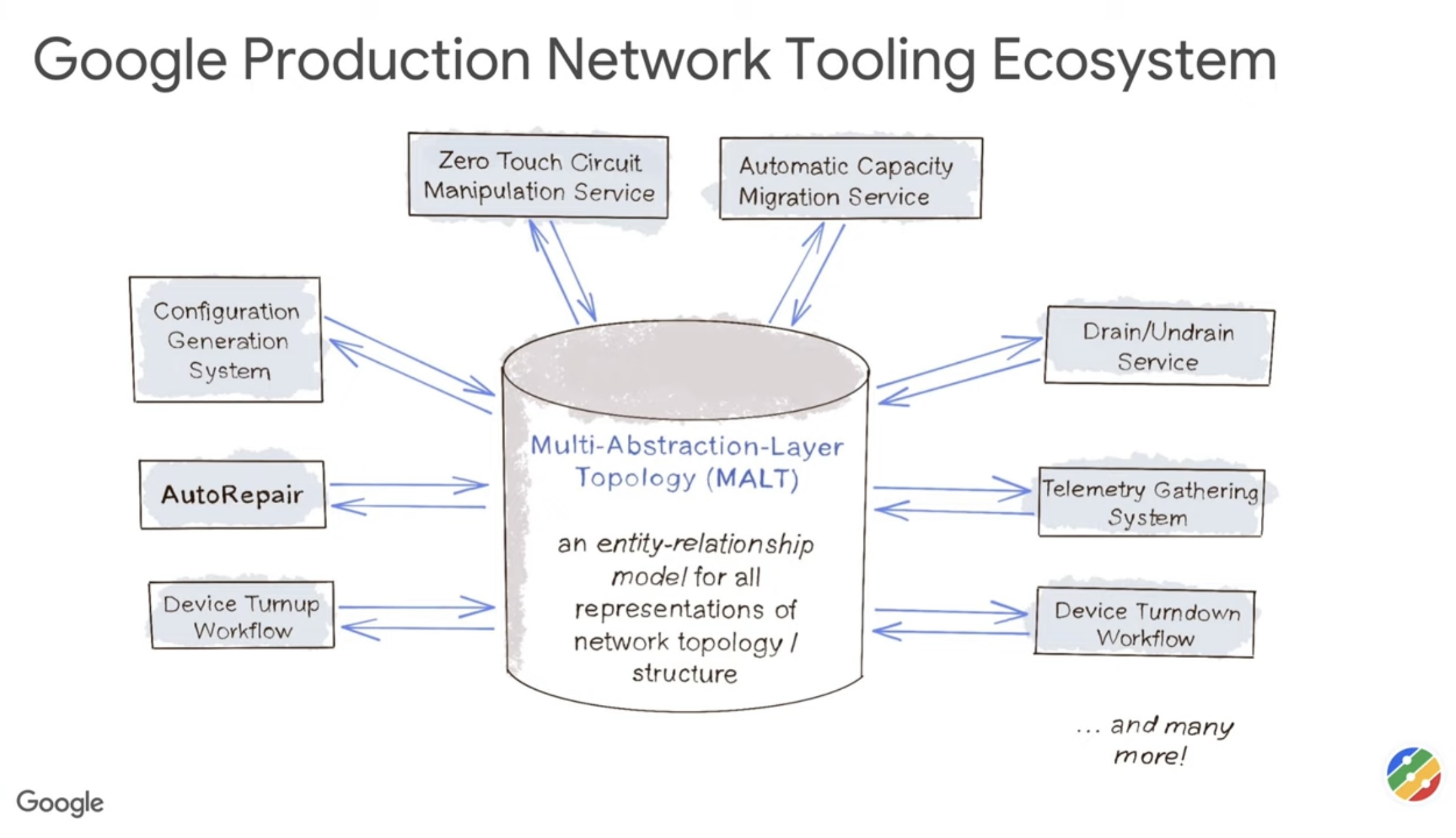
HADAL – Мониторинг сетевой инфраструктуры. Система поддержки принятия решений (Monitoring). ЦИФРОВОЙ ДВОЙНИК/ВЕРИФИКАЦИЯ.
- Обещали opensource, по факту пиар коммерческого проекта, классика!
- Netdevops и независимая от вендора конфигурация, CI/CD
- Вендоронезависимый конфиг – OpenConfig Yang ((по факту они реализовали на базе protobuf))
- Проверка настройки устройств по тексту конфигурации (стат анализ) – пример batfish (подробнее в devnet)
- Коллекторы
- Потенциальные интерфейсы: CLI/SNMP/peering/sniffing/BGP BMP
- Коллектор OSPF пакетов Golang GoPacket fork (sniffing)
- Коллектор BGP получает данные от GoBGP (peering), который устанавливает связность с роутерами
- Для описания всех форматов пакетов и других структур, включая динамический построитель топологии (от routing данных коллекторов, отрисовка L2 в планах; если зеркалировать сложно для ospf то достаточно поднять один frr в area и сделать на нем зеркалирование или сделать пассивную оптику/тап), использовали protobuf/proto-файлы, что оказалось очень удобным решением для интеграции со сторонними системами. Моделирование end to end путей (полный путь пакета) в планах.
- (batfish/hadal)
- batfish работает на основе анализа конфига, собираются конфиги, на их основе строится модель – верификация control plane
- hadal снимает состояние коробок и строит модель – верификация Data Plane
- кто использует верификацию сетей – amazon, google, microsoft, alibaba, bytedance
- Мнения паблика (по сути относится к обоим продуктам, но написано для batfish)
- Звучит как какое-то очень амбициозное и, скорее всего, практически нерабочее (за вычетом самых примитивных случаев, когда и без него всё понятно) говно. Впрочем я, как огурец, всегда уважаю хороший компост. Он нужен для резюме)))
- Была надежда что если скормить в batfish конфиги и выхлопы всяких bgp то он покажет где петли, но конечно же это было наивным предположением
-
Да нет вполне рабочее было еще года 4 назад когда я в него тыкал питоном Загружал в него конфиги железок и оно исправно чекало все ацлы пройдет ли пакет по 5-тапл сквозь сеть И избыточность в ацл показывало когда одно правило перекрывает другие
Зачем нужен мониторинг сетевой инфраструктуры?
-
Обеспечение стабильной работы прикладной инфраструктуры и бизнеса
-
Обнаружение узких и проблемных мест в сети
-
Увеличение утилизации сети
-
Предупреждение и защита от угроз (DDoS, Route Hijacking, etc.)
- Доказать коллегам, что проблема не с сетью
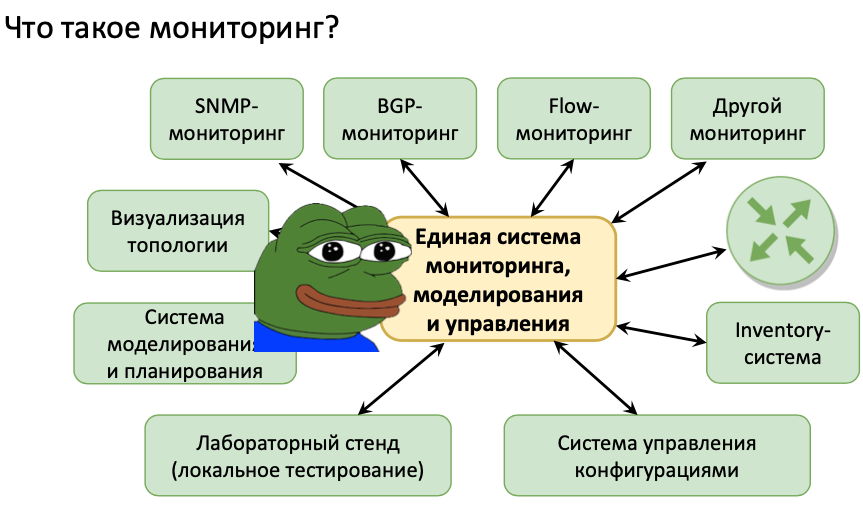
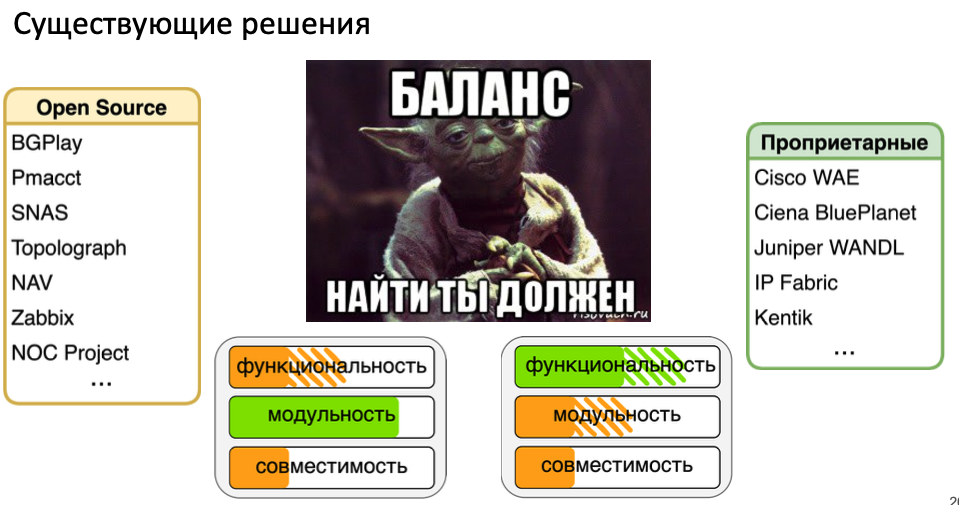
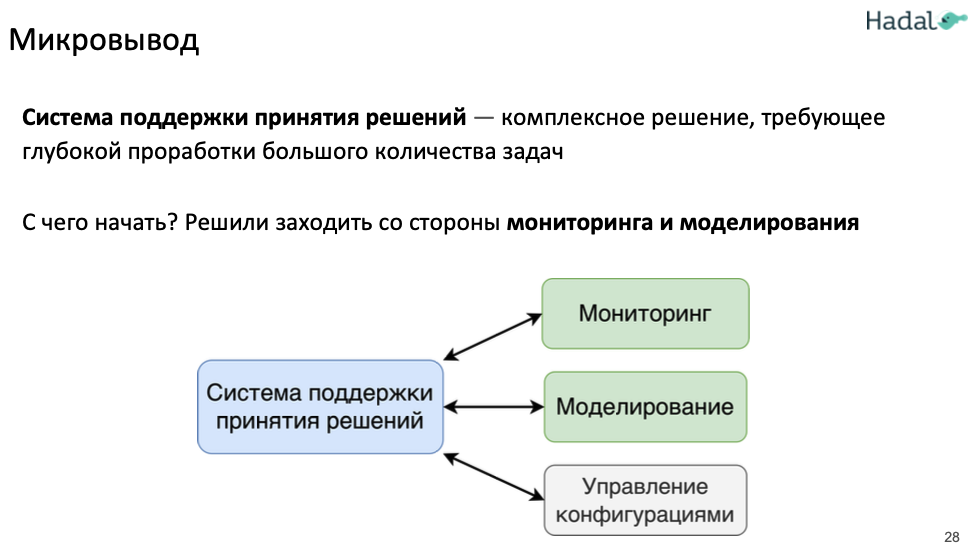

- Абстрактные модели сети
- 1) abstract network model от IETF RFC 8345-8346, использовали YANG для описания модели
- 2) transport api (TAPI) от open networking foundation (ONF), тоже использовали YANG для описания модели
- (Hadal, Google MALT/AutoRepair) 3) Google MALT (autoRepair, Usenix 2020 Paper MALT). В google любое взаимодействие с сетью происходит черед MALT (эксплуатация/планирование/моделирование и проч). Полного описания модели в открытом доступе нет.
- Для реализации аналога MALT использовали Neo4j (графовая база, из известных есть еще ArangoDB). База поддерживавает шардирование, что упрощает горизонтальное масштабирование и позволяет хранить много данных (большой размер графа и исторические данные).
- Вся структура топологии описывается с помощью proto-файлов (protobuf), не yang-модель.
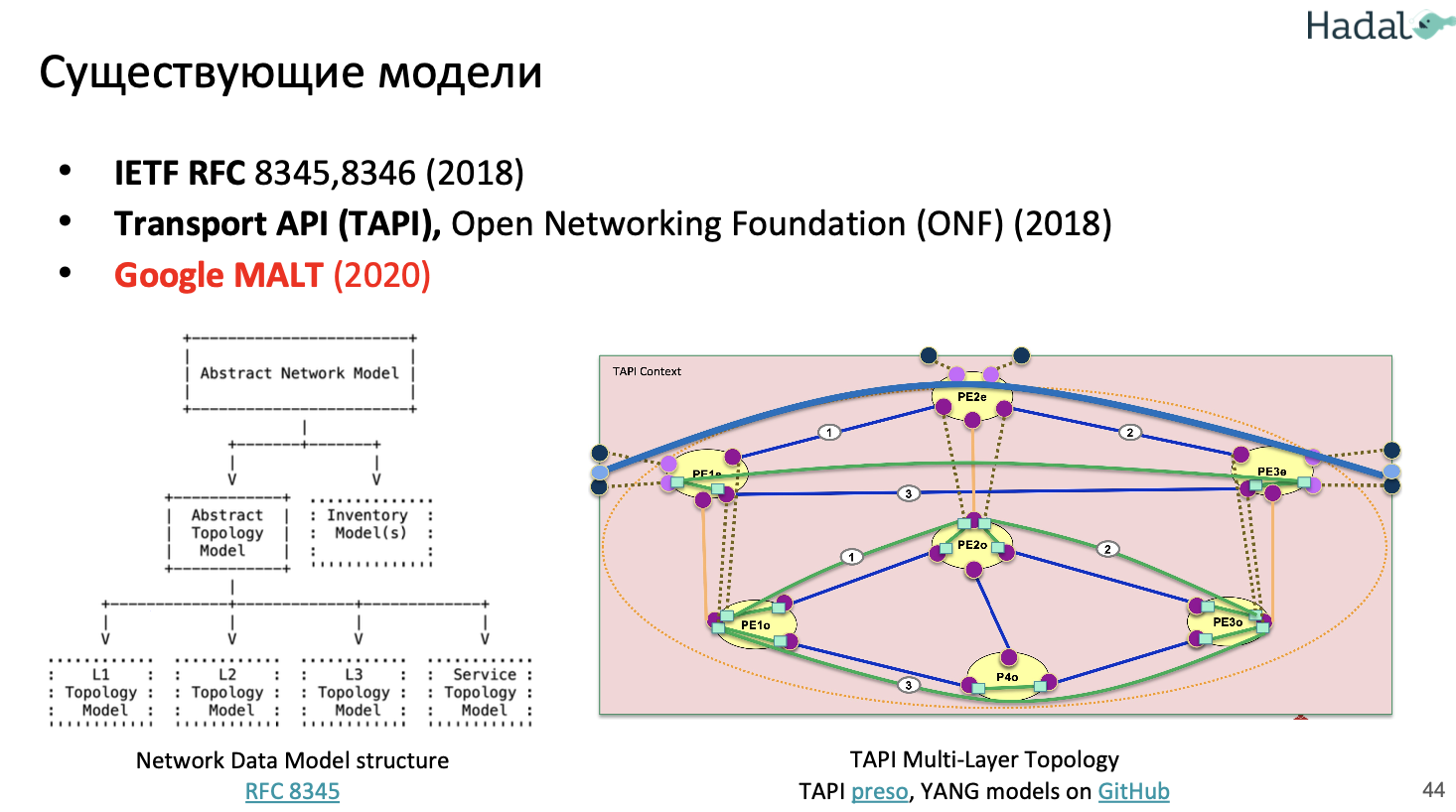
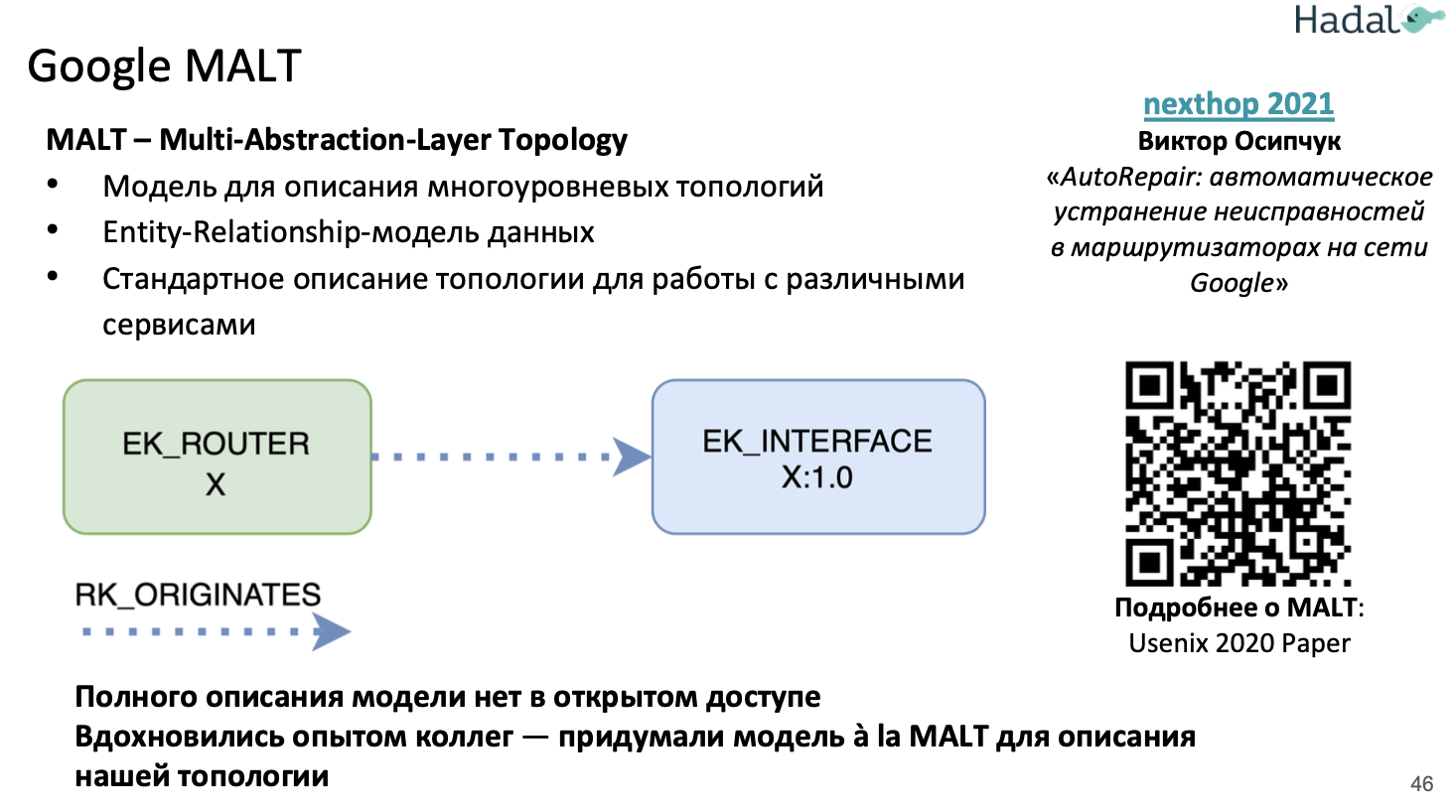

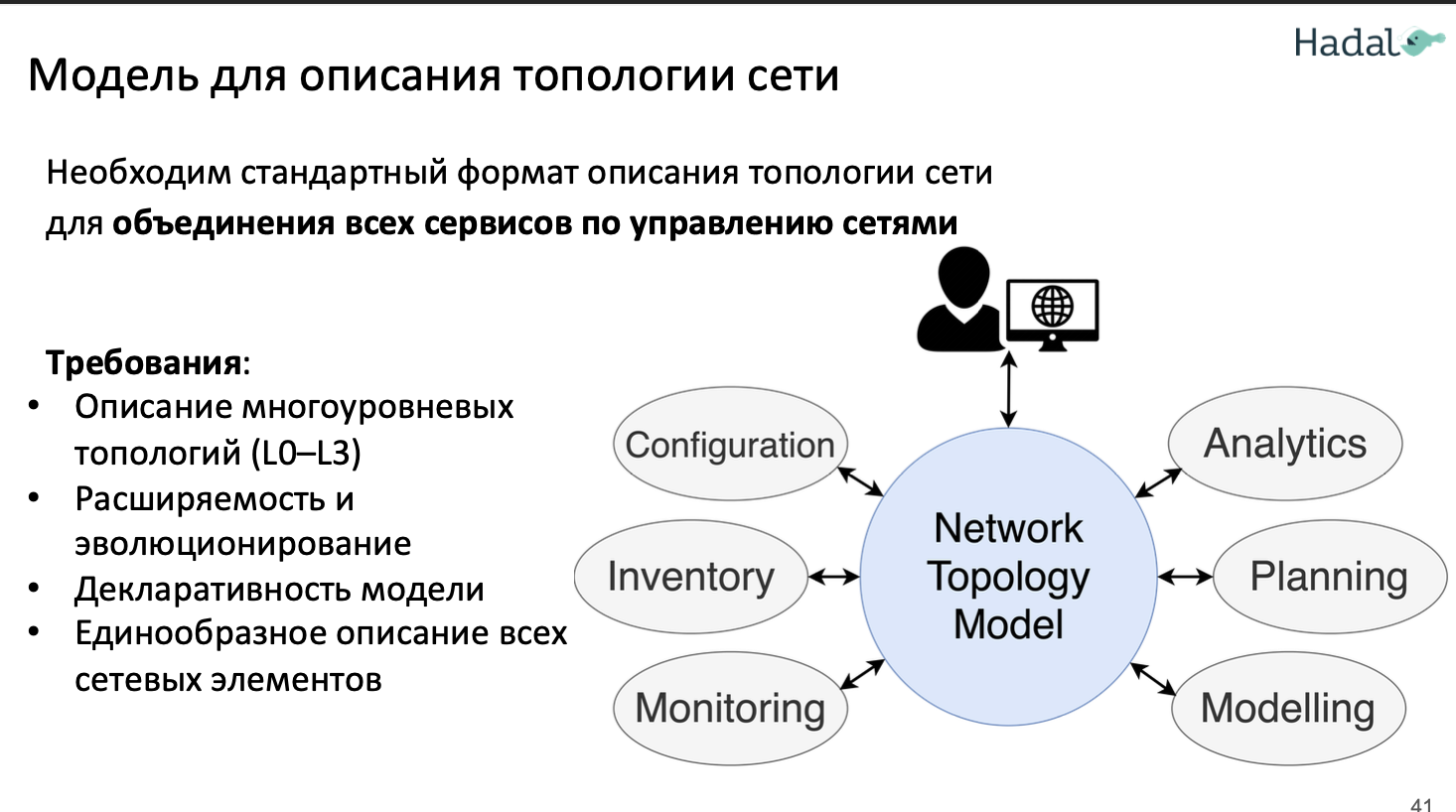
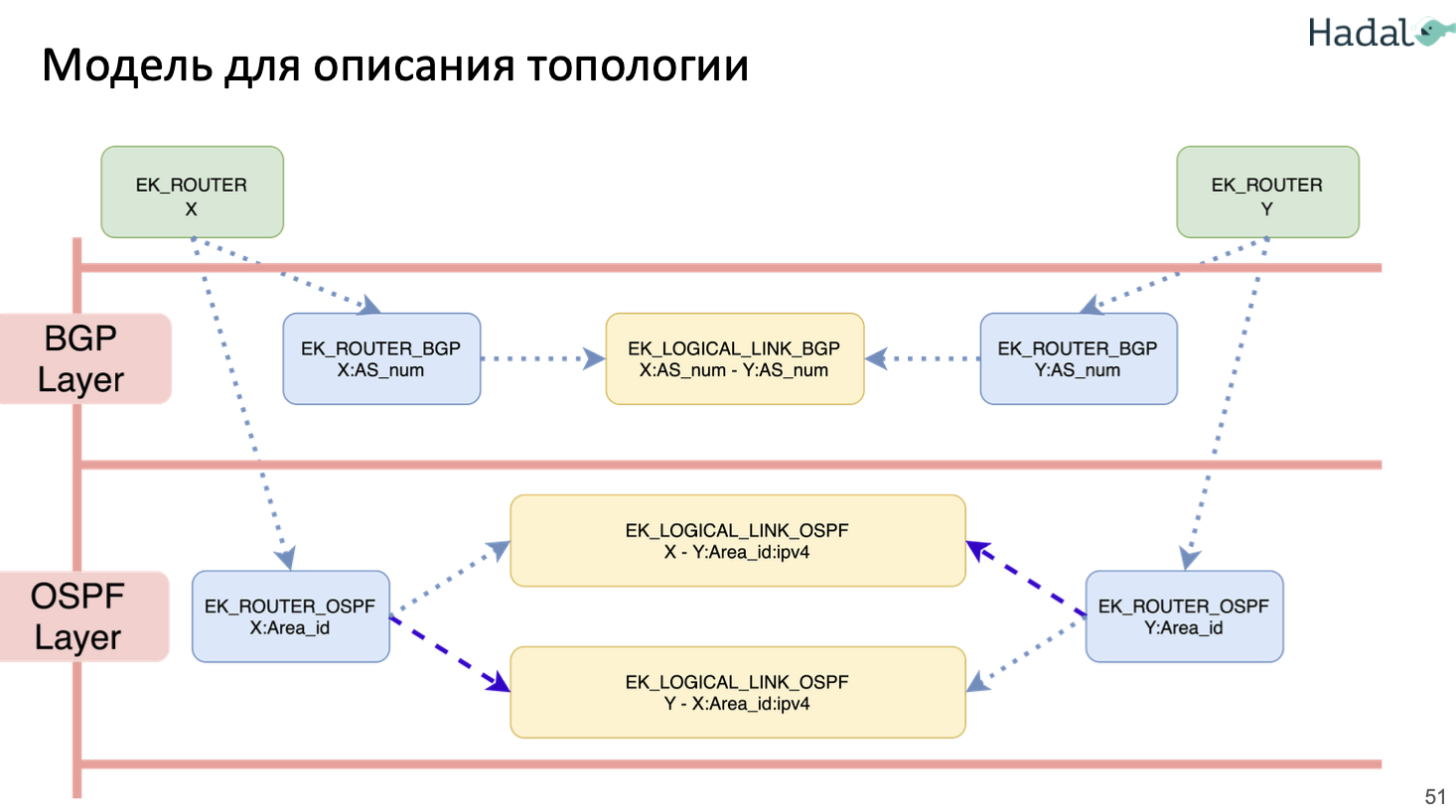
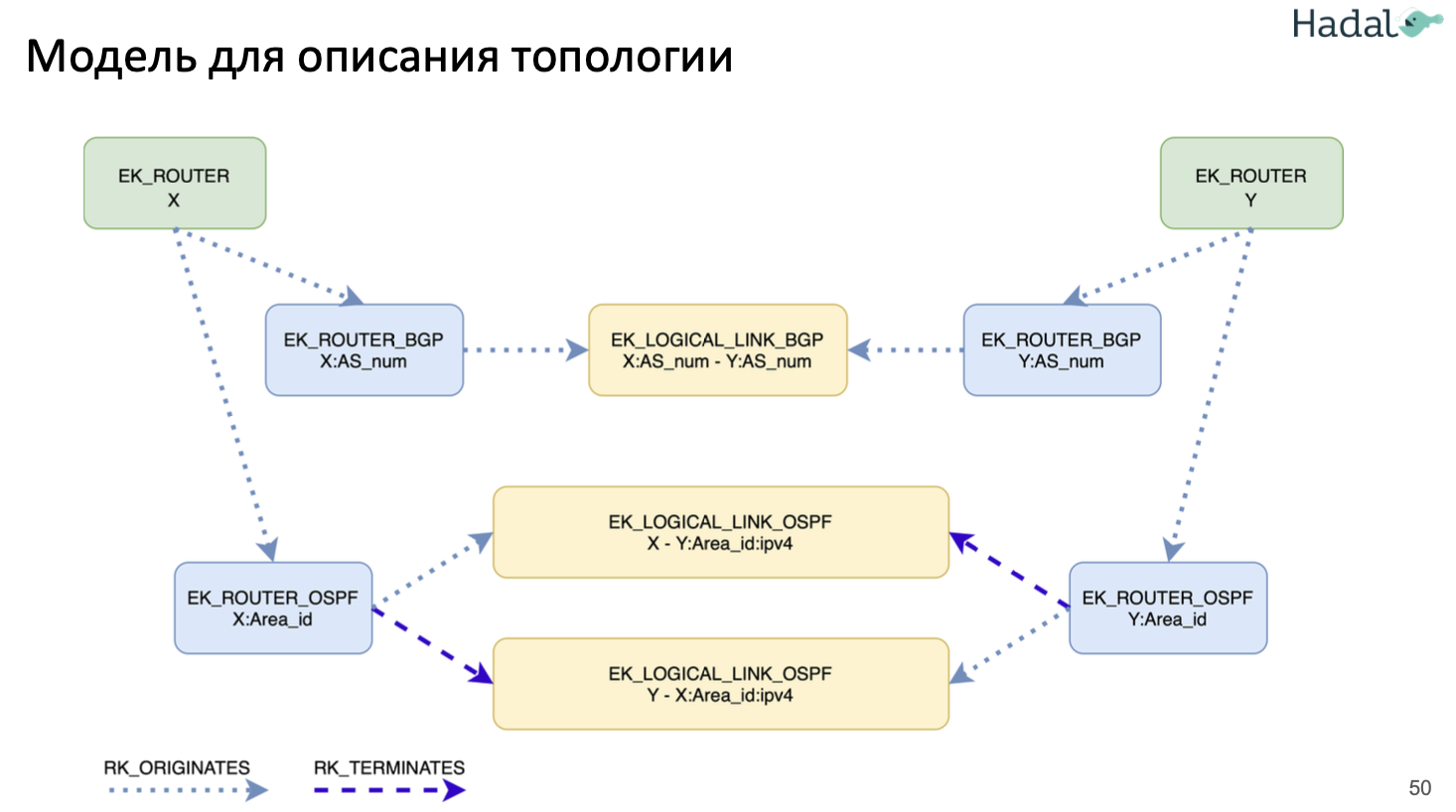
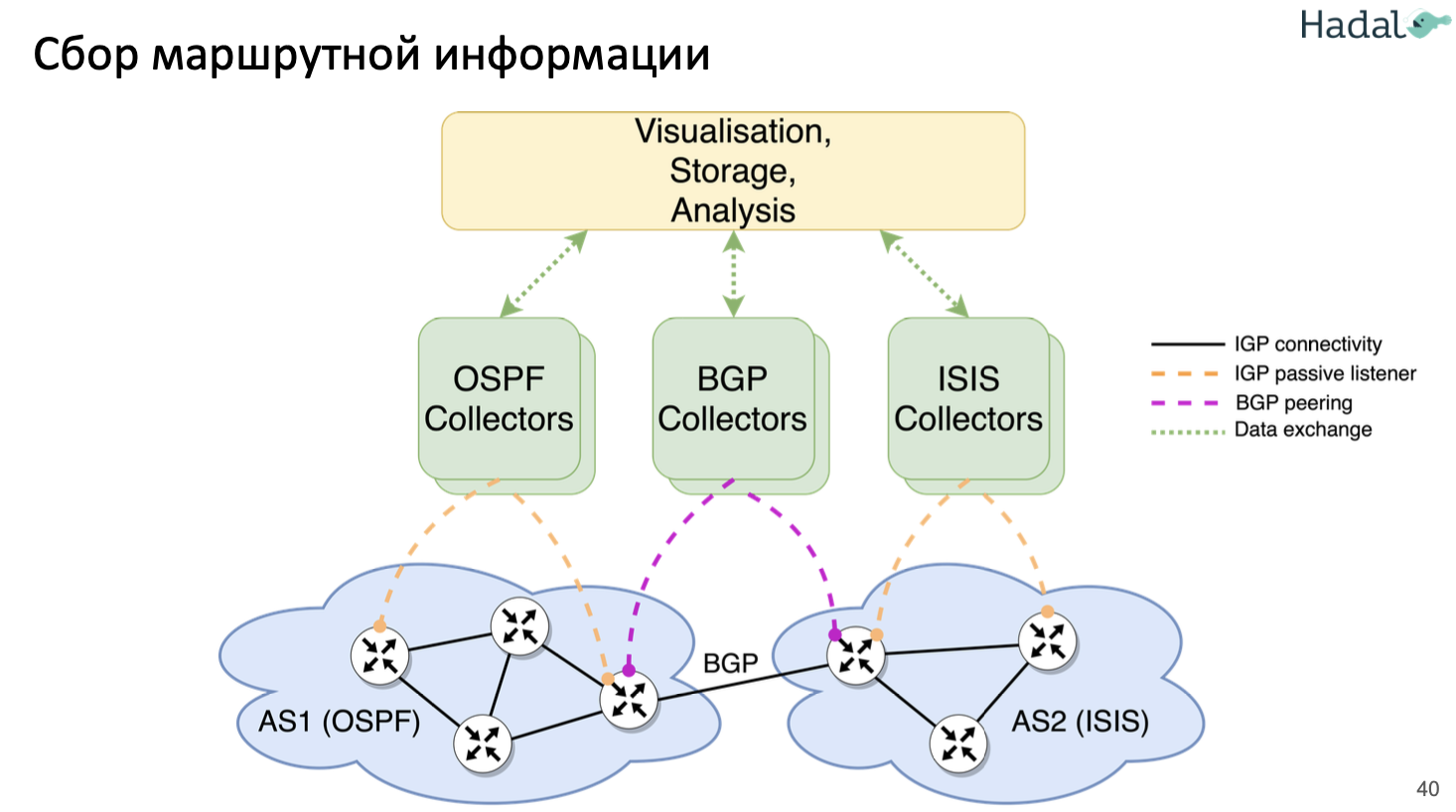
- Простое масштабирование всей системы за счет контейниризации/шардирования базы – просто увеличиваем кратно количество instance в k8s и получаем большую производительность
- Сообщения от коллекторов попадают в распределенную очередь Kafka, которая служит буфером на случай всплесков сообщений во время аварий, так же служит дополнительным резервный хранилищем сырых сообщений коллекторов и в целом упрощает интеграцию новых коллекторов в систему. Далее сообщения протоколов мапятся на обработчиков этих протоколов, эти обработчики реализуют MALT абстракцию в виде API с точки зрения внешней сети.
- Все сообщения от коллекторов проходят через Grafana, ClickHouse, Vector.dev и доступны в ui для дебага сетевыми инженерами
- Клиент на базе web приложения на react с разными плюшками.
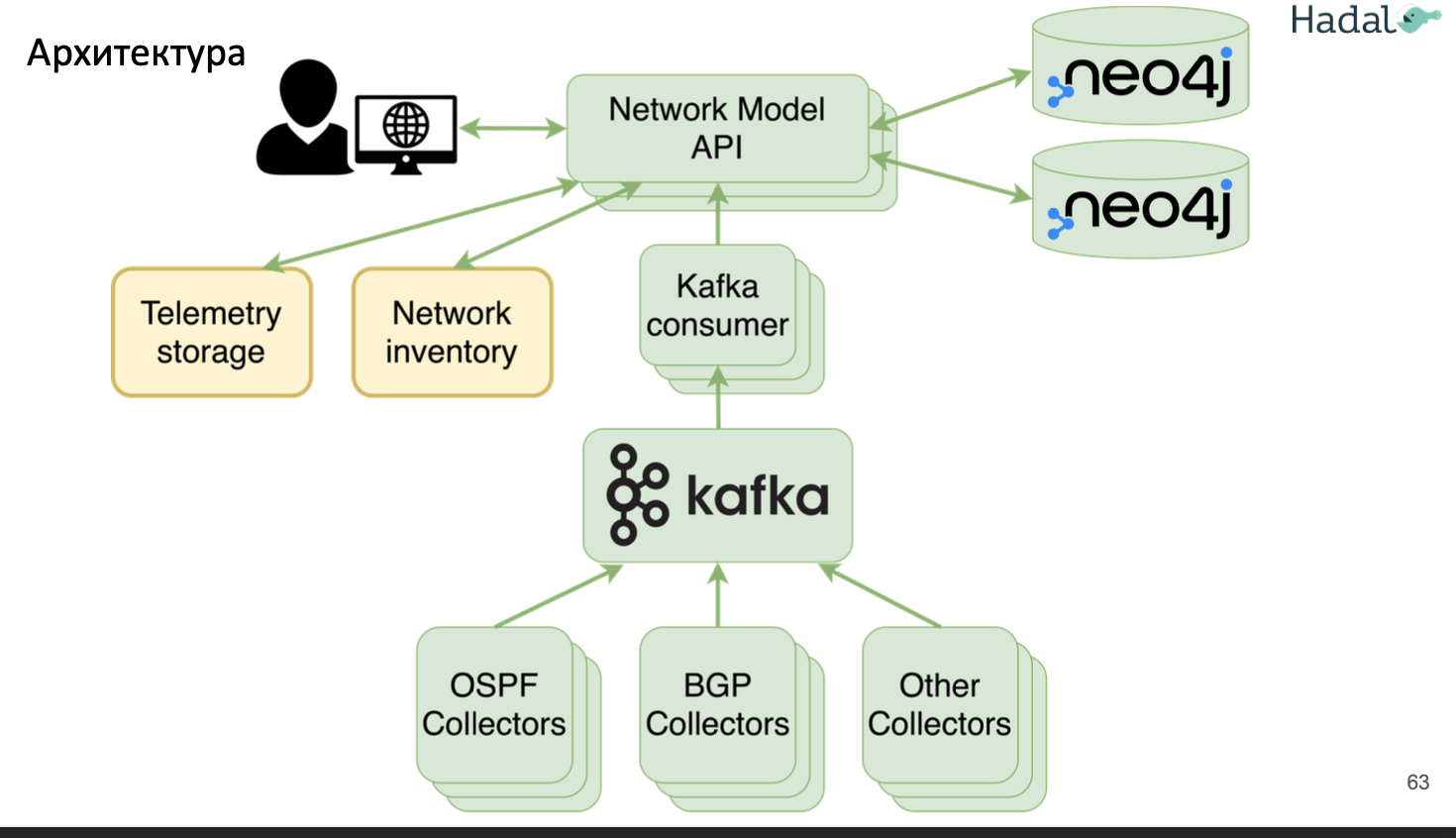
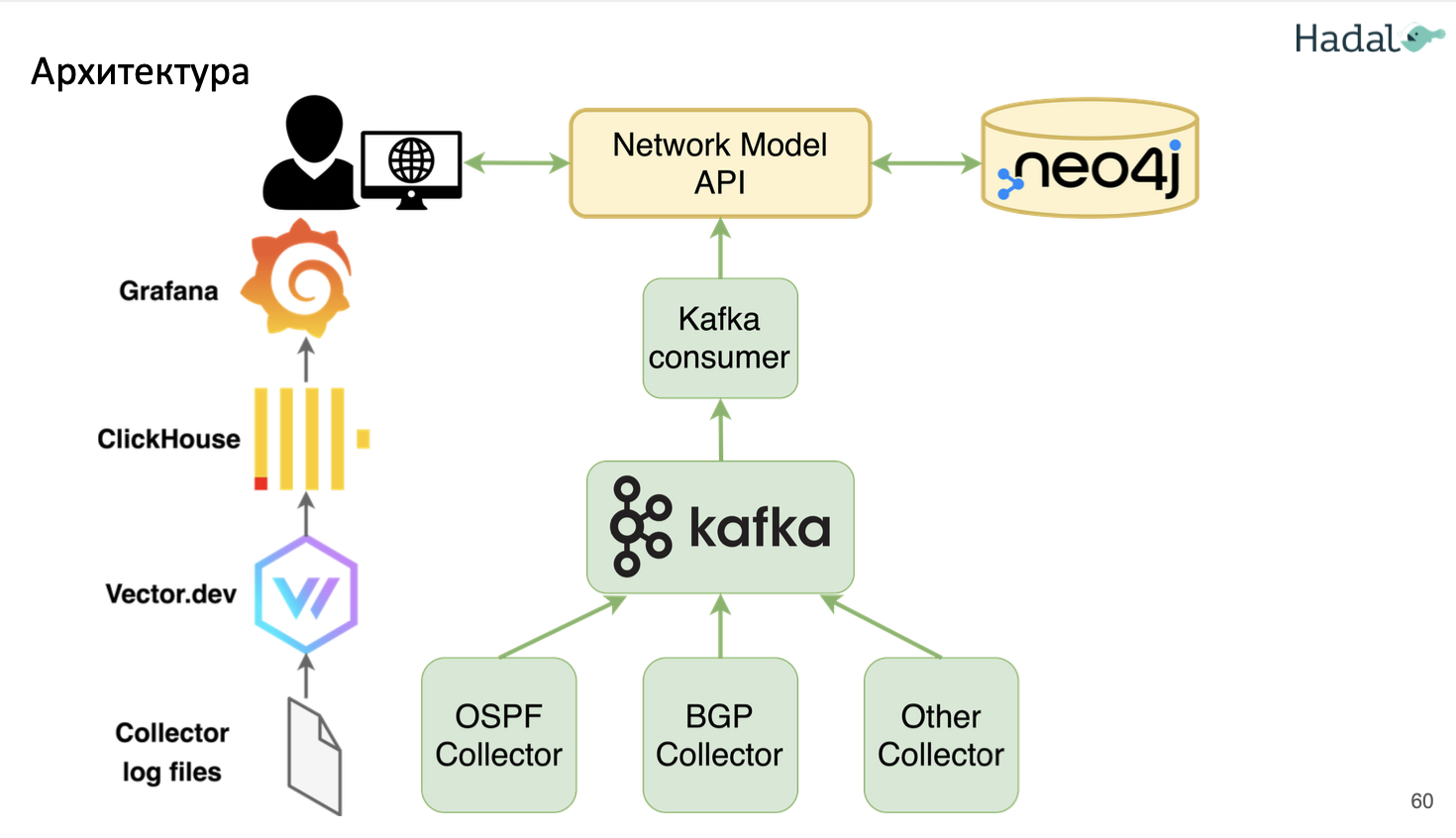
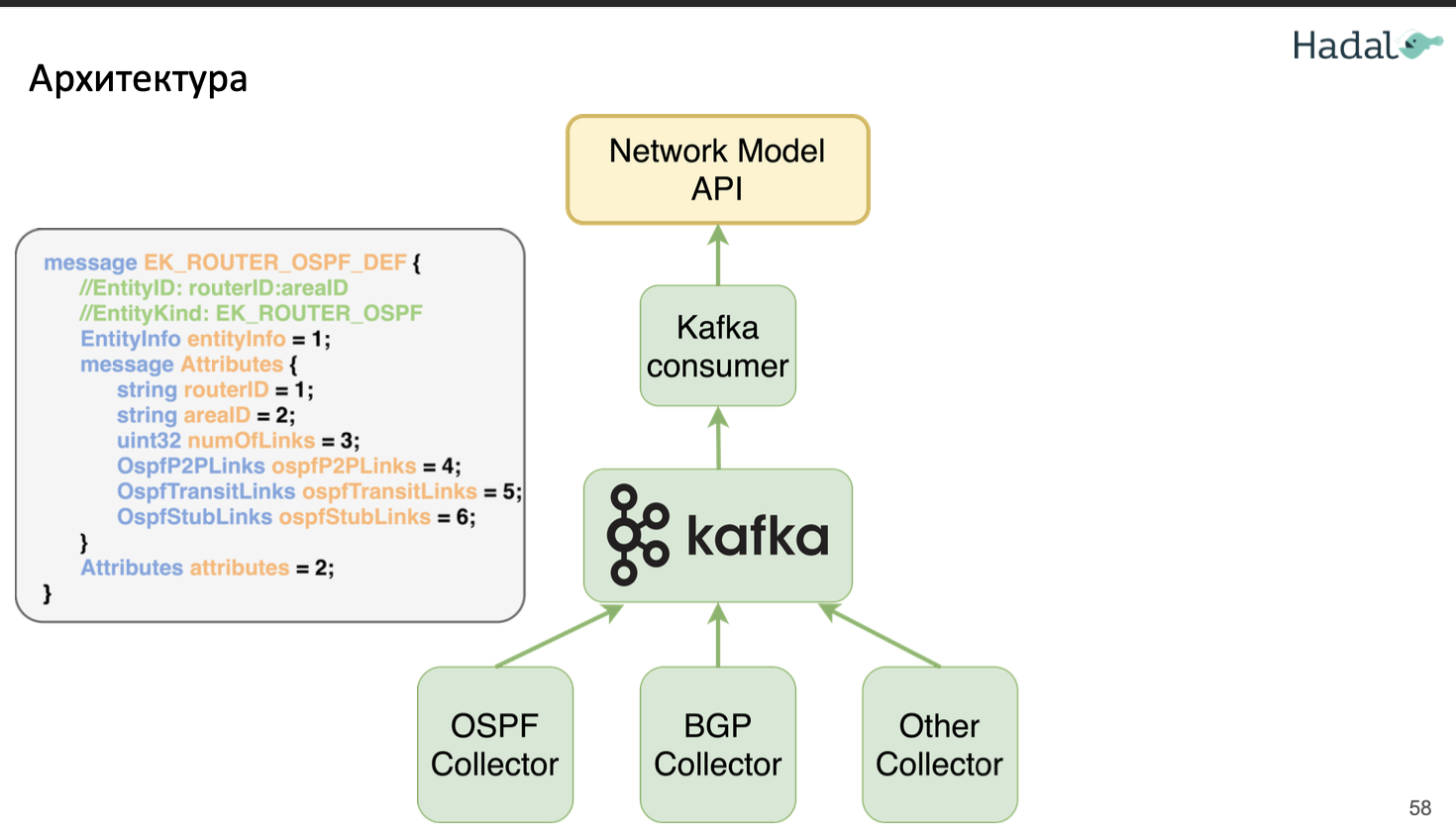

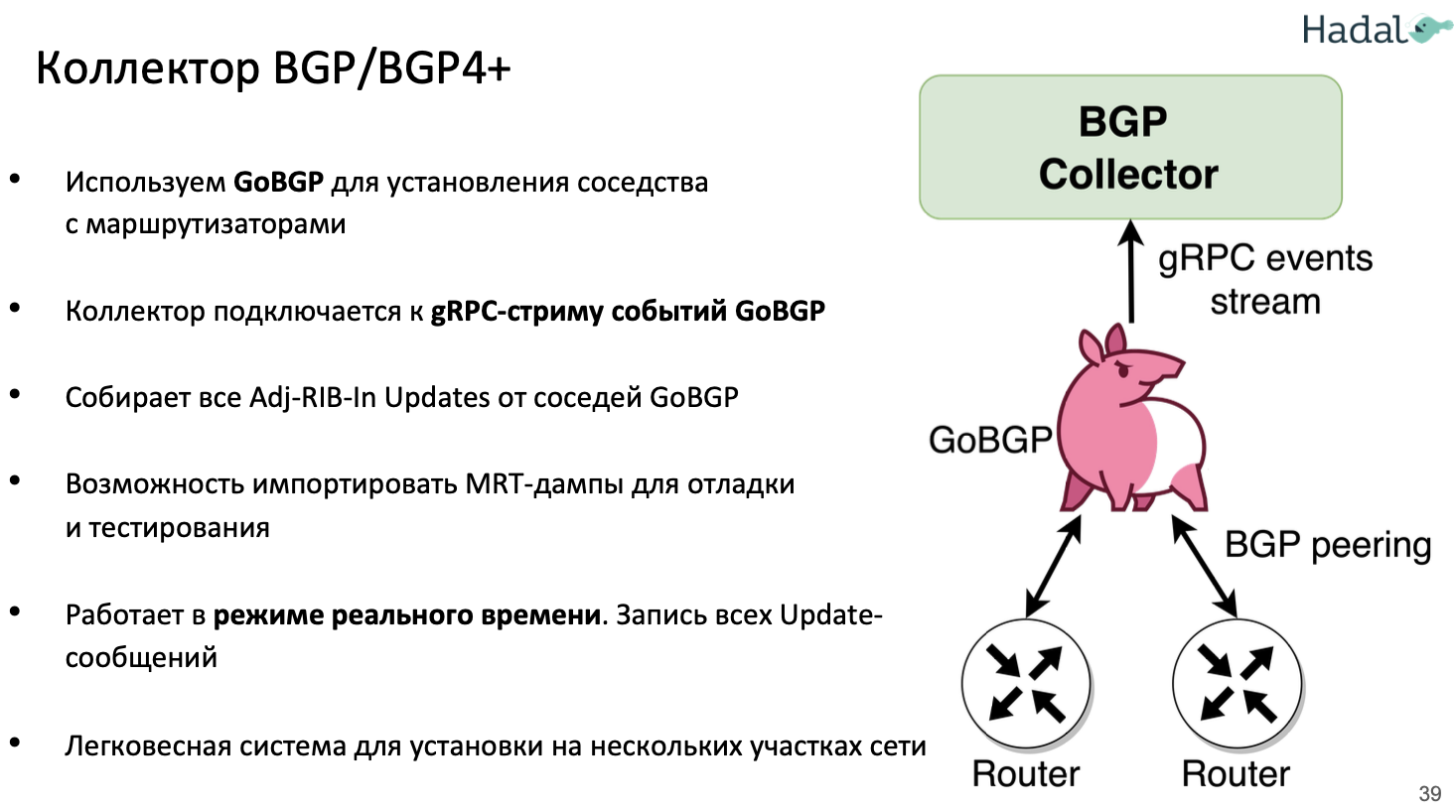

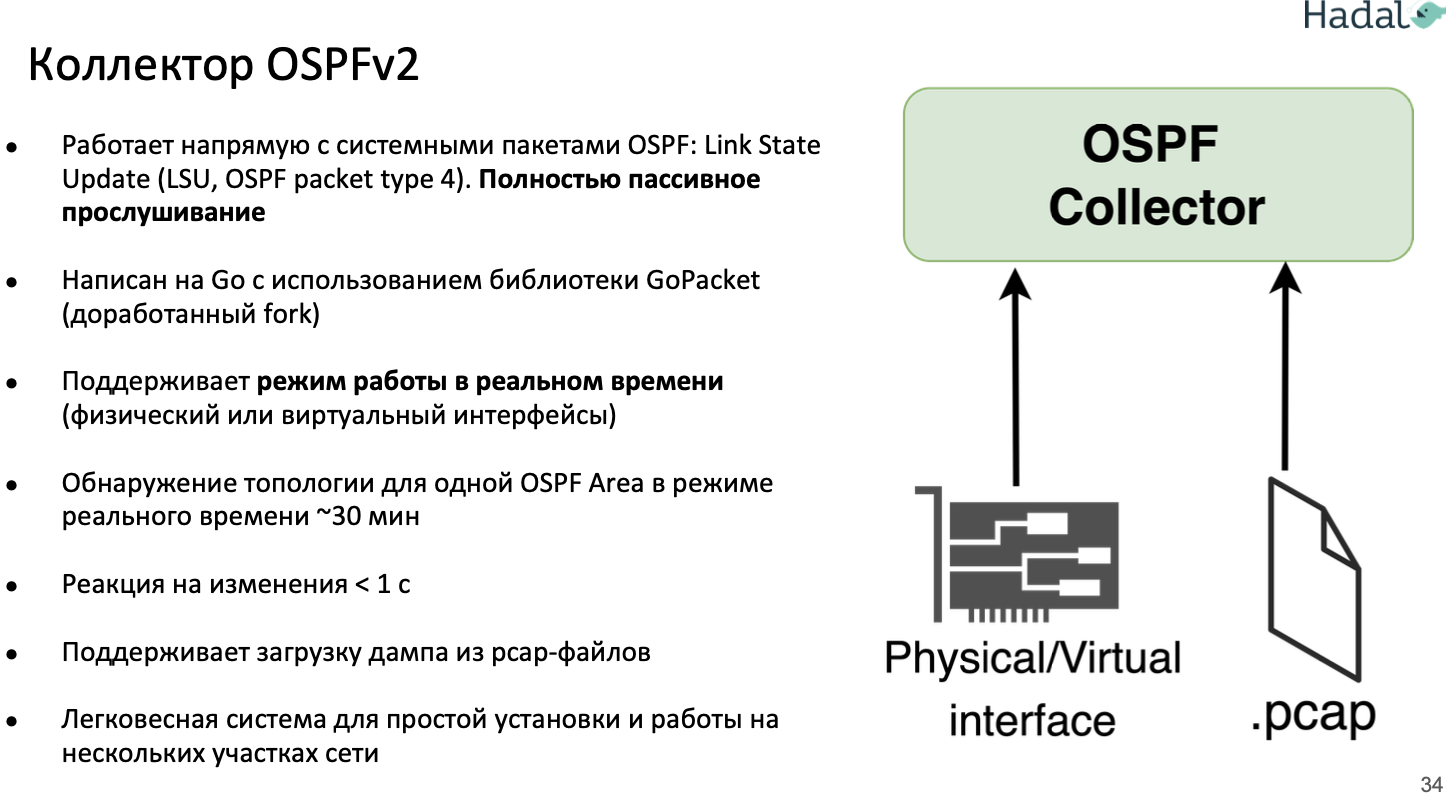

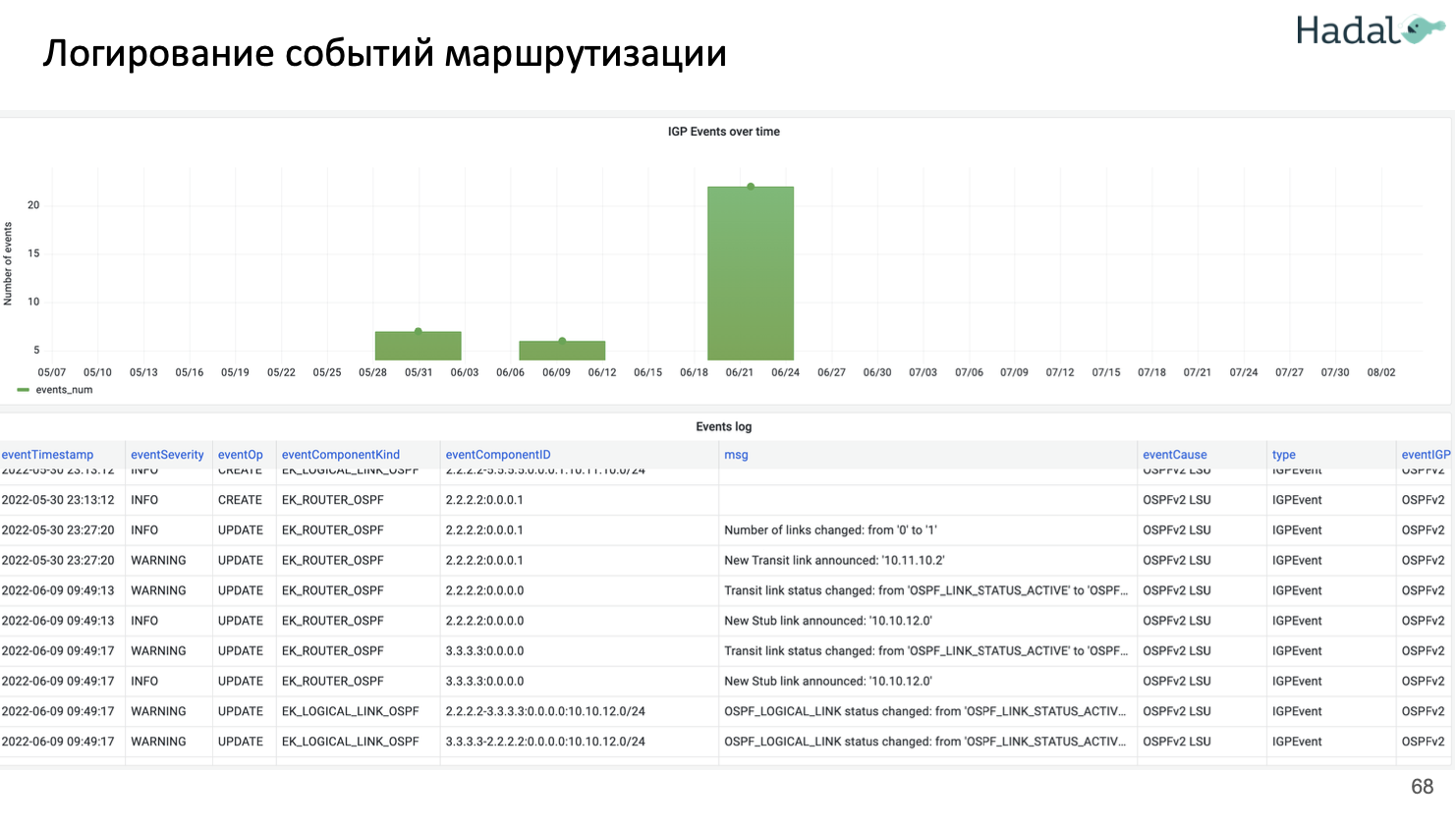
Визуализация операционная (на основе полученных данных с коллекторов), а не конфигурационная.
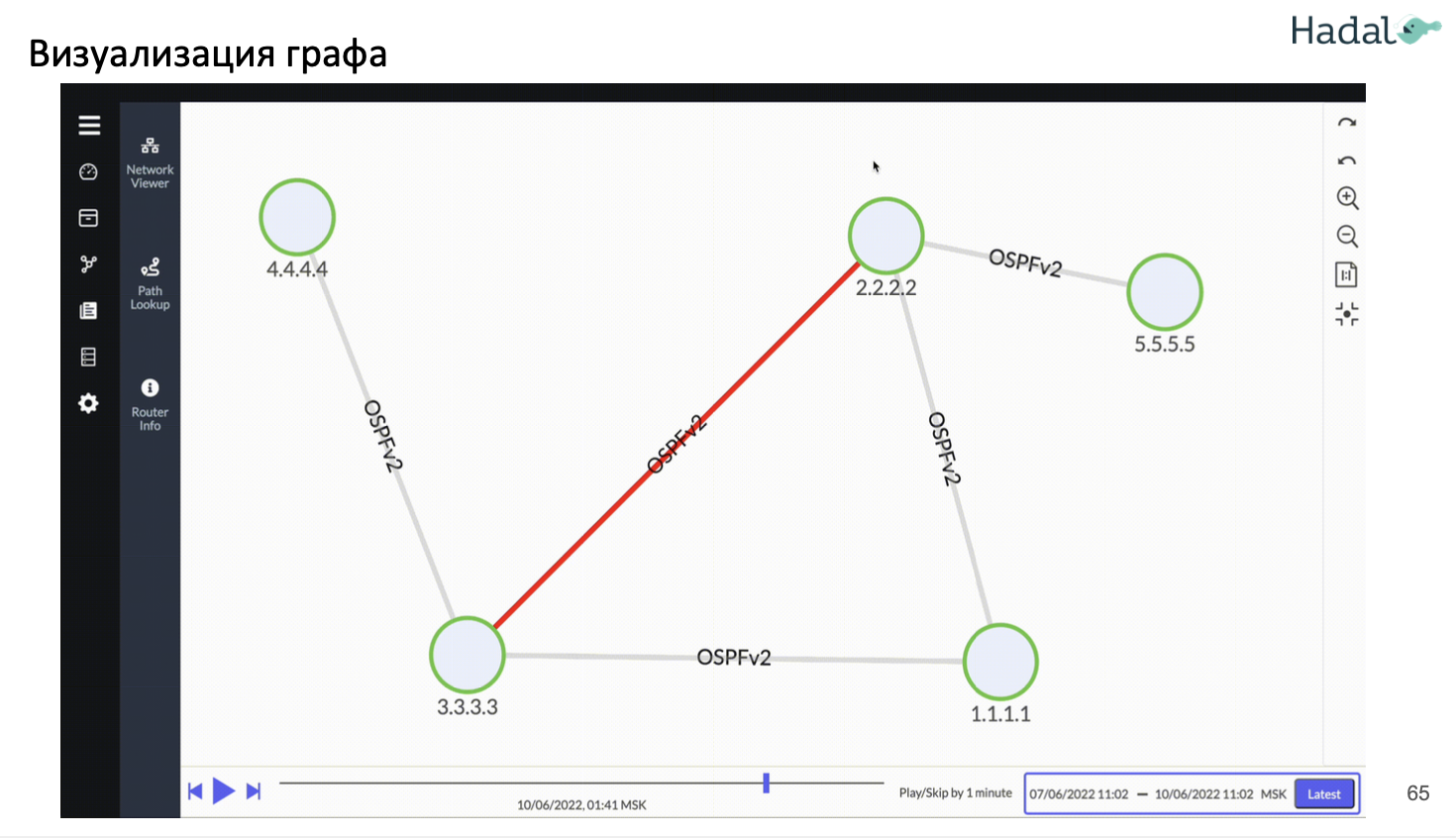
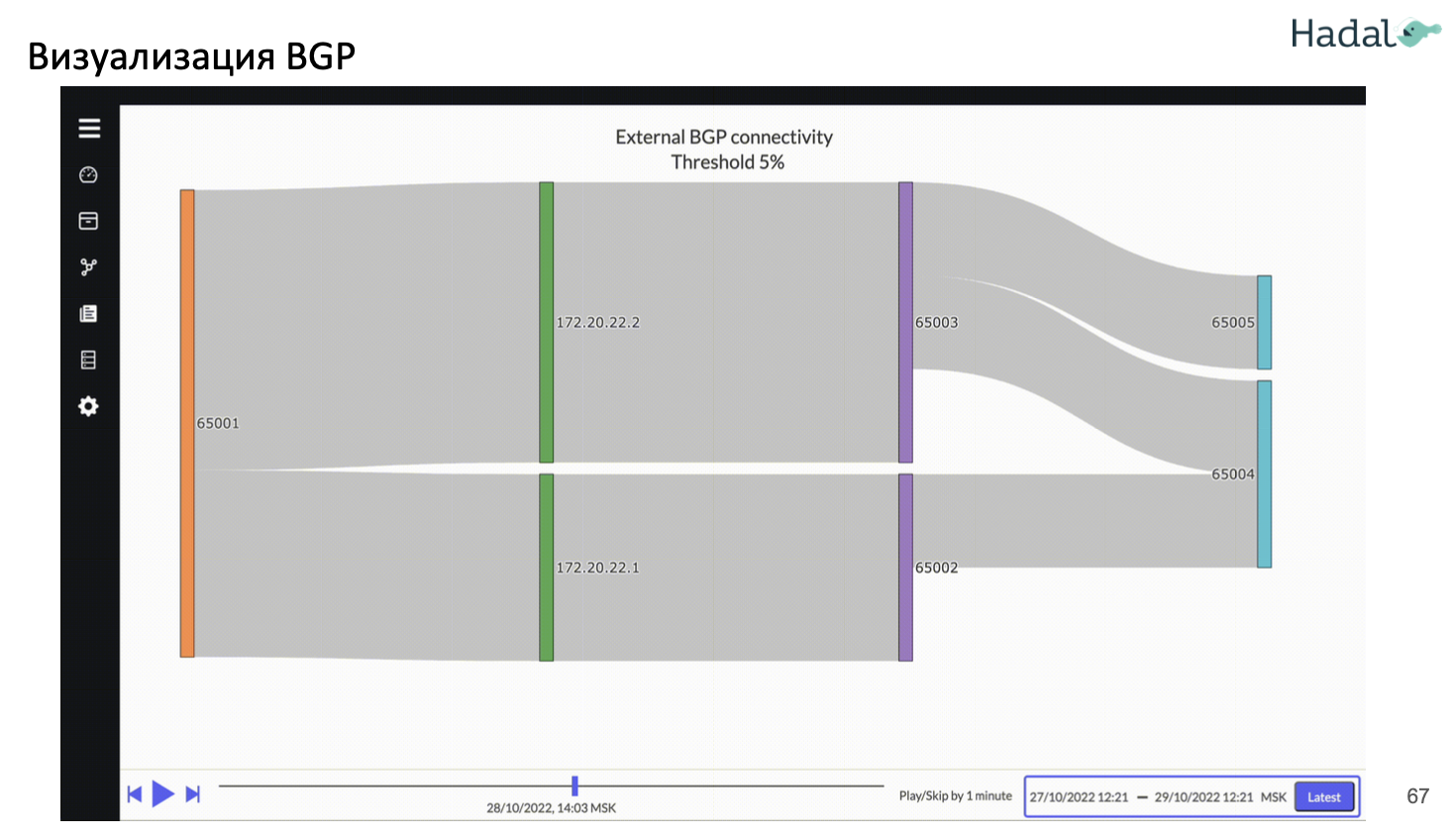
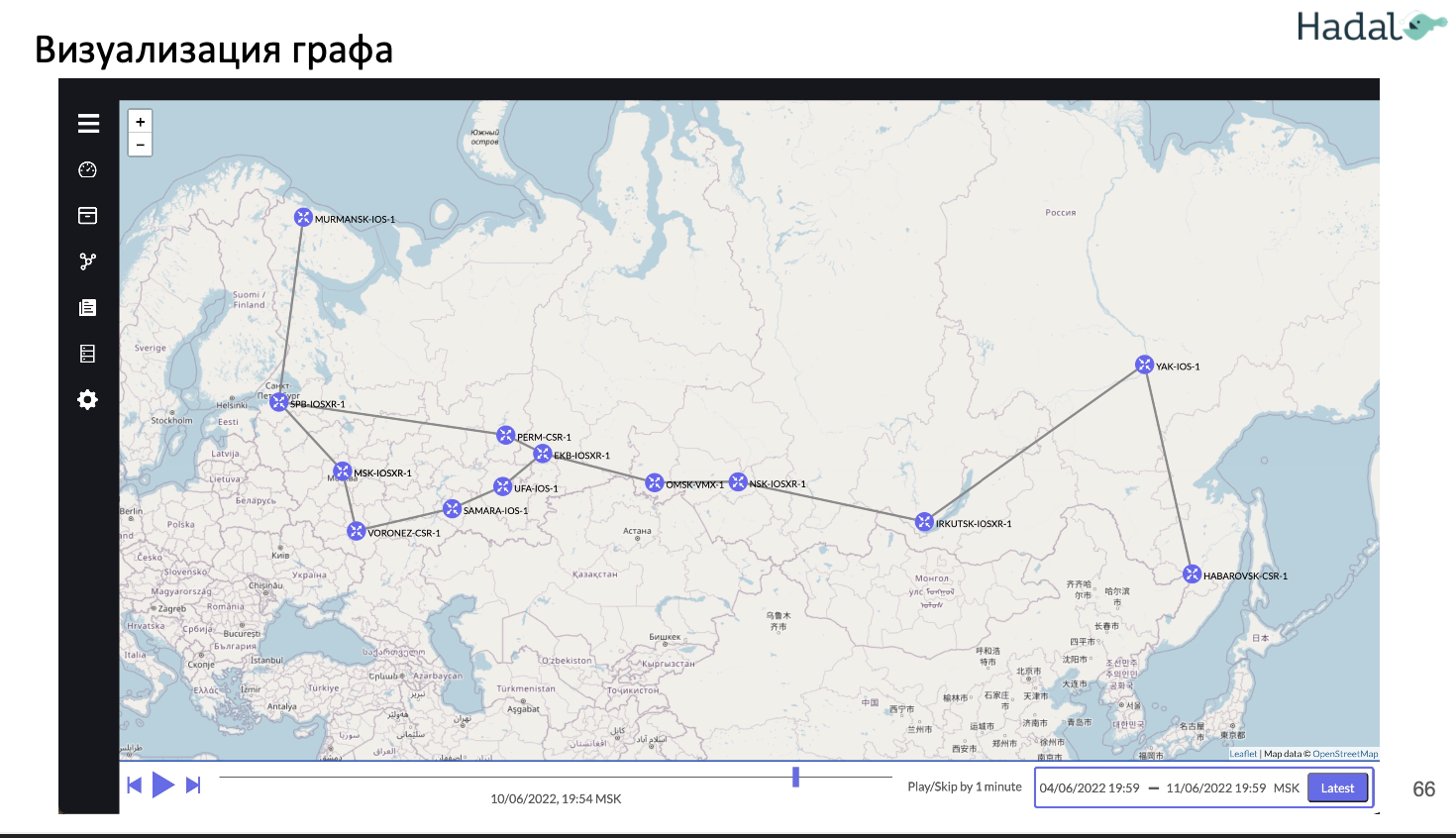

- Сократить время устранения сетевых сбоев на 40% – система используется при устранении критических сбоев.

- Автоматизировать документирование инфраструктуры – инвентарная информация заполняется автоматически, самописные скрипты инженеров выведены из эксплуатации.

- Упростить и ускорить задачи автоматизации управления оборудованием за счет предоставления нормализованных, вендор-независимых и всегда актуальных данных об оборудовании с возможностью дальнейшей выгрузки во внешние системы при помощи REST API.

Интересное из презентации Garda/ Гарда (чего нет выше)
Телеметрия vs Копия трафика

Мировые тенденциии анализа трафика
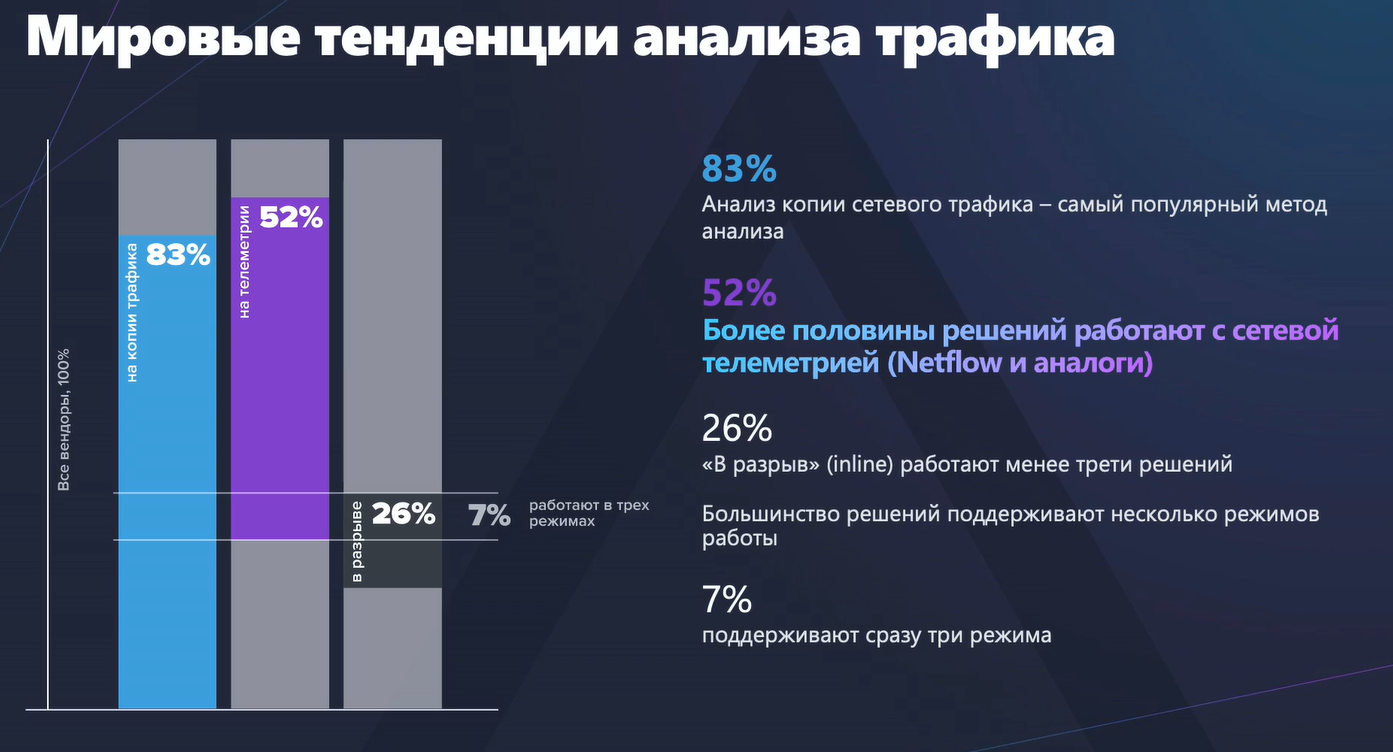
- Виды трафика
- Копия трафика / пакетный анализ: SPAN / RSPAN / ERSPAN , ICAP , TAP
- Сетевая телеметрия / анализ потоков: Netflow , sFlow , J-Flow , NSEL , IPFIX , NetStream

OTel
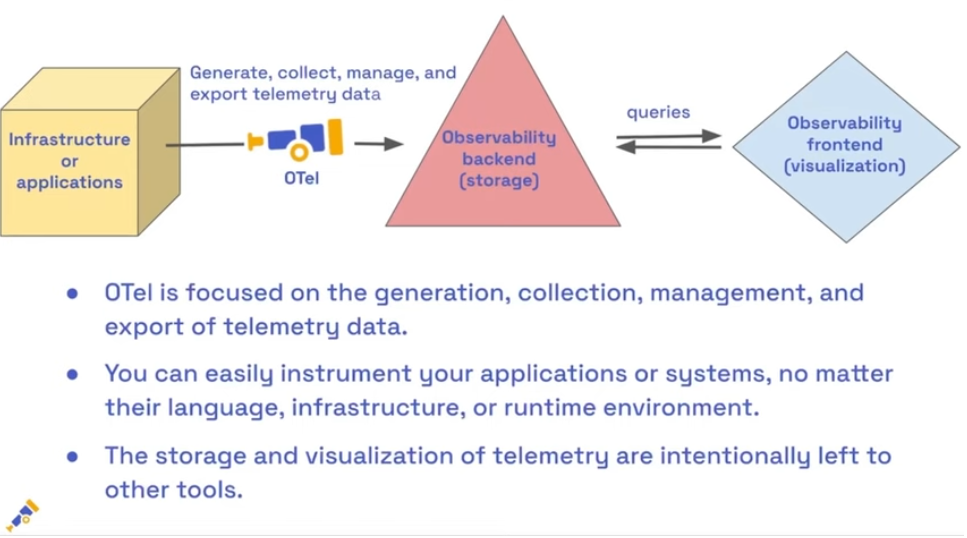

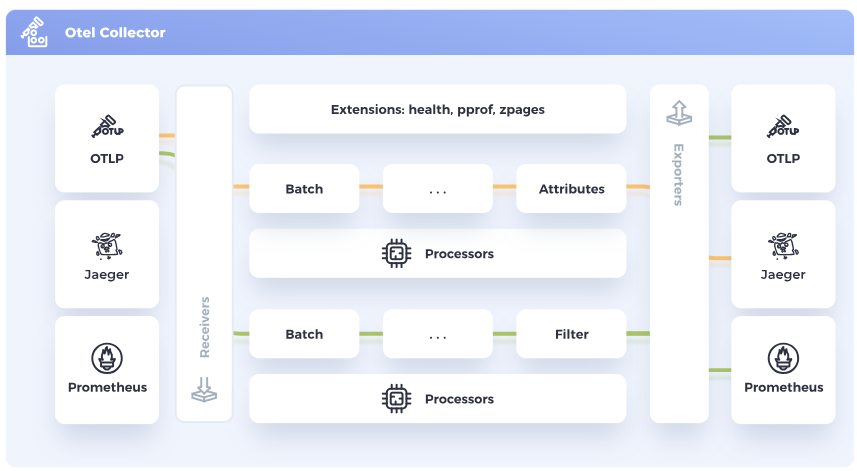
Сейчас самый лучший вариант это собирать данные в ОпенТелеметри Коллектор, а с ним работают все вендоры для визуализации данных, триггеров и т.п. Если есть вариант так сделать, то это самый прагматичный подход. Опентелеметри Коллектор это один бинарник на go. Он собирает сигналы (метрики, логи и трейсы) с приложений, кубернетисов, умеет из journald серверов логи собирать. Дальше он может обработать эти сигналы: добавить какие-то атрибуты, удалить, изменить или вообще отфильтровать. После этого он отправляет эти сигналы в хранилище где все эти данные хранятся. Хранилищем может выступать elastic search, clickhouse или какие-то другие решения. После этого к хранилищу прикручивается какая-то веб морда типа Графаны, но есть и другие self host решения: Signoz, openobserve. Довольно важно, чтоб все сигналы хранились и визуализировались в одном месте. Это позволяет удобно коррелировать, например, замедление приложения с проблемами на сети.